





La Hipercolesterolemia Familiar (HF) es una enfermedad autósómica dominante con una prevalencia estimada entre 1/200-250. Se encuentra infra-tratada e infra-diagnosticada. El rastreo masivo de datos puede incrementar la detección de pacientes con HF.
MétodosPoblación a estudio: Residentes en la zona sanitaria de cobertura (N: 195.000 habitantes) y con al menos una determinación de colesterol ligado a lipoproteínas de baja densidad (C-LDL) realizada entre el 1 de Enero de 2010 y el 30 de Diciembre de 2019. Se seleccionaron los valores más altos de C-LDL. Criterios de exclusión: síndrome nefrótico, hipotiroidismo, tratamiento hipotiroideo o triglicéridos > 400 mg/dL. Se analizaron 7 algoritmos sugestivos de fenotipo de Hipercolesterolemia Familiar (F-HF).Se seleccionó el algoritmo más eficaz y de fácil traslación a la práctica clínica
ResultadosPartiendo de 6.264.877 asistencias y 288.475 pacientes tras aplicar los criterios de inclusión-exclusión se incluyeron 504.316 analíticas correspondiendo a 106.382 adultos y 10.509 < 18 años. El algoritmo seleccionado presentó una prevalencia de 0.62%.Se detectaron 840 pacientes con fenotipo de Hipercolestereolemia Familiar (F-HF) siendo el 55.8% mujeres y 178 <18 años, El 9.3% tenían antecedentes de enfermedad cardio-vascular (ECV) y 16.4% habían fallecido. El 65% de los pacientes en prevención primaria presentaron valores de C-LDL >130 mg/dL y el 83% en prevención secundaria valores >70mg/dL. Se obtuvo una ratio de 7.64 (1-18) pacientes con HF-P por médico solicitante de analítica
ConclusionesEl rastreo masivo de datos y el perfilado de pacientes son herramientas eficaces y fácilmente aplicables en práctica clínica para la detección de pacientes con HF.
Familial Hypercholesterolemia (FH) is an autosomal dominant disease with an estimated prevalence between 1/200-250. It is under-treated and underdiagnosed. Massive data screening can increase the detection of patients with FH.
MethodsStudy population: Residents in the health coverage area (N: 195.000 inhabitants) and with at least one determination of cholesterol linked to low-density lipoproteins (LDL-C) carried out between January 1, 2010 and December 30, 2019. The highest LDL-C values were selected. Exclusion criteria: nephrotic syndrome, hypothyroidism, Hypothyroid treatment or triglycerides> 400 mg / dL. Seven algorithms suggestive of Familial Hypercholesterolemia Phenotype (HF-P) were analyzed, selecting the most efficient algorithm that could easily be translated into clinical practice.
ResultsBased on 6.264.877 assistances and 288.475 patients, after applying the inclusion-exclusion criteria, 504.316 tests were included, corresponding to 106.382 adults and 10.509 <18 years. The selected algorithm presented a prevalence of 0.62%. 840 patients with HF-P were detected, 55.8% being women and 178 <18 years old, 9.3% had a history of cardiovascular disease (CVD) and 16.4% had died. 65% of the patients in primary prevention had LDL-C values> 130 mg / dL and 83% in secondary prevention values> 70mg / dL. A ratio of 7.64 (1-18) patients with HF-P per analytical requesting physician was obtained.
ConclusionsMassive data screening and patient profiling are effective tools and easily applicable in clinical practice for the detection of patients with FH.
La hipercolesterolemia familiar (HF) es la enfermedad autósómica dominante asociada con enfermedad cardiovascular (ECV) más frecuente1. Su prevalencia estimada es de 1/313 (1/250-1/397)1, por lo que en el mundo existirían unos 34 millones de pacientes. En España, la prevalencia se sitúa en torno a 1/282 para HF genéticamente definida2 y 1/192 para el fenotipo clínico de HF3 (F-HF), por lo que en nuestro medio existirían entre 166.000 y 244.000 pacientes con HF, de los cuales solo estarían diagnosticados entre el 12 y el 15%. En pacientes con HF sin tratamiento hipolipemiante (TH), el 50% de los hombres antes de los 50 años y el 30% de las mujeres antes de los 60 años presentarán enfermedad coronaria (EC)4. Se calcula que 1/31 pacientes con EC y 1/15 en pacientes con EC precoz están afectos de HF5. Los pacientes con HF respecto a la población general no solo presentan una ECV más precoz, sino que también una EC más difusa, con mayor prevalencia de infarto con elevación de ST, mayor afectación polivascular6 y con el doble de recurrencia de SCA en el primer año del evento y peor pronóstico7.Un estudio del registro de dislipemias de la Sociedad Española de Arteriosclerosis ha puesto de manifiesto que un inicio precoz de TH y una duración de al menos cinco años reduce considerablemente el riesgo de ECV en pacientes con HF8.Se estima que por cada 1.000 pacientes tratados entre 35 y 85 años con HF se evitarían 101 eventos cardiovasculares, que si extrapolamos a la población europea supondría evitar unos 210.000 eventos cardiovasculares9. El registro SAFEHEART ha mostrado que solo el 3,4% de los pacientes alcanzan el objetivo de C-LDL < 100 mg/dL10. En nuestro medio, solo un 3% de los pacientes con F-HF que no alcanza los objetivos terapéuticos, a pesar de estar con TH óptimo, reciben tratamiento con inhibidores de proproteína convertasa subtilisina/kexina tipo 9 (iPCSK9)11.
Recientemente la Federación Mundial del Corazón ha destacado que la HF es un problema prioritario de salud pública, y que precisa de una acción a nivel mundial12. La capacidad actual de realizar rastreo masivo de datos en los registros clínicos electrónicos (EHR) puede ser una excelente oportunidad para incrementar la detección de pacientes con HF.
Material y métodosEstudio descriptivo mediante análisis masivo de EHR comparando diversos algoritmos de detección de pacientes con F-HF.
Objetivo del estudio: Evaluar la eficacia diagnóstica de distintos algoritmos para la detección de F-HF mediante rastreo de EHR13–19 (tabla 1). Describir las características clínicas de los pacientes detectados por un algoritmo que sea eficaz, de fácil traslación a la práctica clínica y que se aproxime a la prevalencia de F-HF descrita en la reciente revisión sistemática de Hu et al. 0,31 (intervalo de confianza [IC] 95% 0,20-0,44) en adultos20 y de 0,46% (IC 95%: 0,41-0,52) en menores de 18 años3.
Algoritmos de búsqueda definidos para detectar pacientes con fenotipo FH
| Algoritmo 1 | Sí ([C-LDL > 140 y edad < 18] o [C-LDL > 190 y tratHipolip = No] o [C-LDL > 160 y tratHipolip = Sí y edad ≥ 18]) | Dislipemia severa de probable origen genético13 |
| Algoritmo 2 | Sí ([C-LDL > 160 y edad < 18] o [C-LDL > 240 y tratHipolip = No] o [C-LDL > 160 y tratHipolip = Sí y edad ≥18]) | Aproximación a los criterios definidos por SEA-Proyecto ARIAN para detección automatizada de HF14 |
| Algoritmo 3 | ([C-LDL ≥ 150 y edad < 18] o [C-LDL ≥ 230 y edad ≥ 18 y edad < 30] o [C-LDL ≥ 238 y edad ≥ 30]) | Aproximación a los puntos de corte en adultos sugestivos de HF genéticamente definida en población española15 |
| Algoritmo 4 | Sí ([C-LDL > 190 y edad < 18] o [C-LDL > 225 y tratHipolip = No y edad > 18 años y edad < 40] o [C-LDL > 260 y tratHipolip = No y edad ≥ 40]) | Puntos de corte más coste-efectivos para diagnóstico genético propuestos en población polaca16 |
| Algoritmo 5 | Sí ([C-LDL > 120 y edad < 50 y tratEzetimiba = Sí y tratEstatinas = Sí] o [C-LDL > 120 y edad < 60 y tratEzetimiba = Sí y tratEstatinas = Sí y ECV = Sí] o [C-LDL > 130 y edad ≥ 50 y tratEzetimiba = Sí y tratEstatinas = Sí]) | Criterios diagnósticos utilizados en el proyecto HF-Find, a través de machine-learning17 |
| Algoritmo 6 | ([edad < 18 y C-LDL ≥ 190] o [edad ≥ 18 y C-LDL > 328]) | Definición simplificada de HF de la Sociedad Canadiense18 |
| Algoritmo 7 | (edad ≥ 18 y LDL > 359) | Puntos de corte definido más sensible para HF genéticamente positivo19 |
C-LDL: colesterol ligado a lipoproteínas de baja densidad; tratHipolip: tratamiento hipolipemiante; tratEstatinas: tratamiento estatinas; tratEzetimiba: tratamiento ezetimiba; ECV: enfermedad cardiovascular, HF: hipercolestereolemia familiar.
Criterios de inclusión: Residentes en la zona sanitaria de cobertura, con una población censada de 195.000 habitantes, de los que se disponía de al menos una determinación analítica del colesterol ligado a lipoproteínas de baja densidad (C-LDL), realizada en ámbito hospitalario, ambulatorio o sociosanitario) entre el 1 de enero de 2010 y el 30 de diciembre de 2019. Cuando se disponía de más de una analítica, se seleccionó el valor más alto de C-LDL. Los pacientes bajo TH se analizaron de forma cualitativa (bajo TH o sin TH), según los criterios de inclusión del algoritmo seleccionado. Criterios de exclusión: diagnóstico de síndrome nefrótico, hipotiroidismo, tratamiento con hormona tiroidea o triglicéridos (TG) > 400 mg/dL.
Los datos clínicos evaluados fueron: sexo, edad, colesterol total (CT), colesterol-HDL (C-HDL), TG, C-LDL, prescripción de TH, problemas de salud asociados al paciente registrados en atención primaria y diagnósticos de alta en hospitalizaciones, ingresos por ECV y éxitus de causa cardiovascular. Se realizó una validación interna de la calidad de los datos mediante el análisis de 25 historias clínicas seleccionadas de forma aleatoria.
Análisis estadísticoLos datos cuantitativos se presentan con la media y desviación estándar (DE). Las variables categóricas se expresan en porcentajes. Las diferencias entre grupos serán analizadas mediante la prueba t de Student para variables continuas con reducción estimada de los grados de libertad, en caso de no homogeneidad de las varianzas, y la prueba de χ2 para variables categóricas. También se presentan los intervalos de confianza al 95% de las proporciones y de las medias. Se considerará estadísticamente significativo un valor p < 0,05. El análisis estadístico se realizó mediante el paquete estadístico SAS Enterprise Guide v7.15 (SAS Institute Inc., Cary, NC, EE. UU.).
Consideraciones éticasEl análisis de datos se aplicó bajo la normativa vigente (Reglamento [UE] 2016/679 del Parlamento europeo y del Consejo Europeo del 27 de abril de 2016 sobre la Protección de Datos [RGPD])21. Se creó una base de datos seudonimizada con una metodología de trabajo que implicaba a dos equipos diferenciados, uno encargado del rastreo de datos y otro de elaborar el listado de pacientes por médico. La extracción y preparación de la matriz de datos la realizó un miembro del equipo experto en bioinformática que no participó en la preparación del proyecto, ni en el análisis detallado. El estudio obtuvo una calificación de bajo riesgo en la valoración de impacto de protección de datos. El protocolo del estudio fue aprobado por el Comité Ético de Investigación Clínica de referencia, incluyendo la aprobación de la exención del consentimiento informado para la fase de rastreo de pacientes con F-HF.
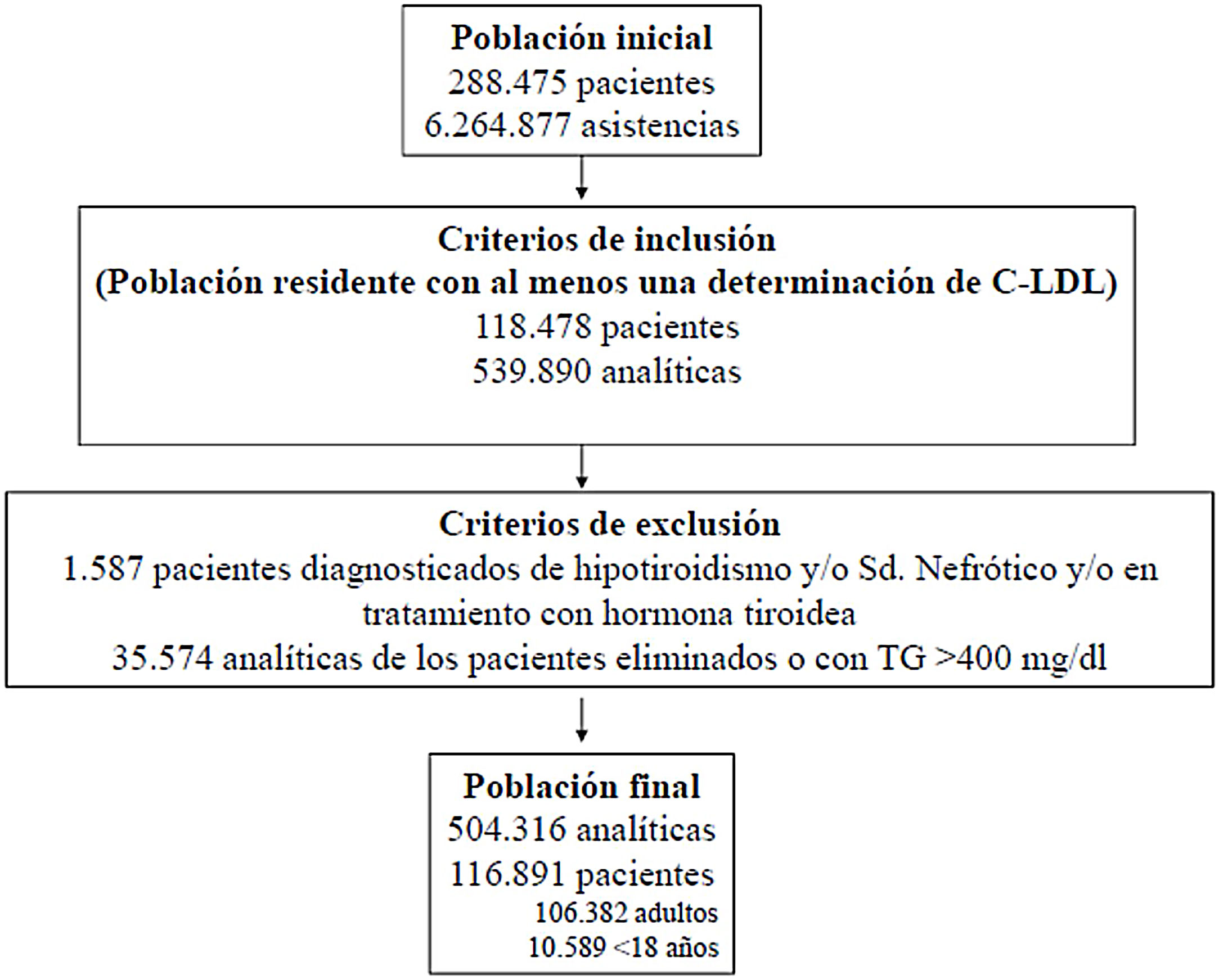
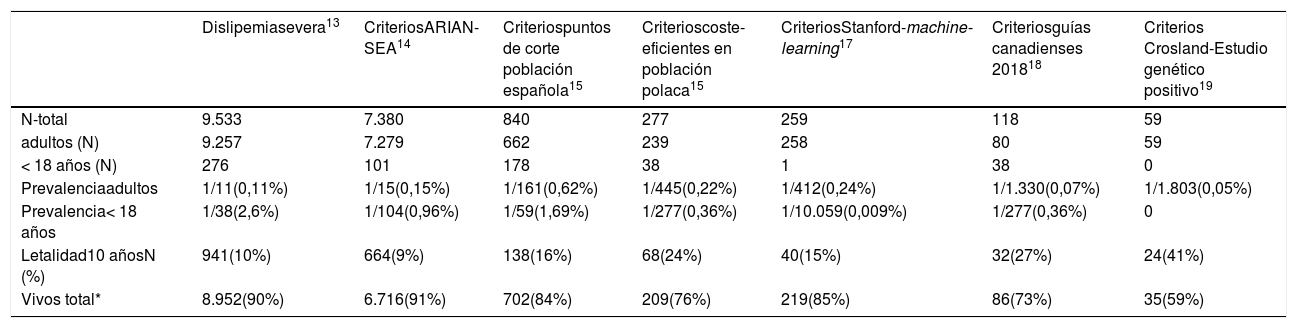
ResultadosSe valoraron 6.264.877 asistencias clínicas correspondientes a 288.475 pacientes, incluyendo residentes y población de temporal o de paso. Tras aplicar los criterios de inclusión-exclusión la muestra final incluida en el estudio fue de 504.316 análisis bioquímicos correspondientes a 116.891 pacientes, 106.382 adultos y 10.509 < 18 años (fig. 1). La prevalencia de F-HF y letalidad a los 10 años, en función de los diferentes algoritmos utilizados, se muestra en la tabla 2.

Prevalencia de F-HF y letalidad a 10 años con base en los diferentes algoritmos de búsqueda
| Dislipemiasevera13 | CriteriosARIAN-SEA14 | Criteriospuntos de corte población española15 | Criterioscoste-eficientes en población polaca15 | CriteriosStanford-machine-learning17 | Criteriosguías canadienses 201818 | Criterios Crosland-Estudio genético positivo19 | |
|---|---|---|---|---|---|---|---|
| N-total | 9.533 | 7.380 | 840 | 277 | 259 | 118 | 59 |
| adultos (N) | 9.257 | 7.279 | 662 | 239 | 258 | 80 | 59 |
| < 18 años (N) | 276 | 101 | 178 | 38 | 1 | 38 | 0 |
| Prevalenciaadultos | 1/11(0,11%) | 1/15(0,15%) | 1/161(0,62%) | 1/445(0,22%) | 1/412(0,24%) | 1/1.330(0,07%) | 1/1.803(0,05%) |
| Prevalencia< 18 años | 1/38(2,6%) | 1/104(0,96%) | 1/59(1,69%) | 1/277(0,36%) | 1/10.059(0,009%) | 1/277(0,36%) | 0 |
| Letalidad10 añosN (%) | 941(10%) | 664(9%) | 138(16%) | 68(24%) | 40(15%) | 32(27%) | 24(41%) |
| Vivos total* | 8.952(90%) | 6.716(91%) | 702(84%) | 209(76%) | 219(85%) | 86(73%) | 35(59%) |
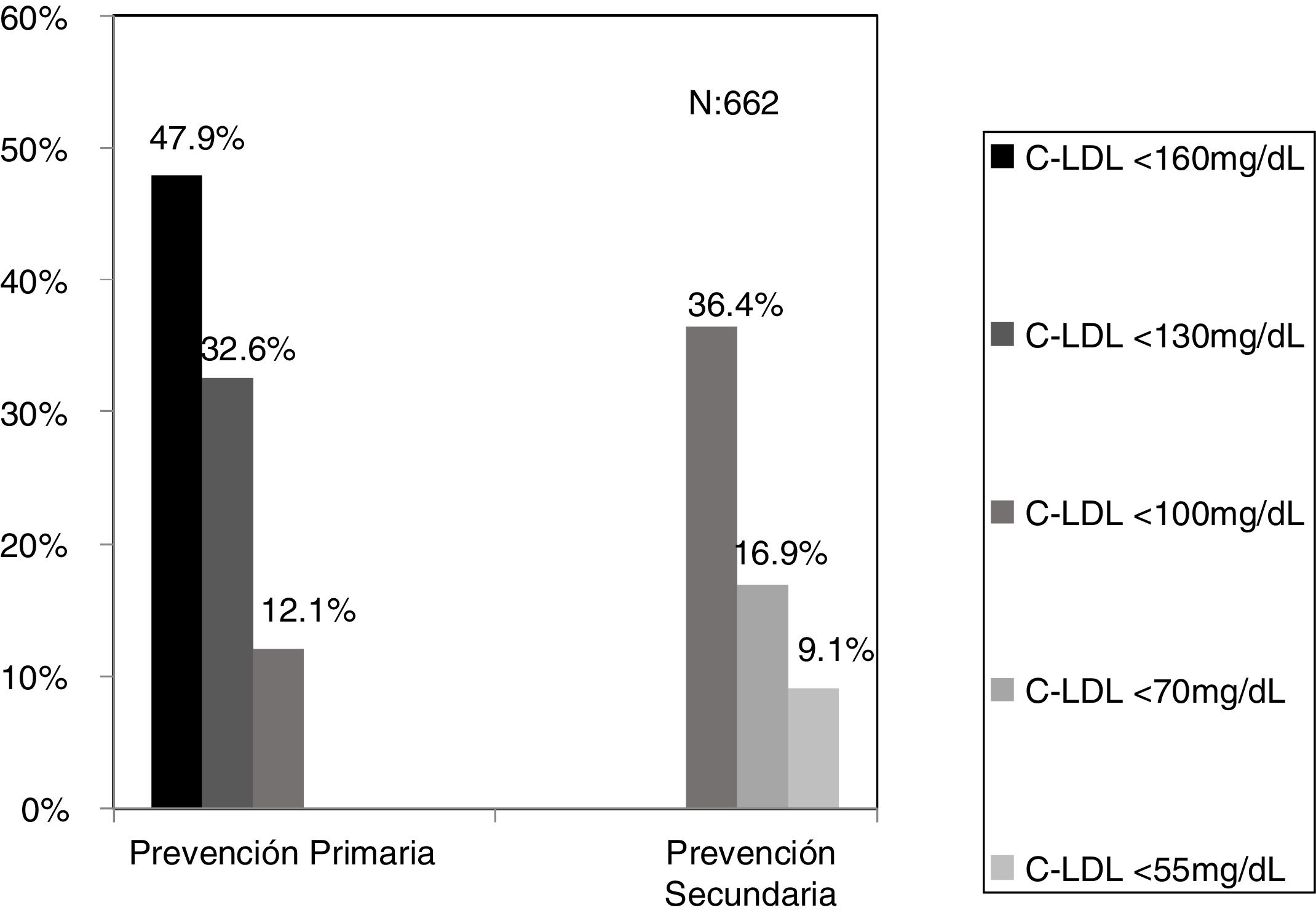
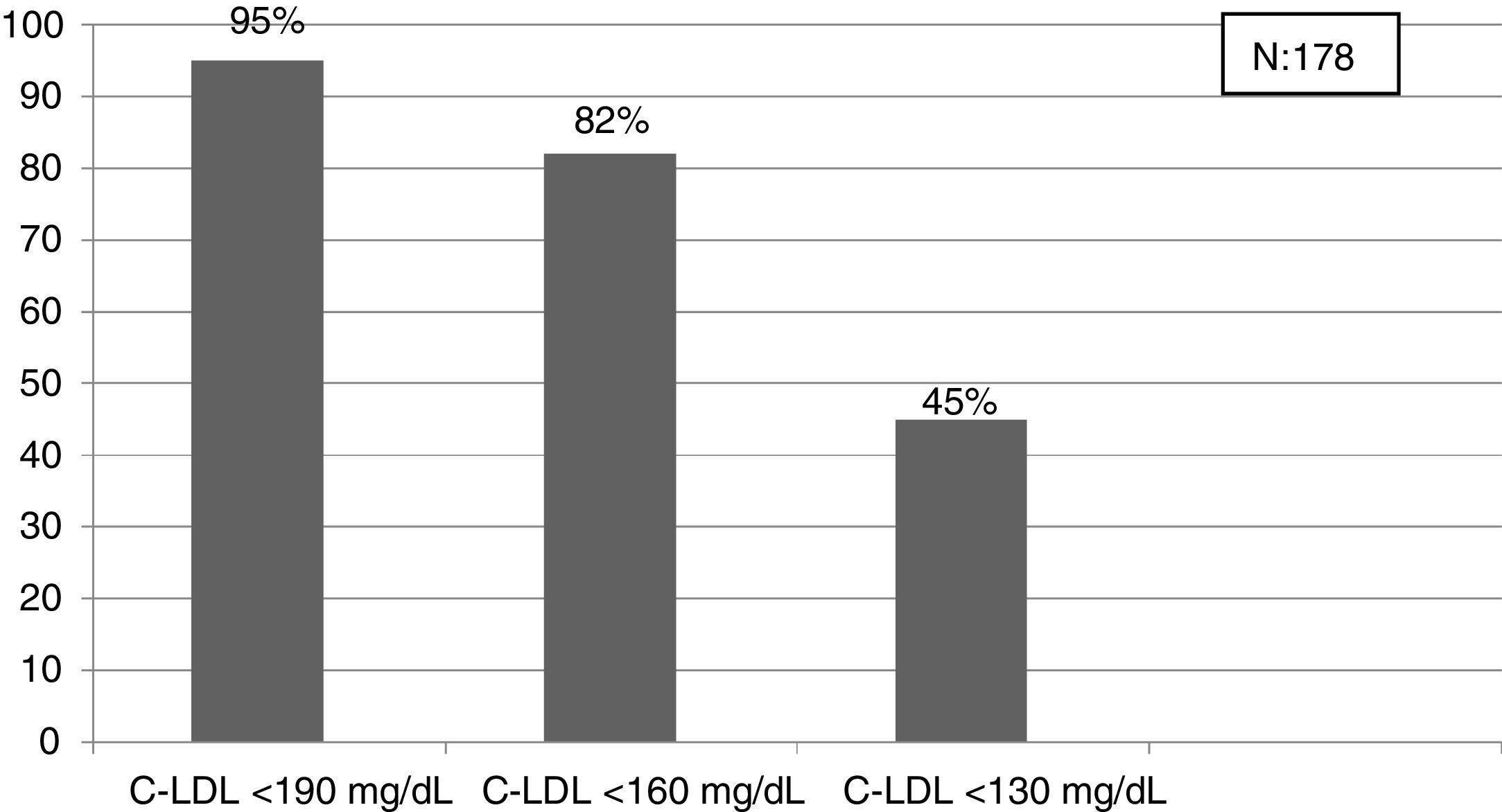
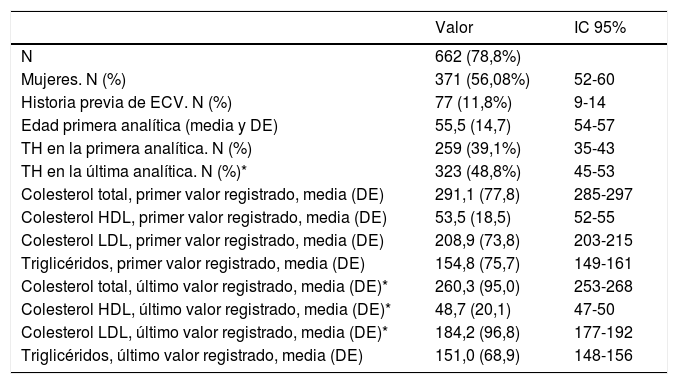
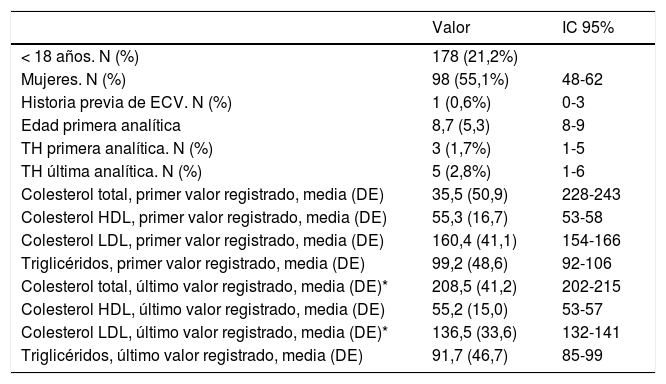
El algoritmo seleccionado fue el basado en los puntos de corte de C-LDL sugestivos de HF genéticamente en población española (LDL ≥ 150 y edad < 18 o LDL ≥ 230 y edad ≥ 18 < 30) o LDL ≥ 238 y edad ≥ 30)15. Este algoritmo detectó una prevalencia para F-HF de 0,61%. Según este criterio, se detectaron 840 pacientes con F-HF, de los cuales 178 eran menores de 18 años. El 55,8% eran mujeres y 78 (9,3%) tenían antecedentes de ECV (tabla 3). El 16,4% (n = 138) de la población fue éxitus durante el seguimiento de 10 años. Del total de pacientes con F-HF, 259 (39%) adultos se encontraban bajo TH y 38 pacientes < 18 años con C-LDL > 190 mg/dL, de los cuales, solo siete se encontraban en TH y solo uno recibía estatinas más ezetimiba. El número de analíticas realizadas por paciente fue 7,4 (1-43). La media de C-LDL en la analítica más cercana al 31 de diciembre del 2019 fue de 184,2 (96,8) y 136,5 (33,6) mg/dL para adultos y < 18 años, respectivamente. Se observó que la media de C-LDL desciende significativamente entre la primera y la última analítica registrada (tablas 3 y 4). El 65% de los pacientes en prevención primaria presentaron valores de C-LDL > 130 mg/dL y el 83% en prevención secundaria valores > 70 mg/dL (fig. 2). El 55% de los menores de 18 años presentaban valores < 130 mg/dL (fig. 3). Solo nueve pacientes tenían en alta clínica el diagnóstico codificado de HF (ICD-10:E78.01), disponible desde enero de 2018 en Cataluña. El número medio de pacientes con HF-P por médico solicitante de analítica fue de 7,64 (1-18). En el proceso de validación interna se obtuvo un 100% de concordancia.
Características de la población adulta seleccionada con base en los puntos de corte de C-LDL definidos en población española para HF genéticamente definida
| Valor | IC 95% | |
|---|---|---|
| N | 662 (78,8%) | |
| Mujeres. N (%) | 371 (56,08%) | 52-60 |
| Historia previa de ECV. N (%) | 77 (11,8%) | 9-14 |
| Edad primera analítica (media y DE) | 55,5 (14,7) | 54-57 |
| TH en la primera analítica. N (%) | 259 (39,1%) | 35-43 |
| TH en la última analítica. N (%)* | 323 (48,8%) | 45-53 |
| Colesterol total, primer valor registrado, media (DE) | 291,1 (77,8) | 285-297 |
| Colesterol HDL, primer valor registrado, media (DE) | 53,5 (18,5) | 52-55 |
| Colesterol LDL, primer valor registrado, media (DE) | 208,9 (73,8) | 203-215 |
| Triglicéridos, primer valor registrado, media (DE) | 154,8 (75,7) | 149-161 |
| Colesterol total, último valor registrado, media (DE)* | 260,3 (95,0) | 253-268 |
| Colesterol HDL, último valor registrado, media (DE)* | 48,7 (20,1) | 47-50 |
| Colesterol LDL, último valor registrado, media (DE)* | 184,2 (96,8) | 177-192 |
| Triglicéridos, último valor registrado, media (DE) | 151,0 (68,9) | 148-156 |
TH: tratamiento hipolipemiante; IC 95%: intervalo de confianza del 95% del valor de la media o la proporción correspondiente.
Características de la población < 18 años con C-LDL > 150 mg/dL española para HF genéticamente definida
| Valor | IC 95% | |
|---|---|---|
| < 18 años. N (%) | 178 (21,2%) | |
| Mujeres. N (%) | 98 (55,1%) | 48-62 |
| Historia previa de ECV. N (%) | 1 (0,6%) | 0-3 |
| Edad primera analítica | 8,7 (5,3) | 8-9 |
| TH primera analítica. N (%) | 3 (1,7%) | 1-5 |
| TH última analítica. N (%) | 5 (2,8%) | 1-6 |
| Colesterol total, primer valor registrado, media (DE) | 35,5 (50,9) | 228-243 |
| Colesterol HDL, primer valor registrado, media (DE) | 55,3 (16,7) | 53-58 |
| Colesterol LDL, primer valor registrado, media (DE) | 160,4 (41,1) | 154-166 |
| Triglicéridos, primer valor registrado, media (DE) | 99,2 (48,6) | 92-106 |
| Colesterol total, último valor registrado, media (DE)* | 208,5 (41,2) | 202-215 |
| Colesterol HDL, último valor registrado, media (DE) | 55,2 (15,0) | 53-57 |
| Colesterol LDL, último valor registrado, media (DE)* | 136,5 (33,6) | 132-141 |
| Triglicéridos, último valor registrado, media (DE) | 91,7 (46,7) | 85-99 |
TH: tratamiento hipolipemiante; IC 95%: intervalo de confianza del 95% del valor de la media o la proporción correspondiente.
 N: población; C-LDL: colesterol ligado a lipoproteínas de baja densidad; HF: hipercolesterolemia familiar.")

El presente trabajo muestra la eficacia y viabilidad del rastreo masivo y perfilado de registros clínicos en la detección de pacientes con fenotipo de F-HF, tanto en prevención primaria como secundaria.
Un algoritmo de cribado para pacientes con F-FH idealmente debe ser eficaz, efectivo, fiable, reproductible y coste-eficiente. Cuanto más se baje el punto de corte elegido se gana en sensibilidad, pero se pierde en especificidad y se aumenta considerablemente el número de pacientes candidatos a evaluar y el de recursos necesarios para garantizar la aplicabilidad de la intervención22. De los algoritmos analizados, el basado en los puntos de corte de C-LDL sugestivos en población española de HF genéticamente definida, es el más eficaz a la hora de plantear un cribado masivo15. Este algoritmo tiene una sensibilidad del 91% y valor predictivo positivo del 71% para HF genéticamente definida15.Un cribado en registros sanitarios con este algoritmo permitiría detectar en torno al 50% de la población con HF3. Se ha estimado que la detección mediante rastreo entre el 17 y 47% de los pacientes con HF seguida de una estrategia de estudio genético en cascada directa e inversa se podrán alcanzar cifras de detección en torno al 80%23, muy superiores al 12-16% actual24. No obstante, utilizar solo las cifras de C-LDL para la detección en cascada puede dejar sin diagnosticar hasta un 20-40% de los familiares con valores lipídicos normales, pero con mutación positiva2, por lo que es importante completarlo con una valoración clínica. Actualmente, la escala de Dutch Lipid Clinic Network Score (DLCNS) es la más utilizada en nuestro medio para seleccionar a pacientes candidatos a estudio genético, aquellos con DLCNS > 524, aunque esta escala puede ser de difícil aplicación y tiene muchos puntos de mejora25. La confirmación de HF mediante el estudio genético nos permitirá la detección entre dos y ocho familiares mediante la aplicación del cribado en cascada directa1.
En un estudio sobre 162.864 sujetos en población italiana con un punto de corte C-LDL > 190 mg/dL mostró una prevalencia de HF de 2,9% en población sin TH y de 3,5% en población tratada26, valores superiores a los detectados en el presente estudio. En nuestro caso, el número de pacientes con posible F-HF a analizar se multiplicaría por 11 al utilizar los criterios de hipercolesterolemia severa (C-LDL > 190 mg/dL). Hacer un cribado masivo de HF mediante el algoritmo seleccionado puede ser factible y asumible en la práctica clínica, en cuanto que los pacientes candidatos a reevaluar por cada médico son pocos, alrededor de siete pacientes de media. Si se aumentan los puntos de corte se gana valor predictivo positivo para el estudio genético, pero se detectan menos pacientes con HF de baja-moderada expresividad fenotípica, pero de elevado RCV. En nuestro caso, al utilizar el punto de corte de C-LDL > 359 mg/dL19 estaríamos detectando un subgrupo pequeño de pacientes con la más alta probabilidad de positividad en el estudio genético, lo que puede tener interés a la hora de detectar nuevas mutaciones genéticas. Se trata, por otro lado, de un subgrupo de pacientes de extremo riesgo, con una letalidad en 10 años superior al 40% en la presente serie. El criterio de Mickiewicz et al.16 en población polaca podía ser también un criterio efectivo a la vez que coste-eficiente. Son necesarios estudios en población española que evalúen el coste-efectividad de una estrategia combinada de rastreo y estudio genético en cascada.
Otra estrategia utilizada en el rastreo de pacientes con HF es la detección de patrones mediante técnicas de machine-learning como el proyecto FIND-HF, con un valor predictivo positivo del 88% para HF17. Este modelo es técnicamente más difícil en cuanto que exige el rastreo de datos no estructurados. En el presente estudio hemos rastreado pacientes con ECV precoz o en TH combinada, obteniéndose una prevalencia en el límite inferior del rango esperado, lo que indica la infrautilización de TH de alta intensidad. En nuestra serie, en la población seleccionada solo el 3% de los pacientes están tomando TH combinada. Destaca igualmente la escasa codificación, de diagnóstico HF en los diagnósticos de alta, situándose en el presente trabajo en torno al 1%, aunque probablemente esté enmascarado en el diagnóstico genérico de hipercolesterolemia.
Recientemente, el grupo de Civeira F. ha señalado que una estrategia útil en el cribado de pacientes con HF genéticamente definida sería la combinación de un C-LDL basal superior a 220 mg/dL y/o superior a 130 mg/dL en TH2, con una prevalencia en nuestra serie del 12,5%. Esta prevalencia tan elevada puede reflejar un peor control lipídico en la población del presente estudio.
El estudio FAMCAT, centrado en atención primaria y con 750.000 pacientes incluidos, ha mostrado la capacidad de detectar HF a través del rastreo masivo de EHR con un valor predictivo positivo del 88% y un valor predictivo negativo del 99%27. El problema para su aplicación es la falta de datos clínicos esenciales en los registros electrónicos. Un estudio centrado en altas hospitalarias de pacientes coronarios con presentación precoz detectó que solo en el 60% se señalaban los antecedentes familiares de EC precoz28. Se estima que el 20% de los pacientes < 50 años con infarto de miocardio e historia familiar de EC precoz presentarían HF, este porcentaje subiría al 60% si se asocia un C-LDL > 160 g/dL29.
Una de las prioridades debe ser la detección de HF en edades tempranas para iniciar precozmente medidas terapéuticas24. En nuestro estudio, el criterio que obtiene la prevalencia más cercana a la esperada en población < 18 años es el punto de corte C-LDL > 190 mg/dL (HF segura, si se excluyen causas secundarias). En esta población sería mejor bajar el punto de corte hasta 160 mg/dL (probable HF con historia familiar compatible) e incluso a 130 mg/dL (probable si un progenitor tiene HF genéticamente demostrada). Toda esta población será candidata al menos a educación e implicación en hábitos saludables y en función de los valores de C-LDL a TH. La realización de un estudio genético en cascada inversa a familiares de primer orden de niños con sospecha de HF, permite detectar un 84% de los niños con mutación positiva y un 63% de los progenitores30. Un estudio reciente ha mostrado que la combinación de cascada directa e inversa a través de un cribado en niños de un año, aprovechando las campañas de inmunización permitiría detectar al 50% de la población con HF en 17 años y al 75% en 30 años31. El rastreo masivo de datos, junto con una cascada directa e inversa de estudios genéticos podría reducir considerablemente estos tiempos.
La visión a través de la ventana de los macrodatos refleja una práctica clínica con amplio margen de mejora y es una llamada urgente a la acción. En el presente trabajo, la población con F-HF seleccionada es de alto o muy alto RCV, con una prevalencia de ECV del 9% y una letalidad a 10 años del 16%. A pesar de que en nuestro estudio se observa una reducción significativa en el C-LDL en el intervalo temporal analizado y que probablemente sea debida a un mejor abordaje terapéutico de los pacientes, hay un escaso número de pacientes con F-FH en objetivos terapéuticos, tanto en prevención primaria como secundaria, concordante con lo observado en otros estudios en población HF10,32, y es especialmente llamativa la falta de TH en población pediátrica y juvenil. Las técnicas de perfilado de pacientes, siguiendo círculos concéntricos con base en el RCV, nos permiten priorizar la detección de pacientes empezando por los de riesgo extremo33, lo que nos permitiría hacer un uso coste-eficiente de los tratamientos más innovadores34,35.
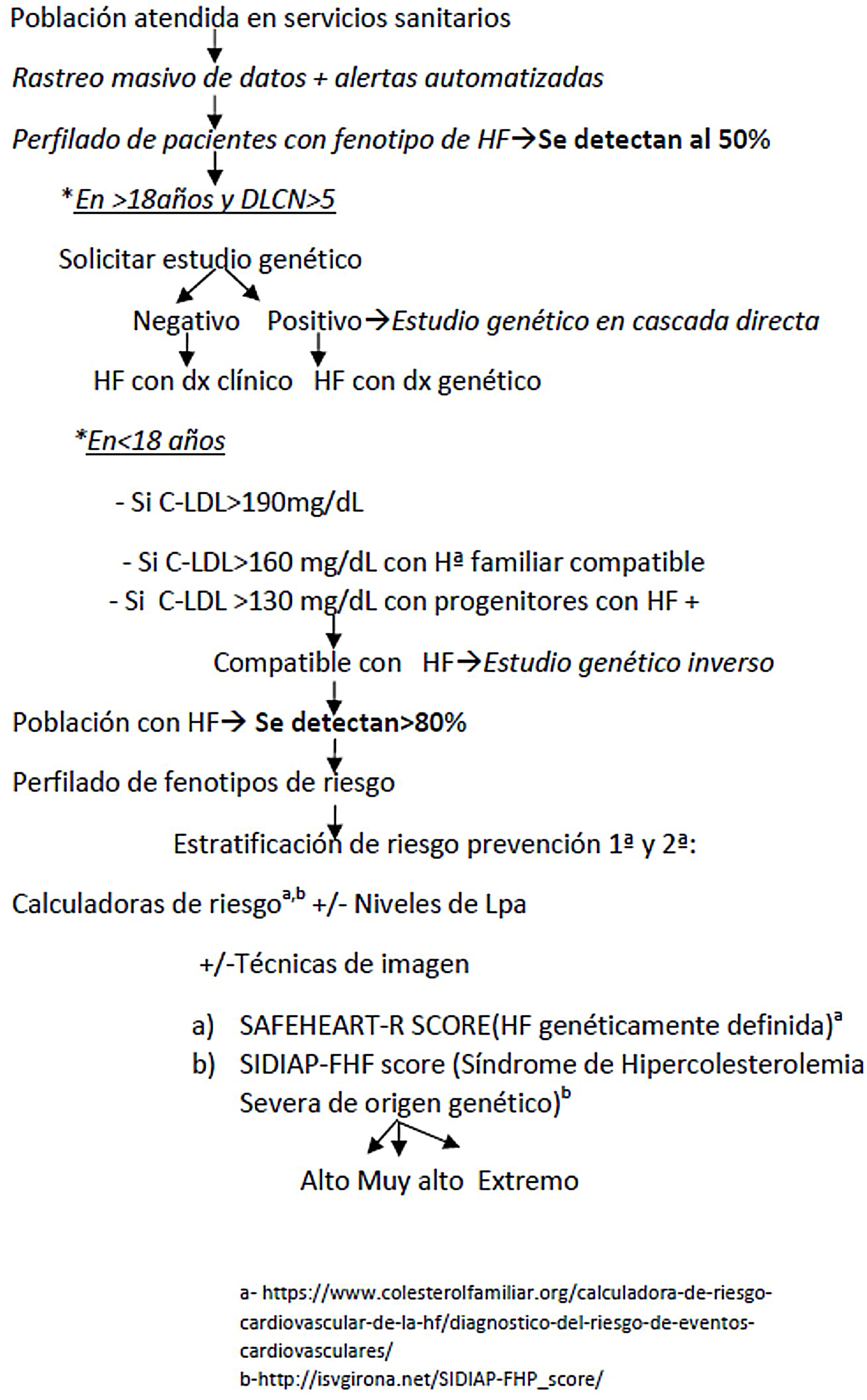
Los autores proponen un programa clínico de mejora de la calidad asistencial a pacientes con F-HF, combinando rastreo masivo de datos, detección automatizada, perfilado de pacientes, valoración clínica, estudio genético en cascada directa-inversa y valoración del RCV (fig. 4). La LOPDGDD 3/2018 autoriza a la reidentificación de datos al tratarse de una situación de especial relevancia para la salud pública21. Los principios que regirán la re-identificación de pacientes serán los de transparencia, beneficencia y proporcionalidad. Los equipos encargados del perfilado y reidentificación deben ser diferentes. La etapa clínica debe ser liderada por el médico responsable de cada petición de analítica, previo consentimiento informado.
.")
Como fortaleza del estudio cabe señalar que el rastreo se ha realizado tras la fusión de bases de datos de los diferentes niveles asistenciales, lo que permite analizar un número importante de pacientes y tener una visión transversal de la atención sanitaria. En cuanto a limitaciones, señalar que se trata de un estudio retrospectivo con un corte temporal y centrado en un área geográfica concreta, aunque la aproximación a las prevalencias esperadas apunta a su utilidad en el cribado de F-HF. El rastreo basado en valores de C-LDL puede sobreestimar el número de pacientes con HF genéticamente definida, especialmente a costa de pacientes con hipercolesterolemias poligénicas o combinadas, aunque serían englobados junto con la HF en el síndrome de hipercolesterolemia severa de origen genético36, de elevado RCV y que precisan igualmente TH intensiva. Al no considerar si los valores de C-LDL se encuentran bajo TH, se puede subestimar el número de pacientes con HF; no obstante, al seleccionar el valor más alto de C-LDL se seleccionan al menos un 40% sin TH, es de fácil aplicación, permite utilizar algoritmos que valoran C-LDL bajo TH y se evitan sesgos por imputaciones al generalizar respuesta terapéutica y adherencia. Otra limitación es la ausencia de acceso a datos genéticos y a niveles de lipoproteína (a)2. Se necesitan definir criterios sugestivos de F-HF en población española diferenciados por edad y sexo. No se han capturados datos no estructurados, aunque estos hechos no invalidan los resultados como propuesta de cribado inicial.
El rastreo masivo de datos y el perfilado de pacientes son una herramienta eficaz y fácilmente aplicable en práctica clínica para la detección de HF. Estas técnicas suponen una segunda oportunidad para mejorar el diagnóstico y tratamiento de pacientes con HF, tanto en prevención primaria como secundaria.
- -
La HF presenta una prevalencia en España en torno 1/282 y para el fenotipo de HF/1/192.
- -
Es la causa más frecuente de ECV prematura. Se asocia a una EC más difusa y peor pronóstico.
- -
Se encuentra infradiagnosticada, con tasas de diagnóstico en torno al 12-15% e infratratada.
- -
Es un problema de salud pública que requiere una intervención urgente.
- -
El rastreo masivo de datos es una técnica eficaz para el cribado inicial de pacientes con F-HF.
- -
El perfilado de pacientes nos permite identificar pacientes con HF y muy alto –extremo RCV.
- -
Un algoritmo de cribado eficaz y factible en nuestro medio puede ser el que utiliza los puntos de corte de C-LDL sugestivos de HF genéticamente definida en población española.
- -
Estas herramientas permiten una fácil traslación y es asumible en la práctica clínica diaria
Fondos propios de Corporació de Salut del Maresme i al Selva.