




El ser humano está expuesto a entornos acústicos cotidianos que resultan complejos y se convierten en un desafío incluso para las personas con audición dentro de los parámetros de la normalidad. La percepción del habla no depende simplemente de elementos invariables accesibles directamente en la onda acústica, sino que está condicionada por la intensidad del habla, del ruido ambiental, la cantidad de personas que conforman una conversación, factores específicos de cada individuo, la separación espacial de las fuentes de sonido, la reverberación ambiental, las señales audiovisuales, entre otras. El objetivo de este estudio es determinar la capacidad auditiva que tienen las personas normoyentes de discriminar la palabra hablada en condiciones acústicas existentes en la vida real y realizar el análisis fonético de las palabras erróneas.
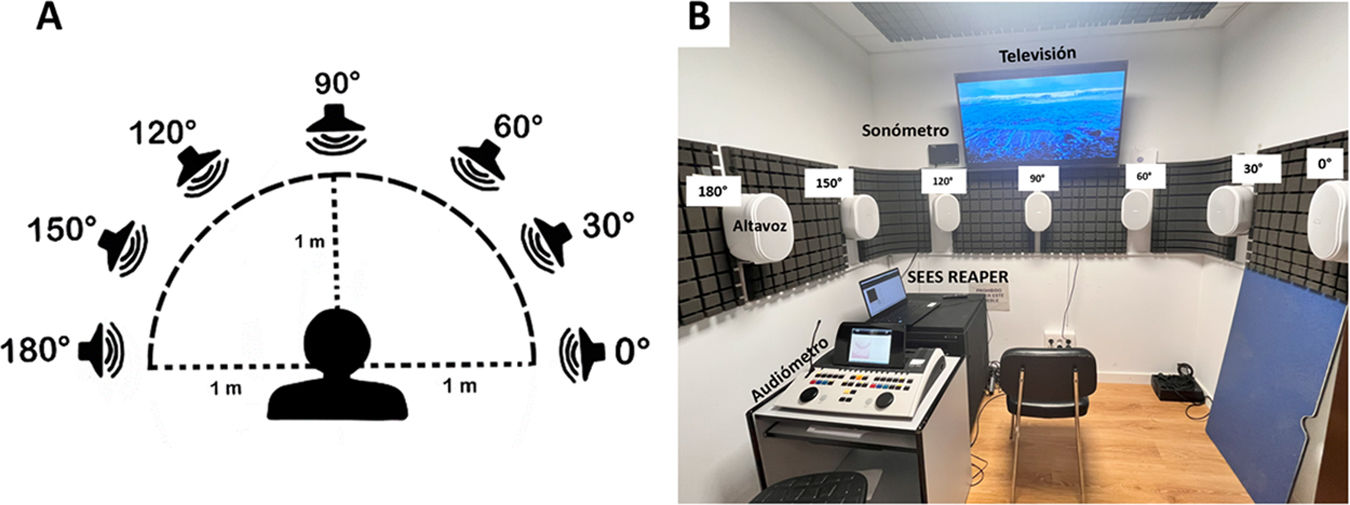
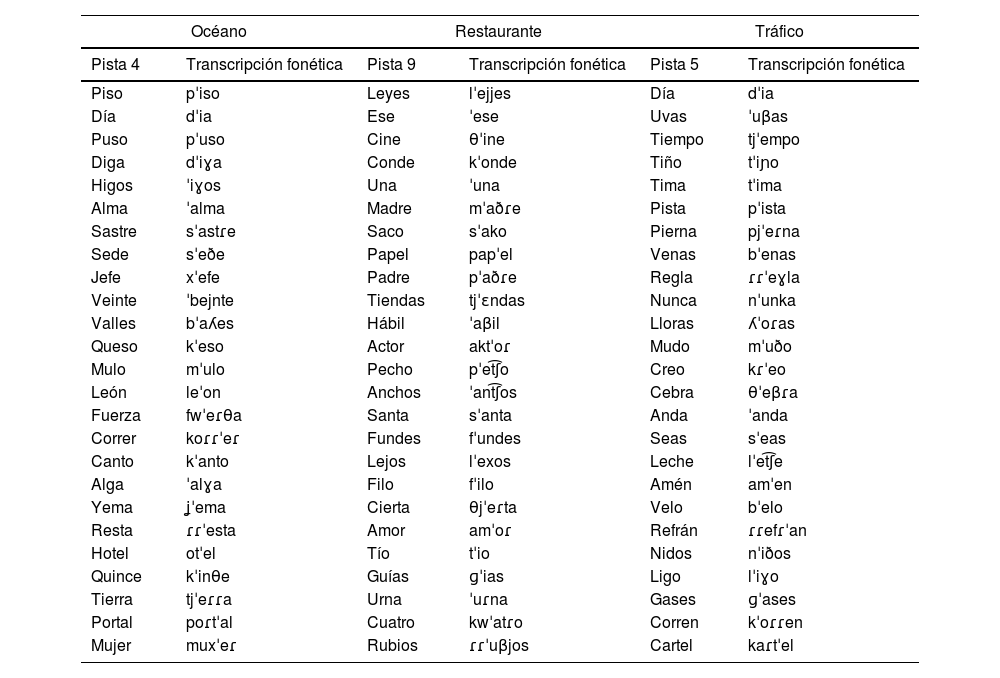
Materiales y métodosEs un estudio descriptivo observacional de corte transversal constituido por 20 personas normoyentes a los que se les realizó audiometrías verbales en campo libre enmascaradas con entornos sonoros reales simulados a distintos rangos de intensidad del sonido. La emisión de los sonidos se reforzó con el apoyo visual de imágenes alusivas en 2D transmitidas por una televisión. Se analizó el porcentaje de aciertos de las bisílabas emitidas y se realizó el análisis fonético de las palabras erróneas en cada entorno.
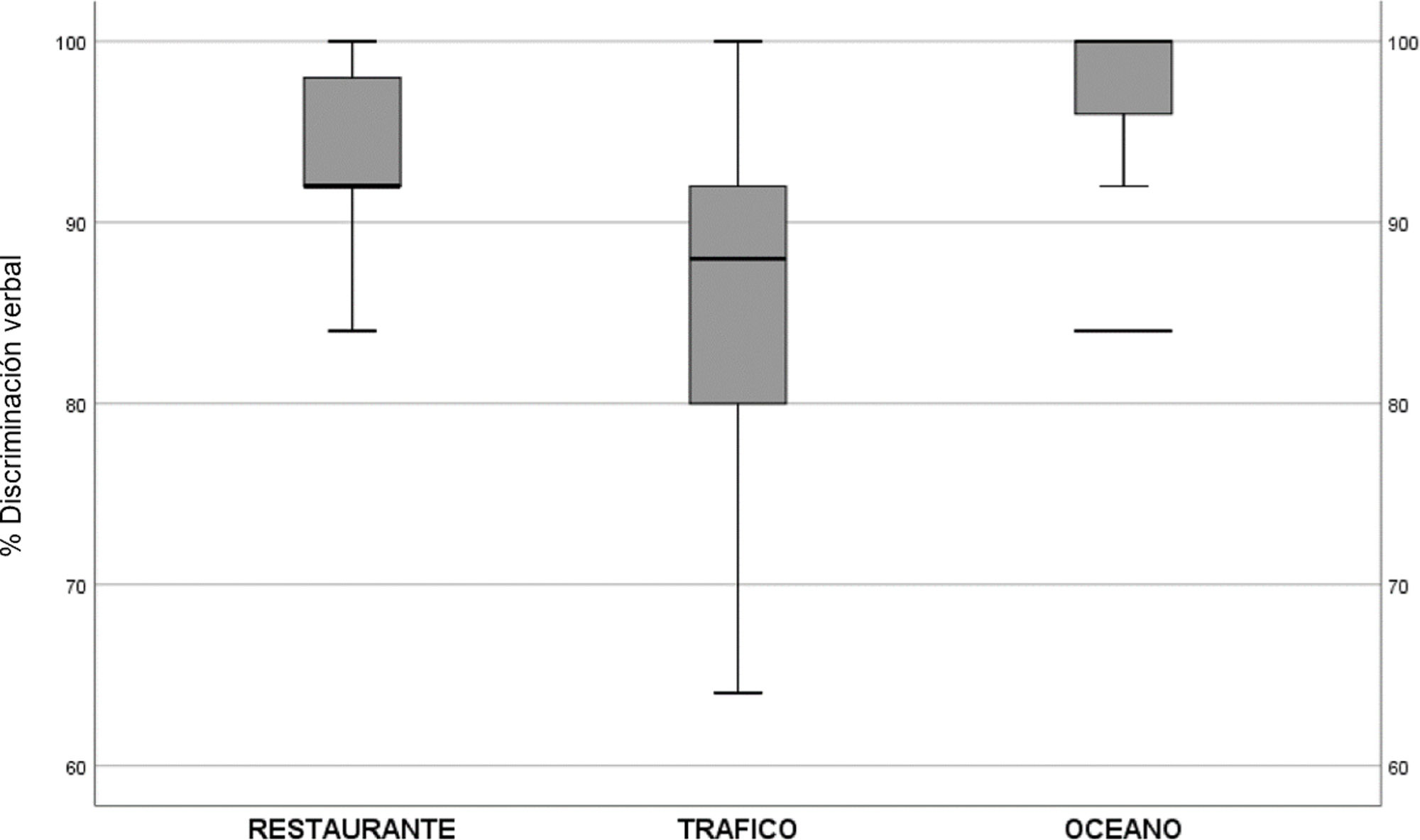
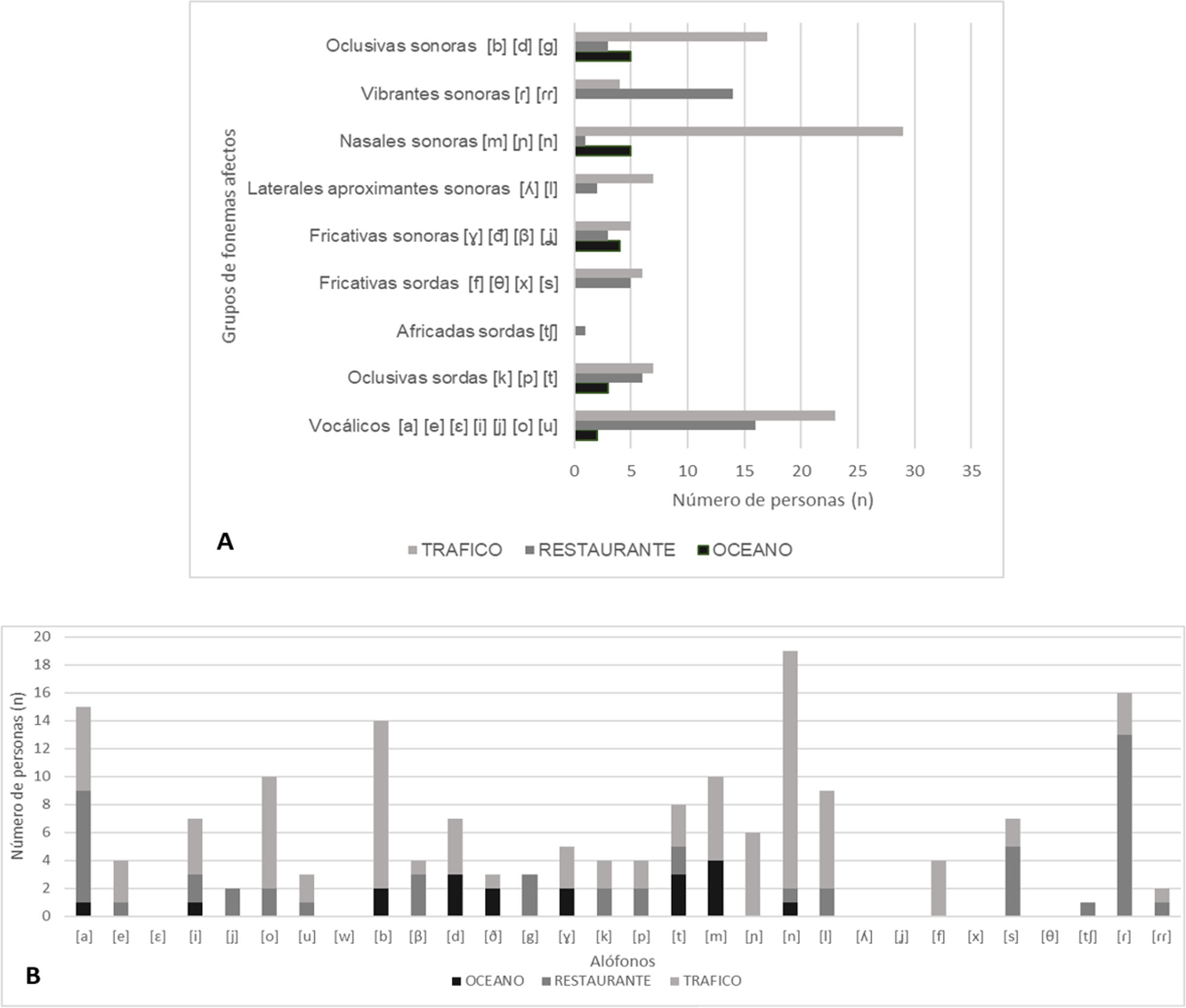
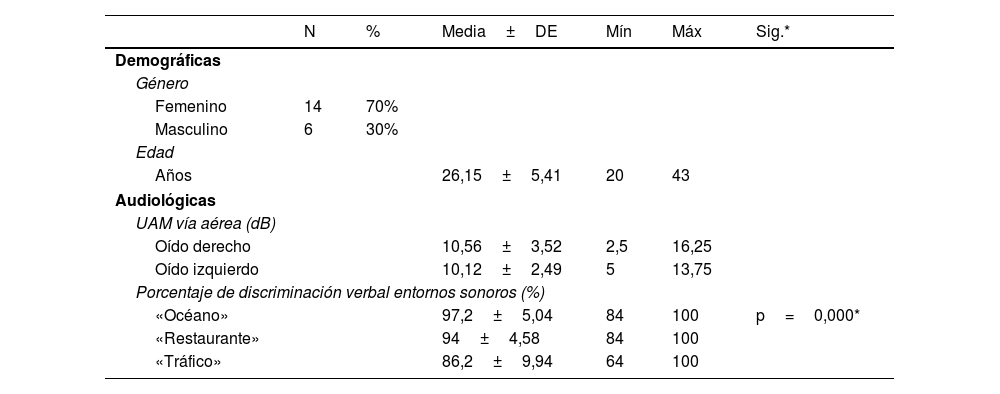
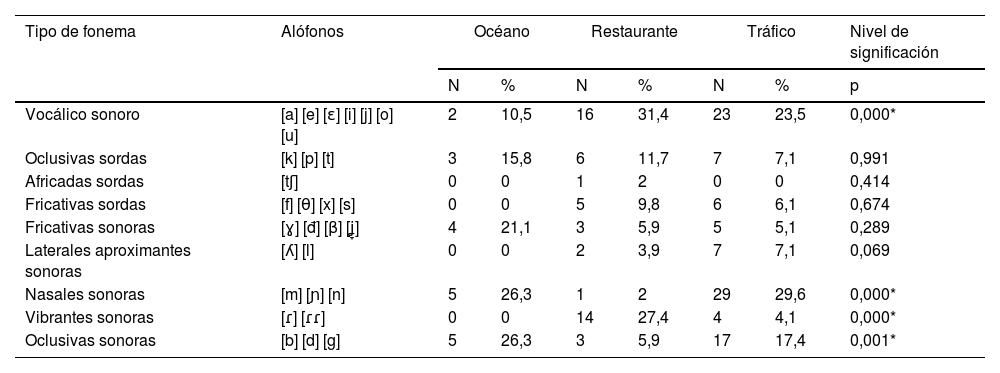
ResultadosUn total de 14 mujeres (70%) y 6 hombres (30%), con una edad promedio de 26±5,4 años y un umbral auditivo medio (UAM) de la vía aérea en oído derecho de 10,56±3,52dB SPL y en oído izquierdo de 10,12±2,49dB SPL. El porcentaje de discriminación verbal en el entorno sonoro «Océano» fue del 97,2±5,04%, «Restaurante» del 94±4,58%, y «Tráfico» del 86,2±9,94% (p=0,000). Con respecto al análisis fonético, los alófonos que presentaron diferencias estadísticamente significativas fueron: el alófono [o] (p=0,002) del grupo de fonemas vocálicos, el alófono [n] (p=0,000) de las consonantes nasales sonoras, el alófono [ɾ] (p=0,016) de las vibrantes sonoras, y los alófonos [b] (p=0,000) y [g] (p=0,045) de las oclusivas sonoras.
ConclusionesLas propiedades dinámicas del entorno acústico pueden afectar la capacidad de una persona con audición normal de comprender una señal verbal. Nuestro estudio demuestra que esta capacidad disminuye cuando la señal verbal está enmascarada por una o más voces simultáneas, como se observa en el entorno «Restaurante», y cuando está enmascarada por un ambiente de ruido continuo e intenso como el del entorno «Tráfico»: con respecto al análisis fonético, cuando el ambiente sonoro estaba compuesto por un ruido continuo y de baja frecuencia, las consonantes nasales sonoras [m] [ɲ] [n] fueron las más complicadas de identificar, y cuando existían estímulos verbales distractores, las vocales y las consonantes vibrantes sonoras [ɾ] [ɾɾ] fueron las que presentaron peor inteligibilidad.
Human beings are constantly exposed to complex acoustic environments every day, which even pose challenges for individuals with normal hearing. Speech perception relies not only on fixed elements within the acoustic wave but is also influenced by various factors. These factors include speech intensity, environmental noise, the presence of other speakers, individual specific characteristics, spatial separatios of sound sources, ambient reverberation, and audiovisual cues. The objective of this study is twofold: to determine the auditory capacity of normal hearing individuals to discriminate spoken words in real-life acoustic conditions and perform a phonetic analysis of misunderstood spoken words.
Materials and methodsThis is a descriptive observational cross-sectional study involving 20 normal hearing individuals. Verbal audiometry was conducted in an open-field environment, with sounds masked by simulated real-word acoustic environment at various sound intensity levels. To enhance sound emission, 2D visual images related to the sounds were displayed on a television. We analyzed the percentage of correct answers and performed a phonetic analysis of misunderstood spanish bisyllabic words in each environment.
Results14 women (70%) and 6 men (30%), with an average age of 26±5,4 years and a mean airway hearing threshold in the right ear of 10,56±3,52dB SPL and in the left ear of 10,12±2,49dB SPL. The percentage of verbal discrimination in the ‘Ocean’ sound environment was 97,2±5,04%, ‘Restaurant’ was 94±4,58%, and ‘Traffic’ was 86,2±9,94% (p=0,000). Regarding the phonetic analysis, the allophones that exhibited statistically significant differences were as follows: [o] (p=0,002) within the group of vocalic phonemes, [n] (p=0,000) of voiced nasal consonants, [ɾ] (p=0,0016) of voiced fricatives, [b] (p=0,000) and [g] (p=0,045) of voiced stops.
ConclusionsThe dynamic properties of the acoustic environment can impact the ability of a normal hearing individual to extract information from a voice signal. Our study demonstrates that this ability decreases when the voice signal is masked by one or more simultaneous interfering voices, as observed in a ‘Restaurant’ environment, and when it is masked by a continuous and intense noise environment such as ‘Traffic’. Regarding the phonetic analysis, when the sound environment was composed of continuous-low frequency noise, we found that nasal consonants were particularly challenging to identify. Furthermore, in situations with distracting verbal signals, vowels and vibrating consonants exhibited the worst intelligibility.
