







Los modelos empleados para la caracterización del proceso de pirólisis de los materiales han evolucionado de forma paralela a las capacidades computacionales y a la adquisición de destrezas en la aplicación de nuevos ensayos de caracterización de materiales que provienen de campos próximos como el de la ingeniería química. Así, se utilizan modelos que no solo caracterizan las propiedades físicas de los materiales (inercia térmica), sino también los mecanismos y ritmos de reacción de los procesos de pérdida de masa asociados a la liberación de combustibles volátiles (triplete cinético). Esta descripción detallada implica una gran cantidad de parámetros, lo que hace difícil un ajuste de la respuesta del material, por lo que se hace necesario aplicar herramientas para su optimización. En este estudio se presenta la optimización para 2 materiales con mecanismos diferenciados, uno real con un proceso caracterizado por un solo paso, y otro sintético de 2 pasos. A continuación se estudia la importancia de ciertas variables en la velocidad y precisión del algoritmo (diversidad de la población, amplitud del rango de entrada de los parámetros, influencia del tipo de mezcla).
The pyrolysis models undergoes a fast development due to the enhancement of both the computational power and the new test used to characterize the behaviour of materials under thermal stresses, which were widely used in the field of the chemical engineering to obtain the reaction rates. Thus, these models allow us to characterize either the transient heat of material (thermal inertia) or the complete chemical scheme of mass loss processes (kinetic triplet). The pyrolysis model needs a several number of parameters what does the optimization of a suitable set of parameters a difficult task. Two kinds of materials have been investigated; the first one was a real material which mass loss process was characterized as “one-step” reaction and the second one as a “two-steps” process. Further, it has been analyzed the influence of some algorithm features (initial population number, parameter range, crossover influence) in the optimization time and also in the accuracy of results.
La aplicación de los procedimientos actuales de la ingeniería de la seguridad contra incendios implica el conocimiento detallado de la respuesta de todo tipo de materiales ante solicitaciones térmicas diversas (que se producen en entornos cerrados durante las distintas fases de desarrollo de un incendio). Para ello, y dados los costes de la experimentación a escala real, se han desarrollado distintos modelos computacionales de simulación de la dinámica de incendio (MSCI). Estos modelos tienen diferentes componentes que representan los fenómenos físico-químicos producidos en el desarrollo del evento de incendio (fenómenos de transporte de calor y masa, de descomposición y degradación del material, etc.).
La componente del modelo de fase sólida a la que vamos a aplicar la técnica de algoritmos evolutivos es el denominado modelo de fase sólida, es decir la caracterización de la respuesta del material ante solicitaciones térmicas precisas. Esto permitirá conocer la distribución de temperaturas en su interior y el modo en que convierte masa en volátiles al aumentar su temperatura (produciendo, o no, residuos en distintos estados de agregación). Como modelo de fase sólida se utilizó el implementado en el MSCI Fire Dynamics Simulator (FDS5) versión 5.4.3 del National Institute of Standards and Technologies (NIST) [1] que es un modelo de dinámica de incendio con múltiples trabajos de validación a nivel internacional [2].
Los algoritmos evolutivos son utilizados principalmente en problemas con espacios de búsqueda extensos y no lineales, en donde otros métodos no son capaces de encontrar soluciones en un tiempo razonable. Siguiendo la terminología de la teoría de la evolución, las entidades que representan las soluciones al problema se denominan individuos o cromosomas, y el conjunto de estos, población. Los individuos son modificados por operadores genéticos, principalmente el sobrecruzamiento, que consiste en la mezcla de la información de dos o más individuos; la mutación, que es un cambio aleatorio en los individuos, y la selección, consistente en la elección de los individuos que sobrevivirán y conformarán la siguiente generación. Dado que los individuos que representan las soluciones más adecuadas al problema tienen más posibilidades de sobrevivir, la población va mejorando gradualmente.
El algoritmo utilizado está basado en el desarrollado por Chris Lautemberger para el modelo de pirólisis GPYRO [3]. Se efectuaron modificaciones para obtener un algoritmo de tipo elitista [4] y se redefinió el proceso de selección (fitness). Se parte de un concepto diferente en la selección de población de partida (mayor número de individuos), dado que una población mayor de partida añade una variabilidad inicial a los datos necesaria para sistemas de ecuaciones con tantos grados de libertad.
Para la evaluación del algoritmo se han seleccionado 2 casos de modelado de pirólisis: un proceso con un esquema de reacción en un solo paso (material honeycomb utilizado en aplicaciones aeronáuticas que sufre carbonizado) y un proceso con un esquema de reacción en 2 pasos (mecanismo de Broido-Shafizadeh [5,6] para la celulosa). Como elemento de comparación se utilizó la curva de pérdida de masa (MLR) a distintos flujos obtenida en un cono calorimétrico (ISO 5660). También se obtuvieron otros resultados sobre el funcionamiento del algoritmo (variabilidad de los parámetros en distintas fases del proceso y, con distintos procesos de mezcla, dependencia del rango inicial de parámetros). Inicialmente se procede a describir el modelo computacional de fase sólida que va a utilizarse (combustible sólido de FDS) desde el punto de vista matemático [7] definiendo la selección de parámetros que va a realizarse para caracterizar el material. A continuación se describirá con detalle el algoritmo implementado en MATLAB(c) versión 7.7. Se hará una descripción del proceso que hay que modelar, y se presentarán los resultados del modelado para los distintos escenarios de partida del algoritmo evolutivo.
2Procedimiento2.1Modelado computacional de la reacciónEl estudio de la reacción al fuego de un combustible sólido ha sido afrontado en numerosas ocasiones, a pesar de esto, aún no está definida una metodología clara que permita desarrollar el modelado eficiente de un material complejo. Menos aún cuando esto depende, entre otras cosas, del tipo de resultados disponibles, es decir, de si se tienen únicamente las curvas de cesión de calor (por ejemplo, a partir de ensayos de cono calorimétrico) y las descripciones experimentales previas (propiedades físicas como densidades, espesores, etc.), o de si se dispone de otro tipo de ensayos (ensayos de caracterización de la reacción mediante análisis termogravimétrico, análisis diferencial de barrido de energías), además de la descripción de las reacciones de combustión.
En el primero de los casos, se utiliza un modelado global representante de todas las reacciones que en el material tienen lugar, en el segundo, y en función de lo amplios que resulten los resultados disponibles, se podrán caracterizar ciertos comportamientos (no todas las reacciones que tienen lugar) como la acción de un retardante de llama en un cable, por ejemplo [8].
Cuando se refiere a la consideración del estudio de la reacción del material como una única reacción, se obtienen parámetros promedio que en el modelo computacional representarán de forma aproximada al elemento. En este caso, para la descomposición térmica se asume la simplificación de tratarlo como una reacción global representada por:
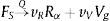
donde Fs es el fuel en estado sólido y Rα el residuo producido tras el proceso de descomposición que puede encontrarse en cualquier estado de agregación, α. Vg son los gases producidos en el proceso de pirólisis. Por supuesto, vR y vV serán los coeficientes estequiométricos del residuo y el volátil. Este es un punto de vista puramente funcional, pero con unas predicciones razonablemente buenas [9].
2.2Modelo de fase sólida de FDSEl modelo realiza las siguientes aproximaciones de partida:
- •
Liberación instantánea de volátiles del sólido a la fase gaseosa.
- •
Equilibrio térmico local entre los sólidos y los volátiles.
- •
No condensación de los productos gaseosos.
- •
Efectos de no porosidad.
De este modo la ecuación de conservación de energía dentro del sólido puede escribirse como:
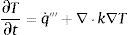
donde q˙′′′ es el flujo de calor por unidad de volumen (kW/m3) y es suma de una componente radiativa, q˙rad′′′, que aquí consideraremos despreciable (mediante la utilización del coeficiente de absorción que caracteriza la absorción de radiación exclusivamente en la superficie del material) y de una química, q˙quim′′′, que tiene que ver con los procesos de pirólisis (la que caracterizaremos en nuestra simulación):
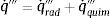
Cada componente del material puede experimentar varias reacciones, y cada una de estas reacciones puede producir algún otro componente sólido (residuos), combustible gaseoso y/o vapor de agua de acuerdo con los coeficientes estequiométricos basados en la masa, vs, vf y vw, respectivamente, que por definición deben cumplir:
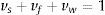
Considerando el componente α del material que se somete a Nr,α reacciones y utilizando el índice β para representar una de estas reacciones:
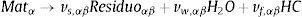
La densidad local del componente α del material evoluciona en el tiempo en función de la ecuación de conservación de especies de la fase sólida:
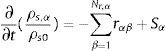
donde la masa de la componente α es consumida por las reacciones de la fase sólida rαβ y producida por otras reacciones. rαβ es la velocidad de reacción (s−1), ρs0 es la densidad inicial de la capa del material y Sα es la velocidad de producción del componente α del material como consecuencia de las reacciones de los demás componentes. Las velocidades de reacción son funciones locales de la concentración de masa y temperatura, y son obtenidas mediante:
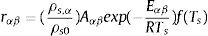
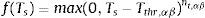
Tthr,αβ es la temperatura umbral que puede ser usada para dictar que la reacción no debe producirse por debajo de una temperatura especificada por el usuario (por defecto, 0 K). Por otro lado, el término de la velocidad de producción Sα se define como la suma de todas las reacciones donde el residuo sólido es un material α. TS y R son la temperatura de la superficie y la constante de los gases ideales respectivamente.
La velocidad de producción por unidad de volumen de gases combustibles y vapor de agua viene dada por las ecuaciones:
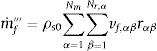
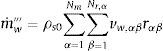
El modelo asume tanto los gases combustibles como el vapor de agua que son trasladados instantáneamente a la superficie, donde proporcionan un flujo másico de:
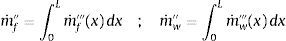
siendo L el espesor de la superficie. Teniendo en cuenta todo esto, el término químico de la ecuación de conducción constará del calor de reacción y las diferencias en el calor latente entre el material original y los productos:
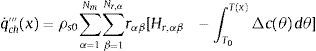
donde los términos Hr,αβ son las entalpías a presión constante de las reacciones caracterizadas y Δc(θ) es el calor específico del material en función de la temperatura.
2.3Descripción del algoritmo evolutivoSe creó un módulo que incorporado al programa FDS permite optimizar los parámetros de caracterización del modelado del elemento de estudio. En la figura 1 se puede observar un diagrama de flujo del procedimiento de optimización de parámetros.

En lo referente al modelo evolutivo propiamente dicho, se puede dividir el procesamiento en 2 fases claramente diferenciadas: una fase previa, que solo se aplica una vez antes del comienzo del proceso de optimización, y una fase de procesado, de carácter iterativo.
2.3.1Fase previaEn esta fase se definen tanto los rangos de variación de los parámetros de definición del modelo físico como los parámetros de caracterización del propio algoritmo. El primer tipo de parámetros se define en función de criterios de coherencia física, mientras que el segundo se define en función de la propia experiencia computacional, utilizando como guía el criterio de convergencia del algoritmo.
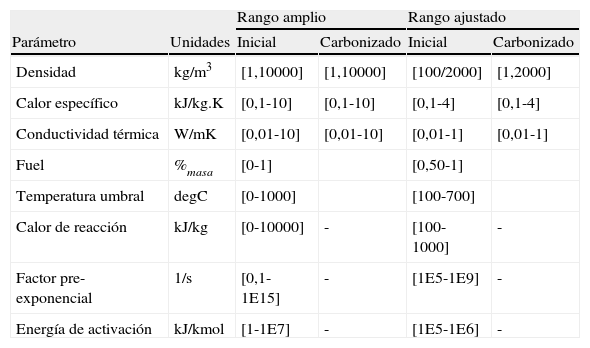
En la tabla 1 observamos los rangos de datos iniciales a partir de los cuales se genera la población de datos de partida o la población inicial de individuos a partir de la que se lanza la fase de optimización, para los 2 materiales.
Parámetros variables del estudio para los rangos amplio y ajustado
| Rango amplio | Rango ajustado | ||||
| Parámetro | Unidades | Inicial | Carbonizado | Inicial | Carbonizado |
| Densidad | kg/m3 | [1,10000] | [1,10000] | [100/2000] | [1,2000] |
| Calor específico | kJ/kg.K | [0,1-10] | [0,1-10] | [0,1-4] | [0,1-4] |
| Conductividad térmica | W/mK | [0,01-10] | [0,01-10] | [0,01-1] | [0,01-1] |
| Fuel | %masa | [0-1] | [0,50-1] | ||
| Temperatura umbral | degC | [0-1000] | [100-700] | ||
| Calor de reacción | kJ/kg | [0-10000] | - | [100-1000] | - |
| Factor pre-exponencial | 1/s | [0,1-1E15] | - | [1E5-1E9] | - |
| Energía de activación | kJ/kmol | [1-1E7] | - | [1E5-1E6] | - |
Finalmente, se obtiene la población inicial generada de forma aleatoria a partir de los rangos de valores de la tabla 1. Se supone un individuo de la población total compuesto por un número de genes previamente seleccionado (los genes son las propiedades del material cuya variación se quiere optimizar).
Para el gen i del individuo j se tendrá el valor P(i, j). A partir de aquí se hace uso del rango de valores inicialmente definido [Pmin(i), Pmax(i)] y se obtienen los valores iniciales de la población a partir de la siguiente expresión:
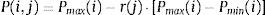
Donde r(j) es un valor del intervalo [0,1] que introduce la aleatoriedad a la que se hizo mención con anterioridad, es decir, se obtiene un valor arbitrario P(i, j) dentro del intervalo [Pmin(i), Pmax(i)].
2.3.2Fase iterativa de procesadoSe utilizan equivalencias genéticas mediante la implementación de distintos módulos que realizan labores de evaluación de resultados, selección de nuevos individuos, sostenimiento de las condiciones de diversidad de estos, etc.
Módulo de comparación, fitness
Se produce un análisis punto por punto entre los resultados proporcionados por la simulación y los parámetros disponibles seleccionados en el análisis previo para la comparación (MLR, HRR, TGA, etc.). En este módulo se asignan probabilidades de selección (en adelante llamados pesos estadísticos) a los individuos que son inversamente proporcionales al error obtenido para el individuo:
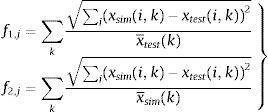
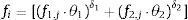
donde f1,j es el error cuadrático relativo respecto del valor real obtenido para un criterio de comparación seleccionado (MLRexp 40kW/m2, MLRexp 50kW/m2), y f2,j es el error cuadrático relativo respecto del valor que se obtuvo en la simulación para el mismo criterio. El xsim(i, k) es el valor obtenido utilizando el criterio de selección k que resulta de la simulación (por ejemplo HRRsim 25kW/m2) de cada punto para el individuo j. θ1, δ1, θ2, δ2, son parámetros de control del propio proceso, y se utilizan para pesar las contribuciones de los valores reales y simulados. Por supuesto, fj es el error asignado al individuo j.
A partir de los valores fj alcanzados se asigna a cada individuo el peso wj en el proceso de selección de nueva población para el siguiente paso del proceso iterativo:
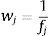
Y dado que para la selección se necesita una densidad de probabilidad, el valor normalizado de la misma, pj:
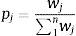
siendo n el número total de individuos de la generación, denominado genoma.
Modulo de selección, selección natural
A partir de las probabilidades de selección del individuo padre, se hace una selección de padres. Esta fase del proceso se divide en varias partes, pues aunque se hayan seleccionado los padres, es necesario combinarlos para producir el nuevo individuo hijo. De cada 2 individuos padre se obtendrán 2 individuos hijo. Es necesario, para que el algoritmo pueda encontrar mínimos más cercanos al valor criterio (HRRexp 25kW/m2, por ejemplo), que haya cierta variabilidad en los genes de los individuos, pues de lo contrario el proceso derivaría en una endogamia que haría imposible progresar el resultado final. Esto se hizo con la implementación de 3 fases:
- I.
Mezcla. Con 2 padres seleccionados j y j+1 cuyo gen i tiene por valor P(i, j) y P(i, j+1) respectivamente y N(i, j) y N(i, j+1), los valores que el gen i tendrá en los hijos j y j+1 serán:
Se hizo un mezclado de tipo aritmético con parámetro de mezcla r que es un valor aleatorio en [0,1]. Para el estudio de variabilidad también fue implementada una función de mezcla con operador de tipo geométrico:
- II.
Mutación. Con el objetivo de permitir una variabilidad se construyó este módulo que hace una mezcla diferente de la habitual utilizando para ello un parámetro del algoritmo denominado pmut el cual controla con qué porcentaje tendrá lugar ese tipo de mezcla.
El tipo de mezcla puede ser de 2 subtipos: libre y heredada. La primera consiste básicamente en generar un valor para el gen de la misma forma en la que se obtuvo la población inicial en la fase previa. La segunda se basa en una mezcla heurística que produce un valor alrededor (hasta un 10%) de un intervalo alrededor del gen padre:
donde en este caso s(j) y g(j) están definidas de forma aleatoria en el intervalo (−0.5e, 0.5e), siendo e un parámetro del algoritmo que establece el porcentaje de variación que se quiere estudiar.
Para seleccionar entre uno y otro tipo de mezcla de mutación, el algoritmo se sirve de otro parámetro de definición que básicamente es la probabilidad con la que se seleccionará uno u otro.
- III.
Elitismo. El último módulo del proceso de selección tiene como objetivo asegurarse que un determinado porcentaje (12,5%) de los mejores individuos pase como tal a la siguiente generación. Este criterio se implementa para mejorar la rapidez de la convergencia del algoritmo, aunque se hace necesario utilizarlo de forma adecuada [4], puesto que en exceso podría generar problemas de baja variabilidad y en defecto, el recorte de tiempo obtenido en la convergencia sería menor que el utilizado para su propio trabajo (son procesos puramente I/O).
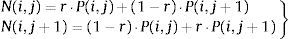
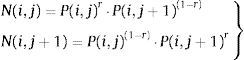
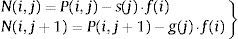
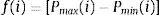
Este proceso se conecta a una nueva simulación hasta alcanzar el número de generaciones inicialmente requeridas (no hay un criterio de parada por convergencia, es el usuario el que indica el número de generaciones que se quiere explorar), lo que dará por finalizado el proceso iterativo y la obtención de los parámetros óptimos para la simulación del material en el modelo.
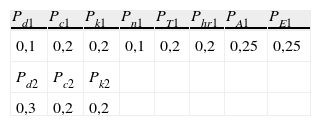
2.3.3Definición del proceso de optimización e importancia del ajuste del rango de partida.El proceso comienza con la generación de una población inicial de 4.096 individuos con 11 genes cada uno. Para la función de selección utilizamos los siguientes parámetros:
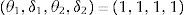
El proceso utiliza como elemento de optimización las curvas de MLR a flujos de 25, 50, 60 y 75kW/m2. Dado que no hubo ignición para el flujo más bajo, el término x¯test(k)=0 para ese flujo, de modo que no se podía utilizar el flujo de 25kW/m2. Para utilizarlo como criterio se utiliza un θ2≠0 que permite un filtrado de la influencia del error en un solo flujo; dado que el valor de la simulación es pequeño pero distinto de 0, se consigue de este modo utilizar el criterio de 25kW/m2.
Los parámetros del modelo utilizado fueron una probabilidad general de mutación durante el proceso de mezcla de 0,2 y una proporción de individuos elitistas de 1/8. Las probabilidades por gen fueron las que se muestran en la tabla 2.
Las generaciones derivadas estaban compuestas por 256 individuos cada una de forma sucesiva. los valores de fitness se establecieron como criterio para definir la precisión de las generaciones iniciales, y se obtuvo que para valores considerados adecuados hubo una proporción de 1/16 de resultados buenos (fitness >0,15) para el rango ajustado. Este valor para el rango no ajustado es muy inferior, y con generaciones de menos de 128 individuos se observa endogamia, esto es, se necesitarían simulaciones iniciales muy grandes (>20.000 individuos) para ese rango. Para las optimizaciones se obtuvieron 200 generaciones.
El efecto del rango de partida se manifiesta en el gráfico de la figura 2, donde se representa el valor del fitness de las 2 poblaciones de 4.096 individuos con rangos distintos ante el mismo criterio de comparación mostrado en la ecuación (10), uno utilizando el rango amplio, y el otro el ajustado a la física del problema.

Para hacerse una idea de la diferencia entre poblaciones para el material en cuestión, las medias son 0,094 y 0,067, las desviaciones estándar son 0,052 y 0,021 y el porcentaje de valores por encima del valor de fitness (0,1) es en el primer caso del 14,82% frente al 5,76% para el segundo caso.
3Resultados3.1Resultados para el proceso en un solo pasoLa discusión de resultados se hizo a partir de los ensayos de un material (un panel honeycomb utilizado en la construcción de aviones) que presenta una sola reacción y del que se disponía su curva de pérdida de masa (MLR) a flujos de 25, 50, 60 y 75 kW/m2 como criterio de optimización. Los resultados de un proceso de optimización basado en el criterio de los 4 flujos son los que se denominan línea base. A partir del resultado de la simulación con FDS 5.4.3 a un flujo de 50kW/m2 se planteó una optimización de 200 generaciones (para el caso del rango ajustado véase la figura 3).

El resultado obtenido (figura 3) se aproxima mucho al valor problema después de 200 generaciones (rango ajustado 0,24%, rango amplio 5,16%).
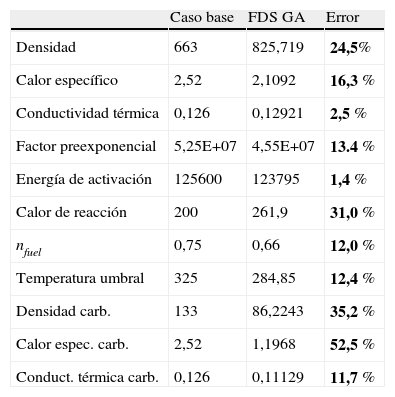
En este caso, dado que el esquema de reacción del material y el computacional coinciden (un solo paso), los resultados (tabla 3) muestran un error relativamente pequeño para los 2 rangos. Que el valor del error sea más pequeño en el caso del rango ajustado indica que este procedimiento es más rápido en el ajuste.
Comparación de los parámetros reales-obtenidos con rango ajustado
| Caso base | FDS GA | Error | |
| Densidad | 663 | 825,719 | 24,5% |
| Calor específico | 2,52 | 2,1092 | 16,3 % |
| Conductividad térmica | 0,126 | 0,12921 | 2,5 % |
| Factor preexponencial | 5,25E+07 | 4,55E+07 | 13.4 % |
| Energía de activación | 125600 | 123795 | 1,4 % |
| Calor de reacción | 200 | 261,9 | 31,0 % |
| nfuel | 0,75 | 0,66 | 12,0 % |
| Temperatura umbral | 325 | 284,85 | 12,4 % |
| Densidad carb. | 133 | 86,2243 | 35,2 % |
| Calor espec. carb. | 2,52 | 1,1968 | 52,5 % |
| Conduct. térmica carb. | 0,126 | 0,11129 | 11,7 % |
Respecto a la comparación de los valores obtenidos para los parámetros en el caso del rango ajustado, se muestran diferencias claras que indican que la representación de la fase sólida tal y como lo hacen los modelos matemáticos definidos en el modelo FDS es ambigua y, por lo tanto, se pueden utilizar diferentes sets de parámetros con respuestas similares.
3.2Resultados para el proceso de 2 pasosDel mismo modo que se describió la reacción de un solo paso, se hizo una discusión para un material con esquema de 3 reacciones [5] (celulosa). La optimización se hizo suponiendo una única reacción computacional para el modelado, reacción (R1). El único dato disponible fue una curva de pérdida de masa para 50 kW/m2 obtenida en ensayos de cono calorimétrico (caso base) que fue la utilizada como elemento de selección (criterio de comparación - fitness). En la figura 4 se muestran los resultados obtenidos para los 2 rangos de parámetros inicialmente definidos en la tabla 1.

Los resultados muestran la aparición de un segundo pico en la curva de pérdida de masa que resulta difícil de modelar con una sola reacción. Se utilizaron los 2 rangos iniciales de variación. Los resultados presentaron un error del 14,4% frente a un 14,1% en el rango amplio.
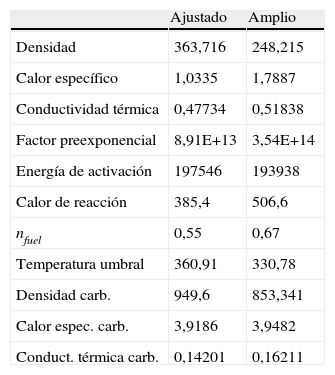
Cabe destacar que para el caso en el que se realiza una optimización con un esquema de reacción computacional diferente del propio material, el error aumenta en torno al 14 % para las mismas 200 generaciones. En este caso, sin embargo, no se observa diferencia en el error entre los rangos, lo que se debe a la dificultad del modelo para la representación de ese comportamiento. En la tabla 4 se pueden observar 2 sets de parámetros que dan lugar a una respuesta similar.
Parámetros obtenidos rango ajustado-rango amplio
| Ajustado | Amplio | |
| Densidad | 363,716 | 248,215 |
| Calor específico | 1,0335 | 1,7887 |
| Conductividad térmica | 0,47734 | 0,51838 |
| Factor preexponencial | 8,91E+13 | 3,54E+14 |
| Energía de activación | 197546 | 193938 |
| Calor de reacción | 385,4 | 506,6 |
| nfuel | 0,55 | 0,67 |
| Temperatura umbral | 360,91 | 330,78 |
| Densidad carb. | 949,6 | 853,341 |
| Calor espec. carb. | 3,9186 | 3,9482 |
| Conduct. térmica carb. | 0,14201 | 0,16211 |
Estos resultados confirman los resultados de análisis previos y demuestran que, usando esta clase de herramientas de optimización, existen diversos conjuntos de parámetros adecuados [10] y que los genes del mejor individuo tienen propiedades físicas que no siempre corresponden a propiedades reales debido a los errores inherentes al modelo utilizado.
3.3Variabilidad de los parámetros a lo largo de la optimizaciónPara ello se estudiaron las poblaciones del rango ajustado a lo largo de la simulación de 200 generaciones, desde el valor inicial en adelante. La figura 5 muestra el resumen de este estudio para 2 tipos de operadores de mezcla, uno geométrico [ecuación (20)] que está representado por las 4 primeras barras del gráfico siguiente (orden decreciente 200, 100, 25, 2-punteado) y uno aritmético (orden creciente 2-negro, 25, 100, 200).

En este gráfico se muestra la variación cuadrática media porcentual de cada población de 256 individuos a medida que se produce el proceso. En general la variabilidad de la segunda generación es parecida pues provienen de la misma generación inicial. Puede verse que en el caso de la conductividad del material virgen (conductividad 1) el factor inicial está por encima del 100% y se estabiliza en la generación 25 por debajo del 20%. Para la conductividad del carbonizado (conductividad 2) también tenemos una intensa variación inicial, sin embargo no se produce esa estabilización.
Pueden observarse valores cortados de frecuencia (factor pre exponencial) para todas las generaciones, lo que indica que estos tienen variabilidad garantizada, debido claramente a la amplitud del rango seleccionado. Otros parámetros como los valores de los parámetros del carbonizado también muestran gran variabilidad. El resto de valores del material virgen, sin embargo, muestran en general una tendencia a la homogeneidad que es sinónimo de «endogamia», con el sentido que le damos en este análisis. El calor específico, sin embargo, muestra un comportamiento diferenciado entre la mezcla geométrica y la aritmética. El resto de parámetros no mostraron esta diferencia.
4ConclusionesLos procesos con muchos grados de libertad encuentran en los algoritmos evolutivos herramientas para conseguir respuestas computacionales próximas a un ensayo de referencia. El proceso de acotación del rango, sin embargo, es fundamental a la hora de dotar de contenido físico a los parámetros, y también a la hora de acelerar el proceso de ajuste, por lo que el trabajo previo (preferiblemente basado en ensayos en laboratorio) es deseable a la hora de acotar los rangos.
Por otro lado, la variabilidad de los parámetros a lo largo del proceso debe incorporarse al proceso de redefinición del ensayo, con el sentido de poder conservar una variabilidad alta en determinados genes que permita al algoritmo encontrar el mínimo absoluto entre todos los mínimos posibles (conjuntos de parámetros óptimos). No se encontraron diferencias significativas entre los 2 tipos de procesos de mezcla (aritmético y geométrico) que justifiquen la implementación de uno de ellos por encima del otro.
Si la variabilidad del proceso no es suficientemente alta las poblaciones van cayendo en valores «endogámicos», impidiendo encontrar alternativas y con ello mejores resultados. La razón de este efecto tiene que ver con la importancia de ciertos parámetros para el modelo al representar el criterio seleccionado como elemento de comparación (en este caso MLR), por lo que el uso de otros valores de comparación (temperaturas, energías, otros flujos) mejoraría la representación del material, y la variabilidad.
Los autores queremos agradecer al Ministerio de Ciencia e Innovación (Gobierno de España) por la subvención TRA2010-19006 otorgada por el proyecto «Modelado Matemático de la Combustión de los Materiales Presentes en los Trenes de Pasajeros de Alta Velocidad».