





Demostrar que mediante técnicas estadísticas es posible obtener un número reducido de perfiles de glucosa de 4h con los que se puede identificar cualquier comportamiento de la glucosa en pacientes con diabetes mellitus tipo1.
Material y métodosSe ha realizado un estudio retrospectivo de 10pacientes con diabetes mellitus tipo1, con datos adquiridos mediante monitorización continua de glucosa. Se ha utilizado una técnica de minería de datos basada en árboles de decisión denominada CHAID (CHi-square Automatic Interaction Detection) para clasificar los perfiles de glucosa en grupos utilizando dos criterios de decisión. Por un lado, los diferentes días (lunes; martes; miércoles; jueves; viernes; sábado; domingo); por otro, diferentes franjas del día, dividiendo el día en seis tramos de 4h cada uno (00:00-04:00h; 04:00-08:00h; 08:00-12:00h; 12:00-16:00h; 16:00-20:00h; 20:00-24:00h). Las agrupaciones se han realizado de acuerdo a los niveles de glucosa registrados, mediante diferencias estadísticamente significativas encontradas.
ResultadosSe han observado diferencias significativas (p<0,05) y dependencias entre los perfiles de glucosa clasificados en función de las variables independientes día de la semana y franja horaria, siendo las relaciones encontradas distintas para cada paciente, demostrando la necesidad de hacer un estudio individualizado.
ConclusionesLos resultados obtenidos facilitarán la modelización matemática de la glucosa y podrán utilizarse para la creación de un clasificador individualizado para cada paciente que clasifique los perfiles de glucosa en función de las variables día de la semana y franja horaria. Utilizando este clasificador se podrán predecir los valores de glucosa del paciente conociendo en qué día de la semana se encuentra y en qué franja horaria, obteniendo modelos más precisos. También el profesional de la salud podrá mejorar los hábitos y las terapias de los pacientes.
To show that statistical techniques allow for obtaining a reduced number of four-hour glucose profiles that can identify any glucose behavior in patients with type1 diabetes mellitus.
Material and methodsA retrospective study of 10 patients with type1 diabetes mellitus was conducted using data collected by continuous glucose monitoring. A data mining technique based on decision trees called CHAID (Chi-square Automatic Interaction Detection) was used to classify glucose profiles into groups using two decision criteria. These were: 1, the seven days of the week, and 2, different time slots, the day being divided into six sections of four hours each. Clustering was performed according to the glucose levels recorded using the statistically significant differences found.
ResultsSignificant differences (P<.05) and dependencies were seen between the glucose profiles classified depending on the independent variables ‘day of the week’ and ‘time slot’. The relationships found were different for each patient, showing the need for individualized studies.
ConclusionsThe results obtained will facilitate mathematical modeling of glucose, and can be used to develop an individualized classifier for each patient that categorizes glucose profiles based on the day of the week and time slot variables. Using this classifier, it will be possible to predict the glucose levels of the patient knowing on which day of the week and in which time slot he/she is, leading to more precise models. Healthcare professionals will also be able to improve patient habits and therapies.
La colección de métodos conocidos como minería de datos ofrece soluciones técnicas y metodológicas para resolver problemas de análisis de datos médicos y creación de modelos de predicción. La minería de datos es el proceso de seleccionar, explorar y modelar grandes cantidades de datos para encontrar y descubrir patrones o relaciones desconocidas que brinden un resultado claro y útil1. Es un campo de la ciencia que se ha desarrollado rápidamente en los últimos años y que ayuda a explicar los datos y a ganar conocimiento sobre ellos2. Los árboles de decisión son una de las técnicas estadísticas de clasificación más potentes utilizadas en minería de datos3-8. Un árbol de decisión es una vía clara y concisa para poder examinar y tomar una decisión acerca de las posibles relaciones entre los datos, identificando grupos o segmentos de interés entre ellos.
La realización del presente trabajo tuvo como objetivo identificar, mediante la construcción de árboles de decisión, perfiles de glucosa clasificados en grupos obtenidos mediante las variables día de la semana (lunes; martes; miércoles; jueves; viernes; sábado; domingo) y franja horaria, definida como la división de los valores de glucosa en tramos de 4h de duración (00:00-04:00h; 04:00-08:00h; 08:00-12:00h; 12:00-16:00h; 16:00-20:00h; 20:00-24:00h).
El resto del artículo está organizado de la siguiente manera. En la siguiente sección se describen los datos utilizados y la técnica empleada para la clasificación de la glucosa. El trabajo experimental y los resultados se muestran en la sección «Resultados». La discusión de los resultados y las conclusiones se exponen en la sección «Discusión».
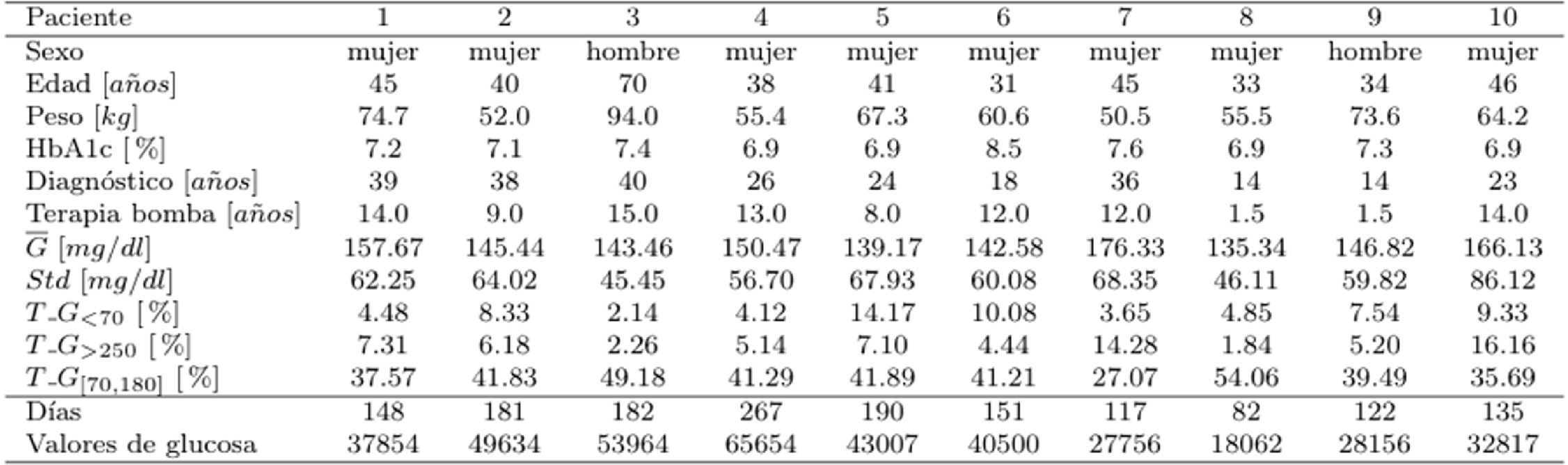
Material y métodosPacientesSe realiza un estudio retrospectivo de 10pacientes con diabetes mellitus tipo1. Se registraron mediciones cada 5min utilizando sensores de monitorización continua de glucosa (MCG) Guardian Real Time y bombas de insulina Minimed, de la compañía Medtronic. Así mismo, se registraron las estimaciones de hidratos de carbono realizadas por los pacientes formados en el proceso de dieta por raciones. Las mediciones se realizaron en días no necesariamente consecutivos ni tampoco los mismos días para cada paciente. Se contemplan únicamente los tramos de 4 horas con al menos 46 valores. La tabla 1 muestra la caracterización de los pacientes con información del sexo, edad, peso, HbA1c medido en los 3meses previos al estudio, y los periodos que llevan con el diagnóstico de la enfermedad y con el tratamiento con la bomba de insulina. Además, para cada paciente se muestran en esa misma tabla la glucosa media, la desviación estándar y los porcentajes de tiempo donde el paciente tiene niveles de glucosa por debajo de 70mg/dl, por encima de 250mg/dl y en el tiempo en rango [70,180] mg/dl.
Métodos estadísticos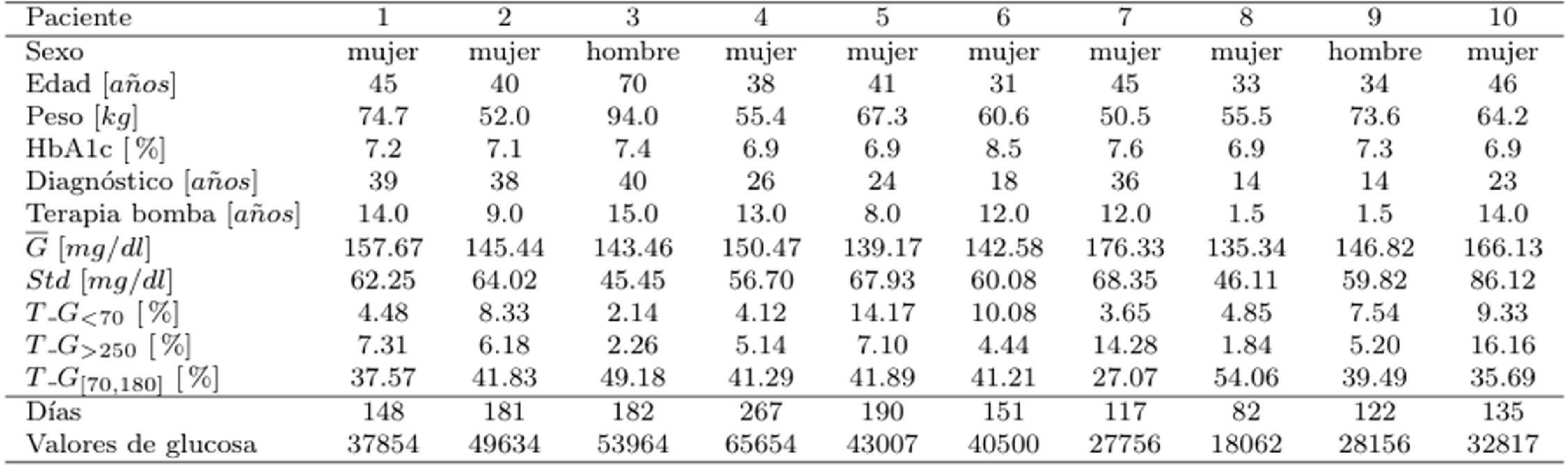
Los árboles de decisión son una técnica de minería de datos que explora los datos para extraer información oculta en ellos. El objetivo de la construcción del árbol de decisión es crear un modelo para predecir el valor de una variable dependiente/objetivo a partir de las variables independientes/predictoras consideradas. El árbol de decisión tiene 3tipos de nodos, a saber, el nodo raíz, los nodos internos y los finales, cada uno representando a una clase caracterizada por los valores estadísticos de la variable objetivo, y las categorías de las variables predictoras que contiene cada nodo. Cada camino en la construcción del árbol de decisión está asociado a una regla de decisión establecida por el propio algoritmo. Así pues, de acuerdo con las reglas establecidas, el conjunto de datos es dividido de forma recursiva en subconjuntos independientes de datos más pequeños (algoritmo divisivo). Uno de los algoritmos más utilizados es el algoritmo de detección automática de interacción chi-cuadrado o CHAID (CHi-square Automatic Interaction Detection)9, empleado en nuestro estudio con el software de análisis predictivo IBM SPSS v.2110. Este algoritmo divide recursivamente los datos mediante una variable respuesta/objetivo usando múltiples divisiones entre las distintas variables de entrada/predictoras. Una división debe alcanzar un nivel umbral de significación entre los valores nominales de la variable objetivo y las ramas, o bien el nodo no se divide. La búsqueda termina cuando no se pueden juntar más ramas o no hay divisiones significativas. La última división se elige como la solución. Hay que tener en cuenta que la última división no tiene por qué ser la división más significativa examinada, es decir, podría existir otra agrupación más significativa diferente de la mostrada en la tabla, aunque esto es una propiedad intrínseca al algoritmo utilizado.
En este estudio se ha utilizado como variable objetivo los niveles de glucosa de cada paciente, como variables predictoras el día de la semana y la franja horaria, y como umbral de significación un nivel de confianza del 95% (α=0,05). Se ha utilizado el estadístico F de Snedecor como criterio de división y el ajuste Bonferroni para el número de valores categóricos de la variable de entrada, mitigando así el sesgo hacia entradas con muchos valores.
ResultadosSe realiza un estudio individualizado para cada paciente. Para la construcción de los árboles de decisión de cada uno de los pacientes se ha seleccionado una profundidad máxima de árbol de 3, un número mínimo de casos en el nodo padre de 100 y en el nodo hijo de 50. La profundidad final del árbol, el número de nodos y el número de nodos finales obtenidos para cada paciente se muestran en la tabla 2. El primer predictor utilizado en la construcción del árbol ha sido el día de la semana y el segundo predictor ha sido franja horaria.

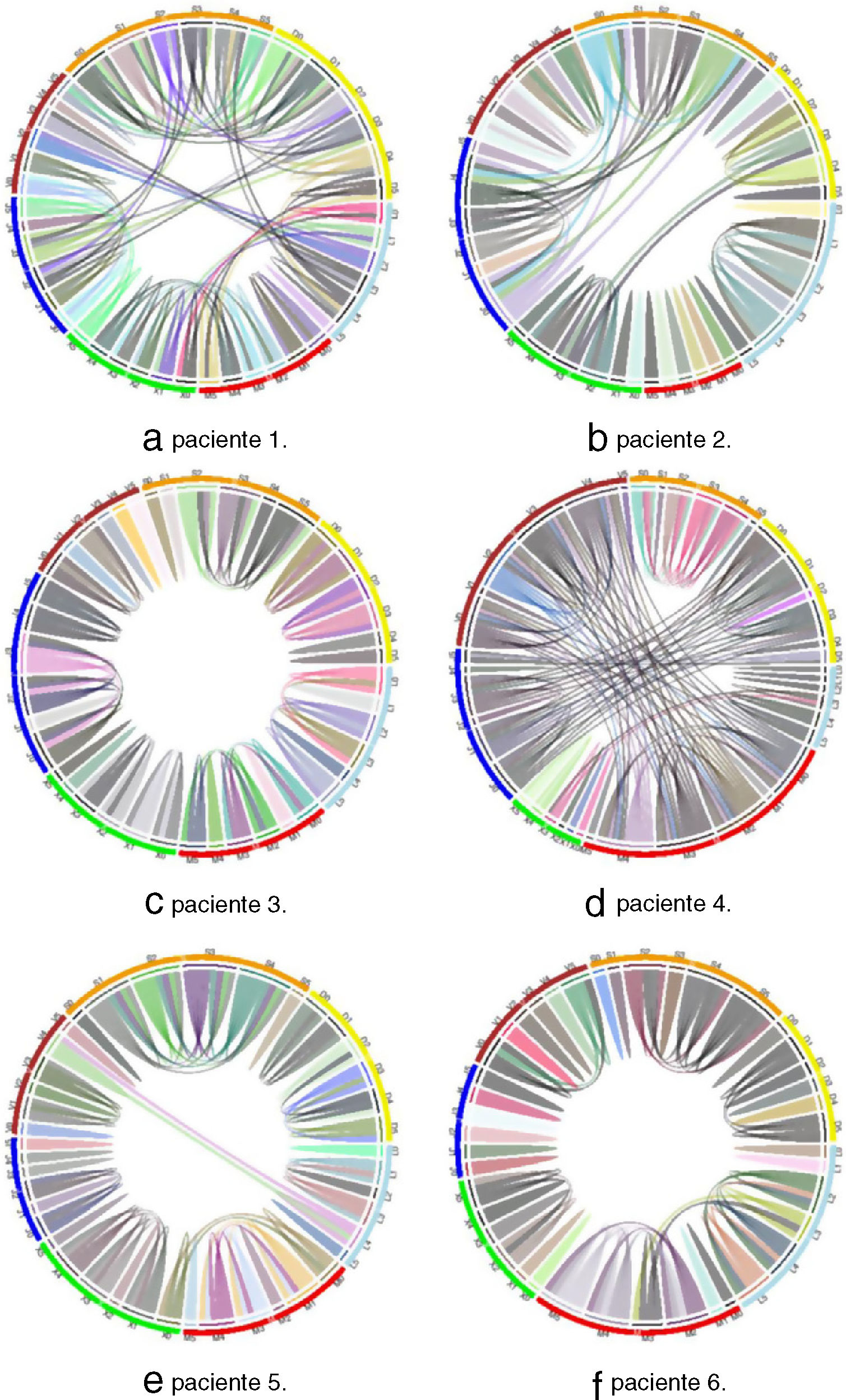
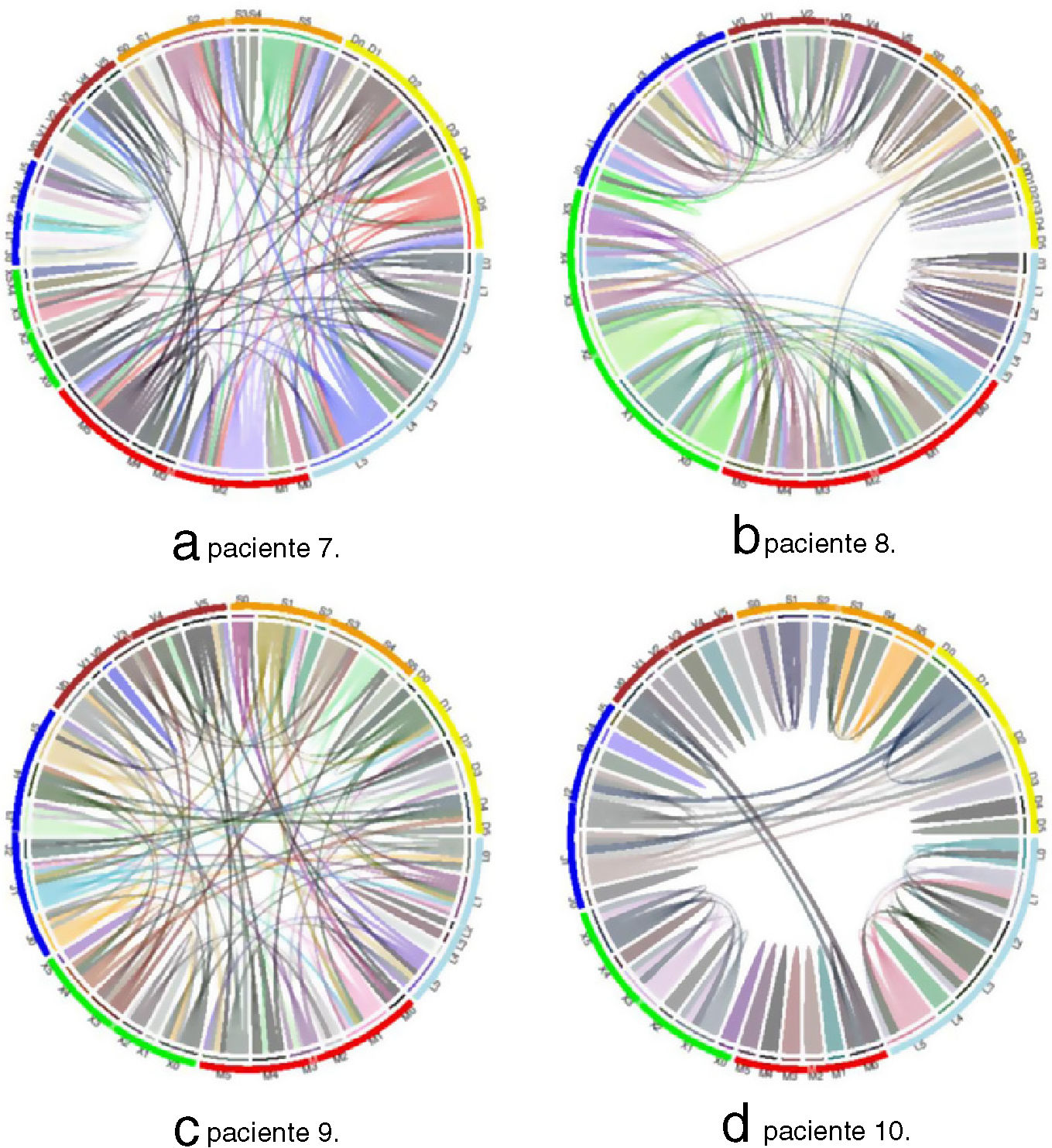
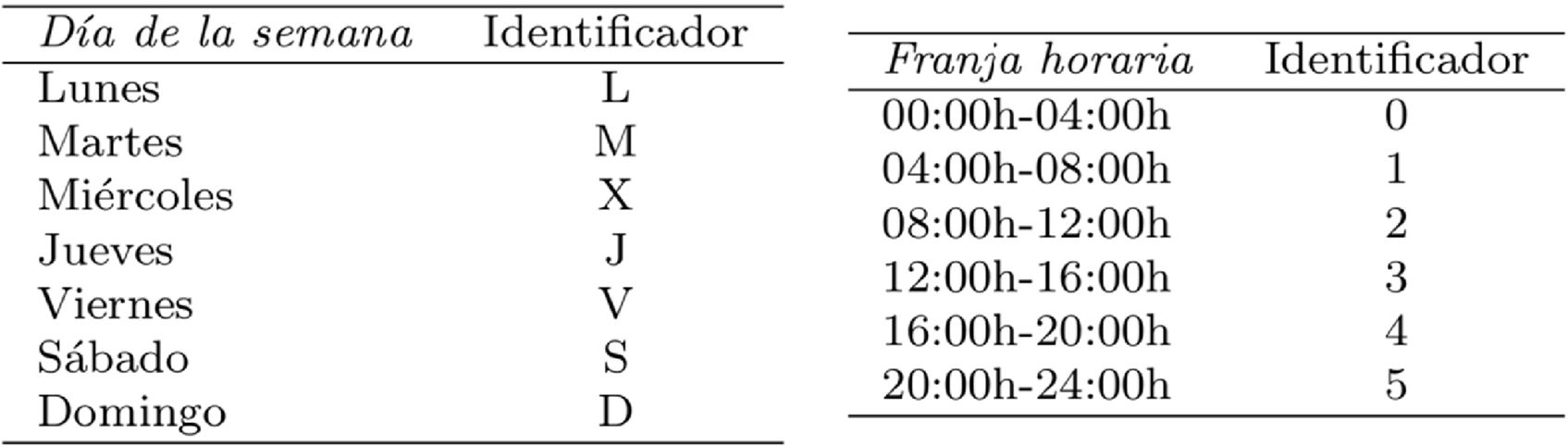
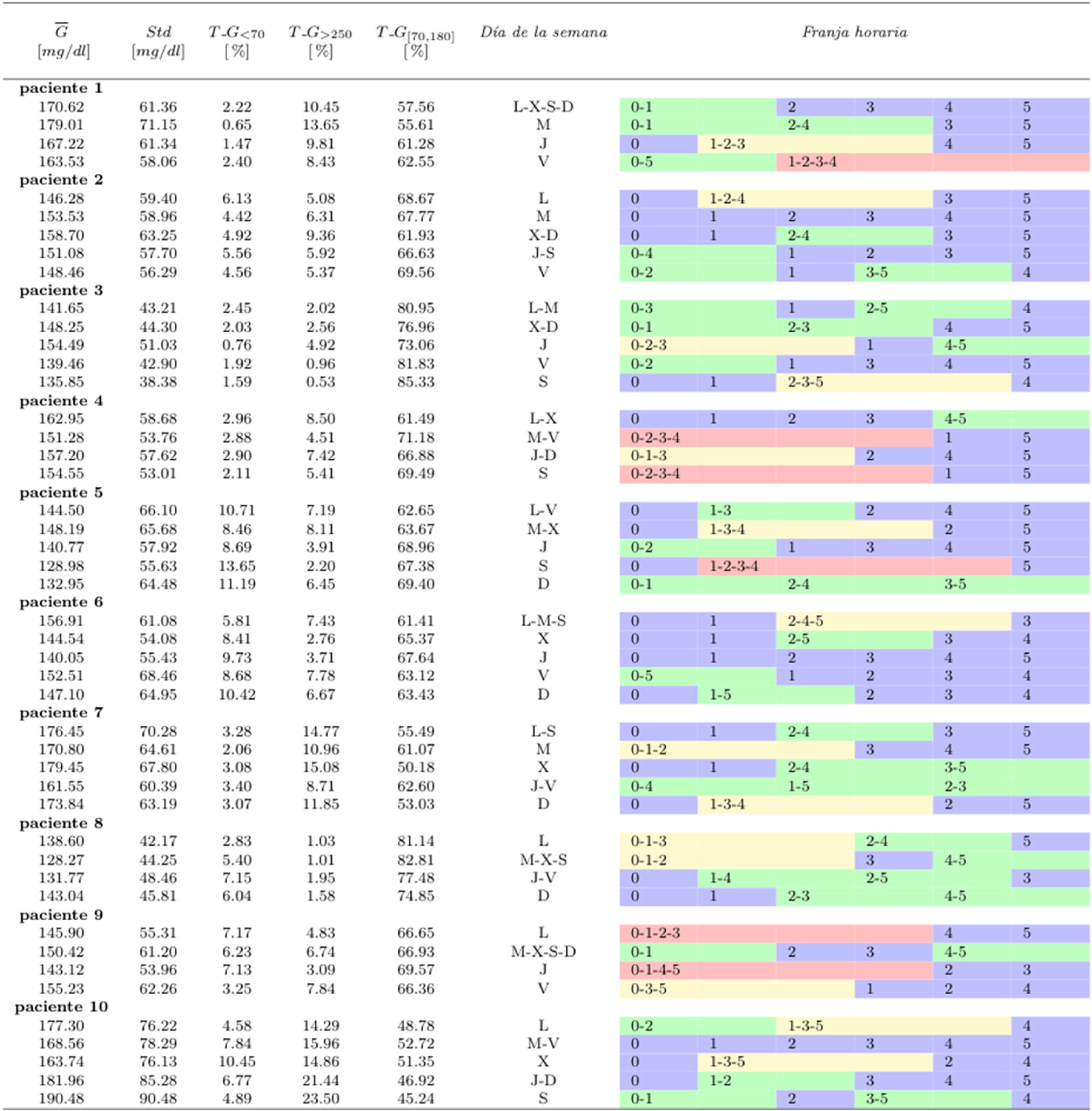
En total tenemos siete categorías para la variable día de la semana y seis categorías para la variable franja horaria. Las categorías de las variables se representan con letras y números, como muestra la tabla 3. La tabla 4 representa los grupos obtenidos para cada paciente. En un primer nivel aparecen los agrupamientos por día. Por ejemplo, podemos ver que en el paciente1 se distinguen cuatro patrones glucémicos diferentes: uno para el martes, otro para el jueves, otro para el viernes y un último patrón para los lunes-miércoles-sábados-domingos, donde el menor valor de glucosa media es para los viernes (163,53±58,06mg/dl) y el mayor es para los martes (179,01±55,61mg/dl). En el segundo nivel aparecen los agrupamientos por franja horaria. El tamaño de los grupos en este nivel está separado por colores, y se puede apreciar que en algunos pacientes existen agrupaciones con una gran cantidad de franjas. En el caso del paciente1, podemos decir que el viernes habitualmente tiene dos comportamientos diferentes, uno para la franja [20:00-04:00h] y otro para el resto del día. El mismo análisis se puede realizar para el resto de los pacientes.
Resultados obtenidos con el algoritmo CHAID para las agrupaciones obtenidas teniendo en cuenta los diferentes días de la semana y las franjas horarias. G es el promedio de glucosa, Std es la desviación estándar, y TG es el porcentaje de tiempo que los valores de glucosa pasan en cada rango (< 70 mg/dl, > 250 mg/dl y [70, 180] mg/dl o tiempo en rango). Los colores en la franja horaria representan el número de elementos que forman un grupo. El color azul se utiliza para representar agrupaciones de 1 elemento, el verde con 2, el amarillo con 3 y el rojo con 4
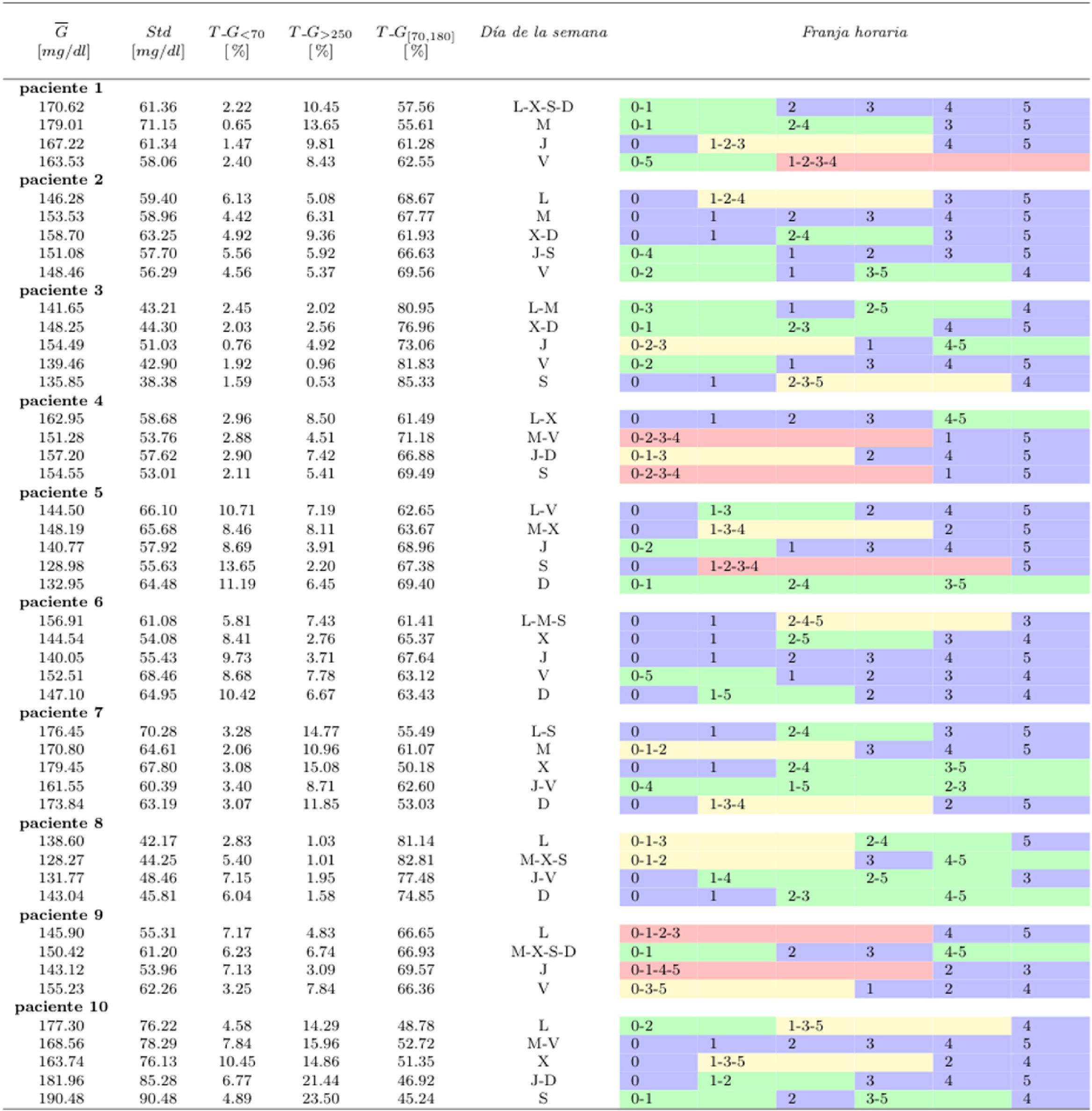
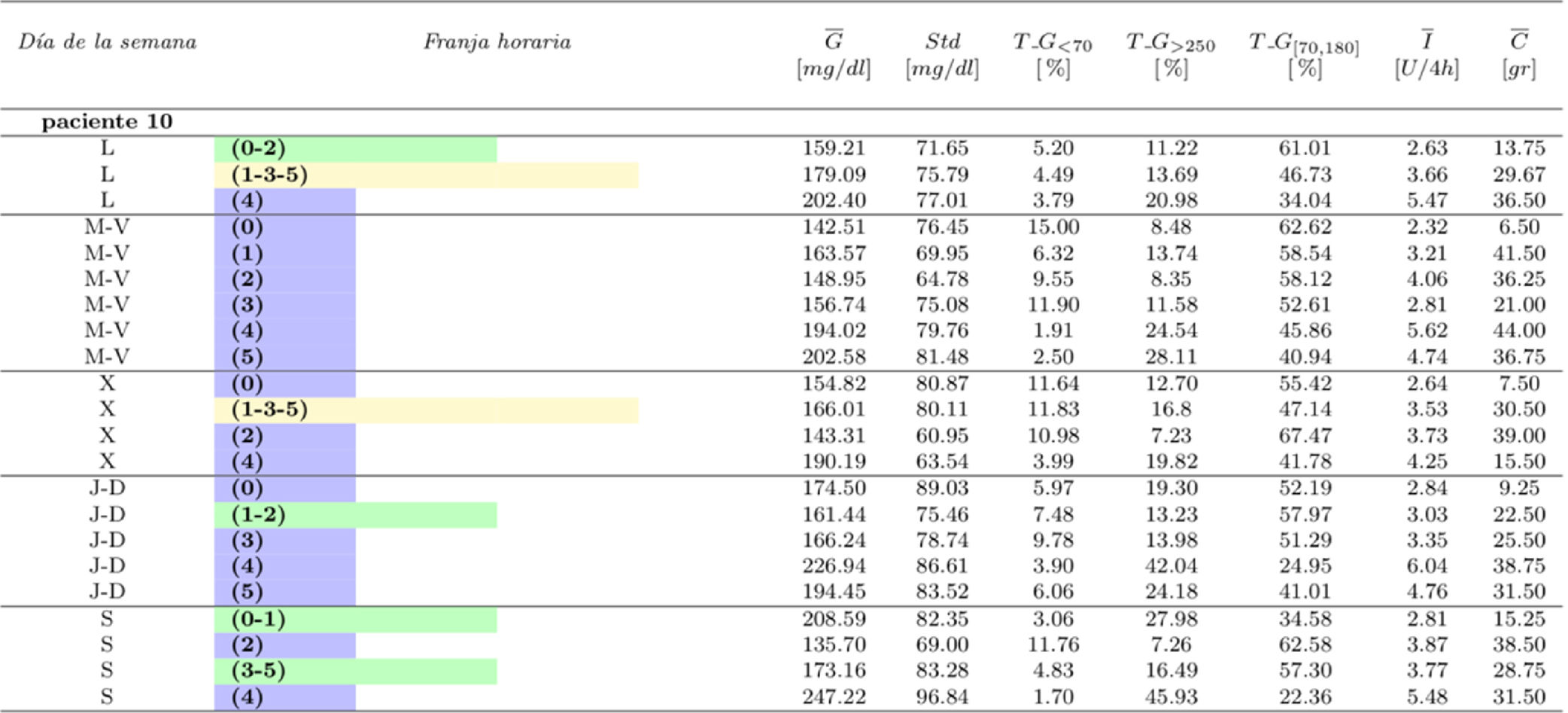
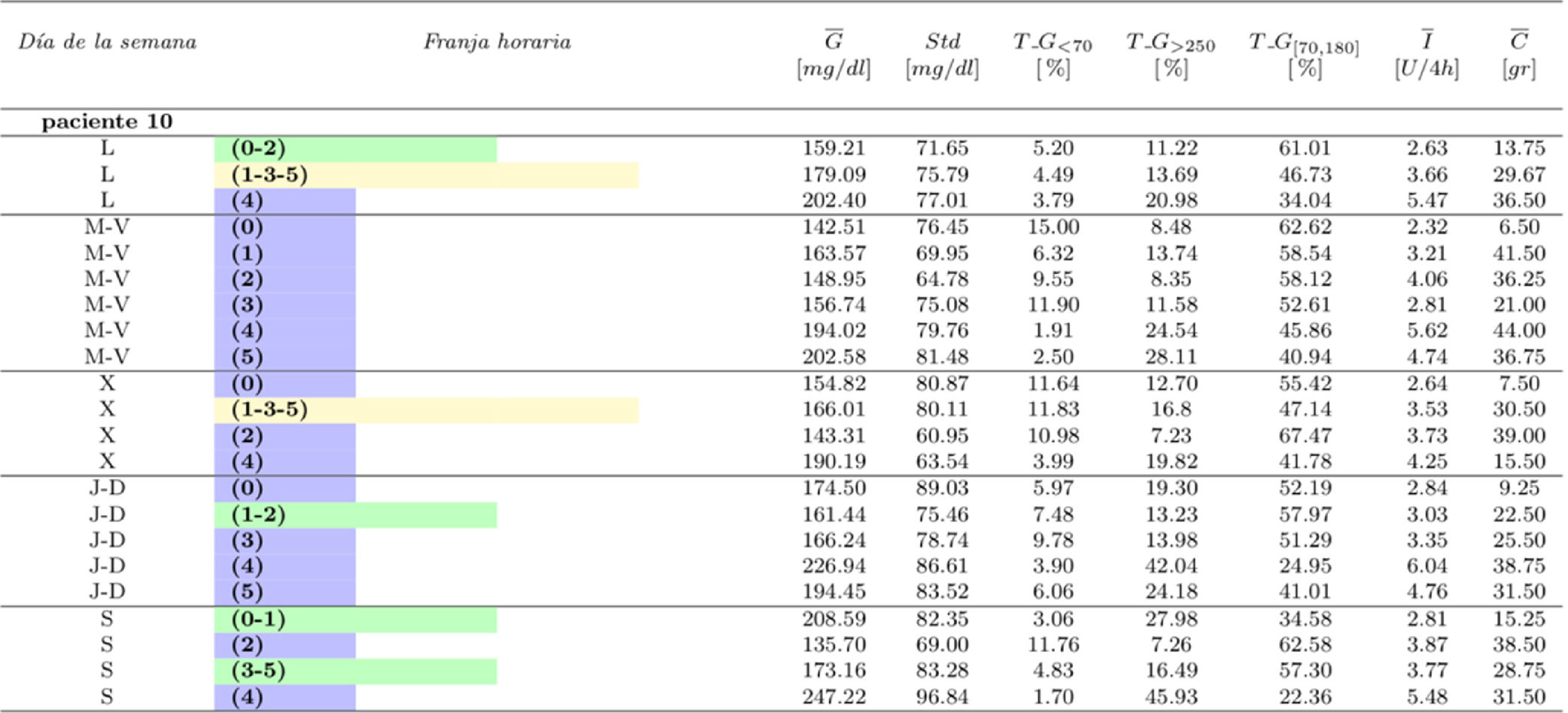
La tabla 5 incluye información de control glucémico sobre los resultados de la tabla 4. Para favorecer la interpretación de resultados se incluye únicamente la información del paciente10. Los datos del resto de los pacientes se incluyen como material adicional.
Resultados obtenidos con el algoritmo CHAID para las agrupaciones obtenidas teniendo en cuenta los diferentes días de la semana y las franjas horarias. G es el promedio de glucosa, Std es la desviación estándar, y TG es el porcentaje de tiempo que los valores de glucosa pasan en cada rango (< 70 mg/dl, > 250 mg/dl y [70, 180] mg/dl o tiempo en rango). Los colores en la franja horaria representan el número de elementos que forman un grupo. El color azul se utiliza para representar agrupaciones de 1 elemento, el verde con 2, el amarillo con 3 y el rojo con 4.
Las relaciones encontradas entre las variables independientes y los valores de glucosa se representan también como gráficos circulares. Los gráficos se han creado utilizando la librería circlize11, con el software libre de análisis estadístico R versión 3.5.212.
Las figuras 1 y 2 representan los gráficos circulares de los resultados de la tabla 4. Para cada paciente se crea un gráfico circular divido en 7 segmentos, uno por cada día, y cada segmento en otros 6, correspondientes a cada franja. Cada segmento tiene una letra y un número que identifica el día y la franja (tabla 3) y las líneas representan las relaciones encontradas entre los días y las franjas.
Discusión

Se han encontrado diferencias significativas en los perfiles de glucosa clasificados por las variables día de la semana y franja horaria en cada uno de los pacientes. La clasificación automática ha encontrado similitudes entre perfiles de glucosa de distintas categorías, entendiendo por categoría todos los perfiles correspondientes a una misma franja horaria de un mismo día de la semana (p.ej., los lunes de 00:00 a 04:00h). Un perfil de glucosa está formado por los valores de glucosa medidos en esa franja horaria.
Las agrupaciones obtenidas con la variable día de la semana son heterogéneas, es decir, están formadas por una, dos, tres y hasta cuatro categorías. Lo mismo sucede para las agrupaciones con respecto a la variable franja horaria. El tamaño de las agrupaciones que más se ha repetido para la variable día de la semana es dos categorías (en todos los pacientes) y la que menos tres categorías (pacientes 6 y 7) y cuatro (pacientes 1 y 9). Por lo que respecta a la variable franja horaria el resultado es similar, aunque se han encontrado un mayor número de similitudes entre perfiles, es decir, más agrupaciones que para la variable día de la semana, y para un mayor número de los pacientes analizados.
Del análisis de las tablas 4 y 5 de manera conjunta se pueden obtener conclusiones de aplicabilidad clínica. En el caso del paciente 10 se puede observar que los sábados está más hiperglucémico que otros días (tabla 4), y con la información de la tabla 5 para el sábado se pueden tomar medidas para reducir este comportamiento, como modificar su pauta de insulina o su dieta.
Si analizamos los gráficos circulares de las figuras 1 y 2 se observa que para los pacientes 3 y 6 los centros de los gráficos están libres de líneas. Esto es debido a que las agrupaciones en estos pacientes están formadas por pocos elementos, habiendo diferencias entre los perfiles de glucosa obtenidos, tanto para los días como para las franjas. En los pacientes 4 y 9 sucede lo contrario. Las agrupaciones están formadas por varios elementos y los centros de los gráficos están ocupados con muchas líneas. En este caso, los perfiles de glucosa obtenidos son parecidos, existiendo un mayor control glucémico en estos pacientes (mayor tiempo en rango).
No obstante, hay gráficos (pacientes 3, 5 y 6) con pocas conexiones debido a que el algoritmo detecta pequeñas diferencias entre los valores de glucosa para los diferentes días que previamente agrupó en un solo conjunto y por ello no aparecen líneas en los gráficos. Es decir, el algoritmo realiza una clasificación con mayor profundidad del árbol (tabla 2). Por ejemplo, en el paciente 3 hay un primer nivel que agrupa los lunes y martes, y después agrupa en un segundo nivel las franjas 0-3, 2-5, 1 y 4. Si el gráfico se realizara con respecto a este segundo nivel, se observaría un mayor número de conexiones entre categorías. Por lo tanto, es necesario establecer previamente a la aplicación del algoritmo el número de niveles.
ConclusionesLas conclusiones obtenidas de este trabajo son:
- •
Se han observado diferencias significativas y dependencias entre los perfiles de glucosa clasificados en función de las variables día de la semana y franja horaria.
- •
Las agrupaciones encontradas han sido diferentes para cada paciente, demostrando la necesidad de hacer un estudio individualizado.
- •
Las tablas 4 y 5 permiten buscar diferencias significativas para corregir y mejorar hábitos o terapias en los pacientes, y obtener modelos más precisos mediante técnicas de aprendizaje automático e inteligencia artificial.
- •
Los resultados obtenidos indican que las técnicas aplicadas pueden facilitar la modelización matemática de la glucosa, y podrán utilizarse para la creación de un clasificador individualizado para cada paciente que clasifique los perfiles de glucosa en función de las variables día de la semana y franja horaria. Utilizando este clasificador, se podrán predecir los valores de glucosa del paciente conociendo en qué día se encuentra y en qué franja horaria, obteniendo modelos más precisos.
Este trabajo ha sido parcialmente financiado por:
Ayudas de la Fundación Eugenio Rodríguez Pascual 2019: Desarrollo de sistemas adaptativos y bioinspirados para el control glucémico con infusores subcutáneos continuos de insulina y monitores continuos de glucosa.
El proyecto B2017/BMD3773 (GenObIA-CM) y Y2018/NMT-4668 (Micro-Stres - MAP-CM), financiado por la Comunidad de Madrid y cofinanciado con los Fondos Estructurales de la UE.
El proyecto Y2018/NMT-4668 (Micro-Stres - MAP-CM), financiado por la Comunidad de Madrid y cofinanciado con los Fondos Estructurales de la UE.
La subvención del Ministerio de Economía y Competitividad española RTI2018-095180-B-I00.
AutoríaMarta Botella, José Ignacio Hidalgo y Oscar Garnica han diseñado el estudio y han participado en la redacción y la revisión del artículo.
Sergio Contador Pachón ha programado el procesado de los datos y las técnicas de clusterización y ha participado en la redacción del artículo.
Jose Manuel Velasco ha realizado las gráficas de clusterización y ha participado en la redacción del artículo.
Esther Maqueda ha participado en la revisión del artículo.
Aranzazu Aramendi y Remedios Martínez han realizado la toma de datos y la formación de los pacientes.
Conflicto de interesesLos autores declaran no tener ningún conflicto de intereses.
Agradecimientos: Almudena Sánchez Sánchez participó en las discusiones y en el origen del trabajo.
