



La velocidad de diseminación del COVID-19 en el mundo llevó a que los países afectados cerraran sus fronteras y tomaran medidas de distanciamiento social. Después de seis meses de que la enfermedad fuera declarada pandemia, muchos países están tomaron medidas de flexibilización del aislamiento, aunque sin una vacuna o un medicamento capaz de enfrentar la infección por el SARS-CoV-2, la situación podría revertirse en cualquier momento. El objetivo del presente trabajo fue proponer un algoritmo de decisión tendiente a optimizar las detecciones de casos asintomáticos y administrar la cuarentena de una manera estratégica, para así evitar la diseminación del virus y tender hacia una normalidad administrada. Se elaboró una propuesta tentativa de optimización y ordenamiento de pruebas de detección del SARS-CoV-2, basada en el análisis de muestras compuestas reunidas a partir de aquellas tomadas de manera individual a personas asintomáticas que integran cohortes de interés. Se definieron cohortes según su función en la sociedad o grado de vulnerabilidad. El algoritmo contempla variables como la prioridad de la cohorte, el número de integrantes de los grupos de análisis dentro de cada cohorte, el contacto intragrupal e intergrupal, la vulnerabilidad al contagio por la actividad desarrollada y el tiempo transcurrido desde que se realizó la prueba por última vez. Se ilustró la propuesta con cohortes hipotéticas definidas, con un único grupo de análisis para simplificar, y se comprobó que la aplicación de la herramienta permite establecer de una manera racional un orden de prioridad para realizar las pruebas en grupos críticos de la sociedad. Esta herramienta permitirá optimizar recursos y disminuir el impacto de la enfermedad en la salud, la sociedad y la economía de una región.
The rapid spread of COVID-19 throughout the world, has led most of the affected countries to close their borders and implement some form of lockdown. Six months after the pandemic started, many countries made decisions tending to relax the lockdown, although without a vaccine or treatment capable of confronting SARS-CoV-2 infection, the situation could be reversed at any time. In this context, the aim of this work was to propose a decision algorithm that will allow to optimize asymptomatic case detections and strategically manage quarantine to prevent the spread of the virus and drive the transition to a managed new normal. This tentative proposal was developed for optimizing and ordering the number of tests for the detection of SARS-CoV-2, analyzing composite samples (group analysis) combining with those samples individually taken from asymptomatic members of cohorts of interest. Cohorts were defined according to their critical role in society and/or their vulnerability. The algorithm includes variables such as cohort priority, number of cohort members in the analysis groups, intra-and intergroup contact, vulnerability to contagion due to the activity performed, and time elapsed since last testing. The proposed tool was illustrated with defined hypothetical cohorts, in which, for the sake of simplification, only one analysis group was considered. The application of this tool allowed to establish in a rational way a priority order to test critical groups in society. Furthermore, this tool would help to optimize resources, reducing the impact on a region's health, society, and economy.
Los coronavirus son una familia de virus que infectan animales, principalmente aves y mamíferos, en los que causan enfermedades; esto se traduce en pérdidas económicas asociadas a sus actividades productivas1. También pueden saltar de especies e infectar a los seres humanos, en los que causan enfermedades de distinta gravedad (resfrío, bronquitis, neumonía, entre otras), dependiendo del virus en particular y de las condiciones de salud del huésped. Si bien la mayoría de las personas se infectan con estos virus alguna vez en la vida sin padecer grandes consecuencias, algunos coronavirus han causado enfermedades que se han diseminado rápidamente y han provocado brotes y epidemias preocupantes. Como ejemplos se pueden citar el síndrome respiratorio agudo grave (SARS) originado en Yunan, China, en 2001; el síndrome respiratorio de Oriente Medio (MERS) causado por el MERS-CoV, iniciado en Arabia Saudita en 201218, y actualmente el COVID-19, causado por un nuevo coronavirus, denominado SARS-CoV-26.
Se cree que esta nueva enfermedad, COVID-19, surgió en diciembre de 2019 en un mercado de mariscos (en donde se vendían animales exóticos vivos y muertos) ubicado en Wuhan, provincia de Hubei, China, aunque hay algunas controversias sobre esto17. La velocidad de diseminación del virus fue tan elevada que, en poco tiempo, las autoridades de China cerraron la ciudad y dispusieron cuarentena obligatoria. A pesar de ello, el contagio se extendió con rapidez por los países limítrofes primero, y, paulatinamente, por los demás, facilitado por la gran movilidad de viajeros. Tan solo después de casi tres meses de haberse detectado la enfermedad, el 11 de marzo de 2020, la Organización Mundial de la Salud (OMS) la declaró una pandemia.
El rápido avance de la enfermedad puso en evidencia la falta de preparación de los sistemas de salud de la mayoría de los países para afrontar la situación. El número de enfermos sobrepasó con creces las capacidades disponibles y el mundo observó con estupor la creciente cifra de muertos en países desarrollados de Europa. Ante ese panorama y con el objeto de contener el contagio, en la mayoría de los países se fueron estableciendo medidas de distanciamiento social (más conocidas como cuarentena), con distintas modalidades. A la fecha de escritura de este artículo (19 de mayo de 2020), el número de casos confirmados en el mundo se acercaba rápidamente a los cinco millones, de los cuales aproximadamente el 7% correspondía a fallecimientos3. (A la fecha de la corrección de este manuscrito, 15 de setiembre de 2020, hay casi 30 millones de casos confirmados en el mundo y el número de fallecimientos se acerca al millón).
De manera muy temprana (20 de marzo de 2020), el gobierno argentino estableció el “aislamiento social preventivo y obligatorio” (ASPO). Esto permitió evitar el contagio masivo y ganar tiempo para que el sistema de salud pudiera mejorar su capacidad de respuesta. Así, se montaron nuevos hospitales o centros de atención; se adquirieron y/o fabricaron respiradores, elementos de protección personal y demás insumos para poder atender la emergencia, a la vez que se convocó al sistema científico a contribuir en la generación de conocimientos para afrontar la pandemia.
Al igual que en el resto del mundo, la detección del SARS-CoV-2 se lleva a cabo en Argentina mediante pruebas de reacción en cadena de la polimerasa en tiempo real con retrotranscripción (RT-qPCR). En principio, esta prueba se le realiza a cada individuo sospechoso de ser portador debido a que presenta síntomas relacionados con la enfermedad o por conexión epidemiológica, aunque esto ha ido cambiando con la evolución de la pandemia. Otros test moleculares recientemente desarrollados por investigadores argentinos permiten detectar la presencia de fragmentos genéticos y han mostrado resultados prometedores; estos son el NEOKIT y el ELA-CHEMSTRIP (https://www.argentina.gob.ar/noticias/los-test-de-diagnostico-rapido-neokit-covid19-y-ela-chemstrip-empezaron-distribuirse-en-los). La ventaja de estos últimos métodos es que permitirían identificar al virus de manera más rápida, lo que haría posible su detección en un grupo poblacional más grande. A pesar de esto, en la mayoría de los países en desarrollo la capacidad para realizar dichos análisis es reducida, por lo que no se puede evaluar a la población que se supone sana o asintomática (aunque puede incluir individuos contagiosos) y, por lo tanto, se deben tomar medidas generalizadas para controlar la diseminación del virus.
Teniendo en cuenta el contexto sanitario que se vive y que el distanciamiento social ha cumplido su propósito en cuanto al enlentecimiento de la diseminación de la enfermedad, se considera necesario volver paulatinamente y de manera controlada a la actividad. No obstante, se sabe que, en caso de deteriorarse la situación sanitaria, las medidas de flexibilización podrían ser revertidas. Por ello, el objetivo del presente trabajo fue proponer un algoritmo de decisión tendiente a optimizar las detecciones de casos asintomáticos y administrar la cuarentena de una manera estratégica, para así evitar la diseminación del virus y permitir una nueva normalidad administrada.
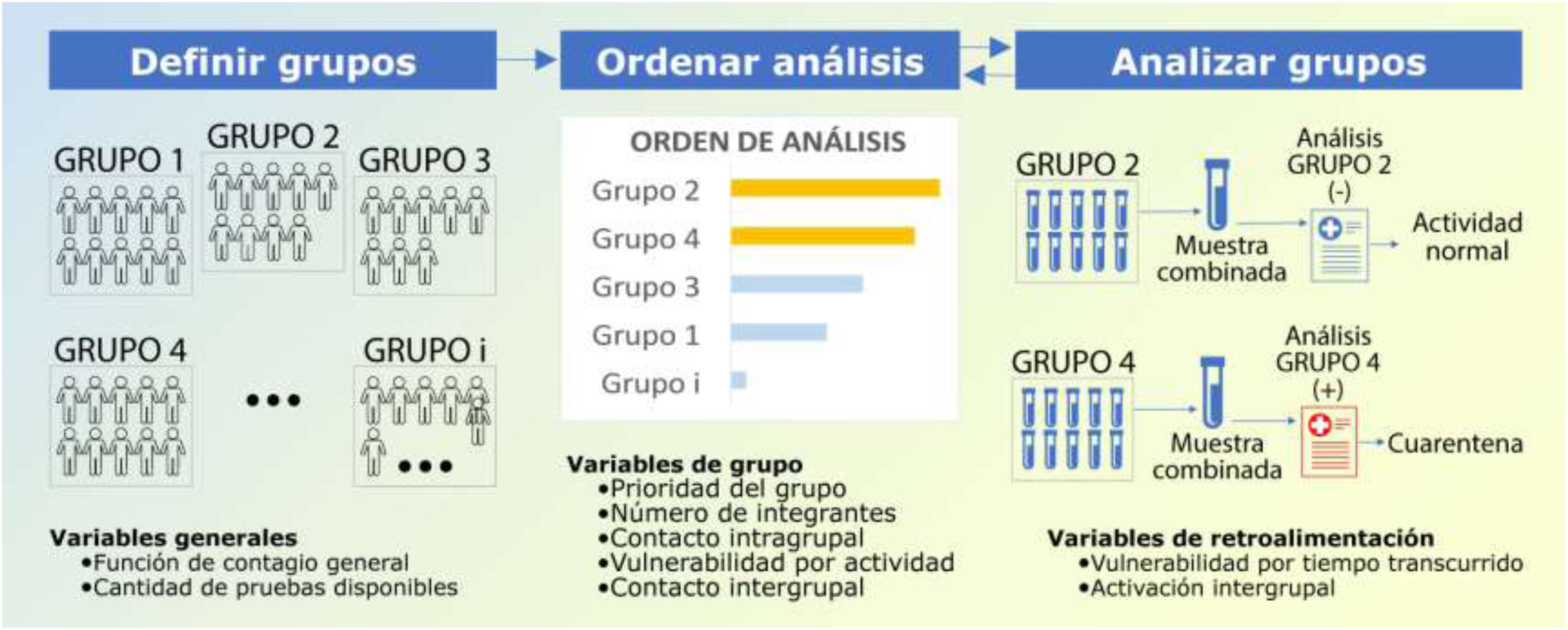
Materiales y métodosSe elaboró una herramienta tentativa para utilizar estratégicamente las pruebas de detección del virus SARS-CoV-2 con el objetivo de controlar la diseminación de la enfermedad en múltiples cohortes12,14. Para ello, y como ya fue indicado por otros autores, se sugirió analizar muestras compuestas (análisis grupal) combinando aquellas tomadas de manera individual a distintas personas asintomáticas que integran la cohorte de interés15,16. De este modo, se podría evaluar la presencia del virus en mayor cantidad de personas simultáneamente, con un ahorro considerable de insumos y de tiempo16. Se propuso comenzar analizando cohortes de personas cuya función fuera crítica para el normal funcionamiento de la sociedad o pertenecientes a sectores muy vulnerables, para luego continuar con cohortes no críticas, según su importancia y grado de vulnerabilidad.
Definición de cohortes críticasLas cohortes que aquí se proponen como críticas y que deberían ser las primeras en someterse a la detección del virus abarcarían los siguientes rubros: salud, seguridad, comercio de bienes de consumo esenciales, tercera edad (geriátricos), servicios e industrias esenciales (fabricación de respiradores, de alimentos, etc.). Es fundamental estudiar a los miembros de estos sectores, al ser potenciales agentes de contagio. El personal de salud (médicos, enfermeros, personal de limpieza, etc.) debería mantenerse en óptimas condiciones, por lo que, además de proveerles los elementos de protección personal, se les debería realizar el análisis de manera sistemática y periódica. Lo mismo vale para el personal de seguridad, ya que está muy expuesto a personas potencialmente infectadas. Los comerciantes de la cadena de suministros, incluyendo los grandes mercados de frutas y verduras, deberían ser analizados regularmente también, ya que una persona infectada podría hacer que se paralice toda la cadena y se generen graves problemas sociales. Otros sectores, como el de trabajadores de la construcción, administrativos, comerciantes de elementos no esenciales, habitantes de zonas residenciales, por mencionar algunos, corresponden a sectores no críticos, por lo que se analizarían cuando la cantidad de pruebas disponibles fuera suficiente, sin comprometer el control de los sectores que sí lo son. Sin embargo, aquellas cohortes no críticas que tengan relación con integrantes de cohortes críticas deberían tener mayor prioridad de análisis.
Realización de los análisisLuego de definir los grupos (o pooles) de las distintas cohortes, se propone tomar muestras individuales (hisopados nasofaríngeos) a todas las personas asintomáticas que los integran. Una parte de la muestra podría ser mezclada en el laboratorio para conformar una muestra compuesta de cada grupo para su análisis. Inicialmente, se debería aproximar la tasa de infectividad y la prevalencia a partir de datos oficiales de los contagios en el lugar geográfico analizado, con el objetivo de definir el tamaño del pool y la metodología de detección por grupos4,7,8,15.
El análisis por pooles de muestras tiene sentido como ahorro de insumos y de tiempo, siempre y cuando la prevalencia sea menor que el 10%7, valor a partir del cual conviene realizar los testeos individuales debido a la alta cantidad de pooles que darían positivos (y tendrían que “abrirse” para estudiar las muestras individuales). El tamaño de los pooles estaría definido por la prevalencia: mientras mayor sea esta, menor será el número de muestras que conformarían un pool. La prevalencia de la enfermedad en la población y también en las cohortes conformadas por personal esencial se consideraría información epidemiológica conocida, que podría calcularse a partir de los casos (individuales) confirmados en los grupos de interés en relación con la población o un tamaño definido de la población.
Cabe aclarar que antes de iniciar la detección mediante pooles de muestras habría que evaluar algunos aspectos metodológicos críticos para asegurar el éxito de esta modalidad diagnóstica. Lo primero que se debería verificar a través de la bioinformática es que las secuencias de los oligonucleótidos que se usarán en la detección son específicas. Luego, correspondería determinar la eficiencia de la amplificación de la reacción de RT-qPCR y verificar que la eficiencia sea máxima, aun a bajas concentraciones de ARN. Además, sería imprescindible determinar el límite de detección del método empleado, ya que de eso dependerá la clasificación de los resultados entre “positivos” y “no detectables (negativos)”. Finalmente, se debería realizar una validación de la técnica de pooles en un grupo de la población y comparar esos resultados con los que se obtienen por testeos individuales para determinar la probabilidad de una inadecuada clasificación de un resultado. Recién al contar con todo el conocimiento mencionado se podría empezar con la detección en pooles de muestras.
El número máximo de individuos que podrían conformar un grupo debería definirse teniendo en cuenta el volumen por muestra individual que se debe agregar a la reacción de detección sin comprometer la sensibilidad, pero permitiendo suficiente carga viral para lograrla2,11. Además, se debería tener en cuenta la prevalencia del virus o la relación entre la cantidad de individuos infectados y la población total analizada para optimizar el tamaño de los grupos desde un punto de vista estadístico11. Estos valores servirían de guía, pero la definición de los grupos debería realizarse de acuerdo con la conveniencia práctica. Por ejemplo, si el tamaño óptimo de grupos fuera 15 personas y en un geriátrico hubiera 10 personas, no sería necesario ni conveniente sumar gente externa al grupo para llegar al valor de tamaño óptimo. Por otro lado, si se analizase a la cohorte de un barrio completo, los grupos deberían contar con el tamaño óptimo y ser seleccionados según su proximidad, con el objetivo de ahorrar recursos.
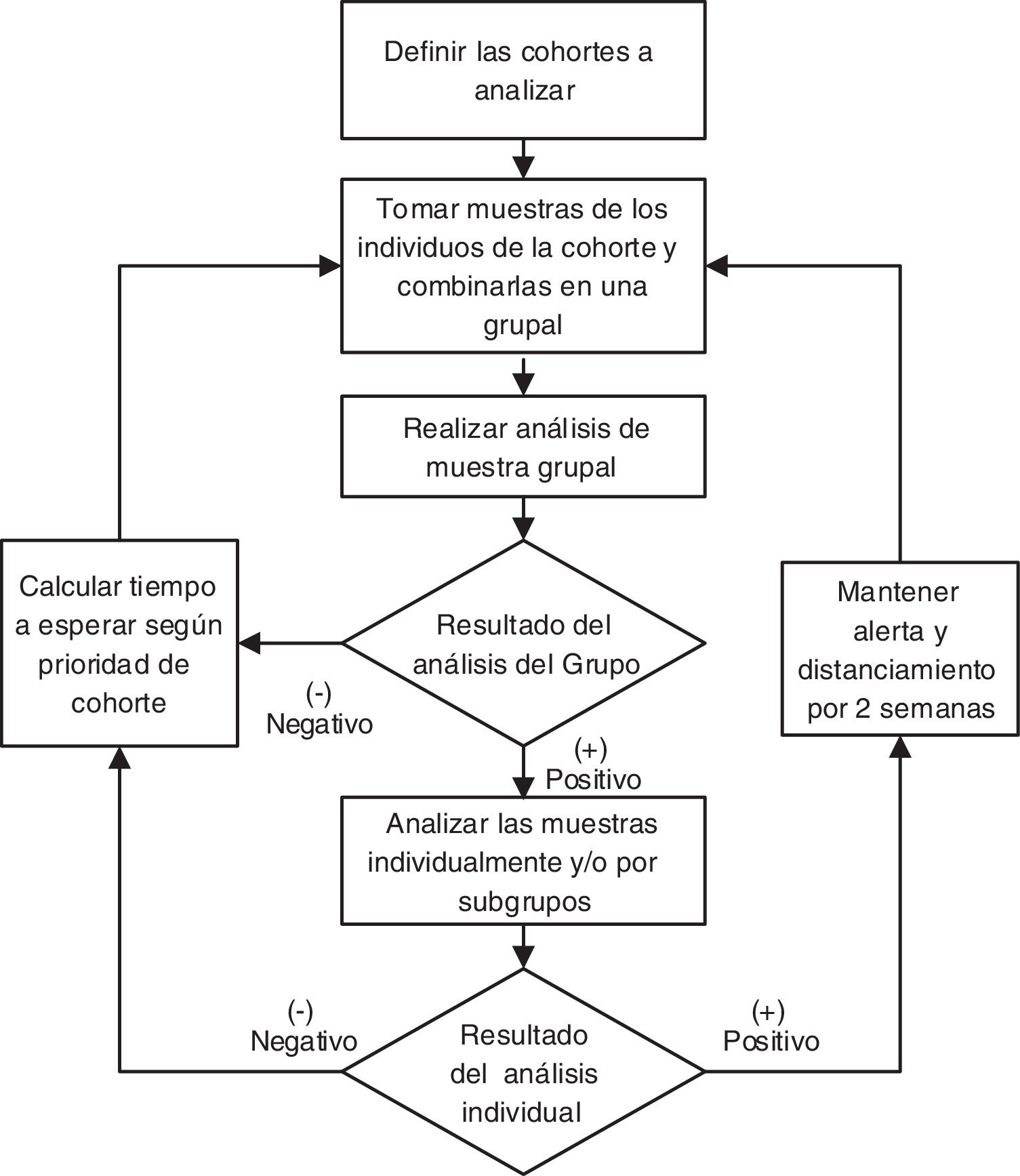
Los grupos con resultados negativos en pruebas de SARS-CoV-2 se deberían analizar cada cierto período de tiempo, el cual tendría que optimizarse según un algoritmo que resolvería el orden de prioridad de cada grupo. De resultar positiva alguna de las pruebas realizadas, se debería aislar al grupo implicado y a las personas con las que hayan tenido contacto estrecho para evitar contagios, hasta completar el análisis. Para ello, el laboratorio debería “abrir los pooles” positivos y profundizar en el análisis de las muestras individuales para identificar al individuo infectado, quien luego debería permanecer aislado4 (fig. 1). Las personas con resultados individuales negativos podrían salir del aislamiento.
Optimización de recursos
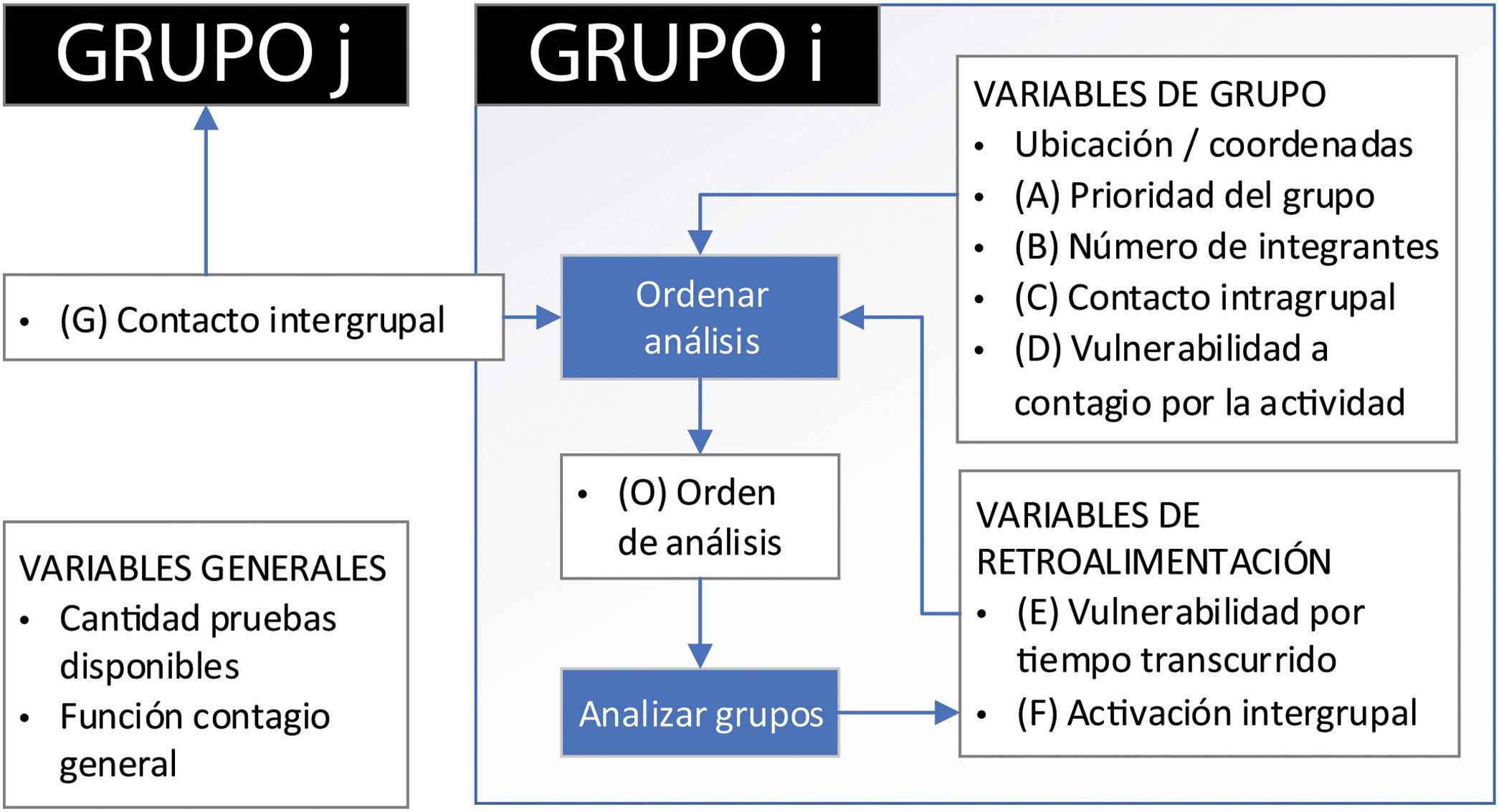
Se desarrolló un algoritmo de decisión para optimizar el testeo estableciendo un orden lógico para su realización, con el fin de modelar y evaluar el comportamiento de la transmisión de la enfermedad, en función del impacto que las cohortes definidas tienen sobre la salud, la seguridad y la economía. Idealmente, se requiere un conocimiento profundo de los integrantes de las cohortes de análisis, por lo que la implementación de este algoritmo a nivel municipal podría resultar más beneficiosa.
Se consideró necesario, aunque no excluyente, incluir las siguientes variables generales en el modelo, ya que se supone que afectan a todos los grupos de todas las cohortes, y estas deberían actualizarse diariamente:
Cantidad de pruebas disponibles: condiciona la cantidad de grupos a los cuales se les puede realizar el análisis y, por lo tanto, la cantidad de cohortes que pueden ser analizadas periódicamente.
Función de contagio general: se define como la relación entre la población que es susceptible de contagiarse, la infectada y la recuperada5,9–11. Se aplica en una zona que abarca a las cohortes analizadas y depende de los valores históricos de esas variables.
Otras variables importantes son las relacionadas con características particulares del grupo a analizar:
Ubicación/coordenadas: permite conocer la localización del grupo en cuestión y puede ser útil para determinar el nivel de contacto intergrupal o ayudar a decidir cuál es la vulnerabilidad al contagio por la actividad. Por ejemplo, podría existir mayor riesgo de contagio para un grupo de seguridad que comparta la ubicación con un grupo de un hospital donde hay individuos positivos para SARS-CoV-2.
Grado de prioridad del grupo (A): alude a la prioridad de un grupo por sobre otros para realizar el análisis. Por ejemplo, grupos de la cohorte del sector salud (médicos y enfermeros dedicados al tratamiento de la enfermedad ocasionada por el SARS-CoV-2) tendrían prioridad de ser analizados por sobre un grupo de una cohorte integrada por personas dedicadas a la producción de bienes de consumo. Para que esta decisión sea lo menos subjetiva posible, se definió una escala de 1 a 10, en la que 1 significa nada prioritario y 10 indica máxima prioridad (tabla 1). Se establecieron rangos específicos para cada grupo hipotético incluido en el algoritmo.
Escala de prioridad de grupos para el testeo
| Prioridad del grupo (A) | Rango |
|---|---|
| Médicos dedicados al tratamiento directo de infectados por SARS-CoV-2 | 7 - 10 |
| Otros médicos | 4 - 8 |
| Miembros de un geriátrico | 6 - 9 |
| Personal de seguridad | 4 - 8 |
| Comerciantes de bienes de consumo | 4 - 6 |
| Industria | 3 - 7 |
| Grupos residenciales | 1 - 6 |
Número de integrantes de cada grupo (B): la cantidad de integrantes de cada grupo se definiría de acuerdo con la conveniencia y debería ser tal que los negativos del análisis sean negativos verdaderos (que no comprometan el límite de detección de la muestra), para evitar que se continúe diseminando la infección. Esto significa que si el análisis de un grupo infectado se hace, por ejemplo, por RT-qPCR, la sensibilidad dependerá de la fase de infección en curso, de la calidad de las muestras extraídas y de la cantidad de muestras individuales que formen parte de la muestra compuesta (a mayor número de muestras, menor cantidad de cada blanco y, por tanto, menor sensibilidad).
Contacto intragrupal (C): esta variable indica el nivel de contacto (relacionado con la distancia social y la frecuencia del contacto) entre los miembros del grupo analizado. Se estableció para su valoración una escala entre 1 y 10, donde valores altos indican mayor contacto y valores bajos menor contacto (al contacto nulo se le adjudicó el valor 1). Los valores de contacto para diferentes distancias pueden coincidir a causa de un cambio en la frecuencia del contacto (tabla 2).
Vulnerabilidad al contagio por la actividad (D): hace referencia al grado de vulnerabilidad de los grupos estudiados dentro de una cohorte a causa de la actividad. Se estableció también en este caso una escala entre 1 y 10, en la que un mayor valor indica mayor nivel de vulnerabilidad al contagio por la actividad (tabla 3). Los valores se podrían obtener a partir de estudios del nivel de contagio en estos grupos y deberían ser actualizados periódicamente.
Vulnerabilidad por el tiempo transcurrido (E): valor calculado (ecuación 1) entre 0 y 10 que indica el riesgo de que exista una infección no detectada en el tiempo transcurrido.
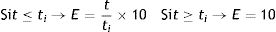
donde t (en días) es el tiempo transcurrido desde la última prueba realizada y ti es el período de incubación máximo del virus (14 días)13.
Activación intergrupal (F): valor que se utiliza para indicar si aumentará (o no) el orden de prioridad a causa de que existe relación con un grupo cuyo análisis dio positivo. Es decir que a causa de la relación intergrupal con grupos infectados, el grupo analizado aumentará su orden de prioridad y, por lo tanto, podría implicar que sea analizado primero. Así F tomará el valor de 1 si la prueba fuera positiva y 0 si resultara negativa (no se activa la relación intergrupal).
Contacto intergrupal (G): variable que establece el nivel de contacto entre grupos distintos (de una misma cohorte o de una diferente). Se definió una escala entre 1 y 10 (al contacto nulo se le adjudicó el valor de 1), donde valores altos indican un contacto más estrecho entre los miembros de distintos grupos (la relación del grupo i con el grupo j se define como relación ij, con i≠j). Los valores de contacto para diferentes distancias pueden coincidir a causa de un cambio en la frecuencia del contacto (tabla 4).
Orden de análisis general (O): valor cuyo resultado permitiría ordenar la prioridad de realización de las pruebas según el modelo actual. Primero, teniendo en cuenta las variables antes establecidas, se calcula un valor local para cada grupo (Li, ecuación 2) y se identifica el mayor valor (Lmáx). Los valores locales representarían la importancia en el análisis y no tienen una escala definida. Luego, para visualizar mejor cuáles grupos deben analizarse primero, se ponderarán los valores locales respecto del valor local máximo (Lmáx) y se obtendrá el orden de prioridad de análisis general para cada grupo (Oi, ecuación 3).
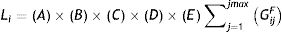
donde j varía desde 1 hasta j máximo (cantidad total de grupos definidos), con i≠j:
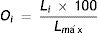
Una vez definido el orden de análisis general de los grupos (O), se podrá realizar la detección siguiendo dicho orden (de mayor a menor) y se actualizará la cantidad de pruebas disponibles. Luego, se retroalimenta la información obtenida al algoritmo con las variables E (vulnerabilidad por tiempo transcurrido) y F (activación intergrupal) (fig. 2).
Alcance temporal y costos
Según la OMS, se espera que esta pandemia se extienda por lo menos por dos años. Aunque ya existen muchos proyectos tanto de vacunas como de tratamientos paliativos, todavía ninguno ha sido implementado de forma eficaz y masiva, por lo que el tiempo de duración de la pandemia puede resultar difícil de predecir. Del mismo modo, el tiempo de aplicación de la herramienta propuesta en este trabajo es difícil de establecer, ya que depende de muchas variables y está íntimamente relacionado con la duración de la pandemia. La herramienta es muy flexible, ya que permite operar con diferentes cantidades de cohortes (según se requiera o según el presupuesto del que se disponga) y también permite hacer los testeos a la frecuencia conveniente para cada localidad en la que se aplique. Por ello, el costo de implementación dependerá, principalmente, de la capacidad de testeo disponible. Otra variable que podría influir en los costos es la posible implementación de test rápidos, los cuales han sido desarrollados y estarán disponibles (principalmente para el sistema de salud) en los próximos meses. Es importante remarcar que el análisis de muestras agrupadas permite obtener una gran cantidad de información y minimizar los costos al analizar numerosas muestras individuales en una sola reacción.
Resultados y discusiónPara ilustrar la aplicación del algoritmo y evaluar su versatilidad y factibilidad se llevó a cabo una simulación. Debido a que no se contaba con datos reales al momento de formular este algoritmo, fue necesario definir algunos de manera arbitraria (intentando acercarnos a la realidad) y realizar diferentes suposiciones.
En primer lugar, se definieron ocho grupos hipotéticos (con fines ilustrativos, ya que en la realidad serán muchos más): GRUPO 1, médicos pertenecientes al hospital 1 (m1); GRUPO 2, personal de seguridad del hospital 1 (s1); GRUPO 3, médicos del hospital 2 (m2); GRUPO 4, personal de seguridad del hospital 2 (s2); GRUPO 5, miembros de un geriátrico (ancianos y personal) que se encuentra en una zona urbana (g1), bajo el supuesto de que no se registraron casos en la zona; GRUPO 6, personal del comercio mayorista 1 de bienes de consumo, ubicado en una zona donde existen otros comercios mayoristas (c1); GRUPO 7, industria de fabricación de insumos ubicada en una zona en donde sí se registraron casos de COVID-19 (i1); GRUPO 8, familia numerosa de un barrio residencial, ubicado en una zona urbana donde no se registraron casos de COVID-19 (r1). Para cada grupo se estableció una cantidad específica de integrantes (tablas 5 y 6).
Ejemplo hipotético de aplicación del algoritmo de decisión desarrollado
| Grupos | m1 | s1 | m2 | s2 | g1 | c1 | i1 | r1 |
|---|---|---|---|---|---|---|---|---|
| Prioridad del grupo (A) | 10 | 7 | 8 | 7 | 10 | 5 | 7 | 3 |
| Número de integrantes de cada grupo (B) | 7 | 6 | 10 | 6 | 8 | 7 | 9 | 2 |
| Contacto intragrupal (C) | 8 | 6 | 8 | 6 | 9 | 7 | 7 | 10 |
| Vulnerabilidad al contagio por la actividad (D) | 10 | 6 | 8 | 4 | 5 | 6 | 3 | 2 |
| Días transcurridos desde el análisis | 6 | 6 | 12 | 14 | 16 | 13 | 10 | 20 |
| Vulnerabilidad por tiempo transcurrido (E)a | 4,3 | 4,3 | 8,6 | 10 | 10 | 9 | 7 | 10 |
| Orden de análisis local (Li)b | 864.000 | 38.880 | 526.629 | 282.240 | 576.000 | 177.450 | 94.500 | 24.000 |
| Orden de análisis general (Oi)c | 100 | 5 | 61 | 33 | 67 | 18 | 9 | 3 |
| Orden de prioridad de pruebas | 1 | - | 3 | 4 | 2 | 5 | 6 | 7 |
a,b,c Calculados mediante las ecuaciones 1, 2 y 3.
Grupos definidos. m1: médicos del hospital 1; s1: seguridad del hospital 1; m2: médicos del hospital 2; s2: seguridad del hospital 2; g1: miembros en el geriátrico 1; c1: personal del comercio 1; i1: personal de la industria 1; r1: vecinos 1 de la zona residencial. En negritas se marca el grupo que se supone infectado.
Ejemplo hipotético para ilustrar una matriz de relaciones intergrupales
| Grupos | m1 | s1 | m2 | s2 | F |
|---|---|---|---|---|---|
| m1 | NA | 6 | 2 | 1 | 0 |
| s1 | 6 | NA | 1 | 2 | 1 |
| m2 | 2 | 1 | NA | 6 | 0 |
| s2 | 1 | 2 | 6 | NA | 0 |
F: la activación intergrupal (1: infectado, 0: no infectado); NA: no aplica el contacto intergrupal para la relación de un grupo consigo mismo.
Grupos definidos. m1: médicos del hospital 1; s1: seguridad del hospital 1; m2: médicos del hospital 2; s2: seguridad del hospital 2.
En negritas se marca el grupo que se supone infectado.
Con respecto a la variable prioridad del grupo (A), se asignó un valor de 10 a los médicos del hospital 1 (m1) (que registra mayor cantidad de pacientes con COVID-19) y 9 a los del hospital 2 (m2). Los altos valores asignados se deben a que ambos son grupos prioritarios (al formar parte de la cohorte “médicos de hospitales”), en concordancia con su función de atender a personas con COVID-19. Para los grupos de la cohorte seguridad, se estableció un valor de 6 tanto para s1 como para s2, ya que a pesar de que son necesarios, podrían ser reemplazados si sucediese un contagio. Los miembros del geriátrico g1 son un grupo de alto riesgo, debido a que la mortalidad por contagio es mucho mayor en este grupo, por lo que se adjudicó un valor de 8. El comercio mayorista de bienes de consumo c1 tiene una prioridad de 4 (relativamente baja), ya que existen otros comercios mayoristas alternativos en la zona. Para la industria i1, el valor asignado fue 7, porque se encuentra en una zona de riesgo entre moderado y alto. Al grupo residencial r1 se le asignó un valor de 3, ya que se encuentra en una zona urbana con tránsito moderado, donde no se registraron casos.
Para la variable vulnerabilidad al contagio por la actividad (D), el hospital h1 es uno de los designados para tratar a personas con coronavirus, mientras que el hospital h2 no lo es. Por lo tanto, se adjudicó un puntaje de 10 a m1 y de 8 a m2 para ponderar el riesgo de contagio. Por la misma razón, el riesgo de contagio de s1 se estableció en 6 y el de s2 en 4. Aunque la actividad de g1 no es riesgosa, sí se trata de un grupo muy vulnerable, por lo que se le asignó un valor de 5. El grupo c1 se encuentra en una zona libre de COVID-19 y tiene un valor de 6 debido a que existe un flujo considerable de personas que no corresponden a la zona y un contacto cercano a los clientes. Finalmente, el grupo i1 desarrolla una actividad en contacto mínimo con personas externas, por lo tanto, se le asignó un valor de 3.
Continuando el análisis con la variable contacto intragrupal (C), los médicos m1 tienen reuniones diarias en el hospital 1 y con una frecuencia media trabajan en conjunto y a distancias menores de 2 metros. Esta suposición es válida también para los médicos m2 del hospital 2. De aquí que el contacto intragrupal para ambos casos fue puntuado con 8. El contacto entre los individuos de los grupos de seguridad (s1 y s2) se da, principalmente, a una distancia menor de 2 metros y con baja frecuencia, en situaciones relacionadas con mantener el orden, por lo que se asignó un valor de 6. Los ancianos y personal del geriátrico (g1) se reúnen a distancias entre 1 y 3 metros y a una frecuencia alta, por lo que se asignó un valor de 9. El personal tanto de c1 como de i1 se reúne a frecuencia y distancia media, por lo que se asignó en ambos casos un valor de 6. Finalmente, el grupo residencial r1 se reúne a distancias bajas y con frecuencia alta, por lo que se le asignó un valor de 10.
Terminando con las variables, el contacto intergrupal (G) de los médicos m1 y m2 es a frecuencia baja y a distancias mayores de 4 metros debido a solicitudes de participación especial o en cursos de actualización, por lo que el valor para la relación intergrupal en este caso es 2. Esta suposición es válida también para la relación entre los grupos de seguridad s1 y s2. El resto de las relaciones intergrupales es inexistente, por lo que su valor se estableció en 1 (tabla 5).
Suponiendo que en el último análisis realizado 6 días antes, al grupo s1 le hubiera dado positivo (tabla 5), habría dos consecuencias directas. En primer lugar, ese grupo debería enviarse a aislamiento preventivo hasta que se pueda identificar al individuo infectado (o a los individuos infectados), para lo cual se tendría que “abrir” el pool y habría que analizar las muestras individuales, y luego proceder a los correspondientes reemplazos laborales (fig. 1). En segundo lugar, esto ocasionaría un cambio en el orden de análisis para los otros grupos por el contacto intergrupal. En este ejemplo no se analizó al grupo de seguridad s1 por subgrupos, ya que se prevé suficiente disponibilidad de reemplazos hasta que s1 vuelva de la cuarentena; no obstante, si eso se quisiera hacer, deberían seguirse los pasos establecidos (fig. 1).
Se puede observar, entonces, que se debería realizar el análisis en primer lugar a los médicos del hospital 1 (m1; Oi = 100), seguido por el grupo del geriátrico 1 (g1; Oi = 67), los médicos del hospital 2 (m2; Oi = 61), la seguridad del hospital 2 (s2; Oi = 33), comercio mayorista (c1; Oi = 18), industria (i1; Oi = 9) y, finalmente, al grupo residencial (r1; Oi = 3). Se debe tener en cuenta que el grupo de seguridad s1 se encontraría en el sexto día del aislamiento preventivo (cuarentena), por lo que debería ser analizado nuevamente una vez transcurrido el período de incubación del virus (tabla 5). Si bien el grupo médico del hospital 1 (m1) tuvo un contacto intergrupal con el grupo de seguridad infectado (s1), transcurrieron 6 días desde su último análisis, mientras que fueron 12 días para el grupo m2 del hospital 2. Además, el hecho de que no existan contagios grupales en el hospital 2 no implica que ese hospital no esté recibiendo personas enfermas que podrían contagiar a los grupos analizados en dicho hospital. Si, en cambio, el grupo de seguridad s1 hubiese dado negativo, se debería realizar el análisis, en primer lugar, al grupo del geriátrico 1 (g1; Oi = 100), seguido por los médicos del hospital 2 (m2; Oi = 91), comercio mayorista (c1; Oi = 26), la seguridad del hospital 2 (s2; Oi = 25), los médicos del hospital 1 (m1; Oi = 25), industria (i1; Oi = 14), el grupo de seguridad s1 (s1; Oi = 7), y, finalmente, al grupo residencial (r1, Oi = 4).
Este ejemplo permite visualizar el potencial para el ahorro en pruebas cuando se analiza la diseminación del COVID-19 en un determinado municipio. Se podrían analizar hasta 55 individuos distribuidos en 8 grupos a través de 8 pruebas, lo que significaría un ahorro del 85,45% de las pruebas si se procede con el método de análisis grupal, respecto del individual.
En otro trabajo de investigación en donde se realizaron experimentos a través de RT-qPCR, se encontró que se pueden analizar grupos de hasta 32 individuos, con un 10% de falsos negativos para la presencia de SARS-CoV-214. Por otro lado, Hogan et al. (2020) analizaron mediante la técnica de RT-qPCR muestras almacenadas en un hospital tomadas de personas en cuyas historias clínicas se consignaban síntomas de infección por coronavirus, en grupos de hasta 10 individuos. Tres de los 292 grupos analizados por estos autores dieron resultados positivos para infección con SARS-CoV-2. Con los análisis individuales, luego se comprobó que dos de los tres grupos estaban integrados por personas infectadas12. Sin embargo, como la calidad de las pruebas de detección y los protocolos varían internacionalmente, se recomienda realizar experimentos independientes antes de llevar a la práctica la propuesta de este trabajo.
El algoritmo presentado permite establecer un orden racional de prioridad para realizar el testeo de grupos críticos de la sociedad (fig. 3). Como una limitación relevante de esta propuesta, cabe destacar que la asignación de los valores de las variables de los grupos se basa en el criterio y la experiencia del operador de la herramienta, además de las particularidades epidemiológicas analizadas. Por esta razón, de aplicarse esta herramienta, su potencial irá aumentando a medida que avance la infección en la comunidad y el conocimiento de las particularidades que con ella se presentan.
Conclusiones
Mediante este análisis simulado demostramos que el algoritmo propuesto es una opción interesante y puede ser una herramienta para el control de la diseminación del SARS-CoV-2, por lo que merece ser explorada y, eventualmente, desarrollada, con el fin último de lograr una mejor administración del distanciamiento social empleando la menor cantidad del insumo limitante (pruebas de detección). Esta herramienta presenta un alto potencial para mitigar los problemas que genera la pandemia, como así también para disminuir la probabilidad de rebrotes cuando se cuenta con recursos escasos, con la consiguiente reducción del impacto en la salud, la sociedad y la economía de una región.
FinanciaciónEste trabajo fue financiado por la Agencia Nacional de Promoción Científica Tecnológica, ANPCyT (PICT 2017-1909). M. Rivero es becario doctoral del Consejo Nacional de Investigaciones Científicas y Tecnológicas (CONICET). Consejo Nacional de Investigaciones Científicas y Técnicas (CONICET)(PIP 332).
Conflicto de interesesLos autores declaran no tener ningún conflicto de intereses.
