




El objetivo del presente trabajo es analizar cómo se distribuye la capacidad tecnológica entre las entidades federativas de México y examinar su evolución. Para ello, se desarrolló un estudio empírico utilizando la técnica de análisis estadístico multivariante de cluster, con base en el set de indicadores propuesto por Cepal (2007) y recopilando los datos de diversas fuentes públicas del país para los años 2006 y 2012, con el fin de estudiar la evolución en el tiempo de dichos clusters, tratando de ver qué estados han podido mudarse a un cluster situado en posiciones más avanzadas y cuáles han retrocedido en dicho periodo. Los resultados muestran la existencia de 7 grupos de estados caracterizados por distintos niveles de capacidad tecnológica, y se detectan también 3 entidades que evolucionaron a un cluster más avanzado, tanto en lo referente a la capacidad de absorción e innovación, como en lo relativo a las capacidades tecnológicas de infraestructura.
This paper conducts an analysis on the existence of state clusters related with technological capabilities in Mexico. An empirical study was conducted using the technique of multivariate statistical cluster analysis, based on the set of indicators proposed by Cepal (2007), collecting data from various public sources country for 2006 and 2012 in order to study the time evolution of such clusters, trying to see what states have been moving to a cluster located in positions more which have advanced and retreated over the period. The results show the existence of 7 groups of states characterized by different technological capabilities, plus states are identified in decline and progress, both in terms of absorptive capacity and innovation, and in relation to the technological infrastructure capabilities.
La ciencia, la tecnología y la innovación son los principales conductores del desarrollo económico sustentable (Stern, Porter y Furman, 2000; Schumpeter, 2005; Brunner, 2011; Dosi, 2008; Diaconu, 2011). Esto justifica la realización de estudios tanto nacionales como internacionales enfocados a medir las capacidades tecnológicas a nivel macro. Los estudios a nivel estatal no son tan numerosos. En México, el Foro Consultivo Científico y Tecnológico (FCCyT) se da a la tarea de presentar el estado de la Ciencia, Tecnología e Innovación (CTI) a nivel estatal-nacional. Sin embargo, tal como señala FCCyT (2014, p. 16), los estudios desarrollados en materia de medición de la CTI a nivel estatal «son incipientes y se requiere de análisis más amplios, complementarios o particulares».
Además, el concepto del sistema nacional de innovación es proclive a analizar las capacidades tecnológicas de diferentes entidades, ya que esto ayuda a entender de mejor manera sus transformaciones socioeconómicas (Dutrénit, Capdeville, Corona, Puchet y Vera-cruz, 2010). Se denota que la competitividad (internacional, nacional, estatal, industrial y empresarial) se construye. Es pues una ventaja adquirida y depende, esencialmente, de la amplitud y de la profundidad de las capacidades tecnológicas nacionales (Borrastero, 2012; Guzmán, 2008; Morales, 2009; Calderón y Hartmann, 2010; Close y Garita, 2011). En ese sentido, «las capacidades tecnológicas que impulsan la innovación han sido siempre un componente fundamental de la competitividad, el crecimiento y bienestar económico de los países» (Velarde, Garza y Coronado, 2011, p. 17).
El objetivo del presente trabajo es analizar cómo se distribuye la capacidad tecnológica entre las entidades federativas de México y examinar su evolución. Para ello, siguiendo a Blázquez y García (2009), se considera necesario realizar un análisis empírico que explore la existencia de diferentes grupos de estados (clusters) caracterizados por distintos niveles de capacidad tecnológica, de absorción y de innovación, evaluando la evolución de dichas capacidades entre los grupos de estados, para detectar aquellos que han logrado migrar a un cluster mejor posicionado y aquellos que han retrocedido en dicha materia. El estudio se ha realizado utilizando los datos de los años 2006 y 2012, publicados en diversas fuentes (tabla 1), los cuales contienen una serie de indicadores que tratan de cuantificar diferentes aspectos relacionados con la capacidad tecnológica.
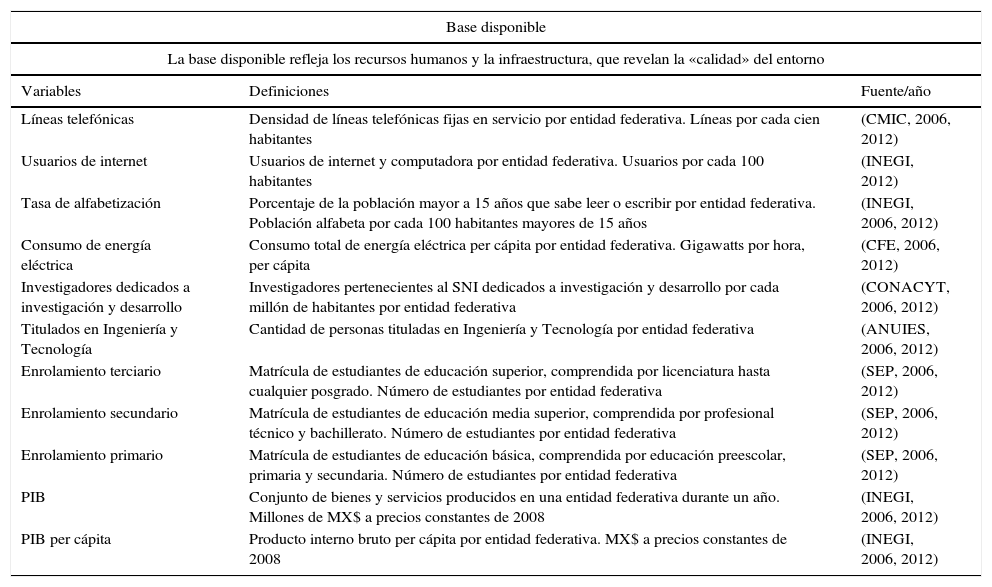
Indicadores usados en el análisis empírico por estados para el año 2006 y 2012
| Base disponible | ||
|---|---|---|
| La base disponible refleja los recursos humanos y la infraestructura, que revelan la «calidad» del entorno | ||
| Variables | Definiciones | Fuente/año |
| Líneas telefónicas | Densidad de líneas telefónicas fijas en servicio por entidad federativa. Líneas por cada cien habitantes | (CMIC, 2006, 2012) |
| Usuarios de internet | Usuarios de internet y computadora por entidad federativa. Usuarios por cada 100 habitantes | (INEGI, 2012) |
| Tasa de alfabetización | Porcentaje de la población mayor a 15 años que sabe leer o escribir por entidad federativa. Población alfabeta por cada 100 habitantes mayores de 15 años | (INEGI, 2006, 2012) |
| Consumo de energía eléctrica | Consumo total de energía eléctrica per cápita por entidad federativa. Gigawatts por hora, per cápita | (CFE, 2006, 2012) |
| Investigadores dedicados a investigación y desarrollo | Investigadores pertenecientes al SNI dedicados a investigación y desarrollo por cada millón de habitantes por entidad federativa | (CONACYT, 2006, 2012) |
| Titulados en Ingeniería y Tecnología | Cantidad de personas tituladas en Ingeniería y Tecnología por entidad federativa | (ANUIES, 2006, 2012) |
| Enrolamiento terciario | Matrícula de estudiantes de educación superior, comprendida por licenciatura hasta cualquier posgrado. Número de estudiantes por entidad federativa | (SEP, 2006, 2012) |
| Enrolamiento secundario | Matrícula de estudiantes de educación media superior, comprendida por profesional técnico y bachillerato. Número de estudiantes por entidad federativa | (SEP, 2006, 2012) |
| Enrolamiento primario | Matrícula de estudiantes de educación básica, comprendida por educación preescolar, primaria y secundaria. Número de estudiantes por entidad federativa | (SEP, 2006, 2012) |
| PIB | Conjunto de bienes y servicios producidos en una entidad federativa durante un año. Millones de MX$ a precios constantes de 2008 | (INEGI, 2006, 2012) |
| PIB per cápita | Producto interno bruto per cápita por entidad federativa. MX$ a precios constantes de 2008 | (INEGI, 2006, 2012) |
| Los esfuerzos realizados | ||
|---|---|---|
| Esta dimensión refleja los esfuerzos realizados para el incremento y consolidación de las capacidades (adquisición de conocimiento en sus diversas formas, I+D, y otras) | ||
| Variables | Definiciones | Fuente/Año |
| Gasto I+D empresas | Gasto destinado por las empresas del sector productivo en actividades de investigación y desarrollo tecnológico intramuros por entidad federativa. Miles de MX$ | (INEGI, 2012) |
| Inversión extranjera directa | Inversión extranjera directa por entidad federativa. Millones de US$ | (SE, 2006, 2012) |
| Los resultados logrados | ||
|---|---|---|
| Esta dimensión muestra los resultados logrados a partir de las capacidades existentes (patentes, tasa de innovación y contenido tecnológico de las exportaciones) | ||
| Variables | Definiciones | Fuente/Año |
| Artículos en publicaciones científicas | Artículos publicados por titulares mexicanos en publicaciones científicas y técnicas por entidad federativa | (CONACYT, 2012) |
| Patentes solicitadas | Patentes solicitadas en México por titulares mexicanos por entidad federativa por cada 100,000 habitantes | (IMPI, 2006, 2009) |
| Patentes otorgadas | Patentes solicitadas en México por titulares mexicanos por entidad federativa por cada 100,000 habitantes | (IMPI, 2006, 2009) |
Fuente: elaboración propia con base en la taxonomía de Cepal (2007).
Con el trabajo empírico se analizan 2 periodos (2006 y 2012) a través de 3 etapas. La primera consiste en reducir un gran número de indicadores a través del análisis factorial, obteniéndose 2 factores. Después, tales factores se utilizan para identificar diferentes grupos de estados mediante la técnica de cluster. Finalmente, se realiza un test econométrico para evaluar la precisión estadística de los resultados de los conglomerados obtenidos, comprobando así la existencia de 7 grupos de estados caracterizados por distintos niveles de capacidad tecnológica y detectando también 3 entidades que evolucionaron a un cluster más avanzado, tanto en lo referente a la capacidad de absorción e innovación, como en lo relativo a las capacidades tecnológicas de infraestructura.
Breve revisión de conceptosBell, Pavitt y Lall (citados por Cepal, 2007, p. 11) señalan que el desarrollo de capacidades tecnológicas «implica conocimientos y habilidades para adquirir, usar, absorber, adaptar, mejorar y generar nuevas tecnologías». Partiendo de esta definición, se entiende que las capacidades tecnológicas incluyen las capacidades de innovación y las capacidades de absorción. La primera está sujeta a aspectos como las infraestructuras, las actividades de innovación y formación de capital humano, y las habilidades de los países para crear, imitar y gestionar el conocimiento, mientras que la segunda se refiere a la posibilidad de acceder, aprender y asimilar tecnologías extranjeras (Quiñones y Tezanos, 2011).
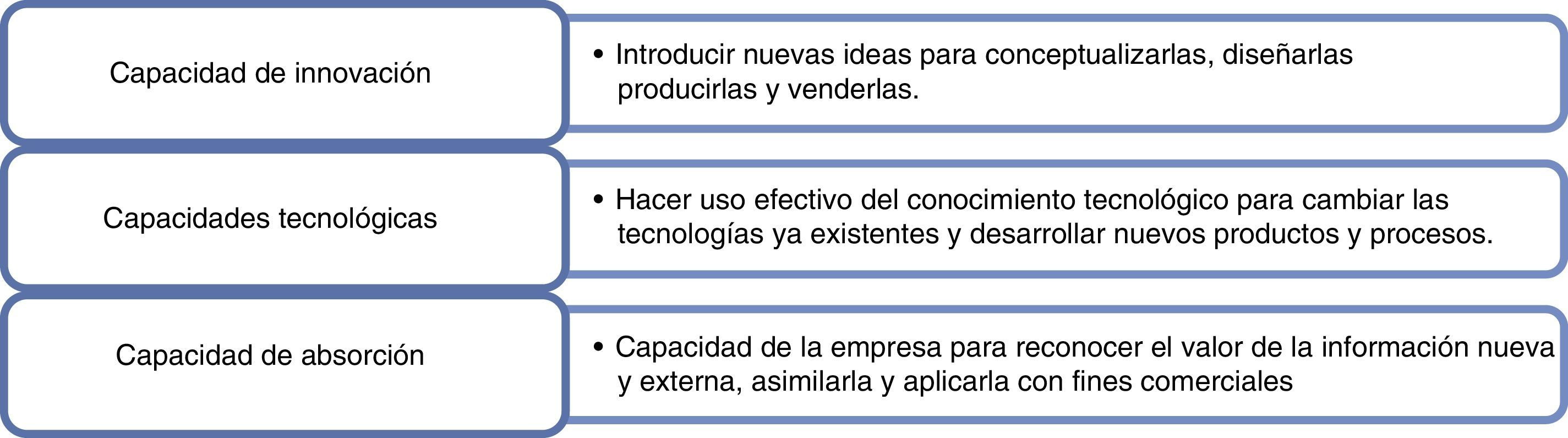
Para García, Blázquez y Ruiz (2012) existen 3 tipos de capacidades: la capacidad tecnológica, la capacidad de absorción y la capacidad de innovación (fig. 1), las cuales han sido usualmente tratadas por separado. Sin embargo, se ha evidenciado la existencia de elementos compartidos entre ellas y una intensa correlación que hace posible que dichas capacidades puedan ser estudiadas conjuntamente. Además, dado que las capacidades tecnológicas incluyen la capacidad de absorción e innovación, consecuentemente la conexión existente entre dichas capacidades hace pertinente la focalización hacia las capacidades tecnológicas como elemento central.
 y García et al. (2012a).")
Tipos de capacidades.
Fuente: elaboración propia con base en Biggs, Shah y Srivastava (1995) y García et al. (2012a).
Chinaprayoon (2007) indica que una de las peculiaridades de la tecnología es su variedad y, por lo tanto, las capacidades tecnológicas están compuestas de elementos heterogéneos, incluyendo las actividades de investigación, infraestructura, stock de conocimiento, recursos humanos y otros componentes. Debido a ello es imposible usar un solo indicador para explicar las capacidades tecnológicas de una nación o entidad.
En este artículo se utilizó una serie de indicadores que miden directa e indirectamente distintos aspectos relevantes de la capacidad tecnológica para las 32 entidades federativas de México. Es bien sabido que la ventaja de utilizar una batería de indicadores es que así se consigue definir con mayor precisión la situación de cada país (en este caso la situación estatal), proporcionando una comprensión más fácil de las diferencias entre ellos.
Propiamente, este trabajo adoptó las dimensiones propuestas por Cepal (2007), ya que dichas dimensiones toman en cuenta los sistemas de innovación para países en desarrollo (como México), los cuales merecen contar con su propia batería de indicadores basada en los componentes que son relevantes para su contexto. En ese sentido, se adaptaron algunas variables en relación a la dimensión de los esfuerzos realizados y los resultados logrados, ya que, como indican Archibugi y Coco (2005), en muchos casos las variables son dictadas por la disponibilidad de las fuentes estadísticas, más que de las preferencias teóricas. Para este estudio se tomaron los años 2006 y 2012, por tratarse de información pública disponible (tabla 1).
Es importante indicar que los datos que se han utilizado para este trabajo provienen de 2 fuentes: datos publicados referentes al año 2006 y 2012 (datos duros) y datos de la Encuesta sobre Investigación y Desarrollo Tecnológico y Módulo sobre Actividades de Biotecnología y Nanotecnología (datos de encuesta)1.
Para lograr que los datos sean comparables se ha procedido a normalizarlos de acuerdo con la fórmula para comparar indicadores individuales propuesta por Archibugi y Coco (2004), la cual se expresa como sigue: (valor observado − valor mínimo) / (valor máximo − valor mínimo); rango de índices: [0 y 1].
Metodología y análisis de resultadosLa metodología del presente trabajo consiste en desarrollar un análisis estadístico multivariante de cluster para los años 2006 y 2012 que, como primer punto, muestre los resultados referentes a la estadística descriptiva de las variables previamente normalizadas; posteriormente se realiza el análisis factorial, para destacar los principales componentes relativos al estudio de la capacidad tecnológica, y como tercer paso se corre un análisis de conglomerados jerárquicos, mejor conocido como análisis cluster, para identificar los grupos de estados que comparten características similares. Finalmente, se realiza un test econométrico para la validación del análisis cluster. Los métodos mencionados se describirán puntualmente en las siguientes secciones.
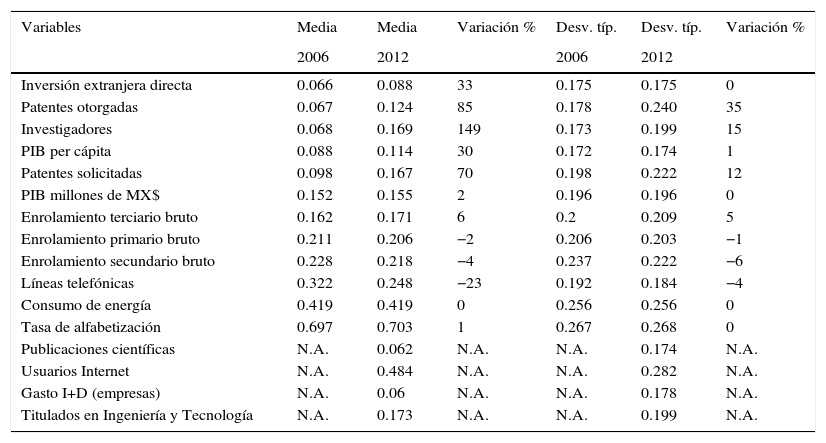
Revisión de los estadísticos descriptivosEn esta sección se presentan los estadísticos descriptivos previamente normalizados para los años analizados, en los cuales se considera que al tomar el dato menor y aplicarle la fórmula de normalización, se obtiene un cero. Asimismo, el dato mayor será un uno. Por lo tanto, estos datos definen el rango [0,1] y todos los demás datos estarán contenidos en dicho intervalo. Podría entenderse que el dato se vuelve un porcentaje, donde el 0% es el valor mínimo y el 100% es el valor máximo, y las variables en cuestión representan algún porcentaje entre 0 y 100.
Los estadísticos descriptivos que resultan útiles en el análisis son la media y la desviación típica (tal como se muestra en la tabla 2). Para la mayoría de las variables la media tiene un crecimiento pequeño y la desviación típica se mantiene igual o casi igual, lo que implica que la mayoría de los estados crecieron aproximadamente en la misma cantidad.
Estadísticos descriptivos (año 2006 y 2012)
| Variables | Media | Media | Variación % | Desv. típ. | Desv. típ. | Variación % |
|---|---|---|---|---|---|---|
| 2006 | 2012 | 2006 | 2012 | |||
| Inversión extranjera directa | 0.066 | 0.088 | 33 | 0.175 | 0.175 | 0 |
| Patentes otorgadas | 0.067 | 0.124 | 85 | 0.178 | 0.240 | 35 |
| Investigadores | 0.068 | 0.169 | 149 | 0.173 | 0.199 | 15 |
| PIB per cápita | 0.088 | 0.114 | 30 | 0.172 | 0.174 | 1 |
| Patentes solicitadas | 0.098 | 0.167 | 70 | 0.198 | 0.222 | 12 |
| PIB millones de MX$ | 0.152 | 0.155 | 2 | 0.196 | 0.196 | 0 |
| Enrolamiento terciario bruto | 0.162 | 0.171 | 6 | 0.2 | 0.209 | 5 |
| Enrolamiento primario bruto | 0.211 | 0.206 | −2 | 0.206 | 0.203 | −1 |
| Enrolamiento secundario bruto | 0.228 | 0.218 | −4 | 0.237 | 0.222 | −6 |
| Líneas telefónicas | 0.322 | 0.248 | −23 | 0.192 | 0.184 | −4 |
| Consumo de energía | 0.419 | 0.419 | 0 | 0.256 | 0.256 | 0 |
| Tasa de alfabetización | 0.697 | 0.703 | 1 | 0.267 | 0.268 | 0 |
| Publicaciones científicas | N.A. | 0.062 | N.A. | N.A. | 0.174 | N.A. |
| Usuarios Internet | N.A. | 0.484 | N.A. | N.A. | 0.282 | N.A. |
| Gasto I+D (empresas) | N.A. | 0.06 | N.A. | N.A. | 0.178 | N.A. |
| Titulados en Ingeniería y Tecnología | N.A. | 0.173 | N.A. | N.A. | 0.199 | N.A. |
N.A.: dato no disponible en dicho año.
n válido=32 (según lista).
Fuente: elaboración propia (SPSS 21).
Sin embargo, variables como la inversión extranjera directa o el PIB per cápita muestran un crecimiento importante en la media. No obstante, la desviación típica se mantiene muy parecida. Esto indicaría que la mayoría de los estados aumentaron su valor en estas variables de forma importante pero mantuvieron la misma dispersión en sus diferencias con respecto a los demás estados. Podría interpretarse que hubo un cierto factor que afectó a todos los estados causando el aumento generalizado en los valores.
Por otro lado, variables como las patentes otorgadas, el número de investigadores y el PIB aumentaron en gran medida en sus medias y también sufrieron cambios importantes en sus desviaciones típicas. Esto quiere decir que los estados crecieron pero de forma dispareja, unos más que otros. Puede interpretarse que para estas variables no hubo un solo factor que produjera los cambios en todos los estados, sino que cada uno cambió por sus propias causas. Finalmente, cabe recalcar que la variable líneas telefónicas sufrió un decremento en su media; dicha variable, según Chinaprayoon (2007), es considerada como difusora de las viejas tecnologías, en contraste con internet y las líneas de teléfono celular, que representan la difusión de las nuevas tecnologías.
Análisis factorialEl análisis factorial tiene como objetivo identificar las variables explicativas que mejor examinan la distribución de la capacidad tecnológica entre estados. El objetivo del análisis factorial es, por tanto, extraer un número menor de factores que expliquen la mayor parte de la varianza de la muestra, y es una técnica ampliamente utilizada y aceptada en este tipo de estudios (Archibugi, 1988). Sin embargo, previo al análisis factorial se estudió la viabilidad de realizarlo para el conjunto de datos (años 2006 y 2012), para lo cual se utilizó la prueba de Kaiser-Meyer-Okin (KMO) y la prueba de esfericidad de Bartlett (tabla 3).
El índice de KMO se utiliza para comparar las magnitudes de los coeficientes de correlación múltiples observados con las magnitudes de coeficientes de correlación parcial (Álvarez, 1995). Cuando el valor del índice es bajo, menor de 0.5, se desaconseja la aplicación del análisis, ya que las correlaciones entre pares de variables no se pueden explicar a través de las otras variables. Cuanto más próximo a 1 esté el índice KMO, más adecuada es la utilización del análisis factorial. Se observa que para el año 2006 el índice KMO=0.763>0.5. Entonces sí tiene sentido hacer un análisis factorial. Lo mismo sucede para el año 2012, ya que el índice KMO=0.717>0.5.
Por otra parte, la prueba de esfericidad de Bartlett contrasta si hay interrelaciones entre las variables mediante la enunciación de la hipótesis nula, consistente en que la matriz de correlación es la matriz identidad (la que tiene unos en la diagonal principal y ceros en el resto de valores). Si se confirma la hipótesis nula, supondría que las variables no están correlacionadas. Si por el contrario se rechaza la hipótesis nula, las variables estarían relacionadas y sería adecuado realizar el análisis factorial (Pedroza, 2006).
Para ambos periodos 2006 y 2012, el valor p asociado a la prueba de esfericidad de Bartlett es menor a 0.05, entonces se rechaza la H0 y, por lo tanto, sí tiene sentido hacer un análisis factorial. La tabla 4 agrupa los resultados de los factores en los años 2006 y 2012, respectivamente. Estos 2 factores conjuntamente explican un alto porcentaje de la varianza de la muestra (entre 74.26 y 78.65%, respectivamente), lo cual es significativo a niveles convencionales e indica, por tanto, que estos factores representan la mayor parte de la variabilidad en los datos.
Resultados de la matriz de componentes rotados
| Factor 1 | Factor 2 |
|---|---|
| Capacidad de absorción e innovación | Capacidad tecnológica de infraestructura |
| Graficado en: | |
| Eje de las Y | Eje de las X |
| Enrolamiento terciario | Usuarios de internet |
| Titulados (Ingeniería & Tecnología) | Tasa de alfabetización |
| PIB precios constantes | Consumo de eléctrica |
| Gasto I+D (empresas) | PIB per cápita |
| Inversión extranjera directa | Líneas telefónicas |
| Publicaciones científicas | |
| Enrolamiento secundario | |
| Enrolamiento primario | |
| Patentes solicitadas | |
| Investigadores | |
| Patentes otorgadas | |
Para cada factor se eligen las variables con saturaciones superiores a 0.5.
Fuente: elaboración propia con base en resultados Matriz de Componentes rotados (SPSS 21).
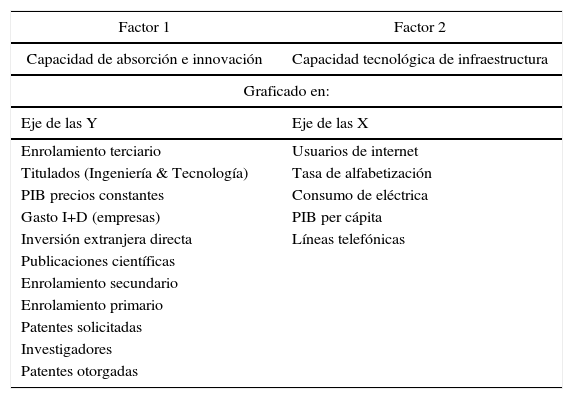
Factor 1. Es una combinación de 11 variables que suponen el 58.5% de la varianza de la muestra en el año 2006 y el 54.7% en el año 2012, por lo que implica ser una dimensión muy relevante para analizar las diferencias en la capacidad tecnológica entre entidades federativas. El factor1, acorde con la literatura, podría ser interpretado como la capacidad de absorción e innovación.
Factor 2. Es una combinación de 5 variables que suponen el 19.5% de la varianza de la muestra (año 2012) y el 20.1% en el año 2006. El factor2, acorde con la literatura, podría ser interpretado como la capacidad tecnológica de infraestructura.
La tabla 4, denominada «matriz de componentes rotados», indica la correlación existente (saturación) entre cada una de las variables y su correspondiente factor. La saturación representa el peso (la importancia) de la variable dentro del factor. Cabe mencionar que a diferencia de lo que ocurre en otras técnicas como el análisis de varianza o el de regresión, en el análisis factorial todas las variables del análisis cumplen el mismo papel: todas ellas son independientes en el sentido de que no existe a priori una dependencia conceptual de unas variables sobre otras. Por lo tanto, las variables de ambos factores (X & Y) son consideradas independientes.
Habrá que poner en claro el significado de los factores obtenidos. El factor1 (graficado en el eje de las Y), denominado capacidad de absorción e innovación, incluye variables relativas a la tasa de enrolamiento, recursos humanos dedicados a la investigación, ciencia y tecnología; dichas variables suponen la capacidad de los estados para reconocer el valor de la información nueva y externa, asimilarla y aplicarla con fines comerciales. Por otra parte, dentro de este mismo factor se incluyen variables de resultados logrados, como lo son las patentes solicitadas y otorgadas y el gasto en investigación y desarrollo de las empresas por estado, indicadores que muestran la capacidad de las entidades federativas para introducir nuevas ideas, conceptualizarlas, diseñarlas, producirlas y venderlas. Otra de las variables incluida en el factor1 es la referente a la inversión extranjera directa, que ejemplifica la adquisición del conocimiento externo de las entidades.
Por otra parte, el factor 2, etiquetado como capacidad tecnológica de infraestructura, considera indicadores de consumo de energía eléctrica, líneas de teléfono y usuarios de internet2, variables consideradas como de infraestructura que aportan un conocimiento general del entorno en el cual se desarrollan las actividades productivas de las entidades de la república mexicana. La combinación de estos 3 aspectos ofrece indicios del grado de sofisticación de la producción, «ya que puede suponerse que a mayor valor de los indicadores en cuestión corresponde una mayor sofisticación, lo que debería traducirse en mayor valor agregado en la producción» (Cepal, 2007, p. 32). Además, dicho factor añade la tasa de alfabetización como una métrica del nivel general del entorno productivo. Finalmente, se incluye el indicador del PIB per cápita, ya que es sabido que los productos con mayor contenido tecnológico (o contenido de conocimiento) se caracterizan por una mayor elasticidad de la demanda. En otros el PIB per cápita es un indicador de la complejidad de la demanda tecnológica3.
Análisis clusterEl análisis cluster es la denominación de un grupo de técnicas multivariantes cuyo principal propósito es agrupar objetos basándose en las características que poseen. Los conglomerados resultantes deberían mostrar un alto grado de homogeneidad interna dentro del conglomerado y un alto grado de heterogeneidad externa del mismo (Álvarez, 1995). En este caso se busca la partición de un conjunto de datos (correspondientes a distintos estados) en grupos, de tal forma que los datos pertenecientes a un mismo grupo sean muy similares entre sí pero muy diferentes a los de los otros grupos. Para conseguir formar grupos homogéneos de observaciones (en este caso de entidades) hay que medir su similaridad o su distancia (disimilaridad). A este respecto, se han desarrollado numerosos métodos para medir la distancia entre los casos. En este trabajo se utilizó la distancia euclídea, la cual mide el parecido entre unidades de análisis que han sido evaluadas en un conjunto de variables métricas (cuantitativas).
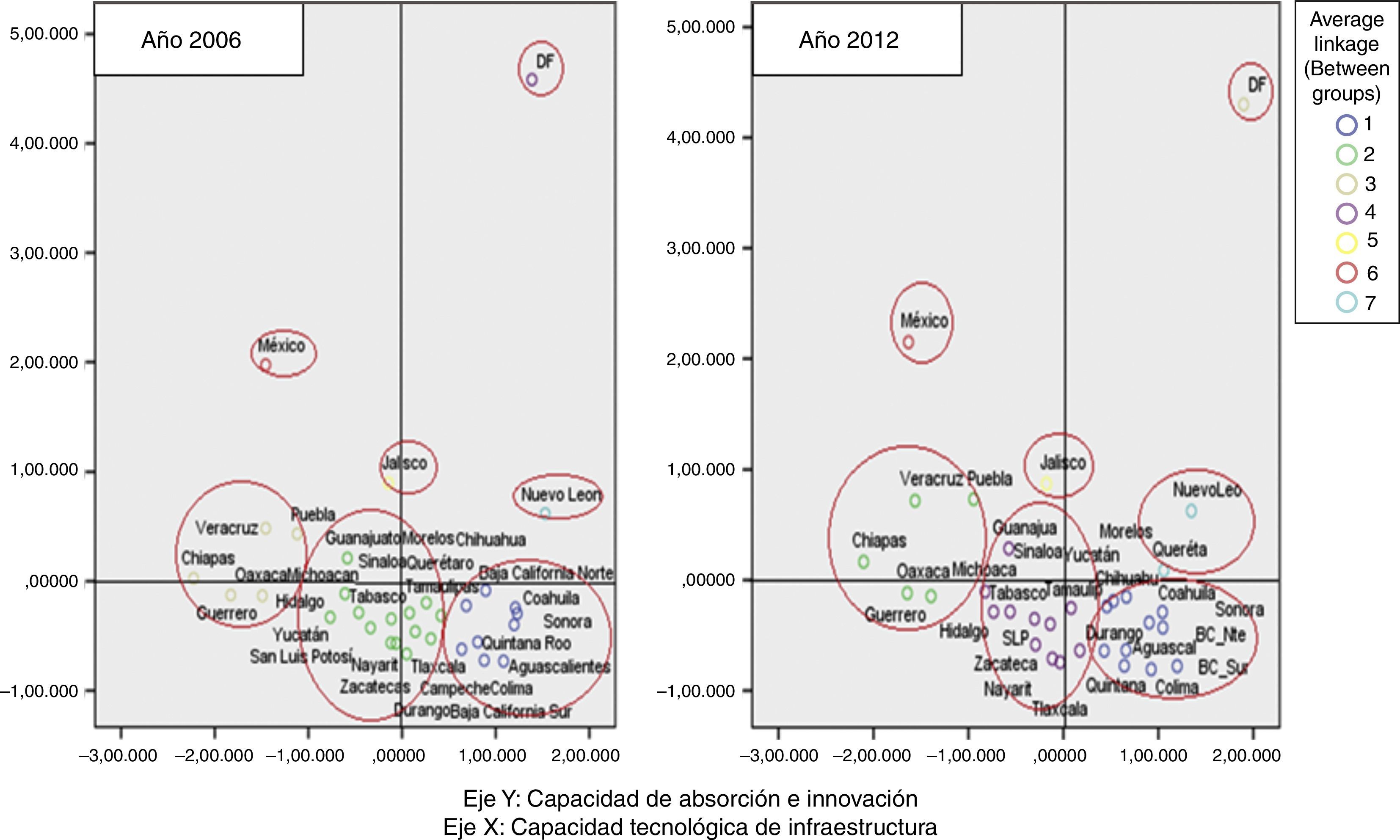
Los clusters estatales y su evolución en el período 2006-2012El análisis de conglomerados jerárquicos (análisis cluster) comienza con el cálculo de la matriz de distancias entre los elementos de la muestra. Esa matriz contiene las distancias existentes entre cada elemento y todos los restantes de la muestra. Posteriormente se buscan los 2 elementos más próximos (es decir, los 2 más similares en términos de distancia) y se agrupan en un conglomerado. El conglomerado resultante es indivisible a partir de ese momento (de ahí el nombre de jerárquico asignado al procedimiento). De esta manera, se van agrupando los elementos en conglomerados cada vez más grandes y más heterogéneos entre ellos, hasta llegar al último paso, en el que todos los elementos muestrales quedan agrupados en un único conglomerado global. El procedimiento de conglomerados jerárquico del SPSS informa de todos los pasos realizados en el análisis, por lo que resulta fácil apreciar qué elementos o conglomerados se han fundido en cada paso y a qué distancia se encontraban cuando se fusionaron. Esto permite valorar la heterogeneidad de los conglomerados. Esta sección presenta los resultados del análisis estadístico multivalente cluster que divide las entidades federativas de México en 7 grupos o clusters caracterizados por distintos niveles de capacidad tecnológica en los períodos 2006 y 2012. En la tabla 5 aparecen los estados que integran cada uno de los grupos en los 2 períodos considerados.
Clusters obtenidos
| Cluster | 2006 | 2012 |
|---|---|---|
| 1 | D.F. | D.F. |
| 2 | Nuevo León | Nuevo León |
| Querétaro* | ||
| 3 | Jalisco | Jalisco |
| 4 | México | México |
| 5 | Aguascalientes | Aguascalientes |
| Baja California Norte | Baja California Norte | |
| Baja California Sur | Baja California Sur | |
| Coahuila | Campeche* | |
| Colima | Coahuila | |
| Chihuahua | Colima | |
| Quintana Roo | Chihuahua | |
| Sonora | Morelos* | |
| Tamaulipas | Quintana Roo | |
| Sonora | ||
| Tamaulipas | ||
| 6 | Campeche* | Durango |
| Durango | Guanajuato | |
| Guanajuato | Hidalgo | |
| Hidalgo | Michoacán | |
| Michoacán | Nayarit | |
| Morelos* | San Luis Potosí | |
| Nayarit | Sinaloa | |
| Querétaro* | Tabasco | |
| San Luis Potosí | Tlaxcala | |
| Sinaloa | Yucatán | |
| Tabasco | Zacatecas | |
| Tlaxcala | ||
| Yucatán | ||
| Zacatecas | ||
| 7 | Veracruz | Veracruz |
| Puebla | Puebla | |
| Guerrero | Guerrero | |
| Oaxaca | Oaxaca | |
| Chiapas | Chiapas |
Fuente: elaboración propia con base en resultados de conglomerados (SPSS 21).
En materia de capacidades tecnológicas, México se mueve a 7 pasos diferentes. Los clusters estatales de capacidad tecnológica obtenidos son descritos a continuación:
Clúster 1. Excelente en capacidad de absorción e innovación y bueno en capacidad tecnológica de infraestructura. En este conglomerado se encuentra únicamente el D.F., en los 2 periodos de tiempo, al contar con una posición claramente destacada en cuanto a estos 2 componentes. Sin embargo, no se ha producido una evolución visible en ninguno de los 2 factores en los períodos considerado. De modo contrario, parece haber disminuido ligeramente en los factores analizados de 2006 y 2012.
Clúster 2. Regular en capacidad de absorción e innovación y excelente en capacidad tecnológica de infraestructura. Este grupo se encuentra a una distancia considerable respecto del cluster1, formado por D.F., en cuanto a capacidad de absorción e innovación. Sin embargo, es el grupo que obtiene una mejor posición en cuanto a capacidad tecnológica de infraestructura. Este conglomerado estaba formado en 2006 únicamente por Nuevo León; sin embargo, en 2012 este grupo está compuesto por Nuevo León y Querétaro, este último estado proveniente del cluster6 en el año 2006, debido fundamentalmente a su mejora en ambos factores.
Clúster 3. Bueno en capacidad de absorción e innovación y con déficit bajo en capacidad tecnológica de infraestructura. En este conglomerado se encuentra Jalisco, tanto en 2006 como en 2012. Por una parte, se encuentra bien posicionado dentro del componente de capacidad de absorción e innovación, pero con un posicionamiento ligeramente negativo en lo relativo a las capacidades tecnológicas de infraestructura.
Clúster 4. Bueno en capacidad de absorción e innovación y con déficit medio en capacidad tecnológica de infraestructura. En este conglomerado se encuentra el estado de México; se observa que en el primer componente presenta una posición positiva (solo por debajo del cluster1), y en lo que respecta al segundo componente, se ubica en el cuadrante negativo.
Clúster 5. Déficit bajo en capacidad de absorción e innovación y regular en capacidad tecnológica de infraestructura. Este grupo estaba constituido por 9 estados en 2006 (Aguascalientes, Baja California Norte, Baja California Sur, Coahuila, Colima, Chihuahua, Quintana Roo, Sonora, Tamaulipas). En 2012, todos esos estados permanecen en este grupo, no observándose ninguna evolución. Sin embargo, para esa fecha se les añaden los estados de Campeche y Morelos (los cuales se encontraban en el cluster6 en el año 2006) y cuyo progreso se debió principalmente a la mejoría en ambos factores.
Clúster 6. Déficit medio en capacidad de absorción e innovación y déficit medio en capacidad tecnológica de infraestructura. Este grupo estaba constituido por 14 estados en 2006 (Campeche, Durango, Guanajuato, Hidalgo, Michoacán, Morelos, Nayarit, Querétaro, San Luis Potosí, Sinaloa, Tabasco, Tlaxcala, Yucatán y Zacatecas). En 2012, todos esos estados permanecen en este grupo, con excepción de Campeche, Morelos y Querétaro, los cuales migraron a clusters en posiciones más avanzadas. Campeche y Morelos avanzaron al cluster5, mientras que el estado de Querétaro proviene del cluster6 (2006) al cluster2 (2012), debido a una ligera mejora en el factor1 y una muy amplia mejora en lo referente al factor2.
Clúster 7. Déficit bajo en capacidad de absorción e innovación y déficit elevado en capacidad tecnológica de infraestructura: Este grupo estaba constituido por 5 estados en 2006 (Veracruz, Puebla, Guerrero, Oaxaca, Chiapas). En 2012, todos esos estados permanecen en este grupo. Se observa que los estados de Veracruz y Puebla se hallan en el límite del grupo, tendentes a migrar a un cluster más avanzado.Estos clusters así definidos se pueden observar con más claridad en la figura 2, que muestran a todos los estados ordenados en función de los 2 factores obtenidos.
.")
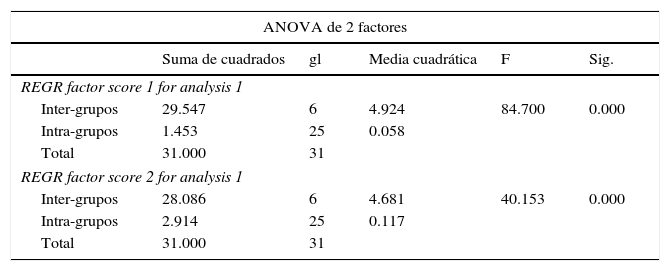
En el mismo sentido, se ha llevado a cabo un test ANOVA (tabla 6) para contrastar que el análisis cluster realizado para el año 2006 es adecuado y si existen diferencias significativas entre los grupos obtenidos. El ANOVA y las pruebas post-hoc nos permitirán verificar que el análisis de clusters efectuado para las distintas variables es correcto, en el sentido de poder comprobar la existencia de diferencias significativas entre los 7 grupos considerados. Los resultados que se muestran a continuación confirman la bondad del análisis.
Prueba ANOVA de 2 factores. Año 2006
| ANOVA de 2 factores | |||||
|---|---|---|---|---|---|
| Suma de cuadrados | gl | Media cuadrática | F | Sig. | |
| REGR factor score 1 for analysis 1 | |||||
| Inter-grupos | 29.547 | 6 | 4.924 | 84.700 | 0.000 |
| Intra-grupos | 1.453 | 25 | 0.058 | ||
| Total | 31.000 | 31 | |||
| REGR factor score 2 for analysis 1 | |||||
| Inter-grupos | 28.086 | 6 | 4.681 | 40.153 | 0.000 |
| Intra-grupos | 2.914 | 25 | 0.117 | ||
| Total | 31.000 | 31 | |||
Fuente: elaboración propia (SPSS 21).
Dentro del test ANOVA (año 2006), dado que p=0.05>Sig=0.000, se rechaza la H0, y por lo tanto existe una diferencia estadísticamente significativa entre el total de grupos.
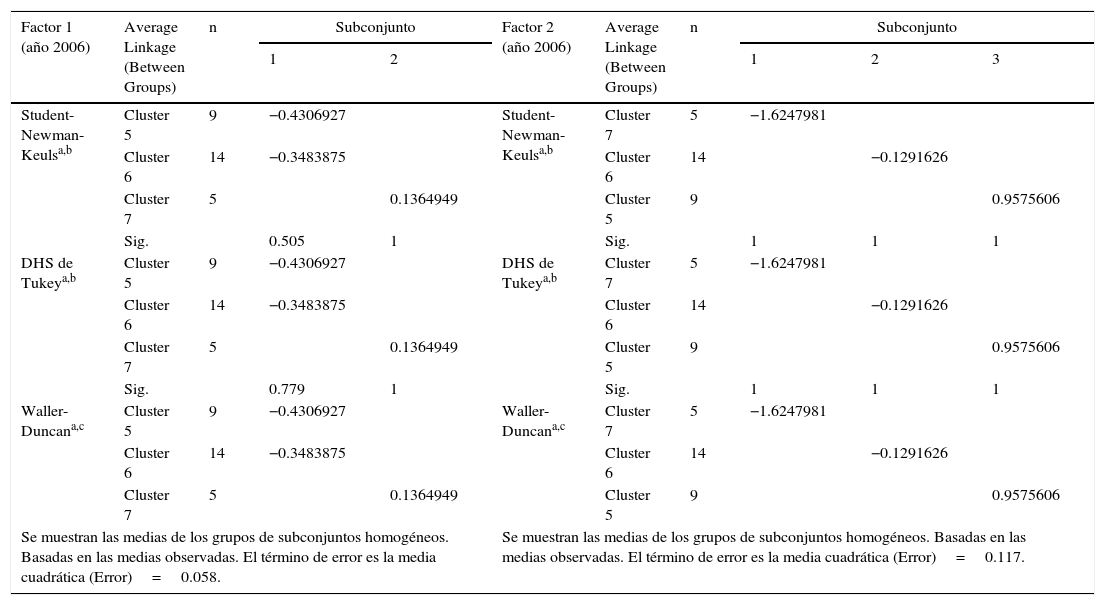
Una vez que se ha determinado que existen diferencias entre las medias, las pruebas de rango post-hoc permiten determinar qué medias difieren. La prueba de rango post-hoc identifica subconjuntos homogéneos de medias que no se diferencian entre sí. Por tanto, para comprobar si existen diferencias entre todos los grupos se han realizado además las pruebas de Student-Newman-Keuls, HDS de Tukey y Waller-Duncan4. Se ha efectuado la prueba con los 3 grupos que contienen más de un estado, eliminando por tanto el caso del D.F., México, Jalisco y Nuevo León, que presenta claras diferencias con el resto de grupos.
La tabla 7 contiene los resultados de las pruebas post-hoc para el factor1 definido como las capacidades de absorción e innovación. Se observa que:
- •
Existe una diferencia estadísticamente significativa entre el cluster5 y el cluster7.
- •
Existe una diferencia estadísticamente significativa entre el cluster6 y el cluster7.
- •
Sin embargo, no se presentan diferencias significativas entre el cluster5 y el cluster6, debido a que la Sig.>0.05, en este caso 0.5>0.05. En el diagrama de dispersión (fig. 2) se puede observar cierta coincidencia.
Pruebas post-hoc para el factor 1-2. Año 2006
| Factor 1 (año 2006) | Average Linkage (Between Groups) | n | Subconjunto | Factor 2 (año 2006) | Average Linkage (Between Groups) | n | Subconjunto | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | 3 | ||||||
| Student-Newman-Keulsa,b | Cluster 5 | 9 | −0.4306927 | Student-Newman-Keulsa,b | Cluster 7 | 5 | −1.6247981 | |||
| Cluster 6 | 14 | −0.3483875 | Cluster 6 | 14 | −0.1291626 | |||||
| Cluster 7 | 5 | 0.1364949 | Cluster 5 | 9 | 0.9575606 | |||||
| Sig. | 0.505 | 1 | Sig. | 1 | 1 | 1 | ||||
| DHS de Tukeya,b | Cluster 5 | 9 | −0.4306927 | DHS de Tukeya,b | Cluster 7 | 5 | −1.6247981 | |||
| Cluster 6 | 14 | −0.3483875 | Cluster 6 | 14 | −0.1291626 | |||||
| Cluster 7 | 5 | 0.1364949 | Cluster 5 | 9 | 0.9575606 | |||||
| Sig. | 0.779 | 1 | Sig. | 1 | 1 | 1 | ||||
| Waller-Duncana,c | Cluster 5 | 9 | −0.4306927 | Waller-Duncana,c | Cluster 7 | 5 | −1.6247981 | |||
| Cluster 6 | 14 | −0.3483875 | Cluster 6 | 14 | −0.1291626 | |||||
| Cluster 7 | 5 | 0.1364949 | Cluster 5 | 9 | 0.9575606 | |||||
| Se muestran las medias de los grupos de subconjuntos homogéneos. Basadas en las medias observadas. El término de error es la media cuadrática (Error)=0.058. | Se muestran las medias de los grupos de subconjuntos homogéneos. Basadas en las medias observadas. El término de error es la media cuadrática (Error)=0.117. | |||||||||
Fuente: elaboración propia (SPSS 21).
Del mismo modo, los resultados de las pruebas post-hoc para el factor2, definido como las capacidades tecnológicas de infraestructura, muestran que existe una diferencia estadísticamente significativa entre todos los clusters.
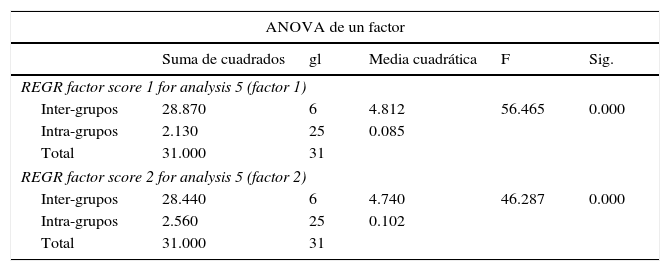
Test econométrico de validación del análisis cluster para el año 2012De igual manera, se ha llevado a cabo el test ANOVA para contrastar que el análisis cluster realizado para el año 2012 es adecuado y si existen diferencias significativas entre los grupos obtenidos (tabla 8).
Prueba ANOVA de 2 factores. Año 2012
| ANOVA de un factor | |||||
|---|---|---|---|---|---|
| Suma de cuadrados | gl | Media cuadrática | F | Sig. | |
| REGR factor score 1 for analysis 5 (factor 1) | |||||
| Inter-grupos | 28.870 | 6 | 4.812 | 56.465 | 0.000 |
| Intra-grupos | 2.130 | 25 | 0.085 | ||
| Total | 31.000 | 31 | |||
| REGR factor score 2 for analysis 5 (factor 2) | |||||
| Inter-grupos | 28.440 | 6 | 4.740 | 46.287 | 0.000 |
| Intra-grupos | 2.560 | 25 | 0.102 | ||
| Total | 31.000 | 31 | |||
Fuente: elaboración propia (SPSS 21).
Los resultados de la prueba ANOVA rechazan la H0. Por lo tanto, existe una diferencia estadísticamente significativa entre el total de grupos, dado que p=0.05>Sig=0.000.
Se han efectuado también las pruebas post-hoc con los 4 grupos que contienen más de un estado, eliminando por tanto el caso del D.F., México y Jalisco, que presenta claras diferencias con el resto de los grupos.
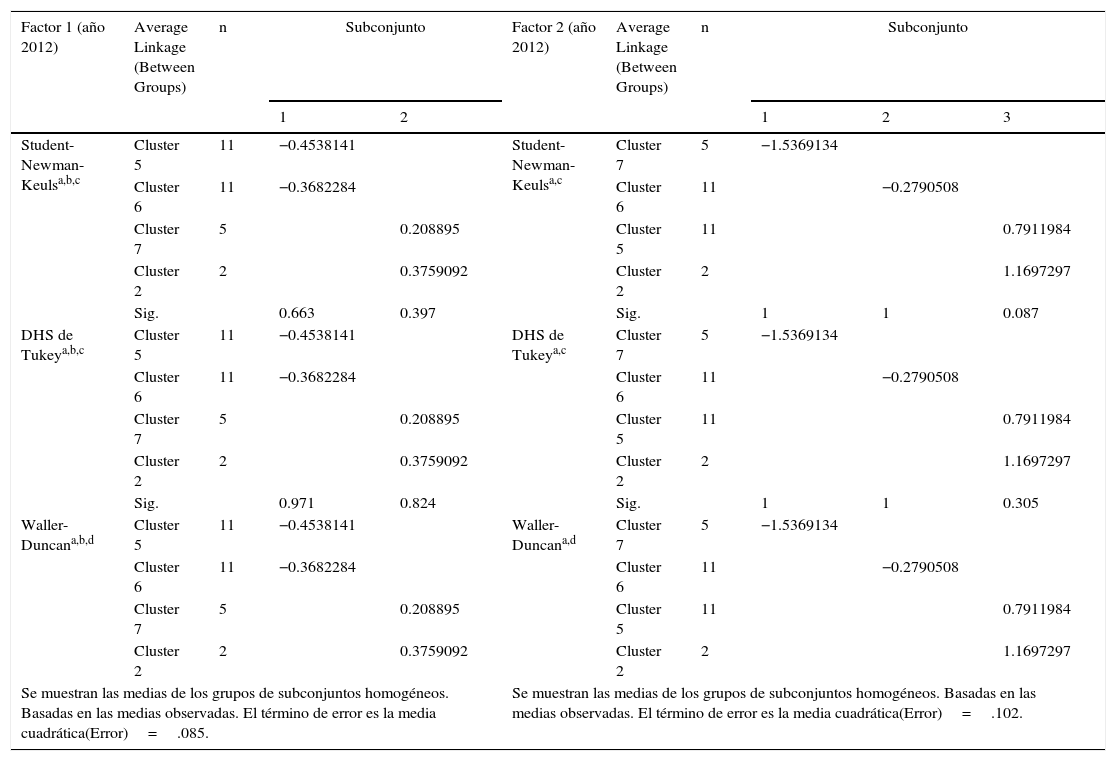
La tabla 9 muestra los resultados de las pruebas post-hoc para el factor1, definido como las capacidades de absorción e innovación, en donde se observa que:
- •
Existe una diferencia estadísticamente significativa entre el cluster5 y el cluster7.
- •
Existe una diferencia estadísticamente significativa entre el cluster5 y el cluster2.
- •
Existe una diferencia estadísticamente significativa entre el cluster6 y el cluster7.
- •
Existe una diferencia estadísticamente significativa entre el cluster6 y el cluster2.
- •
Sin embargo, no se presentan diferencias significativas entre el cluster5 y el cluster6, debido a que la Sig.>0.05, en este caso 0.66>0.05. En el diagrama de dispersión (fig. 2) se puede observar cierta coincidencia. Lo mismo sucede entre el cluster7 y el cluster2.
Pruebas post-hoc para el factor 1-2. Año 2012
| Factor 1 (año 2012) | Average Linkage (Between Groups) | n | Subconjunto | Factor 2 (año 2012) | Average Linkage (Between Groups) | n | Subconjunto | |||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | 3 | ||||||
| Student-Newman-Keulsa,b,c | Cluster 5 | 11 | −0.4538141 | Student-Newman-Keulsa,c | Cluster 7 | 5 | −1.5369134 | |||
| Cluster 6 | 11 | −0.3682284 | Cluster 6 | 11 | −0.2790508 | |||||
| Cluster 7 | 5 | 0.208895 | Cluster 5 | 11 | 0.7911984 | |||||
| Cluster 2 | 2 | 0.3759092 | Cluster 2 | 2 | 1.1697297 | |||||
| Sig. | 0.663 | 0.397 | Sig. | 1 | 1 | 0.087 | ||||
| DHS de Tukeya,b,c | Cluster 5 | 11 | −0.4538141 | DHS de Tukeya,c | Cluster 7 | 5 | −1.5369134 | |||
| Cluster 6 | 11 | −0.3682284 | Cluster 6 | 11 | −0.2790508 | |||||
| Cluster 7 | 5 | 0.208895 | Cluster 5 | 11 | 0.7911984 | |||||
| Cluster 2 | 2 | 0.3759092 | Cluster 2 | 2 | 1.1697297 | |||||
| Sig. | 0.971 | 0.824 | Sig. | 1 | 1 | 0.305 | ||||
| Waller-Duncana,b,d | Cluster 5 | 11 | −0.4538141 | Waller-Duncana,d | Cluster 7 | 5 | −1.5369134 | |||
| Cluster 6 | 11 | −0.3682284 | Cluster 6 | 11 | −0.2790508 | |||||
| Cluster 7 | 5 | 0.208895 | Cluster 5 | 11 | 0.7911984 | |||||
| Cluster 2 | 2 | 0.3759092 | Cluster 2 | 2 | 1.1697297 | |||||
| Se muestran las medias de los grupos de subconjuntos homogéneos. Basadas en las medias observadas. El término de error es la media cuadrática(Error)=.085. | Se muestran las medias de los grupos de subconjuntos homogéneos. Basadas en las medias observadas. El término de error es la media cuadrática(Error)=.102. | |||||||||
Fuente: Elaboración propia (SPSS 21).
Se visualizan también los resultados de las pruebas post-hoc para el factor 2, definido como las capacidades tecnológicas de infraestructura, denotando que existe una diferencia estadísticamente significativa entre todos los clusters, con excepción del cluster5 y el cluster2, debido a que la Sig.>0.05, en este caso 0.08>0.05.
Finalmente, se puede decir que las pruebas post-hoc han mostrado diferencias significativas en la mayoría de los casos entre los grupos considerados, y a nivel conjunto (como se comprueba en los resultados del ANOVA y el gráfico de dispersión) existen diferencias significativas entre los 7clusters. Por lo tanto, el análisis de conglomerados realizado para ambos periodos es aceptable.
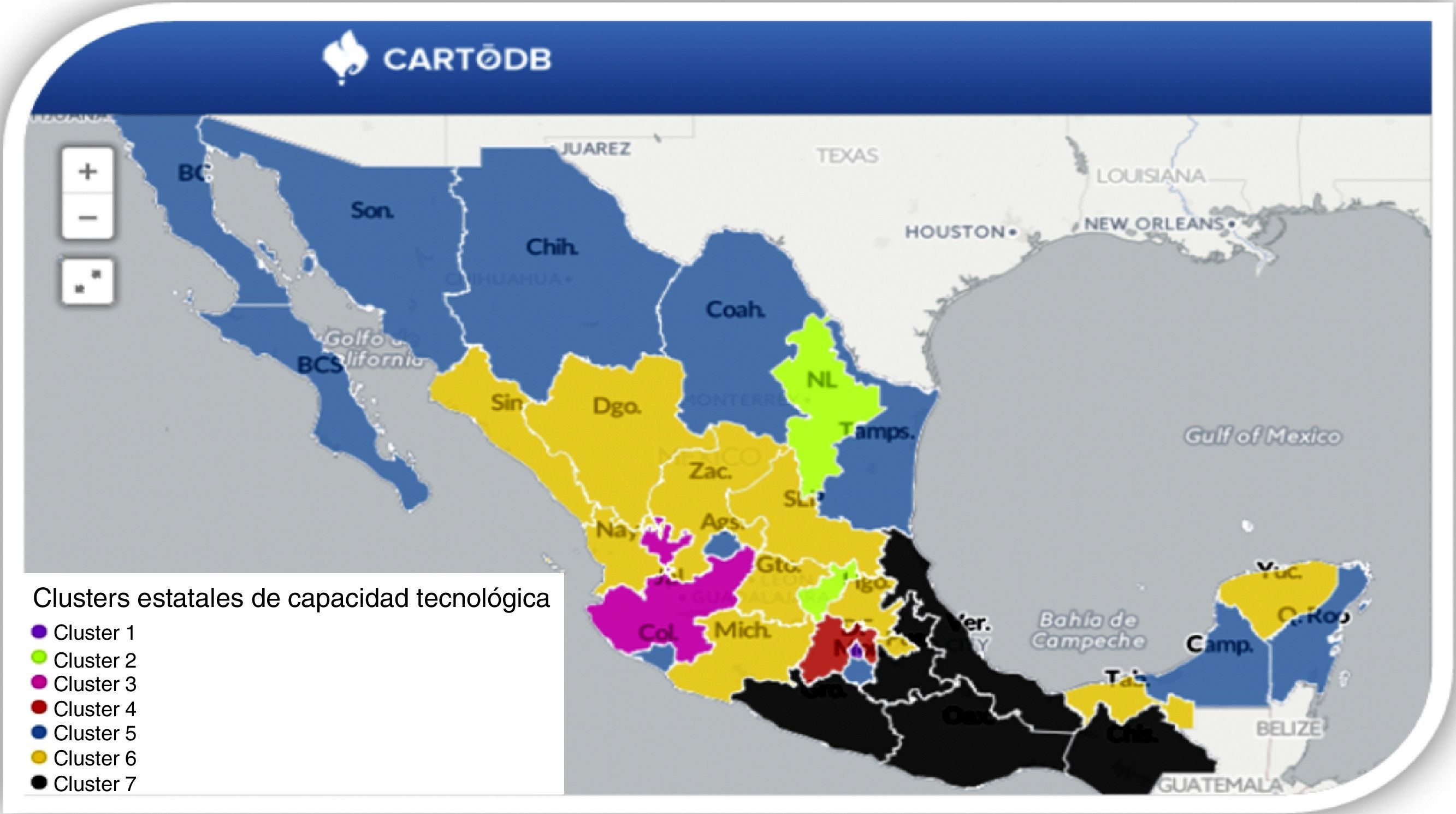
ConclusionesEste trabajo muestra una investigación empírica sobre las diferencias entre las entidades de la república mexicana en lo referente a su capacidad tecnológica y su evolución a lo largo de un período de 6 años (2006-2012). Los resultados muestran la existencia de 7 grupos de estados caracterizados claramente por distintos niveles de capacidad tecnológica; en la figura 3 se observa el predominio de los clusters5, 6 y7, dejando ver que los clusters del 1 al 4 manifiestan resultados satisfactorios en alguno de los factores analizados (capacidad de absorción e innovación y/o capacidad tecnológica de infraestructura); sin embargo, dichos clusters son los menos numerosos (5 entidades). Se visualiza la necesidad de descentralizar las actividades científicas y tecnológicas, a fin de contribuir a potenciar el desarrollo económico y el bienestar en todas las regiones del país, considerando su vocación productiva.

La clasificación de las entidades en 7 clusters diferentes y el análisis de su evolución a lo largo de 6años permiten concluir que, en general, la brecha en capacidad tecnológica —y por consecuencia en innovación tecnológica— entre los estados de la república mexicana es amplia y se concentra en unas pocas entidades (D.F., Nuevo León, Querétaro, Jalisco, Estado de México). Del 2006 al 2012, únicamente 3 entidades (Querétaro, Morelos y Campeche) lograron mudarse a un cluster más avanzado. Destaca la situación de Querétaro, que en el año 2006 se encontraba en el cluster6 y para el año 2012 se ubica en el segundo cluster, acompañando a Nuevo León y solo por debajo del D.F. Esto habla de que, a pesar de que la capacidad tecnológica —y por ende la innovación— es un proceso gradual y acumulativo, existe la posibilidad de que en un periodo de 6años los estados sí puedan avanzar considerablemente en materia de su capacidad tecnológica. El ejemplo lo han puesto estas 3 entidades, tanto en lo relativo a su capacidad de absorción e innovación como es su capacidad tecnológica de infraestructura.
Por otro lado, se pueden señalar algunas implicaciones. La primera hace referencia a la desigual distribución de la capacidad tecnológica entre los clusters observados. La combinación de los 2 factores de la capacidad tecnológica (capacidad de absorción e innovación y capacidad tecnológica de infraestructura) desempeña un importante papel a la hora de posicionar cada sistema estatal de innovación. Cada estado debería no solo observar e intentar imitar a aquellos que están en una posición o un cluster más avanzado, sino que además debería trazar su propio itinerario partiendo de su capacidad tecnológica existente, intentando tener éxito en la mejora de su posición (García, Bajo y Blázquez, 2012).
La segunda implicación se refiere a la evolución general de los sistemas de innovación. En este sentido, se debería analizar cuántos estados han mejorado y se han movido hacia un cluster superior y cuántos han retrocedido. Como se observó, ningún estado ha retrocedido a un cluster inferior, sino que algunos estados se han movido a un cluster superior. En concreto, 2 estados se han movido del cluster6 al cluster5 (Morelos y Campeche), un estado se ha movido del cluster6 al cluster2 (Querétaro) y 29 estados se han quedado más o menos como estaban. En general las variaciones en sus posiciones durante los 6años considerados no han sido demasiado importantes, hecho que puede deberse a que las capacidades tecnológicas son generadas y destruidas lentamente a lo largo del tiempo, incluso en períodos de rápido crecimiento económico (Archibugi y Castellacci, 2008). También cabe señalar que se han reducido distancias entre el cluster6 y el5 en lo referente a la capacidad tecnológica de infraestructura; lo mismo sucede entre el cluster5 y el2. Sin embargo, en los cuadrantes positivos en general solo se encuentran posicionados claramente 4 clusters (5 estados), lo cual parece coincidir con la dinámica global de la tecnología en el mundo, en la que unos pocos países generan la mayor parte del conocimiento (Archibugi y Pianta, 1996). En el largo plazo, lo anterior sugiere que México está evolucionando hacia una región en la que un pequeño grupo de estados —en torno al 16%— domina el paisaje tecnológico, frente al 84% restante de los estados, que estarían más retrasados.
A continuación se presentan con más detalle las principales conclusiones, en términos de posibles áreas de actuación para cada uno de los grupos identificados en el análisis empírico.
Con respecto a los estados situados en los clusters6 y7, estos son los que están situados en las peores posiciones en capacidad tecnológica (absorción e innovación) y tienen, por tanto, la necesidad de una clara actuación para impulsar la innovación. Con objeto de reducir su diferencia tecnológica podrían incrementar sus inversiones en I+D, ya que una mayor capacidad pública y privada de inversión en I+D podría ayudar a la industria a desarrollar sus intereses de investigación, aunado a iniciativas específicas destinadas a aumentar la cultura emprendedora, y la innovación en las PYMES también podrían fomentar la innovación (García, Blázquez y López 2012).
En el cluster 7, Puebla y Veracruz podrían incrementar sus esfuerzos, principalmente en materia de capacidad tecnológica de infraestructura. Los estados integrados en los clusters6 y7 deben hacer un esfuerzo adicional por mejorar las infraestructuras tecnológicas, ya que tienen una capacidad de absorción muy baja. En cuanto al cluster5, se observa una posición positiva en lo referente a las capacidades tecnológicas de infraestructura; sin embargo, sus esfuerzos deberían ir encaminados a incrementar su capacidad de absorción e innovación. Los clusters3 y4 mantienen una posición competitiva en cuanto a las capacidades de absorción e innovación, y a pesar de ello manifiestan ciertas deficiencias en lo relativo a su capacidad tecnológica de infraestructura, por lo que esta última debería ser reforzada prioritariamente. El cluster2, integrado por Nuevo León y Querétaro, es el mejor posicionado en capacidad tecnológica de infraestructura, y en lo referente a su capacidad de absorción e innovación se encuentra dentro del cuadrante positivo. Las empresas de los estados que lo integran determinan la competitividad tecnológica de la región. Estos estados deben prestar una particular atención a desarrollar estrategias que favorezcan la creación y difusión de conocimiento. Para ello, podrían mejorar la calidad de las instituciones de investigación, potenciar la colaboración entre las universidades y las empresas, y mejorar las leyes relacionadas con las tecnologías de la información y la comunicación, facilitando así la interacción entre todos los agentes del sistema de innovación y proporcionando la colaboración con otros actores extranjeros que les ayuden a crear nuevo conocimiento (Clarysse y Muldur, 2001, citado por García et al., 2012c). En todo caso, todavía les queda un largo recorrido para converger con el cluster1 en lo referente a los 2 componentes analizados.
Finalmente, respecto al cluster1, este es el más avanzado en capacidad de absorción e innovación, y se encuentra formado únicamente por el Distrito Federal. En este sentido, las entidades bien posicionadas deben tratar de atraer nuevo talento, facilitando así la creación y difusión de conocimiento de primer nivel (Archibugi y Coco, 2004). Este grupo podría representar un punto de referencia para grupos menos avanzados con objeto de que pudieran identificar actuaciones encaminadas a mejorar la innovación y que les pudieran ayudar a migrar a un cluster superior.
Las principales contribuciones de este trabajo son las siguientes:
Desde el punto de vista de la literatura sobre capacidades tecnológicas, estos resultados aportan nueva evidencia empírica sobre la existencia de 7 grupos diferentes de estados en la república mexicana en cuanto a su capacidad tecnológica, indicando las dimensiones en las que cada grupo se diferencia de los demás. Además, se muestra claramente que las diferencias entre estados están bien reflejadas por los 2 factores, como indican los resultados del análisis factorial y del análisis cluster. La presente investigación y clasificación podría ayudar a identificar y comprender los retos y oportunidades que los estados de cada cluster tienen que enfrentar en el futuro.
A pesar de las contribuciones de este estudio empírico, es preciso señalar sus limitaciones. No cabe duda de que la literatura sobre cambio tecnológico necesita continuar avanzando para encontrar mejores instrumentos de medida. En este sentido, los indicadores contemplados en este trabajo podrían reforzarse mediante la utilización de métodos de triangulación, como la utilización de índices sintéticos, o combinándolos con otros indicadores elaborados por diferentes organismos o instituciones, tal como aconseja García et al. (2012c). Además se señala como crítico el disponer de datos estadísticos estratificados a nivel estatal, debido a que se percibe que en la situación actual el subsistema de generación de estadísticas sobre ciencia y tecnología en México es limitado y denota áreas de oportunidad para su mejora.
Finalmente, cabe resaltar la necesidad de realizar estudios en profundidad de cada estado para poder proponer políticas tecnológicas diferenciadas. Lo que el presente trabajo pretende es simplemente señalar posibles áreas de actuación en cada estado en función de los posicionamientos obtenidos y la evolución observada de cada uno de ellos. La identificación de las áreas débiles de cada entidad en cuanto a capacidad tecnológica sugiere posibles caminos o rutas para su mejora, que obviamente deben ser complementados con estudios en profundidad de cada caso.
ReflexiónEl presente trabajo, es pues, un esfuerzo por incidir en el análisis particular de la CTI pero desde una perspectiva que permita identificar propiamente las capacidades tecnológicas a nivel estado, aglomerando a las entidades que comparten condiciones similares en dicha materia y poder, de esta forma, contar con un mapa que dibuje las distancias y el camino por recorrer, de un cluster a otro, en aras del progreso y la competitividad y con el objetivo, también, que este tipo de estudios sean fuente de referencia para incurrir en políticas tecnológicas diferenciadas y acordes a las necesidades relativas a cada grupo de estados.
Decir que México no crece es olvidar que en nuestro país hay estados que durante ciertos periodos bien podrían ser clasificados como tigres asiáticos, conviviendo con entidades que sufren crisis económicas de proporciones similares a la griega. Por lo tanto, el problema no es que México no crezca, sino que crece a 32 pasos diferentes (Ríos, 2014).
Los resultados de esta investigación sugieren una analogía similar. México sí hace uso efectivo del conocimiento tecnológico para cambiar las tecnologías existentes y desarrollar nuevos productos y procesos, solo que dicha capacidad avanza a 7 pasos diferentes (7clusters estatales de capacidad tecnológica). Por lo tanto, para incrementar dichas capacidades es necesario un ejercicio de benchmarking, tomando como punto de referencia aquellos estados que están realizando un buen trabajo en materia de promoción de la innovación otorgando las condiciones proclives para ejecutarla. Fijarnos en el D.F., Nuevo León y Querétaro5 como casos de éxito quizá sea más provechoso que voltear la vista a Suiza, Reino Unido o Suecia6, dado que los primeros forman parte de nuestro contexto. Sin embargo, para la observancia de los primeros se requiere de diversos tipos y metodologías de investigación para analizar el tema.
Los hallazgos de la presente investigación enriquecen el debate y la discusión relativa a las capacidades de innovación tecnológica en México. Algunos de los resultados son convergentes con estudios previos; por ejemplo, el top 3 de estados con mayores capacidades de innovación y capacidades tecnológicas de infraestructura coincide con el top 3 presentado en el ranking nacional de ciencia, tecnología e innovación (FCCyT, 2014). Sin embargo, dado que la metodología y el enfoque de investigación son diferentes, se aprecia que la estratificación de estos 7clusters marca la pauta para reflexionar como generalmente se suele estratificar la innovación en 3 grupos7. No obstante, los resultados de la presente investigación sugieren la existencia de 4 grupos de estados (casi aislados) que muestran una dinámica eficiente y claramente diferente en materia de capacidad tecnológica en comparación con el resto de la república.
Resulta preocupante la situación principalmente de Chiapas, Guerrero y Oaxaca. Por su parte, los clusters5 y6 se ubican también en los cuadrantes negativos, y las entidades que se congregan en dichos clusters son consideradas estados en transición en inversión de CTI y economía del conocimiento (PECITI, 2014). Finalmente, los clusters del 1 al 4 presentan mejores condiciones en cuanto a sus capacidades tecnológicas; en este caso, los estados en consolidación resultaron únicamente D.F., Nuevo León, Querétaro y Jalisco. Derivado de ello, surge la interrogante de ¿por qué parece que la capacidad tecnológica se concentra en unos cuantos estados? ¿En qué medida esto depende de la ubicación? ¿Cómo se relaciona cada cluster con el desarrollo económico? ¿Cómo la creación y la acumulación de capacidades tecnológicas estatales impactan tanto en el nivel de vida como en la calidad de vida de los mexicanos? Preguntas que se abren como sugerencias de investigación y que podrían ser respondidas bajo diversas metodologías. Finalmente, se auguran buenas expectativas: según el PECITI (2014), se tiene planteado que GIDE/PIB para el año 2018 sea del 1%, cifra que impulsaría las capacidades de ciencia, tecnología e innovación. Sin embargo, una tarea pendiente es revertir que se privilegie el pensamiento mágico sobre el lógico científico, ya que, según la Encuesta sobre la Percepción Pública de la Ciencia y la Tecnología en México (Enpecyt, 2011), el 57.5% de los mexicanos considera que, debido a sus conocimientos, «los investigadores y científicos tienen un poder que los hace peligrosos». Para que los incentivos en materia de ciencia y tecnología funcionen debería cambiar dicha percepción, que repliegue en el aumento de nuestro acervo de recursos humanos dedicados a la investigación, ciencia y tecnología.
La encuesta se conoce como «datos blandos», y por lo general se obtiene de muestras de las encuestas (no de poblaciones enteras). Para el INEGI, la ESIDET-MBN 2012 es la primera encuesta especial en empresas con cobertura geográfica estatal; por lo tanto, la batería del año 2006 no emplea dicha variable.
La revisión por pares es responsabilidad de la Universidad Nacional Autónoma de México.
Para Chinaprayoon (2007), los usuarios de internet son un indicador de la difusión de nuevas tecnologías, mientras que el consumo de energía eléctrica y las líneas de teléfono indican la difusión de las viejas tecnologías.
Se espera que el crecimiento de la actividad económica y el ingreso derive en un aumento de la demanda de bienes de mayor complejidad o tecnológicamente avanzados (Cepal, 2007).
El test Student-Newman-Keuls es un test de comparaciones múltiples, permite comparar las medias de los niveles t de un factor después de haber rechazado la H0 de igualdad de medias mediante la técnica ANOVA. La prueba DHS de Tukey utiliza el estadístico del rango estudentizado para realizar todas las comparaciones por pares entre los grupos y establece la tasa de error por experimento como la tasa de error para el conjunto de todas las comparaciones por pares. La prueba Waller-Duncan utiliza la aproximación bayesiana. Esta prueba de rango emplea la media armónica del tamaño de la muestra cuando los tamaños muestrales no son iguales (Martín, Cabero y de Paz, 2008).
El D.F., en nuestro estudio, resultó la entidad puntera en capacidades tecnológicas, mientras que Nuevo León y Querétaro pertenecen al segundo cluster.
Países de mejor ranking según WIPO (2014).
Clusters A, B, C en el ranking nacional de ciencia tecnología e innovación (FCCyT, 2014); estados en construcción, estados en transición y estados en consolidación según el PECITI, 2014-2018.