








Este estudio tuvo como objetivo evaluar la fiabilidad y legibilidad de las respuestas generadas por dos populares chatbots de inteligencia artificial (IA), «Chat Generative Pretrained» (ChatGPT; desarrollado por OpenAI en San Francisco, CA) y «Google Gemini», a preguntas potenciales de los pacientes sobre las exploraciones PET-TC.
Materiales y métodosSe formularon por separado 30 preguntas potenciales para cada una de las PET-TC con [18F]FDG y [68Ga]Ga-DOTA-SSTR y 29 preguntas potenciales para la PET-TC con [68Ga]Ga-PSMA a ChatGPT-4 y Gemini en mayo de 2024. Se evaluó la fiabilidad y legibilidad de las respuestas mediante la escala DISCERN modificada (mDISCERN), Flesch Reading Ease (FRE), Gunning FogIndex (GFI) y Flesch-Kincaid Reading Grade Level (FKRGL). Se evaluó la fiabilidad entre evaluadores de las puntuaciones mDISCERN proporcionadas por tres evaluadores (ChatGPT-4, Gemini y un médico especialista en medicina nuclear) para las respuestas.
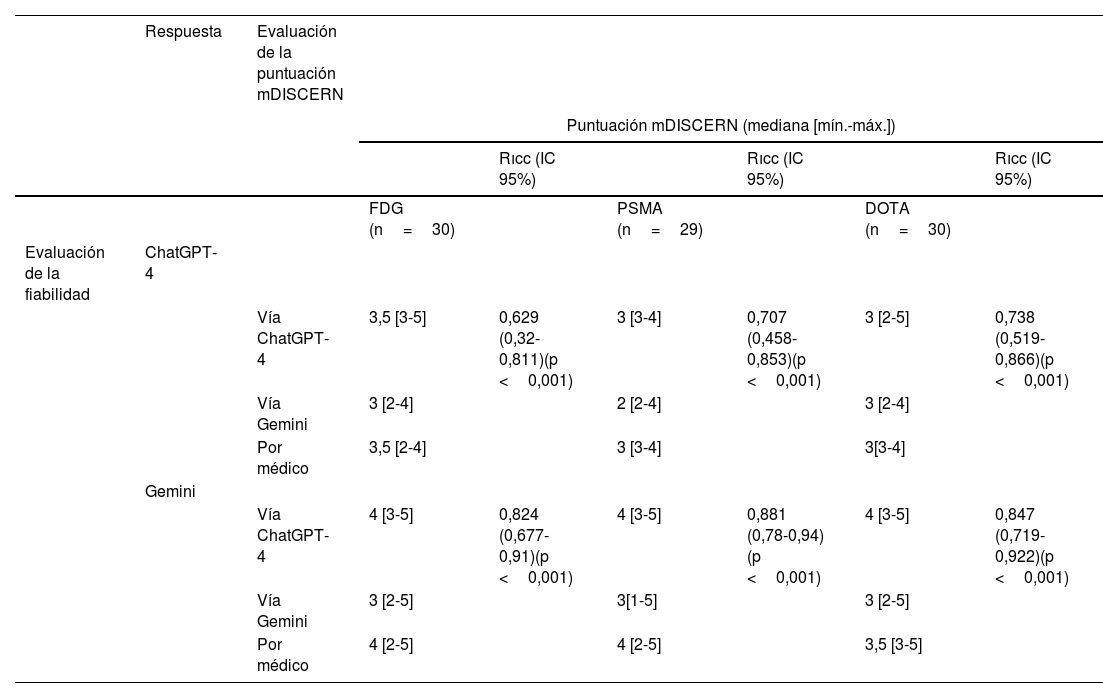
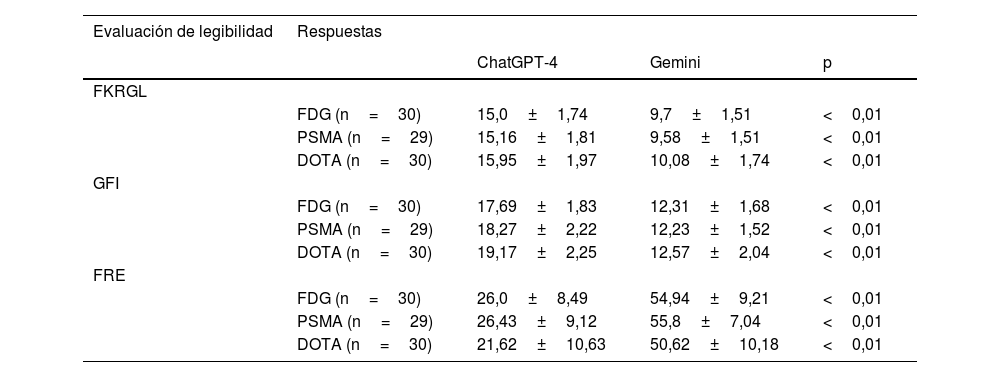
ResultadosLa mediana (mín.-máx.) de las puntuaciones mDISCERN revisadas por el médico para las respuestas sobre las exploraciones con fluorodesoxiglucosa (FDG), antígeno de membrana prostático específico (PSMA) y DOTA PET-TC fueron 3,5 (2-4), 3 (3-4), 3 (3-4) para ChatGPT-4 y 4 (2-5), 4 (2-5), 3,5 (3-5) para Gemini, respectivamente. Las puntuaciones mDISCERN evaluadas mediante ChatGPT-4 para las respuestas sobre las exploraciones PET-TC con FDG, PSMA y el receptor de somatostatina [68Ga]Ga-DOTA (DOTA-SSTR) fueron 3,5 (3-5), 3 (3-4), 3 (2-3) para ChatGPT-4 y 4 (3-5), 4 (3-5), 4 (3-5) para Gemini, respectivamente. Las puntuaciones mDISCERN evaluadas mediante Gemini para las respuestas con FDG, PSMA y DOTA-SSTR PET-TC fueron 3 (2-4), 2 (2-4), 3 (2-4) para ChatGPT-4, y 3 (2-5), 3 (1-5), 3 (2-5) para Gemini, respectivamente. El coeficiente de correlación de fiabilidad entre evaluadores de las puntuaciones de mDISCERN para las respuestas de ChatGPT-4 sobre las exploraciones PET-TC con FDG, PSMA y DOTA-SSTR fue de 0,629 (intervalo de confianza [IC] 95%=0,32-0,812), 0,707 (IC 95%=0,458-0,853) y 0,738 (IC 95%=0,519-0,866), respectivamente (p <0,001). El coeficiente de correlación de las puntuaciones mDISCERN para las respuestas Gemini sobre las exploraciones PET-TC con FDG, PSMA y DOTA-SSTR fue de 0,824 (IC 95%=0,677-0,910), 0,881 (IC 95%=0,78-0,94) y 0,847 (IC 95%=0,719-0,922), respectivamente (p <0,001). Las puntuaciones mDISCERN evaluadas por ChatGPT-4, Gemini y el médico mostraron que las respuestas de los chatbots sobre todos los PET-TC tenían una concordancia estadística de moderada a buena según el coeficiente de correlación de fiabilidad entre evaluadores (p <0,001). Hubo una diferencia estadísticamente significativa en todas las puntuaciones de legibilidad (FKRGL, GFI y FRE) de las respuestas de ChatGPT-4 y Gemini sobre PET-TC (p <0,001). Las respuestas de Gemini fueron más cortas y tuvieron mejores puntuaciones de legibilidad que las de ChatGPT-4.
ConclusionesHubo un nivel aceptable de acuerdo entre los evaluadores para la puntuación mDISCERN, lo que indica un acuerdo con la fiabilidad general de las respuestas. Sin embargo, la información proporcionada por los chatbots de IA no puede ser leída fácilmente por el público.
This study aimed to evaluate the reliability and readability of responses generated by two popular AI-chatbots, ‘ChatGPT-4.0’ and ‘Google Gemini’, to potential patient questions about PET/CT scans.
Materials and methodsThirty potential questions for each of [18F]FDG and [68Ga]Ga-DOTA-SSTR PET/CT, and twenty-nine potential questions for [68Ga]Ga-PSMA PET/CT were asked separately to ChatGPT-4 and Gemini in May 2024. The responses were evaluated for reliability and readability using the modified DISCERN (mDISCERN) scale, Flesch Reading Ease (FRE), Gunning Fog Index (GFI), and Flesch-Kincaid Reading Grade Level (FKRGL). The inter-rater reliability of mDISCERN scores provided by three raters (ChatGPT-4, Gemini, and a nuclear medicine physician) for the responses was assessed.
ResultsThe median [min-max] mDISCERN scores reviewed by the physician for responses about FDG, PSMA and DOTA PET/CT scans were 3.5 [2-4], 3 [3-4], 3 [3-4] for ChatGPT-4 and 4 [2-5], 4 [2-5], 3.5 [3-5] for Gemini, respectively. The mDISCERN scores assessed using ChatGPT-4 for answers about FDG, PSMA, and DOTA-SSTR PET/CT scans were 3.5 [3-5], 3 [3-4], 3 [2-3] for ChatGPT-4, and 4 [3-5], 4 [3-5], 4 [3-5] for Gemini, respectively. The mDISCERN scores evaluated using Gemini for responses FDG, PSMA, and DOTA-SSTR PET/CTs were 3 [2-4], 2 [2-4], 3 [2-4] for ChatGPT-4, and 3 [2-5], 3 [1-5], 3 [2-5] for Gemini, respectively. The inter-rater reliability correlation coefficient of mDISCERN scores for ChatGPT-4 responses about FDG, PSMA, and DOTA-SSTR PET/CT scans were 0.629 (95% CI= 0,32-0,812), 0.707 (95% CI=0.458-0.853) and 0.738 (95% CI=0.519-0.866), respectively (p<0.001). The correlation coefficient of mDISCERN scores for Gemini responses about FDG, PSMA, and DOTA-SSTR PET/CT scans were 0.824 (95% CI=0.677-0.910), 0.881 (95% CI=0.78-0.94) and 0.847 (95% CI=0.719-0.922), respectively (p<0.001). The mDISCERN scores assessed by ChatGPT-4, Gemini, and the physician showed that the chatbots’ responses about all PET/CT scans had moderate to good statistical agreement according to the inter-rater reliability correlation coefficient (p<0,001). There was a statistically significant difference in all readability scores (FKRGL, GFI, and FRE) of ChatGPT-4 and Gemini responses about PET/CT scans (p<0,001). Gemini responses were shorter and had better readability scores than ChatGPT-4 responses.
ConclusionThere was an acceptable level of agreement between raters for the mDISCERN score, indicating agreement with the overall reliability of the responses. However, the information provided by AI-chatbots cannot be easily read by the public.
