





A lo largo de su historia, la ciencia ha sufrido una enorme transformación, pasando de una fase caracterizada por aportaciones individuales de autores singulares, como Euclides (300 a.C.), Galileo (1564–1642), Isaac Newton (1643–1727), Charles Darwin (1809–1882) o Albert Einstein (1879–1955), a otra definida por la actividad colectiva a pequeña y gran escala —tómense los proyectos «Genoma humano» o el sincrotrón como ejemplos recientes—. Este espectacular cambio se produjo a caballo entre las guerras mundiales y se conoce como «from little science to big science»1. Si bien los premios Nobel2 dan continuidad a la idea de individualidad premiando a investigadores concretos, en la actualidad la ciencia es una actividad predominantemente colectiva3.
Una de las consecuencias del paso a la big science ha sido el crecimiento a escala mundial de la comunidad científica, y con éste la aparición de lo que en bibliometría se conoce como homónimos, es decir, distintos autores que publican usando la misma firma bibliográfica. Ya en 1974 E. Garfield4, creador del Institute for Scientifc Information (ISI), se refería al problema que supone identificar autores que usan la misma firma, sobre todo si trabajan en el mismo centro o, peor aún, si se dedican a la misma disciplina científica. Posteriormente, y desde su perspectiva de compilador de bases de datos, ese autor describe monográficamente las diferencias entre las prácticas de firma de autores de los cinco continentes, puntualizando que éstas pueden además cambiar si el autor publica dentro o fuera de su país de origen5. Según Garfield, a esto se suman otros factores como la falta de regularidad en la firma, tanto por parte del propio autor como por la del citante, y la presencia de artículos y preposiciones en las firmas. Con todo, admite que en muchas ocasiones no es posible distinguir el nombre del apellido de un autor, lo cual se ve agravado por la creciente presencia de variantes de las firmas de los autores, lo que se conoce como sinónimos. Como se puede ver, los homónimos y sinónimos son el principal obstáculo para identificar a un autor a través de sus publicaciones y, lo que es peor, no se trata de un fenómeno específico de un país en particular, sino de un fenómeno mundial.
¿Pero en qué situaciones es necesario evaluar de forma individual el rendimiento de un investigador? En general se podrían describir tres: en convocatorias competitivas donde la solvencia científica del investigador principal tiene un gran peso; en la creación de paneles de expertos, y en la promoción dentro de la institución. Estas situaciones, esenciales en la carrera de todo investigador, dependen del rigor de la evaluación, la cual a su vez depende del grado de complejidad que encierre establecer una correspondencia entre las firmas bibliográficas y el autor en cuestión. Una incorrecta evaluación, ya sea por inclusión u omisión de publicaciones, por lo general va en detrimento del autor objeto de la evaluación.
¿Cómo puede facilitarse la evaluación individual? Teniendo en cuenta las fuentes de información es posible actuar en tres frentes. Si entramos en un proceso de evaluación y se nos requieren las publicaciones, nuestro currículum vitae (CV) es la primera opción. Entre sus ventajas se cuentan su exhaustividad y el hecho de que es posible presentarlo en diferentes formatos: ordenando las publicaciones más recientes primero, y diferenciando los artículos y revisiones indizados del resto de los documentos, por ejemplo. La principal limitación del CV es que no tiene un vínculo con las bases de datos capaces de proveer el número de citas recibidas, y/o algún indicador de la revista de publicación. Establecer dicho vínculo para cada publicación es poco factible. Así pues, la utilidad del CV en evaluaciones es limitada. Con el objetivo de superar esta limitación, la Fundación Española para la Ciencia y la Tecnología (FECYT) está desarrollando el CV Normalizado (CVN)6, una aplicación con acceso web que, entre otras características, permitirá enlazar las publicaciones registradas por los autores con las bases de datos bibliográficas, de forma que se puedan elaborar indicadores bibliométricos que complementen su evaluación. Si bien el CVN supone un gran avance, la información bibliográfica continuará proviniendo de las grandes bases de datos generalistas, lo que nos lleva al siguiente frente de acción. Supongamos que un organismo decide crear un panel de expertos y, por lo tanto, a priori no sabe qué personas lo compondrán. Una de las opciones será realizar una búsqueda temática en una o varias bases de datos para recopilar las publicaciones pertinentes y, a partir de éstas, identificar a los autores más activos y/o más visibles. En este caso los potenciales integrantes del panel desconocen el proceso de evaluación, por lo que no podrán intervenir aportando sus publicaciones, y su inclusión o no dependerá únicamente del rigor en el proceso de selección y la experiencia de los seleccionadores. En vista de que al final siempre se recurre a las bases de datos generalistas, la opción más razonable es evitar la utilización de homónimos y minimizar la probabilidad de que se generen sinónimos de nuestra firma, de forma que sea más fácil identificarnos a través de las publicaciones.
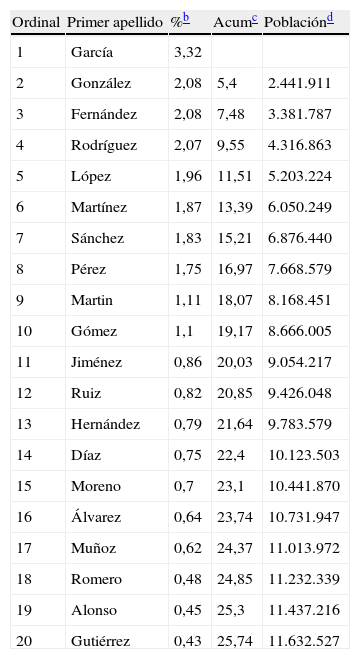
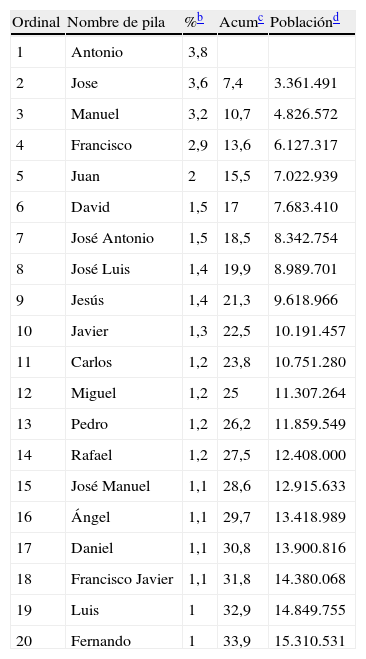
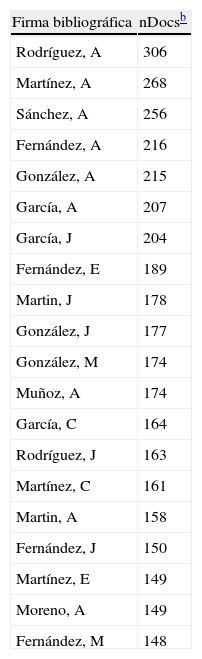
Para evitar utilizar firmas homónimas tan sólo basta con buscar la firma en cuestión en PubMed7, Web of Science (WOS)8, Google Scholar9 o SCOPUS10, y podremos evaluar su singularidad. La probabilidad de ser objeto de una evaluación incorrecta aumenta drásticamente cuanto mayor es el número de autores que comparten una firma. Este número se puede aproximar por diferencias en el centro de filiación, la disciplina (revistas de publicación) o porque publican con distintos subgrupos de coautores11. El número de homónimos depende de la distribución de apellidos en el país de que se trate12. Según datos del INE13, una cuarta parte de la población española, unos 11,5 millones de personas en números redondos, comparten tan sólo 20 apellidos, de los cuales García y González son los más frecuentes (tabla 1). Si reproducimos este análisis con los 20 nombres de pila más frecuentes, el resultado es que una tercera parte de la población, unos 15 millones de habitantes, comparten tan sólo 20 nombres distintos, que además se pueden resumir en 13 iniciales, lo que indica que a cada uno de estos nombres corresponde más de 1 millón de personas, el doble que la proporción de habitantes por apellido (tabla 2). Si extrapolamos estos resultados a la comunidad científica española, los nombres de cuyos integrantes están inevitablemente afectados por lo expuesto anteriormente, se puede ver que la estrategia de elegir una firma bibliográfica construida únicamente a partir del primer apellido y la inicial del nombre de pila resulta, a todas vistas, inapropiada para identificar, ni siquiera con las mínimas garantías, a un determinado autor. Los artículos y resúmenes publicados desde España durante 2006–2008 disponibles en la WOS así lo confirman. Por un lado, las firmas de los 20 autores más productivos tienen el formato de primer apellido e inicial del nombre, pudiéndose resumir el listado en tan sólo 9 apellidos y 5 iniciales distintas; por el otro, el elevado número de documentos, 306 para la primera firma de la lista, es un claro indicio de que estamos frente a un homónimo; en caso contrario estaríamos hablando de un autor que es capaz de publicar en promedio 100 documentos al año o un documento cada 3 días (tabla 3). En resumen, para evitar utilizar una firma homónima, tan sólo es necesario hacer una búsqueda bibliográfica en una base de datos de cobertura mundial y comprobar que no exista. En caso de que por cualquier situación la creatividad esté bajo mínimos, invito al lector a visitar la página de IRALIS14, en la que se pueden obtener algunas sugerencias de firmas bibliográficas.
Distribución de la población según primer apellido, 2007a
| Ordinal | Primer apellido | %b | Acumc | Poblaciónd |
| 1 | García | 3,32 | ||
| 2 | González | 2,08 | 5,4 | 2.441.911 |
| 3 | Fernández | 2,08 | 7,48 | 3.381.787 |
| 4 | Rodríguez | 2,07 | 9,55 | 4.316.863 |
| 5 | López | 1,96 | 11,51 | 5.203.224 |
| 6 | Martínez | 1,87 | 13,39 | 6.050.249 |
| 7 | Sánchez | 1,83 | 15,21 | 6.876.440 |
| 8 | Pérez | 1,75 | 16,97 | 7.668.579 |
| 9 | Martin | 1,11 | 18,07 | 8.168.451 |
| 10 | Gómez | 1,1 | 19,17 | 8.666.005 |
| 11 | Jiménez | 0,86 | 20,03 | 9.054.217 |
| 12 | Ruiz | 0,82 | 20,85 | 9.426.048 |
| 13 | Hernández | 0,79 | 21,64 | 9.783.579 |
| 14 | Díaz | 0,75 | 22,4 | 10.123.503 |
| 15 | Moreno | 0,7 | 23,1 | 10.441.870 |
| 16 | Álvarez | 0,64 | 23,74 | 10.731.947 |
| 17 | Muñoz | 0,62 | 24,37 | 11.013.972 |
| 18 | Romero | 0,48 | 24,85 | 11.232.339 |
| 19 | Alonso | 0,45 | 25,3 | 11.437.216 |
| 20 | Gutiérrez | 0,43 | 25,74 | 11.632.527 |
Distribución de la población según nombre de pila, 2007a
| Ordinal | Nombre de pila | %b | Acumc | Poblaciónd |
| 1 | Antonio | 3,8 | ||
| 2 | Jose | 3,6 | 7,4 | 3.361.491 |
| 3 | Manuel | 3,2 | 10,7 | 4.826.572 |
| 4 | Francisco | 2,9 | 13,6 | 6.127.317 |
| 5 | Juan | 2 | 15,5 | 7.022.939 |
| 6 | David | 1,5 | 17 | 7.683.410 |
| 7 | José Antonio | 1,5 | 18,5 | 8.342.754 |
| 8 | José Luis | 1,4 | 19,9 | 8.989.701 |
| 9 | Jesús | 1,4 | 21,3 | 9.618.966 |
| 10 | Javier | 1,3 | 22,5 | 10.191.457 |
| 11 | Carlos | 1,2 | 23,8 | 10.751.280 |
| 12 | Miguel | 1,2 | 25 | 11.307.264 |
| 13 | Pedro | 1,2 | 26,2 | 11.859.549 |
| 14 | Rafael | 1,2 | 27,5 | 12.408.000 |
| 15 | José Manuel | 1,1 | 28,6 | 12.915.633 |
| 16 | Ángel | 1,1 | 29,7 | 13.418.989 |
| 17 | Daniel | 1,1 | 30,8 | 13.900.816 |
| 18 | Francisco Javier | 1,1 | 31,8 | 14.380.068 |
| 19 | Luis | 1 | 32,9 | 14.849.755 |
| 20 | Fernando | 1 | 33,9 | 15.310.531 |
Autores más productivos en el periodo 2006–2008a
| Firma bibliográfica | nDocsb |
| Rodríguez, A | 306 |
| Martínez, A | 268 |
| Sánchez, A | 256 |
| Fernández, A | 216 |
| González, A | 215 |
| García, A | 207 |
| García, J | 204 |
| Fernández, E | 189 |
| Martin, J | 178 |
| González, J | 177 |
| González, M | 174 |
| Muñoz, A | 174 |
| García, C | 164 |
| Rodríguez, J | 163 |
| Martínez, C | 161 |
| Martin, A | 158 |
| Fernández, J | 150 |
| Martínez, E | 149 |
| Moreno, A | 149 |
| Fernández, M | 148 |
El tratamiento de las variantes o firmas sinónimas es más complejo, por lo que empezaremos por revisar qué y dónde se generan. El primer y principal agente generador de sinónimos es el propio autor. La solución en este caso pasa por elegir una firma, lo más singular posible, y mantenerla a lo largo de toda la carrera científica. También es cierto que en algunos casos, como por ejemplo en las estancias cortas, nuestros colegas nos incluyen entre los autores de publicaciones posteriores a nuestra estancia, a veces sin ni siquiera informarnos, de forma que no podemos controlar que nuestra firma aparezca correctamente. Otra fuente nada despreciable de variantes son los compiladores de bases de datos bibliográficas. Por un lado, las hoy anecdóticas «mutaciones» de letras causadas por errores en el reconocimiento automático de texto, gracias a la transmisión electrónica de datos, y por otro, y más importante, la aplicación por igual del patrón de firma anglosajón —apellido e inicial del nombre de pila— que crea artefactos difíciles de reconocer, incluso para el propio autor. Son especialmente sensibles a esta manipulación las firmas que incluyen nombres de pila compuestos, artículos y/o preposiciones o simplemente los dos apellidos. A este respecto, en 2006 un grupo de bibliómetras de España consensuó un documento de recomendaciones dirigidas a minimizar y contrarrestar el efecto de la aplicación del mencionado patrón de firma anglosajón15. En general se recomienda utilizar guiones para unir las diferentes partículas que forman la firma. Así, por ejemplo, las firmas que incluyan artículos y preposiciones adoptarían un aspecto similar a éstas: de-los-Cobos, A; del-Río, J; aquellas que incluyeran dos o más apellidos quedarían como: González-García, J; Morales-Suárez-Varela, A; etc. Asimismo, en mi experiencia16–18, he podido observar que los nombres compuestos pueden ser otra fuente de variantes. A diferencia de lo que ocurre habitualmente con nombres como María del Carmen, que coloquialmente pueden ser utilizados indistintamente como Maricarmen o simplemente Carmen, es altamente recomendable no reproducir estas variantes en la firma bibliográfica. Los cambios de idioma pueden igualmente dar pie a la creación de variantes muy difíciles de identificar, piénsese en la metamorfosis que supone el paso de la letra J a X en nombres como Javier o José en su paso a catalán o gallego respectivamente, o la de la letra C a K en el caso de Carlos a euskera. En definitiva, los autores y las manipulaciones de los compiladores de bases de datos son las principales fuentes de variantes de firmas o sinónimos.
Bien, ya conocemos la enfermedad y además tenemos elementos para conjurar un remedio, ¿pero qué pasa con las publicaciones que ya están recopiladas en las bases de datos o registro histórico? Ni Thomson-ISI ni SCOPUS, únicos proveedores generalistas de bases de datos bibliográficas, normalizan de forma sistemática la información referente a centros o firmas contenidas en las publicaciones, si bien han lanzado herramientas como Research ID19 o Author Identifier20 con el objetivo de paliar el déficit de información normalizada en cuanto a la producción de autores individuales. Precisamente, el gran problema de la evaluación bibliométrica individual tiene su raíz en la ausencia de correspondencia entre firmas bibliográficas y autores. En la actualidad dicha correspondencia se obtiene con garantías suficientes únicamente a través de procesos manuales y, en el mejor de los casos, semiautomáticos21 aunque, por lo general y debido su complejidad, estos procesos suelen afectar a reducidos volúmenes de datos. Determinar las correspondencias entre firmas y autores del registro histórico pasaría por disponer de un sistema diseñado con objetivos evaluativos, como por ejemplo el CVN6, que estando en conexión con bases de datos bibliográficas nos permitiera registrar nuestras publicaciones bajo un único e inequívoco identificador y, además, permitiera elaborar diferentes indicadores. Sería igualmente deseable que este sistema recopilara por mecanismos automáticos las nuevas publicaciones y, previa validación por nuestra parte, actualizara nuestro registro personal. Y así sucesivamente… En la actualidad las tecnologías de la información hacen posibles herramientas similares, por lo que ésta es la parte fácil. El verdadero reto es conseguir la aceptación y el uso generalizado y asiduo de una herramienta de estas características por la comunidad científica.
A falta de un sistema de registro y evaluación de amplia aceptación, invito al lector a que incluya en su CV, bajo un epígrafe que podría ser «Ayuda o guía para la evaluación», su particular colección de sinónimos y coautores más duraderos buscando sus publicaciones en PubMed, WOS o SCOPUS. Además de constatar lo difícil que resulta identificar incluso las propias publicaciones en estas bases de datos y descubrir las variantes de firmas creadas por sus compiladores, contribuirá a que sus evaluaciones sean más justas.
En definitiva, las evaluaciones individuales con frecuencia son determinantes en la carrera de todo investigador, aunque la existencia de homónimos y sinónimos puede reducir su validez, ya que falsean la correspondencia entre firmas y autores. Frente a esta situación, y mientras no dispongamos de un sistema de registro y evaluación de amplia aceptación, es imperativo elegir una firma lo más singular posible y mantenerla a lo largo de nuestra carrera profesional.
