









Este artículo presenta el diseño de un algoritmo basado en redes neuronales en tiempo discreto para su aplicación en robótica móvil. También se muestran las condiciones de estabilidad y una evaluación de los resultados.
El robot móvil en el cual se aplicó el algoritmo neural posee 2controladores en cascada, uno para la cinemática y otro para la dinámica; ambos controladores están basados en la linealización por realimentación. El controlador de la dinámica solo posee la información de la dinámica nominal (parámetros). La red neuronal de compensación se adapta para reducir las perturbaciones ocasionadas por las variaciones en la dinámica y las incertidumbres existentes en el modelo, y esas diferencias en la dinámica entre el modelo nominal y el real son aprendidas por una red neuronal RBF (funciones de base radial) usando el filtro de Kalman extendido para el ajuste de los pesos de salida de las funciones de base radial. El algoritmo de compensación neuronal es eficiente, ya que el costo computacional es menor que el necesario para aprender la totalidad de la dinámica y al mismo tiempo posee la robustez que podría aprender la totalidad de la dinámica en caso de fallo del controlador dinámico. En este trabajo se muestra un análisis de estabilidad del algoritmo neuronal adaptable, y además se comprueba que los errores de control están acotados en función del error de aproximación de la red neuronal RBF. Se muestran resultados de experimentación sobre un robot móvil que prueban la viabilidad práctica y el rendimiento para el control de los mismos.
This paper presents the design of an algorithm based on neural networks in discrete time for its application in mobile robots. In addition, the system stability is analyzed and an evaluation of the experimental results is shown.
The mobile robot has two controllers, one addressed for the kinematics and the other one designed for the dynamics. Both controllers are based on the feedback linearization. The controller of the dynamics only has information of the nominal dynamics (parameters). The neural algorithm of compensation adapts its behaviour to reduce the perturbations caused by the variations in the dynamics and the model uncertainties. Thus, the differences in the dynamics between the nominal model and the real one are learned by a neural network RBF (radial basis functions) where the output weights are set using the extended Kalman filter. The neural compensation algorithm is efficient, since the consumed processing time is lower than the one required to learning the totality of the dynamics. In addition, the proposed algorithm is robust with respect to failures of the dynamic controller. In this work, a stability analysis of the adaptable neural algorithm is shown and it is demonstrated that the control errors are bounded depending on the error of approximation of the neural network RBF. Finally, the results of experiments performed by using a mobile robot are shown to test the viability in practice and the performance for the control of robots.
Las redes neuronales (RN) poseen un amplio campo de aplicación, que incluye la clasificación, la identificación y el control de sistemas. En este trabajo se presenta el diseño de un algoritmo basado en redes neuronales RBF (funciones de base radial) para su aplicación en robótica móvil, cuyo objetivo es mejorar el control de trayectorias en tiempo real, pero debido a deslizamientos, perturbaciones, ruidos y errores de sensado y medición (odometría) resulta muy difícil reducir los errores entre la posición deseada y la posición real del robot. Asimismo, lograr controlar eficazmente un robot móvil para realizar el seguimiento preciso de una trayectoria deseada es aún un problema abierto en robótica.
Se han publicado varios estudios en relación con el diseño de controladores para el seguimiento de trayectoria de robots móviles. La mayoría de los controladores diseñados hasta el momento se basan únicamente en la cinemática, como los controladores presentados en Wu et al. [1], Künhe et al. [2] y en Gracia y Tornero [3].
Sin embargo, para realizar tareas que requieren movimientos de alta velocidad o transporte de cargas pesadas es importante tener en cuenta, además de la cinemática, la dinámica del robot. Más aún: el controlador debería contemplar las incertidumbres o los eventuales cambios en esa dinámica sin degradar el desempeño. A modo de ejemplo, en el caso de transporte de carga, las características dinámicas como la masa, el centro de masa y la inercia varían con la carga. Para mantener un buen desempeño, el controlador debe ser capaz de adaptarse a este tipo de cambios. Esta capacidad de adaptación también es importante debido a la dificultad de modelar el sistema con exactitud, aun cuando no se verifiquen cambios dinámicos de tarea a tarea.
Otros controladores de seguimiento que contemplan la incertidumbre en la dinámica del robot son desarrollados por Liu et al. [4] y Dong y Guo [5], cuyo desempeño es mostrado a través de simulaciones. Otros trabajos similares se pueden ver en Liyong y Wei [6] y en Chaitanya y Sarkar [7]. Das y Kar [8] presentan un controlador de lógica difusa adaptable donde la incertidumbre del sistema, que incluye variación de parámetros del robot móvil y no linealidades desconocidas, se estima por un sistema de lógica difusa cuyos parámetros son sintonizados en línea.
En Fukao et al. [9] se propone el diseño de un controlador de seguimiento de trayectoria adaptativo para generar pares motores sobre la base de un modelo dinámico cuyos parámetros son desconocidos.
En Velagic et al. [10] se presenta el diseño de un controlador adaptable directo utilizando RN recurrentes. La eficiencia de la técnica de control es investigada sobre el modelo cinemático del robot móvil.
Otros tipos de controladores de seguimiento de trayectoria que consideran la incertidumbre en la dinámica del robot son los desarrollados en Dong y Guo [5] y en Dong y Huo [11], los cuales presentan resultados de simulación.
Martins et al. [12] y Rossomando et al. [13] utilizan un controlador de dinámica inversa adaptable y neural adaptable respectivamente que identifica toda la dinámica real del robot; estos trabajos presentan todo el diseño en el dominio continuo.
Bugeja et al. [14] presentan el uso de una red neuronal RBF en tiempo discreto para las estimaciones de las incertidumbres en el diseño del control, en la que se optó por emplear técnicas de control adaptable estocástico, más concretamente, el principio de doble control, que fueron introducidas por Fel’dbaum [15].
Para lograr ese objetivo la red RBF se entrena por un algoritmo basado en el filtro de Kalman extendido (EKF). Esta red aproxima la dinámica directa completa de los robots móviles. Con esta estimación de la dinámica se obtiene un funcional de coste para el desarrollo del controlador. Los autores solo muestran resultados de simulación y no presentan un análisis de estabilidad.
Alanís et al. [16] presentan un controlador backstepping basado en RN; el controlador está diseñado en tiempo discreto sobre la dinámica completa, solo muestra un ejemplo de simulación y no es aplicado en robótica móvil. En este trabajo se realiza el ajuste de los pesos de la RN del controlador a través de un filtro de Kalman extendido.
Kim et al. [17] han propuesto un controlador adaptable robusto para un robot móvil dividido en 2partes. El primero se basa en la cinemática de robots y se encarga de generar las referencias para la segunda, que compensa la dinámica del modelo. Sin embargo, los parámetros adaptados no son los parámetros reales del robot, y no se presentan resultados experimentales. Además, las acciones de control se dan en términos de pares motores, aun cuando usualmente los robots comerciales aceptan comandos de velocidad.
En el trabajo de De la Cruz y Carelli [18] se presenta una parametrización lineal de un robot móvil uniciclo y el diseño de un controlador de seguimiento de trayectoria que se basa en el modelo completo conocido. Una de las ventajas de su controlador es que sus parámetros están directamente relacionados con los parámetros del robot. Sin embargo, si los parámetros no son correctamente identificados o cambian con el tiempo, debido por ejemplo a la variación de la carga, el desempeño del controlador resulta afectado.
La contribución de este trabajo es el diseño de un controlador de seguimiento de trayectoria adaptable basado en la dinámica nominal del robot y en un algoritmo compensador neuronal. Todo el sistema de control está diseñado en 2partes: una incluye un controlador cinemático y otra un controlador dinámico con su compensador neuronal. Esto presenta como ventaja, respecto de trabajos previos, que la compensación se hace solo sobre la parte incierta de la dinámica. El método presentado aquí muestra algunas ventajas: la primera es la aplicación a un sistema no lineal multiple input-multiple output (MIMO) en tiempo discreto; la segunda es la garantía de que el error está acotado en presencia de perturbaciones, y la tercera es que el diseño puede ser aplicado a diferentes sistemas. Finalmente, este trabajo propone el uso de una red RBF entrenada por un EKF que ajusta los pesos de salida de las RBF, con el fin de aproximar la ley de control de compensación. También se incluye un análisis de los errores de control de trayectoria para el sistema robótico MIMO no lineal en función de los errores de aproximación de la red neural.
Este trabajo está organizado de la siguiente manera: la sección2 presenta un panorama general del sistema y muestra la representación matemática de todo el modelo de uniciclo del robot. La cinemática y la dinámica de los controladores y de la red de compensación RBF se examinan, respectivamente, en las secciones3 y 4, así como los correspondientes análisis de errores. En la sección 5 se presentan algunos resultados de experimentación que muestran el rendimiento del compensador adaptable. Por último, en la sección6 se presentan las conclusiones.
2Modelo del robot2.1Visión general del sistemaEn esta sección se describe el modelo del robot móvil tipo uniciclo como el que se muestra en la figura 1, donde se indican los parámetros y las variables de interés. Las variables v y ω representan las velocidades lineal y angular, respectivamente, desarrolladas por el robot, G es el centro de masa del robot, c es la posición de la rueda castor, E es la ubicación de la herramienta, h es el punto de interés con coordenadas rx, ry en el plano XY, Ψ es la orientación del robot, a es la distancia entre el punto de interés y el punto central del eje virtual vinculado a las ruedas de tracción. La representación matemática del modelo completo [18] está dada por:

Modelo cinemático

Modelo dinámico
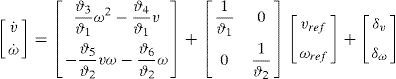
Los parámetros identificados ϑ=ϑ1ϑ2ϑ3ϑ4ϑ5ϑ6T del modelo dinámico del robot móvil están descritos por las siguientes relaciones (validadas en [18]):



En estas relaciones m es la masa del robot; r es el radio de las ruedas izquierda y derecha; kb es igual a la constante electromotriz multiplicada por la constante de reducción; Ra es la constante de resistencia eléctrica; ka es la constante de torque multiplicada por la constante de reducción; kPR, kPT, y kDT son constantes positivas; Ie y Be son el momento de inercia y el coeficiente de fricción viscosa de la combinación rotor del motor, caja de reducción y rueda, y Rt es el radio nominal del neumático.
El valor de los parámetros identificados de los robots móviles está indicado en la tabla 1.
El vector de incertidumbres asociados al robot móvil es, δ=δrxδry0δvδωT, donde las variables δrx y δry son funciones de la velocidad de deslizamiento y de la orientación del robot, δv y δω son funciones de los parámetros físicos como la masa, la inercia, diámetros de las ruedas, del motor y parámetros de los servos, fuerzas aplicadas sobre las ruedas, y otras variables. El vector de incertidumbres es considerado como una perturbación al sistema.
El modelo del robot presentado en (1) y (2) se divide en una parte cinemática y una dinámica, respectivamente, tal como se muestra en la figura 2. Por lo tanto, se aplican 2 controladores, basados en la linealización por realimentación, para la cinemática y la dinámica del modelo del robot, respectivamente.

El modelo del robot se discretiza, a los fines de su control digital, con un intervalo de muestreo T0=0,1s. Este valor es el mismo que usa el robot internamente para el muestro de las señales de velocidad y posición. El índice k es el índice de tiempo discreto. El resultado de la discretización directa del modelo del robot resulta:
Modelo cinemático discretizado
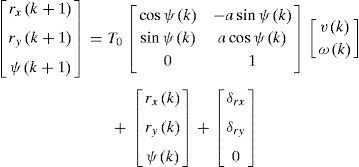
Modelo dinámico discretizado

Donde:
3Controlador cinemático discreto
El diseño del controlador cinemático se basa en el modelo de la cinemática del robot móvil (4). Se propone el siguiente controlador cinemático:
donde vrefck,ωrefckT es el vector de valores deseados de velocidad lineal y angular, y rxsk,ryskT es el vector de posición deseada del robot. Considerando solo las variables de posición del robot en la trayectoria [rx(k), ry(k)]T y bajo la suposición de seguimiento perfecto de velocidad, vrefck,ωrefckT=vk,ωkT, puede sustituirse (7) en (4), resultando la ecuación de lazo cerrado:

Definiendo el vector de error de salida h˜k=r˜xkr˜ykT=rxskryskT−rxkrykT, la ecuación(8) puede ser escrita como:
lo cual implica que h˜k→0 cuando k→∞. La suposición de seguimiento perfecto de velocidad será abandonada luego, en el análisis de estabilidad del controlador dinámico.4Controlador dinámico discreto4.1Formulación del problema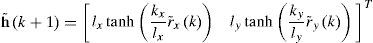
El controlador dinámico recibe las referencias de velocidad linear y angular, las cuales son generadas por el controlador cinemático, y este genera otro par de comandos de velocidades linear y angular que son enviados a los servos del robot móvil, como se muestra en la figura 2.
Primeramente se diseña el controlador dinámico principal basado sobre la dinámica nominal del robot. Esta dinámica nominal representa una estimación de la dinámica principal del robot móvil. La dinámica inversa del robot es obtenida en base a (5), sin considerar las incertidumbres dinámicas, y es parametrizada de la siguiente forma:
donde Ω es el vector de parámetros discreto y es igual a:
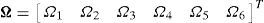
La ecuación (10) puede ser reescrita como:

En notación compacta se puede expresar de la siguiente forma:
dondedonde D=diagΩv,Ωω, y siendo Ωv=Ω1,Ωω=Ω2.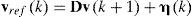

La ley de control propuesta de la dinámica inversa es:
donde
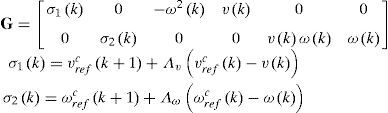
En forma matricial se expresa:
donde σk=σ1kσ2kT y Λ=diagΛv,Λω
La ecuación (13) puede ser expresada como:

En (14), Ω es el vector de parámetros, el cual es constante. Debido a las incertidumbres en el modelo nominal (incertidumbres paramétricas Ω˜ y dinámica no considerada en el modelo δ), se propone el uso de una compensación neuronal RBF. La ley de control completa puede ser expresada por:
donde NN(.) es una función que indica la compensación neuronal que aprende la diferencia entre en la dinámica nominal y actual del robot móvil, y vrefk es la acción de control del robot móvil.
La estructura completa de control propuesta se muestra en la figura 2, en la cual la implementación es expresada en función del tiempo discreto k.
4.2Algoritmo compensador neuralUn compensador neuronal puede ser obtenido usando la información pasada y presente del vector de salida de la red vN(k), y del vector de salida del sistema v. Muchas RN son implementadas por computadores digitales y la parte dinámica de un sistema no lineal es obtenida utilizando operadores de atraso de tiempo (time-delays). Una red neuronal RBF implementada en un computador digital puede ser considerada como un sistema de control de tiempo discreto.
Para identificar la dinámica del robot se propone la siguiente RN cuya estructura está basada en una red neural de base radial (RBF):
donde w* representa los pesos óptimos del compensador neuronal w*=wv*wω* y ¿ ∈ℜ2x1 es un vector de perturbaciones acotado.
El vector de funciones RBF es indicado por ξ*, siendo el número de estas funciones igual a M.
En la figura 3 se muestra la estructura interna del compensador neuronal, la cual está basada en una red RBF, donde ta, tb son enteros que están relacionados con el orden del sistema, donde z–1 es el operador de atraso de tiempo y vcref(k+1) es el vector de salida deseado del sistema dinámico del robot móvil.

El vector de salida vN(k) de la de red de compensación neuronal es adicionada al vector vref(k) para generar la acción de control total del robot vdref(k). Definimos el vector del patrón de entrada a la RN:
donde vrefck=vrefck,ωrefckT,vN=vNk,ωNkT y v=vk,ωkT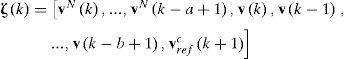
Aquí, ξ es la función de base radial no lineal de la red, y se representa por:
donde c es el vector de centros de cada función ξ(.); λ es una constante de la función ξ(.), en nuestro caso es igual a 1, y M es el número de neuronas RBF.
El vector de pesos ideales w* es una cantidad artificial requerida solo para propósitos analíticos. En general se supone que existe un vector de pesos constantes w* pero desconocido cuya estima es w(k). Definiendo el error de pesos:
donde la salida de la RN vN(k) queda expresada por:4.3Algoritmo de entrenamiento usando filtro de Kalman extendido

El filtro de Kalman estima de modo óptimo los estados de un sistema lineal que está afectado con ruido blanco sobre los estados y las salidas. Para el entrenamiento de la RN basado en el filtro de Kalman, los pesos neuronales son los estados a ser estimados. En este caso, el error entre la salida de la referencia de velocidad (vcref(k)) y la salida de la dinámica del robot (v(k)) puede ser considerado como un ruido blanco aditivo. Debido a este hecho y a que el mapeo de la RN es no linear, se necesita un EKF [19].
El objetivo del entrenamiento es encontrar los valores óptimos de los pesos que minimizan la predicción del error [20]. Se aplica un algoritmo de entrenamiento basado en el filtro de Kalman desacoplado descrito por:
siendodonde ev,ω(k) son los elementos del vector de error de salida, donde el subíndice v y ω indican su correspondencia con la velocidad lineal y la velocidad angular, respectivamente, Pv,ω(k)∈ℜMxM es la matriz de covarianza del error de predicción, wv,ω(k)∈ℜMx1 es la estimación del vector de pesos de salida de la red RBF para v y ω, respectivamente, γ es el factor de aprendizaje (0<η<1), Kv,ω(k)∈ℜMx1 es el vector de ganancia de Kalman, Γv,ω(k)∈ℜMxM es la matriz de covarianza del ruido que afecta los estados (pesos), Rv,ω(k)∈ℜ1x1 es la matriz de covarianza del ruido de medición. Usualmente Pv,ω(k) y Γv,ω(k) son inicializadas como matrices diagonales. Además, Hvω ∈ℜMx1 es la matriz de medición, la cual puede obtenerse aplicando el método de la regla de la cadena sobre el vector de salida con respecto al vector de pesos. Esta matriz puede expresarse como:Las matrices (Hv,ω) pueden ser expresadas por:
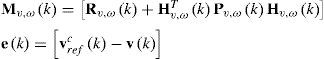


Para utilizar eficazmente esta matriz (Hv,ω) es necesario conocer ∂v/∂vN, que es difícil de calcular cuando el modelo del sistema es desconocido o los parámetros del mismo varían. Sin embargo, se puede utilizar una aproximación, siendo esta una función acotada.

La red RBF de compensación neural puede ser entrenada por el método presentado con las ecuaciones precedentes y proporciona un mapeo no lineal expresado por (19).
Generalmente las matrices Γv,ω(k), Rv,ω(k) y Pv,ω(k) son inicializadas como matrices diagonales. Es importante indicar que Hv,ω(k), Kv,ω(k) y Pv,ω(k) son acotadas [21].
4.4Entrenamiento y ubicación de los centros en las funciones de base radialEl procedimiento de entrenamiento para las redes RBF se divide en 2etapas: el ajuste de los centros de las funciones de base radial en la capa oculta, seguido del entrenamiento de los pesos entre la salida y la capa oculta indicada por (24b). Generalmente en aplicaciones de control solo se entrena los pesos entre la salida y la capa oculta, donde los centros son ajustados fuera de línea.
Los algoritmos de ajuste de los centros más usados son el fast k-means (método de entrenamiento autorganizado) y el gradiente descendente (método supervisado) [19]. Para esta aplicación se usa el método del gradiente descendente.
La posición de los centros (capa oculta) puede ser expresada:
donde J(k) es una función de costo. Para poder usar el método del gradiente descendiente debemos aplicar la regla de la cadena a ∂J(k)/∂ci(k), y se obtiene:donde


Para usar el método del gradiente debemos conocer ∂v/∂vN, que fue aproximado por (28).
Sustituyendo (31) y (28) en (30):

Este resultado permite ajustar los centros de la red neuronal RBF-NN, que para fines prácticos ¿ no es considerado.
4.5Descripción del algoritmo compensador neuronalHay que tener en cuenta que para el vector de salida deseado vcref(k+1), el compensador producirá la señal vN(k):

El algoritmo de compensación de este sistema neural es descrito por los siguientes pasos:
- a)
Inicializar aleatoriamente los pesos y centros de la red de compensación RBF neural wi(0), ci; e inicializar las matrices Γv,ω(k), Rv,ω(k) y Pv,ω(k) como matrices diagonales.
- b)
Proporcionar el patrón de entrada de compensación neural en el momento de k:
- c)
Calcular la salida del compensación neural (19) como acción de control en el momento k.
- d)
Tomar la salida vN(k) y adicionar vref(k) al instante k, calcular el error de salida del sistema como:
- e)
Actualizar los pesos por medio de la ecuación (24b) y los centros por (32).
- f)
Hacemos k=k+1 y retornamos al paso b) para calcular el próximo ciclo.


Para la ley de control propuesta, la red neuronal RBF (19) entrenada con el algoritmo basado en el EKF (24) asegura que el error de estimación de la salida (25b) es uniformemente acotado; por lo tanto, los pesos de la red neuronal RBF se mantienen acotados, siendo:
donde wMax es un valor constante.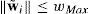
Para realizar el análisis se debe determinar el error de control en el instante k+1 y teniendo en cuenta que la ley de control de la dinámica inversa representada por (14) se expresa como:

La ley de control completa que incluye la compensación neuronal (18) puede ser expresada por:

De (13), el modelo dinámico que incluye las incertidumbres está representado por:

Igualando (36) y (35), el sistema de lazo cerrado resulta:

Teniendo en cuenta la (25), que define el error control, (37) puede ser reescrita por:

La compensación neuronal tiende a hacer el error de control igual a cero, y reemplazando el valor de vN(k) expresado por (23):
e igualando ambos miembros en (39), queda:

Reescribiendo (39):

Expresando (41) en función de sus componentes:

Considerando la función candidata de Lyapunov para el análisis de estabilidad:
donde el subíndice i indica si corresponde a los elementos de v o de ω.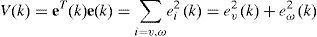
La ecuación en diferencias de Lyapunov expresada en función de los componentes de error de velocidad queda:

Reemplazando (42) en (43):

Calculando las raíces de la ecuación (45) para determinar la cota de error de control, se obtiene:

El error queda acotado por:
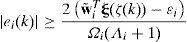
De (47) para garantizar que ΔVk sea negativo y de esta forma el sistema de control propuesto sea asintóticamente estable se debe cumplir:

Lo cual implica ΔV(k)≤0. Esto asegura que Δe(k)→Bδe˜ está acotado.
Con este resultado se regresa al análisis del comportamiento del error de control de trayectoria h˜k. Abandonando la suposición inicial de un seguimiento perfecto de velocidad de los controladores cinemáticos de la sección 3, (8) se reescribe ahora como:
donde el vector de error εk=ε1kε2kT es el error de la velocidad de seguimiento previamente definido como Θ(k)e(k). Siendo la matriz Θ (k):

De (49) hacemos:
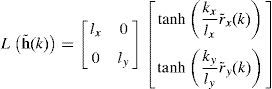
Reescribiendo (49) en forma compacta, para pequeños errores de control, se puede aproximar Lh˜k≈Kxyh˜k con Kxy=diagkx,ky

Considerando la función candidata de Lyapunov:

La diferencia discreta es:

La condición suficiente para que ΔV sea negativa:

Calculando la raíces de la ecuación (65):

La condición suficiente para estabilidad asintótica para que ΔV≤0 pueda ser expresada como:

Esto implica que ΔV<0. Asegurando que h˜→Bδh˜.
Esto constituye un resultado práctico que permite afirmar que el error de control de posición queda finalmente acotado en términos del error de aproximación del algoritmo neuronal de compensación.
5Resultados experimentalesEl robot móvil Pioneer 2-DX posee a bordo una PC Pentium III con 800MHz y 512Mb de memoria RAM (fig. 4), y los algoritmos de control propuesto se aplicaron en el robot que admite velocidades lineales y angulares, como las señales de entrada de referencia. El controlador fue inicializado con los parámetros dinámicos del robot Pioneer 3-DX y se usaron 5 neuronas RBF (M=5). Los parámetros dinámicos fueron obtenidos a través de la identificación, según lo propuesto por Song y Grizzle [21].

El objetivo del experimento es demostrar que para distintas velocidades y distintas trayectorias el robot móvil sigue la trayectoria de referencia lo más fielmente posible con el menor error. El robot debe seguir una trayectoria indicada por:
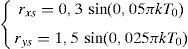
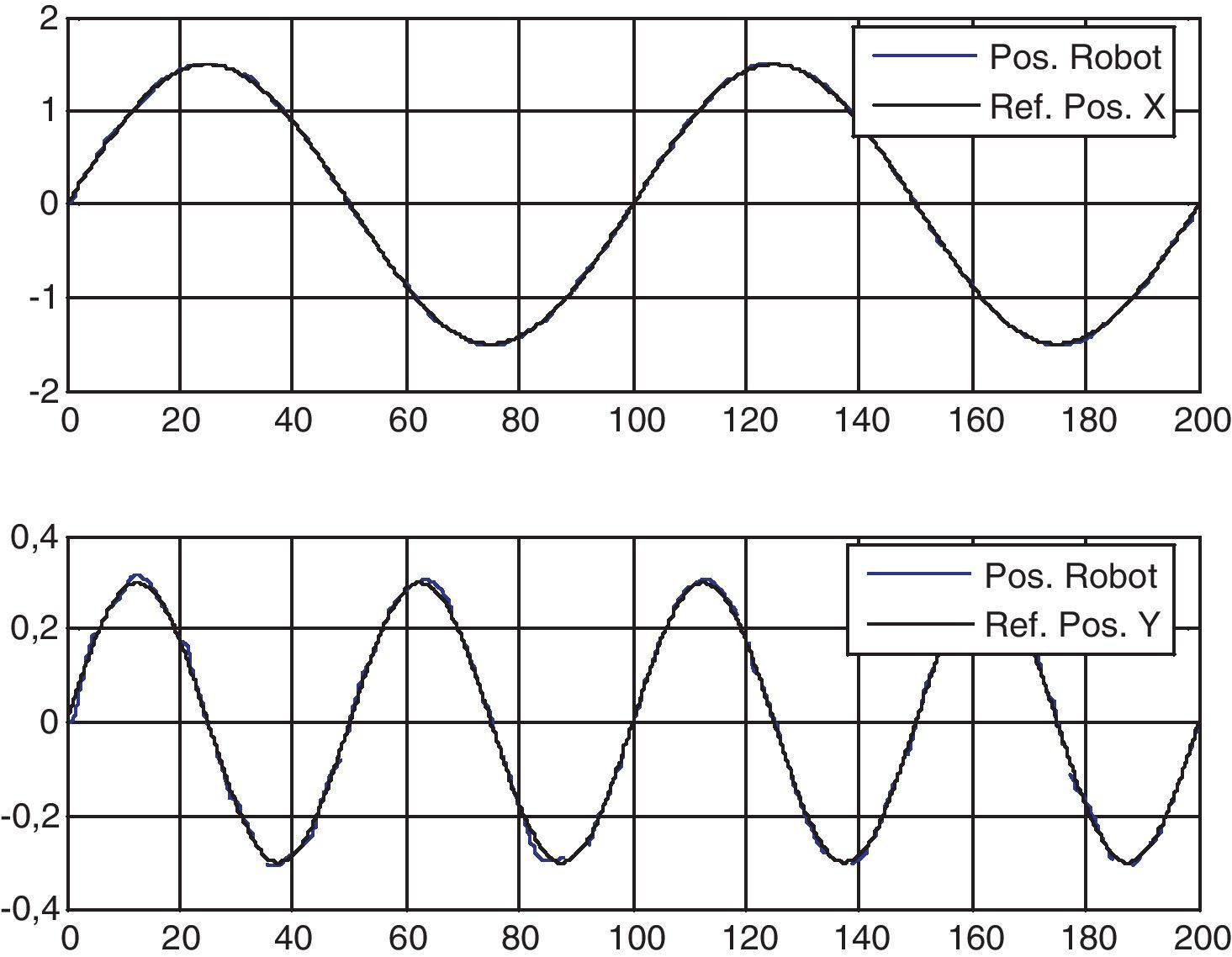
En el experimento, el robot comienza en la posición (rx,ry)=(0,0)m y sigue una trayectoria de referencia en forma de 8 horizontal (58). El experimento se realizó usando el algoritmo de compensación neuronal y se comparó con otro experimento desactivando el algoritmo de compensación neuronal. Los resultados se describen a continuación.
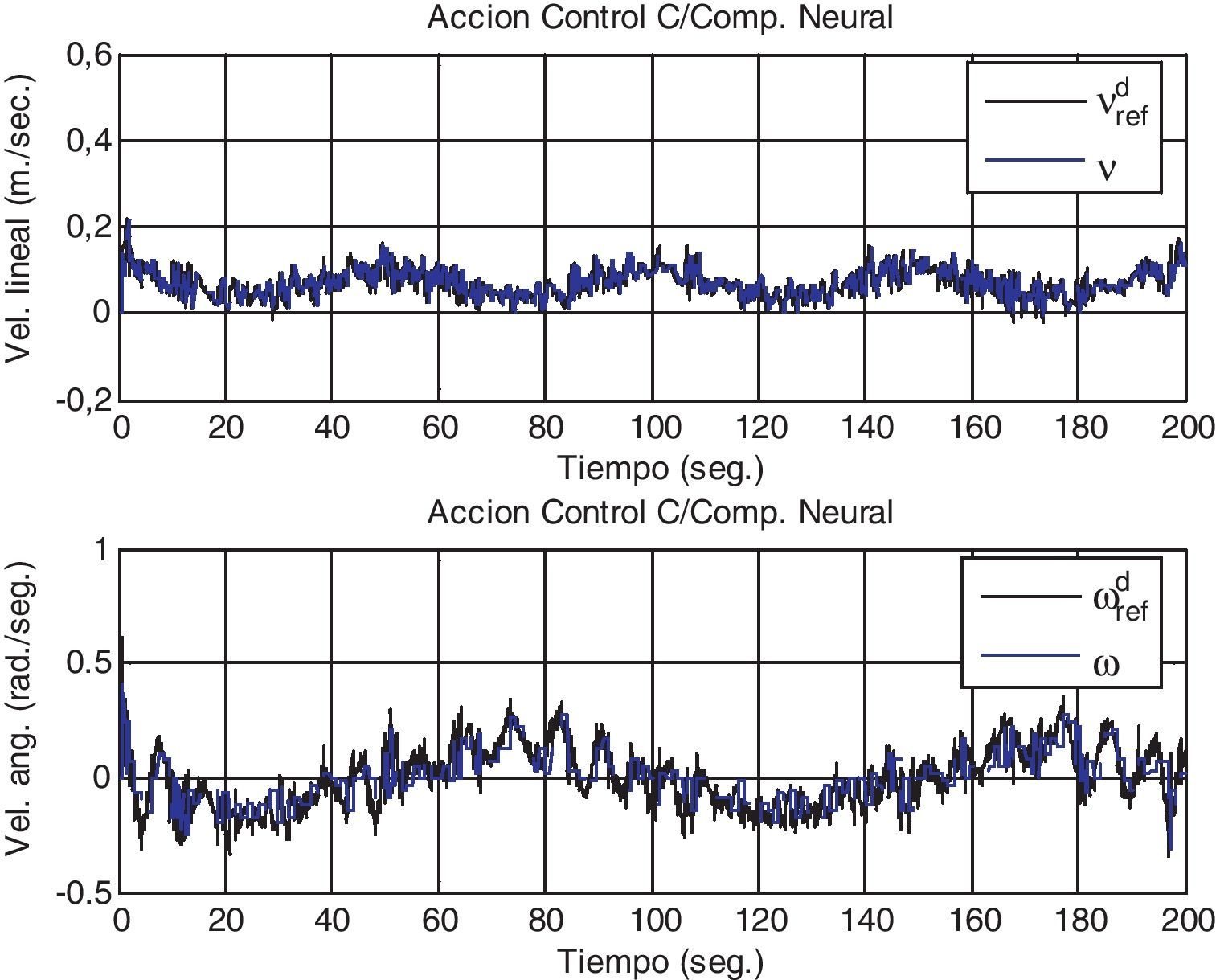
Las figuras 5 y 6 describen las velocidades y acciones de control del compensador neuronal RBF, así como las referencias y las variables de posición del robot móvil, respectivamente. La figura 7 muestra la trayectoria seguida por el robot móvil, sin compensación y con el compensador neuronal adaptable para el seguimiento de la trayectoria deseada. Se observa claramente en dicha figura que el robot con compensador neuronal sigue más fielmente la trayectoria deseada.



La figura 8 muestra la norma del error de trayectoria de los controladores con y sin compensación. El error de trayectoria se define como la distancia instantánea entre la referencia y la posición del robot. También muestra que el error con compensador neuronal discreto es menor cuando los parámetros dinámicos no son los correctos, debido a la mala sintonía del controlador o porque estos han variado a consecuencia de perturbaciones externas.

En el experimento no se utilizó un sistema de referencia absoluto. Se comparó el controlador sin compensación y con compensación, y se muestra que con este último se mejora el seguimiento. El mismo resultado se esperaría con un sistema de referencia absoluto.
6ConclusionesEn este trabajo se propuso un algoritmo de compensación neuronal adaptable para el seguimiento de la trayectoria de un robot móvil del tipo uniciclo. Este compensador, junto al controlador no lineal, es capaz de generar los comandos de velocidad con mínimo error para el mismo. Se demostró que los errores de control de seguimiento están acotados, y que los límites son calculados en función del error de aproximación de la red neuronal RBF.
El algoritmo neuronal adaptable RBF aprende la diferencia entre una dinámica nominal conocida y la dinámica real del robot para su posterior compensación. Por lo tanto, el esfuerzo computacional es significativamente menor que un modelo completo de RN inversa que tuviera que aprender toda la dinámica del robot. Los resultados experimentales muestran el buen desempeño del controlador de seguimiento propuesto y su capacidad para adaptarse a la dinámica de robots reales.
v Velocidad lineal del robot móvil Velocidad angular desarrollada por el robot móvil Vector de velocidades del robot móvil Coordenadas del robot (pto. h) en el plano XY Vector de interés con coordenadas rx, ry en el plano XY Centro de masa del robot Posición de la rueda castor Ubicación de la herramienta Orientación del robot Distancia entre el punto de interés y el punto central del eje virtual vinculado a las ruedas de tracción Vector de incertidumbres del robot Vector de parámetros del robot (tiempo continuo) Elementos del vector de parámetros (tiempo continuo) donde i=1,…,6 Vector de parámetros del robot (tiempo discreto) Elementos del vector de parámetros (tiempo discreto) donde i=1,…,6 Matriz diagonal diag(Ω1, Ω2) Periodo de muestreo Índice de tiempo discreto Número de neuronas RBF Pesos de salida de la red neuronal RBF Error de pesos de salida Pesos óptimos de salida Funciones RBF Vector de funciones RBF Constante de la función ξi. Vector de centros asociados a la función ξi. Vector de salida de la red RBF Vector de salida del controlador cinemático Vector de salida del controlador dinámico Vector de acción de control total para la dinámica del robot (vrefk=vrefdk−vNk) Matriz de covarianza del error de predicción Estimación del vector de pesos de salida Factor de aprendizaje (0 < γ < 1) Vector de ganancia de Kalman. Γv,ω(k) ∈ℜMxM es la matriz de covarianza del ruido que afecta los estados (pesos) Matriz de covarianza del ruido de medición Matriz de medición Funcional de costo que es usado para la localización de centros de la RBF Vector de error de velocidades de salida, siendo e(k)=[ev(k), eω(k)]T Error de salida, para v y ω respectivamente Vector de perturbaciones (acotado) Matriz T0cosψk−asinψk;sinψkacosψk