





Recientemente, la fusión de datos entre una cámara y un sensor de profundidad del tipo LiDAR se ha convertido en un problema de gran interés en la industria y en la ingeniería. La calidad de los modelos 3D producidos depende, en buena manera, de un proceso correcto de calibración entre ambos sensores. En este artículo, se realiza un análisis de sensibilidad en un modelo de calibración cámara-LiDAR. Se ha calculado individualmente la variabilidad de cada parámetro por el método de Sobol, basado en la técnica de ANOVA, y el método FAST, que se basa en el análisis de Fourier. Se han definido los parámetros más sensibles y con mayor tendencia a introducir errores en nuestra plataforma de reconstrucción. Se han simulado múltiples conjuntos de parámetros para su análisis y comparación utilizando los métodos de Monte Carlo e Hipercubo Latino. Se muestran estadísticas sobre la sensibilidad total y global de cada parámetro. Además, se presentan resultados sobre la relación de sensibilidad en la calibración cámara-LiDAR, el costo computacional, el tiempo de simulación, la discrepancia y la homogeneidad en los datos simulados.
Recently the data fusion between a camera and a depth sensor of LiDAR type, has become an issue of major concern in industry and engineering. The quality of the delivered 3D models depends greatly on a proper calibration between sensors. This paper presents a sensitivity analysis in a camera-lidar calibration model. The variability of each parameter was calculated individually by the Sobol method, based on ANOVA technique, and the FAST method, which is based on Fourier analysis. Multiple sets of parameters were simulated using Monte Carlo and Latin Hypercube methods for the purpose of comparing the results of the sensitivity analysis. We defined which parameters are the most sensitive and prone to introduce error into our reconstruction platform. Statistics for the total and global sensibility analysis for each sensor and for each parameter are presented. Furthermore, results on the sensitivity ratio on camera-LiDAR calibration, computational cost, time simulation, discrepancy and homogeneity in the simulated data are presented.
Actualmente, la calibración de un sensor LiDAR y una cámara ha sido abordada por múltiples investigadores; sin embargo, el análisis de incertidumbre y la sensibilidad de la calibración son temas poco estudiados. El interés de este trabajo es cuantificar la variabilidad de los parámetros del modelo del sensor con respecto a la técnica de calibración. Además, se calcula la injerencia individual de cada parámetro en esta variación.
Como preámbulo, y para comprender mejor los conceptos que se utilizan en el cuerpo del artículo, precisamos que un modelo en términos de esta investigación se refiere al estudio de las relaciones geométricas de las variables que existen en un sistema óptico (cámara) o una serie de emisores láser (LiDAR). Estos modelos se aplican en el proceso de calibración para calcular los parámetros intrínsecos y/o extrínsecos que definen geométricamente las variables con respecto al mundo y al propio sensor. En ocasiones, estos modelos son tan complejos que es preciso utilizar procedimientos estadísticos (simulaciones) para comprender su comportamiento y predecir las consecuencias de sus resultados, según las variaciones del modelo.
El análisis de sensibilidad se centra en la relación que existe entre las entradas y las salidas dentro de un sistema, el cual estudia las relaciones entre las variables. Por ejemplo, en un modelo de calibración para una cámara, se analiza de qué modo los parámetros resultantes del modelo (salidas) varían en función de las coordenadas de los puntos de referencia (entradas) y cómo se puede distribuir cuantitativamente esta variación a los diferentes niveles de cambio. Por otro lado, el análisis de incertidumbre ayuda a reducir la propagación del error en la salida del modelo del sensor. Al conocer la desviación del error en los parámetros de entrada, es posible mejorar la precisión, ya sea optimizando el proceso de calibración o adicionando un factor nominal para aumentar la precisión. En conjunto, la sensibilidad y el análisis de incertidumbre ayudan a enlazar la influencia de las suposiciones y los parámetros de entrada en el modelo del sensor.
Para crear escenas urbanas 3D a gran escala (visión profunda), es importante que la fusión de los datos sea eficaz, flexible y con la mínima intervención humana (autónoma). Eficaz, en cuanto a la correspondencia entre la geometría y la topología observada por los sensores de las estructuras urbanas. Flexible, para poder reconstruir cualquier tipo de estructura sin ninguna limitación por algún tipo de descripción específica previa. Y autónoma, para lograr la fusión de los datos sin necesidad de que haya un usuario. Mediante el análisis de la sensibilidad y la incertidumbre, podemos cuantificar en qué grado nuestro sistema es eficaz, y esta es la razón que justifica esta investigación.
Una vez definidos el modelo del sensor y la técnica de calibración y de fusión de datos, el análisis de la sensibilidad determinará la incertidumbre en los parámetros de entrada [21]. Existen varios enfoques sobre el análisis de la sensibilidad y de la incertidumbre, entre ellos: (1) los basados en el muestreo, que utilizan la generación de muestras considerando su distribución probabilística para analizar los resultados de su variación [12]; (2) el análisis diferencial, que consiste en aproximar el modelo a una serie de Taylor y después, mediante un análisis de la varianza, obtener el análisis de sensibilidad [4]; (3) la prueba de sensibilidad de amplitud de Fourier (FAST, por sus siglas en inglés), que se basa en la variación de las predicciones del modelo y las contribuciones de las variables individuales a la varianza [22]; (4) la metodología de superficie de respuesta (RSM, por sus siglas en inglés), en la cual se diseña un experimento que proporcione valores razonables de respuesta del modelo del sensor para, a continuación, determinar el modelo matemático que se ajuste mejor a los datos obtenidos. El objetivo final del RSM es establecer los valores de los factores que optimizan la respuesta (costo, tiempo, eficiencia, etc.) [19].
En general, en un modelo se puede realizar un análisis de sensibilidad local o global [21]. El análisis local analiza la varianza de las funciones de salida con respecto a los parámetros de entrada. Los parámetros de entrada son alterados dentro de un intervalo pequeño, alrededor de un valor nominal, y se aplica un análisis a cada parámetro en particular. Un factor limitante es que este análisis solo proporciona información del punto de partida desde el cual es calculado y no analiza todo el espacio de entrada del parámetro. Además, si el modelo no es continuo, no se puede hacer el análisis. Por otro lado, los enfoques basados en la sensibilidad global asignan la incertidumbre del parámetro de salida a la incertidumbre de los factores de entrada, mediante el muestreo de funciones de densidad de probabilidad (PDF, por sus siglas en inglés) asociadas a los parámetros de entrada. Para este enfoque, todos los parámetros se modifican simultáneamente y sus índices de sensibilidad se calculan sobre el rango de variación total de los parámetros de entrada.
Los métodos de Sobol y FAST toman en consideración el efecto de las PDF de cada parámetro, la variación simultánea de todos los parámetros, y no requieren que los modelos sean aditivos o lineales. Estos métodos permiten descomponer la varianza de la salida utilizando las técnicas de simulación de Monte Carlo (MC) o el Muestreo Hipercubo Latino (LHS, por sus siglas en inglés). Un algoritmo de simulación debe considerar tres enfoques al muestrear un modelo: diseño, análisis y evaluación. Primero, se debe elegir qué parámetros son los importantes en el modelo; está claro que los resultados variarán cuando diferentes parámetros sean alterados. Segundo, la distribución estadística escogida para el modelo ha de analizar, además, si la incertidumbre es estocástica o no. Tercero, la estructura de correlación es sumamente importante. Si no se toma en consideración esta correlación, los intervalos del análisis de incertidumbre y sensibilidad pueden generar resultados incorrectos.
La técnica de MC aporta un procedimiento estándar para evaluar la incertidumbre, simulando y muestreando las variables de entrada [15,16,27]. MC genera números pseudoaleatorios en un espacio definido por una PDF. La cantidad de secuencias a simular se debe determinar según la recomendación propuesta en [7]. Cuando un modelo contiene demasiadas variables, su análisis de incertidumbre y sensibilidad utilizando la técnica de MC resulta difícil y tiene un alto costo computacional. Esta dificultad es debida a que demasiadas variables requieren una gran cantidad de simulaciones para calcular unos resultados representativos del modelo.
La técnica de LHS es similar a la de MC, con la diferencia básica de que los parámetros son tratados como estratos y los pseudonúmeros se distribuyen de forma proporcional a los elementos de cada muestra entre los estratos establecidos. La PDF se genera a partir del promedio de cada estrato y debe presentar una distribución semejante a la distribución de los elementos de la muestra. La cantidad de pseudonúmeros aleatorios que deben generarse para la simulación se establecen de manera similar a la definida en MC. En [18], se presenta un análisis de la eficiencia y de la velocidad de la técnica LHS frente a la técnica de MC.
Otros métodos para el análisis global de la sensibilidad se presentan en [6], [17], [20].
En este trabajo, se muestran las estadísticas y los resultados del comportamiento de la calibración y de la fusión de datos entre un sensor láser y una cámara panorámica para tareas de reconstrucción urbana en 3D. Se obtiene el comportamiento analítico de los parámetros de calibración en condiciones no controladas, así como la relación entre los parámetros de calibración de la plataforma y los datos ruidosos que se ingresan directamente de los sensores. Además, se comparan con simulaciones utilizando las técnicas de MC y de LHS, y cinco diferentes tipos de PDF.
2Modelo de la plataforma de adquisiciónEl objetivo es modelizar geométricamente el comportamiento de nuestra plataforma multisensor (v. figura 1), compuesta por un escáner láser Velodyne HDL-64E y una cámara panorámica Point Grey Ladybug2, para realizar tareas de reconstrucción tridimensional en ambientes urbanos.
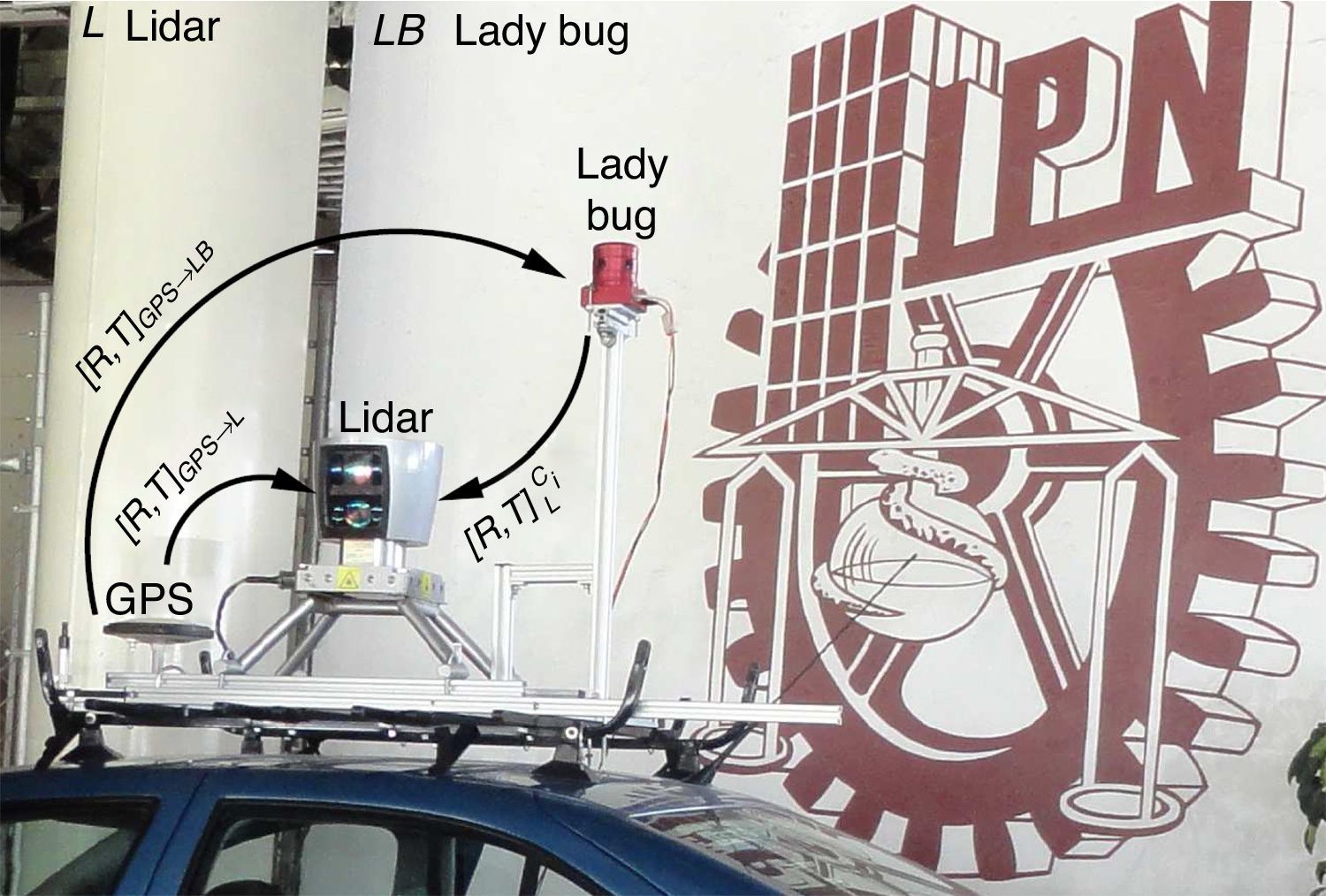
![Plataforma multisensor compuesta por un LiDAR Velodyne HDL-64E (L), una cámara Ladybug2 (LB) y un GPS. La Ladybug2 es un sistema compuesto por seis cámaras (Ci). [R,T]LCi representa la translación y la rotación del LiDAR y de las seis cámaras de la Ladybug2.](https://static.elsevier.es/multimedia/02131315/0000003200000004/v1_201609231323/S021313151500053X/v1_201609231323/es/main.assets/gr1.jpeg?xkr=ue/ImdikoIMrsJoerZ+w997EogCnBdOOD93cPFbanNdXKeWo41MsZkw/vID64cuEiPuJOyFxneHZSkizm96flfSXRuq9PKMsoqi+EW0rIT6ZxIRjSCsFY0ZegDvuDFPcw0MvLSv4UQ8vl6m3Wskby6b28WRBAFmw4nNg/nZDCepKm0cNNiQ0VgfFU9DQPA/2+axdbk4kNXujIb1pKyLEKb2buGfwMgH4xuHmicT75cKv8tLlNu9cWjYHA7kQG1zirExmKs+0ISHy62wE9bcdvYPYmY+ycAqavsdYw2X5bScVXNmUlbc8q2wbz9MNAcFsq+BxIfDNg+NcLuROKnXWag== "Plataforma multisensor compuesta por un LiDAR Velodyne HDL-64E (L), una cámara Ladybug2 (LB) y un GPS. La Ladybug2 es un sistema compuesto por seis cámaras (Ci). [R,T]LCi representa la translación y la rotación del LiDAR y de las seis cámaras de la Ladybug2.")
El LiDAR es un conjunto de láseres que obtiene distancias de los objetos al medir el tiempo de vuelo del haz de luz, desde que es emitido hasta que regresa tras ser reflejado por la superficie de un objeto. Está compuesto por una serie de 64 láseres que giran sobre su eje vertical ofreciendo un campo de visión de 360°. Verticalmente, el LiDAR cuenta con un ángulo de visión de 26,8°. Los láseres son activados cada 4 nanosegundos. La cámara Ladybug2 es un sensor omnidireccional de alta resolución, compuesto por seis cámaras de 0,8 megapíxeles. La forma de anillo en que están dispuestas cinco de las seis cámaras permite tener imágenes con una visión de más del 75% de la esfera total. La figura 3 muestra todo el sistema de coordenadas entre el LiDAR y la cámara.
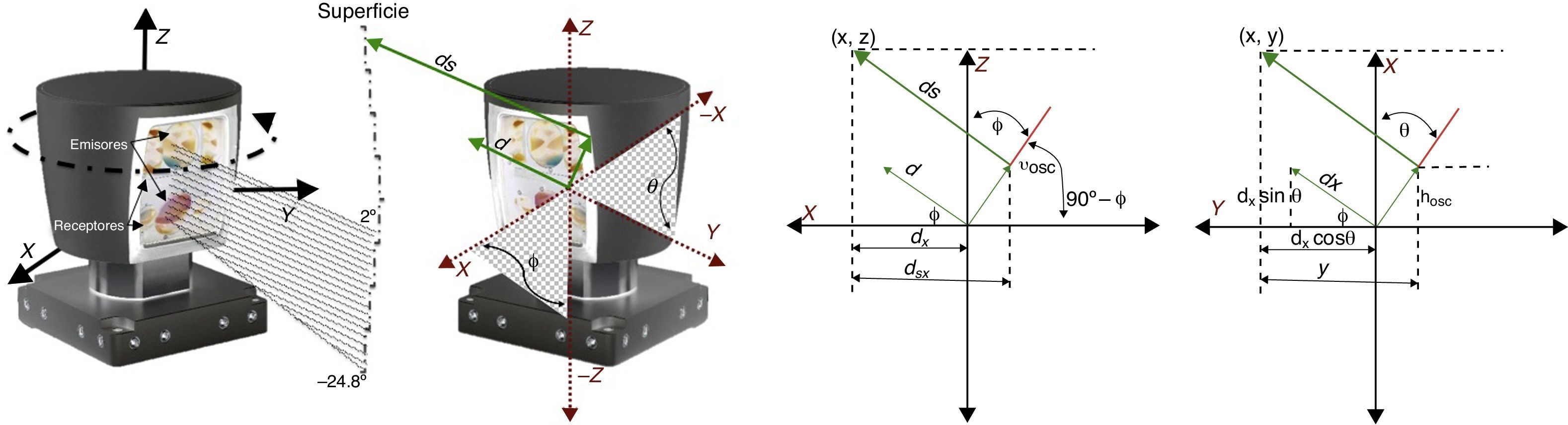
2.1Modelo del LiDARSe ha definido un sistema de coordenadas esféricas global cuyo origen es el centro del LiDAR, como el que se presenta en [2]. Después, se han generado los datos 3D utilizando la función puntos3D=f(ds, θ, ϕ) con respecto al origen, donde ds, es la distancia a que se encuentra el objeto con el cual rebota el láser, θ es el ángulo cenital y ϕ, el ángulo azimutal en que el láser está orientado (v. figura 2). El principio del modelo matemático se basa en la transformación de los puntos 3D en el sistema de coordenadas esféricas al sistema cartesiano, como se observa en la siguiente ecuación:
.")
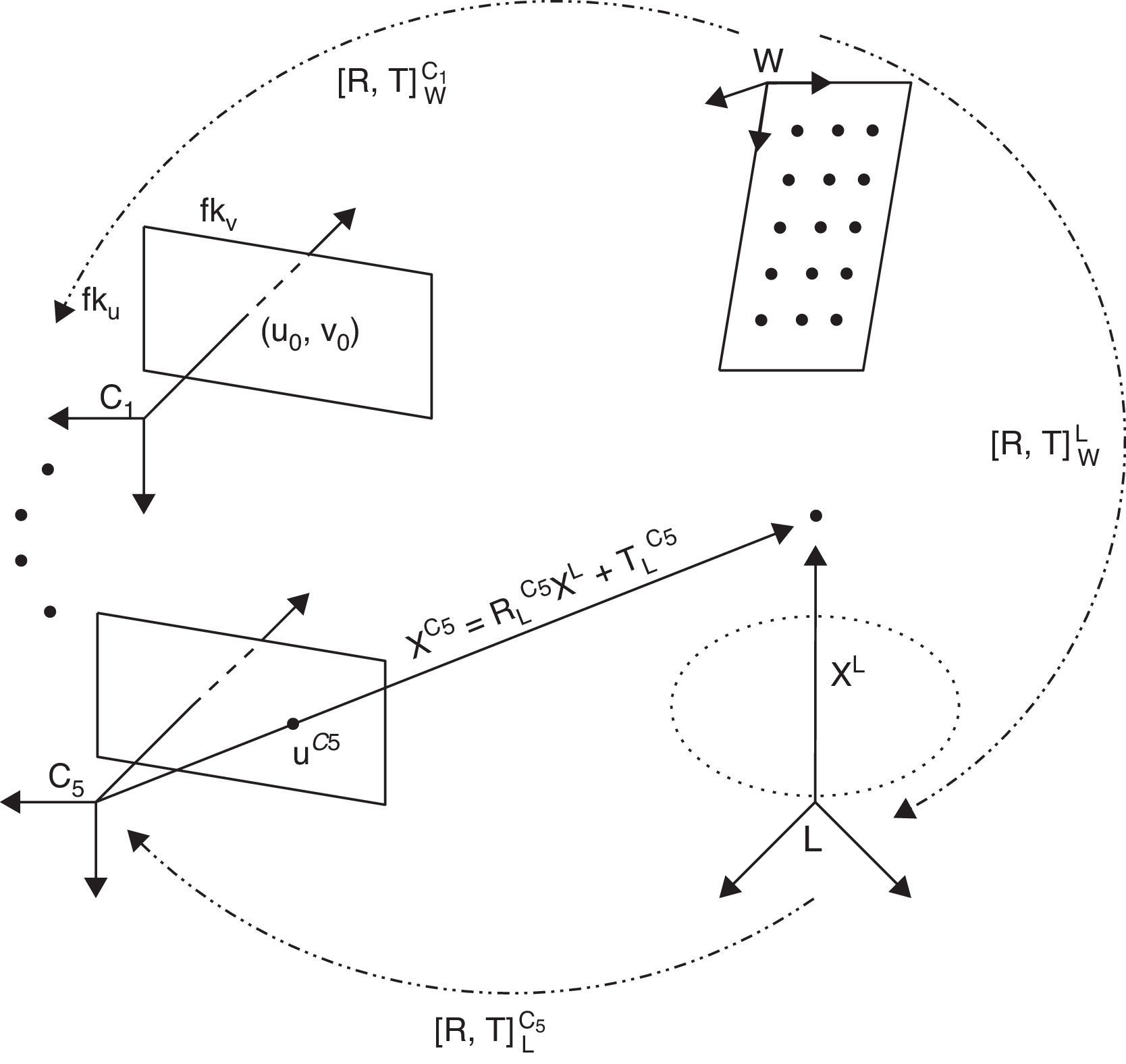
![Marco de referencia del LiDAR L y el sistema multicámara C1, ⋯, C6. [R,T]WCi representa la transformación mundo-LiDAR y [R,T]LCi, la transformación LiDAR-cámara.](https://static.elsevier.es/multimedia/02131315/0000003200000004/v1_201609231323/S021313151500053X/v1_201609231323/es/main.assets/gr3.jpeg?xkr=ue/ImdikoIMrsJoerZ+w997EogCnBdOOD93cPFbanNdXKeWo41MsZkw/vID64cuEiPuJOyFxneHZSkizm96flfSXRuq9PKMsoqi+EW0rIT6ZxIRjSCsFY0ZegDvuDFPcw0MvLSv4UQ8vl6m3Wskby6b28WRBAFmw4nNg/nZDCepKm0cNNiQ0VgfFU9DQPA/2+axdbk4kNXujIb1pKyLEKb2buGfwMgH4xuHmicT75cKv8tLlNu9cWjYHA7kQG1zirExmKs+0ISHy62wE9bcdvYPYmY+ycAqavsdYw2X5bScVXNmUlbc8q2wbz9MNAcFsq+BxIfDNg+NcLuROKnXWag== "Marco de referencia del LiDAR L y el sistema multicámara C1, ⋯, C6. [R,T]WCi representa la transformación mundo-LiDAR y [R,T]LCi, la transformación LiDAR-cámara.")
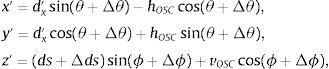
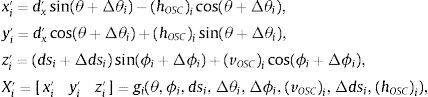
Este modelo matemático considera cinco parámetros intrínsecos para cada láser {Δθi,(hOSC)i,(vOSC)i,Δϕi,Δdsi}.
2.2Modelos de la cámaraLas seis cámaras de la Ladybug2 son representadas por Ci (i=1, …, 6). Un punto 2D en la cámara Ci es representado por uCi=uCivCiT. Un punto 3D del LiDAR es representado por XL=XLYLZLT. Utilizamos xˆ para representar un vector homogéneo adicionando un 1 como último elemento: uˆCi=uCivCi1T y XˆL=XLYLZL1T. El punto uCi referenciado en la cámara corresponde a la intersección del plano de la imagen con la línea formada por el punto XL y el centro óptico Ci. La relación entre un punto 3D y su proyección en la imagen viene dada por:
paray P=ACi[R,T]LCi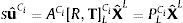
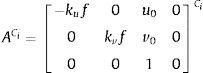
donde s es un factor de escala, [R,T]LCi son los parámetros extrínsecos y representan la transformación rígida entre un punto en la referencia del LiDAR L al de la cámara Ci, y ACi es la matriz de parámetros intrínsecos de la cámara Ci, formada por las coordenadas del punto principal de la imagen (u0,v0), la distancia focal f, −kuf=α y kvf=β los factores de escala de los ejes u y v en la imagen. La 3×4 matriz PLCi es la matriz de proyección. La traslación y la rotación están definidas como: T=[tx ty tz]T y R=[wx wy wz]T, expresada en ángulos de Euler.
Aunque la cámara es geométricamente modelada con el modelo pinhole, se ha calibrado por las técnicas de Tsai [26], Heikkilä [11] y Zhang [28]. Como preámbulo, en la nomenclatura utilizada en las tres técnicas, se define lo siguiente: la transformación de las coordenadas en la referencia del mundo (Xw,Yw,Zw) al sistema de coordenadas de la cámara (Xci, Yci, Zci) se realiza con los parámetros extrínsecos [R, t]. La transformación de las coordenadas en la referencia de la cámara (Xci, Yci, Zci) a la referencia del plano imagen (xpi, ypi) se realiza con los parámetros intrínsecos. En las técnicas de Tsai y Heikkilä, estos son el punto principal o centro de la imagen (cx, cy), la distancia focal (f), el factor de escala de la imagen (sx), las distancias entre píxeles adyacentes (dx, dy) en las direcciones x e y, o sus inversas (Dx, Dy). En la técnica de Zhang, los parámetros son el centro de la imagen (cx, cy), la distancia focal (α, β) a lo largo de los ejes x e y. Para estandarizar la nomenclatura, definimos: α=fsx/dx=fsxDx y β=f/dy=fDy, relacionando la distancia focal en los tres métodos (tabla 1).
Relación de los parámetros extrínsecos-intrínsecos y las coordenadas en las técnicas de calibración de Tsai [26], Heikkilä [11] y Zhang [28]. Para estandarizar la nomenclatura, definimos: α=fsx/dx=fsxDx y β=f/dy=fDy, relacionando la distancia focal en los tres métodos. R=[wx wy wz]T en ángulos de Euler. T=[tx ty tz]T
| Tsai | Heikkilä | Zhang |
|---|---|---|
| XciYciZci=RXwYwZw+t | XciYciZci=RXwYwZw+t | XciYciZci=RXwYwZw+t |
| xpiypi1=sx/dx0cx01/dycy001xdyd1 | xpiypi1=sxDx0cx0Dycy001xdyd1 | xpiypi1=αγcx0βcy001xdyd1 |
El LiDAR ha sido calibrado con el método descrito en la sección 2.1. Así pues, un punto reconstruido por el LiDAR (ds, θ, ϕ) es transformado a [XL, YL, ZL] mediante la ecuación (2). Este punto es proyectado a la imagen utilizando los parámetros intrínsecos de la cámara ACi y la transformación rígida entre la cámara y el LiDAR [R,T]LCi. Aplicando los algoritmos y el patrón de calibración presentado en [8], encontramos la transformación cámara-LiDAR, la cual puede describirse como se observa en la siguiente ecuación:
3Metodología de análisisIncertidumbre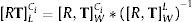
La guía para la expresión de la incertidumbre de las medidas (GUM, por sus siglas en inglés) propone una metodología para estimar la incertidumbre mediante la ley de propagación de la incertidumbre [3]. El enfoque que se presenta se resume en cuatro pasos: especificaciones, identificación, cuantificación y combinación. La etapa de especificación establece una relación algebraica entre el resultado analítico Y y los parámetros xi que afectan el procedimiento:
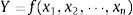
En la etapa de identificación, se localizan todas las fuentes de incertidumbre en el procedimiento y, posteriormente, se miden en la etapa de cuantificación. Las incertidumbres pueden evaluarse a partir de la desviación estándar de una serie de mediciones repetidas. En la etapa de combinación, la incertidumbre combinada estándar u(Y) se evalúa a partir de las incertidumbres estándar de los parámetros individuales u(xi) y la covarianza cov(xi, xj) entre los parámetros correlacionados. De acuerdo con los principios de la propagación de error:
donde, si todos los parámetros son independientes, entonces cov(xi, xj)=0. Puesto que se ha evaluado la incertidumbre estándar, se calcula la incertidumbre expandida U(Y) multiplicando u(Y) por un factor de cobertura k, suponiendo que la distribución de probabilidad de Y es normal. El valor k=2 da un valor de confianza a los resultados del 95%.3.1Sensibilidad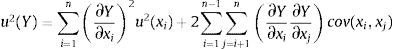
Particularmente, el análisis de la sensibilidad es una consecuencia del análisis de la incertidumbre. Para calcular la sensibilidad de la respuesta a los cambios en los parámetros, se debe seleccionar un método de probabilidad para asignarle los valores a los parámetros dentro de todo el espectro de su incertidumbre [22]. El peso de cada parámetro en la sensibilidad se mide por la correlación entre el parámetro y su respuesta. Mayores cambios indican parámetros con mucha sensibilidad.
En [21], los autores agrupan el análisis de sensibilidad en: (1) métodos de selección, (2) métodos locales y (3) métodos globales. En este trabajo, en concreto, se realizará el análisis global para conocer los efectos que tienen las variables de entrada en el modelo de calibración, es decir, teniendo en cuenta la dispersión de la desviación de los resultados con respecto a su media.
Se han utilizado dos métodos para realizar este análisis, el de Sobol y el FAST, porque presentan las ventajas siguientes: (1) los parámetros se evalúan en todo su rango de variación; (2) la estimación de los valores esperados y la varianza de cada parámetro se calcula de manera directa; (3) calculan la contribución que cada parámetro tiene sobre la sensibilidad total; (4) determinan los efectos de la interacción entre los parámetros dentro del análisis de sensibilidad, y (5) no requieren modificaciones en los modelo de calibración para realizar el análisis.
3.1.1SobolSupongamos que el modelo viene dado por Y=f(X1, …, Xk), donde Xi son parámetros independientes de entrada y Y es la salida del modelo. Realizando el análisis según su dispersión [1], f puede ser lineal o no lineal, y el análisis de la sensibilidad evalúa la aportación de cada parámetro Xi en la varianza de Y. Este estudio es conocido como análisis de varianza (ANOVA, por sus siglas en inglés). Para conocer los índices de sensibilidad de cada parámetro independientemente, la varianza V del modelo se descompone como:
donde Vk=V(E(Y|Xi, Xj, ⋯, Xk))−Vi−Vj−…−Vk.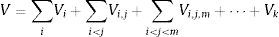
Los índices de sensibilidad se obtendrían con:
donde i1, i2, ⋯, ik son los parámetros de entrada. Entonces, todos los índices de sensibilidad que nos permiten observar la interacción entre las entradas y la no linealidad han de cumplir la condición: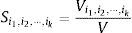
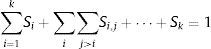
Por otro lado, el índice Si=ViV solo muestra el efecto que tiene el parámetro Xi en la salida del modelo, pero no toma en consideración la interacción con otros parámetros. Para estimar la influencia total de cada parámetro, se calcula la varianza parcial total:
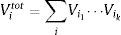
La sumatoria se hace sobre todos los diferentes grupos de índices que satisfacen la condición 1≤i1<i2<⋯<ik≤s, en que uno de los índices es igual a i. Entonces, el índice total de sensibilidad viene dado por:
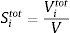
El índice total de sensibilidad Sitot representa el porcentaje esperado de la varianza que permanece en la salida del modelo, si se conocen todos los parámetros excepto i. Se deduce, pues, que 0≤Si≤Sitot≤1. El resultado de Sitot y Si indica la interacción entre el parámetro i y los demás parámetros.
De acuerdo con [5], del valor de los índices de sensibilidad se puede inferir lo que se muestra en la tabla 2, donde τ∈{i1, i2, ⋯, ik}.
3.1.2FASTFAST permite generar índices de sensibilidad independientes para cada parámetro de entrada a través de la búsqueda en todo el espacio de los parámetros de entrada, donde se estiman el valor esperado y la varianza del parámetro. La idea del método es convertir la ecuación (8) en una integral unidimensional s utilizando las funciones de transformación Gi:
donde s∈(−π, π). Una buena elección de la transformación Gi y la frecuencia ωi permitirá evaluar el modelo en un número suficiente de puntos [22]. De hecho, si se elige un conjunto linealmente independiente de frecuencias ω1, …, ωk, para s∈{−∞, ∞}, el vector obtenido Xi(s), …, Xn(s) traza una curva que cubre completamente el espacio n−dimensional del cubo unitario Kn (ωi no puede obtenerse como una combinación lineal de otras frecuencias con coeficientes enteros). Esta curva se define de modo que sea periódica, con diferentes intervalos relativos a cada parámetro. El proceso de transformación se define como Xi(s)=12+1πarcsin(sin(ωis)), para s determinado por el tamaño de la muestra N: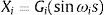
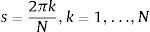
Debido al uso de frecuencias impares y a las propiedades de las series de Fourier, en las aplicaciones FAST, s=πr(2j−r−12),j=1,…,r y r=N2. Entonces, el valor esperado de Y puede aproximarse por:
para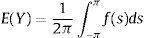
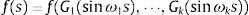
En consecuencia, se puede aproximar la varianza de Y como:
donde Ai y Bi son los coeficientes de Fourier. La contribución de Xi en la varianza V(Y) puede aproximarse por:donde ωi está relacionado con su valor Gi en la ecuación (16) para p=1, 2⋯M. Entonces, M será el armónico máximo. Los coeficientes de sensibilidad por el método FAST para cada parámetro se calculan:3.2Simulación y discrepancia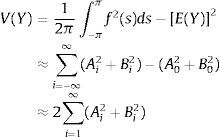
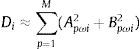
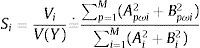
El número de iteraciones necesarias para calcular la precisión es un dato importante para evaluar las simulaciones. A menos iteraciones, más eficiencia. Además, también hay que evaluar la capacidad de detener el análisis cuando se haya alcanzado la precisión suficiente, lo cual supone menos tiempo de cálculo. Esta posibilidad se denomina convergencia del cálculo. En este trabajo, evaluamos dos enfoques para obtener los índices de sensibilidad de nuestro método de calibración, que se describen en las secciones 3.2.1 y 3.2.2, respectivamente.
Dado que los parámetros del modelo de calibración siguen diferentes tipos de distribuciones, es complicado definir una distribución estadística universal para todo el modelo. Comúnmente, se opta por aproximar el comportamiento estadístico de un modelo complejo a una distribución normal (ecuación (20)). Para nuestro estudio, hemos decidido generar los datos que alimentan el análisis de la sensibilidad con cinco diferentes distribuciones (secuencias de Halton y de Sobol; distribuciones normal, uniforme y multivariada). El objetivo es observar un patrón de comportamiento y cuantificar acertadamente los parámetros de mayor sensibilidad, independientemente de qué tipo de distribución tengan el modelo o los parámetros.
El modelo continuo más importante estadísticamente para desarrollar técnicas de inferencia es la distribución normal X∼N(μ, σ), donde μ es el promedio y σ, su desviación estándar. Dado que, en gran parte de la literatura, los modelos de calibración y simulación se aproximan a esta distribución, decidimos incluirla en nuestro análisis, cuya función de densidad se observa en la ecuación siguiente:
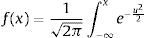
Decidimos implementar la distribución multivariada X∼N(μ, V), donde V es la matriz de varianzas/covarianzas. Podemos representar su función de densidad como:
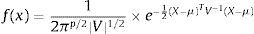
Otra de las características importantes es que todos los valores sigan una distribución uniforme en el espacio Is=[0, 1]s, que exista una convergencia rápida y, además, que sean algoritmos con baja discrepancia.
La discrepancia es una forma de medir la desviación de una secuencia de números con respecto a la distribución uniforme. Considerando los métodos de simulación que se utilizan en este trabajo, es importante implementar técnicas que tengan un bajo valor de discrepancia. Sea un conjunto de parámetros P=x1, x2, …, xn∈Is. Para un subconjunto B en Is, se define la función de análisis de discrepancia, que analiza cuántos elementos de P pertenecen a B mediante la ecuación (22), donde cB es la función característica del conjunto B(cB(x)=1) para x∈B
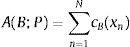
Para una familia no vacía de subconjuntos ß⊆Is medibles en el sentido de Lebesgue, la forma de cuantificar la discrepancia para un conjunto de puntos P viene dada por la ecuación (23), donde λs es la medida de Lebesgue s-dimensional
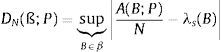
En [23], se presenta un algoritmo generador de números aleatorios de baja discrepancia, en que cada nuevo punto es calculado por un mecanismo que considera la restricción de alta correlación con los números precedentes, y se evitan así los clústeres. Se puede afirmar que un conjunto P se considera de baja discrepancia si tiene valores pequeños en DN(P).
Una secuencia de Halton [10] con dimensión s se define mediante la expresión X(n)=gb1(n),…,gbs(n), utilizando como base los números b1, …, bs primos entre sí para bi>1≤i≤K. En términos de la métrica de discrepancia, la secuencia de Halton cumple la propiedad siguiente:
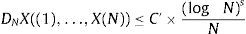
Un problema que existe en la secuencia de Halton es la degradación, ya que, como se ha dicho, la secuencia utiliza un número primo para cada dimensión del espacio a muestrear. El tiempo de cálculo se incrementa linealmente a medida que la dimensión del espacio crece.
Por tanto, la secuencia de Halton multidimensional tiene un ciclo muy largo, dado que utiliza el n−ésimo número primo, por lo cual se requieren varios pasos para completar un recorrido completo en [0, 1)s.
La secuencia de Sobol [24] (que no debe confundirse con el método de Sobol para el análisis de la sensibilidad) tiene una formulación similar a la de Halton, con la diferencia de que esta técnica utiliza únicamente una base para todas las dimensiones e incorpora un método de reordenamiento de los elementos. Podemos definir una secuencia de Sobol como:
donde b es la base en que está representado un número entero positivo n>1 utilizando valores dk, para 0≤dk<b. Para cualquier número de base b, los elementos de una secuencia de Sobol están uniformemente distribuidos en un intervalo [0, 1]. En función de la métrica de discrepancia, las secuencias de Sobol cumplen con la propiedad siguiente: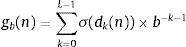
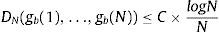
En el caso multidimensional, la secuencia se obtiene mediante la reordenación de los valores obtenidos de manera unidimensional, y se evitan así los problemas de generación de clústeres. La secuencia de Sobol es más resistente a la degradación, aun cuando las dimensiones aumenten, pero es recomendable descartar los primeros n puntos generados.
3.2.1MCEl análisis de MC utiliza, para generar las entradas independientes X1, X2, ...., Xk, un muestreo aleatorio para variables no correlacionadas. Cada elemento es generado independientemente de todos los demás elementos de la muestra, y la probabilidad de que este elemento pertenezca a un subconjunto del espacio de muestreo es igual a la probabilidad del subconjunto. Para la técnica MC, se generan tres tipos de datos de secuencias de salida: (1) La secuencia de Sobol, que genera números aleatorios de baja discrepancia; (2) la secuencia de Halton, que trabaja en espacios multidimensionales, y (3) la secuencia con distribución normal.
3.2.2LHSUn planteamiento para calcular un conjunto de resultados representativos sin un consumo tan elevado de recursos es el método LHS. Se basa en el muestreo estratificado de las distribuciones de probabilidad [12,13]. Este enfoque consiste en dividir cada distribución en intervalos iguales de probabilidad n, donde n es el número de simulaciones. En cada iteración, se selecciona un valor para cada parámetro por cada distribución. Por ejemplo, si cada distribución se divide en dos partes y cada una tiene p parámetros, entonces tendremos 2p posibles conjuntos de regiones para seleccionar. En un caso más general, el uso de p parámetros implica la división de los rangos en p particiones equiprobables. Los rangos constituirán las aristas del hipercubo n−dimensional, que quedará dividido en un total de pn subcubos. A continuación, se seleccionarán p muestras dentro del hipercubo con la restricción de que, por un lado, cada muestra debe ubicarse aleatoriamente dentro de un subcubo y, por otro, cada proyección unidimensional de los p parámetros y particiones solo ha de encontrarse una muestra en cada subcubo.
Para la técnica de LHS, generamos tres tipos de datos de secuencias de salida. (1) La secuencia con distribución normal. Este método nos permite generar un muestreo por LHS de cualquier muestra no ortogonal con la misma dependencia. (2) La secuencia con distribución uniforme por el método de Iman-Conover [14]. Este método, también denominado transformación por rangos, consiste en reemplazar los datos de entrada al modelo (originales) por sus rangos, para luego aplicar una prueba paramétrica (por ejemplo, la prueba de Fisher). De este modo, es más probable que se satisfaga la homogeneidad de las varianzas en los datos simulados. (3) La secuencia con distribución multivariada.
4ResultadosLos índices de sensibilidad representan la contribución de cada parámetro a la varianza de salida y se dividen en índices de sensibilidad global y total, como se explica en la sección 3.1. Los índices globales miden la influencia media de un parámetro sobre la salida del modelo, pero no toman en consideración la relación que tienen los parámetros entre sí. Los índices de sensibilidad total calculan la suma de los índices factoriales que involucran el parámetro considerado, es decir, su sensibilidad de primer orden, más todos los efectos que sean producto de las interacciones en el modelo. En este estudio, hemos decidido evaluar ambos índices de sensibilidad para determinar la robustez del modelo de calibración presentado en [8] y calcular la relevancia de las incertidumbres calculadas en [9].
4.1CámaraPara cada parámetro involucrado en la calibración, se han simulado 2.000 muestras por MC y LHS (sección 3.2). La cámara fue calibrada intrínsecamente por tres técnicas: (1) La técnica de Tsai [26], la cual está basada en el modelo de pinhole, en que la distorsión radial se corrige a partir de un solo coeficiente. (2) La técnica de Heikkilä [10], que hace una estimación de los parámetros utilizando un patrón conocido a través de la transformación lineal directa (DLT, por sus siglas en inglés), para la transformación de las coordenadas del patrón a coordenadas en la referencia de la imagen; este método ignora las componentes no lineales de distorsión tangencial y radial. El objetivo es, pues, resolver los parámetros de la matriz DLT, primero normalizando para evitar una solución trivial y resolver la ecuación con una técnica pseudoinversa, por ejemplo la SVD. (3) La técnica de Zhang [28], que se basa en el proceso de observación de un patrón en diferentes posiciones y orientaciones. La ventaja de este método es que no es necesario conocer la ubicación de las marcas de referencia en la escena como en la técnica de Tsai.
En general, el proceso de calibración se basa en: a) la conversión del sistema de coordenadas del mundo al de la cámara (parámetros extrínsecos), b) la corrección de distorsiones y c) la obtención de las coordenadas 2D de la imagen (parámetros intrínsecos).
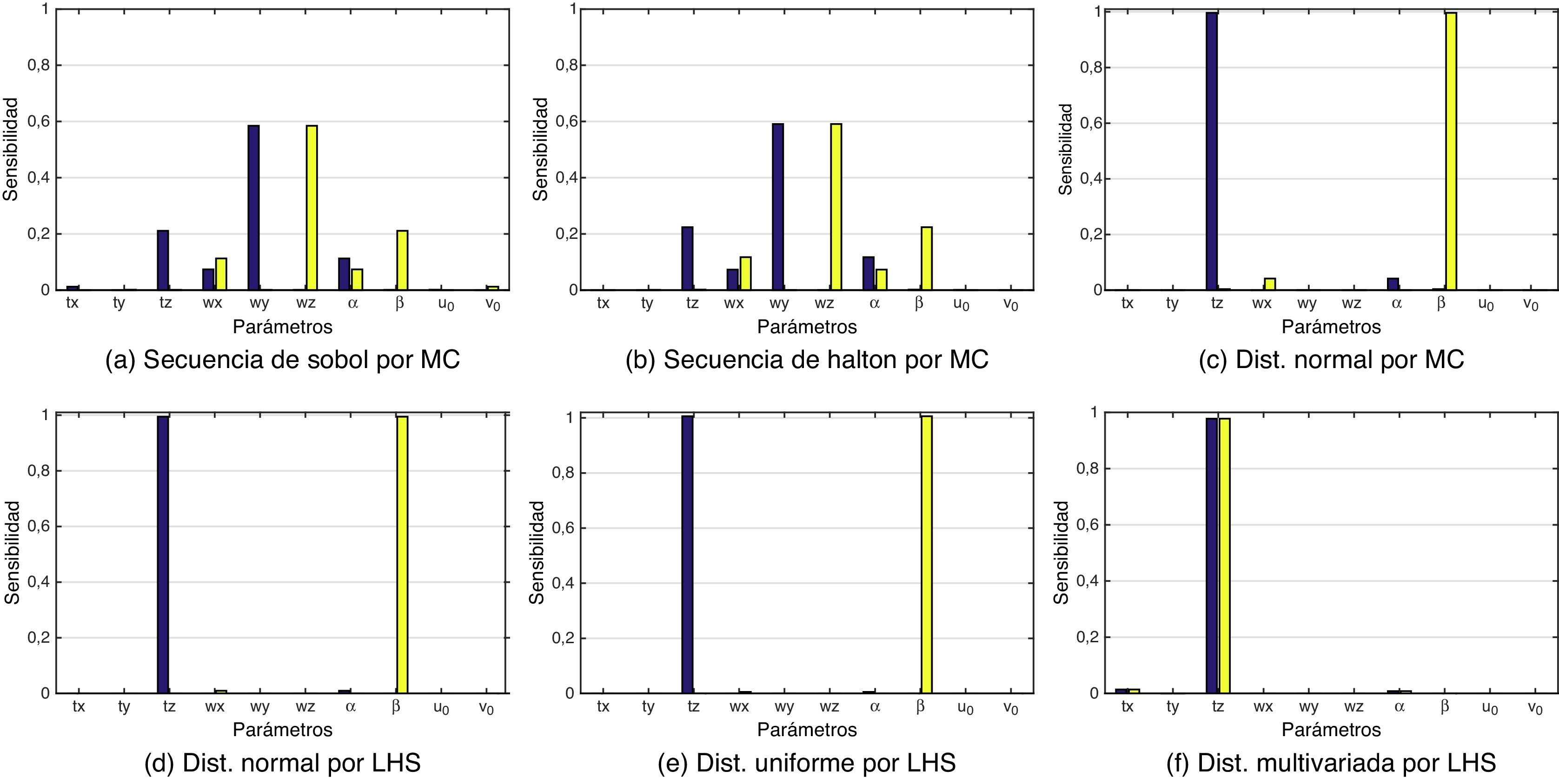
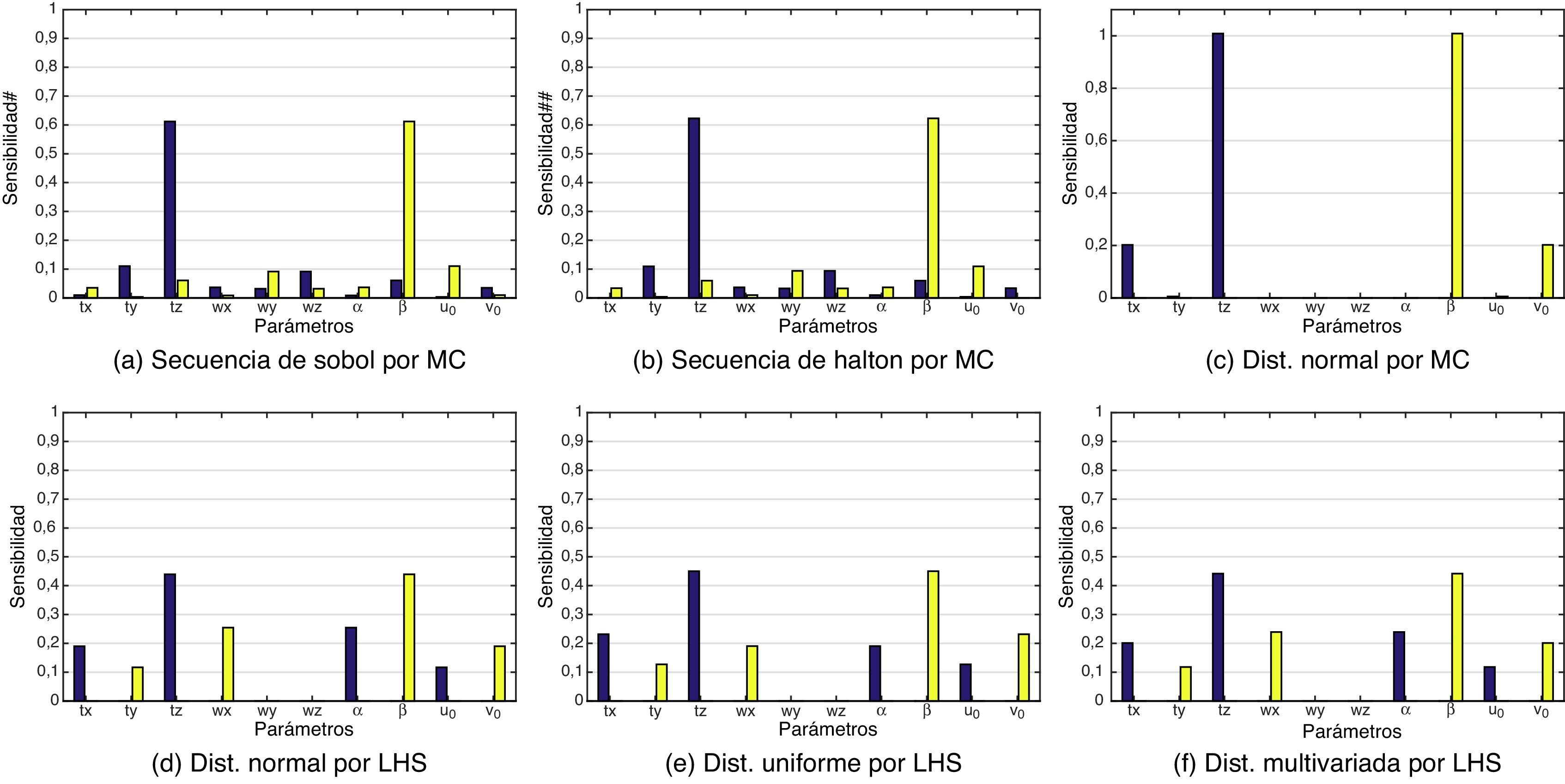
Como se ha explicado anteriormente, el análisis de sensibilidad se llevó a cabo por dos métodos: Sobol y FAST. En el método de Sobol, el cálculo de los índices Si y Sitot (ecuaciones (9) y (12), respectivamente) tiene un coste computacional elevado, debido al gran número de operaciones realizadas al descomponer la varianza del modelo para cada uno de los parámetros. Las figuras 4, 5 y 6 muestran seis gráficas, una para cada distribución sobre la cual se ha realizado el análisis de sensibilidad, como ya se ha explicado en la sección 3.2.
. Se han simulado los datos de entrada al modelo por MC y LHS, con cinco diferentes distribuciones. Las gráficas muestran la tendencia en que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 3 muestra los resultados por el método FAST.")
Calibración por la técnica de Tsai para el método de Sobol (morado Si y amarillo Sitot). Se han simulado los datos de entrada al modelo por MC y LHS, con cinco diferentes distribuciones. Las gráficas muestran la tendencia en que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 3 muestra los resultados por el método FAST.
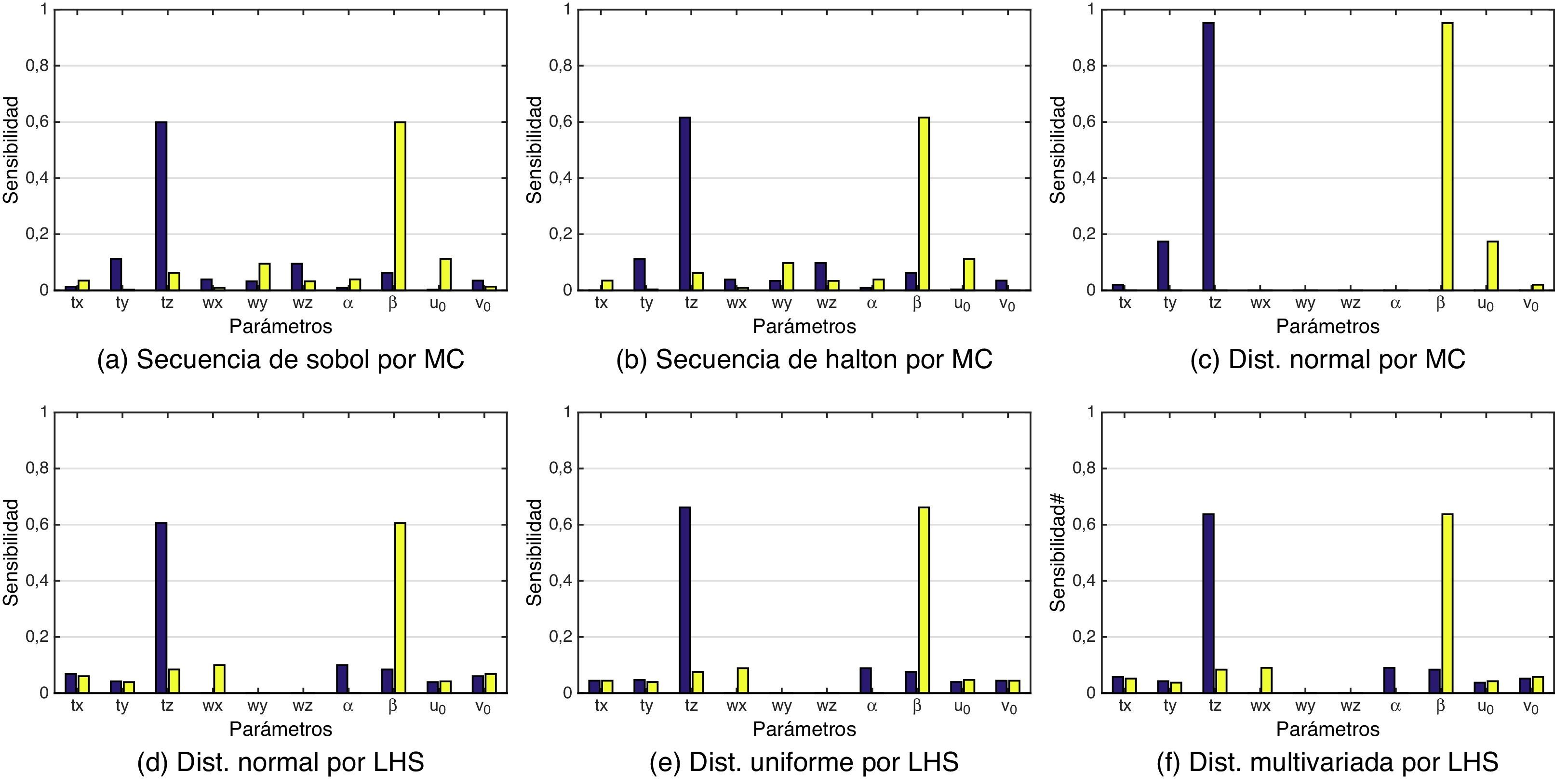
. Se han simulado los datos de entrada al modelo por MC y LHS con cinco distribuciones distintas. Las gráficas muestran la tendencia en que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 3 muestra los resultados por el método FAST.")
Calibración por la técnica de Heikkilä para el método de Sobol (morado Si y amarillo Sitot). Se han simulado los datos de entrada al modelo por MC y LHS con cinco distribuciones distintas. Las gráficas muestran la tendencia en que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 3 muestra los resultados por el método FAST.
. Se han simulado los datos de entrada al modelo por MC y LHS con cinco distribuciones distintas. Las gráficas muestran la tendencia de que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 5 muestra los resultados por el método FAST.")
Calibración por la técnica de Zhang para el método de Sobol (morado Si y amarillo Sitot). Se han simulado los datos de entrada al modelo por MC y LHS con cinco distribuciones distintas. Las gráficas muestran la tendencia de que los parámetros tz y β son los más relevantes, es decir, los más sensibles. La tabla 5 muestra los resultados por el método FAST.
En el análisis de Tsai y Heikkilä, se observa que el parámetro tz tiende a ser el predominante en el índice de sensibilidad global (sin tener en cuenta la interacción entre los parámetros), es decir, la profundidad a la cual se encuentran las posiciones de referencia en la escena. Esto se debe a que las distorsiones radial y tangencial dependen de la distancia de estos puntos a la lente. El índice de sensibilidad total (contando la interacción entre los parámetros) más relevante es β (v. ecuación (4)). Nuevamente, este parámetro tiene que ver con la profundidad, aunque ahora se trata de la distancia entre el sensor CCD y la lente de la cámara. En la ecuación (4), se define f, que es una distancia expresada en metros - por ejemplo, el píxel tiene las dimensiones 1ku×1kv, las cuales son expresadas en pixeles×m−1. Los parámetros ku,kv y f no son independientes y pueden reemplazarse por el factor de escala α=ku*f y β=kv*f, expresadas en píxeles. Las diferencias de sensibilidad entre α y β son debidas a las dimensiones del píxel ya que, por lo regular, los píxeles no son cuadrados.
Aunque también wz muestra un valor a tener en cuenta, que es la rotación del eje de profundidad, es interesante observar que la distancia del patrón de calibración con respecto a la cámara tiene un efecto determinante en la calibración.
En la calibración por la técnica de Zhang, se observa que el parámetro con mayor sensibilidad global es tz, comportamiento que ya se ha observado en el análisis de Heikkilä. Otro parámetro que presenta una sensibilidad total destacada es β. Queda demostrado que ambos parámetros son muy relevantes (tabla 2) al comprobar que se obtienen los mismos resultados por las dos técnicas de calibración evaluadas en este trabajo. En [9], se presenta un comportamiento similar, pero analizado desde la perspectiva de la propagación del error en la calibración LiDAR-cámara.
Podemos afirmar entonces que los parámetros involucrados directamente con la distancia del patrón de calibración y las distorsiones de la imagen tienden a ser los más relevantes en la propagación del error. Este error se puede minimizar de tres formas: 1) eliminando la distorsión de las imágenes y normalizándolas, 2) aumentando las posiciones de referencia que se procesan en los métodos de calibración y 3) mejorando la calidad del patrón de calibración. En el caso de la técnica de Tsai, sería aumentar las marcas de referencia en la escena, lo que hace más laborioso este procedimiento. Por otro lado, esto demuestra la flexibilidad que supone seguir un enfoque de calibración que utilice un patrón.
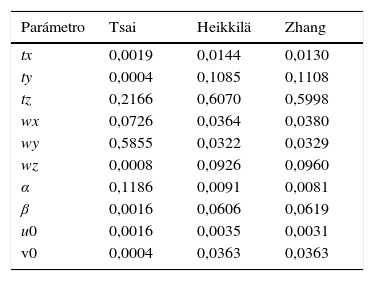
El segundo método implementado fue FAST. Este método nos da índices de primer orden Si según la ecuación (19). La tabla 3 muestra la sensibilidad cuantificada según FAST. Se observa que los parámetros tz y wy son los más sensibles en la técnica de Tsai. Ello es debido a que los datos que utiliza para calibrar son las coordenadas del patrón referenciado a un punto fijo en el mundo; en consecuencia, cualquier error en la medición de las coordenadas hace variar a los parámetros. Este comportamiento también se puede observar en la figura 4(a) - 4(b). Por otro lado, en la técnica de Zhang, el parámetro tz resulta el parámetro sensiblemente predominante, al igual que la técnica de Heikkilä. Al igual que en Sobol, la profundidad es importante. Esta condición puede reducirse utilizando un patrón con más esquinas. Estos resultados confirman los experimentos realizados por [25] de manera empírica y también los que se muestran en las gráficas de la figura 6.
Análisis de sensibilidad por el método FAST, según la ecuación (19) para la cámara. Se observa que los parámetros tz y wy son los más sensibles. El parámetro tz coincide con el análisis por el método de Sobol, y marca una tendencia a introducir error.
| Parámetro | Tsai | Heikkilä | Zhang |
|---|---|---|---|
| tx | 0,0019 | 0,0144 | 0,0130 |
| ty | 0,0004 | 0,1085 | 0,1108 |
| tz | 0,2166 | 0,6070 | 0,5998 |
| wx | 0,0726 | 0,0364 | 0,0380 |
| wy | 0,5855 | 0,0322 | 0,0329 |
| wz | 0,0008 | 0,0926 | 0,0960 |
| α | 0,1186 | 0,0091 | 0,0081 |
| β | 0,0016 | 0,0606 | 0,0619 |
| u0 | 0,0016 | 0,0035 | 0,0031 |
| v0 | 0,0004 | 0,0363 | 0,0363 |
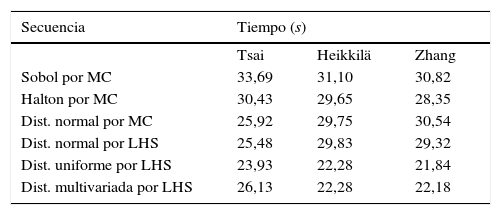
Hablando de los tiempos de simulación entre las técnicas de calibración y las distribuciones elegidas en este trabajo, se observa en la tabla 4 que: 1) la calibración por la técnica de Tsai utilizando la secuencia de Sobol para generar los datos de simulación requiere 33 segundos y es la que más tiempo necesita; 2) la técnica de Zhang con datos simulados siguiendo una distribución uniforme es la que necesita menos tiempo de cómputo, con 21,84 segundos; 3) en general, cada simulación requiere un tiempo de cómputo en el rango de los 20 y los 30 segundos para generar 2.000 datos. Además, la técnica de Tsai requiere más que Zhang, y la técnica de Heikkilä consume casi el mismo tiempo que la de Zhang, ya que ambas usan patrones de calibración móviles.
Tiempo de simulación de 2.000 valores utilizando diferentes distribuciones para las técnicas de MC y LHS en el análisis de sensibilidad de la cámara.
| Secuencia | Tiempo (s) | ||
|---|---|---|---|
| Tsai | Heikkilä | Zhang | |
| Sobol por MC | 33,69 | 31,10 | 30,82 |
| Halton por MC | 30,43 | 29,65 | 28,35 |
| Dist. normal por MC | 25,92 | 29,75 | 30,54 |
| Dist. normal por LHS | 25,48 | 29,83 | 29,32 |
| Dist. uniforme por LHS | 23,93 | 22,28 | 21,84 |
| Dist. multivariada por LHS | 26,13 | 22,28 | 22,18 |
Estas diferencias en tiempo dependen de la complejidad de los modelos de calibración y de los algoritmos de simulación. Por ejemplo, el tiempo de cómputo para generar la secuencia de Halton se incrementa linealmente a medida que aumenta la dimensión del espacio a muestrear, aunque esto es compensado al tener un muestreo más homogéneo de los parámetros y, en consecuencia, un análisis mucho más preciso. Las simulaciones se implementaron en una máquina Intel®Xeon® Dual Core (2, 40 GHz), con 8 Gb de RAM.
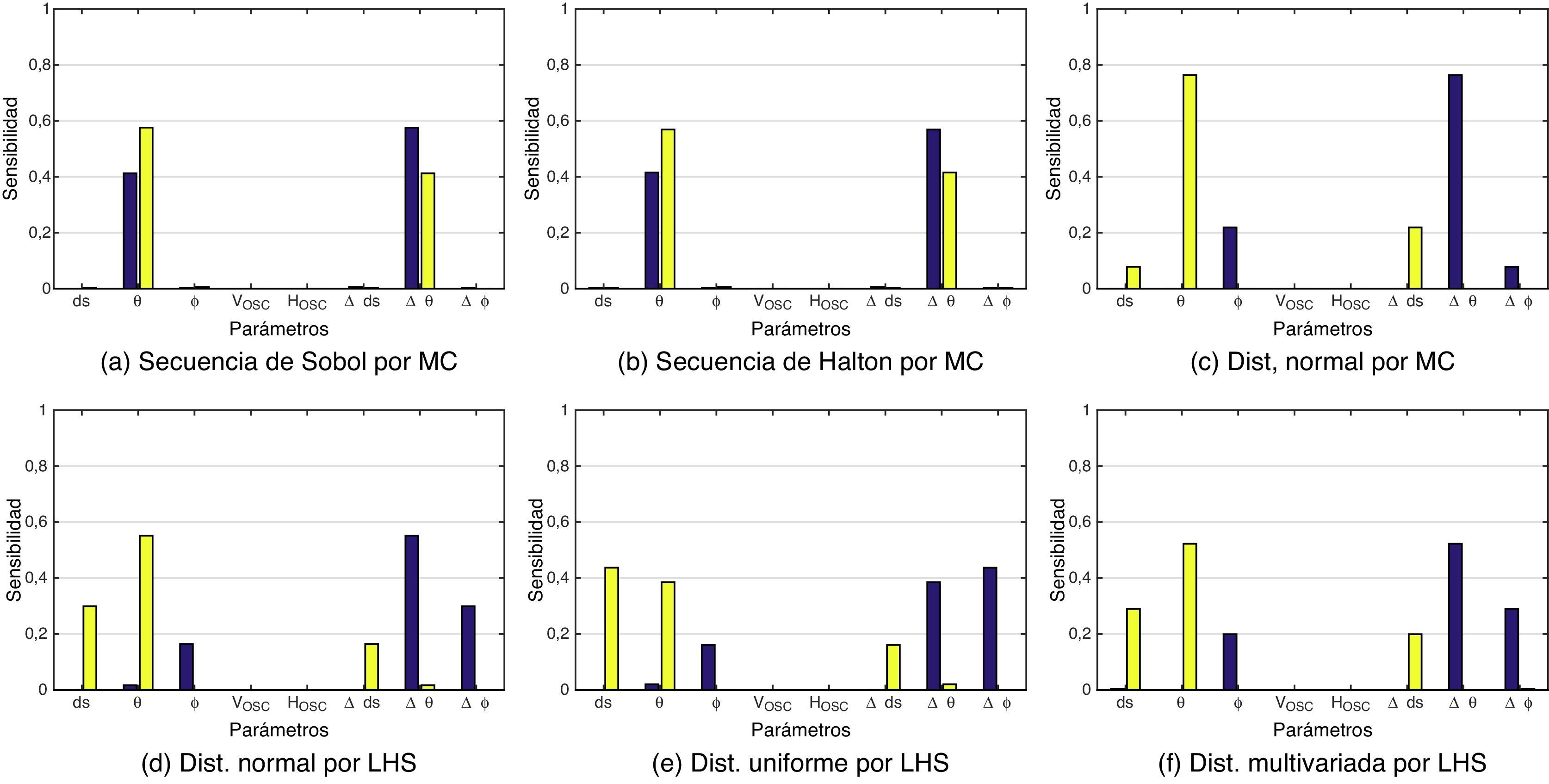
4.2LiDARSiguiendo la misma metodología utilizada para el análisis de la cámara, se ha calculado la sensibilidad de los parámetros de calibración del LiDAR por el método de Sobol. La figura 7 muestra las gráficas de los índices globales (Si) y los totales (Sitot). Se puede observar que los parámetros θ y Δθ son los que introducen mayor incertidumbre en el modelo de calibración. El parámetro θ corresponde al ángulo de orientación del LiDAR y está relacionado con la parte mecánica de su rotación, mientras que Δθ es un factor de corrección de la orientación de cada uno de los láseres, debido a que no todos ellos se encuentran en un solo plano.
 para la calibración del LiDAR. Se han simulado los datos de entrada al modelo por MC y LHS, con cinco distribuciones distintas. Las gráficas muestran la tendencia de que θ y Δθ son los parámetros más relevantes, es decir, los más sensibles. La tabla 5 muestra los resultados por el método FAST.")
Índices de Sobol (morado Si y amarillo Sitot) para la calibración del LiDAR. Se han simulado los datos de entrada al modelo por MC y LHS, con cinco distribuciones distintas. Las gráficas muestran la tendencia de que θ y Δθ son los parámetros más relevantes, es decir, los más sensibles. La tabla 5 muestra los resultados por el método FAST.
Por medio del método FAST, los índices de sensibilidad coinciden con el método de Sobol (v. figura 7), y determinan que tanto θ como Δθ son los parámetros más sensibles a introducir ruido en el modelo y, en consecuencia, a aumentar la incertidumbre de error en la salida de los valores de calibración (5).
Análisis de sensibilidad por el método FAST según la ecuación (19) para el LiDAR. Se observa que los parámetros θ y Δθ son los más sensibles a introducir error.
| Parámetro | FAST |
|---|---|
| ds | 0,014 |
| θ | 0,4137 |
| ϕ | 0,0004 |
| Vosc | 0,016 |
| Hosc | 0,0 |
| Δds | 0,0006 |
| Δθ | 0,5552 |
| Δϕ | 0,0 |
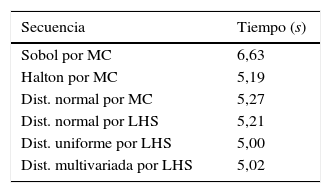
Los tiempos de simulación para el LiDAR se sitúan entre los 5 y 6 segundos para la generación de 2.000 valores, como se observa en la tabla 6, y son la distribución uniforme y la secuencia de Sobol las que menor y mayor tiempo requieren, respectivamente.
Tiempo de simulación de 2.000 valores utilizando diferentes distribuciones para las técnicas de MC y LHS en el análisis de sensibilidad del LiDAR.
| Secuencia | Tiempo (s) |
|---|---|
| Sobol por MC | 6,63 |
| Halton por MC | 5,19 |
| Dist. normal por MC | 5,27 |
| Dist. normal por LHS | 5,21 |
| Dist. uniforme por LHS | 5,00 |
| Dist. multivariada por LHS | 5,02 |
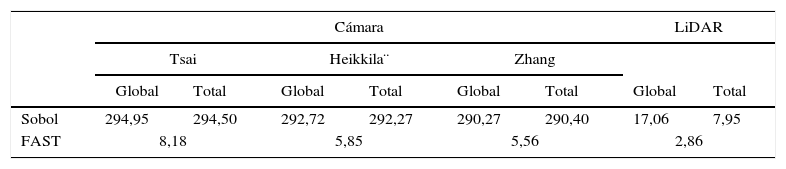
El tiempo de ejecución computacional necesario para realizar el análisis de sensibilidad por los métodos de Sobol y FAST en los procesos de calibración de la cámara y del LiDAR se muestra en la tabla 7. En este análisis, se observa que el método FAST es más rápido que el método de Sobol. Esto se debe a que lleva más tiempo descomponer la varianza y, cuantos más parámetros se evalúan, más tiempo se requiere. No existe una diferencia significativa entre las técnicas de calibración para la cámara. El método de Sobol requiere una media de 292 segundos en completarse, frente a los 5,85 segundos requeridos por el método de FAST. Para el análisis del LiDAR, se ha observado que el análisis de sensibilidad global consume más tiempo que el análisis total, 17,06 frente a 7,95, respectivamente. El método FAST para el LiDAR tardó cerca de 2,86 segundos.
En general, es necesario que las técnicas de simulación cubran todo el espacio de variación que los parámetros tienen con la misma probabilidad, de manera que, cuando se generen las muestras aleatorias, estas cubran homogéneamente las dimensiones de cada uno de los parámetros.
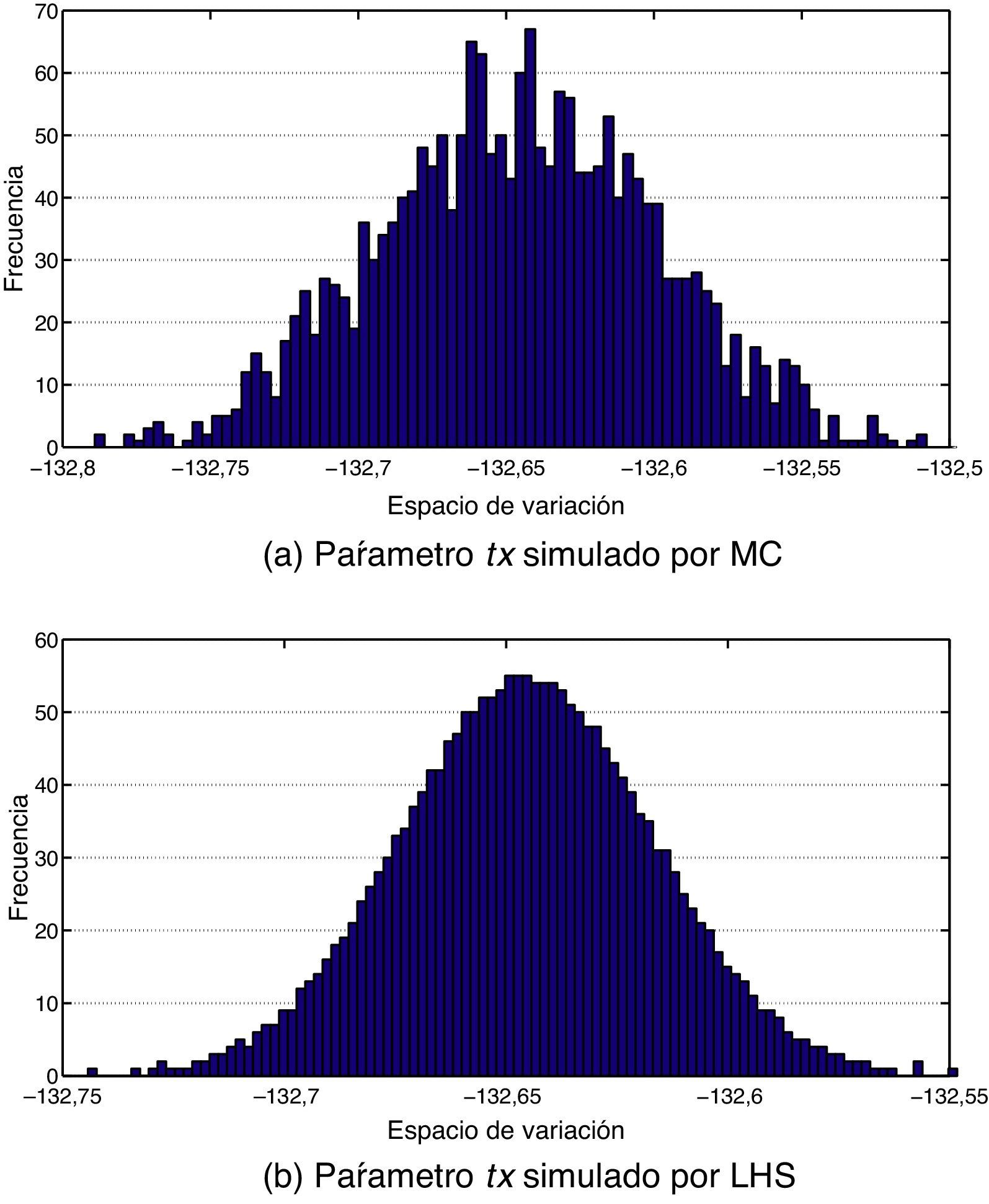
Podemos concluir que las técnicas aleatorias por medio de MC no aseguran esta condición. Por otro lado, la técnica de LHS crea subespacios con la misma importancia y con la misma probabilidad de éxito; en este caso (figura 8), el método LHS dividió en 2.000 estratos la dimensión de variación del parámetro tx para asegurar que su probabilidad de ocurrencia es homogénea. Esta necesidad de homogenizar las simulaciones asegura una mayor precisión en los índices de sensibilidad, como se presenta en [13].

Hablando un poco de la discrepancia en la secuencia de números aleatorios generados, podemos concluir que las secuencias de Halton y de Sobol presentan una mayor complejidad de O(N−1(logN)s−1), por comparación a las técnicas estándar de MC y LHS, en que es del orden de O(1/N).
5ConclusionesLa exactitud de las posiciones de referencia del patrón, el modelo de la cámara y la técnica de calibración son los principales aspectos que afectan la sensibilidad en la calibración cámara-LiDAR. El propósito de este análisis ha sido determinar la precisión con que se realizan las reconstrucciones tridimensionales y qué factores intervienen en el error. Ello permitirá, a corto plazo, obtener modelos urbanos en 3D más reales.
La técnica de simulación que consume más tiempo es la de MC. La secuencia de Sobol es más eficiente que la de Halton, ya que requiere menos tiempo de cómputo, al utilizar la misma base para todas las dimensiones (b=2).
Se ha demostrado que los parámetros tz y β (muy relevantes, v. tabla 2) son los más sensibles en nuestro modelo de calibración. Se han llevado a cabo pruebas de sensibilidad con las técnicas de calibración de Tsai, Heikkilä y Zhang. Y, en las tres técnicas, se ha concluido que los parámetros involucrados en la distancia (la profundidad) entre la cámara y el patrón de calibración son los más propensos a introducir error en los datos de la cámara, como también se ha deducido del análisis de incertidumbres de [9]. Nuestros resultados indican que la técnica de Tsai es más sensible, ya que se basa en unos datos precisos de entrada al modelo (figura 4), frente a las técnicas de Heikkilä y Zhang (figuras 5 y 6).
Estudios de sensibilidad o incertidumbre como el que aquí se presenta suelen basarse en un gran número de parámetros. Lo ideal sería evaluar cada parámetro con la distribución de probabilidad que lo caracteriza, lo cual se traduciría en un consumo excesivo de recursos. Por ello, se requiere un método eficiente para poder obtener los resultados más fiables (sección 3.2). La técnica de LHS tiende a calcular unos resultados más estables, es decir, con menos variabilidad y de rápida convergencia, y ha demostrado su eficiencia para el análisis presentado en este trabajo. Los métodos de Sobol y FAST permiten una variedad de análisis de sensibilidad muy amplia. El inconveniente es que, cuantos más parámetros tiene el modelo, más tiempo de cómputo se requiere para descomponer la varianza. Esta es la razón fundamental para escoger una metodología de simulación adecuada a la técnica de análisis de la sensibilidad, en nuestro caso LHS.
Ulteriores trabajos deberán incluir otras técnicas de calibración tanto para la cámara como para el sensor láser que estén centradas en los parámetros con más sensibilidad. También deberán implementarse otras técnicas de análisis de sensibilidad mediante métodos matemáticos basados en la probabilidad para poder comparar los resultados obtenidos en esta investigación. Los desarrollos posteriores deberán basarse en la reducción del error en la calibración de la plataforma de adquisición, puesto que, con los datos obtenidos en esta investigación y en otras anteriores [9], somos capaces de minimizar la propagación del error en los datos al conocer su sensibilidad e incertidumbre. También deberán analizarse las desviaciones de error que presentan los índices de sensibilidad.
Los autores agradecen el apoyo económico que han recibido para la realización de este trabajo del Consejo Nacional de Ciencia y Tecnología (CONACYT), a través de los proyectos SEP−2005−O1−51004/25293, y del Instituto Politécnico Nacional, a través del proyecto SIP−20151617. Este trabajo se ha desarrollado en el Centro de Investigación en Ciencia Aplicada y Tecnología Avanzada (CICATA) de Querétaro, México.