




Article information
Full Text
Bibliography
Download PDF
Statistics
Figures (1)
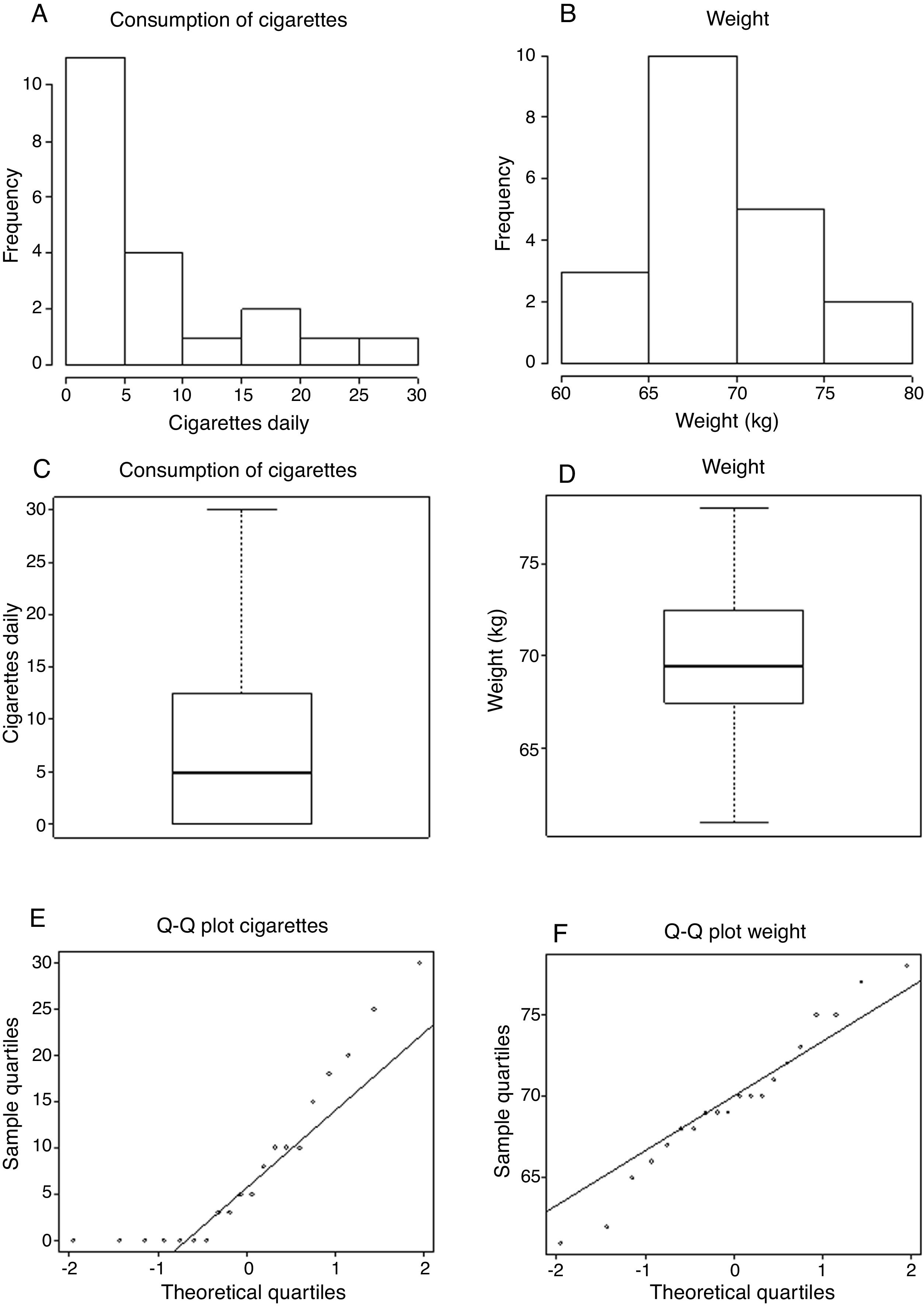
Tables (1)
Table 1. Daily cigarette consumption and weight (kg) in a hypothetical series of 20 subjects.

Article
These are the options to access the full texts of the publication Medicina Clínica (English Edition)
Subscriber
Subscribe

Purchase
Contact
Phone for subscriptions and reporting of errors
From Monday to Friday from 9 a.m. to 6 p.m. (GMT + 1) except for the months of July and August which will be from 9 a.m. to 3 p.m.
Calls from Spain
932 415 960
Calls from outside Spain
+34 932 415 960
E-mail
