









Generative artificial intelligence is a technology that provides greater connectivity with people through conversational bots (“chatbots”). These bots can engage in dialogue using natural language indistinguishable from humans and are a potential source of information for patients. The aim of this study is to examine the performance of these bots in solving specific issues related to orthopedic surgery and traumatology using questions from the Spanish MIR exam between 2008 and 2023.
Material and methodsThree “chatbot” models (ChatGPT, Bard and Perplexity) were analyzed by answering 114 questions from the MIR. Their accuracy was compared, the readability of their responses was evaluated, and their dependence on logical reasoning and internal and external information was examined. The type of error was also evaluated in the failures.
ResultsChatGPT obtained 72.81% correct answers, followed by Perplexity (67.54%) and Bard (60.53%). Bard provides the most readable and comprehensive responses. The responses demonstrated logical reasoning and the use of internal information from the question prompts. In 16 questions (14%), all three applications failed simultaneously. Errors were identified, including logical and information failures.
ConclusionsWhile conversational bots can be useful in resolving medical questions, caution is advised due to the possibility of errors. Currently, they should be considered as a developing tool, and human opinion should prevail over generative artificial intelligence.
La inteligencia artificial generativa es una tecnología que ofrece su mayor conectividad con las personas gracias a los bots conversacionales («chatbot»). Estos pueden mantener un diálogo con un lenguaje natural indistinguible del humano y son una fuente potencial de información para los pacientes. El objetivo de este trabajo es estudiar el rendimiento de estos bots en la resolución de cuestiones específicas de cirugía ortopédica y traumatología empleando las preguntas del examen MIR español entre 2008 y 2023.
Material y métodosSe analizaron 3 modelos de «chatbots» (ChatGPT, Bard y Perplexity) respondiendo a 114 preguntas del MIR. Se compararon aciertos, se valoró la legibilidad de las respuestas y se examinó su dependencia con el razonamiento lógico y la información interna y externa. En los fallos también se evaluó el tipo de error.
ResultadosChatGPT obtuvo un 72,81% de aciertos, seguido por Perplexity (67,54%) y Bard (60,53%). Las respuestas más legibles y completas las ofrece Bard. Las respuestas demostraron un razonamiento lógico y el uso de información interna de los enunciados de preguntas. En 16 preguntas (14%) las 3 aplicaciones fallaron simultáneamente. Se identificaron errores, que incluían fallos lógicos y de información.
ConclusionesAunque los bots conversacionales pueden ser útiles en la resolución de preguntas médicas, se señala la necesidad de precaución debido a la posibilidad de errores. Actualmente deben considerarse como una herramienta en desarrollo, y la opinión humana debe prevalecer sobre la inteligencia artificial generativa.
Artificial intelligence (AI) encompasses technological developments that emulate the cognitive abilities of humans. In orthopaedic surgery and traumatology, applications include image recognition and diagnosis, medical text records, rehabilitation and postoperative care, surgical training, and predictive algorithms.1 In recent years, AI has gone a step further by becoming generative AI. That is to say, it no longer simply analyses problems and solves them, but with the data it is provided with, it improves its learning and generates original content (text, images, videos, presentations, molecules, etc.).2
Recently, chatbots or conversational bots have become popular. These are generative AIs that have the ability to maintain a conversation, giving coherent and human-like responses. Their behaviour can even be modulated when responding, lending a certain amount of “personality” to the responses.
In November 2022, the free conversational bot (or “chatbot”) called ChatGPT (generative pre-trained transformer) by the company OpenAI (OpenAI, LLC, San Francisco, California, USA) developed in Python language was launched. Its main limitation was that it only had access to the Internet until 2021, but the new (paid) version has already updated access to the network. In addition, it is multimodal, allowing text and image input to generate response.
In response to this application, several technology companies launched other “chatbots” onto the market, such as Bing by Microsoft (Microsoft Corporation, Redmond, Washington, USA) or Bard by Google (Google LLC, Mountain View, California, USA) or Perplexity by designers Denis Yarats, Aravind Srinivas, Johnny Ho and Andy Konwinsk. The latter has the particularity of providing citations to support its information.
These ground-breaking technological developments are creating a range of options yet to be explored and have enormous implications in the fields of medicine and teaching.3 This is not only because they offer answers to questions that are raised, but because they can generate information with multiple uses. Their capabilities continuously grow and they are even beginning to recognise voices, images and videos, resulting in exponential potential.
Patients use this technology to answer questions about medicine and health4 and professionals to solve cases5 or create scientific texts.6,7 They even generate answers which contain more, better quality information, and with greater empathy than humans are capable of,8 although some patients rarely accept its use as a substitute for professionals.9 Obviously, this has important legal and ethical connotations, which involve responsibility in decision-making or in authorship of scientific production.10 All the more so, when the presence of errors, known as “hallucinations”,11 is detected, and these are more common than what a sensitive-data-generating “intelligence” should supposedly produce. We should remember that, in 2022, 40% of Internet users turned to the Internet in search of information on health issues.12
The development of conversational AI is based on three pillars: machine learning, big data and natural language processing.2 Machine learning enables computers to automatically learn and improve from experience without having been specifically programmed to do so. Data is analysed using algorithms to identify patterns and make decisions with varying degrees of human supervision. The machine architecture uses neural networks that mimic the functioning of the human brain. This enables deep learning by processing vast amounts of data, or “big data”, which includes unstructured or unlabelled data such as images, audio and text, to perform tasks such as voice or image recognition. Version 3 of ChatGPT was trained with 175 billion parameters. This means that the AI does not search the network for information, but rather generates responses by following predictive models from the information it has collected and processed into smaller units (known as “tokens”). In this sense, there are authors who advocate talking about “computational statistical learning” instead of “artificial intelligence”.13 This explains why AI has failures, or “hallucinations” in computer jargon, largely due to its ability or lack thereof to handle the data it feeds on and generate results following stochastic patterns. If we add to this the effect known as GIGO (Garbage In Garbage Out)7 we are looking at a system that requires a learning and supervision process.
Natural language processing is another area of AI that deals with the interaction between machine and human language. Thanks to this application, text can be understood, interpreted and generated efficiently. All of this leads to processing the order or “prompt”, “understanding” it and responding in a natural and suposedly correct way. It also adds the ability to remember previous conversations.
In the field of medicine,14 huge amounts of electronic medical records can be processed, enabling them to be analysed and organised to obtain efficient and accurate information. In the surgical field,1 AI can provide the simulation of complex surgical procedures in virtual environments. Moreover, patterns of success and areas of improvement in surgical training can be identified, improving the quality and safety of medical care.
The objective of this study was to study and compare the capacity of conversational AI to solve orthopaedic surgery and traumatology questionnaires used in the national exam to obtain a position as a resident physician.
Material and methodAll questions from the Spanish medical training entrance exam (MIR exam) from 2008 to 2023 were reviewed. The inclusion criteria were: questions relating to traumatology and orthopaedic surgery. The exclusion criteria were: questions cancelled by the governing body or those containing images that were necessary for answering the question.
The questions were multiple choice with four or five answer options and only one correct answer. Some of the questions included images. Since not all applications have image recognition, those that required perusal of the image to answer were excluded. The questions were grouped according to the subject in traumatology, adult orthopaedics, paediatric orthopaedics and spine, and according to the year. In addition, they were classified into two types according to the knowledge needed to give the answer15: type 1, only one piece of knowledge was required and type 2, several steps were needed to reach the answer.
The answers were analysed by assessing narrative coherence.16 The data were binary and included three sections: logical reasoning (if the answer was selected based on the information presented), internal information (the answer included information provided in the question) and external information (the answer provided information external to that provided). We also analysed the readability of Flesch–Kincaid,17,18 adapted to Spanish by Fernández Huerta19 and corrected by Law.20 The result shows the ease of understanding a text and correlates it with the level of education as a result of this formula:
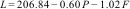
L is “readability”; P, the average number of syllables per word; F, the average number of words per sentence.
The INFLESZ21 scale was also used, which measures the ease of reading a text, as well as the number of words in each response.
When errors occurred, they were labelled as logical errors (correct information is found but not transferred to the response), information errors (a key piece of information provided in the question or in external information is not identified) and statistical errors (based on arithmetic errors, e.g. incorrect estimation of the frequency of a disease).22
The AI engines evaluated were ChatGPT (version 3.5), Bard and Perplexity (Fig. 1). All responses were obtained within a period of 48h. When writing this work, the Bard application was renamed Gemini, but since the results were obtained with the first name, it was kept in the results and conclusions.

The data collected were quantitative, qualitative and descriptive. Qualitative variables are presented with their absolute frequency and relative percentage. To compare qualitative values of a dichotomous nature, Cochran's Q test was used, and for quantitative values, the ANOVA test was used if it met normality and the Kruskal–Wallis test if it did not. The accepted alpha risk for all hypothesis contrasts was .05. If the test was significant, a post-hoc test was performed for pairwise comparison of variables. The data were analysed using the MedCalc program version 22.016 (MedCalc Software Ltd, Ostend, Belgium; https://www.medcalc.org; 2023) for data processing and statistical study. The null hypothesis (H0) that we assumed was that the success rate of the different programmes evaluated was the same.
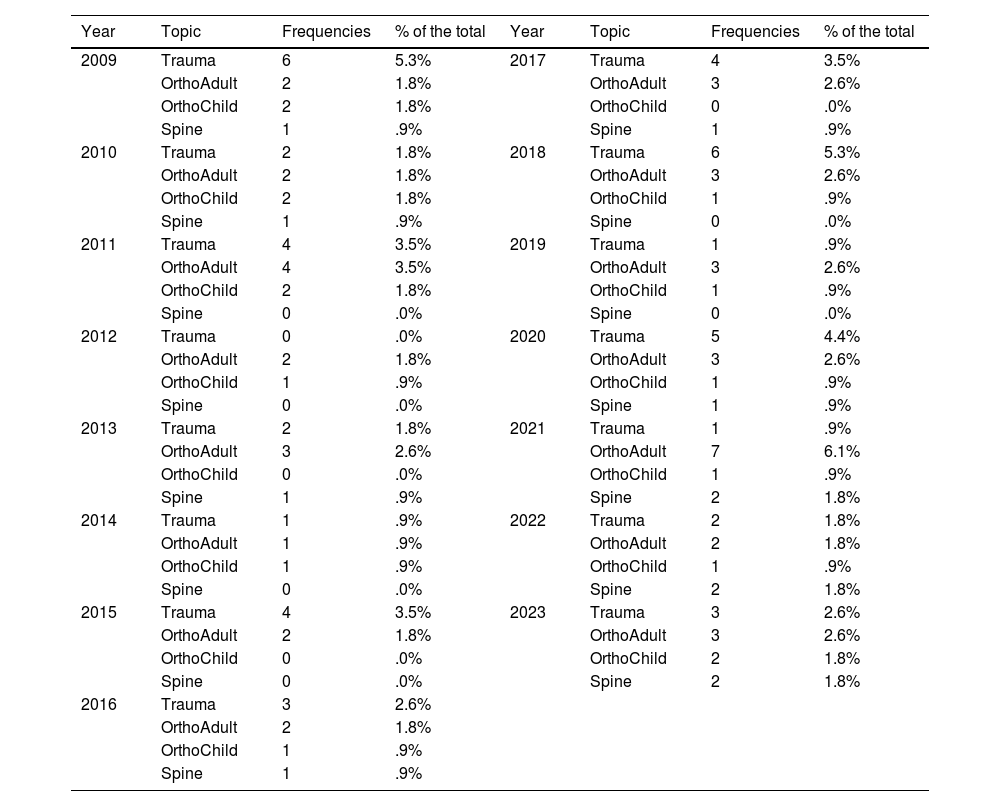
ResultsInitially, 129 questions were collected from the MIR exams related to orthopaedic surgery and traumatology. Fifteen were excluded because they included images (14 questions) and one because it had been cancelled. Table 1 shows the distribution of the questions by year and topic.
Frequency of topic/year.
| Year | Topic | Frequencies | % of the total | Year | Topic | Frequencies | % of the total |
|---|---|---|---|---|---|---|---|
| 2009 | Trauma | 6 | 5.3% | 2017 | Trauma | 4 | 3.5% |
| OrthoAdult | 2 | 1.8% | OrthoAdult | 3 | 2.6% | ||
| OrthoChild | 2 | 1.8% | OrthoChild | 0 | .0% | ||
| Spine | 1 | .9% | Spine | 1 | .9% | ||
| 2010 | Trauma | 2 | 1.8% | 2018 | Trauma | 6 | 5.3% |
| OrthoAdult | 2 | 1.8% | OrthoAdult | 3 | 2.6% | ||
| OrthoChild | 2 | 1.8% | OrthoChild | 1 | .9% | ||
| Spine | 1 | .9% | Spine | 0 | .0% | ||
| 2011 | Trauma | 4 | 3.5% | 2019 | Trauma | 1 | .9% |
| OrthoAdult | 4 | 3.5% | OrthoAdult | 3 | 2.6% | ||
| OrthoChild | 2 | 1.8% | OrthoChild | 1 | .9% | ||
| Spine | 0 | .0% | Spine | 0 | .0% | ||
| 2012 | Trauma | 0 | .0% | 2020 | Trauma | 5 | 4.4% |
| OrthoAdult | 2 | 1.8% | OrthoAdult | 3 | 2.6% | ||
| OrthoChild | 1 | .9% | OrthoChild | 1 | .9% | ||
| Spine | 0 | .0% | Spine | 1 | .9% | ||
| 2013 | Trauma | 2 | 1.8% | 2021 | Trauma | 1 | .9% |
| OrthoAdult | 3 | 2.6% | OrthoAdult | 7 | 6.1% | ||
| OrthoChild | 0 | .0% | OrthoChild | 1 | .9% | ||
| Spine | 1 | .9% | Spine | 2 | 1.8% | ||
| 2014 | Trauma | 1 | .9% | 2022 | Trauma | 2 | 1.8% |
| OrthoAdult | 1 | .9% | OrthoAdult | 2 | 1.8% | ||
| OrthoChild | 1 | .9% | OrthoChild | 1 | .9% | ||
| Spine | 0 | .0% | Spine | 2 | 1.8% | ||
| 2015 | Trauma | 4 | 3.5% | 2023 | Trauma | 3 | 2.6% |
| OrthoAdult | 2 | 1.8% | OrthoAdult | 3 | 2.6% | ||
| OrthoChild | 0 | .0% | OrthoChild | 2 | 1.8% | ||
| Spine | 0 | .0% | Spine | 2 | 1.8% | ||
| 2016 | Trauma | 3 | 2.6% | ||||
| OrthoAdult | 2 | 1.8% | |||||
| OrthoChild | 1 | .9% | |||||
| Spine | 1 | .9% |
According to the type of question, there were 49 (43%) of type I (requiring one piece of knowledge) and 65 (57%) of type II (requiring several to obtain the answer).
The ChatGPT application obtained 83 correct answers (72.81%), compared to 69 (60.53%) for Bard and 77 (67.54%) for Perplexity. We found statistical significance in the Cochran Q test (0.049) regarding the frequency distribution between the groups, and when the post-hoc analysis was performed, a significant difference was only found in ChatGPT compared to Bard, but not between the other pairs. If we group the answers according to the type of question, we observe that in type I ChatGPT gets 36 (73.47%) correct, Bard gets 27 (55.10%) and Perplexity 36 (73.47%) which shows a significant difference (.030) but in the multiple comparisons it does not find differences between pairs due to the sample size of the subgroup. In type II questions we do not find significant differences between groups, ChatGPT obtained 47 (72.31%) correct answers, compared to 42 (64.62%) for Bard and 41 (63.08%) for Perplexity.
Table 2 shows the accumulation of correct answers for each of the questions when answering the three “chatbots”.
In the analysis of each programme's responses, ChatGPT used logical reasoning in 92 (80.7%), internal information in 108 (94.7%) and external information in 50 (43.8%). In Bard, logical reasoning was used in 114 (100%) responses, internal information in 114 (100%) and external information in 111 (97.3%). In Perplexity, logical reasoning was used in 109 (95.6%) responses, internal information in 113 (99.1%) and external information in 60 (52.6%). In this last section, we noted that this application included citations that were linked to web pages but external information was not considered since it would require an evaluation that differed from the purpose of this study. When analysing logical reasoning, we found statistical significance (p<.001) in favour of Bard compared to the rest. This difference (p<.001) is also present in the external information provided, favouring Bard over its competitors. The internal information shows a significant difference (p=.012) between Bard and ChatGPT in favour of the former. Table 3 analyses the responses according to the correct and incorrect answers.
Analysis of answers.
| ChatGPT | Bard | Perplexity | ||||
|---|---|---|---|---|---|---|
| Correct(n=83) | Incorrect(n=31) | Correct(n=69) | Incorrect(n=45) | Correct(n=77) | Incorrect(n=37) | |
| Logical reasoning | ||||||
| Yes | 69 (83.1%) | 23 (74.4%) | 69 (100%) | 45 (100%) | 72 (93.5%) | 37 (100%) |
| No | 14 (16.9%) | 8 (25.8%) | 0 (0%) | 0 (0%) | 5 (6.5%) | 0 (0%) |
| Internal information | ||||||
| Yes | 79 (95.2%) | 29 (93.5%) | 69 (100%) | 45 (100%) | 76 (98.7%) | 37 (100%) |
| No | 4 (8%) | 2 (6.5%) | 0 (0%) | 0 (0%) | 1 (1.3%) | 0 (0%) |
| External information | ||||||
| Yes | 41 (49.45) | 9 (29.1%) | 66 (95.7%) | 45 (100%) | 44 (57.1%) | 16 (43.3%) |
| No | 42 (50.6%) | 22 (70.9%) | 3 (4.3%) | 0 (0%) | 33 (42.9%) | 21 (56.7%) |
Statistical analysis of the subgroups “Correct” and “Failure” flagged up significant differences (p<.001) in the external information and in the logical reasoning in favour of Bard. We found no significant differences in the analysis of the internal information in the subgroups that get the question right or wrong.
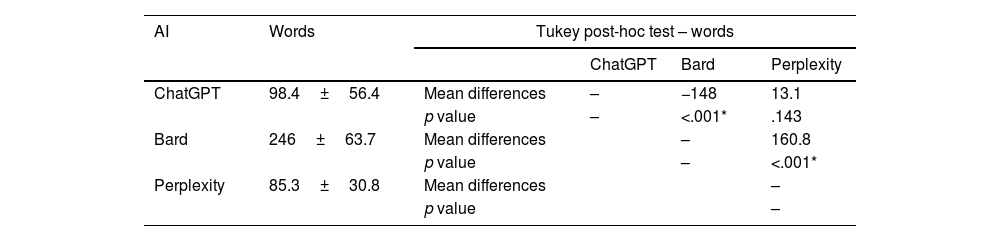
Comparison between the number of words in each answer clarified a significant difference. The analysis of the pairwise differences is shown in Table 4.
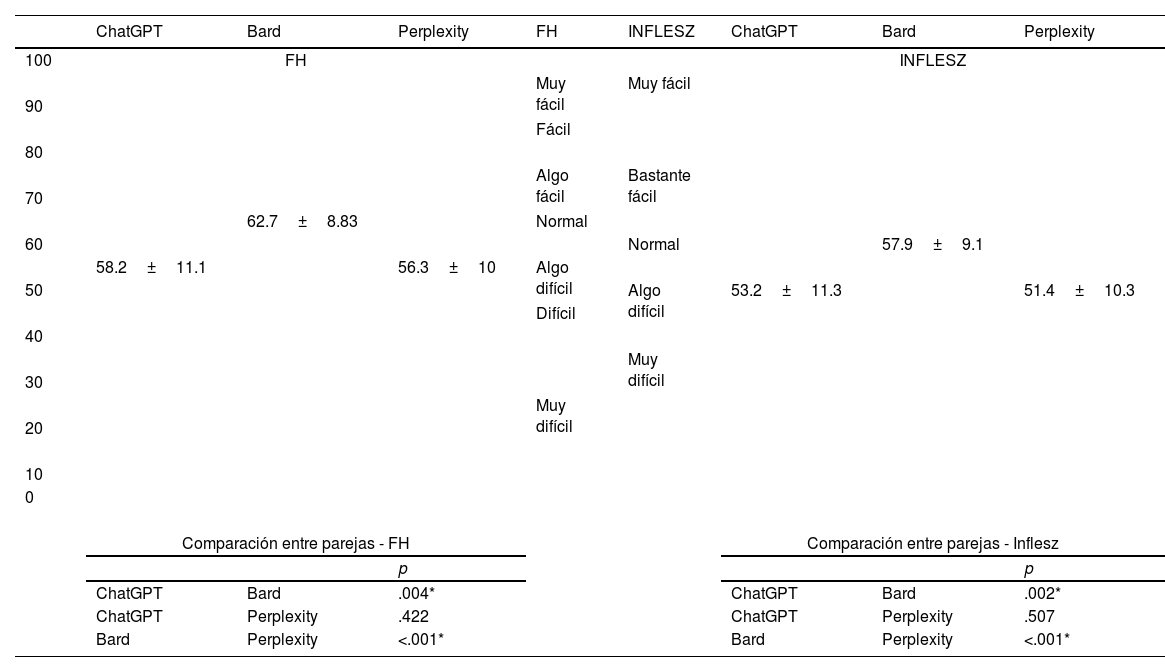
This significant difference was also obtained in the analysis of the modified index of “readability” of Fernández Huerta and in the INFLESZ scale. The comparisons between groups are shown in Table 5. To show the relationship between the scores and the levels of “readability”, the different levels of each scale are provided in the table.
Legibility of answers.
| ChatGPT | Bard | Perplexity | FH | INFLESZ | ChatGPT | Bard | Perplexity | |
|---|---|---|---|---|---|---|---|---|
| 100 | FH | INFLESZ | ||||||
| Muy fácil | Muy fácil | |||||||
| 90 | ||||||||
| Fácil | ||||||||
| 80 | ||||||||
| Algo fácil | Bastante fácil | |||||||
| 70 | ||||||||
| 62.7±8.83 | Normal | |||||||
| 60 | Normal | 57.9±9.1 | ||||||
| 58.2±11.1 | 56.3±10 | Algo difícil | ||||||
| 50 | Algo difícil | 53.2±11.3 | 51.4±10.3 | |||||
| Difícil | ||||||||
| 40 | ||||||||
| Muy difícil | ||||||||
| 30 | ||||||||
| Muy difícil | ||||||||
| 20 | ||||||||
| 10 | ||||||||
| 0 | ||||||||
| Comparación entre parejas - FH | Comparación entre parejas - Inflesz | |||||||
| p | p | |||||||
| ChatGPT | Bard | .004* | ChatGPT | Bard | .002* | |||
| ChatGPT | Perplexity | .422 | ChatGPT | Perplexity | .507 | |||
| Bard | Perplexity | <.001* | Bard | Perplexity | <.001* | |||
FH: Fernández Huerta index.
There are 31 wrong answers in ChatGPT. The reason is logical error in 10 (32.2%), information error in 13 (41.9%) (Fig. 2), statistical error in one (3.2%) and combination of logical and information error in 7 (22.5%).

Bard had 45 incorrect answers. Logical error in 3 (6.6%), information error in 3 (6.6%), statistical error in 1 (2.2%) (Fig. 3) and combination of logical and information error in 38 (84.4%).

Perplexity had 37 inaccurate answers, the cause was logical error in 9 (24.3%) (Fig. 4), information error in 14 (37.8%), statistical error in 2 (5.4%) and combination of logical and information error in 2 (32.4%).
Discussion
Our results indicate that the conversational AI programmes analysed (ChatGPT, Bard and Perplexity) pass the exam with orthopaedic surgery and traumatology questions taken from the MIR exam for the period 2008–2023. The ChatGPT application is better than Bard but similar in results to Perplexity. Our data improves on the previous data of Jin et al.15 in similar North American exams and those of Carrasco et al.23 who analysed the Spanish MIR exam of 2022 where 54.8% of global questions without images were answered correctly and which rose to 62.5% in the subgroup of traumatology questions. This improvement relies on the process of continuous improvement these systems are prone to. The analysis of correct answers according to the type of question is inconclusive, which suggests that the app responds similarly to questions with one, or several, reasons, at least with this sample size.
Our results reveal that all three apps use logical reasoning and external information in a large number of their correct answers, with Bard ranking first here. However, this advantage does not translate into obtaining the best results.
AI hallucinations include biases (they can give xenophobic answers, for example), mistakes or omissions.24 This problem, inherent to the design and operational structure of the model, undermines the reputation of the AI, negatively affects decision-making and can lead to ethical and legal conflicts.25 To avoid this problem, it has been recommended to use several AIs to reinforce the quality of the answer. Our results indicate that almost half of the questions were answered correctly by the three AIs simultaneously. However, 14% of the questions were incorrectly answered by all of them. The use of several AIs does not therefore completely eliminate the presence of hallucinations.
It is interesting to note that incorrect answers include logical reasoning and use of internal information. In ChatGPT it was known that the errors had less support from these two factors.22 In the case of Bard and Perplexity, they appear in 100% of the errors, which would indicate that this model justifies its information based on providing more complete answers backed up by the actual information from the question. Regarding the use of external information, Bard stands out for providing as many correct answers as erroneous ones. In all three, external information appears more in correct answers than in incorrect ones, particularly in ChatGPT.22,23 As previously stated, Perplexity includes citations to other sites, but the objective of this study was to determine the response the app provided, not to analyse its sources. The provision of citations could be considered of great value in supporting a response, but it outside the realm of this study.
Text legibility is essential in generative “chatbots” that offer medical information. We know that the chatbot improves with shorter sentences containing fewer words,21 although it is also related to the complexity of the words or the presence of visuals.26 It is interesting to note that Bard offers a better comprehension capacity than the other analysed apps. Furthermore, it often adds images to improve the information. The ChatGPT and Perplexity produce “somewhat difficult” responses, which may affect the dialogic interaction with untrained users.
This study has its limitations. Firstly, the MIR exam questions are incomparable with the questions an AI user could ask. The purpose of this study was not so much to know if they would pass an exam but how they would respond to the questions and how they would offer greater or lesser information. Secondly, we know that the “chatbot” allows the response to be modulated according to the indications we give it, using orders or prompts which improve it in terms of quantity or quality, but we have avoided using this modulation so that the response was as “spontaneous” as possible. Thirdly, two assessment systems out of other existing ones were used for the type of responses. The decision was based on the fact that they had been contrasted for the Spanish language and for medical texts without comparative studies between them. Another possible limitation is that ChatGPT 3.5 had no access to Internet information from 2021 onwards compared with the other two systems, but we understand that the majority of the population uses free apps and the comparison was therefore objective and also the questions analysed did not include data that required information from 2021 onwards. It is interesting to note that systems with a greater volume of answers, legibility and external information did not achieve better results.
This study provides the basis for further research into this novel and interesting topic. We suggest investigating the dialogic interaction of patients with their medical questions, or how a chat can explain the medical information we offer to our patients, or how the modulation of questions through prompts can improve the quality of responses. The reliability of these programmes could also be compared with students or medical personnel, both in training and in practice.
To conclude, conversational chatbots can be a very interesting tool for resolving medical issues, but they are not exempt from making mistakes, or “hallucinations”, which can have important implications for patients and doctors. We should warn against their use in the general untrained population and remember that medical information produced by medical professionals must prevail hierarchically over the development of generative AI.
Level of evidenceLevel of evidence IV.
Ethical considerationsThe study was not conducted on humans or animals and did not require informed consent. Nor did it require approval from the Ethics Committee.
FundingNo funding was received for this article.
Conflict of interestsThe authors have no conflict of interests to declare.
