


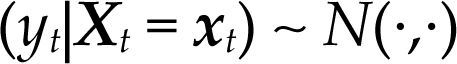
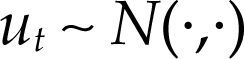
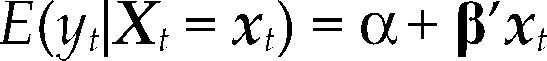
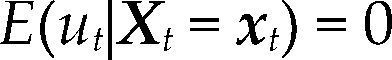
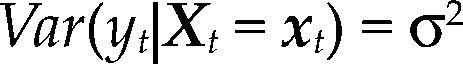
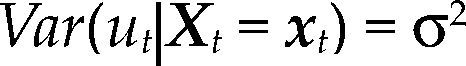
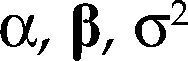
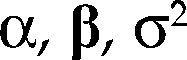
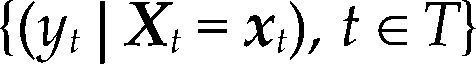
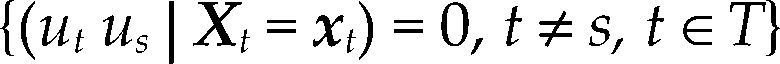
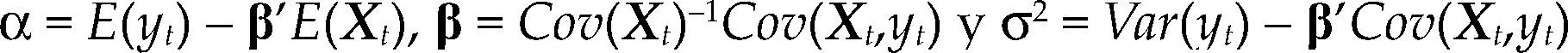
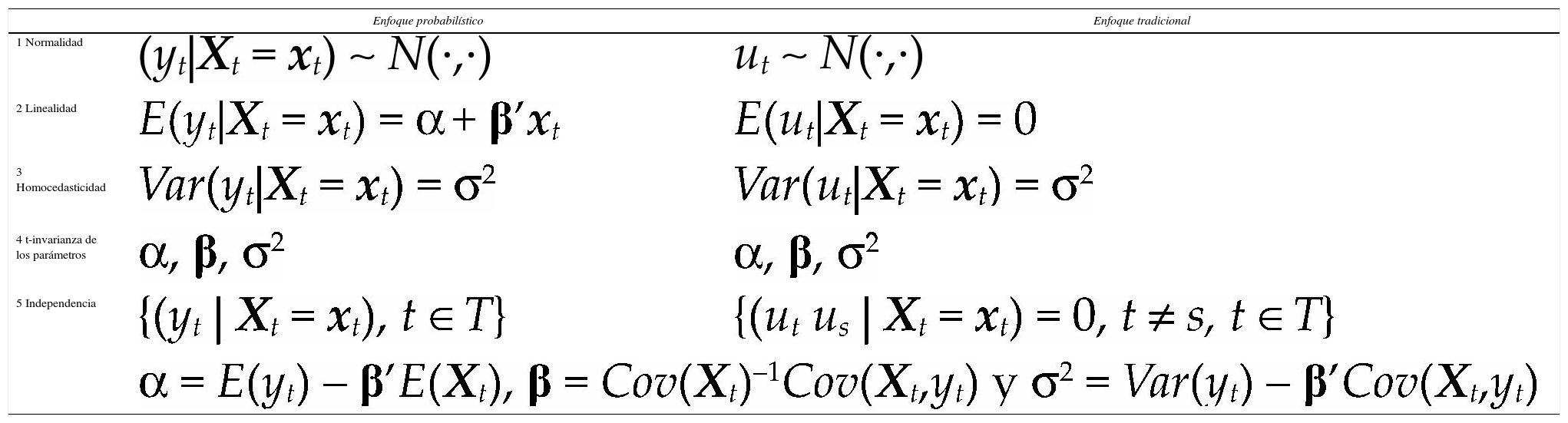




El objetivo de este artículo es argumentar que para que la economía se fundamente plenamente como una ciencia, y no simplemente como un arte basado en la intuición, se deben seguir ciertos principios científicos. El artículo contribuye al debate sobre la materia, específicamente en dos aspectos metodológicos: 1) el adecuado análisis de datos para la verificación de las hipótesis de una investigación y 2) la replicación de los hallazgos científicos con la finalidad de evaluar a los mismos. El primer aspecto, con base en el enfoque probabilístico de la econometría de Haavelmo (1944), implica que los economistas aseguremos que los supuestos probabilísticos de los modelos estadísticos que utilizamos en nuestras investigaciones se cumplan. El segundo aspecto plantea que las replicaciones son un medio para establecer la fragilidad (derivada por errores del manejo de bases de datos o por la inadecuada especificación de los modelos estadísticos), o la solidez (derivada de la robustez de los resultados ante cambios en el periodo de análisis, en la economía analizada, en la especificación de las variables, en el método de estimación, etc.) de los resultados reportados en una investigación publicada. El artículo contribuye con una ilustración de nuestra propuesta metodológica: se trata de la replicación del artículo de Kakkar (2001), “Long run real exchange rates: evidence from Mexico”, publicado en la revista Economics Letters.
The aim of this article is to argue that for the economics to be fully settled as a science, and not simply as an art based on intuition, it has to follow certain scientific principles. The article contributes to the debate on the matter, specifically on two methodological aspects: 1) the proper analysis of data to confirm the hypothesis of a research, and 2) the replication of scientific findings in order to evaluate them. The first aspect, based on Haavelmo's monograph of 1944 entitled “The probabilistic approach to econometrics”, implies that economists should make sure that the probabilistic assumptions of the statistical models used in their research are met. The second aspect suggests that the replications are a means to show the fragility (arose by errors of mishandling databases or inadequate specification of statistical models), or the strength (arose from the robustness of the results from changes in time period, the economy under analysis, the specification of the variables, the estimation methods, etc.) of the results reported in a published research. The article contributes with an illustration of our own methodological proposal: it is a replication of an article by Kakkar (2001), entitled “Long run actual exchange rates: Evidence from Mexico”, published in the journal Economics Letters.
El estatuto de la economía como una disciplina científica, y no simplemente como un arte basado en la intuición, es algo que se viene discutiendo prácticamente desde su nacimiento. El objetivo de este artículo es contribuir al debate sobre la materia, específicamente en dos aspectos metodológicos: 1) el adecuado análisis de datos para la verificación de las hipótesis de una investigación y 2) la replicación de los hallazgos científicos con la finalidad de evaluar a los mismos. La discusión abstracta podría extenderse hasta el infinito, y por eso consideramos que es más útil seguir un camino diferente. Así, primeramente, se hará referencia en esta introducción y en la segunda sección a las cuestiones metodológicas generales relativas al análisis de datos en economía que se desprenden del artículo pionero “The probability approach in econometrics” (“El enfoque probabilístico de la econometría”) de Haavelmo (1944). Inmediatamente después se presentará un reporte sobre las replicaciones a investigaciones empíricas en economía, que describe la escasa cultura entre los economistas de replicar los resultados de investigaciones publicadas y, posteriormente, publicar sus hallazgos. Finalmente, mediante una replicación del artículo de Kakkar (2001), titulado “Long run real exchange rates: Evidence from Mexico”, publicado en la revista Economics Letters, se ilustrará cómo ambos aspectos deben ser debidamente garantizados para evitar que las conclusiones de una investigación sean inválidas, o poco confiables.
Por lo común sólo aquellas disciplinas que tienen que ver con las ciencias naturales se reconocen como propiamente científicas, fundamentalmente porque en ellas es posible someter las hipótesis a experimentación y, mediante el uso de métodos estadísticos, validarlas o rechazarlas. Por supuesto, las investigaciones en economía aplicada son distintas, porque no se pueden medir características de un gran número de elementos de una muestra bajo un mismo experimento. No se trata de que las estadísticas públicas del producto interno bruto (pib) en un año únicamente se reunieron una vez, sino que el pib de ese año en cuestión existió sólo una vez; la historia exclusivamente nos proporciona ese “experimento”.1
Sin embargo, el carácter no experimental de los datos económicos, que proceden de “la corriente de experimentos que la naturaleza está constantemente realizando en su enorme laboratorio, de la que meramente somos observadores pasivos” (Haavelmo, 1944, p. 14), no debería ser un obstáculo para que en economía se apliquen metodologías estadísticas basadas en la teoría de la probabilidad para estimar y probar relaciones a cerca de fenómenos reales con todo rigor científico.
La econometría, o al menos la corriente de la econometría con la que me identifico, adopta el fundamento metodológico del enfoque probabilístico de Haavelmo (1944). En este enfoque se supone que todas y cada una de las variables que conforman un cierto fenómeno son variables aleatorias y que, por tanto, se caracterizan por poseer una cierta función de densidad que, grosso modo, indica la probabilidad de ocurrencia de los distintos valores que podrían tomar cada una de esas variables. A la vez, se considera el conjunto de datos disponibles respecto de cada una de esas variables (x) como una muestra, fruto de la realización de un proceso generador de datos (pgd).2 Este proceso es desconocido, y de hecho quizá no lleguemos nunca a conocerlo con precisión. Pero al caracterizarlo mediante una determinada distribución de probabilidad3 resulta posible realizar pruebas de hipótesis o cualquier otro tipo de inferencia estadística. En palabras de Haavelmo (1944, p. iii): It is sufficient to assume that the whole set of, say n, observations may be considered as one observation of n variables (or a “sample point”) following an n-dimensional joint probability law, the “existence” of which may be purely hypothetical. Then, one can test hypotheses regarding this joint probability law, and draw inference as to its possible form, by means of one sample point (in n dimensions).
Ahora bien, consideramos que en economía al igual que en las ciencias naturales (y también la medicina, por ejemplo) es importante, antes que nada, modelar de manera formal, y general, nuestra hipótesis, por ejemplo, cuáles son los determinantes del tipo de cambio real en un periodo de tiempo dado. Pero si estudiamos un fenómeno real, para ello no basta una formulación general, o teórica. Es preciso que el modelo en cuestión tome en cuenta debidamente la forma en que el fenómeno se manifiesta en la realidad concreta; esto es, que recoja adecuadamente los datos que proporciona la realidad.
Pero, ¿qué quiere decir en este contexto recoger adecuadamente los datos? En la econometría inspirada en el enfoque de Haavelmo, esto quiere decir ni más ni menos que tomamos esos datos como si ellos provinieran de una determinada función de probabilidad, y que verificamos que, al estimar parámetros o contrastar hipótesis (teorías económicas), cumplimos los supuestos probabilísticos del modelo estadístico. Esta es una cuestión fundamental puesto que los métodos estadísticos no tienen sentido sin la teoría de la probabilidad que los fundamenta. “For no tool developed in the theory of statistics has any meaning —except, perhaps, for descriptive purposes— without being referred to some stochastic scheme” (Haavelmo, 1944, p. iii).
En la siguiente sección se exponen algunos aspectos del enfoque probabilístico de la econometría de Haavelmo, que representan un conjunto de principios metodológicos para la economía aplicada.
EL ENFOQUE PROBABILÍSTICO DE LA ECONOMETRÍAEl objetivo de esta sección es destacar los fundamentos metodológicos que los planteamientos del economista noruego Trygve Haavelmo dieron a la econometría, al adaptar las nuevas perspectivas probabilísticas y estadísticas de la época a los datos económicos, y que hoy en día permiten el uso de métodos estadísticos para evaluar teorías económicas, o hipótesis económicas, contra los datos, con todo rigor científico. Dichas ideas se publicaron en 1944, en la revista Econométrica, bajo el titulo “The probability approach to econometrics”.4
El enfoque probabilístico que Haavelmo dio a la econometría fue influenciado por los axiomas de la teoría de la probabilidad (Kolmogorov, 1933), por los planteamientos de inferencia estadística basada en la teoría de muestras finitas, la teoría de la estimación y de pruebas de hipótesis de Fisher (1922), así como por los métodos estadísticos basados en probabilidad de Jerzy Neyman y Abraham Wald.5
Previo a los planteamientos de Haavelmo, los economistas de la época se habían mostrado renuentes a adoptar modelos probabilísticos para modelar fenómenos económicos por la falta de independencia y homogeneidad de los datos. Se creía que, basados en el concepto de muestra aleatoria,6 los modelos de probabilidad estaban reservados a experimentos cuyas realizaciones, con objetos (o individuos) de una misma “población” y bajo las mismas condiciones, generen una serie de observaciones independientes con idéntica distribución, por ejemplo en juegos de azar (véase Spanos, 2015).
Así pues, había mucho escepticismo en la mayoría de los economistas de la época, ya que se creía que el análisis econométrico basado en la teoría de la probabilidad no era aplicable en la mayoría de las situaciones. No obstante, Haavelmo insistió que la teoría de probabilidad era lo suficientemente general para hacer frente a las particularidades de los datos económicos. What we want are theories that, without involve us in direct logical contradictions, state that the observations will as a rule cluster in a limited subset of the set of all conceivable observations, while it is still consistent with the theory that an observation falls outside this subset ‘now and then’. As far as is known, the scheme of probability and random variables is, at least for the time being, the only scheme suitable for formulating such theories (Haavelmo, 1944, p. 40).
El primer aspecto metodológico del enfoque probabilístico de la econometría para comparar la teoría contra los datos es puntualizar bajo qué condiciones se espera que la teoría se cumpla. Es decir, para que un modelo tenga significado económico deberá tener asociado un diseño de experimentos que describa e indique cómo medir un sistema de variables verdadera7 (X1,X2,…,Xn) asociadas a las correspondientes variables teóricas.8 De esta forma, el modelo se convierte en una hipótesis del fenómeno real, donde todo sistema de valores que podríamos observar9 de las variables “verdaderas” será uno que pertenece al conjunto de sistemas de valores admisibles dentro del modelo. En pocas palabras, la filosofía del planteamiento es la siguiente: (…) that Nature has a way of selecting joint value-systems of the ‘true’ variables such that these systems are as if the selection had been made by the rule defining our theoretical model. Hypotheses in the above sense are thus the joint implications —and the only testable implications, as far as observations are concerned— of a theory and a design of experiments (Haavelmo, 1944, p. 9).
Haveelmo distinguió entre dos tipos de experimentos, los que se pueden aislar artificialmente, y los de la naturaleza: (1) experiments that we should like to make to see if certain real phenomena —when artificially isolated from “other influences”— would verify certain hypotheses, and (2) the stream of experiments that Nature is steadily turning out from her own enormous laboratory, and which we merely watch as passive observers (Haavelmo, 1944, p. 14).
En la mayoría de los casos, los fenómenos económicos no se pueden realizar un gran número de veces bajo las mismas condiciones. Los economistas, por tanto, deben modelar con resultados que la naturaleza ha realizado, y de los cuales son observadores pasivos. En este caso, Haavelmo propone utilizar la teoría para explicar los resultados que la naturaleza está produciendo: In order to test a theory against facts, or to use it for predictions, either the statistical observations available have to be “corrected”, or the theory itself has to be adjusted, so as to make the facts we consider the “true” variables relevant to the theory (…). The economist (…) is presented with some results which, so to speak, Nature has produced in all their complexity, his task being to build models that explain what has been observed (p. 7) (…) try to adjust our theories to reality as it appears before us (Haavelmo, 1944, p. 14).
Y los datos disponibles van a ser tratados como si hubiesen sido generados por el diseño de experimento y la teoría elegida: “We try to choose a theory and a design of experiments to go with it, in such a way that the resulting data would be those which we get by passive observation of reality” (Haavelmo, 1944, p. 14).
El fundamento probabilístico de los modelos económicos consiste en considerar el conjunto de los n valores observados, (x1,x2,…,xn), de las n variables (X1,X2,…,Xn) involucradas en alguna relación de teoría económica de interés, X1=f (X2,X3,…,Xn), como un punto muestral, extraído del universo n-dimensional, ℝn, obedeciendo alguna función de distribución de probabilidad conjunta n-dimensional desconocida, denotada por:
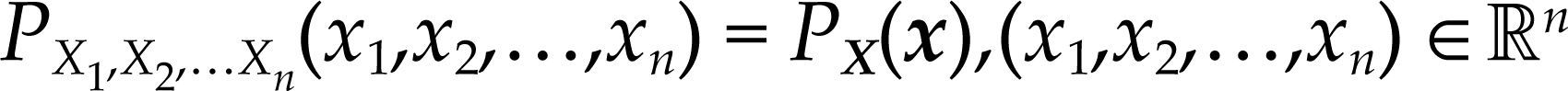
Dicha función contiene toda la información probabilística del vector aleatorio, de manera que esta función adquiere central importancia puesto que ella constituye la base del modelo estadístico que captura toda la información contenida en las series de datos observados.10 De hecho, esta información expresada en la función de densidad conjunta de todas las variables bajo análisis:
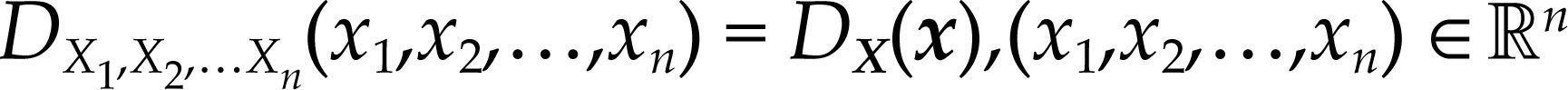
constituye el proceso generador de datos. Por lo general, la función de densidad conjunta del proceso observable tiene una estructura probabilística complicada debido a su alta dimensionalidad y a la heterogeneidad de los datos económicos.
A partir de lo anterior, podemos dar un nuevo paso. En el marco del enfoque probabilístico se ha desarrollado la teoría de la reducción probabilística (Hendry y Richard, 1983; Spanos, 1986). La anterior consiste en evaluar rigurosamente supuestos sobre el vector observable, para llegar a una estructura probabilística simplificada y aceptable del mismo. Los supuestos en cuestión se refieren a: 1) la distribución (normal, t de Student, logistica, etc.), 2) la dependencia (propiedad de Markov (p), martingala, ergodicidad, etc.) y 3) la heterogeneidad (idéntica distribución, estacionariedad estricta, estacionariedad de orden k, etc), de dicho vector.
Respecto al supuesto de distribución Haavelmo señaló: Since the assignment of a certain probability law to a system of observable variables is a trick of our own, invented for analytical purposes, and since the same observable results may be produced under a great variety of different probability schemes, the question arises as to which probability law should be chosen, in any given case, to represent the ‘true’ mechanism under which the data considered are being produced. To make this a rational problem of statistical inference we have to start out by an axiom, postulating that every set of observable variables has associated with it one particular ‘true’, but unknown, probability law (Haavelmo, 1944, p. 49).
Haavelmo fue consciente de que las características de dependencia y heterogeneidad exhibidas por las variables económicas (principalmente series de tiempo de macroeconomía) eran fuente de correlaciones (regresiones) espurias, tal como lo evidenció Yule (1926).11 Sin embargo, él estaba completamente convencido de que tales características de las variables económicas, sólo podían ser captadas mediante un modelo estadístico rigurosamente formulado en la teoría de la probabilidad, específicamente en la distribución conjunta del proceso estocástico observable mediante los datos (véase Haavelmo, 1943a y 1944).
Siguiendo el enfoque probabilístico, la adopción de tales supuestos se convierte en un problema de inferencia estadística que debe ser contrastado estadísticamente con los datos observados: “We make hypothetical statements before we draw the sample, and we are only concerned with whether the sample rejects or does not reject an a priori hypothesis” (Haavelmo, 1944, p. 70).
Así, el diseño de experimentos de Haavelmo vía la distribución conjunta del vector observable coincide con una primera aproximación del proceso generador de datos, pgd, cuando los datos son observaciones pasivas de la realidad.12 No obstante, en la práctica este proceso es desconocido y debe ser determinado a partir de la información disponible, es decir, del conjunto de variables observadas para el análisis de acuerdo a alguna teoría económica, de todos los términos determinísticos asociados, del conocimiento institucional y de la evidencia anterior. Por lo tanto, el éxito de los modelos empíricos para recoger toda la información del fenómeno de interés depende de la especificación del modelo estadístico, que consiste en reconocer ciertas regularidades en los datos y la adopción de supuestos probabilísticos apropiados para captar dichas regularidades.
Para hacer más concretas las observaciones anteriores, considérese el siguiente modelo estadístico:
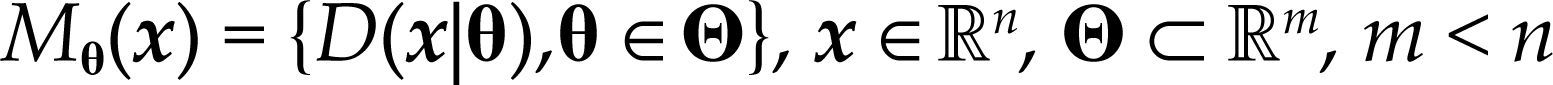
donde Θ denota el espacio paramétrico; ℝn, el espacio muestral; D(x|θ), la densidad conjunta. El modelo Mθ(x) es la parametrización del proceso {Xt, t ∈ ℕ} conociendo los valores de la muestra x, con la estructura de probabilidad elegida. Por ejemplo, para el modelo estadístico conocido como regresión lineal, yt=α+β’xt+ut, t ∈T, su estructura probabilística se presenta en el cuadro 1 usando dos enfoques distintos.
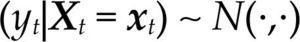
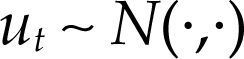
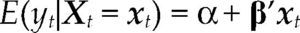
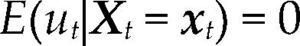
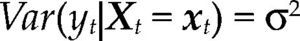
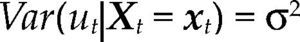
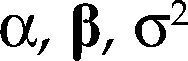
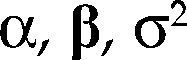
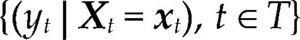
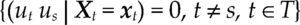
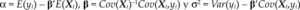
Ahora bien, antes de contrastar las hipótesis acerca del fenómeno de interés con el modelo [1], es necesario verificar que el modelo estadístico satisfaga la lista completa de supuestos probabilísticos subyacentes a la especificación elegida con los datos de la muestra x. Dicha verificación garantiza la confiabilidad de cualquier inferencia basada en el modelo. Nótese que cuando el modelo es incorrectamente especificado, en el sentido que alguno de los supuestos del modelo fue rechazado, entonces la distribución P(·;θ) estará erróneamente especificada para la muestra x e invalidará la distribución de los estimadores, de los estadísticos de prueba y de cualquier estadístico Tn obtenido a partir de D(x|θ).
Supóngase que mediante alguna prueba (test) estadística se encuentra que el modelo [1] está incorrectamente especificado. Pues bien, el modelo se debe de reespecificar, elegir una nueva especificación que considere las regularidades en los datos no explicadas por el modelo incorrectamente especificado, y posteriormente evaluar que los datos, x, no rechazan los supuestos de esta nueva especificación. Este procedimiento se debe de repetir hasta determinar una especificación estadísticamente válida para los datos, a partir de la cual se puedan hacer inferencias confiables.
Debe reconocerse que, a partir del enfoque probabilístico de la econometría, los economistas cuentan con un método analítico formal basado en la teoría de la probabilidad que permite el uso de los métodos estadísticos con el mismo rigor científico que en las ciencias experimentales. Purely empirical investigations have taught us that certain things in the real world happen only very rarely, they are “miracles” while others are “usual events”. The probability calculus has developed out of a desire to have a formal logical apparatus for dealing with such phenomena of real life. The question is not whether probabilities exist or not, but whether —if we proceed as if they existed— we are able to make statements about real phenomena that are “correct for practical purposes” (Haavelmo, 1944, p. 43).
Dicho método consiste en: 1) definir el diseño de experimento que relacione el modelo de teoría económica a los datos en un esquema probabilístico mediante la especificación del modelo estadístico; 2) la verificación de los supuestos estadísticos subyacentes a la especificación, y 3) la reespecificación del modelo con el objeto de establecer un modelo correctamente especificado con el cual contrastar las hipótesis, a fin de establecer conclusiones estadísticamente confiables a la luz de los datos.
A continuación se desarrolla el enfoque probabilístico del modelo de regresión lineal múltiple. En la exposición se enfatiza la razón por la cual cada supuesto del cuadro 1 es necesario en la construcción del modelo y las implicaciones de no cumplirlos.
ENFOQUE PROBABILÍSTICO DEL MODELO DE REGRESIÓN LINEAL MÚLTIPLESupongamos que nos interesa modelar los determinantes del pib en un periodo determinado. Sea la siguiente relación económica de interés:
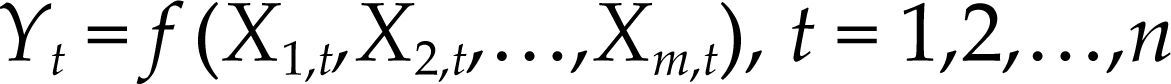
Sea {Zt}t=1n el proceso estocástico que considera todas las variables que suponemos están involucradas en la relación [2], donde Zt :=(Yt,X1,t,X2,t,…,Xm,t), Yt denota la variable dependiente, y Xi,t, i=1,2,…,m denota la i-ésima variable independiente al tiempo t. Enseguida se muestra como el modelo estadístico de regresión lineal múltiple:
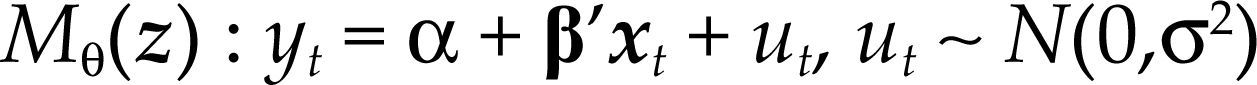
para Z∈ℝn(m+1) con vector de parámetros θ=(α,β,σ2) y bajo los supuestos del cuadro 1, es una parametrización de la densidad conjunta de todas las variables observables del proceso Ztt=1n bajo los siguientes supuestos: distribución normal, independencia e idéntica distribuido, es decir: Zt ∼ NIID (μ,∑), t=1, 2,…,n.
Por el supuesto de independencia e idéntica distribución de Zt, la función de densidad conjunta del proceso es igual a DZ (Z1,Z2,…,Zn;Φ)=∏nt-1D(Z ;ψ) aplicando la definición de probabilidad conjunta se obtiene:
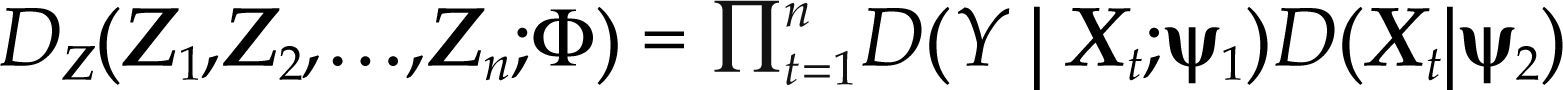
Por el supuesto de distribución normal de Zt, y suponiendo exogeneidad de las variables Xi,t para i=1,2,…,m, es posible ignorar la densidad marginal de Xt=(X1,t,X2,t,…,Xm,t), denotada por D(Xt|ψ2), para hacer inferencia en el espacio paramétrico ψ1 (véanse Spanos, 1986 y Hendry y Nielsen, 2007, cap. 10), entonces:
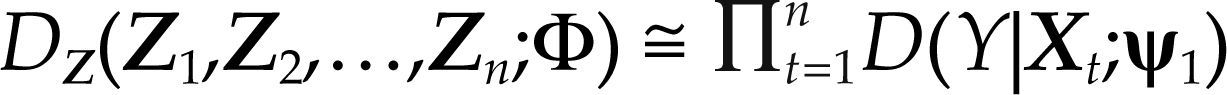
Por el teorema 1 (en Apéndice 1) sabemos que Yt, dados los valores del vector aleatorio Xt=xt, se distribuye como una variable aleatoria normal:
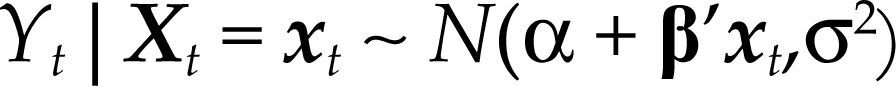
donde α=E(yt)–β’E(Xt), β=Cov(Xt)–1Cov(Xt,yt) y σ2=Var(yt) – β’Cov(Xt,yt).
Este resultado muestra que existe una relación lineal entre Yt y Xt del siguente tipo:
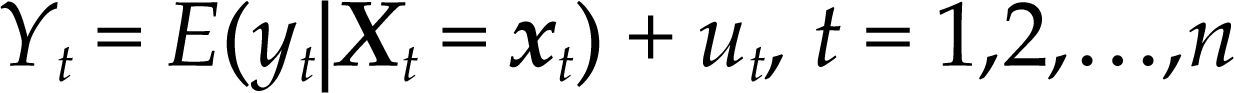
donde el término de error ut=yt – E(yt|Xt=xt) no es autónomo, su estructura probabilística está completamente determinada por [3]. De hecho, los supuestos del modelo estadístico se pueden expresar en términos de ut, como en el cuadro 1.
Como es habitual, para determinar los valores más probables de los parámetros del modelo estadístico θ=(α,β,σ2), cuando el proceso aleatorio Ztn=1n ha sido observado, maximizamos el logaritmo de la función de verosimilitud respecto a θ. Pero, como la función de verosimilitud es la densidad conjunta del proceso observado z=(z1,z2,…,zn) condicionada por θ, entonces:
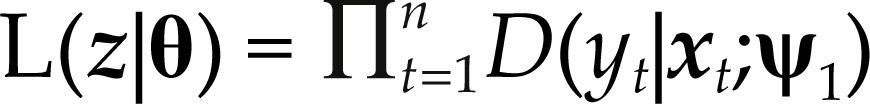
donde D(yt|xt;ψ1) es la densidad normal multivariada dada por [3]. Por lo tanto, las propiedades probabilísticas de los estimadores de máxima verosimilitud, de cualquier estadístico de prueba, y medida de bondad de ajuste, serán completamente determinadas por [3].
Supongamos ahora que Mθ(z), el modelo de regresión lineal, no cumple con alguno de los supuestos probabilísticos del cuadro 1vis-à-vis los datos, entonces D(yt|xt;ψ1) será erróneamente especificada e invalidará las propiedades probabilísticas de cualquier estadístico derivado de ésta. Pues bien, ello implica no sólo que la inferencia estadística, las medidas de bondad de ajuste y los pronósticos realizados a partir del modelo estadístico no sean confiables, sino que el modelo completo estará en tela de juicio como pgd.
El supuesto de la distribución normal de Zt, t=1,2,…,n, es muy importante en este modelo. Nótese que los supuestos 1-3 en el cuadro 1 dependen de éste, sin embargo, también es uno de los supuestos más difícil de cumplir. En Hoover, Johansen y Juselius (2008) y Hoover y Juselius (2012) se argumenta que la hipótesis de normalidad multivariada de los datos económicos no es una característica que esperamos que se cumpla, más bien es una hipótesis que nos permite asegurar que hemos considerado tanto los eventos usuales, que son adecuadamente descritos por la distribución normal, como los milagros,13 que tienden a caer fuera del rango de la distribución normal. Tales eventos extraordinarios, frecuentemente son la causa de asimetría o exceso de curtosis y, por tanto, del rechazo del supuesto de normalidad de ut. Es decir, la falta de control adecuada de este tipo de eventos puede ser la causa de autocorrelación entre los errores, de sesgo en los estimadores y de imprecisión en las inferencias.14
Del supuesto de normalidad también depende la linealidad, en variables y parámetros, del modelo estadístico. Por ejemplo, en un modelo donde se supone que el PIB es una función lineal de un conjunto de variables del tipo PIB=aer+bω (donde a y b son parámetros, er es el tipo de cambio real y ω es la participación salarial), si encontramos que el supuesto de normalidad no se cumple, la forma funcional del modelo también será cuestionada.
Para Haavelmo, el término de error debe captar todos los factores que influyen en el fenómeno que no fueron considerados por el modelo empírico, y dada la complejidad de la economía real, estos factores debían de ser muchos respecto a los considerados. De modo que si tales factores son independientes, los errores podrían distribuirse aproximadamente como variables aleatorias normales por el teorema del límite central: if we consider a set of related economic variables, it is, in general, not possible to express any one of the variables as an exact function of the other variables only. There will be an “unexplained rest,” and, for statistical purposes, certain stochastic properties must be ascribed to this rest, a priori. (…) For the necessity of introducing “error terms” in economic relations is not merely a result of statistical errors of measurement. It is as much a result of the very nature of economic behavior, its dependence upon an enormous number of factors, as compared with those which we can account for, explicitly, in our theories. We need a stochastic formulation to make simplified relations elastic enough for applications (Haavelmo, 1943b, p. 1).
El supuesto de independencia de Zt, t=1,2,…,n, en el proceso observable de variables económicas, también ha sido cuestionado (supuesto 4 del cuadro 1); de hecho, es muy frecuente observar que el proceso Zt=1n muestra algún tipo de dependencia. Por ejemplo, si Zt=1n cumple la propiedad de Markov, P(zt|zt–1, zt–2,…, z0)=P(zt|zt–1) es necesario incluir a zt–1 como regresor en la especificación del modelo para dar cuenta de este tipo de dependencia.
El supuesto de idéntica distribución de Zt, t=1,2,…,n, es difícil de cumplir, principalmente en variables macroeconómicas, donde la heterogeneidad de estas variables induce que tanto la esperanza como la matriz de varianzas y covarianzas del proceso observable sean función de t. Es decir, el proceso Zt=1n no es estacionario. Por ejemplo, los modelos integrados y cointegrados surgen cuando se sustituye el supuesto de variables idénticamente distribuidas por el de variables estacionarias de segundo orden.
Así pues, la única estrategia correcta para conseguir inferencias válidas y confiables es adoptar un modelo estadístico cuyos supuestos probabilísticos sean válidos vis-à-vis los datos antes de realizar cualquier inferencia. Esta es la razón por la cual todo artículo de investigación de economía aplicada, cuyo propósito sea explicar la realidad tal como se manifiesta frente a nosotros, por medio de métodos estadísticos, debe presentar de manera clara y precisa: 1) el diseño de experimento, en el sentido de Haavelmo, propuesto como pgd del fenómeno objeto de la investigación, y sobre el cual se probaron las hipótesis (teóricas), y 2) los resultados de las pruebas de incorrecta especificación, es decir, de las pruebas que evalúan el cumplimiento de los supuestos probabilísticos de las metodologías estadísticas empleadas vis-à-vis los datos.
En la siguiente sección se describe y analiza el segundo requisito importante para que exista rigor científico en nuestra disciplina. Nos referimos a la posibilidad de que otro investigador pueda reproducir (repetir exactamente los procedimientos con los mismos datos) los números reportados en artículos publicados. Lo cual es importante, porque es lo único que un investigador puede garantizar de un estudio, ya que no puede garantizar que las afirmaciones hechas son correctas, a menos que sean puramente descriptivas. En última instancia, el tiempo nos dirá si las conclusiones de una investigación fueron correctas o incorrectas, pero lo que sí podemos saber en este momento es si los números sobre los cuales se realizaron dichas conclusiones se pueden recalcular o no.
REPLICACIONES EN LA ECONOMÍAAún no hay un consenso en la literatura sobre la definición de replicación. Algunas propuestas y debates se pueden consultar en Collins (1991), Cartwright (1991), Lindsay and Ehrenberg (1993), Hamermesh (2007), Clemens (2015), Zimmermann et al. (2015) entre otros.
Hamermesh (2007) define replicación pura como hacer algo otra vez exactamente en la misma forma. En investigaciones económicas implica examinar la misma pregunta, modelo y base de datos que la investigación original. Cuando se utiliza diferente muestra, diferente población y, quizá, un modelo similar, pero no idéntico, se define como replicación científica.
La definición de Zimmermann et al. (2015) comprende tanto el concepto de replicación pura como el de replicación científica. Una replicación es repetir un estudio previo para verificar su validez (verificación). Lo cual podría hacerse con los datos y el código computacional originales, pero también podría realizarse con otra muestra de los datos originales (reproducción) o con nuevos datos o con un código computacional similar al que se usó originalmente (robustez). Una definición más amplia implica usar nuevos datos (diferente periodo, geografía); una solución diferente o método de aproximación o un nuevo enfoque estadístico (extensión).
Para el Journal of Applied Econometrics (jae) (Pesaran, 2003) la replicación en un sentido estricto implicaría la comprobación de los datos presentados contra las fuentes primarias (cuando se aplique) para la consistencia y exactitud, la comprobación de la validez de los cálculos, ya sea directamente o mediante la realización de la estimación (incluyendo el cálculo de los errores estándar) usando otro software. La replicación en un sentido amplio supone que la replicación en sentido estricto ha sido un éxito, y cuestiona si el hallazgo empírico de fondo del artículo puede ser replicado con datos de otros periodos, países, regiones u otras entidades, según proceda.
De estas definiciones se reconocen dos tipos de replicaciones, aquellas cuyo objetivo es reproducir los números reportados en un estudio previo, usando los mismos datos y procedimientos, y aquellas que buscan establecer la solidez (robustness) de los resultados. Ambos tipos de replicaciones son muy importantes en economía, las primeras constituyen la mejor manera de establecer la validez de los cálculos, mientras que las segundas prueban la generalización de resultados y/o regularidades empíricas documentadas en los artículos originales.
Recientemente The Replication Netword,15 organizada por Maren Duvendack y W. Robert Reed, definió un estudio de replicación como: cualquier estudio, cuyo objetivo principal sea establecer la exactitud de un estudio previo. Esta definición más general, y por lo tanto más incluyente, parece más adecuada porque reconoce como replicaciones a los ejercicios donde podría haber subjetividad. Es decir, replicaciones donde por falta de acceso a bases de datos y códigos de estimación originales (lo cual sucede frecuentemente en economía, véase la siguiente sección), no es posible realizar la replicación estricta. Sin embargo, el autor replicante recurre a las fuentes originales referidas y siguiendo las indicaciones metodológicas publicadas en el artículo, crea la base de datos y códigos de estimación con alguna discrepancia respecto a los originales (periodo, uso de alguna variable proxi, distinto método de estimación) con el objetivo de replicar los resultados originales publicados y obtener un resultado coherente.
En economía, como en cualquier otra ciencia, se deben realizar replicaciones para establecer la fragilidad o solidez de los resultados de investigaciones publicadas que sirvan de guía en el proceso de generación de conocimiento. Además, las replicaciones podrían desincentivar malas prácticas científicas, como señalan Crocker y Cooper (2011) en la Editorial del número especial de la revista Science, titulado Data Replication & Reproducibility: “Scientists generally trust that fabrication will be uncovered when other scientists cannot replicate (and therefore fail to validate) findings” (p. 1182). En este sentido, las replicaciones constituyen un medio que nos provee la información para discriminar entre conclusiones establecidas sobre procedimientos que la propia comunidad económica es capaz de juzgar y verificar, y conclusiones generadas en la opacidad de bases de datos y métodos ocultos.
Un beneficio adicional de realizar replicaciones es la mejor compresión que se adquiere de las ideas de los autores del artículo original cuando se realizan replicaciones. A continuación se describe el actual estado de las replicaciones en economía.
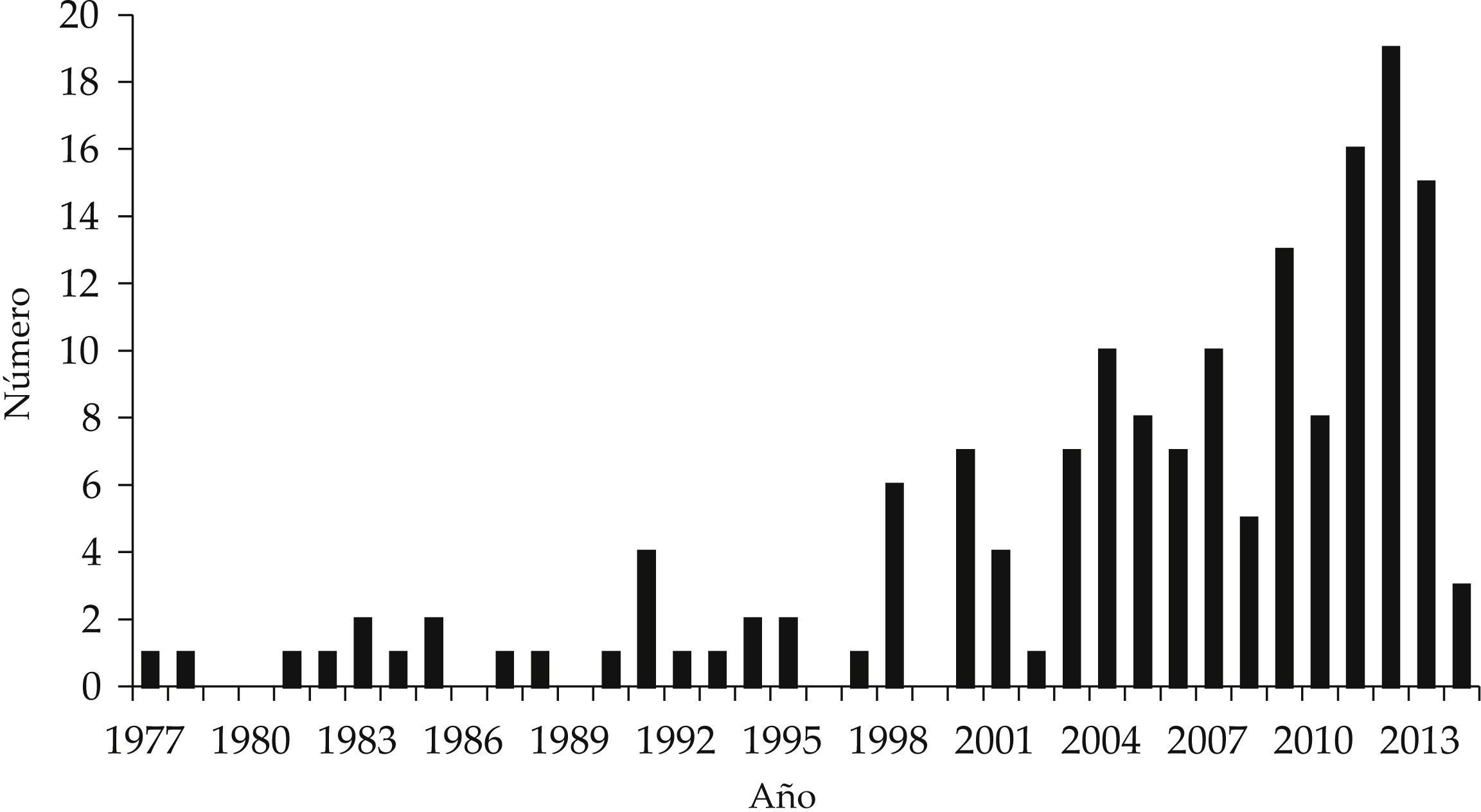
REPLICACIONES DE ESTUDIOS PUBLICADOS EN LAS MÁS IMPORTANTES REVISTAS DE ECONOMÍASegún el reporte sobre las replicaciones en economía de Duvendack, Palmer-Jones y Reed (2015), de 333 revistas de economía (Economics journals) que los autores encontraron listadas en el Thomson Reuters Journal Citation Report en 2013, únicamente:
- •
En veintisiete revistas se puede acceder regularmente (en al menos 50% de los artículos) en línea a los datos y códigos de los artículos empíricos publicados.16
- •
En diez revistas se menciona explícitamente en su sitio web que publican estudios de replicación.17
Estos datos evidencian la escasez de insumos para realizar estudios de replicación de artículos publicados, y la falta de espacios dedicados a la divulgación de los hallazgos de las replicaciones en las principales revistas de economía a nivel internacional
En Duvendack, Palmer-Jones y Reed (2015) también se describe el estado del arte de las replicaciones publicadas en economía, a partir de una muestra de 162 estudios que cumplieron con dos características definidas por los autores para considerar un estudio como un “estudio de replicación”: 1) haberse publicado en una revista peer-reviewed y 2) tener como principal objetivo la replicación de un artículo de investigación.18 De esta muestra, los autores reportan que:
- •
El 59.4% de los estudios de replicación se publicaron en seis revistas: Journal of Applied Econometrics (19.1%), Journal of Human Resources (11.7%), American Economic Review (9.3%), Econ Journal Watch (6.8%), Journal of Development Studies (6.2%) y Experimental Economics (5.6%)
- •
En el 64% de los estudios, la replicación utilizó exactamente los mismos datos, especificación y procedimiento de estimación que el estudio original.
- •
En el 50.5% de los estudios, la replicación incluyó una extensión de los hallazgos originales, por ejemplo mediante la validación de los resultados en distintas economías o periodos de análisis.
Respecto a la confirmación de resultados originales:
- •
En el 66% de los estudios se encontró alguna diferencia significativa respecto al estudio original.
- •
En el 12.3% de los estudios se obtuvo alguna confirmación junto con, al menos, una diferencia significativa de los principales hallazgos del estudio original.
- •
En el 21.3% de los estudios se confirmaron todas las conclusiones principales del estudio original.
Otros importantes estudios que mostraron que en la economía muchas investigaciones empíricas no son replicables fueron el de Dewald, Thursby y Anderson (1986), donde los autores sólo fueron capaces de replicar dos de 54 artículos, y el de McCullough, McGeary y Harrison (2006), donde únicamente se pudo replicar 14 de 62 artículos.
Esta información es evidencia de dos hechos que cuestionan seriamente la transparencia y credibilidad de las investigaciones económicas:
- 1.
La inusual publicación de estudios de replicación entre las principales revistas de economía de acuerdo a su factor de impacto.
- 2.
La alta proporción de estudios de replicación publicados, el 78.3% en el reporte de Duvendack, Palmer-Jones y Reed (2015), donde no se valida al menos alguno de los principales hallazgos de los artículos originales.19
A la luz de esta información vale la pena analizar cuáles son las razones de la escasez de replicaciones en materia económica. Sin lugar a dudas, no es la falta de resultados y conclusiones de relevancia en la economía, de hecho existen suficientes investigaciones dignas de ser replicadas. La evidencia en favor de ello está disponible en el sitio Economics Replication Wiki,20 por medio de un listado de artículos publicados en las principales revistas de economía, para los cuales no existe replicación. Tampoco es porque los estudios de replicación no generen beneficios para la economía como una ciencia, como ya se apuntó en la sección anterior; las replicaciones son una guía para construir conocimiento con base en conclusiones juzgadas y verificadas por la propia comunidad de economistas. En seguida se describen dos de los principales factores que frenan la realización de replicaciones.
ACCESO A BASES DE DATOS Y CÓDIGOS COMPUTACIONALESA pesar de que el interés por proveer las bases de datos que permitieran replicaciones de investigaciones en el campo de la economía data desde 1933, y quedó manifestada en la editorial de Ragnar Frisch del primer número de la revista Econometrica: In statistical and other numerical work presented in Econometrica the original raw data will, as a rule, be published, unless their volume is excessive. This is important in order to stimulate criticism, control, and further studies. The aim will be to present this kind of paper in a condensed form. Brief, precise descriptions of (1) the theoretical setting, (2) the data, (3) the method, and (4) the results, are the essentials (Frisch, 1933, p. 3),
dicha práctica no ha sido seriamente atendida. McCullough, McGeary y Harrison (2006), en el artículo “Lessons from the jmcb Archive”, señalan que en no pocos casos los artículos no pueden ser replicados ni siquiera en principio, porque los autores generalmente no están obligados a hacer disponibles sus datos y el código para su verificación. Incluso cuando tal requisito existe, puede ser (y es) ignorado impunemente.
Previo a la década de los noventa muy pocas revistas contaban con alguna política de acceso a bases de datos y/o publicaron estudios de replicación, tal es el caso de Journal of Human Resources, Journal of Political Economy y Journal of Money, Credit and Banking.
Sin embargo, fue hasta el 2004 cuando, a causa del intento fallido de McCullough y Vinod (2003) por replicar algunos artículos de American Economic Review (aer), el entonces editor de esta revista, Ben Bernanke, fortaleció la política de acceso a bases de datos y códigos computacionales. El cambio consistió en requerir las bases de datos y códigos para correr el modelo final, una descripción de cómo fueron usadas las bases de datos primarias y códigos intermedios para crear la base de datos final de artículos econométricos y de simulación. Desde entonces Econométrica, Journal of Applied Econometris, Journal of Political Economy y Review of Economic Studies han ido adoptando la política de requerir tanto las bases de datos como los códigos de estimación de los artículos publicados para mantenerlos disponibles en su sitio web.
Es cierto que las políticas de acceso a datos y códigos de algunas de las revistas en economía han mejorado considerablemente en las últimas décadas. No obstante, los autores pueden argumentar que sus bases de datos no pueden ser liberadas por motivos de confidencialidad.
PUBLICACIÓN DE ESTUDIOS DE REPLICACIÓNSegún el reporte de Duvendack, Palmer-Jones y Reed (2015), a partir de las políticas editoriales de acceso a datos de la aer, y desde la creación de la sección de replicaciones del jae en enero de 2003, ha habido una mayor disposición a la publicación de estudios de replicación que en años anteriores (véase la gráfica 1). No obstante, a partir de la evidencia mostrada por estos autores aún son muy pocas revistas que explícitamente mencionan en su sitio web que publican replicaciones (véase Duvendack, Palmer-Jones y Reed, 2015, cuadro 2, p. 175), entre las cuales destacan: Journal of Applied Econometrics, que se limita a publicar réplicas de artículos empíricos propios y publicados en nueve de las más prestigiadas revistas de economía;21Econ Journal Watch, una revista en línea de acceso libre y que pone gran énfasis en las replicaciones fallidas. En áreas específicas destacan: Experimental Economics (en simulación) y Empirical Economics. Otras revistas que no figuran en esta lista, pero que también publican replicación son: Journal of Human Resources, American Economic Review, Journal of Development Studies, Applied Economics y Journal of Economic and Social Measuremen.
 Fuente: Duvendack, Palmer-Jones y Reed (2015).")
Base de datos para estimar la ecuación [4], 1955-1996
| E | Tipo de cambio nominal pesos / dólar, promedio del periodo |
| pGDP | Deflactor del pib |
| pT | ipw proxi de precios de mercancías comerciables |
| pN | ipc proxi de precios de mercancías no comerciables |
| ln(er) | =lnpGDPEpGDP* |
| ln(qmx) | =lnpNpT |
| ln(qus) | =lnpN*pT* |
Nota: variables sin (con) asterisco corresponde a México (Estados Unidos).
A partir de 2016, Economics: The Open Access, Open Assessment e-Journal, que desde 2009 tiene una política de acceso a datos, comenzó a aceptar replicaciones de cualquier revista de economía peer-reviewed y de otras fuentes originales (libros y publicaciones gubernamentales) de reconocido impacto para su publicación.
En el caso de las revistas mexicanas de economía, hasta hace menos de un año, ninguna recibía investigaciones de replicación para su publicación. Fue en el segundo trimestre de 2015 cuando la revista Investigación Económica, editada por la Facultad de Economía de la unam, comenzó a aceptar estudios de replicación que confirmen o no los hallazgos de artículos publicados.
La divulgación de los resultados de los estudios de replicación debe dejar de ser infravalorada en la economía. Es cierto que una replicación no amplía la frontera de conocimiento como lo podría hacer un artículo original, pero su importancia radica en evidenciar si las conclusiones establecidas en una investigación lo fueron sobre resultados que no se pueden replicar, o bien, asegurar que la contribución al cuerpo de conocimiento de un artículo está basada en un análisis de datos exitosamente replicable.
A continuación se analizan los incentivos de los editores de revistas para publicar replicaciones, de los autores originales para compartir bases de datos y códigos de estimación y de los autores de estudios de replicación para realizar este tipo de trabajos, que han conducido a la relativa escasez de las replicaciones en la literatura económica.
ACCIONES DE LAS PARTES DE LA PROFESIÓN ECONÓMICA QUE INFLUYEN EN LA REALIZACIÓN Y PUBLICACIÓN DE REPLICACIONESEl editor de una revista tiene como objetivo publicar artículos que por su novedad y relevancia académica mantengan el interés de actuales y nuevos lectores. Con la finalidad de asegurar la credibilidad de la revista, el editor debería tener incentivos para mantener una política de acceso a datos y códigos que faciliten la replicación de los artículos que publica.
Sin embargo, la evidencia muestra que la gran mayoría de las revistas (editores) no están interesadas en que las investigaciones que publican sean replicables. Zimmermann et al. (2015) define el problema como “un dilema del prisionero”. En la carrera por factores de impacto altos, las revistas que dejen de publicar artículos originales por publicar replicaciones podrían devaluar su contenido respecto a las que no publican réplicas, si acaso las replicaciones son menos citadas que los artículos originales.22 Además, siempre correrán el riesgo de publicar replicaciones que contradigan artículos originales previamente publicados. Por estos motivos, muchas revistas incluso son reacias a incluir una sección de replicaciones.
Los autores originales, a sabiendas de que su investigación podría ser objeto de replicaciones y de que les sean solicitados los códigos de estimación de sus modelos econométricos, los archivos de datos originales y de datos subyacentes (trasformaciones), deberían tener mayores incentivos por realizar rigurosos análisis de datos en sus investigaciones. Lo anterior debido a que una replicación fallida podría implicar desde la pérdida de financiamiento o nombramiento hasta el rechazo académico por falta de credibilidad de su investigación. Por lo tanto, la confianza en las bases de datos y códigos que garanticen la replicación exitosa de una investigación debería ser el principal incentivo para hacer públicos estos archivos.
Empero, una práctica común entre los investigadores es obtener mayor provecho posible de una base de datos desarrollada, por lo que con frecuencia éstas no se hacen públicas. Lo mismo ocurre con el código de estimación, ya que el investigador se abre a la crítica acerca de los procedimientos. Es mucho más fácil ocultar todo. Como ha ocurrido hasta ahora, no afecta mucho a la credibilidad porque la mayoría de los investigadores procede de la misma manera (Dewald, Thursby y Anderson, 1986; McCullough, McGeary y Harrison, 2006) debido a que son pocas las revistas que exigen las bases datos y código para que una investigación sea publicada.
Los replicantes encuentran como mayor desincentivo para realizar trabajos de replicación el costo de oportunidad que significa construir las bases de datos y/o el código de estimación del artículo original a replicar, respecto a las investigaciones propias, estudios de posgrado, docencia u otras actividades.
¿Por qué gastar el tiempo en replicaciones si uno tiene ideas propias y datos para probarlas? Considerando que actualmente el reconocimiento académico, los nombramientos y las plazas de investigación están relacionados con el grado académico, el número de investigaciones publicadas, el prestigio de la revista donde se publican los artículos propios y la cantidad de citas que tengan los artículos de un investigador (véase Liebowitz, 2014), y dado que muy pocas revistas publican replicaciones, es más probable que una investigación de conocimiento nuevo sea publicada que una replicación. Por lo tanto, el beneficio académico de realizar estudios de replicación no es muy grande.
A menos que exista la voluntad de todas las partes de la profesión económica (revistas, investigadores, profesores y estudiantes) por acoger el principio de la replicación, las replicaciones seguirán siendo inusuales en la literatura económica. Si nuestro interés es hacer que las investigaciones sean replicables, lo primero que podemos hacer es dar acceso a los datos y códigos de estimación de nuestras investigaciones. Pero esto no es lo único que como comunidad académica podemos hacer. Por ejemplo:
- •
Si usted es árbitro de un artículo en una revista con política de acceso a datos, cuando le pidan dictaminar un artículo de investigación debería verificar los datos y códigos de estimación. Incluso en los casos donde el acceso a éstos le sea negado, cabría la posibilidad de negarse a arbitrar dicha investigación.
- •
Si usted es jurado de un concurso de oposición o de un comité que otorga reconocimientos a la investigación, becas u otras posiciones u honores, antes de emitir su voto sería recomendable que consulte el sitio web de los candidatos, y el de las revistas donde éstos hayan publicado, para verificar el acceso a datos y códigos de estimación de sus investigaciones. Lo anterior, con la finalidad de reconocer en tales promociones u honores a aquellos candidatos que no temen a la replicación de sus investigaciones.
- •
Si usted es investigador, podría dejar de citar artículos no replicables o bien hacer explícito que sus conclusiones podrían no ser confiables debido a que los códigos y datos de cierta investigación no están disponibles.
Ahora bien, con el objetivo de incrementar los incentivos para realizar estudios de replicación:
- •
Si usted es editor de una revista, podría iniciar la publicación de estudios de replicaciones.
- •
Si usted es organizador de conferencias o seminarios, podría incluir exposiciones o alguna sesión de replicaciones.
- •
Si usted es jurado o forma parte de un comité que otorga posiciones o reconocimientos, valore los estudios de replicación que los candidatos hayan realizado.
- •
Si usted es profesor, podría promover la realización de replicaciones entre sus alumnos.
A fin de contribuir con la realización de replicaciones en economía, en la siguiente sección se desarrolla una replicación del artículo “Long run real exchange rates: evidence from Mexico” de Kakkar (2001) publicado en la revista Economic Letters.
UNA REPLICACIÓN DEL ARTÍCULO “LONG RUN REAL EXCHANGE RATES: EVIDENCE FROM MEXICO” (ECONOMICS LETTERS, 2001)La replicación que a continuación se presenta no es una replicación exacta debido a que la base de datos original no es pública,23 y a que se va a emplear un método de estimación distinto al que usó el autor. Sin embargo, dado que se utiliza el mismo periodo de estudio, fuente de datos y especificación de variables que en el artículo original, la replicación podría ser considerada como un estudio que busca confirmar la solidez (robustez) de los hallazgos publicados empleando un método de estimación distinto.
El objetivo de la investigación de Kakkar (2001) fue determinar si los cambios en los precios relativos de las mercancías no comerciables pueden explicar los cambios persistentes del tipo de cambio real bilateral entre México y Estados Unidos a lo largo del periodo 1955-1996. La conclusión de la investigación es que existe una relación de cointegración entre el tipo de cambio real y los precios relativos de mercancías no comerciables a comerciables de México y de Estados Unidos que confirma su hipótesis.
La modelación de Kakkar (2001) parte del hecho estilizado de que el tipo de cambio real es no estacionario, así como de los siguientes supuestos:
- 1.
El tipo de cambio real se define con índices de precios generales (deflactor del pib) mediante la siguiente ecuación:
donde E denota el tipo de cambio nominal (pesos por un dólar), y el índice general de precios en cada país se define como el promedio geométrico de los precios de mercancías comerciables (pT) y no comerciables (pN) ponderados por un factor α, según la siguiente ecuación: pGDP=cGDP[pT]α[pN](1–α). Las variables de Estados Unidos se denotan con el superíndice *.
De acuerdo a la definición de Kakkar (2001), un incremento (decremento) de er equivale a una apreciación (depreciación) real del peso respecto al dólar.
- 2.
Se supone que en el largo plazo se cumple la paridad de poder de compra (ppp por sus siglas en inglés, Purchasing Power Parity) en mercancías comerciables, es decir:
donde u es una variable aleatoria estacionaria con media cero, lo cual implica que un choque en el precio de mercancías comerciables en un país que desvíe al tipo de cambio real de la condición de ppp se desvanecerá con el tiempo.
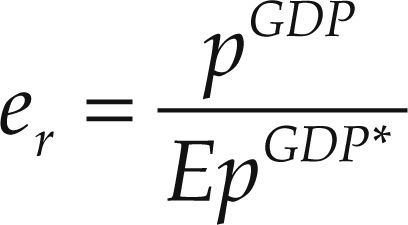
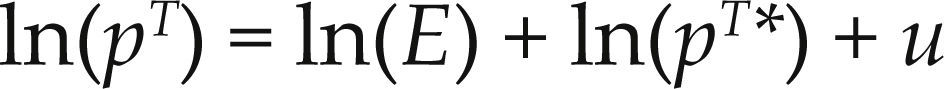
De los supuestos 1 y 2, el tipo de cambio real (tcr) se puede escribir de la siguiente manera:
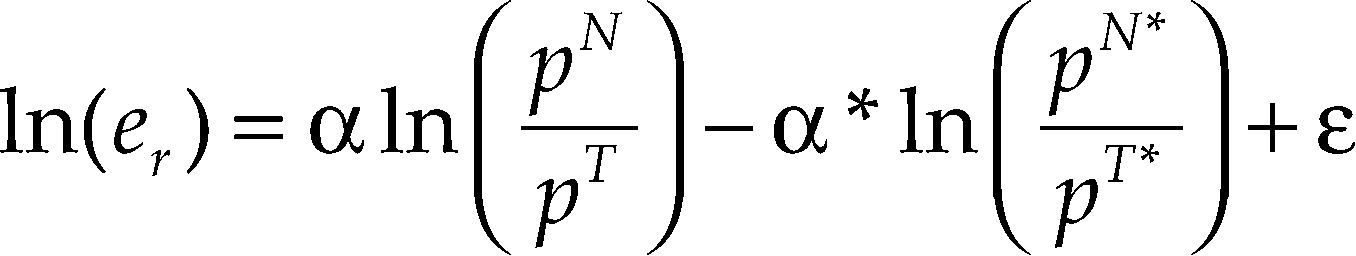
donde ¿=ln(cGDP) – ln(cGDP*)+u. En esta ecuación se observa que la dinámica del tcr depende de la dinámica de los precios relativos (no comerciables a comerciables) internos y externos. En la cual un incremento de los precios internos de los bienes no comerciables respecto a los comerciables conduce a una apreciación real, y un incremento de los precios externos de los bienes no comerciables respecto a los comerciables conduciría a una depreciación real.
Si ln(pN/pT) y ln(pN*/pT*) son integrados de orden uno y se cumple la PPP en las mercancías comerciables en el largo plazo, entonces las variables ln(er), ln(pN/pT) y ln(pN*/pT*) deberían de cointegrar con vector de cointegración igual a (1, –α, α*). Por lo tanto, para estimar los coeficientes de la ecuación [4] es necesario que se satisfaga la hipótesis de raíz unitaria, lo que permitirá, posteriormente, probar la hipótesis de cointegración de las variables.
Para estimar la ecuación [4] en el periodo de análisis 1955-1996, el autor utilizó el índice de precios al mayoreo (ipw) y el índice de precios al consumidor (ipc) como variables proxi de los precios de mercancías comerciables y no comerciables respectivamente.24 La validación empírica se realizó con datos anuales del Fondo Monetario Internacional (fmi), específicamente del CD-ROM de las International Financial Statistics (ifs) [Estadísticas Financieras Internacionales, efi] (imf, 2015). Según lo indicado en Kakkar (2001), las tres variables involucradas en la ecuación [4] se especifican como en el cuadro 2, pero no se indica el año base de los índices de precios.
Los resultados de las pruebas de raíces unitarias en Kakkar (2001) no rechazan la hipótesis de raíces unitarias de las variables ln(er), ln(qmx) y ln(qus) con las pruebas Dickey-Fuller aumentada (adf) (Dickey y Fuller, 1979) y Philips-Perron (pp) (Phillips y Perron, 1988) al 90% de confianza.
La hipótesis de cointegración fue probada mediante una regresión de cointegración canónica (véanse Park, 1992, Ogaki, 1993 y Ogaki y Park, 1997) estimada en el paquete ccr de Gauss desarrollado por Ogaki (1993). Kakkar (2001, p. 83), con base en sus estimaciones publicadas en el cuadro 2 (reproducida en el Apéndice 2), concluye que a los niveles de significancia convencionales no se rechaza la hipótesis de cointegración estocástica con los estadísticos H(0,2) y H(0,3), y tampoco se rechaza la hipótesis de cointegración determinística con la estadística H(0,1). Asimismo, el autor señala que los coeficientes estimados de la ecuación [4], α=3.731 y α*=–1.163, están de acuerdo a lo esperado en la teoría, en signo y magnitud, y son estadísticamente significativos.
Sin embargo, el autor no reporta los estadísticos o valores p (p-values) de las pruebas de significancia ni la distribución de los estadísticos de prueba ni los niveles de confianza empleados en las pruebas de significancia. Tampoco reporta ninguna prueba de incorrecta especificación asociada al modelo.
RESULTADOS DE LA REPLICACIÓNLa replicación de la investigación de Kakkar (2001) consiste en realizar pruebas de raíces unitarias y de traza que permitan determinar el rango de cointegración del sistema xt=(ln(ert), ln(qmxt), ln(qust)) en el mismo periodo de estudio del artículo de Kakkar, 1955-1996 (t=1,2,…,42), a fin de estimar los coeficientes de la ecuación [4].
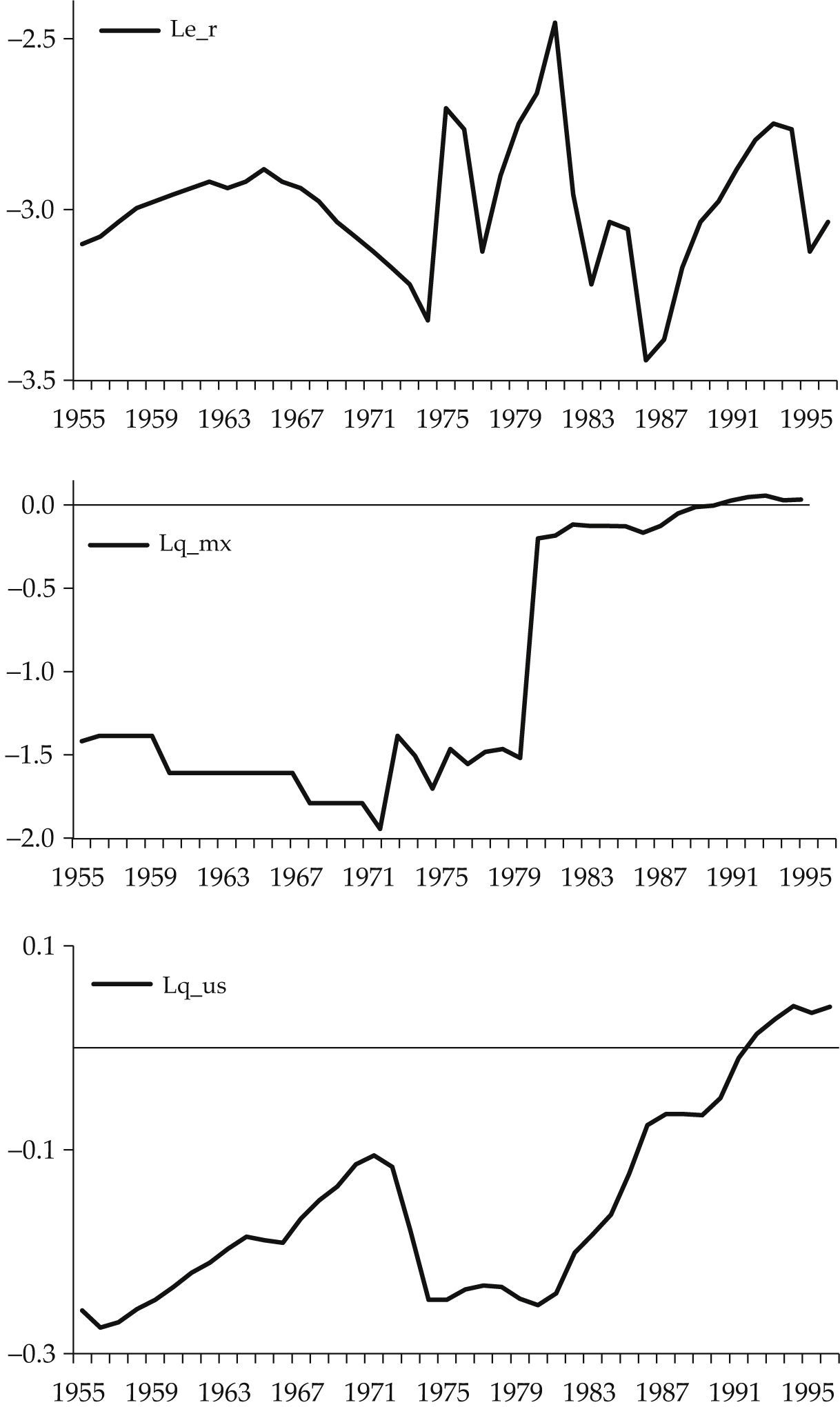
La base de datos fue construida usando la misma especificación de las variables que el autor uso (véase el cuadro 2). La única diferencia es que los datos provienen de la edición de 2015 de las ifs, donde los índices de precios usan como base al año 2000. En la gráfica 2 se muestran las series de tiempo de las variables ln(er), ln(qmx) y ln(qus).
.")
Además de las pruebas de raíces unitarias reportadas en Kakkar (2001), en la replicación se muestran los resultados de las pruebas Kwiatkowski, Phillips, Schmidt y Shin (KPSS) (Kwiatkowski et al., 1992) y la Zivot-Andrews Z-A (Zivot y Andrews, 2002). Ésta última debido a que la serie de tiempo de la variable ln(qmx) presenta un cambio permanente en el nivel de la serie para 1981.
A diferencia de la metodología econométrica utilizada en Kakkar (2001), en la replicación el análisis de cointegración fue realizado con la metodología de Johansen (1988), descrita en Juselius (2006), y las estimaciones se realizaron en PcGive. A partir de un var(k) correctamente especificado para el vector xt=(ln(ert), ln(qmxt), ln(qust)), la hipótesis de cointegración se contrasta con la prueba de la traza, y la identificación del vector de cointegración (β) se realiza en el modelo corrector de errores que representa al var(k) restringido por el rango de cointegración:
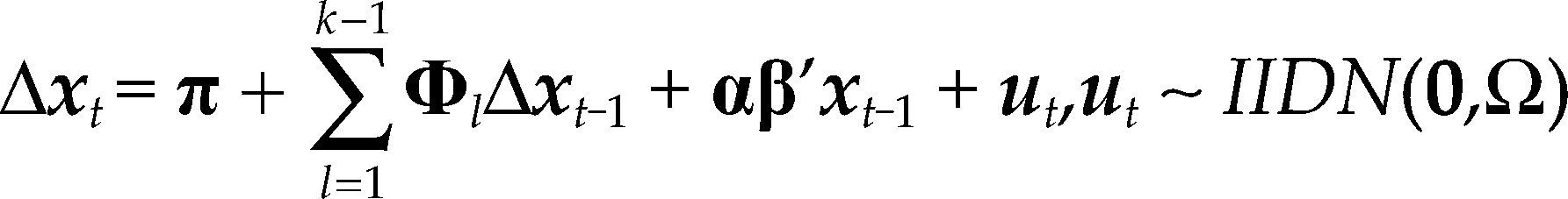
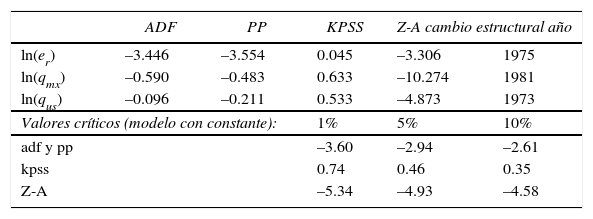
En el cuadro 3 se muestran los resultados de las pruebas de raíces unitarias en el periodo 1955-1996.25 A continuación se comentan los resultados para cada variable.
Pruebas de raíces unitarias 1955-1996 (modelo con constante)
| ADF | PP | KPSS | Z-A cambio estructural año | ||
|---|---|---|---|---|---|
| ln(er) | –3.446 | –3.554 | 0.045 | –3.306 | 1975 |
| ln(qmx) | –0.590 | –0.483 | 0.633 | –10.274 | 1981 |
| ln(qus) | –0.096 | –0.211 | 0.533 | –4.873 | 1973 |
| Valores críticos (modelo con constante): | 1% | 5% | 10% | ||
| adf y pp | –3.60 | –2.94 | –2.61 | ||
| kpss | 0.74 | 0.46 | 0.35 | ||
| Z-A | –5.34 | –4.93 | –4.58 | ||
La variable ln(er) rechaza la hipótesis de raíz unitaria al 5% de significancia, pero no al 1% con las pruebas adf y pp, con la prueba kpss no existe evidencia estadística suficiente para rechazar la hipótesis de estacionariedad de ln(er). No obstante, la prueba Z-A no rechaza la hipótesis nula de raíz unitaria que excluye cambio estructural. De acuerdo a esta información, se concluye que hay evidencia suficiente en favor de la no estacionariedad del tcr para el periodo 1955-1996.
La variable ln(qmx) no rechaza la hipótesis de raíz unitaria con las pruebas adf y pp a los niveles de significancia usuales, con la prueba kpss rechaza al 5% de significancia la hipótesis de estacionariedad. Sin embargo, la prueba Z-A rechaza al 99% de confianza la hipótesis nula de raíz unitaria, lo que implica que ln(qmx) es estacionaria con cambio estructural para 1981, lo cual parece evidente del comportamiento descrito en la gráfica 2. En resumen, a pesar que las pruebas adf, pp y kpss encuentran evidencia estadística a favor, ln(qmx) ∼ I(1), la conclusión de la prueba Z-A, ln(qmx) ∼ I(0), es la adecuada, puesto que, como Perron (1989) mostró, la potencia de las pruebas adf y pp para rechazar una raíz unitaria disminuye cuando la hipótesis alternativa (la variable es estacionaria) es verdadera y se ignora un cambio estructural.
La variable ln(qus) presenta raíz unitaria, puesto que las pruebas adf y pp no rechazan esta hipótesis, la prueba KPSS rechaza al 5% la hipótesis de estacionariedad y la prueba Z-A no rechaza al 5% de significancia la hipótesis de raíz unitaria sin cambio estructural.
La conclusión final acerca de la heterogeneidad de los datos en el periodo 1955-1996 es que: ln(er) ∼ I(1), ln(qmx) ∼ I(0) y ln(qus) ∼ I(1). A consecuencia de ello, el análisis de cointegración del vector xt=(ln(ert), ln(qmxt), ln(qust)) es inadecuado.
Sólo con la finalidad de observar el resultado del análisis de cointegración de la ecuación [4], se ignorará el resultado de la prueba Z-A para ln(qmx).
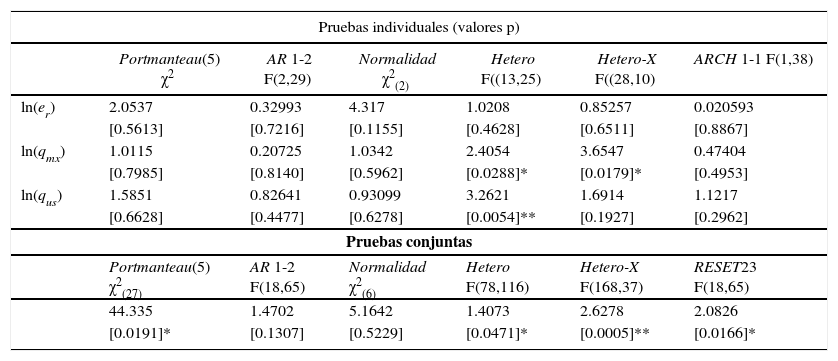
La especificación del modelo var(2) para el vector xt=(ln(ert), ln(qmxt), ln(qust)), en el periodo 1955-1996 (t=1,2,…,42), incluye término constante; una variable dummy de impulso en 1973, D1973 (toma el valor de uno 1973, cero en otro caso), y una variable dummy de cambio en 1981, S1981 (toma el valor de uno en el periodo 1955-1980, cero en cualquier otro caso). El modelo cumple con los supuestos probabilísticos del modelo estadístico, según se observa en las pruebas de incorrecta especificación del cuadro 4.26
Pruebas de incorrecta especificación del var(2) en el periodo 1955-1996
| Pruebas individuales (valores p) | ||||||
|---|---|---|---|---|---|---|
| Portmanteau(5) χ2 | AR 1-2 F(2,29) | Normalidad χ2(2) | Hetero F((13,25) | Hetero-X F((28,10) | ARCH 1-1 F(1,38) | |
| ln(er) | 2.0537 | 0.32993 | 4.317 | 1.0208 | 0.85257 | 0.020593 |
| [0.5613] | [0.7216] | [0.1155] | [0.4628] | [0.6511] | [0.8867] | |
| ln(qmx) | 1.0115 | 0.20725 | 1.0342 | 2.4054 | 3.6547 | 0.47404 |
| [0.7985] | [0.8140] | [0.5962] | [0.0288]* | [0.0179]* | [0.4953] | |
| ln(qus) | 1.5851 | 0.82641 | 0.93099 | 3.2621 | 1.6914 | 1.1217 |
| [0.6628] | [0.4477] | [0.6278] | [0.0054]** | [0.1927] | [0.2962] | |
| Pruebas conjuntas | ||||||
| Portmanteau(5) χ2(27) | AR 1-2 F(18,65) | Normalidad χ2(6) | Hetero F(78,116) | Hetero-X F(168,37) | RESET23 F(18,65) | |
| 44.335 | 1.4702 | 5.1642 | 1.4073 | 2.6278 | 2.0826 | |
| [0.0191]* | [0.1307] | [0.5229] | [0.0471]* | [0.0005]** | [0.0166]* | |
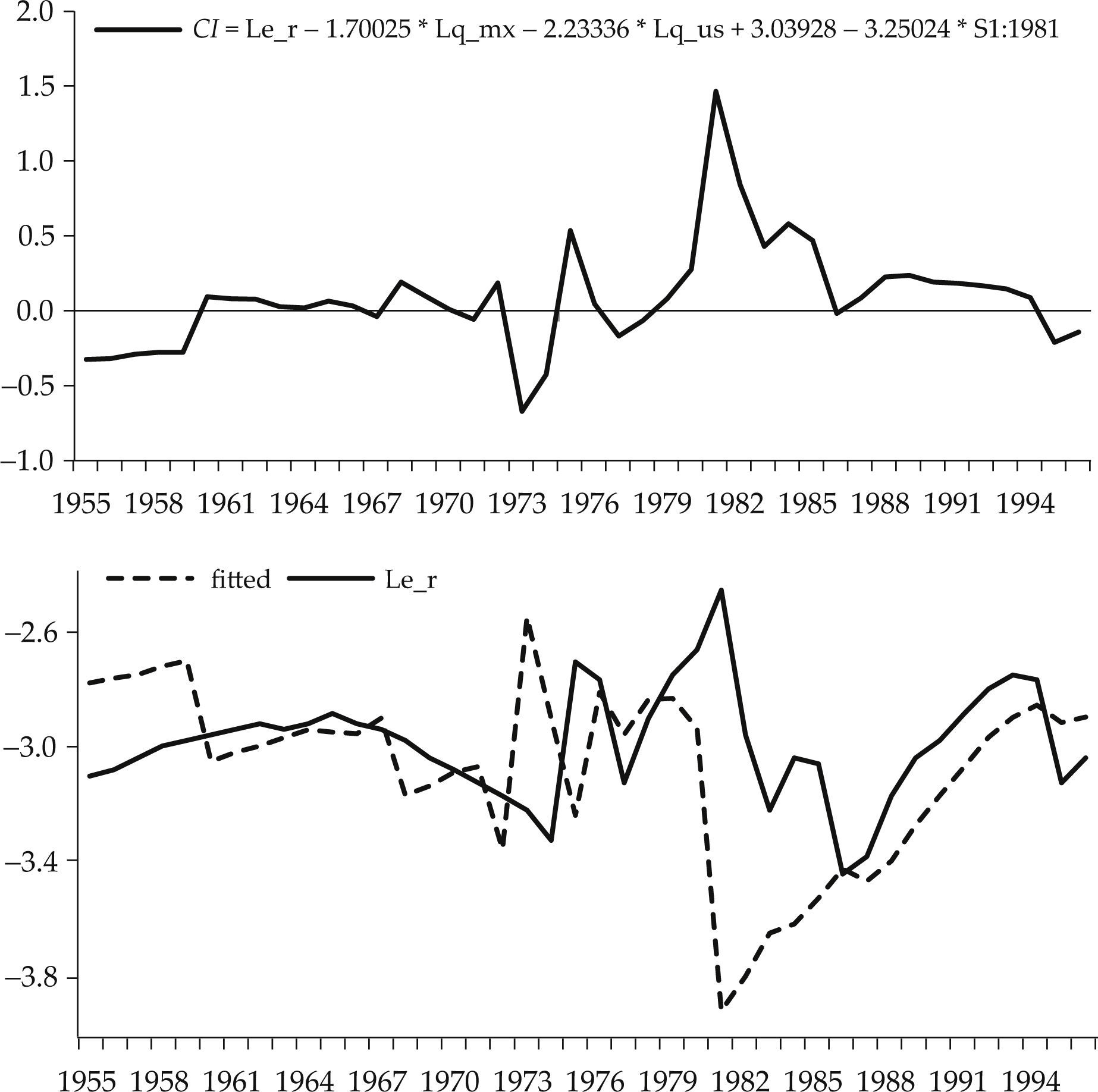
La prueba de la traza (véase el cuadro 5) determinó el rango de cointegración del sistema en r=1, lo cual implica que existe una combinación lineal estable, β’xt, denominada también relación de largo plazo o de cointegración, entre las variables del sistema cuya solución para ln(er) se interpreta como la relación de equilibrio de largo plazo del tcr, y está dada por la siguiente ecuación:27
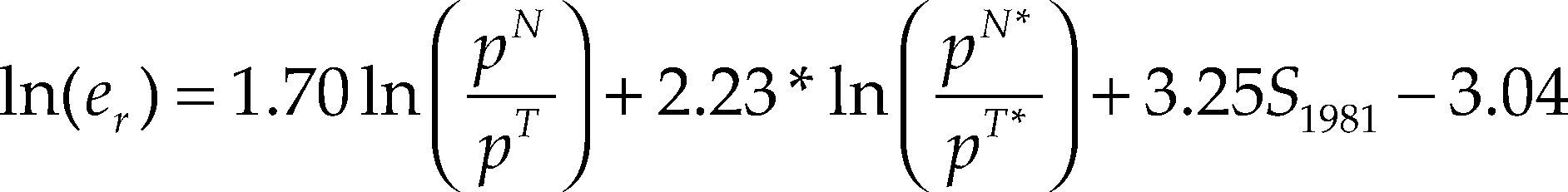
La principal diferencia respecto al resultado que Kakkar (2001, p. 83) reporta en el cuadro 2, es que en la relación de cointegración estimada por el método de Johansen la variable dummy de cambio (S1981)28 es estadísticamente significativa (véase el cuadro 6) y el signo estimado de los precios relativos de las mercancías no comerciables respecto a las comerciables en Estados Unidos es incorrecto, puesto que éste debía ser negativo de acuerdo al marco teórico que sirve de fundamento al estudio del autor.
En la gráfica 3 se muestra la relación de cointegración dada por β’xt y el tipo de cambio real de largo plazo estimado mediante el análisis de cointegración dado por [4’].

La evidencia estadística muestra que los resultados reportados por Kakkar (2001) no son robustos al método de estimación. Más aún, las pruebas de raíces unitarias del cuadro 3 muestran que los precios relativos de los no comerciables en México, ln(qmx), para el periodo 1955-1996 son una variable estacionaria con cambio estructural. Esto implica que no se cumple el supuesto que exige el análisis de cointegración29 requerido para el cumplimiento de la hipótesis principal de la investigación:
The main purpose of this paper is to study whether permanent (or persistent) changes in the relative price of nontradable goods can explain the persistent movements of Mexico's real exchange rate. In other words, we test whether the Mexican-US bilateral real exchange rate is cointegrated with the Mexican and US relative price of nontradables. The evidence supports the existence of this cointegrating relationship (Kakkar, 2001, p. 80).
Aunque no resulta indispensable para nuestro trabajo, anotemos aquí que, por ejemplo, Kakkar y Ogaki (1999) refieren argumentos por los cuales el tcr y los precios relativos internos y externos pudieran no cointegrar. En primer lugar, muchos bienes comerciables entre países no son idénticos. También es difícil encontrar bienes comerciables puros porque los bienes comerciables a menudo se combinan con los servicios no comerciables, como los servicios de venta al por menor. Por lo tanto, la ppp no puede mantenerse para estos bienes comerciables en el largo plazo. En segundo lugar, los pesos colocados (en el índice general de precios) en bienes comerciables y no comerciables pueden no ser estables y moverse junto con el tcr. Tercero, las variables proxies, disponibles de los precios relativos de los bienes comerciables y no comerciables, pueden ser aproximaciones pobres de los precios relativos. Probablemente alguno de estos argumentos se aplique al caso del tcr del peso respecto al dólar en el periodo 1955-1996.
REFLEXIONES FINALESEn toda investigación, el autor debe garantizar el análisis de datos sobre el cual establece las conclusiones de su investigación. En economía, los datos representan observaciones pasivas de la realidad, es decir, no hay posibilidad de repetir experimentos en la población objetivo bajo las mismas circunstancias para generar tantas observaciones como deseemos. El enfoque probabilístico de la econometría de Haavelmo establece un conjunto de principios metodológicos para la economía aplicada que permite el uso de métodos estadísticos para evaluar teorías económicas, o hipótesis económicas, contra los datos con todo rigor científico.
Bajo el enfoque de Haavelmo, si suponemos que los datos, de los cuales disponemos, de las variables que intervienen en la relación económica de estudio se pueden considerar como una realización de la distribución conjunta del proceso observable, podemos parametrizar un modelo estadístico haciendo algunos supuestos. Para que las estimaciones de los parámetros y las inferencias realizadas a partir de la distribución conjunta del proceso observable sean estadísticamente válidas, es necesario que los supuestos probabilísticos del modelo estadístico no sean rechazados por los datos, es decir, que el modelo estadístico esté correctamente especificado.
Ahora bien, en la economía, como en cualquier otra ciencia, la generación de conocimiento debe basarse en investigaciones replicadas y replicables. Replicadas, es decir, que un investigador independiente, haciendo uso de los datos originales y el código de estimación original, obtenga (o no) los mismos resultados que fueron reportados en el estudio original. Tales estudios establecen la solidez (o fragilidad) de la investigación en cuestión. Replicables, es decir, de acceso libre a datos y códigos de estimación, para mitigar los altos costos de oportunidad que significa crear las bases datos y códigos de estimación para verificar los resultados y el análisis estadístico de un artículo original.
Me parece que, a menos que exista una fuerte demanda profesional por la transparencia y una voluntad académica por hacer las investigaciones empíricas replicables, las replicaciones en economía seguirán siendo inusuales. Por lo tanto, debemos cambiar algunos comportamientos en aras de hacer replicables los resultados económicos, comenzando por: 1) dar acceso a los datos y códigos de estimación de nuestras investigaciones y 2) crear espacios para la divulgación de tales estudios de replicación.
De no promover la realización y publicación de los estudios de replicación, estamos impidiendo que tales estudios: 1) mediante la verificación, garanticen que la generación de conocimiento en nuestra disciplina esté libre de errores y 2) mediante el uso de conjuntos de datos alternos (distinta definición de variables, distinto periodo de estudio o economía de análisis), métodos de estimación y modelo, doten de solidez y/o extiendan los hallazgos de una investigación publicada.
Teorema. Sea:
donde Y es una variable aleatoria escalar y X es un vector aleatorio p-dimensional,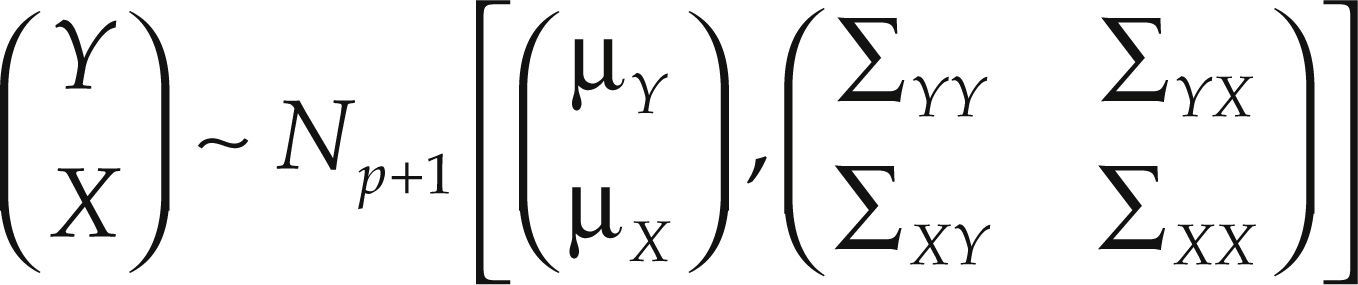
μY=E(Y), μX=E(X), ∑YY=Var(Y)=E[(Y – E(Y))(Y – E(Y))’], ∑XX=Var(X)=E[(X – E(X))(X – E(X))’], ∑YX=Cov(Y,X)=E[(Y – E(Y))(X – E(X))’], ∑XY=Cov(X,Y)=E[(X – E(X))(Y – E(Y))’]=∑’YX y ∑XX es una matriz no singular. Entonces, condicionando sobre X=x, la variable aleatoria (Y|X=x) se distribuye normal con esperanza condicional E(Y|X=x)=α+β’X donde β=∑XX−1∑XYyα=μY−β′μX y con varianza condicional Var(Y|X=x) =−∑YX∑XX−1∑XY Es decir:
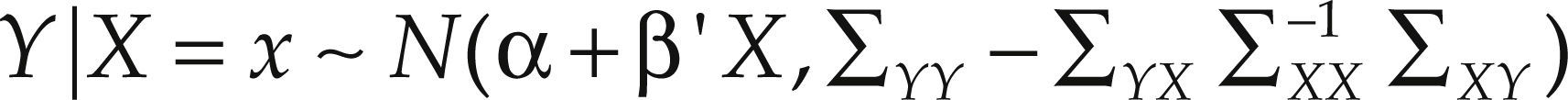
Regresión de cointegración canónica entre el tipo de cambio real y los precios relativos de bienes no comerciables, 1995-1996
| αa/ | α*a/ | H(0,1)b/ | H(0,2)b/ | H(0,3)b/ |
| 3.731 | –1.163 | 1.508 | 0.021 | 0.139 |
| (–0.83) | (–0.428) | (0.219) | (0.885) | (0.933) |
Notas: a/ Errores estándar en paréntesis. b/ p-values en paréntesis. Fuente: Kakkar (2001, cuadro 2, p. 83).
Posgrado en Economía de la Facultad de Economía de la Universidad Nacional Autónoma de México (unam, México). La autora agradece los comentarios y sugerencias del Dr. Julio López Gallardo.
Aunque el desarrollo de la economía experimental está abordado de esta manera los fenómenos económicos por medio de la simulación de eventos.
En el artículo se usan letras mayúsculas para denotar variables aleatorias, los valores observados de éstas se denotan con las letras minúsculas correspondientes. Las letras en formato negrita denotan arreglos de números o variables; las mayúsculas denotan matrices y las minúsculas vectores.
Dicha distribución fue llamada ley de probabilidad por Haavelmo.
Trabajo por el cual Haavelmo recibió el grado de doctor en 1946, y junto a su análisis de estructuras económicas simultáneas lo hicieron acreedor al Premio Nobel de Economía en 1989.
Haavelmo estudió la entonces nueva estadística frecuentista con Neyman en 1936, en Londres, y en 1939, en Berkeley, y con Wald estudió inferencia estadística con muestras heterogéneas y dependientes durante sus estudios en Estados Unidos entre 1939-1944 (véase Spanos, 2015).
La sucesión de n variables aleatorias independientes e idénticamente distribuidas, (X1,X2,…,Xn), se define como muestra aleatoria de tamaño n.
Las variables “verdaderas” (o funciones de tiempo) representan nuestro ideal en cuanto a las medidas exactas de la realidad “como lo es en realidad” (Haavelmo, 1944, p. 5).
Las variables teóricas son las medidas verdaderas que debemos hacer si la realidad estuviera realmente de acuerdo con nuestro modelo teórico (Haavelmo, 1944, p. 5).
Los valores observados, cuando contradicen la teoría, dejan la posibilidad de que estuviésemos pro-bando la teoría en hechos para los que la teoría no estaba destinada a cumplirse (Haavelmo, 1944, p. 7).
En el caso de las variables aleatorias con valores reales, la distribución de una variable aleatoria X queda determinada por su función de distribución PX(x).
El coeficiente de correlación muestral (contemporáneo) entre dos series diferentes {(xt,yt), t = 1,2,…,T} es una medida de dependencia de primer orden significativa sólo cuando las medias de ambos procesos observables son constantes, E(Xt) = μx, E(Yt) = μy, para todo t∈T, de otra forma la medida no tendrá sentido.
Hendry acuñó el concepto de proceso generador de datos local (ldgp) que ofrece un “diseño de experimentos” apropiado, mediante el cual se describen los datos observados de forma pasiva dentro de los más pequeños errores posibles, dada la elección del conjunto de datos (véase Hendry, 2016).
Entre los eventos extraordinarios caben las reformas económicas y, en general, las intervenciones políticas.
Por ejemplo, la autocorrelación en los errores generada al no modelar los cambios en las tasas medias de crecimiento de las variables, puede sugerir el uso innecesario de mayores rezagos en un modelo de vectores autorregresivos (var).
The Replication Network. Furthering the Practice of Replication in Economics. Disponible en: <http://replicationnetwork.com/>.
Información del cuadro 1 de Duvendack, Palmer-Jones y Reed (2015): 1. Agricultural Economics; 2. American Economic Journal: Applied Economics; 3. American Economic Journal: Economic Policy; 4. American Economic Journal: Macroeconomics; 5. American Economic Journal: Microeconomics; 6. American Economic Review; 7. Brookings Papers on Economic Activity; 8. Econometrica; 9. Economic Journal; 10. Econometrics Journal; 11. Economics: The Open-Access; Open-Assessment E-Journal; 12. European Economic Review; 13. Explorations in Economic History; 14. International Journal of Forecasting; 15. Jahrbücher für Nationalökonomie und Statistik/ Journal of Economics and Statistics; 16 Journal of Applied Econometrics; 17. Journal of Labor Economics; 18. Journal of Money, Credit, and Banking; 19. Journal of Political Economy; 20. Journal of the European Economic Association; 21. Quarterly Journal of Economics; 22. Review of Economic Dynamics; 23. Review of Economic Studies; 24. Review of Economics and Statistics; 25. Review of International Organizations; 26. Studies in Nonlinear Dynamics and Econometrics, y 27. World Bank Economic Review.
Información del cuadro 2 de Duvendack, Palmer-Jones y Reed (2015): 1. Econ Journal Watch; 2. Economic Development and Cultural Change; 3. Economics of Education Review; 4. Empirical Economics; 5. Experimental Economics; 6. Explorations in Economic History; 7. International Journal of Forecasting; 8. Jahrbücher für Nationalökonomie und Statistik/Journal of Economics and Statistics; 9. Journal of Applied Econometrics, y 10. Review of International Organizations.
Es importante señalar que el tamaño de muestra se redujo debido a que los artículos no cumplieron con las características señaladas. Inicialmente, los autores seleccionaron una muestra aleatoria de 1 601 artículos de un total de 13 261 identificados mediante la búsqueda de los términos “replicat*” y “Replicate*” en distintas fuentes que, podríamos decir, abarcaron las 50 revistas de economía más importantes respecto al factor de impacto. La búsqueda se realizó en las siguientes fuentes: Google Scholar y Web of Science, “Replication in Economics” wiki (es un proyecto de la Universidad de Gottinger financiado por el Institute for New Economic Thinking que ha reunido en un sitio web (wiki) un gran número de estudios de replicación publicados en revistas de economía), sugerencias de editores de revistas y colecciones de replicaciones de autores.
Es posible que esta proporción esté sobrestimada porque algunas revistas únicamente publican replicaciones fallidas. Para evitar este sesgo, en Duvendack, Palmer-Jones y Reed (2015) también se calculó esta proporción considerando únicamente artículos publicados en el Journal of Applied Econometrics, donde —según Drukker y Guan (2003)— no existe esta discriminación. No obstante, la proporción de replicaciones que no confirman por lo menos alguno de los principales resultados fue del 65%, es decir, aún muy alta.
Disponible en: <http://replication.uni-goettingen.de/wiki/index.php/Category:Study_lacking_replication>.
Econometrica, American Economic Review, Journal of Political Economy, Quarterly Journal of Economics, Review of Economics and Statistics, Review of Economic Studies, Journal of Econometrics, Journal of Business y Economic Statistics Economic Journal.
Aunque también es posible que las revistas que publican replicaciones mejoren sus factores de impacto cuando los estudios de replicación sean mejor valorados por la comunidad de economistas. Es decir, cuando los economistas prefieran investigaciones para las cuales exista algún trabajo donde se haya verificado los cálculos sobre los cuales se fundamentan las conclusiones de los autores originales.
En el artículo de Kakkar (2001) no se menciona que las bases de datos o el código de estimación serán enviados (abiertos) a los lectores que lo soliciten, y la revista Economic Letters no da acceso a ellos.
El autor asume que el ipc se basa en una canasta fija de bienes y servicios consumidos por el hogar promedio, y es probable que tenga una gran participación de los bienes no transables en forma de servicios de venta al por menor, vivienda, transporte y otros servicios. Mientras que, el ipw se limita, generalmente, a los bienes del sector agrícola y manufacturero que son en gran medida comerciables.
Las pruebas de raíces unitarias se realizaron con las rutinas de Eviews 8.
Hendry y Juselius (2001) reconocen que la inferencia estadística de un modelo var es sensible a la validez de los supuestos de parámetros constantes, la no correlación serial y la simetría de la distribución de los errores, mientras que la inferencia se mantiene moderadamente robusta al exceso de curtosis (distribuciones de cola pesadas) y heterocedasticidad de los errores. Por lo que recomiendan asegurar, especialmente, la validez de los tres primeros supuestos.
La relación de equilibrio del tcr de la ecuación [4’] rechaza al 5% de significancia la hipótesis nula de raíz unitaria con la prueba adf con constante, estadístico de prueba τ=– 3.591, valores críticos 5%=–2.94 y 1%=–3.61 de significancia. Este resultado nos lleva a concluir que la relación es estacionaria.
Las pruebas de exclusión se realizaron condicionadas por el orden de cointegración del sistema, es decir, r=1. El estadístico de la prueba del cociente de verosimilitudes lr (Likelihood Ratio) se distribuye asintóticamente como χ2, con un grado de libertad.
La cointegración del conjunto de datos, por ejemplo, xt=(ln(ert), ln(ln(qmxt), ln(qust)) está basado en un supuesto, xt∼I(1).