















Edited by: Brij B. Gupta, Kwok Tai Chui
More infoWeb APIs provide enterprises with a new way of driving innovations of new technology with limited resources. API recommendations greatly alleviate the selection burdens of enterprises in identifying potential useful APIs to meet their business demands. However, these approaches disregard the privacy leakage risk in cross-platform collaboration and the popularity bias in recommendation. To address these issues, first, we introduce MinHash, an instance of locality-sensitive hashing, into a collaborative filtering technique and propose a novel, privacy-enhanced, API recommendation approach. Second, we present a simulation algorithm to analyze the popularity bias in API recommendation. Third, we mitigate popularity bias by improving the novelty of recommendation results with an adaptive reweighting mechanism. Last, comprehensive experiments are conducted on a real-world dataset collected from ProgrammableWeb. Experimental results show that our proposed approach can effectively preserve usage data privacy and mitigate popularity bias at a minimum cost in accuracy.
The emergence of web application programming interfaces (referred to as APIs hereafter) defines a new way of making applications easier to develop, driving innovations of new technology with limited resources (Calero et al., 2019; Hu et al., 2021; Wulf & Blohm, 2020). Because of their advantages in speed, ease, and portability in data exchange, many enterprises offer their services utilizing APIs. An increasing number of enterprises outsource specific business requirements to APIs (Catlett et al., 2020; Jensen & Ashby, 2018; Sánchez et al., 2019). This trend is referred to as the API economy (Bonardi et al., 2016). With the growing prosperity of the API economy, the number of APIs has dramatically grown (Evans & Basole, 2016). According to ProgrammableWeb1 (referred to as PW hereafter), the most prominent API repository, there were more than 24,500 APIs on the website as of May 2022, which is a thirtyfold increase since 2008 (refer to Fig. 1). All the APIs are derived from 507 categories across a wide range of market sectors, e.g., financial, data, social, tools, e-commerce, and payments (see Fig. 2).


The vast number of APIs provide enterprises with a wide range of choices. However, enterprises also face heavy burdens in selecting suitable APIs to meet their demands (Vijayakumar et al., 2022). Fortunately, recommendation techniques (e.g., collaborative filtering) have demonstrated effectiveness in alleviating such burdens (Zhou et al., 2020). A series of API recommendation approaches have been proposed for different scenarios (Bai et al., 2020; Kang et al., 2020; Qi et al., 2022; Yan et al., 2021). However, two significant challenges arise for current API recommendation approaches.
First, many recommendation approaches (e.g., matrix factorization) assume that the historical usage data employed for API recommendation are centrally stored. However, in practice, these data are often owned by different platforms. Moreover, these platforms are reluctant to share data with others because of privacy concerns (Liang et al., 2020; Yang et al., 2022). Consequently, the risk of privacy leakage heavily reduces the possibility of cross-platform collaboration, which decreases the accuracy of recommendation.
Second, because of the intrinsic features of recommendation approaches and training sets, most recommendation methods suffer from popularity bias issues, i.e., popular APIs are overly recommended to enterprises. However, recommending popular APIs to enterprises is trivial. Enterprises may have been aware of popular APIs and decided whether they met their business demands. In addition, enterprises tend to adopt novel APIs that differentiate from their competitors to innovate at a faster rate than competitors.
Given the abovementioned challenges, we propose a novel API recommendation approach named NAPIRec, which introduces MinHash to the traditional collaborative filtering technique to preserve data privacy and promote cross-platform collaboration. Furthermore, we present an adaptive weighting mechanism to mitigate the popularity bias of our proposed approach. To the best of our knowledge, few studies have attempted to employ MinHash to preserve data privacy in API recommendations. Moreover, few studies have focused on the popularity bias issue in API recommendations. The significant contributions of this paper include the following:
- •
We analyze the usage frequency of APIs in PW to reveal the long-tail distribution in API usage. Then, we design a simulation algorithm and demonstrate the popularity bias produced by a classical collaborative filtering approach.
- •
We introduce MinHash into a collaborative filtering technique to preserve API usage privacy in API recommendation. We present an adaptive weighting mechanism to mitigate popularity bias and improve the novelty of recommendation results.
- •
We conduct a series of experiments on a real-world dataset to validate the superiority of our proposed method compared with state-of-the-art approaches.
The remainder of this paper is organized as follows: first, we review related works in API recommendation. Second, we formulate the definition of API recommendation and analyze the popularity bias issue in API recommendation. NAPIRec is introduced and discussed in the ``Methodology'' section. The ``Results and Discussion'' section reports the experimental results conducted on a real-world dataset and discusses its threats to validity. Last, we conclude this paper and outline our future work.
Literature reviewWith the wide adoption of APIs in enterprises, API recommendation has attracted attentions from both researchers and practitioners. A series of API recommendation approaches have emerged, as shown in Table 1. Generally, these approaches are divided into explicit feedback-based approaches and implicit feedback-based approaches. For explicit feedback-based approaches, user preference is explicitly represented as keywords (Gong et al., 2021; Qi et al., 2020, 2022; Xiao et al., 2020) or textual descriptions (Gao & Wu, 2017; Yan et al., 2021).
Differential API recommendation approaches.
| Study | Preference Representation. | Model | Privacy-Aware | Considering Popularity Bias |
|---|---|---|---|---|
| Xiao et al. (2020) | Keywords | Deep Neural Network | No | No |
| Qi et al. (2022, 2020) | Keywords | Minimal Steiner Tree | No | No |
| Cheng et al. (2020) | Keywords | Graph Search | No | No |
| Gong et al. (2021) | Keywords | Minimal Steiner Tree | No | No |
| Gao and Wu (2017) | Plain text | Clustering | No | No |
| Yan et al. (2021) | Plain text | GCN | No | No |
| Yao et al. (2021) | Implicit | Matrix Factorization | No | Yes |
| Wang et al. (2021) | Implicit | Cover Tree | No | No |
| He et al. (2022) | Implicit | Matrix Factorization | No | Yes |
| Qi et al. (2018) | Implicit | LSH + User-based CF | Yes | No |
| This study | Implicit | MinHash +User-based CF | Yes | Yes |
However, to achieve a better user experience, platforms often need to make recommendations without knowing explicit user preferences. Therefore, implicit feedback from historical usage information, such as QoS (Qi et al., 2018; Wang et al., 2021) and historical invocation records, is employed to capture user preference. As the QoS information of APIs is generally incomplete and hard to obtain, most API recommendation approaches focus on utilizing historical invocation records to capture user preference (Yan et al., 2021; Yao et al., 2021).
Recommendation approaches based on implicit feedback usually adopt collaborative filtering methods (Wang et al., 2022), e.g., matrix factorization (He et al., 2022; Yao et al., 2021). These approaches assume that the recommendation base, e.g., historical usage data, is centralized on one platform. However, in practice, historical usage data are distributed across different platforms. Moreover, platforms tend not to share data because of privacy concerns. Qi et al. (2018) introduced locality-sensitive hashing (LSH) to preserve the data privacy of service providers in web service recommendations. However, Qi's recommendation algorithm is based on continuous QoS data, which is unsuitable for discrete API usage data. To the best of our knowledge, few researchers have focused on the problem of privacy preservation in API recommendation.
Some researchers have noticed the popularity bias issue in recommendation and conducted a series of studies. He et al. (2022) investigated the popularity bias in matrix factorization-based, third-party library usage prediction, and neutralized the popularity bias by employing an adaptive mechanism. Gong et al. (2021) improved the diversity of API compositions by introducing sampling techniques to API recommendations. However, from the perspective of innovation, diversity is not equal to novelty, which is more likely to lead to innovation. Little attention has been paid to recommending novel APIs for enterprises. Compared with the previous research works, we propose a recommendation algorithm to meet the demands of enterprises for novel and valuable APIs while preserving their data privacy.
Popularity bias in API recommendationAPI recommendationMost enterprise applications invoke several APIs to implement their business requirements, e.g., online payment and map navigation. Given an enterprise application set E={e1,e2,…,em}, and an API set A={a1,a2,…,an} which are registered in platforms, we represent the API usage data of all the enterprise applications in E as a m×n matrix (referred to as the usage matrix hereafter), as shown in Fig. 3. For an enterprise application ei∈E, if API aj is consumed by ei, ui,j is set to 1. Otherwise, ui,j is set to 0. The aim of API recommendation is, for an enterprise application ei, to select K APIs {a1′,a2′,…,aK′}⊆A that are not consumed by ei but are most likely applicable to ei.

As typical representatives of light applications in the API economy, mashups are created by integrating APIs from different providers to implement specific business requirements. In our preliminary study, we collected 6530 mashups from PW. We discover that some API pairs cooperate in many mashups. Figure 4 shows the cumulative distribution of the cooperation frequency of API pairs, i.e., times invoked by the same mashup. For all the API pairs that collaborate in at least one mashup, approximately 35% of API pairs cooperate in more than five mashups, and more than 20% API pairs appear in more than ten mashups. The API usage patterns inspire a new method to recommend potential useful APIs for enterprises utilizing collaborative filtering.
Popularity bias
Collaborative filtering-based approaches usually suffer from the popularity bias problem, i.e., a small fraction of APIs consumed by most enterprises (named popular APIs) dominate the recommendation list. If this situation continues, APIs consumed by all the enterprise applications will concentrate on a tiny number of popular APIs, which may lead to two problems. First, as many enterprises have been aware of the most popular APIs, they will not benefit much from a recommendation list dominated by popular APIs. Second, newly published APIs have little chance of being seen and consumed by enterprises, hindering innovation in the API economy.
We conduct experiments on a real-world dataset from PW to investigate the popularity bias in API recommendation. To simulate the scenario of recommending APIs for enterprise applications employing historical API usage information, we choose mashups that invoke more than two APIs and APIs consumed by more than one mashup. Then, we build a 2445×604 usage matrix M. Detailed experimental settings are discussed in the “Results and Discussion" section. We propose an iterative simulation algorithm to investigate the longitudinal effect of collaborative filtering recommendation, as shown in Algorithm 1. We assume that enterprises make decisions entirely relying on the recommendation results. Enterprises consume the first API in the recommendation list during each simulation period. We update the usage matrix with new usage data at the end of each iteration. Then, we make recommendations employing the updated mashup-API matrix. We plot the API usage matrix with a scatter diagram, as shown in Fig. 5(a). Each row indicates a mashup, and each column indicates an API. Data is sorted by the usage frequency of APIs and the number of APIs consumed by mashups. Therefore, the first row in the scatter diagram represents the mashup that consumed the most APIs, and the first column represents the API invoked by the most mashups.

Figure 5(a) shows the initial distribution of API usage data. The initial distribution reflects a snapshot of realistic, long-tail distribution, where a small fraction of APIs is consumed by numerous mashups. The results are consistent with the distribution of the usage frequency of APIs, as shown in Fig. 6.

Figure 5(b) depicts the structural distribution of APIs newly consumed by mashups over 40 simulation periods. The distribution indicates that the newly consumed APIs are condensed into a small set of APIs. The reason is that the recommendation results of the collaborative filtering approach mainly depend on the characteristics of historical data, e.g., density and value distribution (Adomavicius & Zhang, 2012). As API usage data follow the long-tail distribution (Park & Tuzhilin, 2008), the recommendation results are more likely to show high skewness. Moreover, increased reliance on the recommendation results leads to a skewed distribution of API usage data, producing more condensed recommendation results.
However, enterprises may not benefit much from popular APIs because they may already be familiar with them. In addition, from the perspective of innovation, recommendation results offering novelty and serendipity are more attractive to enterprises.
MethodologyMinHashMinHash is also known as a minwise independent permutation locality-sensitive hashing scheme. Locality-sensitive hashing (LSH hereafter) (Gionis et al., 1999) is an approximate nearest neighbor search method based on hashing. Letting D(·,·) denote a distance function of two elements from a set P, and Pr(·) represent the probability that an event holds.
Definition 1 A hash function h(·) is referred to as (d1,d2,p1,p2)-sensitive for D(·,·) if for any x,y∈P: ifD(x,y)≤d1,Pr(h(x)=h(y))≥p1 ifD(x,y)≥d2,Pr(h(x)=h(y))≤p2
Due to its advantage in compact storage and efficient retrieval, LSH is widely adopted in many domains, e.g., database, image retrieval, and clustering. Many LSH approaches have been proposed for different purposes. These LSH approaches can be classified into metric-driven and data-driven approaches (Ioffe, 2010). The former approaches aim at approximating specific distance metrics, e.g., cosine distance, Euclidean distance, and Jaccard distance. The latter approaches aim at learning hash functions from the training data to gain optimal performance on specified tasks.
MinHash is designed to approximate the Jaccard distance, which is usually used to measure the similarity between two finite sets. Assuming that A and B are two sets, the Jaccard distance between A and B is defined by

Given a set E, and a series of random hash functions fi:E→Z mapping each element in E to a distinct integer, let A⊆E,B⊆E. The MinHash value of A under the order inferred by fi is calculated by

It has been proved (Broder et al., 2000) that if fi is uniformly and randomly chosen,
Method design
In this section, we discuss NAPIRec in detail. Generally, our approach seamlessly integrates three phases: the privacy preservation phase, prediction phase, and recommendation phase. Concretely, in the privacy preservation phase, NAPIRec adopts the MinHash technique to encode the API usage data of each enterprise application into several binary bits. In the prediction phase, a collaborative filtering-based algorithm is proposed to predict the consumption possibilities of unused APIs for each enterprise application. In the recommendation phase, NAPIRec reweights the usage probability of APIs based on the popularity of APIs and returns a certain number of APIs with the highest possibilities to enterprise applications.
Privacy preservation phaseStep 1: Encode API usage data employing MinHash to preserve the privacy of enterprises. For the usage matrix M, the ith row represents the API usage data of the ith enterprise application. Given a family F of functions, I={0,1,…,n−1}, for each function f(·)∈F:I→I, f(·) maps I into a random permutation of elements in the set I. The form of f(·) is defined by
where d is a random positive integer and i is the index of an API. Moreover, to satisfy ∀j∈I,j≠i,f(i)≠f(j), d and n must be relatively prime. The family H of hash functions is a set of functions h:E→Z+. Letting ui denotes the API usage data of the ith enterprise, i.e., the ith row of usage matrix M. The MinHash value of ui under the order induced by f is defined as follows:where Si={jui,j=1}.Prediction phase

Step 2: Calculate the similarity between two enterprises according to hash values. In Step 1, under the order inferred by each f∈F, the API usage data of each enterprise are hashed to an integer value. Consequently, all the hash values of ui are represented as

The similarity between ui and uj is calculated by


Step 3: Predict consumption possibilities for unused APIs. In this step, for each enterprise, we select the k most similar enterprises into a set, i,e, NB_Set, and then predict the consumption possibility for an unused API by
Recommendation phase
Step 4: Reweight predicted values and make top-k recommendations for enterprise applications. As mentioned in Section ``Popularity bias in API recommendation'', traditional CF-based recommendation approaches may suffer from popularity bias issues. To alleviate the popularity bias in the recommendation list, we assign different weights to APIs according to their popularity and the length of the recommendation list, i.e., r. The weight of API ai is calculated as follows:
where pi denotes the popularity of ai and α is a hyperparameter controlling the influence of popularity in API recommendation. Then we multiply the predicted values of unused APIs by their weights and select the K APIs with highest values as the final recommendation results.Results and discussion
In this section, we describe experimental settings and then show the advantages of NAPIRec based on the following research questions:
- •
RQ1: Does NAPIRec outperform state-of-the-art API recommendation approaches in accuracy and novelty?
- •
RQ2: How does the size of function family F and the number of most similar enterprise applications, i.e., k, affect the performance of NAPIRec?
- •
RQ3: How does the hyperparameter α affect the novelty of the recommendation results provided by NAPIRec?
Dataset. To simulate the scenario of API recommendation for enterprises, we collected 18,748 APIs and 6146 mashups from PW. Each mashup is an enterprise application. We removed the mashups that invoked less than two APIs. To validate the performance of NAPIRec in recommending less popular APIs for enterprises, we removed the API with the lowest popularity in each mashup. The ground truth of the experiments is that these removed APIs are most beneficial to corresponding enterprise applications.
Experimental Environment. All experiments are performed on a machine with Intel i9-10,900K CPU 3.70 GHz, 32 GB RAM, running Windows 10 × 64 Professional and Python 3.8.
Performance Metrics. We adopt four commonly employed metrics to comprehensively measure the performance of NAPIRec from two perspectives: accuracy and novelty. These metrics are within the range of [0, 1].
- •
Mean Precision (MP). Given an API recommendation list, the precision is the ratio of correctly recommended APIs to all the APIs in the list (Tang et al., 2021). MP averages precisions across all recommendation lists. A more significant value indicates better accuracy.
- •
Mean Recall (MR). Given an API recommendation list, recall is considered the ratio of correctly recommended APIs to all APIs that should be recommended (Ma et al., 2021). MR averages recall across all recommendation lists. A more significant value is better.
- •
Normalized discounted cumulative gain (NDCG). NDCG measures the ranking quality of recommendation results and is calculated by

- •
Coverage (Cov). Coverage indicates the fraction of distinct APIs in all recommendation lists to all the APIs in set A (Zhou et al., 2021). Assume that the recommendation lists for all the enterprises are represented as the set RL={rl1,rl2,…,rlm}. The Cov value is calculated as follows:

A higher COV value means that the recommendation method recommends more novel APIs to enterprises. If a recommendation approach suffers more from popularity bias, the COV value will be low.
Compared Methods. In the experiments, to testify to the effectiveness of our proposed approach in privacy-preserving and recommending novelty APIs, we compare NAPIRec with six classical approaches:
- •
POP. The popularity-based method always recommends the most popular APIs that have not been consumed by enterprises, which is the baseline method in our experiments.
- •
UPCC,UJACC. User-based collaborative filtering algorithms adopt Pearson and Jaccard coefficients as similarity metrics. The two methods are also baselines in our experiments.
- •
MF. (Koren et al., 2009) Matrix factorization decomposes the usage matrix into latent factors to obtain better performance.
- •
SerRecdistri_LSH. (Qi et al., 2018) Locality-sensitive hashing-based collaborative filtering approach has the ability to preserve data privacy.
- •
ARIRec. API recommendations can preserve data privacy but do not reweight the predicted values.
To conduct a fair evaluation, we tune the parameters of each approach to achieve the best performance. In detail, we set the number of nearest neighbors k=600 for UPCC and UJACC. For SerRecdistriLSH, the number of hash functions and tables is set to 8. We set the dimension of latent factors to 604 for the MF approach.
RQ1: Performance comparisonTable 2 compares the performance of NAPIRec with six competitive approaches. The comparison demonstrates that NAPIRec outperforms all competing methods in terms of accuracy and novelty, as indicated by four metrics.
Performance Comparison across different K.
Specifically, NAPIRec significantly improved over POP by 240.01%, 240.01%, 286.83%, and 1580.01% in terms of MP, MR, NDCG, and COV, respectively; it also significantly improved over MF by 86.35%, 86.35%, 192.36%, −15.31%. It should be noted that the improvement of MF in COV is achieved at the cost of a decrease in accuracy.
The ways of predicting UPCC, UJACC and APIRec are similar to NAPIRec. We discover that NAPIRec shows a slight advantage over UPCC, UJACC, and APIRec in MP, MR, and NDCG. However, NAPIRec achieves better improvements over the three approaches in COV, i.e., 18.98%, 49.91%, and 50.01%, which fully demonstrates the effectiveness of NAPIRec in improving the novelty of recommendation results.
Moreover, as two recommendation approaches capable of preserving the privacy of enterprises, NAPIRec demonstrates significant advantages over SerRecdistriLSH in MP, MR, NDCG, and COV, i.e., 56.14%, 56.14%, 70.64%, and 112.6%, respectively. These results show the effectiveness of NAPIRec in balancing privacy preservation, accuracy, and novelty.
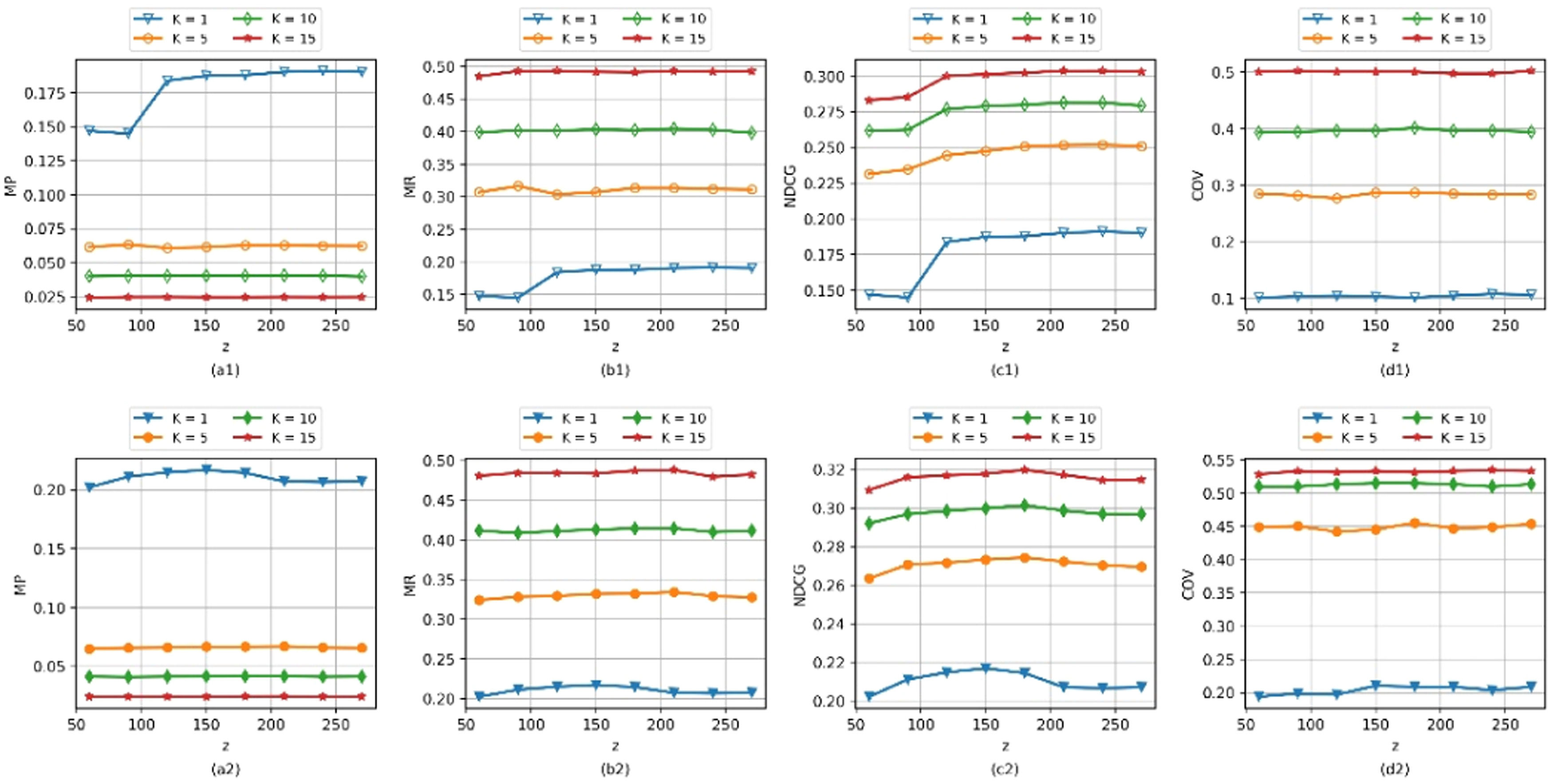
RQ2: Performance analysis w.r.t z and kImpact of z. Parameter z indicates the number of functions in F, which is equal to the number of hash tables in MinHash. Parameter z determines the accuracy of MinHash in identifying approximate nearest neighbors. To investigate its impact on the performance of APIRec and NAPIRec, we vary z from 60 to 270 in steps of 30. Figure 7 shows the performance of APIRec in the first row and NAPIRec in the second row.

We observe that as z increases from 50 to 150, the performance of APIRec shows a significant increase in MP, MR, and NDCG. When z > 180, the increase in z does not significantly increase the performance of APIRec. In addition, the increase in z slightly impacts the performance of NAPIRec in MP, MR, and COV. Moreover, when z > 180, the NDCG value of NAPIRec drops slightly. Therefore, we choose 180 as a reasonable value for z.
Impact of k. APIRec and NAPIRec utilize information from similar enterprise applications to predict the consumption possibilities of APIs for an enterprise application. Parameter k indicates how many similar enterprise applications are employed in making predictions. To evaluate the impact of k, we vary k from 50 to 650 in steps of 50. Figure 8 demonstrates the influence on the performance of APIRec in the first row and NAPIRec in the second row. We discover that APIRec and NAPIRec significantly improved in MP, MR, and NDCG as k increased. In contrast, the COV values of the two approaches decrease slightly as k increases. Thus, the appropriate value of k is set to 600.
RQ3: Performance analysis w.r.t. α
Parameter α is used to set the weight of APIs. It controls the degree of reliance on popularity in API recommendation. An overly small α, i.e., α=0, may lead to a loss in novelty. On the other hand, an excessively large α disregards the positive effect of popularity bias, which may result in a loss in accuracy. To investigate the impact of α, we vary α from 0 to 1.8 in steps of 0.3. The statistical results are shown in Fig. 9. We can find that when α<1.5, the MP and MR values slightly change as α increases. The NDCG and COV values significantly improve as α increases from 0 to 1.5. However, when α>1.5, the performance of NAPIRec decreases in MP, MR, NDCG and slightly increases in COV. Therefore, an appropriate value of α is identified, i.e., α=1.5.
Discussion
There are a few external and internal validity threats in our evaluation. One of the main potential threats to the external validity in evaluation is the representativeness of our dataset. To mitigate this threat, we crawl mashup and API data from PW, one of the world's most famous and largest API repositories. An increasing number of APIs and mashups are registering in PW to further improve its representativeness. Another potential threat is whether our experiments can reflect real-world recommendation demands. To minimize this threat, we simulate the to-be-improved version of these mashups by removing APIs that are currently invoked by mashups. These removed APIs are the ground truth for evaluation and can adequately validate the capability of our approach in making accurate recommendations for enterprises.
Our internal validity is whether the comparison with POP, UPCC, UJACC, MF, and SerRecdistri_LSH correctly verifies the performance of our proposed approach. We mitigate this threat in four different ways. First, we implement a popularity-based method, i.e., POP, as a baseline to analyze the novelty of recommendation results in experiments. Second, to demonstrate the accuracy of our proposed approach, we compare NAPIRec with state-of-the-art collaborative filtering approaches. UPCC and UJACC are two representatives of user-based collaborative filtering methods. MF is one of the most successful collaborative filtering recommendation methods. Third, we also compare NAPIRec with SerRecdistri_LSH, which considers preserving the privacy of service providers while making recommendations. Fourth, to demonstrate the validity of our proposed approach in mitigating popularity bias, we compare NAPIRec with APIRec, which adopts the same approach as NAPIRec without reweighting predicted values. Moreover, we compare these approaches in terms of not only novelty but also accuracy.
ConclusionIn this paper, first, we reveal the importance of API recommendation in facilitating innovation in enterprises. Second, we point out two challenges raised in current API recommendation approaches. To address the first challenge, we introduce MinHash into a classical collaborative filtering approach to preserve data privacy in API recommendations. To address the second challenge, we investigate the popularity bias in a collaborative filtering recommendation approach, and propose a reweighting mechanism to mitigate the popularity bias. Comprehensive experiments are conducted on a real-world dataset obtained from PW. Experimental results show the superiority of NAPIRec in preserving data privacy and mitigating popularity bias.
There are still limitations to our proposed method. First, as an implicit feedback-based approach, NAPIRec provides enterprises with a suggestion list without knowing the specific requirements of enterprises. Therefore, the accuracy is lower than that of keyword search-based approaches. Second, because NAPIRec makes recommendations utilizing historical usage information, it may suffer from cold-start problems. Third, because NAPIRec assigns higher priorities to less popular APIs, it may exclude some potential APIs with high popularity from the recommendation list. Thus, it may not be suitable in some cases, e.g., enterprises taking the API adoption rate as the highest priority. However, in most cases, recommending popular APIs is trivial for enterprises.
In future work, we will collect more API usage data from other sources to validate the effectiveness of NAPIRec. Moreover, we plan to leverage additional information of APIs, e.g., category and description, to further improve the performance of NAPIRec.
Statements and declarationsConsentAll authors have approved the manuscript.
Data availabilityData are available on request due to privacy or other restrictions.
This work was supported by the National Planning Office of Philosophy and Social Science of China (Grant No. 21BJY206).