





El principal objetivo de este trabajo es la construcción de indicadores que permitan agrupar a los individuos con dependencia en función de su situación sociodemográfica, con especial interés por las personas mayores.
Material y métodosA partir de los datos que ofrece la Encuesta de Discapacidades, Deficiencias y Estado de Salud, del Instituto Nacional de Estadística (INE), y mediante técnicas de estadística multivariante y el análisis de supervivencia, se analizan las distintas tipologías de individuos con dependencia. En primer lugar, se determinan cuáles son los factores sociodemográficos que establecen diferencias entre los individuos con dependencia; en segundo lugar, se segmenta la muestra para encontrar grupos de discapacitados con dependencia. Finalmente, se realiza el cálculo de las esperanzas de vida en salud y en dependencia a partir de los 65 años para los grupos de individuos.
ResultadosLas características que mejor diferencian a los individuos con dependencia están relacionadas con el estado civil, los cuidados que reciben, la situación económicalaboral y el nivel de estudios que poseen. Con estos factores se determinan y definen 7 grupos para cada grado de dependencia. Referente a la esperanza de vida en dependencia, las mayores diferencias las encontramos entre los jubilados por edad o por invalidez.
ConclusionesLos perfiles definidos y sus diferencias en esperanza de vida en situación de dependencia ayudan a la planificación de recursos para los cuidados de larga duración y la cuantificación de los costes de la dependencia, así como la creación de sistemas que aseguren que los recursos disponibles se utilizan para disminuir las diferencias entre los grupos de personas con dependencia, incidiendo en la convergencia entre ellas.
The main objective of this study was to construct indicators that would allow individuals with dependence to be grouped, based on their socioeconomic situation, with special interest in the elderly.
Material and methodsData were taken from the Survey of Disabilities, Deficiencies and Health Status (Spanish National Institute of Statistics). The distinct typologies of dependent individuals were analyzed by means of multivariate statistical techniques. Firstly, the factors that best established differences among individuals with dependence were determined; secondly, the sample was segmented to identify disabled individuals with dependence; and finally, healthy life expectancy and dependent life expectancy after the age of 65 years were calculated for the different groups.
ResultsThe characteristics that best defined individuals with dependence were related to marital status, the care received, economic and work situation, and educational level. With these factors, seven groups for each degree of dependence were defined. The greatest differences in dependent life expectancy were found between pensioners who retired due to age and those who retired due to disability.
ConclusionsThe profiles defined and their differences in dependent life expectancy are useful to plan long-term care resources and to quantify the costs of dependency, as well as to create systems that ensure that sufficient resources are used to decrease the differences among the groups of dependent individuals, thus inducing convergence among them.
El motivo de llevar a cabo un estudio como el que presentamos en este artículo tiene su origen en la aprobación de la Ley de Autonomía Personal y Atención a las Personas en Situación de Dependencia, que ha entrado en vigor en España el 1 de enero de 2007. El objetivo de nuestro trabajo es analizar las tipologías sociodemográficas de las personas con dependencia, a partir del análisis de datos mediante las técnicas de la estadística multivariante y el análisis de supervivencia.
No pretendemos dar a conocer cuáles son los esfuerzos que se están llevando a cabo en la concepción y posterior aplicación de la Ley de Dependencia, ya que a este parecer se puede encontrar mucha bibliografía de interés para ahondar en todo lo relacionado con el tema1. En nuestro caso, mediante datos reales y con el uso de la estadística, debemos emplazar la finalidad del estudio en la construcción de indicadores que permitan agrupar a los individuos con dependencia en función de su situación sociodemográfica, haciendo especial énfasis en el caso de las personas mayores. Este análisis permite obtener una imagen más empírica de cuál es la situación de la dependencia en España. Cuestiones como éstas no dejan de ser un tema de interés, tanto a corto como a largo plazo, ya que el envejecimiento progresivo de la población —que también se está empezando a percibir en algunos países de América Latina2— augura que en las próximas décadas se acreciente el número de personas —especialmente mayores— que requieran de asistencia personal, aun en escenarios de disminución de las tasas de prevalencia de las discapacidades3. Por tanto, poder analizar empíricamente la situación sociodemográfica de los individuos con dependencia no debe ni puede ser relegado a un segundo plano, ya que puede corroborar la concepción teórica del asunto4.
Con esta premisa, nos propusimos estudiar cuál es la fotografía de la dependencia en la población española y observar los diferentes grupos que se configuran, a partir de la incidencia que algunos factores tienen en la definición de los colectivos. Para ello, somos conscientes de que cualquier intento de estudio o clasificación de la discapacidad debe estar fundamentado, en primer lugar, en la definición de todos aquellos conceptos que estén involucrados directa o indirectamente y, en segundo término, en la creación de una tipología que permita cuantificar la mayor o menor incidencia de la dependencia en los individuos.
La labor previa realizada por diversos autores u organizaciones pone de manifiesto la extrema complejidad inherente a este tema. Cuestiones tan diversas como que, hasta hace poco, cada Administración desarrollase sus propios sistemas de clasificación y de valoración, adecuándolos a las necesidades de cada momento, y unido a la descentralización administrativa que se ha llevado a cabo, dejan entrever la necesidad de desarrollar unas normativas y un lenguaje común, no sólo de manera local sino también mundial, ya que los procesos de globalización están cada vez más presentes. Además, la homogeneización de un criterio de medición de la dependencia permitiría la comparación entre países5,6.
Así pues, no fue hasta 1980 cuando la Organización Mundial de la Salud (OMS), consciente de esta ausencia de universalidad en los términos, propuso una clasificación general y comprensiva de la disciplina, que va desde una visión de sus orígenes médicos y de la salud hasta sus manifestaciones en los diversos aspectos de la vida. Por primera vez se puso el acento en el entorno físico y social como factor fundamental de la discapacidad. Con esta clasificación, la OMS intenta poner a disposición de Administraciones y de Estados una herramienta que permita simplificar y unificar las terminologías y las diversas escalas de graduación de los problemas relacionados con la discapacidad. Tales consideraciones se recogen en España por el Instituto de Migraciones y Servicios Sociales (IMSERSO)7.
A partir de aquí, pero atendiendo además a los factores sociales y demográficos que rodean a la persona con discapacidad, hemos establecido tipologías, o grupos homogéneos, que describen las distintas clases de individuos con dependencia. A modo de resumen, hemos dividido el trabajo de la siguiente manera. En la primera sección, describimos la base de datos y la metodología utilizada. Concretamente, detallamos cuál fue el proceso de obtención de las muestras y de las variables utilizadas en el análisis, incluida la definición de los tres grados de dependencia propuestos en el Libro Blanco de la Dependencia8 que han inspirado el texto de la Ley. Sobre la metodología, describimos en qué consiste el análisis de coordenadas principales —como técnica estadística adecuada para representar a los individuos cuando la gran mayoría de las variables utilizadas son cualitativas— y el análisis de conglomerados no jerárquico para formar distintos grupos de individuos con el mismo grado de dependencia y distintas características sociodemográficas. Por último, presentamos el método de Sullivan para calcular las esperanzas de vida en salud y en dependencia para los diferentes grupos de individuos. En la segunda sección presentamos los resultados obtenidos con los datos y la metodología utilizada y, finalmente, en la tercera sección, realizamos la discusión de las cuestiones más relevantes.
MATERIAL Y MÉTODOSPara el diseño de la base de datos se ha utilizado información de la Encuesta sobre Discapacidades, Deficiencias y Estado de Salud (EDDES)9 de 1999, realizada por el Instituto Nacional de Estadística (INE)10, el IMSERSO y la Fundación ONCE, a través de la firma de un convenio marco de colaboración para acciones realizadas con el mundo de la discapacidad.
El muestreo utilizado por el INE para la obtención de la muestra es bietápico estratificado, en que las unidades de primera etapa son las secciones censales y las unidades de segunda etapa son las viviendas familiares. En cada vivienda se investiga toda la población residente en ella para identificar a las personas que tienen alguna discapacidad. Dado que los sujetos de la población española residente en hogares familiares no tienen equiprobabilidad de ser seleccionados con el esquema muestral anterior, se introducen ponderaciones (o equivalentemente factores de elevación) para evitar el sesgo en las estimaciones. Debido a la complejidad del diseño, las anteriores ponderaciones deben tenerse en cuenta en el análisis estadístico posterior11.
La encuesta, que cuenta con una muestra de 70.500 viviendas (218.185 individuos en toda España), supone la disponibilidad de información destinada a cubrir las carencias estadísticas sobre los fenómenos de la discapacidad y la dependencia. La EDDES se fundamenta en el marco de la Clasificación Internacional de Deficiencias, Discapacidades y Minusvalías (CIDDM)7. En el cuestionario de la encuesta, y para cada persona del hogar de 6 o más años, se recogían todas las discapacidades que padecía, ya sean independientes o no entre sí. Para cada discapacidad se pedía información al encuestado sobre si persistía en el tiempo y su severidad. Las categorías de discapacidades están relacionadas con la visión (4 actividades), el oído (3), comunicarse (4), aprender, aplicar conocimientos y desarrollar tareas (4), desplazarse (3), utilizar brazos y manos (3), desplazarse fuera del hogar (3), cuidarse de sí mismo (4), realizar las tareas del hogar (5) y relacionarse con otras personas (3). En total, el cuestionario establecía un total de 36 actividades.
En este trabajo, para fijar los grados de severidad de la dependencia, considerando para ello la capacidad de realizar ciertas actividades de la vida diaria, utilizamos el criterio definido por el Libro Blanco. El Libro Blanco antes de definir los grados de dependencia (capítulo 12, p. 6–7) considera sólo las 9 actividades siguientes como actividades básicas de la vida diaria (ABVD): 1) asearse solo, lavarse y cuidar de su aspecto; 2) controlar las necesidades y utilizar el servicio; 3) vestirse, desvestirse y arreglarse; 4) comer y beber; 5) cambiar y mantener las diversas posiciones del cuerpo; 6) levantarse, acostarse y permanecer de pie o sentado; 7) desplazarse dentro del hogar; 8) reconocer personas y objetos y orientarse, y 9) entender y ejecutar órdenes o tareas sencillas.
El modelo de clasificación propuesto por el Libro Blanco considera 3 niveles o grados de dependencia. Así pues, en el grado de mayor gravedad, se situaría la gran dependencia, donde el individuo requiere de ayuda para realizar distintas ABVD varias veces al día y, por su pérdida total de autonomía mental o física, precisa de la presencia continua de otra persona. A continuación, la dependencia severa, donde el individuo requiere de ayuda para realizar varias ABVD 2 o 3 veces al día, pero no precisa de la presencia continua de una persona encargada de su cuidado. Finalmente, la dependencia moderada, en la cual el individuo requiere de ayuda para realizar una o varias ABVD, al menos una vez al día.
De esta manera, el Libro Blanco propone un indicador sintético de la necesidad de ayuda, que tiene en cuenta el número de ABVD y el grado de discapacidad para cada una de ellas. La asignación de puntos permite reflejar la estimación de la gravedad de la discapacidad en las ABVD, donde se asigna 1 punto por la actividad de la cual se presenta una discapacidad moderada, 2 puntos por la actividad de la cual se presenta una discapacidad severa y 3 puntos, por la presencia de discapacidad total en la actividad.
Considerando este criterio de asignación, la puntuación máxima que se puede obtener es de 27 puntos, la cual recaería en un individuo con discapacidad total en las 9 ABVD, mientras que la puntuación mínima será de 2 puntos, ya que la definición de dependencia del Libro Blanco exige la presencia de al menos una discapacidad severa en alguna de las 9 ABVD consideradas. Con estas puntuaciones, la categorización de las personas con dependencia establece que: más de 15 puntos significa gran dependencia, entre 7 y 15 puntos significa dependencia severa y menos de 7 puntos significa dependencia moderada.
Para realizar nuestro trabajo, se ha seleccionado una muestra entre todas aquellas personas que conformaban la base de datos considerada por la EDDES como individuos con dependencia, atendiendo a la definición establecida por el Libro Blanco y descrita en el párrafo anterior. Si bien utilizamos el indicador de dependencia propuesto por el Libro Blanco para seleccionar los individuos con dependencia, conviene señalar que este indicador no es estrictamente para identificar a personas con dependencia, sino para identificar a personas con dependencia a efectos de la Ley de la Dependencia; en particular, no incluye la situación de dependencia ligera. Así pues, la muestra seleccionada no es tanto de personas con dependencia, aunque así nos referiremos en adelante, como un colectivo que presenta condiciones para ser beneficiarios de la Ley de la Dependencia.
Inicialmente, esta muestra está formada por 5.079 individuos. A partir de aquí, la depuración de los datos consiste en eliminar aquellos registros que carecen de información acerca de las variables utilizadas en el análisis. Finalmente, la muestra reúne información válida sobre 3.948 individuos mayores de 5 años y que presentan algún grado de dependencia. Debido a que el número de casos después del proceso de depuración se ve reducido de forma relevante, podemos garantizar la representatividad y ausencia de sesgo de selección en la muestra final, puesto que así lo indican los descriptivos de las variables sobre las que disponemos de toda la información (edad y sexo). Para comprobar que esta reducción de observaciones no afecta significativamente a la representatividad de la muestra original, comparamos algunos estadísticos obtenidos con ambas muestras: depurada y sin depurar. Las únicas 2 variables sobre las cuales se dispone información para los 5.097 casos de la muestra sin depurar son el sexo y la edad de los individuos con dependencia, por tanto, éstas son las 2 variables cuyas distribuciones analizaremos en ambas muestras. Por lo que respecta al sexo, obtenemos que para la muestra sin depurar los porcentajes de varones y de mujeres son del 62,75 y el 37,25%, respectivamente. Para la muestra depurada estos porcentajes pasan a ser el 63,94% de varones y el 36,06% de mujeres. Si realizamos un contraste x2, tomando como distribución
teórica o de referencia la de la muestra sin depurar, obtenemos un valor del estadístico igual a 2,392, que si lo comparamos con la distribución x2 con un grado de libertad no es significativo al 5%. Respecto a la edad, se trata de una variable cuantitativa (medida en años), por tanto, para comparar la distribución de esta variable en ambas muestras (depurada y sin depurar) utilizamos diversos estadísticos básicos. La media de la variable edad para la muestra depurada es de 69,88 años y para la muestra sin depurar es de 68,71 años. Respecto a la dispersión de la variable, obtenemos que las desviaciones típicas son de 248,97 y de 291,18, respectivamente, para la muestra depurada y sin depurar. Los coeficientes de asimetría y curtosis también son muy similares en ambas muestras; sus valores son de −1,44 y 2,53 para la muestra depurada y de −1,31 y 2,38 para la muestra sin depurar. Por último, los cuartiles primero, segundo (mediana) y tercero son, respectivamente, 63, 76 y 84 años para la muestra depurada, y 61, 74 y 82 para la muestra sin depurar. En ambas muestras la moda estimada es de 85. En general, observamos que las distribuciones de la edad en una y otra muestra son muy similares.
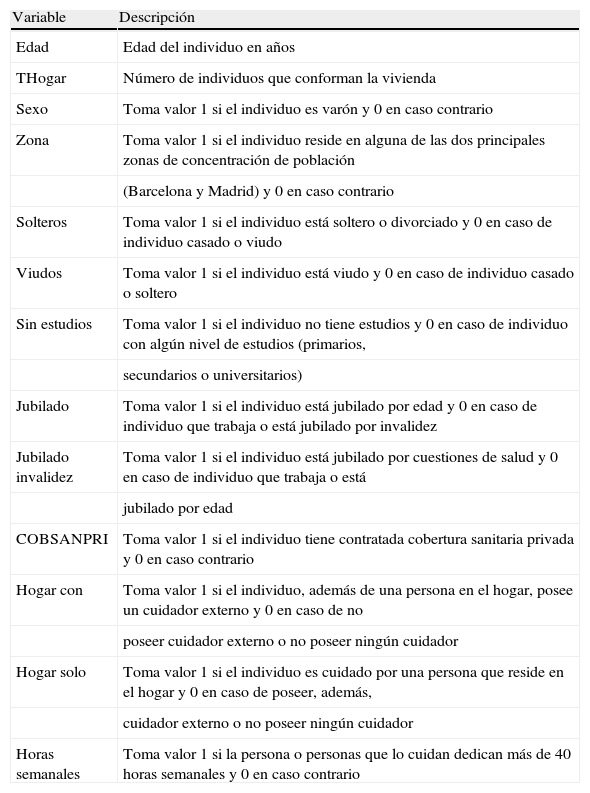
En lo que se refiere a la selección de variables para este análisis, de la mucha información que ofrece la EDDES y después de analizar las respuestas obtenidas en las preguntas incluidas en los diferentes cuestionarios que componen la encuesta, finalmente, tras un proceso de recodificación de algunas de las variables originales, las utilizadas aquí son la edad, el número de individuos que conforman la vivienda, el sexo del entrevistado, la zona de residencia (distinguiendo sólo las principales zonas de concentración y el resto), el estado civil (separando, casados, viudos y resto), el nivel de estudios (si tiene o no), si el individuo se jubiló por edad o por otras causas, si posee cobertura sanitaria privada, si el cuidador reside en el hogar o no y si además dispone de una ayuda externa, y finalmente las horas semanales de cuidados. En la tabla 1 presentamos las variables utilizadas y la métrica para cada una de ellas.
Descripción de las variables
| Variable | Descripción |
| Edad | Edad del individuo en años |
| THogar | Número de individuos que conforman la vivienda |
| Sexo | Toma valor 1 si el individuo es varón y 0 en caso contrario |
| Zona | Toma valor 1 si el individuo reside en alguna de las dos principales zonas de concentración de población |
| (Barcelona y Madrid) y 0 en caso contrario | |
| Solteros | Toma valor 1 si el individuo está soltero o divorciado y 0 en caso de individuo casado o viudo |
| Viudos | Toma valor 1 si el individuo está viudo y 0 en caso de individuo casado o soltero |
| Sin estudios | Toma valor 1 si el individuo no tiene estudios y 0 en caso de individuo con algún nivel de estudios (primarios, |
| secundarios o universitarios) | |
| Jubilado | Toma valor 1 si el individuo está jubilado por edad y 0 en caso de individuo que trabaja o está jubilado por invalidez |
| Jubilado invalidez | Toma valor 1 si el individuo está jubilado por cuestiones de salud y 0 en caso de individuo que trabaja o está |
| jubilado por edad | |
| COBSANPRI | Toma valor 1 si el individuo tiene contratada cobertura sanitaria privada y 0 en caso contrario |
| Hogar con | Toma valor 1 si el individuo, además de una persona en el hogar, posee un cuidador externo y 0 en caso de no |
| poseer cuidador externo o no poseer ningún cuidador | |
| Hogar solo | Toma valor 1 si el individuo es cuidado por una persona que reside en el hogar y 0 en caso de poseer, además, |
| cuidador externo o no poseer ningún cuidador | |
| Horas semanales | Toma valor 1 si la persona o personas que lo cuidan dedican más de 40 horas semanales y 0 en caso contrario |
Para seleccionar las variables que se incluyen en el estudio, hemos tenido en cuenta dos aspectos. El primero, y fundamental, es su relación con las discapacidades y el segundo se basa en la frecuencia de las categorías de las variables originales. Se descartó utilizar la información proporcionada por algunas variables que hubieran tenido cierto interés en el estudio, como es el caso de la nacionalidad de los encuestados o el país de procedencia. Debido a que los individuos extranjeros entrevistados son muy pocos y poseen una frecuencia de respuesta baja, en general, en todas las cuestiones de la encuesta, se decidió prescindir de esas variables. Una situación similar se reproducía en otras categorías, como algunos niveles de estudios y algunas zonas de residencia. Por todo ello, en algunos casos optamos por resumir la información, de modo que se le pudiera sacar el máximo partido posible, en términos de su influencia en la situación de los discapacitados. Por ejemplo, la variable nivel de estudios se ha recodificado en 2 categorías: con y sin estudios. El objetivo es separar a aquellas personas que apenas saben leer y escribir del resto.
Una vez tratado el material utilizado, pasamos a exponer la metodología de este trabajo. El análisis de los datos descritos anteriormente pasa por 3 fases claramente diferenciadas. La primera consiste en determinar cuáles son los factores que mejor explican las diferencias entre individuos con dependencia. Para ello se realiza un análisis de coordenadas principales, método que describiremos posteriormente. En una segunda etapa realizamos la segmentación de la muestra, con el objetivo de encontrar grupos de individuos con dependencia y características similares. Para esta etapa, el método utilizado es el análisis de conglomerados no jerárquicos, también conocido como método k medias. Finalmente, en la última etapa realizamos el cálculo de las esperanzas de vida en salud y en dependencia para distintos grupos de individuos, en función de las variables que mejor explican las diferencias entre ellos. En este caso, utilizaremos el método de Sullivan.
Las dos primeras fases del análisis estadístico, coordenadas principales y segmentación se realizan de forma independiente para cada nivel de dependencia; aun así se observan algunos comportamientos comunes en las distintas submuestras de personas con dependencia: gran dependencia, dependencia severa y dependencia moderada.
El análisis de componentes principales es una técnica de reducción de la dimensión de la base de datos original, que nos podría permitir determinar qué características diferencian mejor a los individuos. Sin embargo, cuando se trabaja con información cualitativa, que en nuestro caso ha sido representada mediante una serie de variables binarias, el análisis de componentes principales es poco robusto ante pequeños cambios en el conjunto de variables binarias utilizadas. Para solventar esta cuestión hemos utilizado una técnica adecuada para el caso en el que la gran mayoría de las variables son binarias y algunas de ellas cuantitativas. Concretamente, nos referimos al análisis de proximidades o multidimensional scaling (MDS)12. Ésta es una técnica multivariante de análisis de datos que permite encontrar una configuración de n puntos en un espacio euclideano, utilizando como información inicial una matriz de similaridades o disimilaridades entre los n puntos.
Cuando el MDS parte de una matriz de distancias euclideanas, Gower13 lo denominó análisis de coordenadas principales, demostrando su estrecha conexión con el análisis de componentes principales. En este trabajo utilizaremos la matriz de coeficientes de similaridad de Gower, cuya transformación a disimilaridades cumple las propiedades de una distancia euclídea. El coeficiente de similaridad de Gower es adecuado cuando en la base de datos existen tanto variables de naturaleza cuantitativa como cualitativa y se obtiene como:
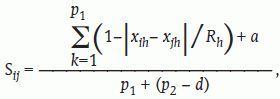
donde p1 es el número de variables cuantitativas, p2 es el número de variables dicotómicas, Rh es el rango de la variable cuantitativa Xh y a y d son el número de dobles presencias y dobles ausencias de las variables dicotómicas.
El análisis de coordenadas consiste en obtener unas nuevas variables que resuman la información original. El objetivo consiste en que con un número reducido de coordenadas podamos representar una parte importante de las diferencias entre individuos. Finalmente, la correlación entre variables originales y coordenadas nos informará de cuáles son las características que mejor diferencian a los individuos con dependencia.
Sea D=(dij) la matriz de distancias o disimilaridades entre los individuos. Consideramos las matrices A=(aij) y B=(bij) de orden n, donde:
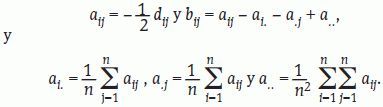
Expresado de forma matricial B=HAH, donde H=In - n-11' es la denominada matriz centradora de datos, siendo In la matriz identidad de orden n y 1 es un vector columna con n unos.
Se cumple que B es una matriz semidefinida positiva de rango r≤n - 1, lo que garantiza que sus valores propios sean≥0. Este resultado permite obtener las coordenadas principales del siguiente modo:
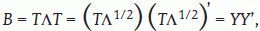
donde T es la matriz de vectores propios de orden n x r y A=diag (λ1, λ2, K, λj.) es la matriz diagonal de r valores propios estrictamente positivos. La matriz Y es de orden n x r y contiene los valores de los individuos en las nuevas variables o coordenadas principales.
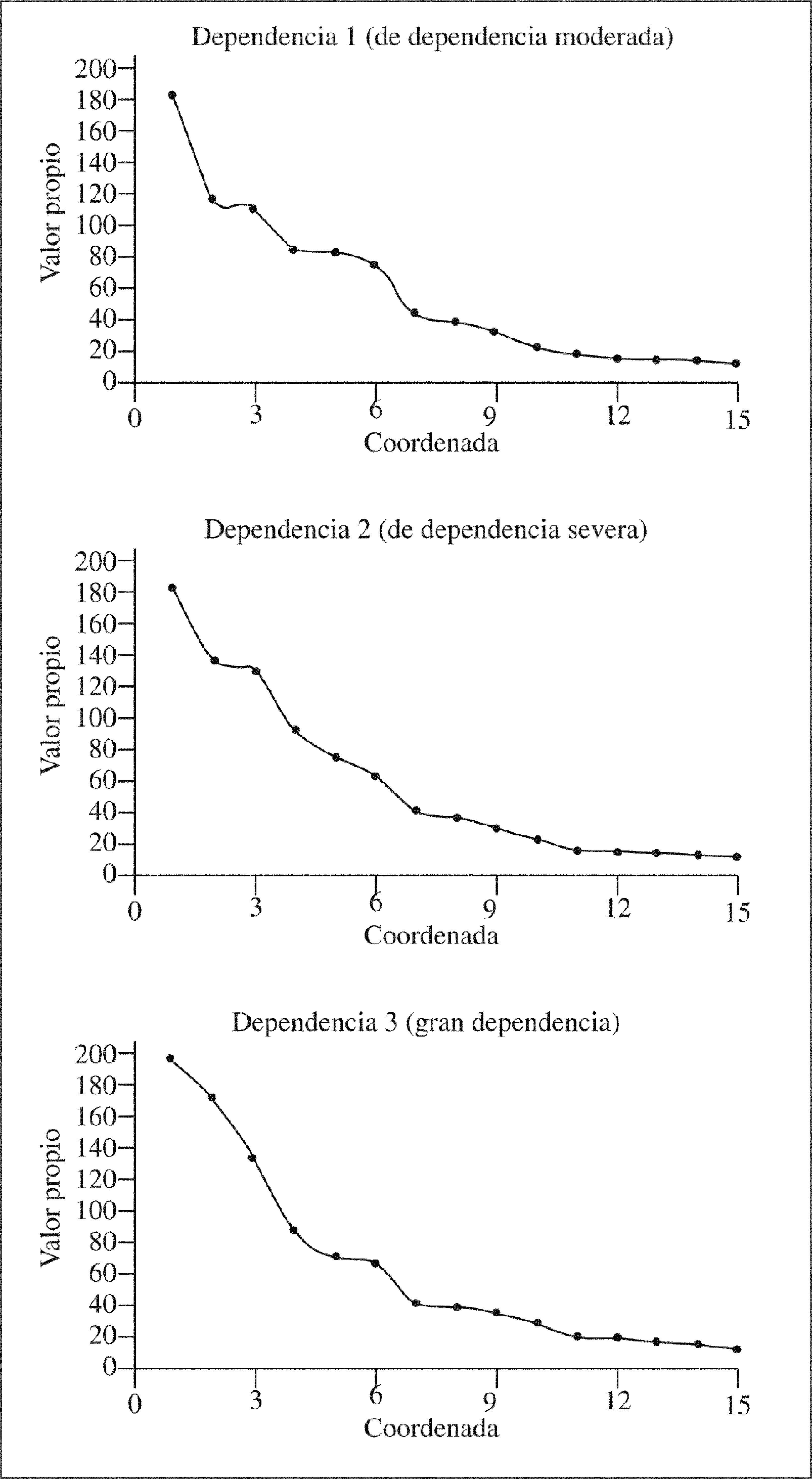
El criterio de selección del número de coordenadas principales y su interpretación son similares a los utilizados en el análisis de componentes principales. Para decidir el número de nuevas variables a utilizar se analizan los valores propios de la matriz B. Mediante el gráfico de sedimentación se estudia la evolución de los valores propios ordenados de mayor a menor, se observa a partir de qué punto se produce un descenso brusco de la curva, y este punto se delimita el número m<r de primeras coordenadas que se utilizarán. En caso de disponer de una matriz de similaridades, para obtener la disimilaridades se utiliza la siguiente transformación
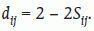
Una vez obtenidas las nuevas variables, denominadas coordenadas principales, las utilizamos para segmentar las submuestras de individuos con dependencia, pasando así a la segunda fase de nuestro estudio. Como ya hemos anunciado, el método utilizado aquí es el análisis de conglomerados no jerárquicos o método k medias.
Este método tiene diversas etapas, que se enumeran a continuación: 1) determinar el número s de conglomerados a formar; 2) obtener unos centros de grupos iniciales, que suelen coincidir con s individuos de la muestra; 3) asignar cada individuo a cada grupo en función del criterio de distancia mínima entre el sujeto y los centros de grupo —la distancia que suele utilizarse es la euclídea—, y 4) recalcular los centros de grupos después de cada asignación y repetir la tercera etapa, hasta que no existan diferencias entre los centros obtenidos en una asignación y la siguiente. Este procedimiento se realiza por triplicado, en cada una de las 3 submuestras de individuos con dependencia.
En resumen, para la obtención de los resultados que presentamos en el siguiente apartado se han utilizado conjuntamente las dos técnicas estadísticas anteriores. Estas técnicas ofrecen una visión completa de las características de los individuos en situación de dependencia, su tipificación y a continuación su caracterización en términos de una mayor o menor esperanza de vida en salud de cada uno de los grupos. La primera técnica (análisis de coordenadas principales) nos ha permitido determinar las características sociodemográficas que diferencian de forma más significativa a estos individuos. La segunda (análisis de conglomerados no jerárquicos) nos muestra las diferentes tipologías en función del grado de dependencia.
El paquete estadístico utilizado en el análisis de datos es el SAS, versión 9.1. Concretamente, el análisis de coordenadas principales se programó utilizando el lenguaje matricial del procedimiento IML de SAS. Los resultados del análisis de conglomerados no jerárquico se obtuvieron mediante el procedimiento FASTCLUS, que realiza un análisis de conglomerados k medias.
En última instancia, entrando en la tercera fase de nuestro análisis, ofrecemos los valores de la esperanza de vida desagregada en salud y dependencia, para los diferentes tipos de individuos con dependencia. A partir de métodos indirectos podemos aproximar el cálculo de la esperanza de vida sin dependencia, sin necesidad de conocer las probabilidades de transición entre los diferentes estados (sano, dependiente, muerte). En este caso, nos centraremos en la dependencia, trabajando por ello con esperanzas de vida sin dependencia y en dependencia.
Uno de los métodos más conocidos es el de Sullivan14, que consiste en la corrección de la cantidad de existencia entre x y x+1, por la tasa de prevalencia correspondiente al estado cuya esperanza de vida se pretende estimar. Por tanto, en nuestro caso, la tasa de prevalencia será el cociente entre el número de personas con dependencia de la edad x y el número de personas de dicha edad (íx). El método de Sullivan se caracteriza por la simplicidad de los cálculos y porque sólo requiere información de carácter transversal: la probabilidad de muerte para cada edad x, qx y las tasas de prevalencia para cada edad, tx. La esperanza de vida en salud a la edad x se calcula como
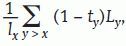
siendo Ly=∑z>xlz y esperanza de vida en dependencia a la edad x se calcula como
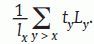
El estimador es consistente en condiciones de estacionariedad de la población15.
RESULTADOSEn primer lugar, obtenemos 3 matrices de distancias entre los individuos según su grado de dependencia (D1, D2 y D3). Para obtener estas matrices de distancias, en primer lugar se calculan los coeficientes de similaridad de Gower descritos en la sección anterior, que son adecuados cuando en el conjunto de variables utilizadas existen algunas cuantitativas y algunas otras binarias; posteriormente, se transforman estas similaridades en disimilaridades. Siguiendo el procedimiento descrito en la metodología, se obtienen los valores propios de las matrices B1,B2 y B3, que nos indican el número de coordenadas principales que aportan diferencias significativas entre los individuos.
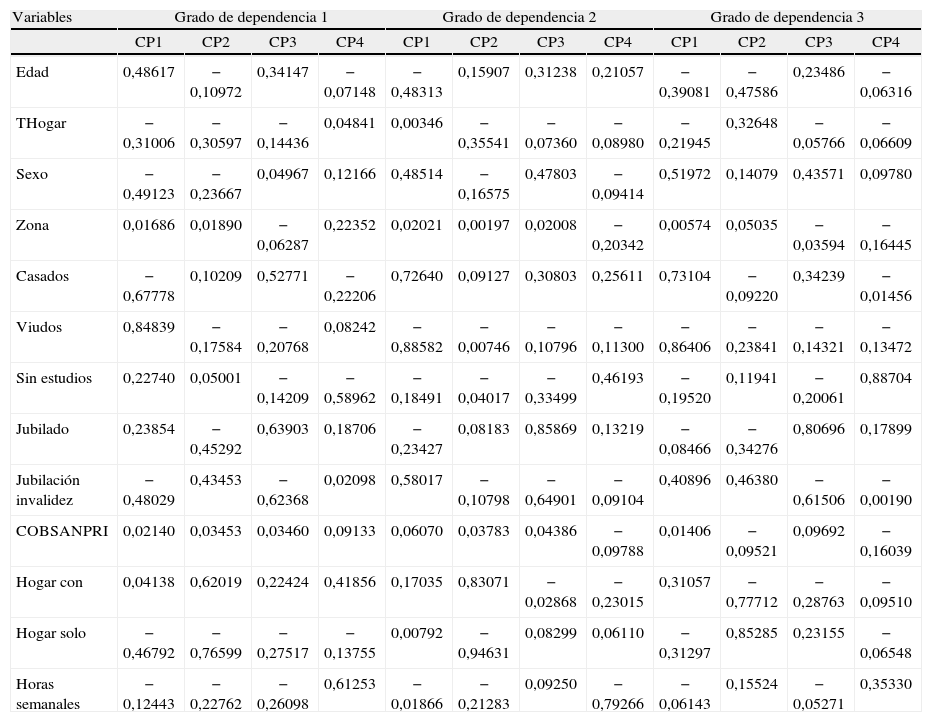
Después de analizar la evolución de los valores propios (gráficos de sedimentación de la fig. 1) y la correlación existente entre las primeras coordenadas principales y las variables originales, optamos por utilizar las cuatro primeras coordenadas de cada uno de los grados de dependencia (CP1, CP2, CP3 y CP4). En los tres casos, éstas suponen casi el 50% de las diferencias entre los individuos considerados y, además, poseen una interpretación clara en términos de su correlación con las variables originales —cuestión que no se da en las coordenadas posteriores. En los gráficos de sedimentación obtenidos para cada grado de dependencia, se representan los 15 primeros valores propios de las matrices B1, B2 y B3 Recordamos que el número de valores propios positivos es al menos igual al tamaño de la muestra menos 1, aunque sólo los primeros toman un valor elevado. En nuestros tres análisis, para el grado de dependencia moderada el número de valores propios positivos es≤(1.897 - 1), para el grado de dependencia severa es≤(1.399 - 1) y para el grado de gran dependencia es≤(652–1). Posteriormente, en la tabla 2 se muestran los coeficientes de correlación entre las cuatro primeras coordenadas principales extraídas y las variables originales; se observa que en los tres análisis todas las variables originales poseen cierto grado de correlación con alguna de las cuatro primeras coordenadas principales; sin embargo, aunque los resultados no se muestren aquí, hemos observado que a partir de la quinta coordenada en ninguno de los tres análisis se da una correlación elevada con alguna de las variables originales.
Correlaciones entre las variables originales y las coordenadas principales. Resultados obtenidos para cada nivel de dependencia
| Variables | Grado de dependencia 1 | Grado de dependencia 2 | Grado de dependencia 3 | |||||||||
| CP1 | CP2 | CP3 | CP4 | CP1 | CP2 | CP3 | CP4 | CP1 | CP2 | CP3 | CP4 | |
| Edad | 0,48617 | −0,10972 | 0,34147 | −0,07148 | −0,48313 | 0,15907 | 0,31238 | 0,21057 | −0,39081 | −0,47586 | 0,23486 | −0,06316 |
| THogar | −0,31006 | −0,30597 | −0,14436 | 0,04841 | 0,00346 | −0,35541 | −0,07360 | −0,08980 | −0,21945 | 0,32648 | −0,05766 | −0,06609 |
| Sexo | −0,49123 | −0,23667 | 0,04967 | 0,12166 | 0,48514 | −0,16575 | 0,47803 | −0,09414 | 0,51972 | 0,14079 | 0,43571 | 0,09780 |
| Zona | 0,01686 | 0,01890 | −0,06287 | 0,22352 | 0,02021 | 0,00197 | 0,02008 | −0,20342 | 0,00574 | 0,05035 | −0,03594 | −0,16445 |
| Casados | −0,67778 | 0,10209 | 0,52771 | −0,22206 | 0,72640 | 0,09127 | 0,30803 | 0,25611 | 0,73104 | −0,09220 | 0,34239 | −0,01456 |
| Viudos | 0,84839 | −0,17584 | −0,20768 | 0,08242 | −0,88582 | −0,00746 | −0,10796 | −0,11300 | −0,86406 | −0,23841 | −0,14321 | −0,13472 |
| Sin estudios | 0,22740 | 0,05001 | −0,14209 | −0,58962 | −0,18491 | −0,04017 | −0,33499 | 0,46193 | −0,19520 | 0,11941 | −0,20061 | 0,88704 |
| Jubilado | 0,23854 | −0,45292 | 0,63903 | 0,18706 | −0,23427 | 0,08183 | 0,85869 | 0,13219 | −0,08466 | −0,34276 | 0,80696 | 0,17899 |
| Jubilación invalidez | −0,48029 | 0,43453 | −0,62368 | 0,02098 | 0,58017 | −0,10798 | −0,64901 | −0,09104 | 0,40896 | 0,46380 | −0,61506 | −0,00190 |
| COBSANPRI | 0,02140 | 0,03453 | 0,03460 | 0,09133 | 0,06070 | 0,03783 | 0,04386 | −0,09788 | 0,01406 | −0,09521 | 0,09692 | −0,16039 |
| Hogar con | 0,04138 | 0,62019 | 0,22424 | 0,41856 | 0,17035 | 0,83071 | −0,02868 | −0,23015 | 0,31057 | −0,77712 | −0,28763 | −0,09510 |
| Hogar solo | −0,46792 | −0,76599 | −0,27517 | −0,13755 | 0,00792 | −0,94631 | 0,08299 | 0,06110 | −0,31297 | 0,85285 | 0,23155 | −0,06548 |
| Horas semanales | −0,12443 | −0,22762 | −0,26098 | 0,61253 | −0,01866 | −0,21283 | 0,09250 | −0,79266 | −0,06143 | 0,15524 | −0,05271 | 0,35330 |
Los resultados son similares para los tres grados de dependencia, siendo más evidente en la muestra de individuos de máxima dependencia. Observamos que estas coordenadas están fuertemente correlacionadas con las variables que definen el estado civil de los individuos (CP1), con las variables referentes al tipo de cuidados que recibe el individuo (CP2), con la situación laboral del individuo con dependencia (CP3) y con las variables relacionadas al nivel de estudios del individuo (CP4).
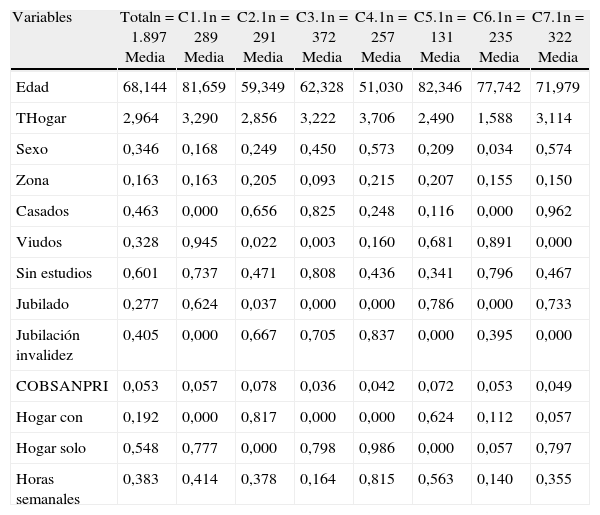
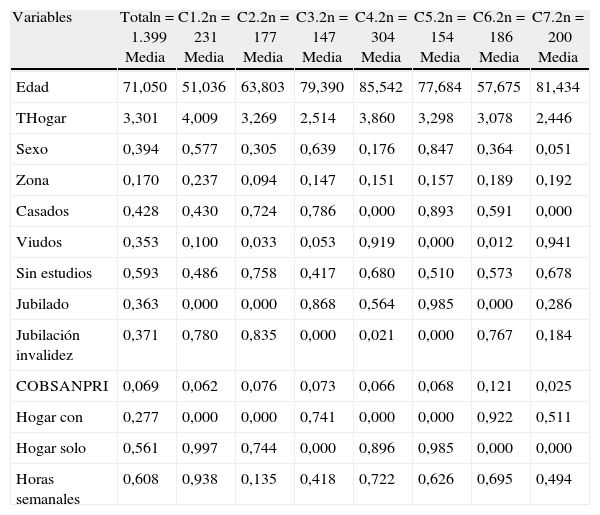
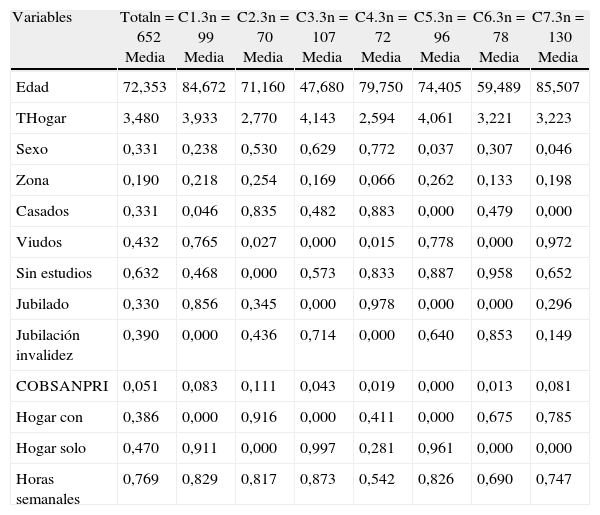
Utilizando las cuatro coordenadas descritas para cada nivel de dependencia, realizamos tres análisis k medias. Para ello tenemos en cuenta el peso poblacional (o factores de elevación de la muestra) de los individuos en cada una de las submuestras. Tras un proceso de prueba con distinto número de grupos, finalmente optamos por la formación de 7 conglomerados. Este resultado es el mismo para cada grado de dependencia. Por tanto, en total dispondremos de 7 perfiles de discapacitados con dependencia moderada (1), 7 perfiles con dependencia severa (2) y otros 7 perfiles con gran dependencia (3). A continuación, en las tablas 3, 4 y 5, respectivamente, para cada nivel de dependencia se muestran los tamaños muestrales y las medias de las variables originales dentro de cada grupo, junto a los mismos resultados obtenidos para todos los individuos con el grado dependencia correspondiente.
Conglomerados de individuos con dependencia de grado 1
| Variables | Totaln=1.897 Media | C1.1n=289 Media | C2.1n=291 Media | C3.1n=372 Media | C4.1n=257 Media | C5.1n=131 Media | C6.1n=235 Media | C7.1n=322 Media |
| Edad | 68,144 | 81,659 | 59,349 | 62,328 | 51,030 | 82,346 | 77,742 | 71,979 |
| THogar | 2,964 | 3,290 | 2,856 | 3,222 | 3,706 | 2,490 | 1,588 | 3,114 |
| Sexo | 0,346 | 0,168 | 0,249 | 0,450 | 0,573 | 0,209 | 0,034 | 0,574 |
| Zona | 0,163 | 0,163 | 0,205 | 0,093 | 0,215 | 0,207 | 0,155 | 0,150 |
| Casados | 0,463 | 0,000 | 0,656 | 0,825 | 0,248 | 0,116 | 0,000 | 0,962 |
| Viudos | 0,328 | 0,945 | 0,022 | 0,003 | 0,160 | 0,681 | 0,891 | 0,000 |
| Sin estudios | 0,601 | 0,737 | 0,471 | 0,808 | 0,436 | 0,341 | 0,796 | 0,467 |
| Jubilado | 0,277 | 0,624 | 0,037 | 0,000 | 0,000 | 0,786 | 0,000 | 0,733 |
| Jubilación invalidez | 0,405 | 0,000 | 0,667 | 0,705 | 0,837 | 0,000 | 0,395 | 0,000 |
| COBSANPRI | 0,053 | 0,057 | 0,078 | 0,036 | 0,042 | 0,072 | 0,053 | 0,049 |
| Hogar con | 0,192 | 0,000 | 0,817 | 0,000 | 0,000 | 0,624 | 0,112 | 0,057 |
| Hogar solo | 0,548 | 0,777 | 0,000 | 0,798 | 0,986 | 0,000 | 0,057 | 0,797 |
| Horas semanales | 0,383 | 0,414 | 0,378 | 0,164 | 0,815 | 0,563 | 0,140 | 0,355 |
Conglomerados de individuos con dependencia de grado 2
| Variables | Totaln=1.399 Media | C1.2n=231 Media | C2.2n=177 Media | C3.2n=147 Media | C4.2n=304 Media | C5.2n=154 Media | C6.2n=186 Media | C7.2n=200 Media |
| Edad | 71,050 | 51,036 | 63,803 | 79,390 | 85,542 | 77,684 | 57,675 | 81,434 |
| THogar | 3,301 | 4,009 | 3,269 | 2,514 | 3,860 | 3,298 | 3,078 | 2,446 |
| Sexo | 0,394 | 0,577 | 0,305 | 0,639 | 0,176 | 0,847 | 0,364 | 0,051 |
| Zona | 0,170 | 0,237 | 0,094 | 0,147 | 0,151 | 0,157 | 0,189 | 0,192 |
| Casados | 0,428 | 0,430 | 0,724 | 0,786 | 0,000 | 0,893 | 0,591 | 0,000 |
| Viudos | 0,353 | 0,100 | 0,033 | 0,053 | 0,919 | 0,000 | 0,012 | 0,941 |
| Sin estudios | 0,593 | 0,486 | 0,758 | 0,417 | 0,680 | 0,510 | 0,573 | 0,678 |
| Jubilado | 0,363 | 0,000 | 0,000 | 0,868 | 0,564 | 0,985 | 0,000 | 0,286 |
| Jubilación invalidez | 0,371 | 0,780 | 0,835 | 0,000 | 0,021 | 0,000 | 0,767 | 0,184 |
| COBSANPRI | 0,069 | 0,062 | 0,076 | 0,073 | 0,066 | 0,068 | 0,121 | 0,025 |
| Hogar con | 0,277 | 0,000 | 0,000 | 0,741 | 0,000 | 0,000 | 0,922 | 0,511 |
| Hogar solo | 0,561 | 0,997 | 0,744 | 0,000 | 0,896 | 0,985 | 0,000 | 0,000 |
| Horas semanales | 0,608 | 0,938 | 0,135 | 0,418 | 0,722 | 0,626 | 0,695 | 0,494 |
Conglomerados de la muestra de individuos con dependencia de grado 3
| Variables | Totaln=652 Media | C1.3n=99 Media | C2.3n=70 Media | C3.3n=107 Media | C4.3n=72 Media | C5.3n=96 Media | C6.3n=78 Media | C7.3n=130 Media |
| Edad | 72,353 | 84,672 | 71,160 | 47,680 | 79,750 | 74,405 | 59,489 | 85,507 |
| THogar | 3,480 | 3,933 | 2,770 | 4,143 | 2,594 | 4,061 | 3,221 | 3,223 |
| Sexo | 0,331 | 0,238 | 0,530 | 0,629 | 0,772 | 0,037 | 0,307 | 0,046 |
| Zona | 0,190 | 0,218 | 0,254 | 0,169 | 0,066 | 0,262 | 0,133 | 0,198 |
| Casados | 0,331 | 0,046 | 0,835 | 0,482 | 0,883 | 0,000 | 0,479 | 0,000 |
| Viudos | 0,432 | 0,765 | 0,027 | 0,000 | 0,015 | 0,778 | 0,000 | 0,972 |
| Sin estudios | 0,632 | 0,468 | 0,000 | 0,573 | 0,833 | 0,887 | 0,958 | 0,652 |
| Jubilado | 0,330 | 0,856 | 0,345 | 0,000 | 0,978 | 0,000 | 0,000 | 0,296 |
| Jubilación invalidez | 0,390 | 0,000 | 0,436 | 0,714 | 0,000 | 0,640 | 0,853 | 0,149 |
| COBSANPRI | 0,051 | 0,083 | 0,111 | 0,043 | 0,019 | 0,000 | 0,013 | 0,081 |
| Hogar con | 0,386 | 0,000 | 0,916 | 0,000 | 0,411 | 0,000 | 0,675 | 0,785 |
| Hogar solo | 0,470 | 0,911 | 0,000 | 0,997 | 0,281 | 0,961 | 0,000 | 0,000 |
| Horas semanales | 0,769 | 0,829 | 0,817 | 0,873 | 0,542 | 0,826 | 0,690 | 0,747 |
En la tabla 6 presentamos, de manera resumida, cuáles son las tipologías sociodemográficas en función del grado de dependencia, para ello se realiza una breve descripción de las características de los individuos dentro de cada grupo.
Descripción de los conglomerados
| Conglomerados Grado de dependencia 1 | Conglomerados Grado de dependencia 2 | Conglomerados Grado de dependencia 3 |
| C1.1 Individuos viudos sin estudios, jubilados, cuidados por miembros residentes en el hogar | C1.2 Individuos casados, con estudios en su mayoría, jubilados por invalidez y cuidados por residentes del hogar | C1.3 Individuos viudos, jubilados por edad y que están cuidados generalmente por miembros del hogar |
| C2.1 Individuos casados, con estudios en su mayoría, jubilados por invalidez, con ayuda externa en sus cuidados | C2.2 Individuos casados, sin estudios, jubilados por invalidez y que están cuidados por miembros residentes en la vivienda | C2.3 Individuos casados, con estudios en su totalidad y que cuentan además con ayuda externa para la atención de sus necesidades |
| C3.1 Individuos casados, sin estudios, jubilados por invalidez, cuidados por los miembros residentes en el hogar | C3.2 Hombres casados con estudios, jubilados por edad, y que reciben ayuda externa para atender las necesidades derivadas de la dependencia | C3.3 Hombres, en su mayoría, casados o solteros/divorciados, jubilados por invalidez y cuidados por personas de la vivienda. Este es uno de los grupos donde están situados los menores de edad |
| C4.1 Individuos casados con estudios en mayor porcentaje, jubilados por invalidez y cuidados prácticamente en su totalidad por individuos residentes en la vivienda (mujer, hijos, etc.) | C4.2 Mujeres viudas, jubiladas por edad o en una situación distinta de la de jubilado, que están cuidadas prácticamente en su totalidad por individuos residentes en el hogar | C4.3 Hombres casados, sin estudios, jubilados por edad, con ayuda en mayor medida externa para sus cuidados. Pueden representar en muchos casos a hombres que viven solos |
| C5.1 Mujeres viudas, en mayor medida con estudios, jubiladas por edad y cuyos cuidados son proporcionados mediante una ayuda externa | C5.2 Hombres casados, con o sin estudios, jubilados por edad y cuidados por personas que conviven en la misma vivienda | C5.3 Mujeres viudas sin estudios, jubiladas por invalidez, y que sólo reciben cuidados por parte de los residentes en el hogar. Sin cobertura sanitaria privada en ningún caso |
| C6.1 Mujeres viudas, sin estudios, que no poseen una pensión de jubilación y que, en su mayoría, podrían vivir prácticamente solas | C6.2 Individuos solteros/divorciados o casados, jubilados por invalidez o en otra situación y que reciben ayuda externa para la atención de sus cuidados | C6.3 Individuos casados, sin estudios, jubilados por cuestiones de invalidez. En mayor medida, reciben ayudas externas para la atención de sus necesidades. En este grupo también se sitúan los menores de edad |
| C7.1 Individuos casados, con estudios, jubilados por edad y que están cuidados por individuos residentes en la vivienda | C7.2 Mujeres viudas que poseen una situación laboral distinta de la de jubilado y, en algunos casos, con ayuda externa | C7.3 Mujeres viudas, con una situación distinta de la de jubilado y con ayuda externa para su atención |
A continuación, para cada nivel de dependencia, representamos los centros de cada grupo en los ejes de las coordenadas principales. Los gráficos resultantes nos permiten tener una perspectiva global de la situación sociodemográfica de la dependencia. En la figura 1 mostramos estos gráficos, respectivamente, para los grados de dependencia —1 (moderada), 2 (severa) y 3 (gran dependencia). En función de la interpretación de las coordenadas, descrita con anterioridad, en cada uno de los ejes apuntamos las etiquetas que permiten diferenciar los grupos en función de su posición en el gráfico.

La figura 2a muestra la representación de los centros de grupo para el grado de dependencia 1 en las dos primeras coordenadas principales (CP1 y CP2). En el mismo gráfico se indica cómo CP1 diferencia a los individuos según su estado civil. Principalmente separa a los individuos viudos del resto. Para la segunda coordenada principal, encontramos una fuerte correlación con las variables que informan sobre el tipo de ayuda de la que disponen los individuos. Con todo ello, podemos afirmar que valores elevados en ambas coordenadas son indicadores de individuos viudos que, posiblemente, necesiten de ayuda fuera del hogar, mientras que valores bajos debemos asociarlos a personas con tendencia a estar en situación de no viudedad y cuya asistencia se encuentra a cargo de personas que conviven con ellos.

Teniendo en cuenta el posicionamiento de los centros de grupo, observamos que los grupos C1, C5 y C6 están formados por individuos viudos, donde distinguiríamos a los que son atendidos por personas residentes en el hogar (C1) de los que requieren una ayuda de fuera de éste, de la que pueden estar ya disponiendo (C5) o no (C6).
Análogamente, para la figura 2b, apreciamos que el grupo C4 lo constituirían principalmente individuos jubilados por invalidez, que en su mayoría poseen estudios, con una asistencia de no menor de 40h semanales, como indica la correlación de la cuarta coordenada con la variable correspondiente al tiempo de cuidados que requiere el individuo. También observamos que los grupos C3 y C6 lo forman básicamente individuos sin estudios.
Para los individuos con dependencia severa (fig. 2c), aunque las cuatro coordenadas principales están asociadas a las mismas variables originales que en el caso anterior, la relación es distinta. En este caso, valores bajos de CP1 nos están representando individuos viudos y, a su vez, valores elevados de CP2 representan personas que están cuidadas por otros miembros residentes fuera del hogar. Con esta premisa, por lo que respecta a la interpretación del posicionamiento de algunos de los grupos, por ejemplo, observamos que el grupo C4, básicamente, lo forman individuos viudos cuidados por personas con las que conviven. Mientras que C3 lo componen individuos solteros o casados, que en su mayoría declaran poseer algún tipo de ayuda externa, a diferencia de C1, que no poseen ayuda ajena a la del hogar.
En la figura 2d vemos que valores negativos en CP3 representan individuos jubilados por invalidez, o en otra situación distinta de la de jubilado, mientras que, contrariamente a lo que sucedía para la dependencia moderada, valores elevados en CP4 representan individuos sin estudios cuyos cuidados requieren de menos de 40h semanales. Además hay una clara diferenciación entre grupos jubilados por edad (C5 y C3) y por cuestiones de invalidez (C2 y C6). Destaca también el grupo C2, formado en su mayoría por personas sin estudios, las cuales declaran no poseer ningún tipo de ayuda externa para sus cuidados.
Para el grupo de personas con gran dependencia, la interpretación de las coordenadas es similar a las de los niveles inferiores. Nos encontramos de nuevo con alguna variación en los signos de las correlaciones entre las coordenadas principales y las variables originales. En la figura 2e los valores negativos de ambas coordenadas nos indican individuos que declaran poseer algún tipo de ayuda externa al hogar (CP2) y viudos (CP1), cuya representación más clara se encuentra en los grupos C5 y C7. La otra cuestión que distingue claramente a estos grupos es la intensidad de los cuidados. El grupo C5 recoge, básicamente, a las mujeres que reciben cuidados por parte de residentes en el hogar, donde también es interesante comentar que en ningún caso poseen algún tipo de cobertura de carácter privado, y en C7 claramente requieren ayuda externa para su atención.
Finalmente, en la figura 2f los valores elevados en ambas coordenadas representan a individuos jubilados por edad y sin estudios. En el caso de los grupos C4 y C6, se distingue a aquellos individuos sin estudios y jubilados por edad (C4) de los jubilados por invalidez (C6).
En lo relativo a resultados, sólo nos queda comentar el último punto, concerniente a las esperanzas de vida en salud y en dependencia. Para ello, a partir de observar, mediante el análisis de coordenadas principales, que las variables que mejor explican las diferencias entre los individuos son las relacionadas con el estado civil, la actividad económica y los estudios, calculamos las esperanzas de vida en salud y en dependencia en esos grupos de individuos. Los grupos que consideramos son: individuos viudos y los no viudos, individuos con estudios o sin ellos y los individuos jubilados por invalidez o por edad.
Los cálculos los hemos realizado sólo para individuos mayores de 64 años, ya que existe un importante interés en el estudio de las personas mayores, como ya hemos mencionado con anterioridad. A partir de los porcentajes de individuos con dependencia en cada uno de los grupos establecidos, y estimando un polinomio cúbico, que toma como variable a explicar la tasa de dependencia y como explicativa la edad, obtenemos las tasas de prevalencia ajustadas. Estas tasas son las que utilizamos en el método de Sullivan para obtener las esperanzas de vida en salud y en situación de dependencia.
Para presentar gráficamente los resultados, realizamos la representación del impacto de la dependencia en la desagregación de la esperanza de vida según el número de años vividos en cada situación (sin dependencia, que equiparamos a salud, y con dependencia). Para distintos grupos de individuos, la figura 3 muestra el cociente entre la esperanza de vida en situación de dependencia y la esperanza de vida restante a partir de cada edad. Se diferencia entre las categorías de las variables viudos y no viudos, con o sin estudios o jubilados por invalidez o por edad. Debemos añadir que para ver los efectos de la variabilidad de las muestras en los resultados, se requeriría el cálculo de intervalos de confianza para la esperanza de vida en dependencia que no ha sido abordado en este momento.

De esta manera, respecto al estado civil (fig. 3 a) observamos que, conforme avanza la edad, el porcentaje de la esperanza de vida en salud disminuye, pero sin descender en ningún caso por debajo del 80%. Sobre la esperanza de vida en situación de dependencia, las mayores diferencias entre los individuos viudos y los no viudos se situarían en los 78 años y los 85 años, aunque no superan los 0,2 año en ningún caso. También apreciamos que a los 80 años de edad, el 5% de la esperanza de vida restante será en dependencia en el caso de los individuos viudos, edad que se ve incrementada hasta los 85 años para las personas que no
Finalmente, respecto a las variables relacionadas a la situación económico-laboral de los individuos (fig. 3 c) podemos ver que la edad a la cual el 5% de la esperanza de vida será en dependencia se alcanza a los 87 años en los individuos jubilados por edad, mientras que para los jubilados por cuestiones de invalidez este valor se asume antes de los 65 años. Además, una persona jubilada por invalidez estará muchos menos años de vida en una situación de«salud», ya que para los individuos jubilados por edad más del 90% de la esperanza de vida será en salud, al menos hasta los 93 años. Pero en el caso de los jubilados por invalidez este valor lo debemos buscar en edades mucho más tempranas.
DISCUSIÓNEn este trabajo se han estudiado las características sociodemográficas de los individuos con dependencia; su objetivo fue la obtención de una serie de agrupaciones que han permitido establecer una clasificación de las distintas situaciones de dependencia.
Las diferentes etapas en las que hemos trabajado los datos muestrales han permitido describir los perfiles de la dependencia en España, ofreciéndonos resultados que pueden ser de interés en la búsqueda de criterios que permitan la adecuada asignación de recursos. Citando a Corral16: «En un contexto de escasez de recursos y ante la evidencia del incesante envejecimiento demográfico y de una creciente e ilimitada demanda de asistencia por parte de la población, es indispensable velar por que los servicios sociales y de salud respondan adecuadamente a las necesidades específicas de cada usuario, y así evitar la duplicidad de recursos y asegurar que su cometido se lleva a cabo de la forma más eficiente posible».
Por ejemplo, la planificación de plazas residenciales para personas con gran dependencia debería priorizar el perfil C5.3 (mujeres viudas, sin estudios, jubiladas por invalidez, que sólo reciben cuidados por residentes en el hogar y que no poseen cobertura sanitaria privada) frente al grupo C2.3 (individuos casados, con estudios y que cuentan con ayuda externa para la atención de sus necesidades), que necesitaría menos medios. Por otra parte, en el acceso a
centros de día se debería tener en cuenta la existencia del perfil C6.1 (mujeres viudas, sin estudios, que no poseen una pensión de jubilación y que mayoritariamente viven solas) como criterio de preferencia.
Los cálculos sobre esperanza de vida en salud pueden ayudar a detectar los colectivos que más ven mermadas sus posibilidades de alcanzar una elevada longevidad en estado saludable. Además, si en el futuro se estudian las tendencias de las esperanzas de vida, el dato actual marca un mínimo que sirve de referencia para evaluar el impacto de políticas de mejora de la calidad de vida de algunos colectivos de mayores.
Nos gustaría destacar la necesidad de poder disponer de información más actualizada sobre la situación de la dependencia en España. Teniendo en cuenta que los datos utilizados son los relativos a la encuesta del año 1999, consideramos que ha pasado un plazo suficiente como para que el panorama de la dependencia haya variado. Por eso es conveniente comentar que cuestiones como no haber sido posible la inclusión de las variables referentes a la nacionalidad de los encuestados, por la gran ausencia de respuesta en las variables seleccionadas, han impedido un análisis más exhaustivo del tema. En nuestra opinión, poder incorporar esta información nos permitiría definir de una manera más precisa las tipologías de individuos con dependencia que encontramos en la sociedad española actualmente, y más importante aún, poder estimar la tendencia que seguirá la dependencia en nuestro país.
No podemos dejar de lado el hecho de que la creciente inmigración tiene un papel importante. El mapa de la dependencia puede variar sustancialmente por ese incremento. Este aumento de la población tiene su reflejo en aspectos como variaciones en la esperanza de vida u otros factores de importancia en un análisis sobre la dependencia. Según los últimos datos de la explotación del Padrón Municipal llevada a cabo por el INE17, el número de extranjeros empadronados supone un 8,7% de la población española.
La información actual es importante como vía para el desarrollo en las técnicas de cuantificación de costes de la dependencia18, así como para la creación de sistemas que aseguren que los recursos disponibles se utilizan para disminuir las diferencias entre los grupos de individuos con dependencia, incidiendo en la convergencia entre ellos. En nuestra opinión, con el auge del tema por la reciente aprobación de la Ley de Dependencia y por las inmediatas implicaciones en la sociedad española, se suscitan dudas sobre la sostenibilidad del sistema público. Es importante ver que las personas con gran dependencia presentan una esperanza de vida realmente efímera, con lo cual las otras dos categorías de individuos con dependencia, para nosotros, son aquellas que a largo plazo requerirán la ayuda del sistema durante mayor tiempo.
