



El aprendizaje computacional (machine learning en inglés) estudia la construcción de sistemas capaces de aprender a partir de datos1. Esto incluye una gran variedad de sistemas, desde sistemas de visión por ordenador hasta sistemas para detectar correo no deseado (spam). En todos los casos, un sistema que aprende debe ser capaz de generalizar, es decir, de encontrar patrones y regularidades en los datos que le permitan desempeñarse bien en datos que no ha observado previamente. Existen 2 tipos principales de modelos de aprendizaje computacional, modelos de aprendizaje supervisado y modelos de aprendizaje no supervisado. En el aprendizaje supervisado se busca inducir modelos capaces de predecir el valor de ciertas variables dependientes a partir de variables independientes. Un ejemplo de problema de aprendizaje supervisado es el problema de clasificación, en el cual la variable dependiente corresponde a un atributo que indica a qué clase (por ejemplo, enfermo o control en el caso de un problema de diagnóstico médico) pertenece una muestra particular. En los modelos de aprendizaje no supervisado no hay una distinción entre variables dependientes y no dependientes, en este caso se pretende encontrar la estructura subyacente que explique la estructura de los datos. El ejemplo más representativo de aprendizaje no supervisado es el análisis de conglomerados (clustering en inglés) en el cual el objetivo es encontrar grupos de datos que compartan características similares.
En medicina los modelos de aprendizaje computacional se han aplicado con éxito tanto a problemas motivados por la práctica clínica, como el diagnóstico asistido por ordenador, como a problemas de análisis de datos de investigación médica básica. En los últimos años ha habido un gran auge en la investigación y desarrollo de modelos de aprendizaje computacional aplicados al diagnóstico médico de diversas enfermedades y condiciones médicas.
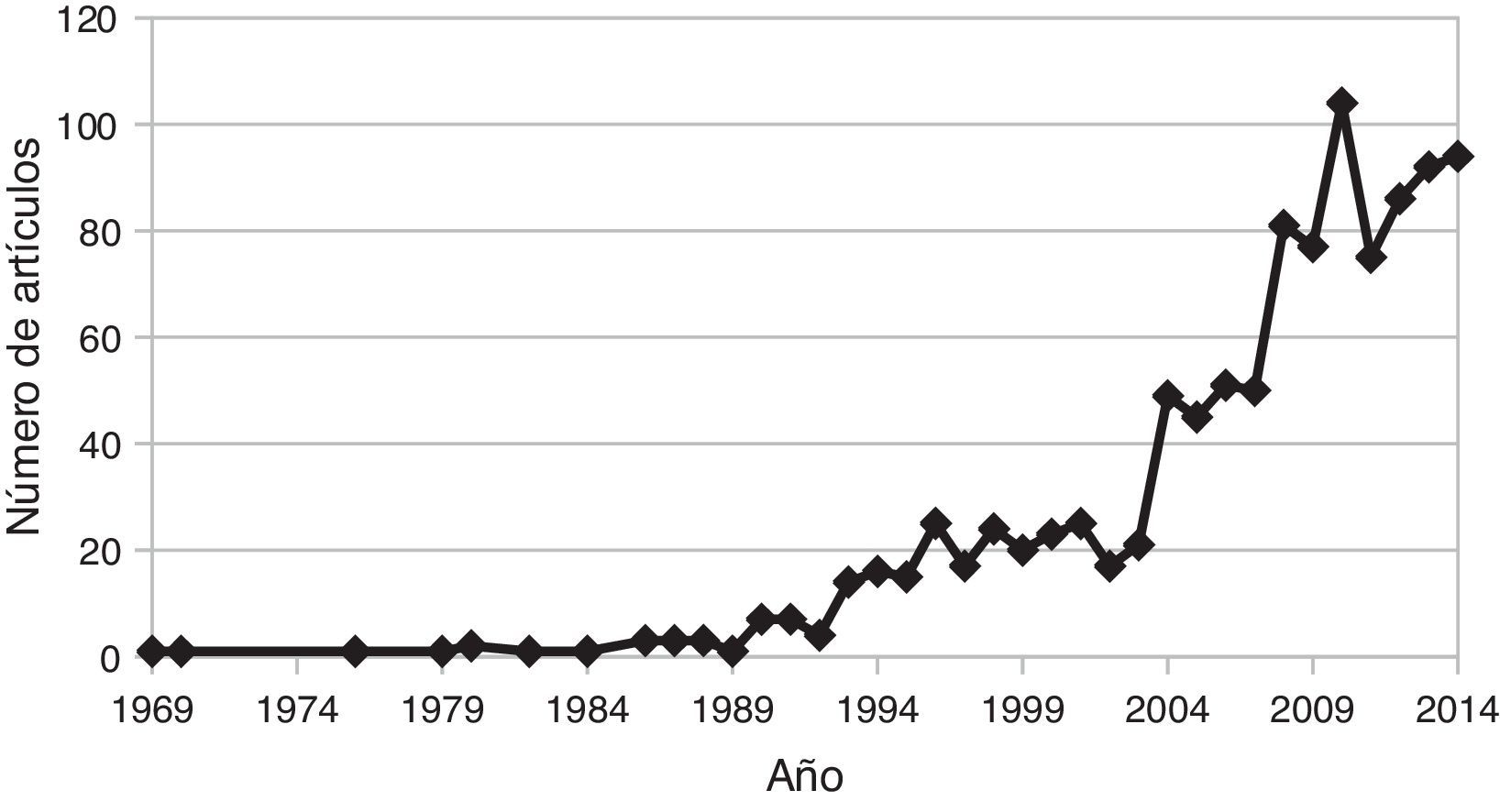
La figura 1 muestra el número de artículos publicados entre 1969 y 2014 sobre aplicaciones de técnicas de aprendizaje computacional al diagnóstico médico. Como se puede observar, hay una tendencia creciente, la cual se ha acelerado durante los últimos 10 años, alcanzando un volumen de cerca de 100 artículos sobre el tema por año. Los tipos de problemas de diagnóstico médico abordados con estas técnicas cubren prácticamente todas las especialidades de la medicina2, algunos ejemplos incluyen: diagnóstico de glaucoma3, identificación de enfermedades cardiovasculares4, detección de la enfermedad de Alzheimer5 y detección del cáncer de próstata6.

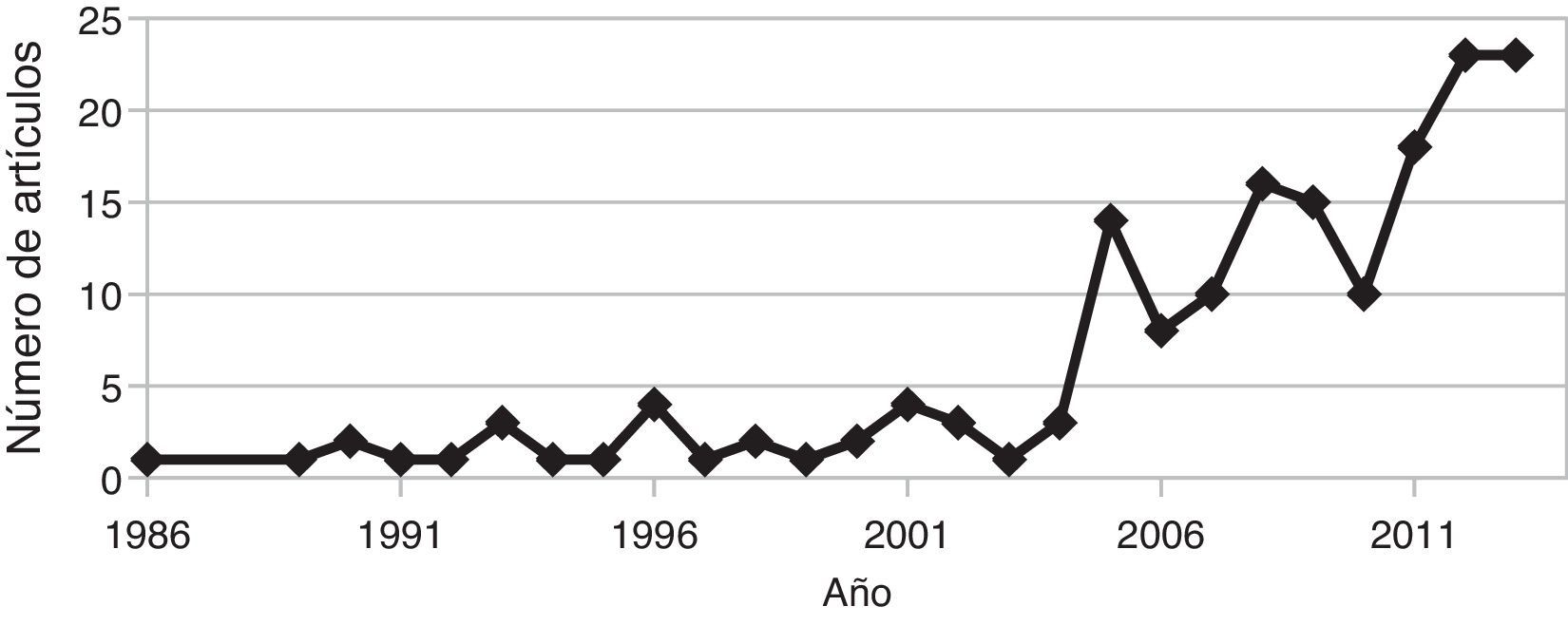
La reumatología no ha sido ajena a este fenómeno, pues también ha habido un incremento en las investigaciones sobre la aplicación de modelos de aprendizaje computacional al diagnóstico de enfermedades reumáticas. La figura 2, muestra el número de publicaciones sobre el tema desde 1986 hasta el 2014, evidenciando un aumento de las mismas en los últimos años. Ejemplos de aplicaciones incluyen: diagnóstico de la artritis reumatoide7,13, predicción de la respuesta al tratamiento con certolizumab pegol en pacientes con artritis reumatoide8, diagnóstico de lupus eritematoso sistémico9, predicción de la respuesta terapéutica en pacientes con artritis poliarticular juvenil idiopática10, diagnóstico del síndrome de Sjögren11, predicción de complicaciones pulmonares y supervivencia de largo plazo en esclerosis sistémica12, entre otros.

Siguiendo esta línea de trabajo, la presente edición de la Revista Colombiana de Reumatología incluye un artículo de investigación que aborda la aplicación de modelos de aprendizaje computacional para la clasificación de pacientes con artritis reumatoide y controles, a partir de datos genéticos, serológicos y clínicos13. Además de los modelos de clasificación, el trabajo logra establecer relaciones entre marcadores genéticos y fenotipos (endofenotipos).
Los autores aplican métodos de aprendizaje supervisado como las redes neuronales y las redes bayesianas, y de aprendizaje no supervisado como el método de agrupamiento k-medias. Adicionalmente, para la identificación de endofenotipos los autores utilizaron alineamiento de secuencias de aminoácidos.
Los resultados presentados en el artículo son bastante prometedores: los modelos predictivos logran un alto desempeño en la tarea de discriminar entre pacientes con artritis reumatoide y controles, con sensitividad y especificidad de hasta el 92,3% y el 93,3%, respectivamente. Por otro lado, el análisis de conglomerados basado en k-medias permitió establecer 2 grupos de pacientes con diferentes niveles de severidad. Finalmente, el análisis de secuencias de aminoácidos reveló secuencias comunes en pacientes con desenlaces iguales.
