










El objetivo de esta investigación es analizar el funcionamiento del mercado de trabajo colombiano e identificar algunas fricciones que lo afectan a nivel agregado, departamental y de agentes, a través de la estimación de la función de emparejamiento, usando los datos mensuales del Servicio Público de Empleo (SPE) de febrero a noviembre de 2014. Este trabajo es la primera aproximación a la estimación de la función de matching del mercado laboral colombiano. De la comparación entre modelos estimados se concluye que: 1)las fricciones son mayores para las firmas que para los desempleados; 2)la función estimada por los métodos tradicionales está sesgada; 3)existe evidencia de retornos constantes a escala; 4)las interacciones se producen primero en las regiones y con menor relevancia por las características de los agentes; 5)el modelo stock-flow no se ajusta en varias estimaciones, y 6)el modelo más robusto es el lineal dinámico.
The objective of this research is to analyze the Colombian labor market and to identify some frictions that affect the aggregate, departmental and agent's levels, through the estimation of a matching function, using monthly data from the Public Employment Service (SPE), from February to November 2014. This research is the first approach to estimating the matching fucntion of the Colombian labor market. Comparison between models concludes that: (i)frictions are higher for firms than for the unemployed; (ii)there is a bias in the estimation of the matching function; (iii)there is evidence of constant returns to scale; (iv)interactions between supply and demand for labor occur first in the regions and are less relevant because of the characteristics of the agents; (v)the stock-flow model does not adjust to several estimates, and (vi)the more robust model corresponds to the dynamic linear model.
Los investigadores en temas laborales han intentado resolver la pregunta de cómo mejorar los resultados del mercado de trabajo a través del desarrollo de teorías, instrumentos de medición y análisis empírico. Una de las teorías que ha tomado relevancia y con escaso análisis empírico en Colombia proviene de los modelos de emparejamiento o matching entre la oferta y la demanda de trabajo. Los estudios de la función de matching surgen a partir de la década de los setenta y se basan en una función que condensa los procesos de intercambio entre las empresas y los trabajadores y produce emparejamientos o contrataciones. La mayoría de países para los que se ha estimado la función son países desarrollados con centros de empleo. Los métodos de estimación de la función de emparejamiento han evolucionado, así como el registro de la información para estimarla, y esto ha permitido hacer comparaciones entre modelos, evaluaciones de políticas activas de trabajo y un análisis más riguroso de los resultados.
En un periodo reciente se ha construido la curva de Beveridge para Colombia (Becerra, 2015), que es la primera evidencia de la función de emparejamiento, pero no se han estimado modelos de matching debido a la ausencia de información. Mientras la curva requiere datos de vacantes y desempleados, la función de emparejamiento necesita, además, registros de las nuevas contrataciones como variable explicativa. Por un lado, en Colombia, los datos de la tasa de desempleo están disponibles desde mediados de los años setenta, por los menos para las cuatro principales ciudades. Por otro, la información de las vacantes ha sido escasa y solo hay dos fuentes: la primera es la serie construida por Álvarez y Hofstetter (2013) a partir de clasificados de vacantes laborales desde 1960 hasta 2010 (Uribe, 2012). La segunda fuente, que no ha sido analizada, es la que ofrece el Servicio Público de Empleo (SPE), creado como una red de prestadores en el año 2013, la cual brinda también los registros de las nuevas contrataciones en cada momento del tiempo.
En Colombia, el SPE se creó como una red que se encarga de los servicios de gestión y colocación de empleo a nivel nacional, departamental y municipal. Esta herramienta atiende a la necesidad de integración e implementación de un sistema de gestión y colocación de empleo que logre un mejor funcionamiento del mercado de trabajo y la efectiva protección y atención a los desempleados (Carrasco, 2013). Los datos que recolecta el SPE acerca del registro de vacantes, buscadores de empleo y colocaciones abren la puerta para estimar la función de matching y así evaluar qué políticas permiten incrementar las contrataciones y estudiar cuáles son los posibles elementos estructurales que están disminuyendo el emparejamiento entre la oferta y la demanda de trabajo. La utilidad de este análisis radica en que la dinámica del desempleo impone el reto de lograr una mejor articulación entre la oferta y la demanda de trabajo. Este proceso implica la formación y recalificación profesional que pretende solucionar no solo el desempleo friccional sino el desempleo estructural.
El objetivo de esta investigación es analizar el funcionamiento del mercado de trabajo colombiano e identificar algunas fricciones que lo afectan a nivel agregado, departamental y de agentes (características de las vacantes y desempleados), a través de la estimación de la función de matching, usando los datos mensuales del SPE de febrero a noviembre de 2014. Esta investigación es la primera aproximación a la estimación de la función de matching del mercado laboral colombiano. Es importante especificar que la función de emparejamiento permite: a)estimar los rendimientos a escala del mercado laboral y el tamaño de las externalidades (o congestión) entre las firmas y los buscadores de empleo; b)calcular la probabilidad de que un desempleado salga del desempleo y de que una vacante se ocupe; c)calcular el tiempo promedio de duración que tarda un desempleado en encontrar trabajo y una firma en encontrar un empleado; d)identificar los posibles elementos en las características de las vacantes y los desempleados que disminuyen o aumentan el emparejamiento, y e)caracterizar estas fricciones a nivel departamental. Esta aproximación es el inicio de futuras investigaciones que, además de hacer uso de la base de datos del SPE, con un periodo de tiempo más largo y mayor detalle a nivel micro, permitan usar métodos más robustos de estimación.
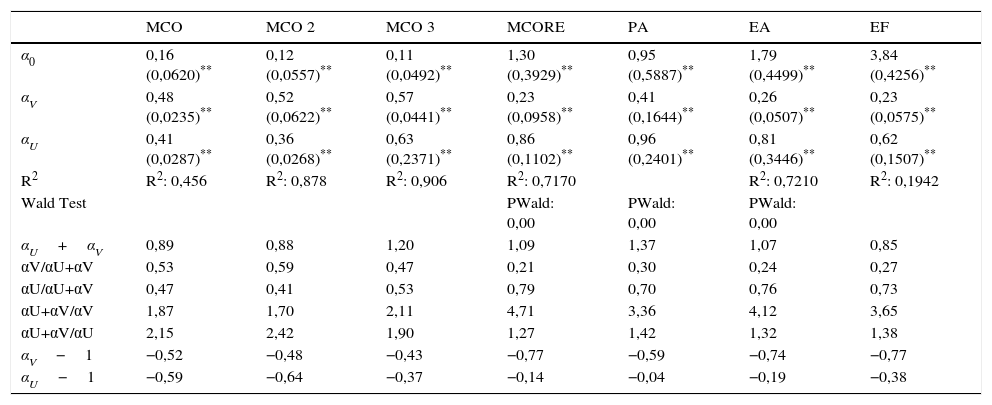
Para lograr el objetivo, se estiman la función de emparejamiento tradicional y el ajuste del modelo stock-flow. La primera se estima usando el método de Mínimos Cuadrados Ordinarios (MCO), Mínimos Cuadrados Ordinarios con errores estándar robustos (MCORE), Population Averaged (PA), Efectos Aleatorios (EA) y Efectos Fijos (EF). El modelo stock-flow se estima por MCO, PA y MCORE. Finalmente, se busca corregir de forma más apropiada el sesgo en los coeficientes causado por la endogeneidad entre las vacantes y los desempleados mediante el modelo lineal dinámico de datos panel propuesto por Arellano y Bover (1995) y Blundell y Bond (1998), que permite incorporar los rezagos de las vacantes y los desempleados como aproximaciones de las variables flujo del modelo stock-flow. Aunque el presente estudio tiene un número pequeño de datos panel (mensuales desde febrero a noviembre de 2014), el modelo lineal dinámico es adecuado para este número de datos y se encuentra evidencia en la literatura de trabajos que con la misma estructura han estimado la función como punto de partida.
De la comparación entre modelos se concluye para el caso colombiano que: 1)las fricciones son mayores para las firmas que para los desempleados, es decir, para un desempleado es más fácil encontrar un empleo que para una firma encontrar un trabajador que cumpla sus requerimientos; 2)la función de emparejamiento tradicional estimada por los métodos de datos panel lineal presenta un sesgo que sobreestima la participación en el emparejamiento de las vacantes y subestima la de los desempleados; 3)para el mercado laboral nacional agregado se encuentra evidencia de retornos constantes a escala, que implica complementariedad entre las acciones de las firmas y los trabajadores, con incompatibilidades fuertes en ciertas regiones; 4)las interacciones entre la oferta y la demanda de trabajo se producen primero en las regiones y con menor relevancia debido las características de los agentes (sector económico u ocupación); 5)los departamentos que inciden menos en el emparejamiento nacional son Arauca, Guainía, Guaviare, Amazonas y Sucre, y las fricciones más altas se presentan en las regiones de Vichada y Vaupés; 6)en el modelo stock-flow las variables stock no resultan significativas y tampoco se obtienen los resultados esperados por la estimación MCO, PA y MCORE, y 7)el modelo más robusto es el modelo lineal dinámico, el cual brinda solución al problema de endogeneidad, permite introducir trabajadores y desempleados stock y algunas variables que caracterizan a las vacantes y desempleados.
Los resultados del modelo lineal dinámico muestran: 1)las externalidades positivas son mayores para los desempleados que para las firmas; 2)la importancia de los desempleados y vacantes stock en el emparejamiento; 3)algunas incompatibilidades para las firmas que solicitan trabajadores con poca experiencia laboral y para los desempleados que tienen mayor nivel educativo, y 4)que existe heterogeneidad inobservada en los mercados de trabajo de los departamentos que afecta el emparejamiento.
El trabajo se organiza en seis partes de la siguiente manera: la primera sección presenta la motivación de esta investigación; la segunda muestra el marco teórico conceptual del desempleo de equilibrio a partir del modelo de emparejamiento propuesto por Pissarides (1990) y las consecuencias de la inclusión de la búsqueda de empleo a través de una agencia con base en el modelo de Pissarides (1979). Esta sección revisa los trabajos teóricos y empíricos más destacados, así como algunos resultados de la estimación de la curva de Beveridge para Colombia. La tercera sección describe el funcionamiento del SPE en Colombia. La cuarta expone la metodología a utilizar a partir de datos panel para estimar el modelo de emparejamiento agregado, el emparejamiento por departamentos, el modelo stock-flow y el modelo de panel dinámico. Después se describe la base de datos y se interpretan los resultados de las estimaciones. Por último, se muestran las conclusiones.
2Marco teórico conceptualUno de los avances más importantes para obtener las funciones de emparejamiento lo adelantó Beveridge; para este autor, analizar las fricciones del mercado laboral partía de la evidencia de que la economía no muestra un comportamiento de pleno empleo. Para Beveridge el pleno empleo significaba, primero, tener siempre más vacantes de trabajo que personas desempleadas (Wasson, 1945), y además significaba contar con trabajos con un salario justo y localizados, donde las personas desempleadas razonablemente los pudieran tomar. Esto se traducía en que el rezago normal entre perder un trabajo y encontrar otro debía ser muy corto (Smithies, 1945).
A partir de la década de los setenta el concepto clave en el análisis del mercado de trabajo fue la generación de modelos que incorporaran las fricciones del mercado en la función de emparejamiento. Los primeros precursores de estos modelos aparecen en respuesta a la demostración de los precios de monopolio de Diamond (1971) (Petrongolo y Pissarides, 2001). Entre los primeros trabajos con una aproximación a la función de emparejamiento están Phelps (1968), Mortensen (1970) y Holt (1970), quienes hacen a un lado la distribución de salarios e incorporan las decisiones de búsqueda. El trabajo teórico de mayor referencia es el de Pissarides (1979), que deriva la misma forma funcional de la función de emparejamiento de trabajo y la combina con los retornos constantes a escala, cuando hay dos métodos de búsqueda.
2.1Modelo matching para el mercado laboralLa función de matching condensa la tecnología de intercambio entre los agentes que ponen sus ofertas de trabajo, leen periódicos y revistas, van a las agencias de empleo y movilizan sus redes locales que eventualmente les dan emparejamientos o contrataciones productivas (Pissarides, 1990). El proceso complejo de intercambio se sintetiza en una función agregada que produce el número de trabajos formados o contrataciones, en cualquier momento del tiempo, en términos del número de trabajadores buscando trabajos, el número de firmas buscando trabajadores y un número pequeño de otras variables (Petrongolo y Pissarides, 2001). De esta manera, captura los efectos en el equilibrio del mercado de la interacción entre la oferta y la demanda de trabajo y permite modelar las fricciones y la información imperfecta entre diversas actividades, diversos trabajos, la incertidumbre en la ubicación y la habilidad para sustituir a los trabajadores (Pissarides, 1990).
La primera función de emparejamiento debe su origen al problema analizado por los teóricos de la probabilidad en el que se escoge aleatoriamente pelotas en una urna. Las firmas juegan el rol de urnas y los trabajadores el rol de bolas, y una urna empieza a ser productiva cuando hay una bola. Aunque haya el número exacto de urnas y bolas, debido a los problemas de coordinación, una ubicación aleatoria de las bolas y las urnas puede no emparejar todos los pares posibles exactamente. Algunas urnas pueden terminar con muchas bolas mientras que otras con ninguna (Petrongolo y Pissarides, 2001).
Este modelo muestra que el desempleo y las vacantes pueden existir en el equilibrio del mercado de trabajo, debido a que en el proceso de búsqueda de los desempleados y firmas se presentan fricciones que impiden que exista claridad inmediata. Las externalidades de búsqueda juegan un rol importante en los resultados, es por esto que el costo de búsqueda se traduce no solo en un mecanismo de asignación, sino que para cada precio hay una probabilidad positiva de que la vacante sea ocupada o de que un trabajador desempleado encuentre trabajo (Pissarides, 1990).
2.1.1Modelo matching simpleEl modelo teórico que se resume en este artículo es el propuesto por Pissarides (1990). En este modelo hay L trabajadores en el mercado de trabajo, u es la tasa de desempleo, v es el el número de vacantes como fracción de la fuerza de trabajo (tasa de vacantes). Hay uL trabajadores y vL vacantes. El número de trabajos emparejados por unidad de tiempo está dado por:
La función de emparejamiento es monótonamente creciente en uL y vL, cóncava y homogénea de grado uno.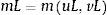
En esta función el cálculo del tiempo promedio, o tasas de transición promedio, de un estado de búsqueda a un estado de ocupación juegan un rol importante en la eficiencia del equilibrio. Lo anterior debido a que el tiempo promedio que le toma a una firma encontrar a un trabajador depende de qué hacen los buscadores de empleo antes de que se encuentren con la firma. De forma similar, la probabilidad de que un desempleado encuentre trabajo depende de lo que hace la firma para la contratación, por ejemplo si publican la vacante o no y en dónde la publican. Generalmente, el equilibrio de búsqueda es ineficiente porque cuando las firmas y los trabajadores se encuentran, los costos de búsqueda, los cuales afectan las probabilidades de transición, son costos hundidos.
La tasa a la cual se ocupan las vacantes está dada por
Donde θ=v/u es el número de vacantes por trabajador desempleado. La probabilidad de que sea ocupada una vacante está dada por qθΔt, que es la probabilidad de que durante un pequeño intervalo de tiempo un trabajo sea emparejado con un trabajador desempleado Por lo tanto, la duración media de una vacante es 1/qθ.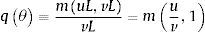
La tasa a la cual un desempleado encuentra empleo está dada por:
La probabilidad de que un trabajador desempleado encuentre trabajo está dada por θqθΔt. La duración media del desempleo es 1/θqθ. Entre más vacantes de trabajo haya, más rápido los trabajadores desempleados van a encontrar trabajo, más grande es θ. En cambio, las firmas pueden ocupar una vacante más rápido cuando θ es más pequeño; en otras palabras, cuando hay pocas vacantes relativas al número de trabajadores disponibles.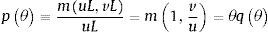
Cada buscador de trabajo y cada vacante de trabajo genera externalidades de búsqueda: un buscador de trabajo causa una externalidad positiva para la firma pero una externalidad negativa para los demás buscadores de trabajo. Cada buscador adicional produce un incremento en la probabilidad 1−θqθΔt de que otro buscador no encuentre una vacante. Al mismo tiempo incrementa la probabilidad qθΔt de que la vacante pueda ser ocupada. Cada vacante adicional produce un incremento en la probabilidad 1−qθΔt de que otra vacante no sea ocupada. Al mismo tiempo incrementa la probabilidad θqθΔt de que un trabajador encuentre una vacante.
El flujo dentro del desempleo (destrucción de trabajo) se da por un choque (una reducción en la productividad o baja el precio relativo de los bienes, entre otros) y hace que no sea beneficioso para la firma ofrecer trabajo. Este tipo de choque ocurre con una probabilidad λ. La probabilidad de que un trabajador se convierta en un desempleado en un pequeño periodo de tiempo está dada por λΔt. Sin crecimiento económico (L constante), los trabajadores que entran al desempleo en un pequeño intervalo de tiempo Δt es λ1−uLΔt.
El flujo de salida del desempleo (creación de trabajo) se presenta cuando una firma y un buscador de empleo se encuentran y concuerdan la forma de emparejar una negociación del salario. El número de buscadores de trabajo que encuentran trabajo está dado por θqθuLΔt.
2.1.2Desempleo de equilibrioLa evolución del desempleo promedio está dada por la diferencia entre las entradas y salidas del desempleo. En el equilibrio de estado estable la media de la tasa de desempleo es constante:
El equilibrio de desempleo depende de las dos probabilidades de transición de creación y destrucción de empleo.2.1.3Las firmas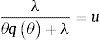
Los productos de las firmas pueden ser vendidos en el mercado de trabajo a un precio constante p>0; este precio representa la productividad de un trabajador. Cuando un trabajo está disponible la firma contrata a un trabajador con un costo fijo pc>0 por unidad de tiempo. El costo de contratar es proporcional a la productividad del trabajador: entre más productivo sea, más costoso es contratarlo. Sea J el valor presente descontado de la ganancia esperada de un trabajo ocupado y V el valor presente descontado del beneficio esperado de una vacante de trabajo. El valor de un trabajo cuando una firma entra al mercado es rV, donde r es una tasa de descuento exógena. En el equilibrio las rentas de una vacante son cero debido a la libre entrada al mercado, por lo tanto, V=0, y la ganancia esperada de un nuevo trabajo es igual al costo esperado de contratar un trabajador:
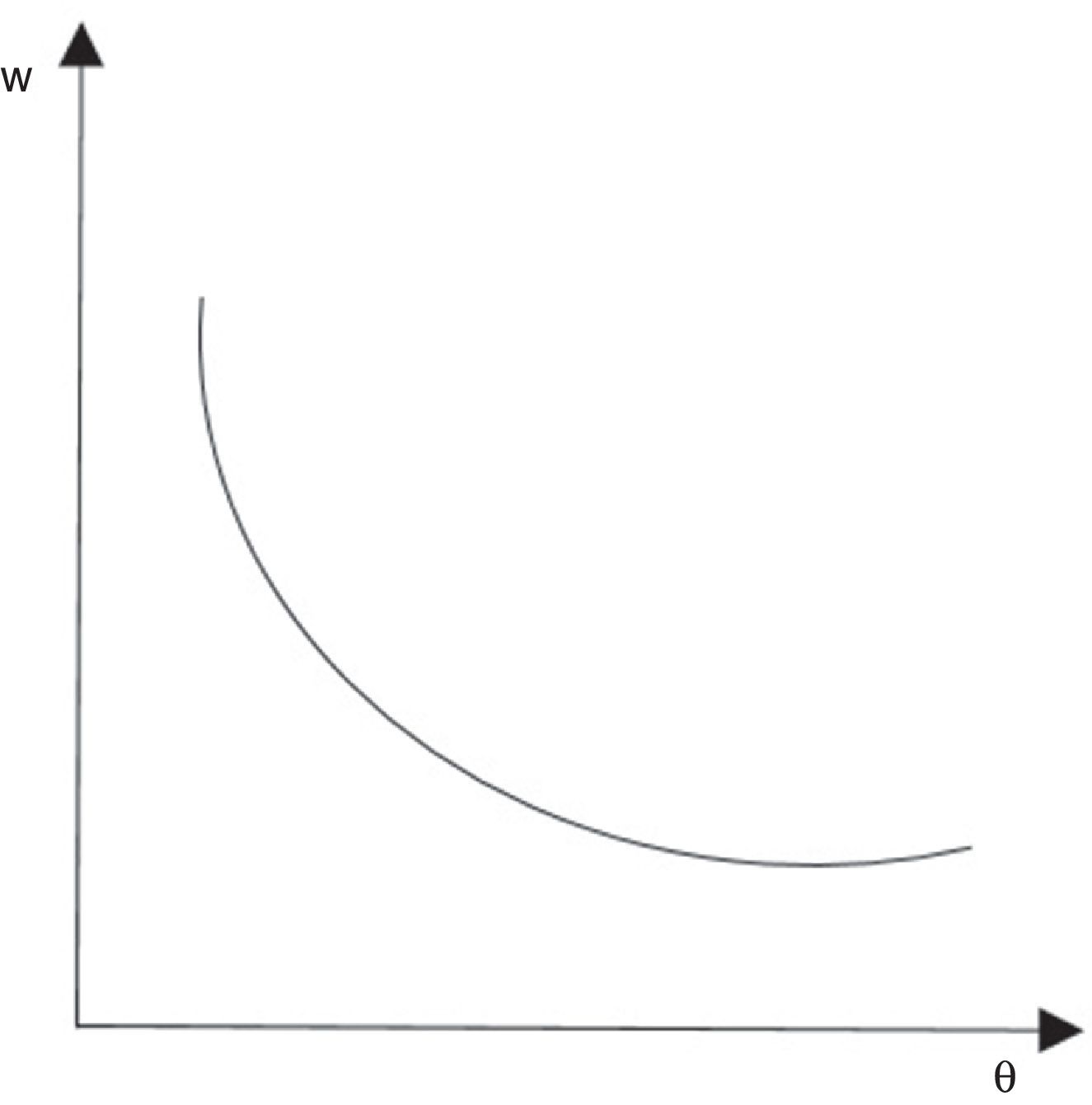
Esta ecuación se denomina la curva de creación de trabajo y muestra una relación negativa entre θ=v/u y el salario w (fig. 1). La pendiente descendente de la curva de demanda es llamada la condición de creación de trabajo.2.1.4Trabajadores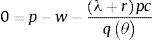
.")
En este modelo la oferta de la fuerza de trabajo es constante. Además, la intensidad de búsqueda de cada trabajador es fija, todos los trabajadores tienen la misma productividad p. Cada trabajador gana w cuando es empleado y z cuando está buscando un trabajo, cada uno está buscando empleo o está empleado. z es algún seguro de desempleo o los retornos por ser autoempleado, incluye el retorno real imputado por las actividades de ocio.
Siendo U el valor presente descontado del flujo del ingreso esperado de un trabajador desempleado y W el valor presente descontado del ingreso esperado de un trabajador empleado, el flujo del ingreso esperado por un trabajador es rU, que es la compensación mínima que un trabajador desempleado requiere para dejar de buscar o el salario de reserva. El retorno neto del trabajador es W−U. rW no es igual a w porque refleja el riesgo de estar desempleado. El salario de reserva está determinado por:
Los trabajadores permanecen en sus trabajos siempre y cuando W≥U; la condición necesaria y suficiente para que esto se cumpla es w≥z. Como w>z, el trabajador empleado tiene mayor ingreso permanente que el trabajador desempleado con el descuento. Si el descuento r=0, los trabajadores desempleados no están peor que los trabajadores empleados. Esto se da porque la ubicación de empleos es aleatoria y cada trabajador es empleado alguna vez (es un horizonte de tiempo infinito).2.1.5La determinación del salario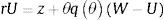
En el equilibrio los trabajadores ocupados producen un retorno total que es estrictamente más grande que la suma de los retornos esperados de búsqueda de una firma y la búsqueda de un trabajador. Un trabajo ocupado produce una renta económica pura que es igual a la suma de los costos esperados de búsqueda de una firma y los costos de búsqueda de un trabajador. Se asume que se comparte la renta de monopolio de acuerdo con la solución del problema de negociación de Nash. Como todos los trabajadores y los trabajos son idénticos en este modelo, el salario es uniforme.
Para un salario w dado, el retorno esperado de la firma por el trabajo, J, satisface la siguiente ecuación:
Para el trabajador es: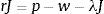
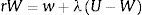
El retorno neto de un trabajo emparejado para la firma es J−V, y para el trabajador, W−U. La solución de negociación de Nash determina un valor que maximiza el producto ponderado de los retornos netos del trabajador y de la firma en un emparejamiento de trabajo. Para realizar el emparejamiento el trabajador renuncia a U por W y la firma renuncia a V por J. Por lo tanto, la tasa de salario satisface la ecuación:
Siguiendo el desarrollo de Pissarides (1990), de las condiciones de primer orden del problema y reemplazando en el salario de reserva se obtiene que:Donde β es la participación del trabajo en el total de oferta que un trabajo ocupado genera. pcθ es el promedio del costo de contratar por cada trabajador desempleado (pcθ=pcvu; pcv es el costo total de contratación de toda la economía).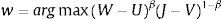

Cuando el ajuste del mercado es alto, reflejado en θ, es decir, hay un número pequeño de trabajadores respecto al número de vacantes, los trabajadores tienen una posición de negociación que ejerce un efecto positivo en los salarios. Esto produce una relación creciente entre θ y w que se representa en la curva de salario (fig. 2).
2.1.6Equilibrio de estado estable.")
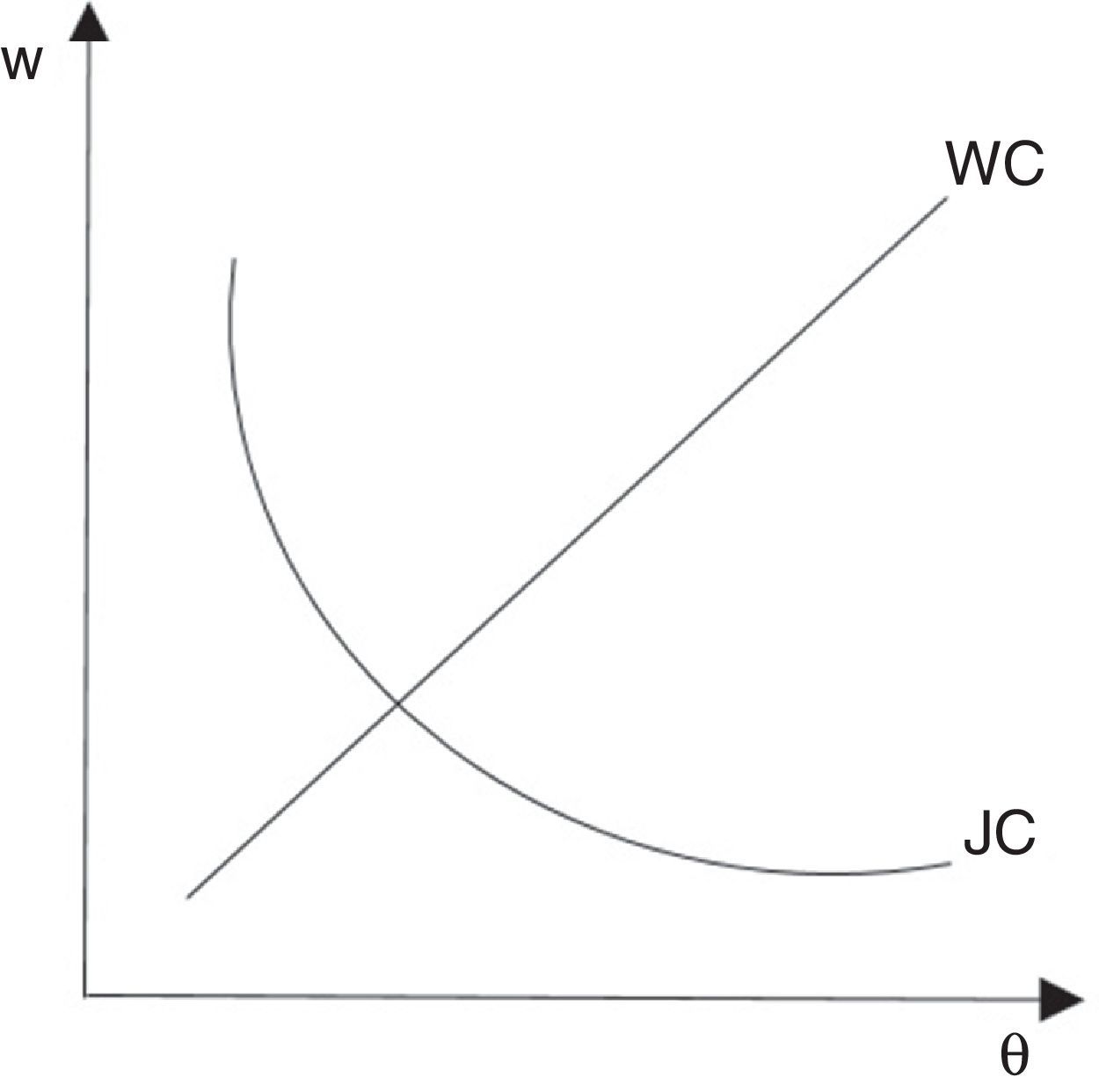
Si u y θ son conocidos, el número de trabajos ocupados 1−uL y el número de vacantes θuL también es conocido. Los resultados que satisfacen la condición de equilibrio provienen de la tasa de desempleo de equilibrio (ecuación 2.4), la curva de creación de empleo (ecuación 2.5) y la tasa de salario (ecuación 2.8). El equilibrio θ,w es único y es la intersección entre las dos curvas y se asume independiente del desempleo (fig. 3).
2.1.7La curva de Beveridge
Beveridge motivó el análisis de la relación entre el desempleo y el número de vacantes. La relación negativa registrada entre el comportamiento de estas dos variables significa que en los momentos en que aumenta el número de vacantes el desempleo es más bajo, mientras que en los periodos de recesión el desempleo se acentúa y las empresas tienen menor número de vacantes (Uribe, 2012).
La curva de Beveridge es una relación de equilibrio donde existen personas desempleadas y vacantes, es decir, se relacionan las entradas y salidas del desempleo (Petrongolo y Pissarides, 2001). El emparejamiento entre una vacante y un desempleado que se explica en la función de matching es una salida del desempleo en la curva de Beveridge. De manera que la eficiencia del emparejamiento determina la posición de la curva vacantes-desempleo (Uribe, 2012). Si se encuentra más alejada del origen, la coordinación entre la oferta y demanda de trabajo presenta más fricciones, que se pueden deber a las diferencias de habilidades requeridas y ofertadas, a la localización de las vacantes y de los posibles trabajadores, entre otras incompatibilidades.
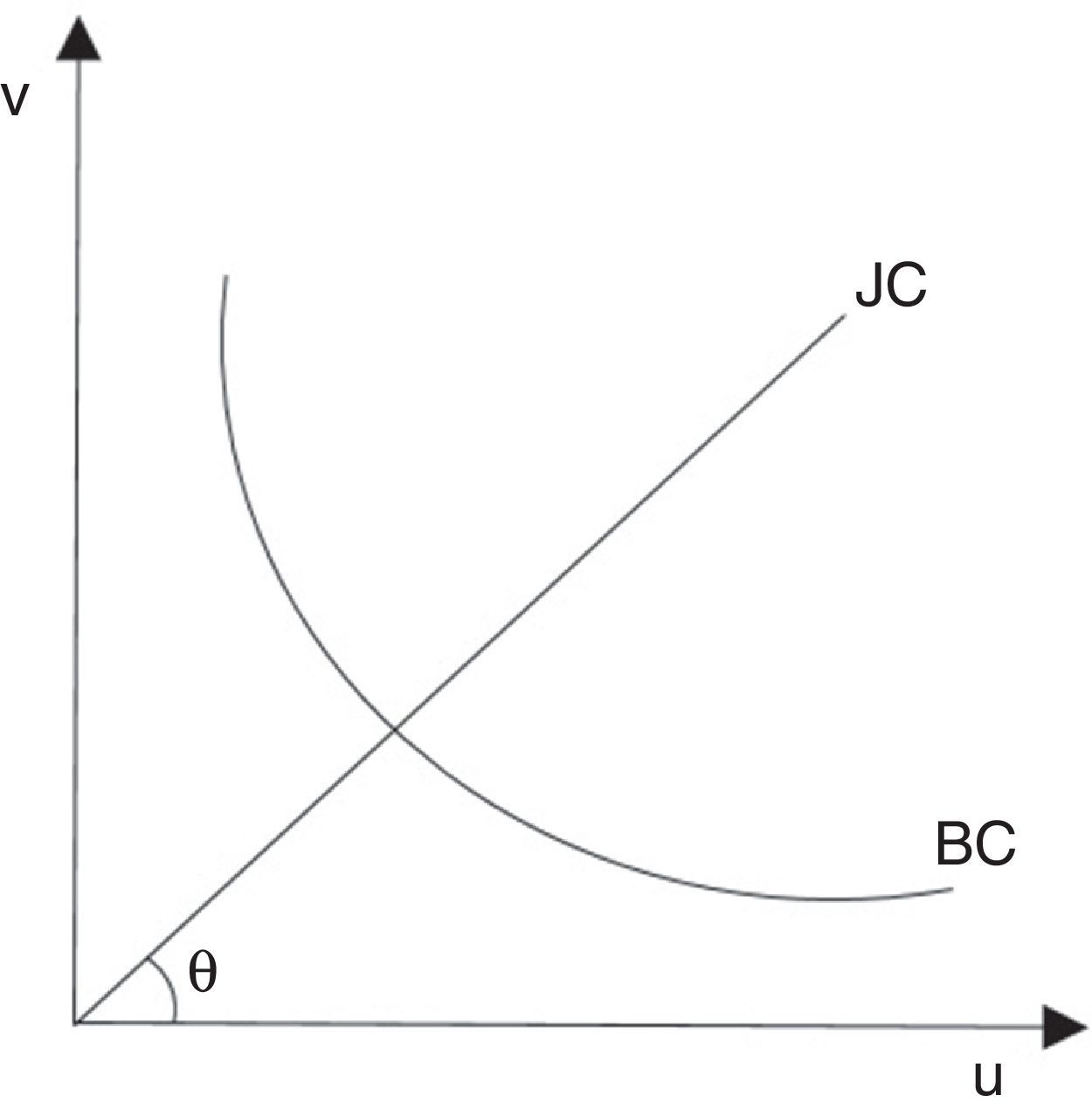
Para analizar la curva de Beveridge en el plano de vacantes y desempleo, primero se sustituyen los salarios de p−w−λ+rpcqθ=0 en w=1−βz+βp1+pcθ y se obtiene la curva de creación de empleo (JC), que es una línea que parte del origen con pendiente θ.
La curva de Beveridge es la condición de estado estable u=λθqθ+λ, es convexa en el origen por las propiedades de la tecnología de emparejamiento: cuando hay más vacantes el desempleo es menor porque el desempleado encuentra trabajo más fácilmente. Los rendimientos decrecientes a escala para los inputs individuales en el emparejamiento generan la forma convexa de la curva. Las vacantes y el desempleo de equilibrio son la única intersección entre la línea de creación de trabajo y la curva de Beveridge (fig. 4).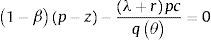

Este modelo muestra como la eficiencia de la función de matching determina el equilibrio entre las vacantes y los desempleados en la economía. En este equilibrio está involucrado un proceso de maximización de los trabajadores y las firmas, así como la negociación del salario.
2.2Modelo matching con agencia de empleo y búsqueda aleatoria y el rol de la agencia de empleoEl modelo de Pissarides (1979) incorpora a las agencias de empleo en un mercado laboral imperfecto. También analiza el efecto del comportamiento de los trabajadores y las firmas en el equilibrio del mercado de trabajo, donde los desempleados y las firmas pueden buscar aleatoriamente o registrándose en una agencia. Pissarides (1979) estudia las implicaciones de política que las agencias de empleo deben adoptar para mejorar los resultados del mercado.
Para analizar el rol de los centros de empleo, el modelo teórico examina la estática comparativa de los parámetros bajo su control (compensación a los desempleados, costo de las firmas por usarlas, y las tarifas cobradas por la agencia). Pissarides (1979) concluye que si el gobierno desea incrementar los emparejamientos de empleo y reducir el desempleo de equilibrio, lo debe hacer motivando la búsqueda fuera de las agencias de empleo a las firmas y a los desempleados y no ofreciendo incentivos a las empresas para registrar sus vacantes. Se puede motivar la búsqueda privada a través de subsidios a la publicidad, ofreciendo compensación a los trabajadores desempleados de acuerdo con los contactos realizados con los potenciales empleadores fuera de la agencia, reduciendo los beneficios del desempleo y cargando una tarifa por el uso de los servicios en el centro de empleo. De acuerdo con el modelo, las firmas responden abriendo más vacantes y se puede tener una menor tasa de desempleo y mayor producto.
Por otro lado, se tienen mayores beneficios del registro completo de los trabajadores desempleados en los centros de empleo. En el modelo esta es una solución de esquina donde se contribuye más a los emparejamientos con el registro completo de los desempleados. Estos resultados pueden no ser válidos en dos casos extremos. En el primero si el incentivo a los trabajadores de la búsqueda fuera de la agencia induce a abandonar el registro, y el segundo se presenta si todos los trabajadores desempleados están usando los dos métodos de búsqueda (Pissarides, 1990).
2.3Trabajos empíricos2.3.1Datos agregados y retornos a escalaEntre los artículos con más reconocimiento en la estimación de la función de emparejamiento están los trabajos de Pissarides (1986) y Layard (1991) para Inglaterra, el trabajo de Blanchard y Diamond (1989) para Estados Unidos y el de Mumford y Smith (1999) para Australia. Así como sucede en la función de producción de la economía, en la función de emparejamiento también se pretende determinar qué tipos de rendimientos a escala existen. La mayoría de análisis teóricos asumen retornos constantes a escala para el matching; sin embargo, determinarlo es un problema empírico (Coles y Smith, 1995). Las interacciones del mercado generan externalidades o «congestión» de búsqueda de acuerdo con el número de participantes en el mercado, por ello se examina cómo se comporta la tasa de emparejamiento al aumentar el número de personas que buscan trabajo y firmas que ofrecen vacantes.
El ejemplo que brindan Coles y Smith (1995) ilustra la importancia de los retornos a escala: se supone un proceso de matching en el que un hombre y una mujer a ciegas deambulan aleatoriamente en un campo hasta que se encuentran. Si luego se supone que se encuentran 1.000 hombres y 1.000 mujeres a ciegas en el mismo campo, ¿se puede esperar que la tasa a la que se encuentran cada miembro del sexo opuesto sea constante o mayor? Si es mayor, la tasa de emparejamiento debe ser creciente con el aumento en el número de participantes. En cambio, si hay 1.000 campos (del mismo tamaño) con un hombre y una mujer en cada uno, la tasa total de emparejamiento es exactamente 1.000 veces, no hay interacción entre estos jugadores. Para Coles y Smith (1995) hay varias conclusiones relevantes de este experimento: 1)Los retornos crecientes de emparejamiento ocurren solo si hay interacción entre los jugadores en el mercado. Además, Diamond (1982) muestra que es posible tener múltiples equilibrios que están en el rango de Pareto, donde la menor tasa de desempleo es el equilibrio más deseable (Coles y Smith, 1995). 2)Los retornos constantes a escala implican tasas de desempleo constantes en el crecimiento de estado estable y un equilibrio único.
El análisis empírico de los rendimientos a escala encierra el problema de agregación, ya que si es la densidad lo que importa, no el número de desempleados y las vacantes, es más razonable analizar el emparejamiento en cada «campo» en vez de en toda la región; por lo tanto, la agregación alrededor de los mercados donde no hay interacción puede sesgar los retornos agregados estimados hacia abajo (Coles y Smith, 1995). En el estudio práctico que se realiza con datos agregados se asume que el mercado es uno solo; por lo tanto, los datos agregados estarían sesgados a retornos constantes a escala, lo cual puede ser refutable si se demuestra que el emparejamiento se lleva a cabo de forma heterogénea en cada campo. Los resultados empíricos muestran funciones de emparejamiento que revelan rendimientos constantes o un poco decrecientes a escala en economías desarrolladas, mientras los resultados son más diversos en las economías en transición (Dmitrijeva y Hazans, 2007).
Los retornos de la función permiten analizar las externalidades que genera la interacción en el mercado de trabajo. Si se define la elasticidad con respecto al desempleo en la función de matching como αU y la elasticidad con respecto a las vacantes como αV, la suma de estas elasticidades (αU+αV) son los rendimientos a escala. De igual manera, αU mide la externalidad positiva entre trabajadores y αU−1 mide la externalidad negativa (congestión) causada por un trabajador desempleado a otro trabajador desempleado. Análogamente, αV es una medida de la externalidad positiva causada por la firma en la búsqueda por trabajadores y αV−1 mide la congestión entre las firmas. Mayor elasticidad implica menos congestión y más externalidades positivas (Petrongolo y Pissarides, 2001).
Si hay retornos crecientes a escala de emparejamiento (αU+αV>1) debe haber más de un equilibrio por las fuertes externalidades positivas: en un equilibrio las firmas y los trabajadores ponen más esfuerzo en la búsqueda, lo cual justifica inputs más grandes; en el otro, el esfuerzo es menor con retornos más bajos, menor tasa de emparejamientos y mayor desempleo (Petrongolo y Pissarides, 2001). A partir de las elasticidades de las vacantes y los desempleados de cada modelo es posible analizar el tipo de rendimientos que presenta la función de emparejamiento así como estimar las tasas de transición: la probabilidad de que una vacante sea ocupada (qθΔt) y de que un desempleado encuentre trabajo (θqθΔt) y calcular la duración media y la congestión tanto de las vacantes (1/qθΔt) como de los desempleados (1/θqθΔt) (ver ecuaciones 2.2 y 2.3).
2.3.2Datos panelEn respuesta a los problemas de agregación que tienen la función de emparejamiento, el análisis sectorial ha tenido como objetivo estudiar las diferencias en los distintos mercados de trabajo. Por ejemplo, para probar si el sesgo de agregación regional genera retornos constantes a escala, Coles y Smith (1995) estiman la función de matching con datos de panel de desempleo, vacantes y colocación de empleo a nivel de ciudades en el Reino Unido. Como resultado obtienen estimaciones que son virtualmente idénticas a las de Blanchard y Diamond (1994) a nivel agregado y encuentran evidencia de retornos constantes a escala. Al mismo tiempo documentan las contribuciones de variables específicas demográficas y por ciudades: la tasa de matching incrementa en los pueblos donde hay mayor población joven y decrece con una mejor calificación de la población. Este resultado les permite dar una intuición acerca de la calidad de los emparejamientos teniendo en cuenta que los salarios están relacionados positivamente con el tamaño de la ciudad. Por lo tanto, ciudades con menores tasas de emparejamiento usualmente eran más grandes y con mejores salarios. Los autores concluyen que el beneficio de buscar en un mercado más denso puede tomar la forma de una mayor calidad de emparejamiento en vez de una tasa de emparejamiento más rápida.
Como solución al sesgo por agregación en las funciones de matching estándar se ha hecho uso del modelo de panel dinámico estimado por el método generalizado de momentos (MGM). Entre ellos, Hujer y Zeissy (2005) realizan un análisis empírico de los datos regionales de los centros de empleo del Este de Alemania para el periodo de mayo de 2003 a diciembre de 2004. Obtienen estimadores consistentes por medio de un modelo de datos panel dinámico MGM y evalúan el impacto en el tiempo de la política activa de trabajo denominada «Job Creation Schemes». Con este mismo método, Borowczyk-Martins, Jolivet y Postel-Vinay (2013) estiman la función por MGM para Estados Unidos, y demuestran que este estimador no solo es robusto, sino que también evita la necesidad de detectar cambios estructurales de forma visual. El sesgo en los coeficientes tendía hacia abajo, es decir, que por MGM los coeficientes son positivos y más grandes. En la misma línea de trabajo, Agovino (2015) propone una función de matching para las personas con discapacidad usando datos panel de 20 regiones de Italia durante 2006 a 2011. Así, implementa un modelo dinámico MGM y muestra que existen efectos de congestión entre los desempleados discapacitados en el mercado regional, debido a un exceso de la oferta de trabajo con respecto a las vacantes disponibles.
2.3.3Stock-flowEl modelo de emparejamiento stock-flow flexibiliza el supuesto de oferta y demanda de trabajo homogénea y diferencia una vacante stock, la cual ya se encontraba participando en el mercado en un periodo dado, y una vacante flujo, la cual es una vacante nueva. Asimismo, distingue entre un desempleado que busca trabajo flujo y un desempleado stock. Bajo este supuesto, el stock de trabajadores al principio del periodo puede no emparejar con el stock de vacantes porque ambos fueron participantes en el mismo proceso de emparejamiento. Por lo tanto, si tras una primera ronda de búsqueda un desempleado no consigue emparejarse con las vacantes stock, en las siguientes rondas dirigirá su búsqueda hacia las nuevas vacantes que vayan entrando en el mercado (Álvarez de Toledo, Núñez y Usabiaga, 2012). Los desarrollos teóricos de los modelos stock-flow los brindan Taylor (1995), Coles y Muthoo (1998), Coles (1999) y Lagos (2000).
Coles y Petrongolo (2008) refutan que el proceso de contratación esté bien capturado por el simple modelo stock-stock. Los autores muestran que las entradas de nuevas vacantes y desempleados durante el periodo de referencia pueden jugar un papel más importante en determinar las salidas del desempleo. De otra parte, Coles y Rogerson (1999) argumentan que existe una probabilidad alta de que un trabajador no cumpla los requisitos de un empleo cuando se postula, debido a la heterogeneidad entre los trabajos y los desempleados, de manera que en el proceso de emparejamiento se hace una distinción entre el contacto y el proceso de contratación. Esto quiere decir que el hecho de que exista un acercamiento no implica que se realice la contratación; para el desempleado que ha contactado con varios empleadores hay dos resultados posibles: 1)Puede emparejar con alguno: si quien busca empleo es aceptado por el empleador, saldrá del desempleo. A nivel agregado, este buscador de empleo es un desempleado flujo que obtiene un empleo que se cuenta dentro del stock de vacantes. Por ende, el emparejamiento se realiza entre la vacante en stock y el buscador de trabajo flujo. 2)Puede seguir desempleado: si el desempleado continúa sin trabajo esto significa que el emparejamiento no existe en el mercado (Dmitrijeva y Hazans, 2007).
Las investigaciones que encuentran correlación entre los nuevos desempleados con las vacantes stock y entre las nuevas vacantes y el stock de desempleados estiman un modelo stock-flow. Uno de los argumentos a favor de este modelo se deriva del hecho de que los desempleados tienen información completa sobre las vacantes disponibles y aplican en aquellas para las que se ven aptos. Este es el caso de Latvian (Dmitrijeva y Hazans, 2007), en donde el stock de desempleo al inicio del mes y el flujo de vacantes son los determinantes de las entradas del desempleo y empleo, mientras que el stock de vacantes y la entrada del desempleo no juegan un papel importante.
2.3.4Evaluación de las oficinas de empleoLa eficiencia de una oficina de empleo se puede medir por la rapidez con la que un empleador encuentra trabajo y las vacantes encuentran trabajadores. Entre más rápido ocurra, mayor es la eficiencia y menor es el nivel de desempleo (Sheldon, 2003). Entre los trabajos que usan datos de los centros de empleo están el de Coles y Smith (1995), Álvarez de Toledo, Núñez y Usabiaga (2008), Burda, Bean y Svejnar (1993), Burda y Boeri (1996) y Burda y Profit (1996). El trabajo de Sheldon (2003) no solo intenta ofrecer un panorama completo del proceso de emparejamiento en los organismos públicos de empleo de Andalucía (Servicio Andaluz de Empleo [SAE]) basado en el análisis de duración, sino también evalúa el proceso de emparejamiento de las ofertas de empleo gestionadas por el SAE. Estima la función con regresiones de series de tiempo agregadas y formas funcionales paramétricas a partir de datos micro de corte transversal y usa técnicas de estimación de frontera no paramétricas (DEA). Los resultados también sugieren que el asesoramiento es más eficaz que otras medidas activas del mercado laboral en el aumento de la eficiencia de emparejamiento.
Otro ejemplo lo constituyen Álvarez de Toledo et al. (2012), quienes pretenden verificar el ajuste del modelo stock-flow determinando la tasa de riesgo de las vacantes hacia la vieja demanda y la tasa de riesgo de las vacantes hacia la nueva demanda de trabajo, la cual según el artículo debe disminuir con la duración de las vacantes. Los autores apuntan a que el resultado obtenido se debe fundamentalmente al papel que ha venido desempeñando la Institución Nacional de Empleo (INEM) de España en la gestión del empleo. Por el lado de la oferta de trabajo, la población desempleada registrada está constituida por los trabajadores más desfavorecidos, principalmente en sectores de ocupación que se caracterizan por la existencia de un exceso de oferta de trabajo. En el encuentro entre la oferta y la demanda de trabajo, Álvarez de Toledo et al. (2012) sugieren que «la persistencia de estos desequilibrios puede deberse al escaso registro, en términos relativos, de nuevas vacantes en las oficinas públicas de empleo y/o a la poca movilidad de los demandantes de empleo hacia sectores de ocupación o espacios geográficos más dinámicos» (p. 32).
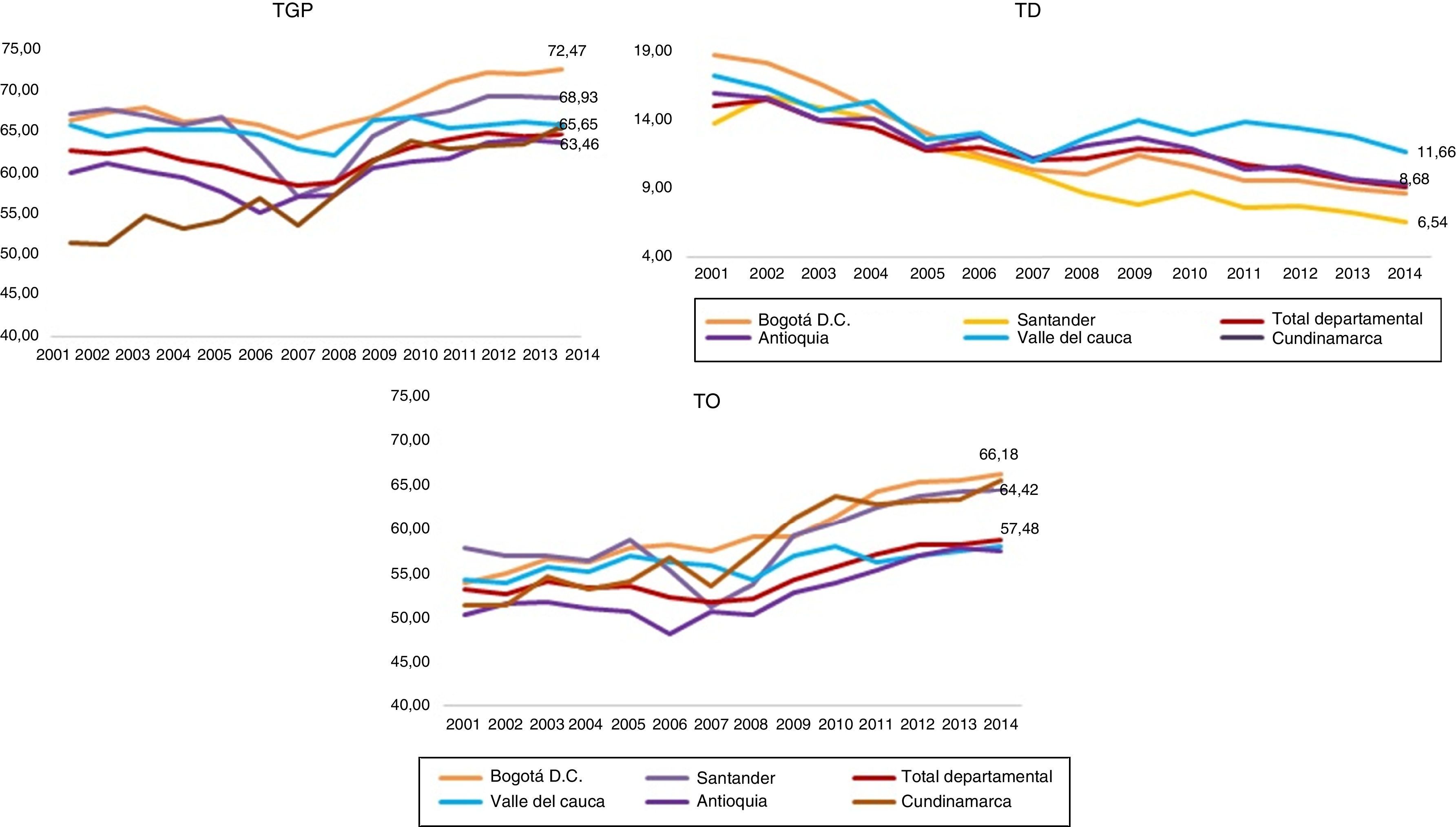
2.4Estimación de la curva de Beveridge para ColombiaLa escasa información acerca del número de vacantes en Colombia ha limitado el análisis del funcionamiento del mercado de trabajo a través del enfoque de los modelos de emparejamiento y de uno de sus principales recursos: la curva de Beveridge. En la revista del Banco de la República 1011 y en el trabajo de Becerra (2015) se estima la curva para Colombia a partir de la primera serie construida por Álvarez y Hofstetter (2013), la cual consiste en datos de clasificados de vacantes laborales publicados en el diario El Tiempo, desde 1960 hasta 2010, con una periodicidad mensual y a partir de los datos que ofrece el SPE administrado por el Servicio Nacional de Aprendizaje (Sena) (Uribe, 2012). Las estimaciones de la pendiente de la curva de Beveridge para las principales ciudades son: −0,771 para Barranquilla, −0,723 para Bogotá, −0,470 para Cali y −0,678 para Medellín, y para el total de siete ciudades: −0,731. El resultado agregado para las siete ciudades sugiere que un incremento del 1% en la tasa de vacantes de trabajo está acompañado de una disminución de la tasa de desempleo del 0,731% (Uribe, 2012, p. 13).
Un hecho estilizado de la curva para el caso colombiano es que hacia los años setenta es más baja hacia la izquierda, en los ochenta hay un salto hacia la derecha a causa de mayores fricciones del mercado laboral y parece que a partir del 2007 se está presentando un regreso de la curva a niveles de los setenta. La forma de la curva de Beveridge está determinada por la función de matching; por esta razón es que Petrongolo y Pissarides (2001) afirman que esta curva es la primera evidencia de la función de emparejamiento. La segunda fuente de evidencia de la función se estima por medio del uso de los datos agregados del desempleo y los flujos del desempleo para obtener una función para toda la economía o para un sector. La tercera son los datos de series de tiempo o panel para los mercados de trabajo locales y las estimaciones de la función de emparejamiento para cada uno. Y la cuarta es el uso de los datos a nivel micro acerca de la transición individual del empleo al desempleo, del desempleo al empleo y de una vacante libre a una ocupada para estimar adicionalmente la función de riesgo para los trabajadores desempleados. Esta investigación parte de la evidencia de la curva de Beveridge para Colombia, y se enfoca en estimar la función de emparejamiento agregada y la función para los mercados de trabajo regionales a partir de los datos panel que se obtienen del SPE.
3Servicio Público de Empleo en ColombiaEl SPE en Colombia, concebido como una red de prestadores a nivel nacional, se define como una herramienta eficiente y eficaz de búsqueda de empleo y como un componente del Mecanismo de Protección al Cesante, de acuerdo con la Ley 1636 del 18 de junio de 2013. El SPE se definió como «un instrumento para la intervención del funcionamiento del mercado laboral, siendo el encargado de la prestación del servicios de gestión y colocación de empleo a nivel nacional, departamental y municipal» (Ministerio del Trabajo, 2014, p. 1). El diseño del SPE también comprende la intervención a través de la gestión de empleo que «tiene por objetivo articular, coordinar y focalizar las políticas activas y pasivas de empleo de una forma eficiente» (Ministerio del Trabajo, 2014, p. 1).
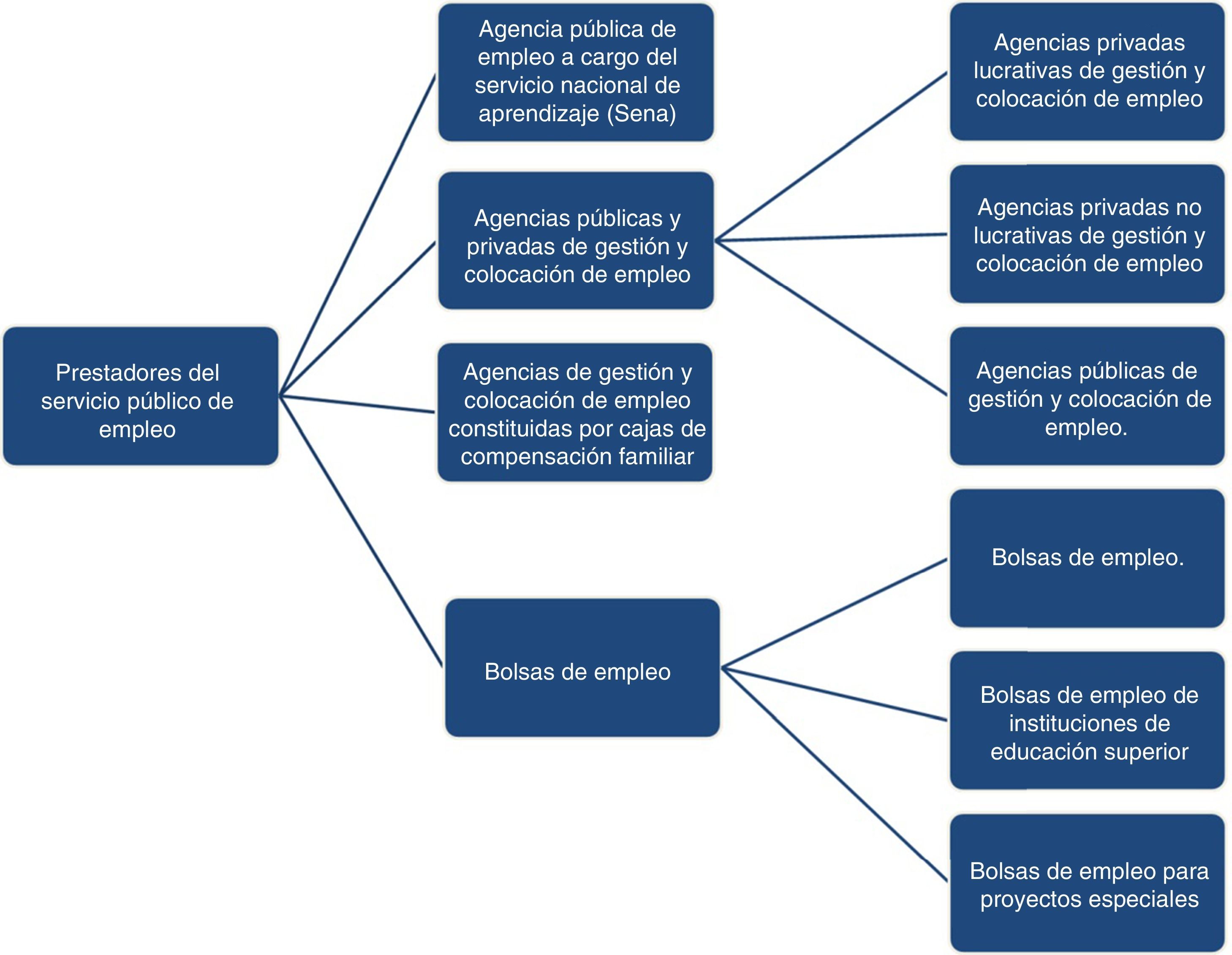
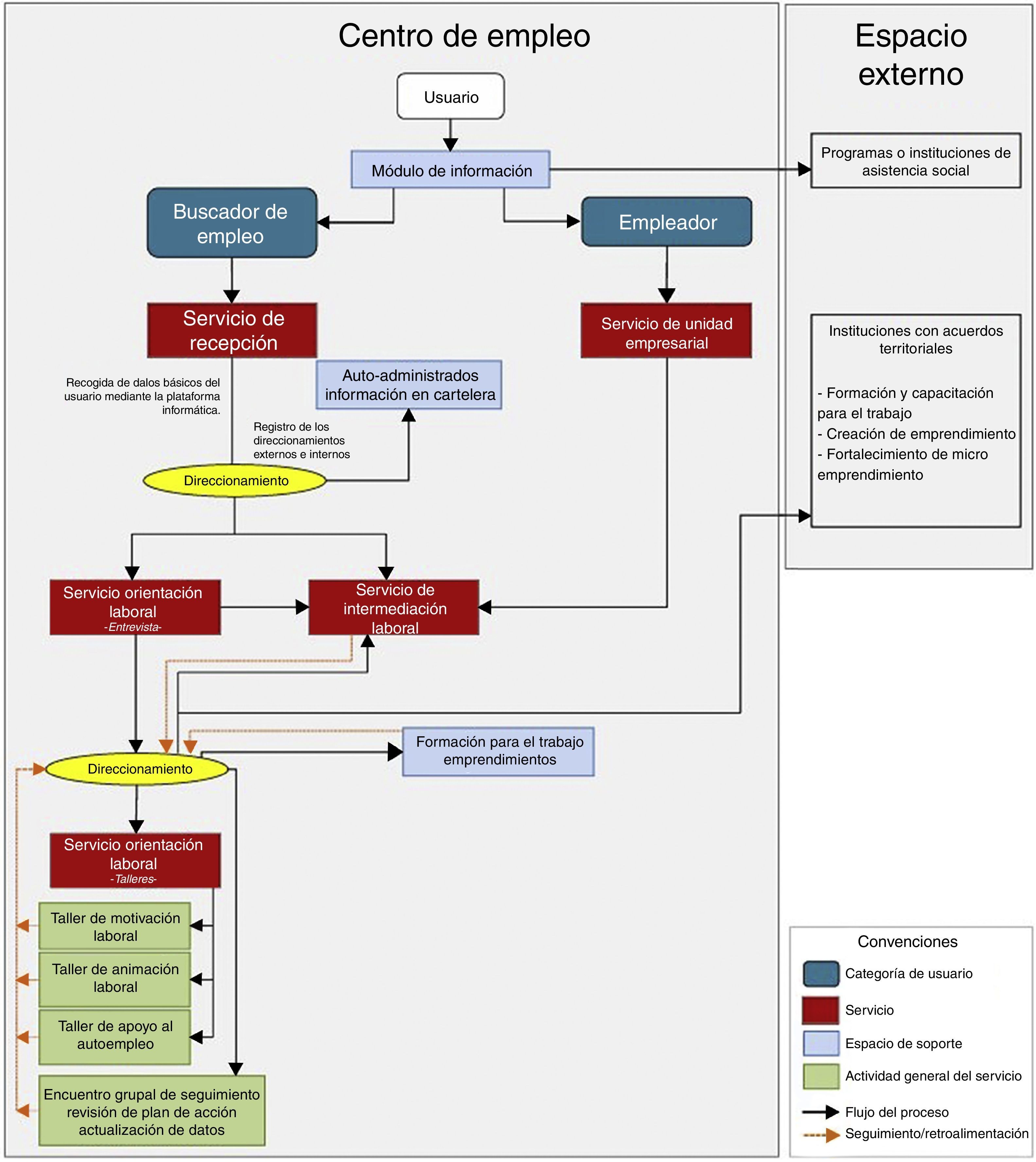
Las entidades autorizadas que conforman la red de prestadores del SPE son: la Agencia Pública de Empleo a cargo del Servicio Nacional de Aprendizaje (Sena), las Agencias Públicas y Privadas de Gestión y Colocación de Empleo, las Agencias de Gestión y Colocación de Empleo de las Cajas de Compensación Familiar (CCF) y las bolsas de empleo1 (fig. 5).
")
Funcionamiento del SPE.
Fuente: tomado conceptualización del SPE. Ministerio del Trabajo, 2014.
(Figura disponible a color en la versión electrónica del artículo.)
La red ofrece actividades básicas de gestión y colocación que, de acuerdo con el decreto 2852 de 2013, son: a)registro de oferentes, demandantes y vacantes; b)orientación ocupacional a oferentes y demandantes; c)preselección, o d)remisión. Estas actividades se deben ofrecer de manera gratuita a los buscadores de empleo y empleadores, y solo las agencias privadas pueden cobrar al empleador una comisión por la prestación de los servicios básicos.
En cuanto al registro de los buscadores de empleo, se puede realizar a través de dos mecanismos: el primero por medio de la Red Nacional Virtual, a la que se puede acceder ingresando a la página de internet <www.redempleo.gov.co>, o ingresando directamente al portal web de los prestadores autorizados por el Ministerio del Trabajo. El segundo mecanismo de acceso es a través de los Centros de Atención, operados por las alcaldías, el Sena, las CCF o las bolsas de empleo vinculadas.
Cuando se realiza el registro presencial hay dos direccionamientos posibles: orientación laboral o intermediación laboral. La inscripción de empleadores y sus vacantes se puede llevar a cabo vía virtual o presencial en el centro de empleo. El proceso de intermediación laboral se puede realizar por medio de la postulación a una vacante por parte del buscador de empleo directamente por el portal o por la gestión de centro. La figura 6 resume la acción de la agencia de empleo.
")
Operación del SPE.
Fuente: tomado de Centros de Empleo-Lineamientos para la operación. Ministerio del Trabajo, 2014.
(Figura disponible a color en la versión electrónica del artículo.)
La información de las vacantes y desempleados registrados en el SPE, así como de las colocaciones gestionadas, proviene de los prestadores de Red Empleo, el Sena, Elempleo.com, Computrabajo y los centros de empleo constituidos por las alcaldías y las CCF. Para el periodo estudiado se constituyeron 64 centros de empleo2 y la prestación de servicio en internet (Red Empleo, Elempleo.com y Computrabajo).
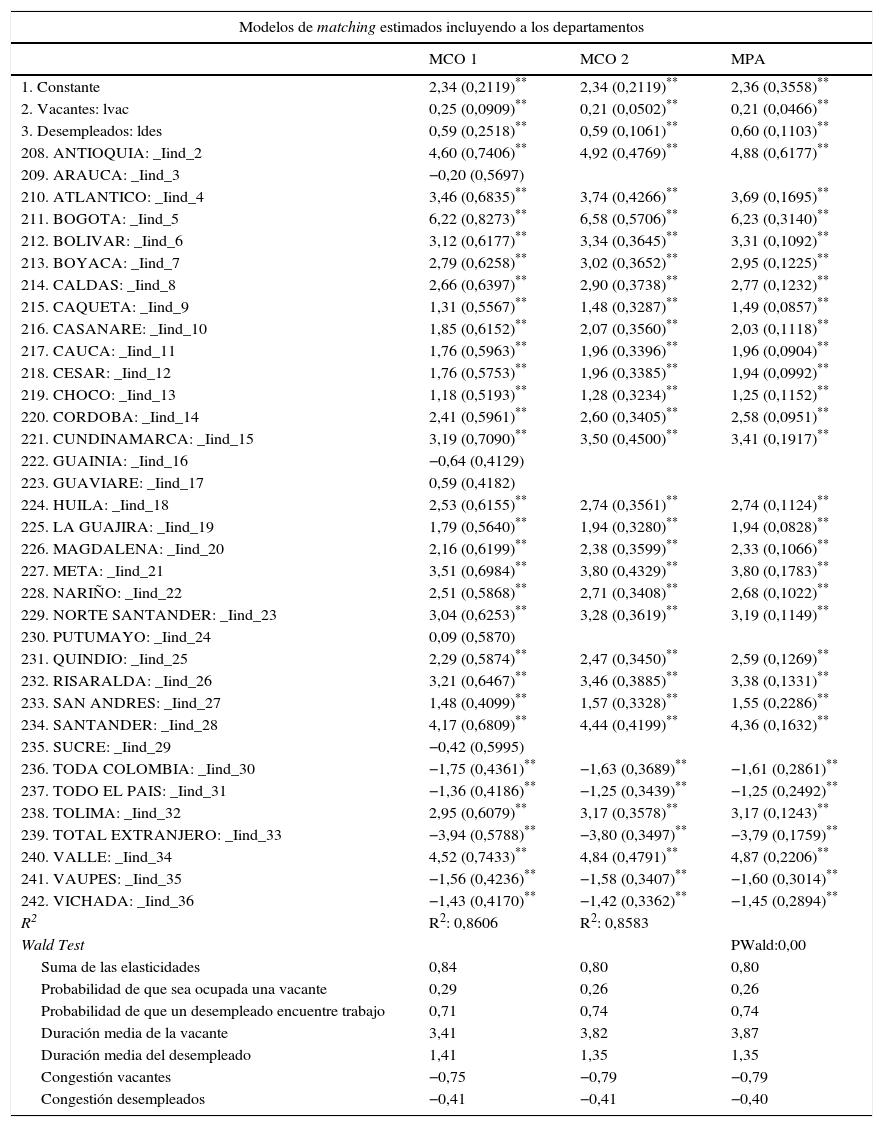
4MetodologíaEsta investigación busca analizar el funcionamiento del mercado de trabajo mediante la comparación de los posibles modelos de matching de búsqueda de trabajo y vacantes en Colombia, usando los datos de panel disponibles del SPE. Para ello se estimará primero una aproximación del modelo de matching agregado (ecuación 2.1) mediante los modelos MCO y MCORE con los datos mensuales desde febrero de 2014 hasta diciembre de 2014. De acuerdo con la metodología de estimación de datos panel, se llevará a cabo la estimación por Population Average (PA), efectos fijos (EF) y efectos aleatorios (EA), y se analizarán los efectos en la función por individuos incluyendo dummies por departamentos.
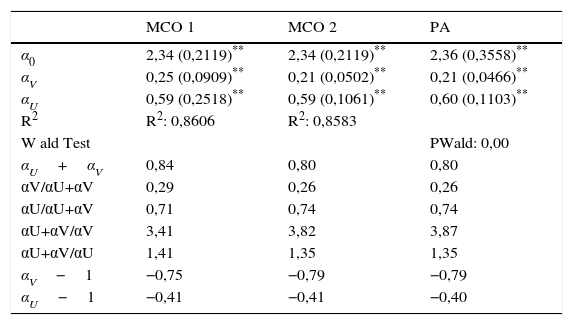
Luego se estimará el modelo stock-flow por MCO y PA. Finalmente, se solucionarán los problemas de endogeneidad entre el término de error y el número de vacantes y desempleados con el modelo de datos panel dinámico propuesto por Arellano y Bover (1995) y Blundell y Bond (1998), el cual permite incorporar los rezagos de la variable dependiente así como de las vacantes y desempleados stock.
A partir de las elasticidades de las vacantes y los desempleados de cada modelo se busca analizar el tipo de rendimientos que presenta la función de emparejamiento. Con estos coeficientes es posible calcular una aproximación de las tasas de transición de un estado a otro: la probabilidad con la que un trabajador encuentra trabajo durante un periodo de tiempo (αU/(αU+αV)) y con la que se ocupa una vacante (αV/(αU+αV)), la duración media de una vacante ((αU+αV)/αV) y la duración promedio de un desempleado ((αU+αV)/αU). En varios modelos se incluyeron las variables relacionadas con las características de los agentes y de las vacantes, las cuales incluyen títulos profesionales, sexo, sectores económicos, entre otros, con el fin de determinar cuáles resultan afectar el proceso de emparejamiento de las vacantes y los desempleados3.
Con la función de emparejamiento en Colombia a través de la operación del SPE y con el tipo de rendimientos a escala es posible comparar los resultados con los obtenidos en otros países. La comparación se realizará de acuerdo con el análisis de las características del mercado laboral que se asemejen a las de Colombia. De los países en los que se ha realizado la estimación de la ecuación de matching, los que cuentan con las características y estructura de datos que se acercan a la experiencia colombiana son República Checa y Eslovaquia. El trabajo de Burda et al. (1993) para la República Checa y Eslovaquia tiene una ordenación de datos panel similar (datos mensuales durante octubre 1990-mayo 1992 con desagregación por distritos) y una tasa de desempleo semejante, la cual, de acuerdo con los datos del Banco Mundial (WDI, 2015), fue del 10,5% en Colombia para el año 2013, para Eslovenia del 10,1% y para la República Checa del 7%.
4.1Modelo de emparejamiento agregadoLa función de matching actúa como una función de producción para las nuevas contrataciones Mi,t en la región i en el periodo t y está relacionada con el número de desempleados que están buscando trabajo Ui,t y vacantes disponibles Vi,t. Siendo Ai,t el parámetro de escala que captura diferentes posibilidades de desajuste, la función de producción simple puede ser formalizada por la forma Cobb-Douglas
Después de una transformación logarítmica en ambos lados, se obtiene la siguiente ecuaciónEl parámetro de desajuste se transforma para capturar eficiencia del emparejamiento debido a las características de las vacantes y los desempleados (lnAi,t=α0+μt+λt). Los parámetros αU y αV son las elasticidades con respecto al total de desempleados y el número de vacantes, respectivamente. El parámetro μt captura los efectos de las características de las vacantes (sector económico, requisitos, entre otras) y λt de las características de los desempleados (número de hombres y mujeres, título profesional, personas a cargo, entre otras) y εi es el error del modelo. En el análisis empírico de los retornos de una función de producción si αU+αV excede, es menor que o igual a uno implica respectivamente retornos a escala crecientes, decrecientes o constantes.4.2Modelo de emparejamiento con datos de datos panel
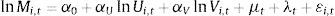
El uso de un panel de datos posee ciertas ventajas con respecto a las series de corte transversal. El panel proporciona un número mayor de datos, incrementa los grados de libertad y reduce la colinealidad entre las variables explicativas, por lo cual mejora la eficiencia en las estimaciones econométricas (Hsiao, 2003). Adicionalmente, permite resolver el problema de variables omitidas no observables que es común al momento de explicar los determinantes del emparejamiento entre la oferta y demanda de trabajo. La base de datos del SPE brinda información relevante acerca de las características de los buscadores de empleo y de las vacantes, no obstante existen todavía elementos que actúan en el momento en el que se encuentran la oferta y demanda de trabajo para que se logre ocupar la vacante. Entre ellos los aspectos culturales e históricos de cada departamento, los cuales influyen en la contratación y el esfuerzo de búsqueda de cada agente; por ejemplo, el centro de empleo del departamento de Quindío, así como los del Valle del Cauca, mencionan que han tenido problemas en los procesos de selección en los que están involucrados jóvenes. Una vez han pasado el proceso de selección deciden no aceptar la vacante o no asisten a la capacitación. Se atribuyó como una de las razones la no disposición a dejar de recibir la ayuda de los programas del Estado al acceder a un empleo formal. Por otro lado, también influye el hecho de que las personas más jóvenes tienen menos claridad acerca de las decisiones que deben tomar en su vida laboral.
Usualmente, en los trabajos acerca de los determinantes del salario reconocen como variables no observables «la habilidad, las oportunidades de acceso al mercado laboral (por ejemplo, falta de información disponible para conseguir trabajo con un salario alto), el capital social (redes sociales y contactos que afectan los nombramientos) y el esfuerzo en la búsqueda» (Martínez Zamora, 2015, p. 45). En los modelos de matching se reconoce que el esfuerzo de búsqueda no se observa, y esto significa, por ejemplo, que los desempleados consulten periódicos, contacten con amigos y busquen en las agencias de empleo (Coles y Petrongolo, 2008). Al momento de modelar las variables que no se observan, es importante determinar si están correlacionadas con otras variables exógenas no excluidas.
El modelo básico de efectos inobservados puede ser escrito para una observación de panel aleatoria i, como:
Donde i representa a los individuos, luego ci es el efecto individual o heterogeneidad individual y uit es el error idiosincrático porque cambia a través de t y de i. El parámetro μt captura los efectos de las características de las vacantes y λt los de las características de los individuos. Como ya se mencionó, es relevante establecer si ci es tratado como un efecto aleatorio o un efecto fijo, es decir, si ci se toma como una variable aleatoria o un parámetro a estimar (Wooldridge, 2002).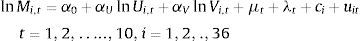
El principal resultado de esta función de emparejamiento agregada es que está compuesta por distintas funciones de emparejamiento en el mercado de trabajo regional, por eso es importante que la estimación pueda controlar por los efectos entre individuos. Las investigaciones muestran que la elasticidad de nuevas contrataciones con respecto a los buscadores de trabajo, αU, es mayor que la elasticidad con respecto a las vacantes, αV (Petrongolo y Pissarides, 2001). En estos mercados, una vacante adicional crea aproximadamente pocas nuevas contrataciones, mientras que un trabajador adicional genera un nuevo emparejamiento con mayor probabilidad. En cualquier caso, los coeficientes positivos de las variables características de las vacantes y los desempleados pueden ser interpretados como un incremento en la eficiencia del mercado de trabajo con respecto a los nuevos emparejamientos formados con la respectiva variable (Fahr y Sunde, 2004).
4.3Modelo de emparejamiento stock-flowSiendo Ui,tS y Vi,tS el stock al principio del periodo de desempleados y vacantes respectivamente para el individuo i en el periodo t, si el flujo de nuevos trabajadores y nuevas vacantes durante el periodo t son Ui,tF y Vi,tF, los trabajadores iniciales Ui,tS se emparejan con el flujo de vacantes Vi,tF, mientras que la entrada de Ui,tF se empareja con Vi,tS y Vi,tF. El modelo captura el hecho de que en el mercado laboral los buscadores de empleo tienen más de una opción e implica que el desempleado que entra no sufre de congestión, mientras que el existente sí (Petrongolo y Pissarides, 2001). La función de producción stock-flow puede ser formalizada como:
La linealización de la ecuación a estimar por MCO es la siguiente:4.4Modelo de emparejamiento panel dinámico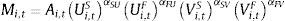
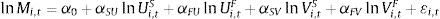
El modelo de datos panel dinámico brinda una forma funcional diferente a la función de matching que se ha estimado tradicionalmente, ya que permite incorporar rezagos de la variable dependiente y rezagos de las variables endógenas para solucionar el problema de endogeneidad que no se corrige por efectos fijos. Este problema de endogeneidad se genera debido a que las vacantes, que son insumo de la función de matching, son publicadas por las firmas porque el retorno de hacerlo es positivo, lo cual hace explícitamente a las vacantes una función de la eficiencia del matching. Por lo tanto, los choques aleatorios de la eficiencia del emparejamiento afectan el número de empleos formados en cada momento del tiempo (Borowczyk-Martins et al., 2013). Este modelo permite corregir el sesgo en los coeficientes generado por los efectos de heterogeneidad no observados que se encuentran en el término de error y que están correlacionados con la variable dependiente. Trabajos como el de Hujer y Zeissy (2005), Borowczyk-Martins et al. (2013), Liu (2013) muestran que la endogeneidad puede ser causada por la productividad de los trabajadores que afecta la eficiencia del matching entre otras variables macroeconómicas no observadas. Este problema se puede presentar en este trabajo que usa los datos regionales del SPE, porque además de las características individuales no observables, el ciclo económico que afecta la eficiencia del matching, contenido en los errores, está relacionado con las vacantes y los desempleados, es decir, E(εitVit)≠0 y E(εitUit)≠0, lo que hace que las estimación a través del método de efectos aleatorios no sea apropiada.
Este modelo es adecuado para datos con pequeños periodos de tiempo (Stata, 2013). Esta metodología posee dos tipos de estimadores: el de Arellano y Bond (1991) y el propuesto por Arellano y Bover (1995) y Blundell y Bond (1998). Arellano y Bond (1991) derivan un estimador consistente por el método generalizado de momentos (MGM), en el cual, además de incluir los efectos no observados de nivel del panel, introduce restricciones de momentos con p rezagos de la variable dependiente. Sin embargo, Blundell y Bond (1998) muestran que el estimador Arellano y Bond (1991) con rezagos en nivel como instrumentos es débil si el proceso autorregresivo es más persistente o si la variación del efecto no observado en nivel en ci se torna más grande en la variación del error uit. Por esta razón, el trabajo de Arellano y Bover (1995) y Blundell y Bond (1998) propone un proceso de estimación que, además de usar los rezagos en nivel en las condiciones de momentos como instrumentos, usa los rezagos de las diferencias.
La elección entre los posibles modelos dinámicos se realiza probando la validez de los instrumentos incluidos (rezagos en nivel y/o los rezagos de las diferencias) mediante el test de Sargan. El test prueba la hipótesis nula de validez en la sobreidentificación de las condiciones de momentos. Los instrumentos deben cumplir las condiciones de momentos, es decir, no deben estar correlacionados con los residuales. Si el modelo es válido no se rechaza la hipótesis nula. Aparte de eso, si los instrumentos resultan relevantes, indica que las colocaciones, o los emparejamientos rezagados, recogen el comportamiento del ciclo económico y son un buen instrumento para Vi,t y Ui,t. El modelo panel dinámico a estimar es el siguiente:
Donde αj son los parámetros de los p rezagos de la variable dependiente, Ui,t y Vi,t son las variables endógenas, φU son los parámetros de los m rezagos de Ui,t y δV son los parámetros de los n rezagos de Vi,t, βi,t son las variables exógenas de las características de las vacantes, γi,t son las variables exógenas de las características de los desempleados y ci son los efectos de nivel del panel (los cuales están correlacionados con las variables).5Datos y estimación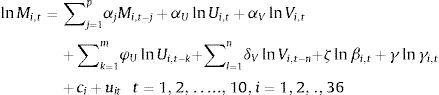
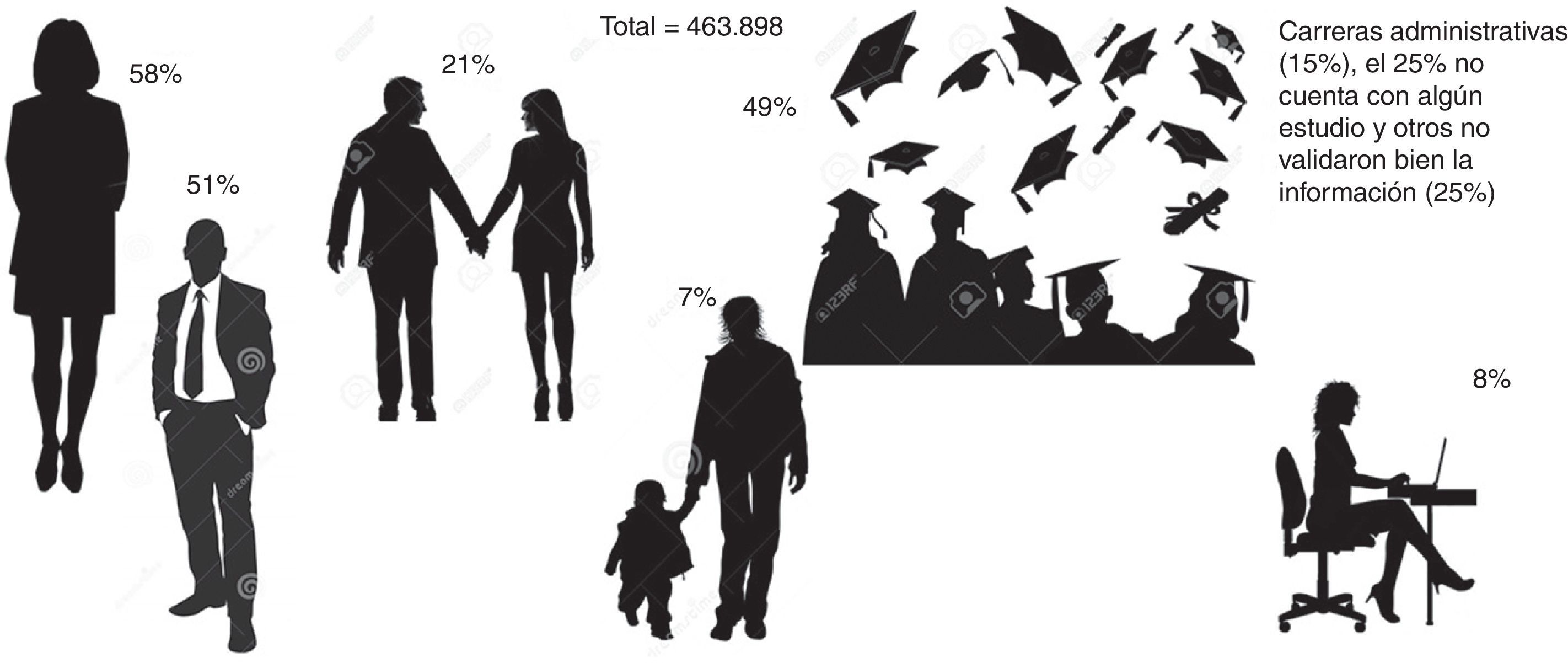
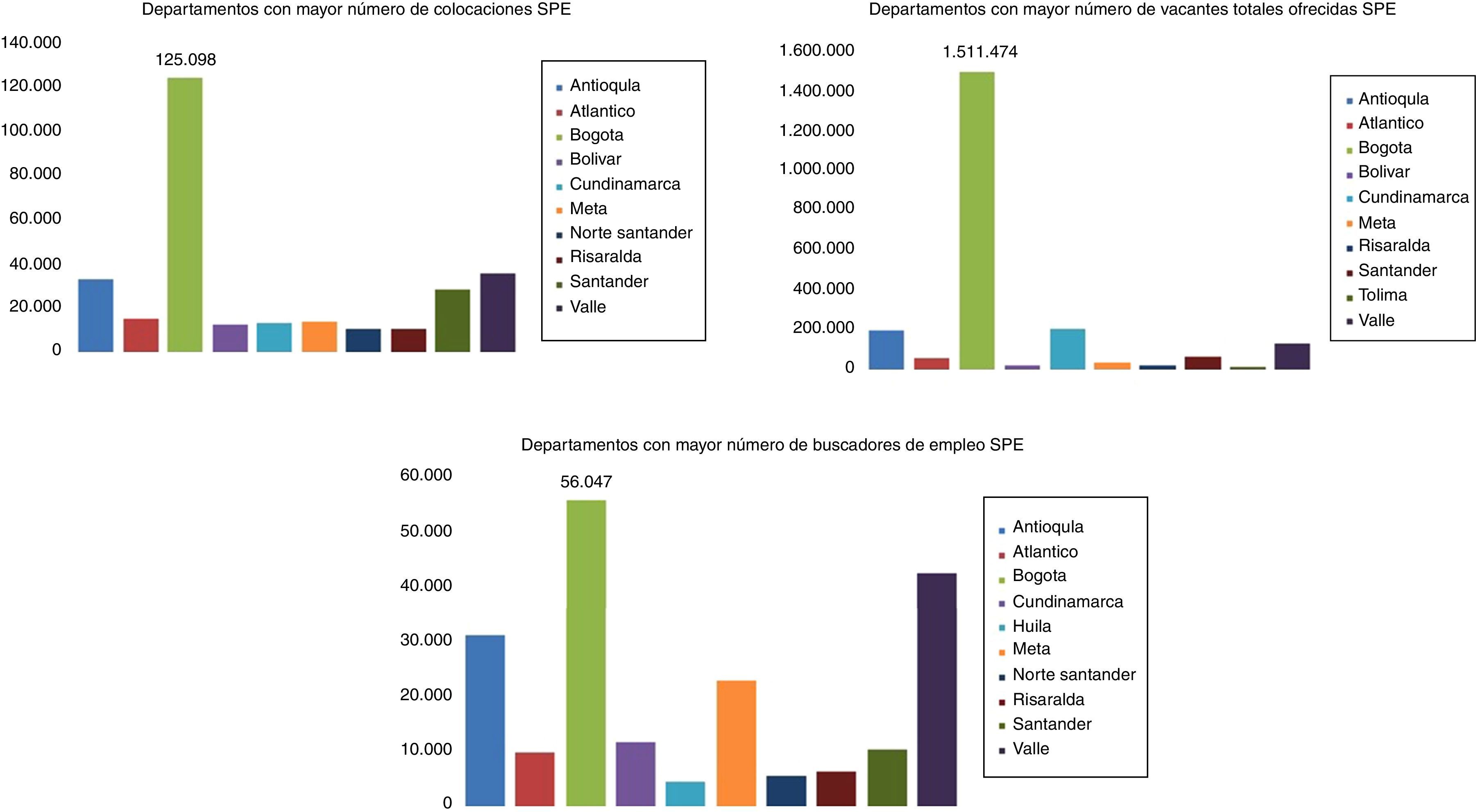
A partir de la inauguración del SPE como una red en Colombia, llevada a cabo el 1 de mayo de 2013, el registro de buscadores de empleo y de vacantes ha presentado un crecimiento exponencial. Para julio de 2013 el registro de hojas de vida completas, donde se cuenta, como datos básicos, con la información del municipio, departamento de residencia, sexo y edad, fue de 60.899 personas, para enero de 2014 el registro ascendió a 220.397 y al final de este año se completó un total de 463.898 hojas de vida. El mayor número de personas que para este periodo de tiempo registraron su hoja de vida son nacidas en Antioquia, Bogotá y Valle del Cauca. Los departamentos con mayores crecimientos en el número de registros, con respecto a los resultados en enero de 2014, fueron Caquetá, Córdoba, Cundinamarca, Meta y Magdalena.
En la base de datos de los buscadores de empleo se tiene información adicional acerca del estado civil, el nivel educativo, el título profesional, los años de experiencia y algunos rasgos familiares, como el número de personas a cargo. Esta información permite hacer inferencia acerca de las características de la oferta de trabajo. En primer lugar, los datos revelan que los registros realizados por mujeres (58%) son mayores que los de los hombres (fig. 7), la mayor parte de las personas son solteras (51%) o en unión libre (21%), el 7% tienen una persona a su cargo y el 5% presentan algún tipo de discapacidad. Cerca del 49% registraron algún título como carrera profesional, de los cuales gran parte son de carreras administrativas (15%), el 25% no cuentan con algún estudio y otros no validaron bien la información (25%). En este artículo se hace mención a los registros de hojas de vida como desempleados; no obstante, el 8% de las personas afirmaron estar ocupadas.
. Fuente: SPE (2014). Elaboración propia.")
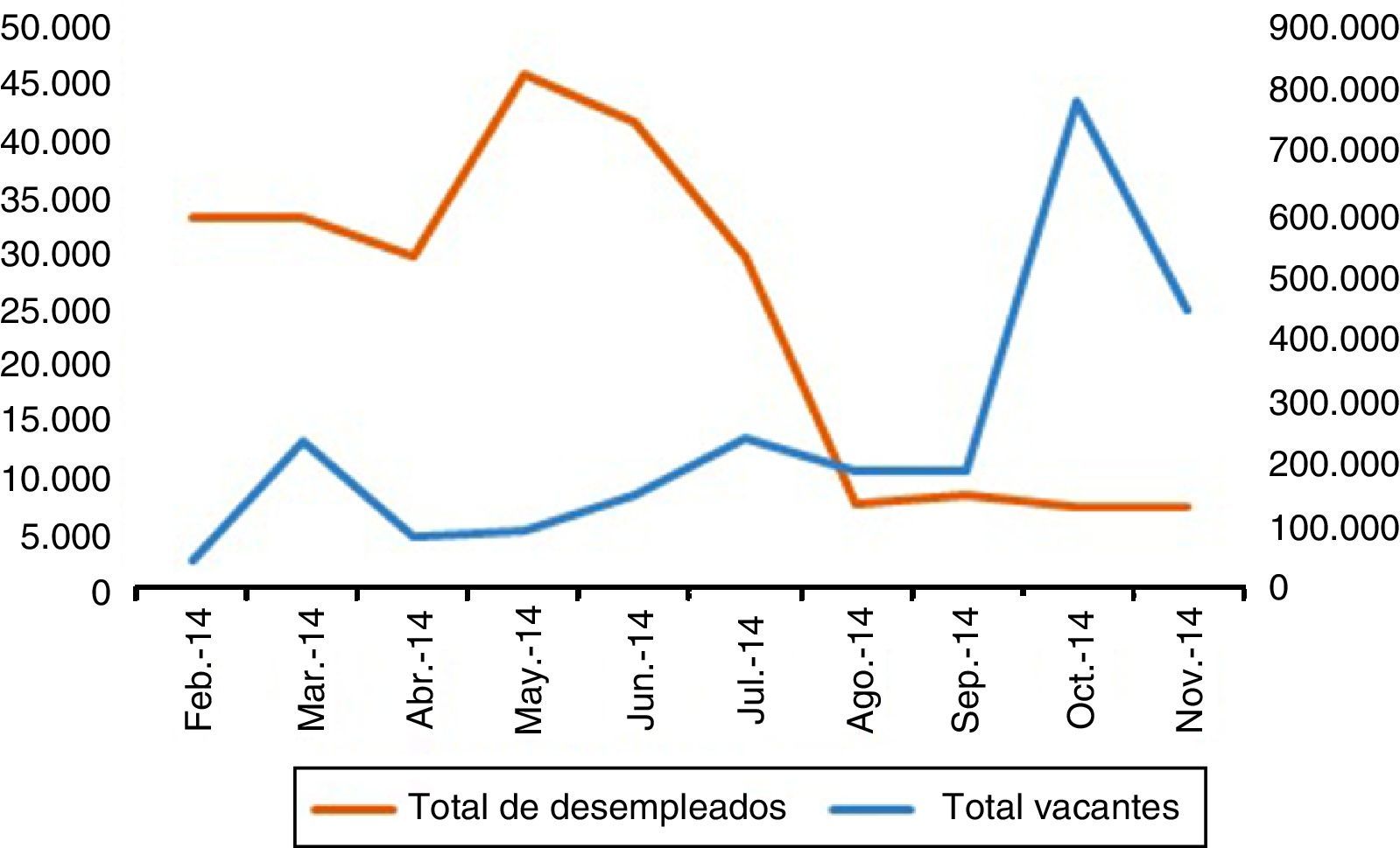
Las vacantes postuladas en el SPE se encuentran disponibles desde febrero de 2014 hasta noviembre del mismo año. El total de vacantes registradas fue de 2.500.307 por parte de 61.480 empresas (fig. 8), las cuales exceden en 2.036.409 al número de hojas de vidas registradas. El 17% piden menos de un año de experiencia, el 12% no piden experiencia y el 11%, un año de experiencia. El 40% de las vacantes no mencionan el salario, el 43% ofrecen entre $550.001 y $1.000.000 y el 10% entre $1.000.001 y $1.500.000.
. Fuente: SPE (2014). Elaboración propia. (Figura disponible a color en la versión electrónica del artículo.)")
Con respecto a la información acerca del sector económico de la empresa, para las vacantes que no poseían dato se realizó la imputación asignando por el nombre de la vacante y se agregó toda la información por sector económico. El 35,2% de las vacantes registran estar en el sector agropecuario, el 8,6% en el sector otros, el 3,5% en el sector salud, el 4,9% en comercio, el 4,8% en servicios, el 4,4% en construcción y el 3,9% pertenecientes a consultorías. En el 13% de las vacantes se especifica que se requiere un hombre, el 10% una mujer y el 1,3% un joven. El 1,4% requieren idioma inglés, el 43% solicitan bachillerato, el 17% tecnólogo y el 7% universitario. Finalmente, los datos de las colocaciones gestionadas por el SPE o emparejamientos se encuentran por mes para el año 2014.
El coeficiente de correlación entre las vacantes y los desempleados es igual a −0,6, lo que soporta la relación negativa registrada entre el comportamiento del número de vacantes y el desempleo. La figura 9 muestra el número total de desempleados y vacantes desde febrero a diciembre de 2014.
. Fuente: SPE (2014). Elaboración propia. (Figura disponible a color en la versión electrónica del artículo.)")
El ordenamiento del panel de datos se realizó por departamento (individuo) de acuerdo con el mes de registro de la hoja de vida del aspirante y el mes de postulación de la vacante. Los datos se tomaron a partir de febrero de 2014 hasta noviembre del mismo año, ya que en ese periodo de tiempo se cuenta con el registro de vacantes. Los individuos del panel de datos son los departamentos del país, incluyendo las categorías de extranjero y toda Colombia. Para obtener este panel se agruparon cada uno de los registros por mes y por departamento, de manera que se sumó el total de personas que se registraron en el SPE en cada uno de los meses en cada uno de los departamentos y se contabilizó el total de vacantes con esta misma clasificación. En este proceso se descartaron 54.342 vacantes que no tenían departamento especificado (representa el 2,2% de la muestra).
Los analistas de los modelos de matching se han preocupado por determinar qué otras variables además del número de vacantes y desempleados influencian el emparejamiento. De acuerdo con Petrongolo y Pissarides (2001) las otras variables que influencian la tasa de emparejamiento se pueden clasificar en dos grupos. En el primer grupo se incluye todo lo que los individuos hacen durante la búsqueda, como escoger cómo hacen las diferentes aplicaciones y el cambio en los métodos de publicación. El segundo grupo incluye los cambios no relacionados con las decisiones de búsqueda de los individuos, por ejemplo los avances realizados debido a los cambios tecnológicos o las políticas de mercado de trabajo. Para esta investigación se incorporan las variables del primer grupo, es decir, las variables que recogen la información que revelan los agentes y algunas características de los mismos con el propósito de determinar su relevancia en el emparejamiento.
La construcción de las variables que tipifican los requerimientos y características de la oferta de trabajo y de los buscadores de empleo por departamento se realizó a partir de la suma mensual total. Por ejemplo, para la variable un año de experiencia se contabilizó el total de vacantes que solicitaron este requisito en cada mes para cada uno de los departamentos. Para el sector económico, se agruparon las vacantes por sector y se totalizaron para cada mes y departamento; de igual manera se realizó para los requisitos de idioma y educación, tipo de contrato y salario ofertado. Para las variables de los desempleados se realizó el mismo proceso: se totalizaron el número de hojas de vida mensual y por departamento que tenían profesiones relacionadas a carreras administrativas, agropecuarias y demás especialidades, así como el número total de aspirantes por sexo, estado civil, personas a cargo y tipo de discapacidad.
Las estadísticas descriptivas (tabla 1) revelan que, en el periodo de tiempo analizado, hubo un promedio de 6.794 vacantes registradas por mes y por departamento, con valor máximo en el mes de octubre que corresponde a la ciudad de Bogotá (594.240). Por otro lado, hubo en promedio 673 desempleados registrados, con valor máximo en el mes de mayo también en Bogotá (12.099) y 1.012 colocaciones promedio, con el mayor valor en el mes de noviembre en la misma ciudad (62.549). En promedio, 789 vacantes al mes solicitaron un año de experiencia, 100 en promedio solicitaron idioma inglés, 1.185 ofrecían contrato indefinido y 2.927 ofrecían un salario entre $550.001 y $1.000.000, 2.024 requerían contar con bachillerato, 1.458 técnico y 1.160 tecnólogo; asimismo, la media de hombres solicitados fue 948, de mujeres 681 y de jóvenes 95. El sector con mayor número de vacantes promedio es el agropecuario (2.389), y le sigue alimentos (716). El registro de desempleados muestra un promedio mensual alto en los títulos relacionados con carreras administrativas (100) y le sigue contaduría (25). La media de mujeres fue 388 y de hombres 284; en promedio se presentaron 341 solteros, 58 personas con una persona a cargo y 47 con un menor de edad.
Estadísticas descriptivas de las variables, 2014
| Variable | Obs | Media | Desv.est. | Mínimo | Máximo |
|---|---|---|---|---|---|
| Total vacantes | 360 | 6.794,347 | 37.261,41 | 0 | 594.240 |
| Total desempleados | 360 | 672,5 | 1.509,045 | 0 | 12.099 |
| Total colocaciones | 360 | 1.011,528 | 3.868,709 | 0 | 62.549 |
| 1 año de experiencia | 360 | 788,75 | 4.926,885 | 0 | 77.262 |
| 2 años de experiencia | 360 | 183,1389 | 966,08 | 0 | 14.168 |
| 3 años de experiencia | 360 | 59,95 | 328,6348 | 0 | 4.285 |
| 4 años de experiencia | 360 | 17,40278 | 99,1474 | 0 | 1.345 |
| 5 años de experiencia | 360 | 21,48611 | 113,379 | 0 | 1.666 |
| 6 años de experiencia | 360 | 18,56944 | 125,486 | 0 | 1.647 |
| 7 años de experiencia | 360 | 1,716667 | 8,484477 | 0 | 123 |
| 8 años de experiencia | 360 | 3,263889 | 20,92152 | 0 | 300 |
| 9 años de experiencia | 360 | 0,6555556 | 6,103857 | 0 | 100 |
| 10 años de experiencia | 360 | 2,772222 | 12,49951 | 0 | 150 |
| 11 años de experiencia | 360 | 0,0888889 | 0,8496363 | 0 | 13 |
| 12 años de experiencia | 360 | 0,2277778 | 1,817067 | 0 | 29 |
| 13 años de experiencia | 360 | 0,0583333 | 0,6149824 | 0 | 11 |
| 14 años de experiencia | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| 15 años de experiencia o más | 360 | 0,4888889 | 3,185078 | 0 | 52 |
| Requiere inglés | 360 | 100,925 | 551,7329 | 0 | 8.253 |
| Requiere francés | 360 | 4,336111 | 52,21539 | 0 | 215 |
| Requiere español | 360 | 55,125 | 473,2594 | 0 | 939 |
| Requiere mandarín | 360 | 0,35 | 1,621496 | 0 | 8.051 |
| Requiere portugués | 360 | 2,397222 | 15,6677 | 0 | 65 |
| Requiere alemán | 360 | 0,5583333 | 4,48171 | 0 | 73 |
| Requiere hombre | 360 | 947,0917 | 5.463,2 | 0 | 82.631 |
| Requiere mujer | 360 | 681,4389 | 4.034,51 | 0 | 63.793 |
| Requiere joven | 360 | 94,16111 | 620,2643 | 0 | 8.994 |
| Contrato fijo | 360 | 236,3806 | 1.015,834 | 0 | 12.617 |
| Contrato indefinido | 360 | 1.184,406 | 7.123,843 | 0 | 110.286 |
| Contrato de aprendizaje | 360 | 26,67778 | 155,5901 | 0 | 2.470 |
| Contrato de servicios | 360 | 55,78611 | 220,6928 | 0 | 3.227 |
| Contrato obra labor | 360 | 636,5556 | 5.020,775 | 0 | 87.924 |
| Tiempo completo | 360 | 3.391,825 | 19.795,05 | 0 | 268.152 |
| Medio tiempo | 360 | 111,1972 | 518,4226 | 0 | 6.442 |
| Contrato por hora | 360 | 196,8806 | 1.166,957 | 0 | 15.950 |
| Requiere primaria | 360 | 48,44444 | 297,9962 | 0 | 4.667 |
| Requiere secundaria | 360 | 107,7361 | 884,9633 | 0 | 14.816 |
| Requiere bachillerato | 360 | 2.923,825 | 20.501,63 | 0 | 346.301 |
| Requiere técnico | 360 | 1.458,119 | 7.640,167 | 0 | 124.703 |
| Requiere universitario | 360 | 450,5528 | 2.540,176 | 0 | 41.667 |
| Requiere tecnólogo | 360 | 1.159,553 | 6.604,763 | 0 | 109.696 |
| Requiere especialización | 360 | 60,66111 | 284,2861 | 0 | 4.700 |
| Requiere maestría | 360 | 10,88889 | 42,66268 | 0 | 561 |
| Requiere doctorado | 360 | 3,633333 | 16,32995 | 0 | 230 |
| No requiere estudio | 360 | 1,675 | 11,18432 | 0 | 150 |
| Actividad de la empresa: Cuero | 360 | 22,65556 | 262,53 | 0 | 4.907 |
| Actividad de la empresa: Naval | 360 | 3,913889 | 20,82012 | 0 | 334 |
| Actividad de la empresa: Otros | 360 | 582,025 | 5.736,613 | 0 | 105.157 |
| Actividad de la empresa: Pulpa | 360 | 30,29722 | 499,5061 | 0 | 9.471 |
| Actividad de la empresa: Salud | 360 | 239,8167 | 1.152,532 | 0 | 17.018 |
| Actividad de la empresa: Medios | 360 | 11,73889 | 90,99398 | 0 | 1.586 |
| Actividad de la empresa: Bebidas | 360 | 159,5167 | 762,4267 | 0 | 10.179 |
| Actividad de la empresa: Consumo | 360 | 125,8694 | 997,1785 | 0 | 18.010 |
| Actividad de la empresa: Estatal | 360 | 21,46111 | 146,8912 | 0 | 2.220 |
| Actividad de la empresa: Minería | 360 | 7,461111 | 60,89293 | 0 | 1.065 |
| Actividad de la empresa: Bebidas | 360 | 18,42222 | 161,6921 | 0 | 2.563 |
| Actividad de la empresa: Comercio | 360 | 330,1222 | 2.556,826 | 0 | 46.307 |
| Actividad de la empresa: Estatal | 360 | 3,788889 | 19,55522 | 0 | 285 |
| Actividad de la empresa: Plástico | 360 | 32,50278 | 260,348 | 0 | 4.097 |
| Actividad de la empresa: Químicos | 360 | 13,84167 | 77,83337 | 0 | 1.224 |
| Actividad de la empresa: Textiles | 360 | 57,47778 | 741,6017 | 0 | 13.969 |
| Actividad de la empresa: Alimentos | 360 | 716,4306 | 3.606,847 | 0 | 51.881 |
| Actividad de la empresa: Editorial | 360 | 39,76944 | 351,131 | 0 | 6.131 |
| Actividad de la empresa: Educativo | 360 | 60,01389 | 310,5452 | 0 | 4.639 |
| Actividad de la empresa: Productos | 360 | 3,611111 | 21,81229 | 0 | 290 |
| Actividad de la empresa: Servicios | 360 | 326,0972 | 1.977,679 | 0 | 33.999 |
| Actividad de la empresa: Vehículos | 360 | 27,8 | 238,981 | 0 | 3.988 |
| Actividad de la empresa: Asegurador | 360 | 107,5167 | 445,087 | 0 | 6.388 |
| Actividad de la empresa: Editorial | 360 | 6,566667 | 58,51125 | 0 | 1.074 |
| Actividad de la empresa: Energético | 360 | 29,16667 | 154,6457 | 0 | 2.480 |
| Actividad de la empresa: Financiero | 360 | 228,7278 | 1.570,264 | 0 | 28.016 |
| Actividad de la empresa: Publicidad | 360 | 30,98889 | 249,2074 | 0 | 4.311 |
| Actividad de la empresa: Tecnología | 360 | 142,1194 | 746,6089 | 0 | 10.768 |
| Actividad de la empresa: Transporte | 360 | 125,8028 | 681,401 | 0 | 9.108 |
| Actividad de la empresa: Manufactura | 360 | 58,64444 | 232,1132 | 0 | 2.866 |
| Actividad de la empresa: Agropecuario | 360 | 2389,761 | 11.715,92 | 0 | 160.503 |
| Actividad de la empresa: Construcción | 360 | 301,4222 | 981,8548 | 0 | 11.859 |
| Actividad de la empresa: Consultorías | 360 | 268,0111 | 1.029,728 | 0 | 11.690 |
| Actividad de la empresa: Organizaciones | 360 | 9,072222 | 60,62474 | 0 | 774 |
| Actividad de la empresa: Entretenimiento | 360 | 43,67222 | 179,7833 | 0 | 2.415 |
| Actividad de la empresa: Telecomunicaciones | 360 | 222,3417 | 3152,173 | 0 | 58.265 |
| Salario menos de $550.000 | 360 | 64,61667 | 280,5592 | 0 | 3.808 |
| Salario más de $21.000.000 | 360 | 0,0722222 | 0,4159837 | 0 | 5 |
| Salario $550.001-$1.000.000 | 360 | 2.926,883 | 13.927,96 | 0 | 189.354 |
| Salario $1.000.001-$1.500.000 | 360 | 1 | 11,19466 | 0 | 65.584 |
| Salario $1.500.001-$2.000.000 | 360 | 171,7 | 858,9973 | 0 | 13.722 |
| Salario $2.000.001-$2.500.000 | 360 | 76,46111 | 345,4764 | 0 | 5.607 |
| Salario $2.500.001-$3.000.000 | 360 | 51,76111 | 284,9939 | 0 | 4.659 |
| Salario $3.000.001-$3.500.000 | 360 | 36,80278 | 200,9097 | 0 | 3.449 |
| Salario $3.500.001-$4.000.000 | 360 | 24,26667 | 159,5405 | 0 | 2.878 |
| Salario $4.000.001-$4.500.000 | 360 | 13,975 | 80,0555 | 0 | 1.175 |
| Salario $4.500.001-$5.500.000 | 360 | 11,97778 | 60,4397 | 0 | 939 |
| Salario $5.500.001-$6.000.000 | 360 | 5,452778 | 27,61672 | 0 | 424 |
| Salario $6.000.001-$8.000.000 | 360 | 14,27222 | 76,932 | 0 | 1.029 |
| Salario $8.000.001-$10.000.000 | 360 | 6,836111 | 51,17601 | 0 | 869 |
| Salario $10.000.001-$12.500.000 | 360 | 1,502778 | 15,57085 | 0 | 207 |
| Salario $12.500.000-$15.000.000 | 360 | 0,3166667 | 2,498969 | 0 | 40 |
| Salario $15.000.001-$18.000.000 | 360 | 0,0722222 | 0,6020444 | 0 | 10 |
| Salario $18.000.001-$21.000.000 | 360 | 0,1444444 | 1,376776 | 0 | 20 |
| Título aspirante: ADMI | 360 | 100,0028 | 226,2368 | 0 | 1.730 |
| Título aspirante: AGRO | 360 | 1,633333 | 3,696569 | 0 | 26 |
| Título aspirante: ANTR | 360 | 0,2583333 | 0,7293585 | 0 | 7 |
| Título aspirante: ARQU | 360 | 2,163889 | 5,012889 | 0 | 34 |
| Título aspirante: ARTE | 360 | 1,805556 | 4,130324 | 0 | 31 |
| Título aspirante: BACT | 360 | 0,5555556 | 1,455839 | 0 | 14 |
| Título aspirante: BSICASECUNDARIA6 | 360 | 0 | 0 | 0 | 0 |
| Título aspirante: BIBL | 360 | 1,669444 | 3,889012 | 0 | 31 |
| Título aspirante: BIOL | 360 | 1,3 | 2,9117 | 0 | 21 |
| Título aspirante: CICL | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| Título aspirante: CIEN | 360 | 4,252778 | 9,465668 | 0 | 60 |
| Título aspirante: COMU | 360 | 5,336111 | 11,75141 | 0 | 78 |
| Título aspirante: CONS | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| Título aspirante: CONT | 360 | 24,96944 | 56,23624 | 0 | 429 |
| Título aspirante: DEPO | 360 | 2,358333 | 5,392343 | 0 | 37 |
| Título aspirante: DERE | 360 | 10,52778 | 23,20526 | 0 | 173 |
| Título aspirante: DISE | 360 | 6,527778 | 15,25382 | 0 | 130 |
| Título aspirante: ECON | 360 | 6,491667 | 15,43447 | 0 | 119 |
| Título aspirante: EDUC | 360 | 18,68056 | 42,76027 | 0 | 365 |
| Título aspirante: ELEC | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| Título aspirante: ENFE | 360 | 12,73056 | 28,9033 | 0 | 221 |
| Título aspirante: FILO | 360 | 0,8138889 | 2,20188 | 0 | 17 |
| Título aspirante: FISI | 360 | 0,1916667 | 0,7346858 | 0 | 10 |
| Título aspirante: FORM | 360 | 1,052778 | 2,612375 | 0 | 17 |
| Título aspirante: GAST | 360 | 0 | 0 | 0 | 0 |
| Título aspirante: GEOG | 360 | 0,4222222 | 1,094201 | 0 | 11 |
| Título aspirante: GEOL | 360 | 0,4388889 | 1,178564 | 0 | 9 |
| Título aspirante: GRAF | 360 | 0,075 | 0,3030716 | 0 | 2 |
| Título aspirante: INGE | 360 | 78,75 | 175,7924 | 0 | 1.355 |
| Título aspirante: INST | 360 | 0,125 | 0,4819153 | 0 | 5 |
| Título aspirante: LENG | 360 | 1,408333 | 3,538477 | 0 | 24 |
| Título aspirante: MADE | 360 | 0 | 0 | 0 | 0 |
| Título aspirante: MARI | 360 | 0 | 0 | 0 | 0 |
| Título aspirante: MATE | 360 | 0,6416667 | 1,55742 | 0 | 11 |
| Título aspirante: MEDI | 360 | 2,694444 | 6,220281 | 0 | 48 |
| Título aspirante: MEDIA1013 | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| Título aspirante: META | 360 | 0,0333333 | 0,1946356 | 0 | 2 |
| Título aspirante: MSI | 360 | 0,3972222 | 1,037188 | 0 | 8 |
| Título aspirante: NOC | 360 | 190,3972 | 434,1921 | 0 | 3.626 |
| Título aspirante: NULL | 360 | 143,775 | 320,3957 | 0 | 2.583 |
| Título aspirante: NUTR | 360 | 1,613889 | 3,90105 | 0 | 38 |
| Título aspirante: ODON | 360 | 3,402778 | 7,862785 | 0 | 62 |
| Título aspirante: OPTO | 360 | 2,116667 | 5,097134 | 0 | 43 |
| Título aspirante: OTRA | 360 | 8,630556 | 20,2894 | 0 | 162 |
| Título aspirante: OTRO | 360 | 0,6583333 | 1,636096 | 0 | 12 |
| Título aspirante: POST | 360 | 0,0555556 | 0,2412184 | 0 | 2 |
| Título aspirante: PRIM | 360 | 0,05 | 0,2306585 | 0 | 2 |
| Título aspirante: PSIC | 360 | 8,9 | 20,51729 | 0 | 173 |
| Título aspirante: PUBL | 360 | 5,263889 | 12,11849 | 0 | 91 |
| Título aspirante: QUIM | 360 | 0,0361111 | 0,2011842 | 0 | 2 |
| Título aspirante: QUM | 360 | 1,141667 | 2,591917 | 0 | 16 |
| Título aspirante: SALU | 360 | 5,972222 | 13,55724 | 0 | 115 |
| Título aspirante: SIN | 360 | 5,344444 | 13,42464 | 0 | 117 |
| Título aspirante: SOCI | 360 | 4,352778 | 10,1496 | 0 | 73 |
| Título aspirante: TCNICALABORAL | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| Título aspirante: TCNICAPROFESIONAL | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| Título aspirante: TECNOLGICA | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| Título aspirante: TERA | 360 | 1,319444 | 2,998729 | 0 | 20 |
| Título aspirante: VEST | 360 | 0,0277778 | 0,1645643 | 0 | 1 |
| Título aspirante: ZOOT | 360 | 1,102778 | 2,809255 | 0 | 24 |
| Aspirante femenina | 360 | 387,5167 | 897,5447 | 0 | 7.287 |
| Aspirante masculino | 360 | 284,9694 | 619,4229 | 0 | 4.812 |
| Aspirante casado (a) | 360 | 97,15 | 202,0148 | 0 | 1.745 |
| Estado civil nulo | 360 | 65,53056 | 181,7833 | 0 | 2.113 |
| Aspirante separado (a) | 360 | 24,66389 | 58,53367 | 0 | 513 |
| Aspirante soltero (a) | 360 | 340,7278 | 782,0006 | 0 | 6.303 |
| Aspirante en unión libre | 360 | 141,2139 | 315,9159 | 0 | 2.396 |
| Aspirante viudo (a) | 360 | 3,2 | 7,413306 | 0 | 56 |
| Aspirante ocupado | 360 | 51,7 | 132,7494 | 0 | 1.030 |
| Aspirante no ocupado | 360 | 620,8 | 1.381,842 | 0 | 11.069 |
| Sin personas a cargo | 360 | 25,65 | 99,12312 | 0 | 1.034 |
| 1 persona a cargo | 360 | 57,79444 | 218,1498 | 0 | 2.243 |
| 2 personas a cargo | 360 | 16,53889 | 60,40406 | 0 | 544 |
| 3 personas a cargo | 360 | 3,894444 | 12,55828 | 0 | 117 |
| 4 personas a cargo | 360 | 0,6472222 | 2,223073 | 0 | 20 |
| 5 personas a cargo | 360 | 0,0722222 | 0,3425377 | 0 | 3 |
| 6 personas a cargo | 360 | 0,0083333 | 0,0910325 | 0 | 1 |
| 7 personas a cargo | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| 8 personas a cargo | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| No personas a cargo | 360 | 0,0083333 | 0,0910325 | 0 | 1 |
| Nulo personas a cargo | 360 | 567,8778 | 1.255,963 | 0 | 9.426 |
| Si personas a cargo | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| Sin personas con discapacidad | 360 | 42,18611 | 153,1916 | 0 | 1.575 |
| 1 persona con discapacidad | 360 | 34,69167 | 138,8471 | 0 | 1.437 |
| 2 personas con discapacidad | 360 | 18,77222 | 70,47466 | 0 | 656 |
| 3 personas con discapacidad | 360 | 6,730556 | 23,69977 | 0 | 226 |
| 4 personas con discapacidad | 360 | 1,833333 | 6,109037 | 0 | 54 |
| 5 personas con discapacidad | 360 | 0,3166667 | 1,119466 | 0 | 9 |
| 6 personas con discapacidad | 360 | 0,0777778 | 0,4410112 | 0 | 6 |
| 7 personas con discapacidad | 360 | 0,0083333 | 0,0910325 | 0 | 1 |
| Nulo personas con discapacidad | 360 | 567,8806 | 1.255,964 | 0 | 9.426 |
| Si personas con discapacidad | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| 1 menor de edad | 360 | 47,75556 | 181,8868 | 0 | 1.897 |
| 2 menores de edad | 360 | 32,425 | 129,821 | 0 | 1.297 |
| 3 menores de edad | 360 | 16,84444 | 61,49175 | 0 | 537 |
| 4 menores de edad | 360 | 5,908333 | 20,48139 | 0 | 192 |
| 5 menores de edad | 360 | 1,291667 | 4,137731 | 0 | 34 |
| 6 menores de edad | 360 | 0,2722222 | 0,9779209 | 0 | 8 |
| 7 menores de edad | 360 | 0,0722222 | 0,3810344 | 0 | 4 |
| 8 menores de edad | 360 | 0,0083333 | 0,1177197 | 0 | 2 |
| 9 menores de edad | 360 | 0,0083333 | 0,0910325 | 0 | 1 |
| 10 menores de edad | 360 | 0,0055556 | 0,0744317 | 0 | 1 |
| 11 menores de edad | 360 | 0,0027778 | 0,0527046 | 0 | 1 |
| Sin menores de edad | 360 | 0,0638889 | 0,3056139 | 0 | 3 |
| Nulo menores de edad | 360 | 0,0111111 | 0,1049679 | 0 | 1 |
| Si menores de edad | 360 | 0,0194444 | 0,1571321 | 0 | 2 |
Fuente: SPE (2014). Elaboración propia.
A partir de estas dos bases de datos, se constituye la estructura del panel de dimensiones NTxK, donde N es el total de observaciones (36), T en el número de observaciones en entre febrero y noviembre de 2014 (10) para cada i (individuos) y K es el número de variables (244). Es importante aclarar que no en todos los modelos se utilizaron las 244 variables explicativas.
Para la estimación del modelo stock-flow lo ideal sería poder acceder a los datos sobre demandas y ofertas de empleo que incluyen, respectivamente, los stocks de demandantes de empleo y de puestos pendientes al final de cada mes, así como los flujos de entradas y salidas del desempleo. No obstante, es posible usar como aproximación las variables stock los rezagos de las variables de número de vacantes y número de desempleados.
5.1Estimación e interpretación del modelo5.1.1Función de matching agregadaEn esta sección se asume que la forma funcional de matching de la ecuación 2.1 es log-log. En la tabla 2 se resumen los resultados de los modelos estimados por MCO, MCORE (ecuación 4.2), PA, EA y EF (ecuación 4.5), y se muestran las elasticidades del emparejamiento respecto al stock de vacantes y del emparejamiento respecto al flujo de desempleados. En el anexo 1 se presentan los resultados de los coeficientes para todas las variables. Se analizó la relevancia en los modelos de las 206 variables construidas que tipifican los requerimientos y las características de la oferta de trabajo y de los buscadores de empleo (tabla 1). Después de realizar varias estimaciones, 76 de estas variables resultaron ser significativas en al menos uno de los modelos.
Modelos de matching agregados estimados
| MCO | MCO 2 | MCO 3 | MCORE | PA | EA | EF | |
|---|---|---|---|---|---|---|---|
| α0 | 0,16 (0,0620)** | 0,12 (0,0557)** | 0,11 (0,0492)** | 1,30 (0,3929)** | 0,95 (0,5887)** | 1,79 (0,4499)** | 3,84 (0,4256)** |
| αV | 0,48 (0,0235)** | 0,52 (0,0622)** | 0,57 (0,0441)** | 0,23 (0,0958)** | 0,41 (0,1644)** | 0,26 (0,0507)** | 0,23 (0,0575)** |
| αU | 0,41 (0,0287)** | 0,36 (0,0268)** | 0,63 (0,2371)** | 0,86 (0,1102)** | 0,96 (0,2401)** | 0,81 (0,3446)** | 0,62 (0,1507)** |
| R2 | R2: 0,456 | R2: 0,878 | R2: 0,906 | R2: 0,7170 | R2: 0,7210 | R2: 0,1942 | |
| Wald Test | PWald: 0,00 | PWald: 0,00 | PWald: 0,00 | ||||
| αU+αV | 0,89 | 0,88 | 1,20 | 1,09 | 1,37 | 1,07 | 0,85 |
| αV/αU+αV | 0,53 | 0,59 | 0,47 | 0,21 | 0,30 | 0,24 | 0,27 |
| αU/αU+αV | 0,47 | 0,41 | 0,53 | 0,79 | 0,70 | 0,76 | 0,73 |
| αU+αV/αV | 1,87 | 1,70 | 2,11 | 4,71 | 3,36 | 4,12 | 3,65 |
| αU+αV/αU | 2,15 | 2,42 | 1,90 | 1,27 | 1,42 | 1,32 | 1,38 |
| αV−1 | −0,52 | −0,48 | −0,43 | −0,77 | −0,59 | −0,74 | −0,77 |
| αU−1 | −0,59 | −0,64 | −0,37 | −0,14 | −0,04 | −0,19 | −0,38 |
Coeficientes significativos al 5%.
MCO solo incluye a V y a U, MCO2 incluye variables de características de las vacantes, MCO3, MCORE, EA y EF incluyen variables de características de las vacantes y los desempleados.
α0: constante; αV: elasticidad del matching con respecto a las vacantes; αU: elasticidad del matching con respecto a los desempleados; αU+αV: suma de estas elasticidades; αV/αU+αV: probabilidad de que sea ocupada una vacante; αU/αU+αV: probabilidad de que un desempleado encuentre trabajo; αU+αV/αV: duración media de una vacante; αU+αV/αU: duración media del desempleado; αV−1: congestión de una vacante; αU−1: congestión de un desempleado.
El primer modelo MCO es el modelo agregado teniendo en cuenta como variables explicativas solo el logaritmo del total de buscadores de empleo y vacantes. El modelo MCO2 contiene 16 variables relacionadas a las características de las vacantes, entre ellas el total de vacantes que requieren hombre o mujer, algunos sectores económicos a los que pertenecen (sector otros, medios, estatal, plástico, químicos, servicios, asegurador, publicidad, transporte, manufactura, consultorías y telecomunicaciones), solicitud de educación (primaria, secundaria y especialización) y algunos rangos de salario (ver anexo 1).
El modelo MCO3 incluye 37 variables, que corresponden no solo a las características de las vacantes sino además a las de los desempleados, entre ellas el total de vacantes que requieren hombre, mujer o joven, algunos tipos de contrato (término fijo, indefinido y por hora), algunos sectores económicos a los que pertenecen (sector otros, estatal, minería, servicios, asegurador, publicidad, transporte, manufactura, consultorías y telecomunicaciones), solicitud de educación (primaria, secundaria y especialización), algunos rangos de salario y algunos títulos profesionales (administrativos, contaduría, enfermería, física e ingeniería), número de personas casadas y sin personas a cargo.
La estimación de MCORE, que permite realizar estimaciones robustas a la heterocedasticidad de los residuos, incluye el total de mujeres solicitadas por las vacantes, el número total de las que ofrecen contrato fijo, indefinido, las del sector naval, estatal, minero, químicos, educativo, servicios, publicidad, consultorías, telecomunicaciones, algunos rangos salariales y, como características de los buscadores de empleo, el total de los que contaban con títulos relacionados con física y lenguaje.
Los coeficientes para el primer modelo son iguales a 0,41 para las vacantes y 0,48 para los desempleados. En la segunda regresión solo se incluyen características de las vacantes de manera, que se presenta una caída en la elasticidad del desempleo. La tercera regresión muestra evidencia de que existen otras variables que influencian el emparejamiento en forma sistemática, debido a que se incluyen las características de los desempleados y vacantes, y como resultado disminuye el peso de las vacantes y aumenta el de los desempleados; estos valores son más coherentes con los trabajos empíricos realizados para otros países. De acuerdo con Petrongolo y Pissarides (2001), un rango plausible para la elasticidad del desempleo es de 0,5 a 0,7, mostrando que quizás los efectos de congestión causados entre las firmas son mayores que los causados por los trabajadores. Cuando se corrige el problema de heterocedasticidad por MCORE se amplía la brecha del incremento del coeficiente de los desempleados con respecto al de las vacantes.
El test de Wald prueba la validez general de los parámetros y muestra que en cada regresión todos los coeficientes son en conjunto estadísticamente significativos. El R2 de la primera regresión es 0,45, cuando se incorporan las características de las vacantes en el segundo modelo sube a 0,87, y para el tercer modelo MCO con variables de los buscadores de empleo sube a 0,90. A pesar de que el R2 de MCO3 es el más alto, con el test de Ramsey (1969) se encuentra que existen variables omitidas que no se están modelando. Este test equivale al ajuste del modelo y=xb+zt+u, en donde se prueba si t=0. El estadístico es igual a F(3,642)=12,15, por lo cual se rechaza la hipótesis nula de la no existencia de variables omitidas, respaldando el uso de métodos de datos panel.
Estimando por clústeres, con el modelo PA aumentan las dos elasticidades y se incluyen los sectores de otros, cuero, servicios, manufactura, consultorías y algunos rangos salariales. Los valores de los coeficientes de EF son similares a los coeficientes de EA en el caso de la elasticidad de las vacantes (0,23 y 0,26). Para los desempleados, EA muestra un coeficiente más alto, 0,81, comparado con 0,62 en EF. El test de Hausman muestra evidencia para rechazar la hipótesis nula de que no existe diferencia sistemática en los coeficientes de las regresiones (χ2=34,74, p=0,0000), y por esta razón el modelo más adecuado es el que incluye efectos fijos (EF).
La función de matching se asume homogénea de grado uno o con retornos constantes a escala, lo cual es evidencia de complementariedad entre las acciones de las firmas y los trabajadores. Para probarlo se suman las elasticidades de las vacantes y los desempleados y se prueba la hipótesis H0:αU+αV=1. Para el modelo MCO se rechaza la hipótesis nula de rendimientos constantes a escala (F(1,357)=46,30, p=0,000), y los demás modelos presentan evidencia positiva de estos retornos4. Para el modelo de efectos fijos (EF) la suma de los coeficientes es igual a 0,85, el estadístico que evalúa los retornos constantes es igual a χ2=0,4 (p=0,8389). Los resultados obtenidos con esta metodología son similares a los obtenidos en el trabajo para la República Checa y Eslovaquia de Burda et al. (1993). La elasticidad de las vacantes para la República Checa es 0,44 y para los desempleados es 0,42, la suma de las elasticidades es 0,86; en el caso de Eslovaquia es 0,61 y 0,10, respectivamente, con retornos de 0,71; para ambos casos presentan evidencia de retornos constantes a escala.
Del cálculo de las tasas de transición para el modelo EF se concluye que, en promedio, un trabajador encuentra trabajo en un mes con una probabilidad del 73% (αU/(αU+αV)=0, 62/0, 85) y se ocupa una vacante con una probabilidad del 27%. Asimismo, la medida de congestión de los desempleados (αU−1) es igual a 0,38, mientras que para las vacantes (αV−1) es 0,77; por ello, con este modelo la duración media de una vacante son 3,65 meses (αV/(αU+αV)) y la duración promedio de un desempleado es 1,38 meses (αU/(αU+αV)). Evidentemente, si los trabajadores y las vacantes son heterogéneos, las probabilidades de transición son diferentes a lo largo del mercado de trabajo, así como las duraciones promedio.
El uso de datos panel para eliminar los efectos no observados entre los individuos revela la importancia de estudiar la función de matching regional. Comparando los resultados obtenidos por efectos fijos con la función agregada (MCO3), las elasticidades son menores en magnitud, ya que según Coles y Smith (1995) la agregación alrededor de los mercados donde no hay interacción puede sesgar los retornos estimados. Este hecho indica que es más razonable asumir que el emparejamiento se realiza en cada «campo», en vez de que se disperse en toda la región. Asimismo, no se está hablando de un solo mercado sino de una colección de distintos mercados laborales con ciertas particularidades.
Con respecto a la información que las firmas revelan acerca de las vacantes, en los modelos estimados las vacantes que solicitan mujeres, estudios técnicos y de especialización, las que ofrecen contrato indefinido, así como las que requieren portugués, incrementan el emparejamiento. Este resultado es coherente con el hecho de que la mayor parte de las personas registradas en el SPE son mujeres, de manera que este instrumento ha servido para su inserción en el mercado laboral. De otra parte, parece existir evidencia de un resultado negativo para quienes están casados. Una posible explicación a este hecho la proveen Arango y Ríos (2015), quienes muestran evidencia de que las mujeres con pareja (casadas o en unión libre) tienen periodos de desempleo de mayor duración, explicado por la hipótesis de un menor esfuerzo de búsqueda debido al ingreso laboral de sus parejas. En cuanto a la información que se revela acerca del salario ofertado, el rango bajo entre $550.001 y $2.500.000 tiene impacto positivo. A pesar de que el 40% de las vacantes no mencionan el salario, en los modelos estimados se sugiere que brindar información acerca de la remuneración salarial tiene un efecto en el emparejamiento de forma positiva.
Entre las características que disminuyen el emparejamiento están las vacantes que solicitan idioma inglés, las que solicitan hombres o jóvenes, las que ofrecen contrato fijo y por hora y las que solicitan solo primaria. Este resultado se presenta porque existe evidencia de que el registro por parte de los desempleados en el SPE lo han realizado en mayor medida personas con algún nivel educativo; se destaca que existe efecto positivo para las carreras técnicas, consistente con el ingreso salarial que tiene impacto positivo (entre $550.001 y $2.500.000). Con referencia al sector económico, las empresas del sector naval, las clasificadas como otros, las del sector de cuero, medios, estatal, minería, plástico, consultorías y telecomunicaciones presentan evidencia de encontrar más fricciones para el emparejamiento, mientras que el sector de químicos, las vacantes relacionadas con trabajo editorial, las empresas del sector educativo, servicios, asegurador, publicidad, transporte y manufactura parecen aportar de manera positiva.
Por último, de las variables que hacen referencia a las características de los desempleados, los títulos profesionales de los buscadores de empleo relacionados con contaduría, enfermería, lenguaje e instructores tienen impacto positivo en el matching, asimismo las personas que no tienen un menor de edad a cargo o que tienen uno. Sin embargo, la información al respecto de personas a cargo es ambigua porque gran parte de los desempleados no revelan correctamente este dato, por ello los valores nulos resultan significativos. De otra manera, ha sido más difícil el emparejamiento para los desempleados que registran títulos administrativos y física.
5.1.1.1Análisis departamentalSe analiza el comportamiento de los departamentos en la función de matching con el objetivo de revisar las incompatibilidades que tienen que ver con la movilidad imperfecta del trabajo, los avances tecnológicos en el emparejamiento por individuo y los asuntos de agregación. Para tener una estimación de la contribución al emparejamiento entre la oferta y la demanda de trabajo, se introdujeron variables dummy por departamento tomando como referencia el departamento del Amazonas. En la tabla 3 se muestran los resultados en las elasticidades de las vacantes y los trabajadores a partir de la estimación de los modelos por mínimos cuadrados ordinarios (MCO1) con todas las dummies por departamento, MCO2 con las dummies significativas5 y PA.
Modelos de matching con el análisis por departamento
| MCO 1 | MCO 2 | PA | |
|---|---|---|---|
| α0 | 2,34 (0,2119)** | 2,34 (0,2119)** | 2,36 (0,3558)** |
| αV | 0,25 (0,0909)** | 0,21 (0,0502)** | 0,21 (0,0466)** |
| αU | 0,59 (0,2518)** | 0,59 (0,1061)** | 0,60 (0,1103)** |
| R2 | R2: 0,8606 | R2: 0,8583 | |
| W ald Test | PWald: 0,00 | ||
| αU+αV | 0,84 | 0,80 | 0,80 |
| αV/αU+αV | 0,29 | 0,26 | 0,26 |
| αU/αU+αV | 0,71 | 0,74 | 0,74 |
| αU+αV/αV | 3,41 | 3,82 | 3,87 |
| αU+αV/αU | 1,41 | 1,35 | 1,35 |
| αV−1 | −0,75 | −0,79 | −0,79 |
| αU−1 | −0,41 | −0,41 | −0,40 |
Coeficientes significativos al 5%.
El modelo MCO1 incluye todos los departamentos como variables dummy, MCO2 y PA incluyen solo las dummies que son significativas.
α0: constante; αV: elasticidad del matching con respecto a las vacantes; αU: elasticidad del matching con respecto a los desempleados; αU+αV: suma de estas elasticidades; αV/αU+αV: probabilidad de que sea ocupada una vacante; αU/αU+αV: probabilidad de que un desempleado encuentre trabajo; αU+αV/αV: duración media de una vacante; αU+αV/αU: duración media del desempleado; αV−1: congestión de una vacante; αU−1: congestión de un desempleado.
En cuanto a la elasticidad de las vacantes y los desempleados, los coeficientes son muy cercanos a los de efectos fijos. Este hecho indica de nuevo la importancia de los emparejamientos en las regiones. En estas estimaciones los rendimientos a escala son constantes6 y el cambio en los resultados se presenta en la disminución de las elasticidades con respecto a MCO3 y MCORE.
A pesar de tener más vacantes de trabajo que personas desempleadas en el SPE, aún existen incompatibilidades entre la localización y las habilidades que solicitan las empresas, especialmente en los departamentos de Arauca, Guainía, Guaviare, Putumayo y Sucre, los cuales no fueron significativos (fig. 10). El caso de Vaupés y Vichada muestra coeficientes negativos. Estos departamentos se caracterizan por altas tasas de desempleo y alta informalidad, y sumado a esto, hay pocos prestadores del SPE: el Sena, donde tenga presencia y los servicios por internet, exceptuando a Arauca y Sucre, donde adicionalmente las Cajas de Compensación inauguraron centro físico. Esto se traduce en mayores fricciones en la búsqueda; en otras palabras, un mayor rezago entre la pérdida de empleo y la ubicación en otro (Smithies, 1945). Si estas incompatibilidades no existieran la función de emparejamiento no existiría y los trabajadores y los trabajos emparejarían inmediatamente. Es por la existencia de algunas incompatibilidades que los encuentros toman lugar solo después de un proceso de búsqueda y un proceso de aplicación (Petrongolo y Pissarides, 2001).
")
Para entender estos resultados, se observa que en Vaupés y Vichada no se presentó un registro significativo de desempleados con respecto a todo el país (0,0029 y 0,0016%), así como un registro de vacantes (0,0022 y 0,0089%). Teniendo en cuenta que la mayor gestión en registros de desempleados la han realizado los centros de empleo de las CCF (46% de los registros) y el servicio por internet (36%), los resultados deficientes para estos departamentos se aseveran porque presentan limitaciones en estas dos modalidades. Primero, pertenecen a la caja de compensación Comcaja, la cual no ha constituido un centro de empleo, y adicionalmente se encuentra intervenida debido a irregularidades en los manejos. Tampoco hay un centro de empleo de las alcaldías, y el acceso a internet por parte de la población es aún limitado. En síntesis, al mercado de trabajo para estos departamentos le hace falta no solo un ajuste estructural para que se adecúe la oferta y demanda, sino que es indispensable mayor gestión de los centros de empleo para superar los obstáculos que impiden la inserción laboral, por medio de acciones de formación, capacitación y recalificación.
El efecto de los demás departamentos es positivo y se destaca la magnitud de los coeficientes de Bogotá, Antioquia, Valle, Santander, Atlántico y Cundinamarca (entre un rango de 3,41 a 6,58), lugares donde además de ser regiones de mayor concentración de la población, fue donde se inauguraron los primeros centros de empleo. Este comportamiento resulta ser coherente con el desempeño del mercado laboral por departamento. En la figura 11 se presenta los departamentos con mayor número de vacantes, desempleados y colocaciones del SPE en el periodo estudiado.
. Fuente: SPE (2014). Elaboración propia. (Figura disponible a color en la versión electrónica del artículo.)")
Para contrastar estos resultados, como una medida de la oferta de trabajo para el año 2014, la tasa global de participación (TGP), que es la relación entre la población económicamente activa (PEA) y la PET, fue más alta en Bogotá (72,47%), Cundinamarca (71,48%), Santander (68,93%), Nariño (67,6%), La Guajira (66,8%), Tolima (67,24%) y Valle del Cauca (66,8%). Para hacer alusión a la demanda de trabajo se observa la tasa de ocupación. Las cifras más altas se encuentran en Bogotá (66,18%), Cundinamarca (65,47%), Santander (64,42%), La Guajira (63,11%), Nariño (60,5%), Tolima (60,33%), Valle del Cauca (58%) y Antioquia (57,5%). La figura 12 resume las variables de TGP, PEA y PET para los departamentos con los mejores resultados durante el periodo de 2001 a 2014. Estos datos refuerzan los resultados obtenidos de emparejamiento positivo para Bogotá, Antioquia, Valle, Santander y Cundinamarca, ya que tienen mercados de trabajo más dinámicos. Aunque La Guajira, Nariño y Tolima presentan alta TGP, TO y bajo desempleo, su desempeño en el SPE ha tenido menor impacto (coeficientes entre 1,78 a 2,97).
5.1.2Modelo stock-flow, Tasa de Desempleo (TD) y Tasa de Ocupación (TO), 2001-2014. Fuente: DANE (2014). (Figura disponible a color en la versión electrónica del artículo.)")
Los resultados de las estimaciones stock-flow por MCO, MCORE y PA (tabla 3) no soportan la evidencia encontrada por Coles y Muthoo (1998) acerca de que el emparejamiento se presenta entre el stock de desempleados y el flujo de vacantes. Por el contrario, parecería ser que las vacantes stock no producen correlaciones significativas y su impacto es negativo en el emparejamiento. Los desempleados que no se emparejan en el primer mes continúan encontrando incompatibilidades con la demanda de trabajo en el siguiente mes. En este caso no se presenta evidencia de rendimientos constantes a escala7 y la elasticidad de los desempleados cae de 0,81 y 0,62 en los modelos EA y EF a 0,35 (MCO2 stock-flow). Se puede observar que con este modelo la duración media de un desempleado aumenta de 1,32 y 1,38 meses (EA y EF) a 2,24 meses (MCO2) debido a que un trabajador que ha buscado y falla en hacer emparejamiento del stock de vacantes puede ahora emparejar con el flujo de nuevas vacantes.
Finalmente, el método de estimación para incluir las variables stock y flujo por MCO y MCORE está sesgado, lo que genera coeficientes no significativos y magnitudes distintas a las esperadas.
5.1.3Panel dinámicoEn este apartado se pretende corregir el sesgo para Ui,t y para Vi,t causado por la correlación con el ciclo económico que se encuentra en el término de error y que no se controla en los modelos anteriores (MCO, MCORE, MPA, EA, EF; MCO y PA con dummies por departamentos; MCO, PA y MCORE stock-flow). En la parte metodológica de este trabajo se hace alusión de que a pesar que se intenta excluir la endogeneidad con la estimación de efectos fijos, si la varianza de los efectos no observados es muy alta, los estimadores son inconsistentes. Del mismo modo, se menciona que la aproximación a la función de matching con el modelo lineal dinámico propuesto por Arellano y Bond (1991) permite solucionar el problema por medio de la inclusión de restricciones de momentos que usan como variables instrumentales los rezagos de la variable dependiente en nivel (tabla 4). Los estimadores de Arellano y Bover (1995) y Blundell y Bond (1998) adicionan a las restricciones variables instrumentales de los rezagos de la variable dependiente en diferencias.
Modelo de matching panel dinámico lineal Arellano-Bover/Blundell-Bond
| αV | 0,16 (0,0909)** |
| αU | 0,94 (0,2518)** |
| αV,t−1 | 0,32 (0,0966)** |
| αU,t−1 | 0,15 (0,1626) |
| αU,t−2 | 0,64 (0,1625)** |
| αU,t−3 | −0,49 (0,2308)** |
| Mi,t−1 | −0,59 (0,1068)** |
| Mi,t−2 | −0,55 (0,1108)** |
| Mi,t−3 | −0,27 (0,1236)** |
| Mi,t−4 | 0,25 (0,1115)** |
| Mi,t−5 | 0,34 (0,1252)** |
| Mi,t−6 | 0,62 (0,1243)** |
| Wald Test | PWald: 0,00 |
| αU+αV | 1,09 |
| αV/αU+αV | 0,14 |
| αU/αU+αV | 0,86 |
| αU+αV/αV | 7,03 |
| αU+αV/αU | 1,17 |
| αV−1 | −0,84 |
| αU−1 | −0,06 |
Coeficientes significativos al 5%.
α0: constante; αV: elasticidad del matching con respecto a las vacantes; αU: elasticidad del matching con respecto a los desempleados; αV,t−1: vacantes flujo (lvac_1); αU,t−1: desempleados flujo (ldes_1); αU,t−2: desempleados flujo (ldes_2); αU,t−3: desempleados flujo (ldes_3); Mi,t−1: colocaciones (lcol_1); Mi,t−2: colocaciones (lcol_2); Mi,t−3: colocaciones (lcol_3); Mi,t−4: colocaciones (lcol_4); Mi,t−5: colocaciones (lcol_5); αU+αV: suma de estas elasticidades; αV/αU+αV: probabilidad de que sea ocupada una vacante; αU/αU+αV: probabilidad de que un desempleado encuentre trabajo; αU+αV/αV: duración media de una vacante; αU+αV/αU: duración media del desempleado; αV−1: congestión de una vacante; αU−1: congestión de un desempleado.
La inclusión de más variables lleva a una gran cantidad de restricciones de momentos, lo cual, de acuerdo con Arellano y Bond (1991), lleva a un sobreajuste del sesgo (Hujer y Zeissy, 2005); sumado a esto, solo se producen estimadores consistentes si las condiciones de momentos son válidas. Por esta razón, el modelo propuesto por Arellano-Bond no se ajustó a las observaciones por departamento del SPE en Colombia, ya que con el test de Sargan, que prueba si la sobreidentificación de las condiciones de momentos son válidas, se rechaza para los posibles modelos estimados con este método. De esta manera, se reconsideró el modelo y los instrumentos.
En el proceso de ajuste del modelo dinámico se determinó que el modelo más adecuado, mediante la estimación propuesta por Arellano y Bover (1995) y Blundell y Bond (1998), incluye seis rezagos de la variable dependiente, un rezago de Vit y tres rezagos de Uit. Lo anterior, debido a que no se rechaza el test de Sargan (χ2=62,29, p=0,18), lo cual indica que las restricciones de momentos son válidas. Con este método se producen estimadores con menor sesgo cuando el proceso autorregresivo es más largo y con mayor eficiencia que los coeficientes de Arellano y Bond (1991).
Los resultados del panel dinámico muestran que las estimaciones por MCO no corregían los problemas de endogeneidad, y por este motivo el sesgo en los coeficientes sobreestimaba la externalidad positiva de las vacantes y subestimaba la de los desempleados. El coeficiente de las vacantes pasa de 0,23 con efectos fijos a 0,16 en el panel dinámico, y el de los desempleados, de 0,62 a 0,94. Aun así, no se rechaza la hipótesis nula de que los retornos a escala son constantes (p=0,7236). En esta línea de ideas, la probabilidad de que sea ocupada una vacante es del 14% en un periodo de tiempo, y que un desempleado encuentre empleo es del 86%. Por otro lado, la duración media de una vacante pasa de 4 a 7 meses, y de un desempleado, de 1,4 a 1,2 meses.
Una explicación a los resultados la brinda la hipótesis del trabajo de Arango y Ríos (2015), el cual, mediante un modelo de duración parametrizado, muestra que una menor duración del desempleo está asociada con una mayor tasa de vacantes. Es posible sugerir que el mayor número de vacantes con relación a los desempleados registrados en el SPE generó mayores probabilidades de que un trabajador salga del desempleo y mayor congestión entre firmas en la búsqueda de un empleado. No obstante, hace falta probar que el efecto no se causó por un efecto de registro. Esto indica que se debe trabajar en la gestión de servicio a las empresas y en las incompatibilidades con los desempleados. De otra parte, se verifica que las mayores facilidades de acceso a la información —en este caso, el acceso por parte de los desempleados a los centros de empleo y al registro por internet— reducen la duración del desempleo y verifican la existencia de heterogeneidad regional del desempeño del mercado laboral.
A pesar de que el modelo stock-flow por MCO no resultó adecuado para analizar los resultados, en el panel dinámico el rezago de las vacantes (0,32) parece explicar en gran medida los emparejamientos, en alrededor del doble que las vacantes flujo (0,16). Por su lado, los desempleados stock del periodo uno no son significativos, y si se compara con el modelo stock-flow este rezago era negativo, de modo que no se presenta evidencia que los buscadores de empleo stock un periodo atrás aumenten su probabilidad de emparejamiento. No obstante, quienes se encuentran buscando trabajo desde dos periodos atrás tienen mayores probabilidades de emparejarse con alguna vacante flujo (58%), y el coeficiente es positivo (0,64) y significativo. Por consiguiente, el tiempo óptimo para que un desempleado ocupe una vacante parece ser dos meses, ya que si se observa la probabilidad de que un desempleado flujo de tres periodos atrás se empareje, esta es negativa.
El panel dinámico muestra que en el primer año de funcionamiento del SPE las incompatibilidades entre la oferta y la demanda de trabajo están influenciadas por fenómenos estructurales, ya que las características de las vacantes y los desempleados resultan ser menos relevantes y no son significativas, mostrando que las incompatibilidades son más agregadas que por un sector o características específicas. En cambio, los rezagos de la variable dependiente indican que aumentos en el emparejamiento de hasta tres periodos atrás reducen el resultado en el momento t; en contraste, hay un resultado positivo cuatro, cinco o seis periodos atrás (0,25, 0,34 y 0,62) debido a que parecen incrementar la tasa de emparejamientos.
Por último, en cuanto a las variables que tipifican a las vacantes, solo un año de experiencia fue significativo, y su impacto es negativo en el emparejamiento. Esta variable es relevante porque recoge características importantes de la demanda de trabajo del SPE. El 32,8% de las vacantes que solicitaron este requisito ofrecían salarios entre $550.001 y $1.000.000, el 14% de ellas solicitaban un hombre y el mayor número de empleos relacionados a este nivel de experiencia estuvieron en ventas, servicio al cliente y relacionados con trabajos administrativos. Aparte de eso, revela un hecho estilizado, y es que para la mayoría de vacantes requerir menor número de años de experiencia está ligado con solicitar menor nivel de estudios. Las vacantes que no solicitan experiencia o solicitan menos de un año o un año requieren, por lo general, nivel de estudios de bachillerato (61, 78 y 51%, respectivamente). En este sentido, como el mayor número de registros de desempleados se realizó para quienes tienen algún nivel educativo, un año de experiencia tiende a disminuir el emparejamiento.
6Conclusiones y recomendaciones6.1ConclusionesEn esta investigación se estimaron diferentes modelos de matching, y los principales resultados a nivel agregado incluyen: un impacto positivo mayor en el emparejamiento entre la oferta y la demanda de trabajo de un desempleado adicional que el de una vacante; evidencias de rendimientos constantes a escala de la función de matching, y la importancia en la función de los desempleados que llevan dos periodos buscando trabajo y las vacantes que llevan un periodo ofertadas. A nivel departamental, se presentaron evidencias de que son menos relevantes en el emparejamiento nacional los departamentos de Arauca, Guainía, Guaviare, Amazonas y Sucre, y que las fricciones más altas se presentan en las regiones de Vichada y Vaupés. En cuanto a las características de los agentes (vacantes y desempleados), se presenta incompatibilidad para los trabajos que solicitan menor nivel de experiencia y para las desempleados con mayor nivel educativo.
El SPE fue concebido como una red de prestadores de servicios de gestión y colocación de empleo con centros de empleo (Sena, las agencias públicas y privadas de gestión y colocación de empleo, las CCF y las bolsas de empleo) o con acceso por internet (Red Empleo, Elempleo.com y Computrabajo). Este instrumento permitió acceder a información que no se poseía antes acerca de las colocaciones, las vacantes y los desempleados, brindando así los elementos para estimar la función de matching para Colombia.
La función de matching condensa el proceso complejo de intercambio en el mercado de trabajo que produce el número de trabajos formados o contrataciones en cualquier momento del tiempo, en términos del número de trabajadores buscando trabajo, el número de firmas buscando trabajadores y un número pequeño de otras variables (Petrongolo y Pissarides, 2001). La comparación entre los modelos estimados de la función de matching para Colombia muestra un primer resultado importante, y es que existe externalidad positiva más alta para los desempleados que para las vacantes. El hecho de que se registraran más vacantes que buscadores de empleo (el total de vacantes fue de 2.500.307, las cuales exceden en 2.036.409 el número de hojas de vidas registradas) se asocia con una menor duración del desempleo, incidiendo así en que un trabajador adicional genera con mayor probabilidad un nuevo emparejamiento.
Se estimó el modelo lineal de panel dinámico para presentar resultados más robustos y corregir el sesgo en la estimación ocasionado por la correlación entre el ciclo económico, contenido en el término de error, y el número de vacantes y desempleados. Así se llega al segundo resultado importante, y es que la elasticidad con respecto al desempleo en la función de matching (αU) estaba subestimada (pasó de 0,7 con EF a 0,94 con el panel dinámico), mientras que la elasticidad con respecto a las vacantes (αV) estaba sobrestimada (pasó de 0,3 a 0,16). Esto genera evidencia de que quizás los efectos de congestión causados entre las firmas son mayores que los causados por los trabajadores. De acuerdo con este resultado, la probabilidad promedio de que un desempleado encuentre trabajo en un mes es del 86% y la probabilidad promedio de que se ocupe una vacante es del 14%. Asimismo, la medida de congestión de los desempleados (αU−1) es de 0,06, mientras que para las vacantes (αV−1) es de 0,86. La duración media de una vacante se encuentra en 7 meses (αV/(αU+αV)) y la duración promedio de un desempleado entre 1,2 y 1,4 meses (αU/(αU+αV). Evidentemente, si los trabajadores y las vacantes son heterogéneos, las probabilidades de transición son diferentes a lo largo del mercado de trabajo, así como las duraciones promedio.
El tercer resultado a destacar de la comparación entre modelos es que en los modelos de matching agregado, así como en los modelos panel, se encuentra evidencia de retornos constantes a escala del emparejamiento. Por lo cual, es posible afirmar que en general existe complementariedad entre las acciones de las firmas y los trabajadores, con incompatibilidades fuertes en ciertas regiones.
En cuarto lugar, las ocupaciones no constituyen una unidad apropiada de observación en el matching del mercado laboral colombiano porque la mayoría no son relevantes para explicar el emparejamiento. A medida que en los modelos estimados por MCO, MPA, MCORE, EA y EF se incluyeron variables adicionales de las características de las vacantes y los desempleados, los coeficientes cambiaron a valores más razonables de acuerdo con la literatura. Aunque estas variables capturan algunos de los efectos no observados, cuando se corrige la endogeneidad estas variables dejan de ser significativas. De estos resultados se puede inferir que los participantes buscan un nuevo mejor emparejamiento por región en vez de hacerlo por industrias u ocupaciones: si están buscando un nuevo empleo, los individuos usualmente tienen en cuenta primero la ubicación del empleo antes que las vacantes de su ocupación. La ubicación influencia el proceso de emparejamiento por la movilidad imperfecta del trabajo, lo cual sugiere que las políticas regionales que mueven a los empleadores y trabajadores más cerca pueden ser apropiadas (Andrews, Bradley, Stott y Upward, 2004). Este resultado difiere de lo que encontraron Fahr y Sunde (2004) para el caso alemán, en el que las ocupaciones resultaron ser la unidad de análisis, ya que los individuos valoran más el conocimiento en el que se han especializado que las regiones geográficas.
El análisis regional lleva al quinto resultado: el uso de datos panel muestra evidencia de la importancia de la ubicación de los buscadores de empleo y las ofertas de trabajo en las posibles incompatibilidades. Por ello, es razonable asumir que el emparejamiento se realiza en cada «campo». Si bien el SPE se creó como una red, su funcionamiento se da por departamentos y responde a las heterogeneidades regionales. Las regiones de Amazonas, Arauca, Guainía, Guaviare, Putumayo y Sucre han tenido poca influencia en el emparejamiento gestionado por el SPE, y en Vaupés y Vichada se encuentran las mayores incompatibilidades. Las fricciones se explican, por un lado, por la dispersión del desempleo regional, y por otro, por la deficiencia en la gestión de intermediación. Por lo anterior, las políticas de empleo deberían dirigirse a motivar la interacción entre los campos, analizando los requerimientos de los sectores productivos y su compatibilidad con las condiciones de empleabilidad de la fuerza de trabajo.
El siguiente punto a mencionar es que, aunque el método de estimación para incluir las variables stock y flujo por MCO y MCORE están sesgados, lo que genera coeficientes no significativos y magnitudes distintas a las esperadas, el modelo de panel dinámico permite la inclusión de rezagos de las vacantes y desempleados como una proxy de los stocks en el mercado. En este sentido, el séptimo resultado muestra que a un desempleado stock que no encuentra compatibilidad con una vacante en el momento en el que se registra le es posible esperar dos meses para encontrar empleo con una probabilidad positiva; en tercer mes la evidencia es ya negativa. Mientras que para una firma que no se empareja en el periodo en el que se registra existe una probabilidad positiva de encontrar un empleado en el siguiente periodo, para los periodos adicionales no existe evidencia.
Adicional a los resultados anteriores, se destaca que para el año 2014 el mayor número de registros se concentra en personas con algún nivel de educación superior. Las mujeres, que representaron el 58% de los registros, se han visto beneficiadas por la mayor información disponible acerca de los anuncios de vacantes. Esto es importante porque, de acuerdo con las estimaciones por MCO, MPA, MCORE, EA y EF en su primera fase de funcionamiento, el proceso de emparejamiento del SPE en el mercado de trabajo aumenta en los departamentos más desarrollados, con mayor participación femenina y donde han tenido un papel importante las personas con algún nivel educativo superior. La tasa de matching incrementa para la población con alguna cualificación (educación técnica y universitaria) y decrece para la población joven con una menor calificación.
Los datos también muestran que hay una demanda de fuerza de trabajo importante para las vacantes que requieren poco nivel educativo (43% solicita bachillerato, 17% tecnólogo, 7% universitario). Este resultado lo recoge el modelo de panel dinámico por medio del efecto negativo en el emparejamiento de las vacantes que solicitan poco tiempo de experiencia, lo cual está relacionado con poco nivel educativo. En particular, se debe impulsar: a)el mayor registro de las personas que cumplen con los requisitos para el mercado que solicita mano de obra con menor cualificación, ya que en general son personas con acceso limitado a internet, así como a los centros de empleo, y b)el registro de las vacantes para la mano de obra calificada con más experiencia.
Por sector económico, las vacantes de mayor impacto, pero con incompatibilidades altas, han sido las relacionadas con el sector naval, las clasificadas como otros, las del sector de medios, estatal, minería, plástico, consultorías y telecomunicaciones. Esto sugiere que estas empresas están enfrentando las diferencias entre habilidades requeridas y ofertadas o fricciones por la localización de los trabajadores compatibles. En este sentido, una política que brinde capacitación a los trabajadores que hagan sus habilidades compatibles con este tipo de demanda de trabajo puede mejorar el emparejamiento. Dentro de las habilidades que presentan dificultad de emparejamiento está el requisito de idioma inglés, por lo cual las capacitaciones también deben reforzar la posibilidad de que los trabajadores cumplan con este requisito.
Debido a los hallazgos mencionados es posible afirmar que el SPE funciona como un instrumento que contribuye a la intervención en el mercado laboral. El SPE determina un cambio en la posición de la curva vacantes-desempleo en Colombia. Teóricamente, de acuerdo con Pissarides (1979), el establecimiento de un centro de empleo incrementa la eficiencia a pesar de que no se registren todos los desempleados o todas las firmas. El centro de empleo mejora el emparejamiento de todos los pares posibles de trabajadores y trabajos porque crea una externalidad positiva y aumenta los incentivos para que las firmas utilicen la publicidad privada para encontrar un trabajador apropiado. Básicamente, el uso de los dos métodos de búsqueda de empleo (el método aleatorio y a través de la agencia de empleo) puede llevar a un resultado deseable para el mercado de trabajo.
6.2RecomendacionesFinalmente, cuando sea posible acceder a una serie de datos más larga y con mayor información de las colocaciones por sector económico, por especialidades e incluso por individuos, será posible tener más detalle de los resultados de la función de matching a nivel micro y explicar el desempeño macroeconómico, así como los posibles cambios en la curva de Beveridge. Por otro lado, si se accede a nueva información de las políticas activas, se podrá evaluar su impacto en la creación de nuevas contrataciones. Al mismo tiempo, será posible usar métodos estadísticos de estimación más sofisticados y estimar de manera más precisa el modelo stock-flow.Conflicto de intereses
La autora declara no tener ningún conflicto de intereses.
| Modelos de matching estimados | |||||||
|---|---|---|---|---|---|---|---|
| MCO | MCO 2 | MCO 3 | MCG | PA | EA | EF | |
| 1. Constante | 0,16 (0,0620)** | 0,12 (0,0557)** | 0,11 (0,0492)** | 1,30 (0,3929)** | 0,95 (0,5887)** | 1,79 (0,4499)** | 3,84 (0,4256)** |
| 2. Vacantes: lvac | 0,48 (0,0235)** | 0,52 (0,0622)** | 0,57 (0,0441)** | 0,23 (0,0958)** | 0,41 (0,1644)** | 0,26 (0,0507)** | 0,23 (0,0575)** |
| 3. Desempleados: ldes | 0,41 (0,0287)** | 0,36 (0,0268)** | 0,63 (0,2371)** | 0,86 (0,1102)** | 0,96 (0,2401)** | 0,81 (0,3446)** | 0,62 (0,1507)** |
| 4. 1 año de experiencia: lanosexp1 | −0,2 (0,0498)5** | −0,4 (0,0338)0 | −0,3 (0,0293)1** | ||||
| 5. 2 años de experiencia: lanosexp2 | |||||||
| 6. 3 años de experiencia: lanosexp3 | |||||||
| 7. 4 años de experiencia: lanosexp4 | |||||||
| 8. 5 años de experiencia: lanosexp5 | |||||||
| 9. 6 años de experiencia: lanosexp6 | |||||||
| 10. 7 años de experiencia: lanosexp7 | −0,3 (0,1074)4** | ||||||
| 11. 8 años de experiencia: lanosexp8 | |||||||
| 12. 9 años de experiencia: lanosexp9 | |||||||
| 13. 10 años de experiencia: lanosexp10 | |||||||
| 14. 11 años de experiencia: lanosexp11 | |||||||
| 15. 12 años de experiencia: lanosexp12 | |||||||
| 16. 13 años de experiencia: lanosexp13 | |||||||
| 17. 14 años de experiencia: lanosexp14 | |||||||
| 18. 15 años de experiencia o más: lanosexp15omas | 0,40 (0,1552)** | ||||||
| 19. Requiere inglés: lingles | −0,27 (0,0674)** | ||||||
| 20. Requiere frances: lfrances | |||||||
| 21. Requiere español: lespanol | |||||||
| 22. Requiere mandarín: lmandarin | |||||||
| 23. Requiere portugués: lportugues | 0,23 (0,1106)** | ||||||
| 24. Requiere alemán: laleman | |||||||
| 25. Requiere hombre: lhombre | −0,18 (0,0901)** | −0,24 (0,0831)** | |||||
| 26. Requiere mujer: lmujer | 0,29 (0,0886)** | 0,40 (0,0834)** | 0,29 (0,0793)** | ||||
| 27. Requiere joven: ljoven | −0,11 (0,0593)** | ||||||
| 28. Contrato fijo: lcontratofijo | −0,17 (0,0564)** | −0,22 (0,0739)** | |||||
| 29. Contrato indefinido: lcontratoindefin | 0,31 (0,0632)** | 0,25 (0,0891)** | 0,21 (0,0746)** | ||||
| 30. Contrato de aprendizaje: lcontratoaprendi | |||||||
| 31. Contrato de servicios: lcontratoservi | |||||||
| 32. Contrato obra labor: lcontratoobra | |||||||
| 33. Tiempo completo: ltcompleto | |||||||
| 34. Medio tiempo: ltmedio | |||||||
| 35. Contrato por hora: lporhora | −0,19 (0,0595)** | ||||||
| 36. Requiere primaria: lprimaria | −0,15 (0,0502)** | ||||||
| 37. Requiere secundaria: lsecundaria | 0,11 (0,0436)** | ||||||
| 38. Requiere bachillerato: lbachillerato | |||||||
| 39. Requiere técnico: ltecnico | 0,24 (0,0867)** | ||||||
| 40. Requiere universitario: luniversitario | |||||||
| 41. Requiere tecnólogo: ltecnologo | |||||||
| 42. Requiere especialización: lespecializacion | 0,17 (0,0789)** | ||||||
| 43. Requiere maestría: lmaestria | |||||||
| 44. Requiere doctorado: ldoctorado | |||||||
| 45. No requiere estudio: lNingunoestudio | |||||||
| 46. Actividad de la empresa: Cuero: lCuero | −0,34 (0,0889)** | ||||||
| 47. Actividad de la empresa: Naval: lNaval | 0,27 (0,0767)** | ||||||
| 48. Actividad de la empresa: Otros: lOtros | −0,42 (0,0637)** | −0,29 (0,0632)** | −0,41 (0,0960)** | −0,26 (0,0717)** | −0,14 (0,0553)** | ||
| 49. Actividad de la empresa: Pulpa: lPulpa | 0,23 (0,1160)** | ||||||
| 50. Actividad de la empresa: Salud: lSalud | |||||||
| 51. Actividad de la empresa: Medios: lMedios | −0,17 (0,0890)** | −0,12 (0,0498)** | |||||
| 52. Actividad de la empresa: Bebidas: lBebidas | |||||||
| 53. Actividad de la empresa: Consumo: lConsumo | |||||||
| 54. Actividad de la empresa: Estatal: lEstatal | −0,38 (0,0708)** | −0,28 (0,0683)** | −0,32 (0,0749)** | ||||
| 55. Actividad de la empresa: Mineria: lMineria | −0,16 (0,0903)** | −0,32 (0,0968)** | |||||
| 56. Actividad de la empresa: Bebidas: lBD | |||||||
| 57. Actividad de la empresa: Comercio: lComercio | |||||||
| 58. Actividad de la empresa: Estatal: lbf | −0,32 (0,1352)** | ||||||
| 59. Actividad de la empresa: Plastico: lPlastico | −0,19 (0,0858)** | ||||||
| 60. Actividad de la empresa: Quimicos: lQuimicos | 0,18 (0,0814)** | 0,23 (0,0963)** | |||||
| 61. Actividad de la empresa: Textiles: lTextiles | |||||||
| 62. Actividad de la empresa: Alimentos: lAlimentos | |||||||
| 63. Actividad de la empresa: Editorial: lEditorial | |||||||
| 64. Actividad de la empresa: Educativo: lEducativo | 0,19 (0,0841)** | ||||||
| 65. Actividad de la empresa: Productos: lProductos | |||||||
| 66. Actividad de la empresa: Servicios: lServicios | 0,16 (0,0716)** | 0,15 (0,0624)** | 0,23 (0,0891)** | 0,23 (0,0675)** | |||
| 67. Actividad de la empresa: Vehiculos: lVehiculos | |||||||
| 68. Actividad de la empresa: Asegurador: lAsegurador | 0,26 (0,0771)** | 0,18 (0,0771)** | |||||
| 69. Actividad de la empresa: Editorial: lbr | |||||||
| 70. Actividad de la empresa: Energetico: lEnergetico | |||||||
| 71. Actividad de la empresa: Financiero: lFinanciero | |||||||
| 72. Actividad de la empresa: Publicidad: lPublicidad | 0,30 (0,0699)** | 0,22 (0,0578)** | 0,29 (0,0800)** | ||||
| 73. Actividad de la empresa: Tecnologia: lTecnologia | |||||||
| 74. Actividad de la empresa: Transporte: lTransporte | 0,31 (0,0748)** | 0,24 (0,0712)** | 0,38 (0,0812)** | 0,15 (0,0647)** | |||
| 75. Actividad de la empresa: Manufactura: lManufactura | 0,29 (0,0731)** | 0,31 (0,1130)** | 0,20 (0,0667)** | ||||
| 76. Actividad de la empresa: Agropecuario: lAgropecuario | |||||||
| 77. Actividad de la empresa: Construccion: lConstruccion | |||||||
| 78. Actividad de la empresa: Consultorias: lConsultorias | −0,56 (0,0646)** | −0,59 (0,0660)** | −0,55 (0,1013)** | −0,48 (0,1384)** | −0,23 (0,0409)** | −0,13 (0,0499)** | |
| 79. Actividad de la empresa: Organizaciones: lOrganizaciones | |||||||
| 80. Actividad de la empresa: Entretenimiento: lEntretenimiento | |||||||
| 81. Actividad de la empresa: Telecomunicaciones: lTelecomunicaciones | −0,16 (0,0406)** | −0,17 (0,0752)** | −0,11 (0,0303)** | −0,09 (0,0280)** | |||
| 82. Salario Menos De $550.000: lMenosDe550000 | 0,14 (0,0647)** | 0,33 (0,0990)** | 0,21 (0,0456)** | 0,12 (0,0518)** | |||
| 83. Salario Mas De $21.000.000: lMasDe21000000 | −1,55 (0,5810)** | −0,62 (0,2539)** | |||||
| 84. Salario $550.001-$1.000.000: lde550001a1000000 | |||||||
| 85. Salario $1.000.001-$1.500.000: lde1000001a1500000 | 0,20 (0,1052)** | 0,49 (0,1651)** | |||||
| 86. Salario $1.500.001-$2.000.000: lde150000a2000000 | 1,10 (0,3747)** | ||||||
| 87. Salario $2.000.001-$2.500.000: lde2000001a2500000 | |||||||
| 88. Salario $2.500.001-$3.000.000: lde2500001a3000000 | −0,17 (0,0710)** | ||||||
| 89. Salario $3.000.001-$3.500.000: lde3000001a3500000 | 0,14 (0,0702)** | ||||||
| 90. Salario $3.500.001-$4.000.000: lde3500001a4000000 | |||||||
| 91. Salario $4.000.001-$4.500.000: lde4000001a4500000 | |||||||
| 92. Salario $4.500.001-$5.500.000: lde4500001a5500000 | |||||||
| 93. Salario $5.500.001-$6.000.000: lde5500001a6000000 | |||||||
| 94. Salario $6.000.001-$8.000.000: lde6000001a8000000 | |||||||
| 95. Salario $8.000.001-$10.000.000: lde8000001a10000000 | |||||||
| 96. Salario $10.000.001-$12.500.000: lde10000001a12500000 | |||||||
| 97. Salario $12.500.000-$15.000.000: lde12500000a15000000 | |||||||
| 98. Salario $15.000.001-$18.000.000: lde15000001a18000000 | |||||||
| 99. Salario $18.000.001-$21.000.000: lde18000001a21000000 | |||||||
| 100. Título aspirante: ADMI: lADMI | −0,53 (0,1736)** | −0,71 (0,1308)** | −0,76 (0,2316)** | −0,82 (0,1620)** | −0,60 (0,1372)** | ||
| 101. Título aspirante: AGRO: lAGRO | |||||||
| 102. Título aspirante: ANTR: lANTR | |||||||
| 103. Título aspirante: ARQU: lARQU | |||||||
| 104. Título aspirante: ARTE: lARTE | |||||||
| 105. Título aspirante: BACT: lBACT | |||||||
| 106. Título aspirante: BSICASECUNDARIA6: lBSICASECUNDARIA6 | |||||||
| 107. Título aspirante: BIBL: lBIBL | |||||||
| 108. Título aspirante: BIOL: lBIOL | |||||||
| 109. Título aspirante: CICL: lCICL | |||||||
| 110. Título aspirante: CIEN: lCIEN | |||||||
| 111. Título aspirante: COMU: lCOMU | |||||||
| 112. Título aspirante: CONS: lCONS | |||||||
| 113. Título aspirante: CONT: lCONT | 0,56 (0,1501)** | ||||||
| 114. Título aspirante: DEPO: lDEPO | |||||||
| 115. Título aspirante: DERE: lDERE | |||||||
| 116. Título aspirante: DISE: lDISE | |||||||
| 117. Título aspirante: ECON: lECON | |||||||
| 118. Título aspirante: EDUC: lEDUC | |||||||
| 119. Título aspirante: ELEC: lELEC | |||||||
| 120. Título aspirante: ENFE: lENFE | 0,23 (0,1358)** | ||||||
| 121. Título aspirante: FILO: lFILO | |||||||
| 122. Título aspirante: FISI: lFISI | −1,30 (0,3500)** | −0,62 (0,3123)** | −0,58 (0,1518)** | ||||
| 123. Título aspirante: FORM: lFORM | |||||||
| 124. Título aspirante: GAST: lGAST | |||||||
| 125. Título aspirante: GEOG: lGEOG | |||||||
| 126. Título aspirante: GEOL: lGEOL | |||||||
| 127. Título aspirante: GRAF: lGRAF | |||||||
| 128. Título aspirante: INGE: lINGE | −0,28 (0,1755)** | ||||||
| 129. Título aspirante: INST: lINST | 0,53 (0,2104)** | ||||||
| 130. Título aspirante: LENG: lLENG | 0,37 (0,1411)** | ||||||
| 131. Título aspirante: MADE: lMADE | |||||||
| 132. Título aspirante: MARI: lMARI | |||||||
| 133. Título aspirante: MATE: lMATE | |||||||
| 134. Título aspirante: MEDI: lMEDI | |||||||
| 135. Título aspirante: MEDIA1013: lMEDIA1013 | |||||||
| 136. Título aspirante: META: lMETA | |||||||
| 137. Título aspirante: MSI: lMSI | |||||||
| 138. Título aspirante: NOC: lNOC | |||||||
| 139. Título aspirante: NULL: lNULL | |||||||
| 140. Título aspirante: NUTR: lNUTR | |||||||
| 141. Título aspirante: ODON: lODON | |||||||
| 142. Título aspirante: OPTO: lOPTO | |||||||
| 143. Título aspirante: OTRA: lOTRA | |||||||
| 144. Título aspirante: OTRO: lOTRO | |||||||
| 145. Título aspirante: POST: lPOST | 2.54 (1,1104)** | ||||||
| 146. Título aspirante: PRIM: lPRIM | |||||||
| 147. Título aspirante: PSIC: lPSIC | |||||||
| 148. Título aspirante: PUBL: lPUBL | |||||||
| 149. Título aspirante: QUIM: lQUIM | |||||||
| 150. Título aspirante: QUM: lQUM | |||||||
| 151. Título aspirante: SALU: lSALU | |||||||
| 152. Título aspirante: SIN: lSIN | |||||||
| 153. Título aspirante: SOCI: lSOCI | |||||||
| 154. Título aspirante: TCNICALABORAL: lTCNICALABORAL | |||||||
| 155. Título aspirante: TCNICAPROFESIONAL: lTCNICAPROFESIONAL | |||||||
| 156. Título aspirante: TECNOLGICA: lTECNOLGICA | |||||||
| 157. Título aspirante: TERA: lTERA | |||||||
| 158. Título aspirante: VEST: lVEST | |||||||
| 159. Título aspirante: ZOOT: lZOOT | |||||||
| 160. Aspirante femenina: lF | |||||||
| 161. Aspirante masculino: lM | |||||||
| 162. Aspirante casado (a): lCASADOA | −0,73 (0,1631)** | ||||||
| 163. Estado civil nulo: lnuloestadociv | |||||||
| 164. Aspirante separado (a): lSEPARADOA | |||||||
| 165. Aspirante soltero (a): lSOLTEROA | |||||||
| 166. Aspirante en unión libre: lUNINLIBRE | |||||||
| 167. Aspirante viudo (a): lVIUDOA | |||||||
| 168. Aspirante ocupado: locupado | |||||||
| 169. Aspirante no ocupado: lnoocupado | |||||||
| 170. Sin personas a cargo: lpersonasacargo0 | 0,27 (0,0992)** | ||||||
| 171. 1 persona a cargo: lpersonasacargo1 | |||||||
| 172. 2 personas a cargo: lpersonasacargo2 | |||||||
| 173. 3 personas a cargo: lpersonasacargo3 | |||||||
| 174. 4 personas a cargo: lpersonasacargo4 | |||||||
| 175. 5 personas a cargo: lpersonasacargo5 | |||||||
| 176. 6 personas a cargo: lpersonasacargo6 | |||||||
| 177. 7 personas a cargo: lpersonasacargo7 | |||||||
| 178. 8 personas a cargo: lpersonasacargo8 | |||||||
| 179. No personas a cargo: lnopersonasacargo | |||||||
| 180. Nulo personas a cargo: lnulopersonasacargp | 690,10 (184,89)** | −142.68 (16,200)** | |||||
| 181. Si personas a cargo: lsipersonasacargo | |||||||
| 182. Sin personas con discapacidad: lpersonasdiscapacitadas0 | −0,28 (0,0829)** | −0,14 (0,0389)** | |||||
| 183. 1 persona con discapacidad: lpersonasdiscapacitadas1 | |||||||
| 184. 2 personas con discapacidad: lpersonasdiscapacitadas2 | |||||||
| 185. 3 personas con discapacidad: lpersonasdiscapacitadas3 | |||||||
| 186. 4 personas con discapacidad: lpersonasdiscapacitadas4 | |||||||
| 187. 5 personas con discapacidad: lpersonasdiscapacitadas5 | |||||||
| 188. 6 personas con discapacidad: lpersonasdiscapacitadas6 | 1,46 (0,5006)** | 0,92 (0,4486)** | |||||
| 189. 7 personas con discapacidad: lpersonasdiscapacitadas7 | |||||||
| 190. Nulo personas con discapacidad: lnulopersonasdiscapacidad | −442,91 (119.15)** | −142,68 (16,434)** | |||||
| 191. Si personas con discapacidad: lsipersonasdiscapacidad | |||||||
| 192. 1 menor de edad: lmenores1 | |||||||
| 193. 2 menores de edad: lmenores2 | |||||||
| 194. 3 menores de edad: lmenores3 | |||||||
| 195. 4 menores de edad: lmenores4 | |||||||
| 196. 5 menores de edad: lmenores5 | |||||||
| 197. 6 menores de edad: lmenores6 | |||||||
| 198. 7 menores de edad: lmenores7 | |||||||
| 199. 8 menores de edad: lmenores8 | 1,16 (0,2596)** | ||||||
| 200. 9 menores de edad: lmenores9 | |||||||
| 201. 10 menores de edad: lmenores10 | |||||||
| 202. 11 menores de edad: lmenores11 | |||||||
| 203. Sin menores de edad: lnomenores | −0,88 (0,1485)** | ||||||
| 204. Nulo menores de edad: lnulomenores | |||||||
| 205. Nulo menores de edad: lnulomenores2 | −246,6 (141,5)** | ||||||
| 206. Si menores de edad: lsimenores | |||||||
| R2 | R2: 0,456 | R2: 0,8784 | R2: 0,9058 | R2: 0,7170 | R2: 0,7210 | R2: 0,1942 | |
| W ald Test | PWald: 0,00 | PWald: 0,00 | PWald: 0,00 | ||||
| Suma de las elasticidades | 0,89 | 0,88 | 1,20 | 1,09 | 1,37 | 1,07 | 0,85 |
| Probabilidad de que sea ocupada una vacante | 0,53 | 0,59 | 0,47 | 0,21 | 0,30 | 0,24 | 0,27 |
| Probabilidad de que un desempleado encuentre trabajo | 0,47 | 0,41 | 0,53 | 0,79 | 0,70 | 0,76 | 0,73 |
| Duración media de la vacante | 1,87 | 1,70 | 2,11 | 4,71 | 3,36 | 4,12 | 3,65 |
| Duración media del desempleado | 2,15 | 2,42 | 1,90 | 1,27 | 1,42 | 1,32 | 1,38 |
| Congestión vacantes | −0,52 | −0,48 | −0,43 | −0,77 | −0,59 | −0,74 | −0,77 |
| Congestión desempleados | −0,59 | −0,64 | −0,37 | −0,14 | −0,04 | −0,19 | −0,38 |
| Modelos de matching estimados incluyendo a los departamentos | |||
|---|---|---|---|
| MCO 1 | MCO 2 | MPA | |
| 1. Constante | 2,34 (0,2119)** | 2,34 (0,2119)** | 2,36 (0,3558)** |
| 2. Vacantes: lvac | 0,25 (0,0909)** | 0,21 (0,0502)** | 0,21 (0,0466)** |
| 3. Desempleados: ldes | 0,59 (0,2518)** | 0,59 (0,1061)** | 0,60 (0,1103)** |
| 208. ANTIOQUIA: _Iind_2 | 4,60 (0,7406)** | 4,92 (0,4769)** | 4,88 (0,6177)** |
| 209. ARAUCA: _Iind_3 | −0,20 (0,5697) | ||
| 210. ATLANTICO: _Iind_4 | 3,46 (0,6835)** | 3,74 (0,4266)** | 3,69 (0,1695)** |
| 211. BOGOTA: _Iind_5 | 6,22 (0,8273)** | 6,58 (0,5706)** | 6,23 (0,3140)** |
| 212. BOLIVAR: _Iind_6 | 3,12 (0,6177)** | 3,34 (0,3645)** | 3,31 (0,1092)** |
| 213. BOYACA: _Iind_7 | 2,79 (0,6258)** | 3,02 (0,3652)** | 2,95 (0,1225)** |
| 214. CALDAS: _Iind_8 | 2,66 (0,6397)** | 2,90 (0,3738)** | 2,77 (0,1232)** |
| 215. CAQUETA: _Iind_9 | 1,31 (0,5567)** | 1,48 (0,3287)** | 1,49 (0,0857)** |
| 216. CASANARE: _Iind_10 | 1,85 (0,6152)** | 2,07 (0,3560)** | 2,03 (0,1118)** |
| 217. CAUCA: _Iind_11 | 1,76 (0,5963)** | 1,96 (0,3396)** | 1,96 (0,0904)** |
| 218. CESAR: _Iind_12 | 1,76 (0,5753)** | 1,96 (0,3385)** | 1,94 (0,0992)** |
| 219. CHOCO: _Iind_13 | 1,18 (0,5193)** | 1,28 (0,3234)** | 1,25 (0,1152)** |
| 220. CORDOBA: _Iind_14 | 2,41 (0,5961)** | 2,60 (0,3405)** | 2,58 (0,0951)** |
| 221. CUNDINAMARCA: _Iind_15 | 3,19 (0,7090)** | 3,50 (0,4500)** | 3,41 (0,1917)** |
| 222. GUAINIA: _Iind_16 | −0,64 (0,4129) | ||
| 223. GUAVIARE: _Iind_17 | 0,59 (0,4182) | ||
| 224. HUILA: _Iind_18 | 2,53 (0,6155)** | 2,74 (0,3561)** | 2,74 (0,1124)** |
| 225. LA GUAJIRA: _Iind_19 | 1,79 (0,5640)** | 1,94 (0,3280)** | 1,94 (0,0828)** |
| 226. MAGDALENA: _Iind_20 | 2,16 (0,6199)** | 2,38 (0,3599)** | 2,33 (0,1066)** |
| 227. META: _Iind_21 | 3,51 (0,6984)** | 3,80 (0,4329)** | 3,80 (0,1783)** |
| 228. NARIÑO: _Iind_22 | 2,51 (0,5868)** | 2,71 (0,3408)** | 2,68 (0,1022)** |
| 229. NORTE SANTANDER: _Iind_23 | 3,04 (0,6253)** | 3,28 (0,3619)** | 3,19 (0,1149)** |
| 230. PUTUMAYO: _Iind_24 | 0,09 (0,5870) | ||
| 231. QUINDIO: _Iind_25 | 2,29 (0,5874)** | 2,47 (0,3450)** | 2,59 (0,1269)** |
| 232. RISARALDA: _Iind_26 | 3,21 (0,6467)** | 3,46 (0,3885)** | 3,38 (0,1331)** |
| 233. SAN ANDRES: _Iind_27 | 1,48 (0,4099)** | 1,57 (0,3328)** | 1,55 (0,2286)** |
| 234. SANTANDER: _Iind_28 | 4,17 (0,6809)** | 4,44 (0,4199)** | 4,36 (0,1632)** |
| 235. SUCRE: _Iind_29 | −0,42 (0,5995) | ||
| 236. TODA COLOMBIA: _Iind_30 | −1,75 (0,4361)** | −1,63 (0,3689)** | −1,61 (0,2861)** |
| 237. TODO EL PAIS: _Iind_31 | −1,36 (0,4186)** | −1,25 (0,3439)** | −1,25 (0,2492)** |
| 238. TOLIMA: _Iind_32 | 2,95 (0,6079)** | 3,17 (0,3578)** | 3,17 (0,1243)** |
| 239. TOTAL EXTRANJERO: _Iind_33 | −3,94 (0,5788)** | −3,80 (0,3497)** | −3,79 (0,1759)** |
| 240. VALLE: _Iind_34 | 4,52 (0,7433)** | 4,84 (0,4791)** | 4,87 (0,2206)** |
| 241. VAUPES: _Iind_35 | −1,56 (0,4236)** | −1,58 (0,3407)** | −1,60 (0,3014)** |
| 242. VICHADA: _Iind_36 | −1,43 (0,4170)** | −1,42 (0,3362)** | −1,45 (0,2894)** |
| R2 | R2: 0,8606 | R2: 0,8583 | |
| Wald Test | PWald:0,00 | ||
| Suma de las elasticidades | 0,84 | 0,80 | 0,80 |
| Probabilidad de que sea ocupada una vacante | 0,29 | 0,26 | 0,26 |
| Probabilidad de que un desempleado encuentre trabajo | 0,71 | 0,74 | 0,74 |
| Duración media de la vacante | 3,41 | 3,82 | 3,87 |
| Duración media del desempleado | 1,41 | 1,35 | 1,35 |
| Congestión vacantes | −0,75 | −0,79 | −0,79 |
| Congestión desempleados | −0,41 | −0,41 | −0,40 |
** Coeficientes significativos al 5%.
| Pruebas de los modelos de matching estimados | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| MCO | MCO 2 | MCO 3 | MCG | PA | EF | EA | EF AR(1) | EA AR(1) | |
| 1. Test de normalidad: Jarque Bera Ho: normalidad | JB(2)=57,81 | JB(2)=64,73 | JB(2)=58,40 | JB(2)=NA | JB(2)=NA | JB(2)= 10,47 | JB(2)=8,96 | JB(2)=6,65 | JB(2)=8,38 |
| Signif level=0,00 | Signif level=0,00 | Signif level=0,00 | Signif level=NA | Signif level=NA | Signif level=0,0053 | Signif level=0,0113 | Signif level=0,0360 | Signif level=0,0151 | |
De acuerdo con el artículo 36 del decreto número 2852 de 2013, «se entiende por bolsa de empleo la persona jurídica sin ánimo de lucro que presta servicios de gestión y colocación para un grupo específico de oferentes con los cuales tiene una relación particular, tales como: estudiantes, egresados, afiliados u otros de similar naturaleza. La prestación de los servicios de gestión y colocación de empleo por las bolsas de empleo será gratuita para oferentes y demandantes usuarios de los servicios» (Presidencia de la República, 2013).
Centro de Alcaldía de Bogotá, Centro Andi Comfenalco, Centro Cafam, Centro Cafasur, Centro Cajamag, Centro Cajasan, Centro Cofrem-Acacias, Centro Cofrem Meta, Centro Colsubsidio, Centro Combarranquilla, Centro Comfaboy, Centro Comfaca, Centro Comfacasanare, Centro Comfacor, Centro Comfama Antioquia, Centro Comfamiliar Cartagena y Bolívar, Centro Comfamiliar Risaralda, Centro Comfamiliares Caldas, Centro Comfandi-Buga, Centro Comfandi-Cartago, Centro Comfandi-Palmira, Centro Comfandi-Tuluá, Centro Comfaoriente, Centro Comfasucre, Centro Comfenalco Antioquia-Medellín, Centro Comfenalco Antioquia-Rionegro, Centro Comfenalco Antioquia-Urabá, Centro Comfenalco Buenaventura, Centro Comfenalco Palmira, Centro Comfenalco Santander, Centro Comfenalco Valle, Centro Comfiar, Centro Compensar, Centro de Barrancabermeja, Centro Yumbo, Centro de Empleo Cajacopi Atlántico, Centro de Empleo Comfacauca, Centro de Empleo Comfacesar, Centro de Empleo Comfachocó, Centro de Empleo Comfaguajira, Centro de Empleo Comfahuila, Centro de Empleo Comfama-Medellín, Centro de Empleo Comfamiliar Atlántico, Centro de Empleo Comfamiliar de Nariño, Centro de Empleo Comfanorte, Centro de Empleo Comfatolima, Centro de Empleo Comfenalco Quindío, Centro de Empleo Comfenalco Tolima, Centro de Empleo Gobernación del Magdalena, Centro de Empleo de Barranquilla, Centro de Empleo de Cali, Centro de Empleo de Cali-Prospera, Centro de Empleo de Cartagena, Centro de Empleo de Medellín, Centro de Empleo de Villavicencio, Comfandi Buenaventura.
Lista de variables base de datos postulados al SPE: departamento de nacimiento, municipio de nacimiento, país de nacimiento, sexo, estado civil, país de residencia, departamento de residencia, municipio de residencia, nivel educativo (básica secundaria, básica primaria, media —10 y 13—, bachillerato, universitaria, tecnológico, técnica profesional, universitaria, maestría, especialización), experiencia total, fecha de la postulación, centro de empleo, discapacitado, jefe de hogar, personas a cargo, edad, meses desempleado.
Lista de variables vacantes SPE: fuente de información (Servicio de Empleo, Sena, Elempleo.com, Computrabajo), municipio, departamento, empresa, cantidad de vacantes, salario, años de experiencia, fecha de inicio de la vacante, fecha de cierre de la vacante, sector económico, actividad de la empresa, requiere inglés, requiere francés, requiere español, requiere mandarín, requiere portugués, requiere alemán, requiere hombre, requiere mujer, requiere joven, contrato fijo, contrato término indefinido, contrato de aprendizaje, contrato de prestación de servicios, contrato obra labor, tiempo completo, medio tiempo, por horas, requiere experiencia (sí, no), nivel educativo (ninguno, primaria, secundaria, bachillerato, técnico, tecnólogo, universitario, especialización, maestría, doctorado), requiere educación (sí, no), nombre de la vacante.
MCO2: F(1,645)=0,72, p=0,3964, MCO3: F(1,666)=3,38, p=0,0665, MCG: χ2=0,53, p=0,4665, PA: χ2=3,17, p=0,0751, EF: F(1,035)=0,80, p=0,3782, EF AR(1): F(1,280)=1,63, p=0,2025, EA AR(1): χ2=3,12, p=0,0774.
La estimación de mínimos cuadrados ordinarios con variables dummy por departamento (MCO2) no es exactamente igual a la estimación EF porque en MCO2 no se incluyen las variables de número de vacantes de empresas de medios y con salarios menores a $550.000 y número de desempleados sin menores de edad a cargo, las cuales están incluidas en EF.