









La Inteligencia Artificial (IA) tiene el impacto actual que tuvo la electricidad; y los datos, su materia prima, son el nuevo petróleo de la era moderna. Encontrar el valor de ello en el contexto de su utilidad clínica son el vínculo que acerca las ciencias de la computación a las ciencias de la salud. La toma de decisiones basadas en datos propios apoyada en algoritmos computacionales que “aprenden” a resolver un problema con grandes cantidades de datos está llevando a la medicina personalizada y de precisión a tener un rol cada vez más relevante. La cirugía no se escapa de ello.
Con tecnologías que parecen ser futurista y lejanas, y en ocasiones confusas, es un deber de la divulgación científica publicar el estado del arte de una realidad con la que convivimos a diario. Conocer las bases de la computación desde las publicaciones de Alan Turing en 1937, permite comprender mejor por qué estamos asistiendo hoy a un momento histórico en que confluyen un gran volumen de datos con un gran poder computacional, que ha llevado al desarrollo actual de estas técnicas que hoy vemos transversalmente en todas las industrias, como en la salud. Es por ello que en esta revisión se pretende reunir y aclarar los conceptos más relevantes de la ciencia de datos en general, enlazado con sus aplicaciones y desarrollo en medicina y cirugía cardíaca. Con ello, se pretende lograr un acercamiento, al menos teórico, a todo el potencial que las técnicas modernas en el cómputo de datos permiten.
Artificial Intelligence (AI) has the current impact that electricity had; and data, its raw material, is the new oil of the modern age. Finding the value of it in the context of its clinical utility is the link that brings computer science closer to health science. Decision-making based on proprietary data supported by computational algorithms that “learn” to solve a problem with large amounts of data is leading personalized and precision medicine to play an increasingly relevant role. Surgery is no exception.
With technologies that seem to be futuristic and distant, and sometimes confusing, it is a duty of popular science to publish the state of the art of a reality with which we live daily. Knowing the bases of the computer since from publications of Alan Turing in 1937, allows us to better understand why we are witnessing today a historical moment in which a large volume of data converges with a great computational power, which has led to the current development of these techniques, that today we see transversally in all industries, such as in health.
That is why this review aims to gather and clarify the most relevant concepts of data science in general, linked to its applications and development in medicine and cardiac surgery. With this, it is intended to achieve an approach, at least theoretical, to the full potential that modern techniques in data computation allow.
Cuando en 1815 el español Francisco Romero realiza con éxito la primera pericardiectomía mediante toracotomía, el matemático británico Charles Babbage afinaba los detalles del modelo de una calculadora mecánica que concluye en 1822 con su “máquina diferencial” que utilizaba la teoría de las diferencias finitas para resolver ecuaciones diferenciales. Por esta invención se le considera el padre de los computadores digitales.
La importancia de la inteligencia artificial (IA) está aumentando en la toma de decisiones quirúrgicas en relación con factores de riesgos, anatomía, historia natural de las enfermedades, costos, etc, y para hacer mejores predicciones de las consecuencias de decisiones quirúrgicas1. Por ejemplo, un modelo de deep learning (DL) se utilizó para predecir qué individuos con resistencia al tratamiento de la epilepsia se beneficiarían más con un tratamiento quirúrgico2,3. En cirugía cardíaca se han desarrollado algoritmos de machine learning (ML), o aprendizaje de máquina, que superan los score de riesgo quirúrgicos estándar para predecir mortalidad intrahospitalaria después de un procedimiento4.
Además, en la planificación y toma de decisiones quirúrgicas, la IA se puede aplicar para cambiar o adaptar técnicas quirúrgicas de forma más personalizada a cada caso en particular. La cirugía robótica controlada a distancia ha mostrado mejorar la seguridad de intervenciones donde los operadores están expuestos a altas dosis de radiaciones ionizantes, y también hacen posible la cirugía en ubicaciones anatómicas que de otra manera serían imposibles de explorar5,6. A medida que la cirugía robótica autónoma mejora, se proyecta que en algunos casos el rol del cirujano podría llegar a ser supervisar los movimientos del robot7.
En relación con el concepto moderno del procesamiento de datos, sin duda que la rama de ciencia de datos tiene un rol protagónico, emergente y de rápido y constante desarrollo. La pandemia del COVID-19 dejó en evidencia varios aspectos positivos y negativos en el procesamiento de grandes volúmenes de datos a nivel mundial, y el requerimiento de información y resultados en tiempo real o cuasi real. A nivel de las distintas industrias de la economía, la salud es un campo de aplicación muy grande en ML, a la par con otras industrias. Sin embargo, aún existe una gran brecha entre lo clínico y lo computacional.
Por todo lo anterior, en esta revisión se pretende reunir y aclarar los conceptos más relevantes del estado del arte en la ciencia de datos en general, enlazado con sus aplicaciones y desarrollo en medicina y cirugía cardíaca. Con ello, se pretende lograr un acercamiento, al menos teórico, a todo el potencial que las técnicas modernas en el cómputo de datos permiten.
2Definiciones y contextoDentro de las distintas líneas de trabajo en IA ha sido difícil llegar a una única definición absoluta, incluso en el mundo académico y científico. Depende desde dónde se le defina, hay una mirada desde los estadísticos, otra desde de los matemáticos más puros, otra exclusivamente desde la ingeniería, otra de la inteligencia de negocios, etc.
3Ciencias de la computaciónEn 1833 Ada Lovelace escribió las instrucciones de la máquina de Babbage. Lo interesante de su trabajo es que agregó notas propias describiendo en forma lógica los pasos para resolver problemas matemáticos complejos, a lo que se le reconocen como el primer algoritmo computacional. Introdujo 4 conceptos fundamentales: 1) operaciones con símbolos y lógica; 2) el algoritmo para resolver los números de Bernoulli8 (donde define las subrutinas, las condicionales y los bucles recursivos); 3) que las máquinas van a hacer sólo lo que se les indican y; 4) la máquina universal.
Posteriormente Hilbert en 1900, plantea 23 problemas matemáticos, de los cuales el problema número 10 en particular, sobre ecuación diofántica, tendría mayor importancia futura en los inicios de la computación.
Luego, en 1928 los científicos se interesan en el llamado “problema de decisión”, donde por primera vez se le da una mirada científica a automatizar demostraciones en matemática, buscando un método que resuelva un problema demostrable de lógica de primer orden sobre números enteros. En 1931 Göedel enuncia su Teorema de Incompletitud (lógica computacional) enunciando que hay fórmulas en matemáticas que son ciertas pero que no se pueden demostrar.
En 1935 Alan Turing (Fig. 1), matemático británico (19121954) se interesa en el estudio de estos postulados (de Hilbert y Göedel), focalizando su trabajo en las fórmulas demostrables. Publica en 1937 su trabajo “On computable numbers, with an application to the Entscheidungsproblem”9. En él, formaliza el proceso de computación automática mediante el control de estados con reglas que gobiernen un proceso, sobre la base de que si algo se puede resolver de manera automática entonces se podría resolver con ese proceso. Propone una “máquina universal” donde enuncia que: “existe una máquina que es capaz de simular todas las otras máquinas”. Encuentra una forma de codificar la tarea de una máquina física, para luego pasar esa codificación a una “máquina universal”. Este trabajo ha sido tan relevante que es considerado el inicio de la ciencia de la computación.

Para el funcionamiento de esta máquina conceptual, Turing diseña una cinta infinita que contiene símbolos (input), sobre la cual un cabezal lee y escribe símbolos y se mueve a través de ella (estados) según las reglas (transiciones) que se le entreguen (estados de transición) desde un estado inicial hasta llegar a un estado final (sin transición definida) que puede ser “encendido” (acepta el input) o “apagado” (no acepta el input) si cumple o no una condición en el lenguaje de símbolos final, con una memoria arbitraria que permite acceder a cualquier dato almacenado (posición) en la memoria. A este concepto se le conoce posteriormente como la “máquina de Turing”. Esta es la primera noción de software sobre un sólo hardware, y es la base de cómo conocemos hoy los computadores (Fig. 2).

Durante el mismo año, Claude Shannon presenta su tesis postulando que cualquier operación matemática, sin importar su complejidad, se puede reducir a operaciones lógicas Booleanas de verdadero o falso (1 ó 0) que pueden ser representadas mediante interruptores eléctricos.
Con los trabajos de Turing y de Shannon se establecen las bases teóricas para la creación de las computadoras digitales (no analógicas) como las conocemos hoy en día, para el procesamiento de datos de propósito general mediante la electrónica. De esta manera, la primera máquina construida con estas características fue el ENIAC (Electronic Numerical Integrator and Computer) entre los años 1941 a 1946 por los ingenieros John Mauchly y John Eckert, que pesaba 30 toneladas. La programación de esta primera computadora fue encargada a 6 mujeres: Betty Snyder Holberton, Jean Jennings Bartik, Kathleen McNulty Mauchly Antonelli, Marlyn Wescoff Meltzer, Ruth Lighterman Teitelbaum y Frances Bilas Spence.
Alrededor de esos mismos años, la teniente Grace Hooper de la marina norteamericana, trabajaba en programar una computadora electromecánica, el Mark I de Harvard (no eléctrica como el ENIAC). Escribió lo que se conoce como el primer libro de programación, donde describe ampliamente las sub-rutinas.
4Inteligencia artificial“La IA es la nueva electricidad” (Andrew Ng, Stanford Adjunct Professor). Pero la IA no es algo “nuevo”; ya en 1944 Turing comenzó a intentar construir una máquina que emule un cerebro. En 1950 publica por primera vez el concepto y la relación de máquinas computacionales e inteligencia en su trabajo “Computing machinery and intelligence”10; y se pregunta si las máquinas pueden pensar. Propone un método mediante preguntas y respuestas para evaluar si un humano es o no capaz de decidir si está interactuando con una máquina o con una persona; si en el 50% o más de las veces no acierta, se dice que la máquina pasa el “test de Turing” y se considera que es un “máquina inteligente”. Esto se considera el origen del concepto de “IA”. Turing predijo que para alrededor del año 2000 la mayoría de las máquinas iban a pasar el test, y que además iban a poder “conversar” entre ellas. No deja de sorprender la visión de Turing por esos años de lo que finalmente estamos viviendo hoy en día.
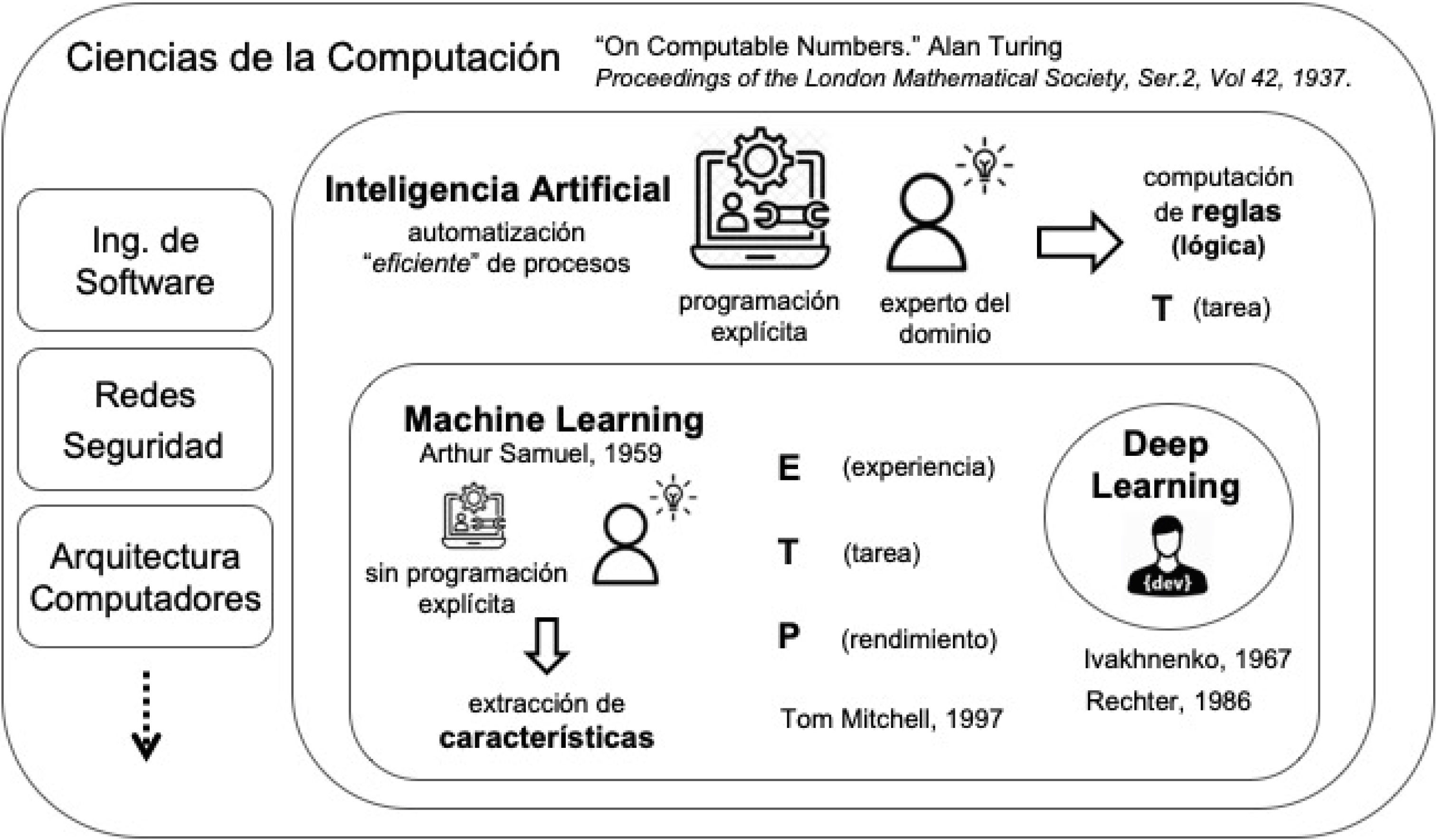
La IA se pude definir como un área de las ciencias de la computación dedicada a crear procesos automáticos que, en base a una serie de reglas, funcionen como se esperaría que fuera un comportamiento inteligente o, dicho de otra forma, cómo se crea o esperaría lo hiciera un ser humano. Las primeras técnicas de IA se basan en algoritmos absolutos del todo o nada, vale decir, su resultado se evalúa como correcto o incorrecto según resuelva exactamente una tarea o no, sin admitir errores; si funciona bien en todos los casos se implementa (Fig. 3).
5MACHINE LEARNING (ML, APRENDIZAJE DE MÁQUINA) como un área de las ciencias de la computación, machine learning (ML) como un área de la IA, y deep learning (DL) como una técnica de ML. Creative Commons Licence, © Javier Mora.")
ML es un área de la IA, donde se trabaja con algoritmos generales que a partir de experiencia (ejemplos) puedan resolver un problema de la mejor manera posible, cometiendo la menor cantidad de errores. Por este motivo se denomina “aprendizaje de máquina”, porque es el proceso por el cual se le “enseña” a una máquina a resolver un problema, tolerando que para ello cometa “errores de acierto” (Fig. 3).
Hay 3 elementos esenciales que definen al ML: 1) la experiencia, 2) la tarea y; 3) una métrica. La experiencia son ejemplos. La tarea es el problema que se requiere resolver. La métrica indica qué tan bien se resuelve el problema. Con estos elementos, Mitchell11 sintetizó el concepto clásico general de ML como: “se dice que un programa computacional aprende de una experiencia E con respecto a algún tipo de tarea T con una medida de rendimiento P, si su rendimiento en la tarea T medido por P mejora con la experiencia E”. Algunas métricas que se basan en una matriz de confusión son: exactitud (accuracy), precisión (precision), sensibilidad (recall), especificidad, curva receiver operating characteristic (ROC) y área bajo la curva ROC (AUROC)12.
Según las técnicas que se utilicen, las operaciones matemáticas que realiza el algoritmo definidas por los hiperparámetros (parámetros modificables), generan cálculos complejos como derivadas y matrices de altas dimensiones (millones), que son las que exigen gran poder computacional. Para este tipo de técnicas, una persona debe extraer las características de la tarea (feature engineering), las que se traspasan a un algoritmo para que luego reconociendo esas características resuelva el problema.
ML tiene 3 grandes grupos de técnicas: 1) el aprendizaje supervisado, 2) el aprendizaje no supervisado y; 3) el aprendizaje por reforzamiento (reinforcement learning)11. La experiencia E, en los casos de aprendizaje supervisado, corresponde al conjunto de datos de entrenamiento que contiene pares de entrada/salida esperada de la función que se quiere aprender; con él se realizan por ejemplo tareas de clasificación (agrupar por diagnósticos); y tareas de regresión (predicciones). En el aprendizaje no-supervisado se utilizan conjuntos de datos no etiquetados, pudiendo realizar tareas de agrupamiento (clustering) y reducción de dimensionalidad, por ejemplo, para visualizar cómo se distribuye un gran volumen de datos del que no se conoce un patrón previamente. El aprendizaje por reforzamiento se utiliza principalmente con tareas robóticas (conducción autónoma, gestión de bodegas y distribución, entre otras).
Con una mirada práctica, ML es útil para problemas en los que las soluciones existentes requieren mucho ajuste manual o largas listas de reglas, en estos casos un algoritmo de ML puede simplificar el código y funcionar mucho mejor; para problemas complejos en los que no se puede encontrar una buena solución algorítmica absoluta o una regla absoluta; problemas cambiantes, ya que un sistema de ML puede adaptarse y aprender de nuevos datos constantemente y en tiempo real; y para realizar minería de datos y obtener conocimiento sobre problemas complejos que involucran grandes cantidades de datos.
6DEEP LEARNING (DL, REDES NEURONALES PROFUNDAS)El primer modelo que se conoce sobre redes neuronales fue propuesto por Alan Turing en 1948 en su publicación titulada “Intelligent Machinery”13,14. Actualmente la técnica de ML que mejor resultados ha demostrado para la mayoría de las tareas que se pueden resolver con ML es el DL15 (Fig. 3), y es la que ha mejorado radicalmente el estado del arte en problemas complejos como visión computacional, reconocimiento de voz y procesamiento de lenguaje natural (natural language processing, NLP).
Mediante esta técnica, es el algoritmo el que extrae las características del problema al estar expuesto a una suficiente cantidad de ejemplos etiquetados o conocidos. Esto lo realiza mediante el cómputo de datos de entrada (ejemplos) que mediante operaciones matemáticas con una función no lineal entrega datos de salida que pueden ser la entrada de otra función o el resultado final del algoritmo, el que como todas las técnicas de ML se evalúa mediante una métrica definida para la tarea. De esta manera, al pasarle al algoritmo suficiente cantidad de ejemplos conocidos, posteriormente será capaz de resolver la tarea con ejemplos no conocidos con un alto nivel de asertividad.
Estas técnicas de aprendizaje de máquina profundas son algoritmos que aprenden múltiples niveles de representación a través de la composición de funciones no lineales15. Estos sistemas son reconocidos por su inmensa habilidad para manejar grandes volúmenes de datos relativamente desorganizados y con un gran número de variables16. Las principales funciones no lineales que se utilizan son: softmax, sigmoide, ReLu y tangente hiperbólica12.
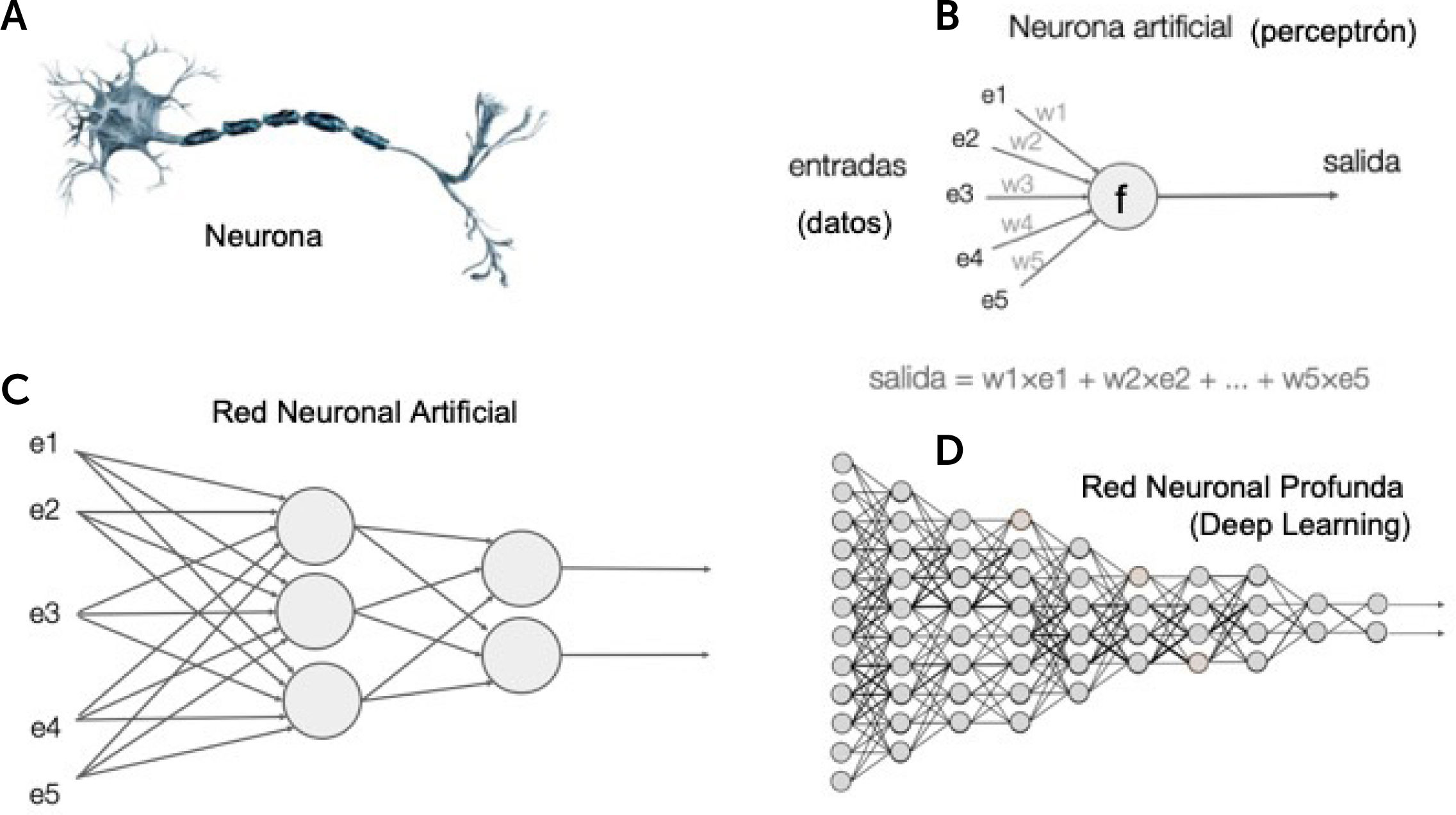
La abstracción matemática de ese concepto en su unidad mínima, que se conoce como neurona artificial o “perceptrón”17, es que a datos de entrada (estimulo inicial) se le aplican operaciones matemáticas cuyo resultado se lleva a una función de activación (excitación de una neurona), que a su vez entrega un valor de salida (conducción del axón) que puede ser el dato de entrada para otra neurona artificial (neurona aferente) o ser el resultado final (neurona eferente). Luego, la concatenación de algunas neuronas artificiales, forman una red neuronal. Y a su vez, muchas capas de muchas redes neuronales conforman una red neuronal profunda o DL14 (Fig. 4).
).")
Los 3 principales tipos de redes neuronales (neural network, NN) según su diseño son: 1) las fully connected, 2) las redes convolucionales (CNN) y; 3) las redes recurrentes (RNN). Las primeras son de fines generales, las CNN son utilizadas para el procesamiento de imágenes, y las RNN son las utilizadas para el procesamiento de texto.
Entrenar una red neuronal es encontrar los parámetros con que se minimiza la función que estima el error. Se calcula el error y luego se propaga desde la capa más profunda o última a la primera capa, calculando cuánto aporta cada valor de las matrices en el error (back-propagation).
7Procesamiento de lenguaje natural (NLP)Una tarea que se resuelve muy bien utilizando redes neuronales es el procesamiento de lenguaje natural (PLN), que en particular es del interés del autor. La tarea de traducción de idiomas, por ejemplo, se resuelve utilizando estas técnicas. Para esta tarea hubo una mejora muy significativa el año 2018, mediante la técnica denominada “transformer”, publicada en el artículo “Attention is all you need”18, que permite predecir con mucha exactitud qué palabra viene, dada la anterior, en un contexto. Este trabajo fue principalmente desarrollado en los laboratorios de Google®, presentado en la 31stConference on Neural Information Processing Systems, USA. Esta tecnología es transferible a muchas otras áreas.
8DatosEtimológicamente el término dato proviene del latín datum que representa “lo que es dado” (hecho o información). La Real Academia Española (RAE) define al dato como “información sobre algo concreto que permite su conocimiento exacto o sirve para deducir las consecuencias derivadas de un hecho”. Desde el punto de vista de la ciencia de datos, es la unidad mínima que describe un atributo de un objeto, que puede ser cualitativa o cuantitativa; ésta última a su vez puede ser discreta o continua.
Según cómo se registran y almacenan, los datos se pueden clasificar en estructurados y no estructurados. Su forma óptima de almacenamiento es mediante bases de datos.
Datos no estructurados. Son aquellos datos que no tienen una estructura definida, como por ejemplo el texto libre que se escribe en una evolución médica o en un protocolo quirúrgico, archivos de audio, etc.
Datos estructurados. Son datos que tienen un orden establecido para el cual son diseñados, generalmente almacenados en listas, tablas o en formatos de diccionarios de datos. Los datos tabulares son una colección de objetos con sus características, estructurados en un sistema de datos de 2 dimensiones de filas y columnas, en que cada columna representa un atributo y cada fila representa un registro único u objeto con los atributos que lo definen. Una lista es un conjunto de registros de 1 dimensión, por lo cual una tabla se puede considerar como un conjunto ordenado y simétrico de listas.
9Bases de datosLas bases de datos son un conjunto organizado de datos estructurados almacenados mediante tablas que se relacionan entre sí por índices únicos, optimizado para consultas sistemáticas complejas con reglas definidas en un modelo entidad-relación, propuesto por Edgar Codd en 197019. Los motores de bases de datos o sistemas gestores de bases de datos son software especializados que permiten almacenar, agregar, modificar y consultar datos de manera expedita, segura, escalable y optimizando los recursos de cómputo. El lenguaje más ampliamente utilizado en estas herramientas es SQL (Structured Query Language)19, que a su vez permite agrupar las bases de datos en SQL(relacionales) y no-SQL (no relacionales), de acuerdo con el diseño y formato en que son almacenadas y a su demanda de cómo son consultados.
10Big dataBig data es un término vagamente definido. Se puede considerar como big data a un gran volumen de datos de diferentes fuentes con distintas estructuras y que va aumentando de manera rápida y constante. Estas características hacen imposible procesar estos datos con técnicas computacionales tradicionales, requiriendo gran poder computacional. Como no es una definición exacta y fija a través del tiempo, tanto en cantidad de datos como en su cómputo, se han establecido por consenso “las 5 v del big data” para considerar que un conjunto de datos es big data: volumen, variabilidad, velocidad, veracidad y valor.
Específicamente en salud, durante la última década hubo un aumento explosivo en la cantidad de información clínica almacenada digitalmente en forma de historiales de salud electrónicos (EHR, electronic health records). Y aunque inicialmente su propósito era más bien de registro y gestión administrativa, los datos ciertamente han comenzado a ser utilizados por investigadores para el desarrollo de modelos analíticos cada vez más complejos. Los EHR se han empleado para optimizar procesos clínicos como la precisión diagnóstica, la readmisión hospitalaria, la estimación de duración de una hospitalización y el pronóstico de mortalidad intra-hospitalaria20,21, entre otros.
11Ciencia de datosLa ciencia de datos, entonces, no es más que la integración de estas técnicas computacionales modernas de procesamiento de grandes volúmenes de datos, con matemática y estadística, y con los expertos del dominio del cual se necesita realizar una tarea específica para resolver un problema que ellos conocen.
Se le denomina “ciencia” pues utiliza el método científico para los experimentos de entrenamiento, evaluación e iteración de distintas técnicas computacionales, y así obtener los mejores resultados posibles (minimizar el error) en la generalización para ser reproducibles en la práctica real. Dentro de esta metodología, sus principales etapas son: definir claramente el problema a resolver (output), definir la fuente de obtención de los datos y de éstos cuáles son útiles para resolver el problema (input), limpieza y transformación de datos para que puedan ser utilizados apropiadamente, diseñar a implementar modelos de ML para solucionar la tarea, implementar modelos simples de comparación, iterar la experimentación de los modelos suficientes veces hasta lograr las métricas esperadas en el diseño, y finalmente concluir acerca de los resultados obtenidos.
Una metodología utilizada en el ciclo de vida de los datos es el proceso KDD (Knowledge Discovery in Databases), propuesto por Fayyad en 199622 para obtener información de grandes bases de datos, mediante la acción reiterada de los siguientes pasos:
- 1.
Selección de los datos. Definir el subconjunto de datos desde los que se hará la extracción.
- 2.
Pre-procesamiento. Eliminación de ruido o datos irrelevantes y gestión de datos faltantes.
- 3.
Transformación. Representar los datos de forma útil para la tarea a realizar.
- 4.
Minería de datos (data mining). Decidir el propósito del modelo: clasificación, regresión, clustering, etc. Consiste en elegir el modelo y los parámetros apropiados para encontrar patrones en los datos.
- 5.
Interpretación y evaluación. Analizar el resultado de la minería de datos y definir una métrica para determinar qué tan bueno o malo es para resolver la tarea.
- 6.
Conocimiento. Generar visualización de datos mediante reportes, tablas o gráficos en los que se representen los resultados de la minería de datos.
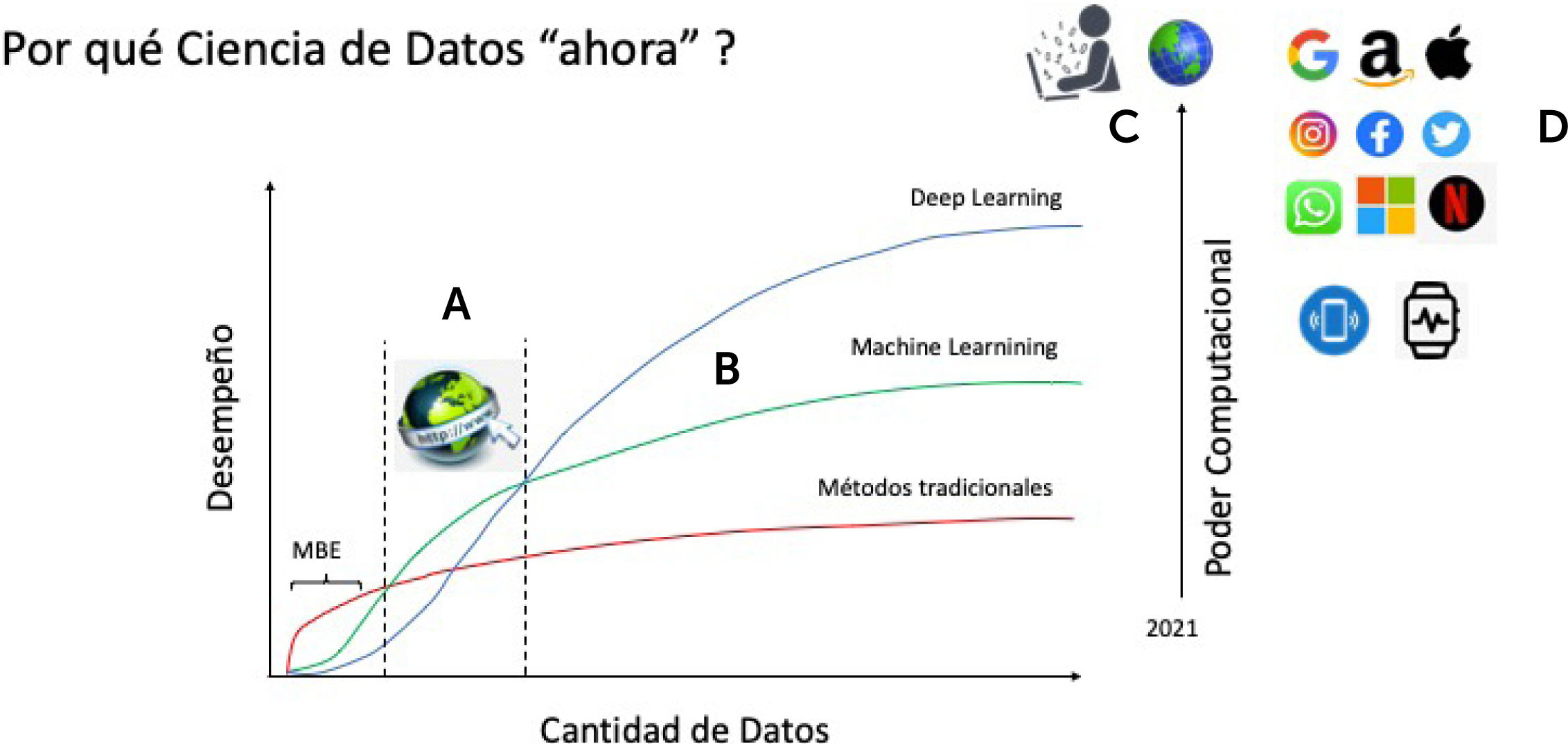
A medida que va aumentando la cantidad de datos almacenada, si para su procesamiento se evalúa el desempeño de las distintas técnicas, se pueden obtener 3 escenarios que se representan en la Fig. 5.

Esquema del desempeño de distintos métodos de procesamiento de datos, de acuerdo con la cantidad de datos. A. Periodo de aparición y expansión de internet, y su rol como fuente de datos masivos. B. Representación del poder computacional requerido a medida que aumenta la cantidad de datos y las técnicas computacionales empleadas. C. Punto de confluencia de gran cantidad de datos con gran poder computacional. D. Ejemplo de empresas internacionales que procesan grandes volúmenes de datos. MBE: Medicina Basada en la Evidencia. Creative Commons Licence, © Javier Mora.
Se ha demostrado que los métodos estadísticos tradicionales (modelados con una función lineal) tienen muy buen rendimiento con pocos datos, pero rápidamente su desempeño se “estanca” y llega a un “máximo” independiente de la cantidad de datos que procese, e incluso algunas empeoran su desempeño con un gran volumen de datos. La medicina basada en la evidencia se encuentra en gran parte (sino casi en su totalidad actualmente) en esta área de acción, que no es menos importante que el ML, sino que cumple su rol con la cantidad de datos y técnicas estadísticas que tradicionalmente se utilizan en salud.
Luego, las técnicas de ML en general con pocos datos se comportan peor que las técnicas tradicionales, pero llega un punto en que con mayor cantidad de datos su rendimiento las supera significativamente, sin llegar a un techo sino más bien persistentemente aumentando con más datos.
Las redes neuronales profundas o DL, por su parte, con pocos datos se comporta aún peor, pero con mayor cantidad de datos es todavía significativamente mejor. A su vez, mientras más “profundas” son las redes neuronales, se puede obtener un rendimiento aún mejor (Fig. 5).
Lo que determinó que estas técnicas superaran a las técnicas tradicionales y demostraran todo su potencial fue la aparición de internet a fines de los años 90s.
El costo que se debe pagar para poder procesar el mayor volumen de datos que se dispone con estas técnicas para un mejor rendimiento es el poder de cómputo, es decir, computadores cada vez más potentes tanto en poder de almacenamiento como de procesamiento de datos en serie (CPU) y paralelo (GPU), y actualmente con el desarrollo de las TPU (Tensor Process Unit) especialmente diseñadas para el cómputo matemático de tensores (operaciones algebraicas entre matrices de muy alta dimensionalidad [millones]).
De esta manera, podemos decir que estamos asistiendo en esta última década a un momento histórico en un punto del tiempo donde se juntan gran cantidad de datos, con gran poder computacional. Pero quienes realmente tienen esa gran cantidad de datos y ese poder computacional son las grandes compañías tecnológicas y telefónicas internacionales, las que son capaces de recolectar datos desde todo el mundo constantemente y procesarlos en tiempo real (Fig. 5).
Por otra parte, cabe mencionar que actualmente el poder computacional está mejor optimizado en la arquitectura denominada “cloud computing” o computación en la nube con recursos escalables, por sobre el uso de grandes computadores de escritorio o servidores de manera local, tanto en eficiencia del uso proporcional de recursos computacionales (a demanda) como en seguridad. En este sentido, hoy por hoy resulta óptimo para la ciencia de datos en términos de costo-beneficio el contratar espacio y servicios en una nube por sobre la compra directa de sofisticados computadores.
13Ciencia de datos clínicosEn 1986 Eugene H. Blackstone junto con John Kirklin de la Universidad de Alabama, durante el naciente periodo del análisis multivariado de la cirugía cardíaca, fueron pioneros en promover modelos paramétricos de funciones de riesgo multifase para generar predictores de resultados paciente-específicos23. La evolución de estos métodos y sus aplicaciones ha sido muy interesante, y destaca la compleja presentación de la “analítica de datos” en esa época inicial24, seguido a lo largo de los años por una progresiva simplificación de las técnicas, que coincidió con una mayor aceptación y aplicación más amplia de estos métodos25.
Con la constante aparición de nuevos procedimientos médicos y técnicas quirúgicas, junto a la enorme cantidad de datos generados en el cuidado de los pacientes en las últimas décadas, una nueva disciplina científica denominada “ciencia de datos clínicos” ha emergido. Su principal rol es mejorar la calidad del cuidado médico y su valor mediante la captura, organización, procesamiento y modelamiento de datos26. Las fuentes de datos pueden ser muy diversas en su origen y forma de registros o tipo de datos, donde la ciencia de datos clínicos toma protago-nismo para reunirlos y obtener información valiosa con técnicas computacionales modernas que de otro modo sería imposible hacerlo o demandaría gran cantidad de tiempo y recuersos físicos y humanos. Sobre estas bases científicas, se han desarrollado prometedoras aplicaciones de IA y ML con el fin último de apoyar la toma de decisiones clínicas y quirúrgicas, que contribuyan a mejorar la seguridad de los pacientes27.
A diferencia del modelamiento de datos “tradicional” basado principalmente en técnicas de regresión y funciones lineales, utilizando una limitada cantidad de datos, la ciencia de datos clínicos aprovecha las técnicas de ML para aprender relaciones entre características de los datos con poca intervención del ser humano y así detectar o extraer esas características, disminuyendo los sesgos y el sub-procesamiento de datos, y en algunos casos superando el paradigma del “consenso de expertos”, que pueden dejar fuera valiosa información. Técnicas de ML supervisadas y no supervisadas han sido usadas para evaluar la competencia del médico en una variedad de entornos o situaciones28.
Un buen ejemplo de cómo la ciencia de datos clínicos puede ser usada para iniciativas de mejora en calidad es el “sistema de caja negra en pabellón”29,30. Esta plataforma analítica permite la captura e integración de una amplia variedad de datos intra-operatorios (como audio, video y parámetros fisiológicos), permitiendo obtener métricas tanto humanas como otras basadas en IA. Recientes estudios han estado utilizando este sistema para investigar rendimiento quirúrgico técnico y no técnico y su relación con el resultado final del paciente30,31. Más recientemente, algunos estudios han podido demostrar la factibilidad y validez de algoritmos de ML para la predicción precoz de complicaciones intraoperatorias, como hipotensión e hipotermia tanto en cirugías cardíacas como no cardíacas4,32.
14Aportes de la ciencia de datos clínicos aplicados en cirugía, con énfasis en cirugía cardíacaEn 2018, Wojnarski et al33 utilizaron algoritmos de agrupación no supervisados (clustering) a un conjunto de datos de 656 pacientes portadores de válvula aórtica bicúspide que se sometieron a cirugía de aorta ascendente en la Cleveland Clínic (Ohio, USA) durante un período de 12 años. Con esta técnica encontraron similitudes en datos no categorizados que, luego agrupados por técnicas de similitud, permitió procesar una gran cantidad de variables para descubrir patrones no conocidos. El resultado fue una nueva clasificación de la aortopatía bicúspide que por primera vez estableció una relación estadística entre las formas de las válvulas bicúspides y los patrones de los aneurismas aórticos.
Otra aplicación de IA en cirugía basada en datos tiene relación con la evaluación del rendimiento intraoperatorio individual y en equipo, como el uso de la visión por computadora, que ofrece una promisoria oportunidad para automatizar, estandarizar y escalar la evaluación del rendimiento en una cirugía. Investigaciones previas han documentado la fiabilidad del análisis de movimientos quirúgicos basados en videos para evaluar el rendimiento laparoscópico en el mismo pabellón, en comparación al enfoque de un evaluador humano que requiere mucho tiempo34. Azari et al. compararon la evaluación de calificación por un cirujano experto con la evaluación por computadora de habilidades de técnicas quirúrgicas, como suturas y nudos, incluyendo fluidez y eficacia del movimiento y la manipulación de los tejidos35, documentando una mejor evaluación y aprendizaje con estos sistemas.
En el cada vez más altamente tecnológico ambiente de trabajo en la sala de operaciones, se han incorporado nuevos sistemas computacionales al flujo de trabajo clínico, con la finalidad de optimizar procesos y apoyar al equipo quirúrgico36. Este ambiente computacional complejo ha permitido también el aumento del conocimiento humano tanto a nivel individual como en equipo37, incorporando sistemas de procesos no-humanos involucrados durante el transcurso de una cirugía.
La cirugía cardíaca es un perfecto ejemplo de cómo la IA puede ser utilizada para apoyar el cuidado quirúrgico mediante amplificación de la inteligencia de procesos en un ambiente complejo y de alto riesgo, con equipamiento altamente tecnológicos38. Funcionando como un sistema complejo, el equipo cardioquirúrgico desarrolla tareas altamente coordinadas, requiriendo habilidades cognitivas que van más allá del rendimiento de cada miembro del equipo en forma individual. Como cada uno de éstos no puede tener control del rendimiento de todo el equipo, la optimización de inteligencia de procesos es más relevante al trabajo de todo el equipo que sólo a tareas individuales39.
Sistemas existentes de IA son capaces de recolectar, procesar y dar sentido a información reunida en una sala de operaciones40. Sin embargo, un importante requerimiento para estos sistemas es la habilidad de entender y adaptar algoritmos basados en información contextual en tiempo real, permitiendo proveer soporte en el contexto de una situación clínica particular41,42. Para poder apoyar y orientar tareas cognitivas del equipo multidisciplinario, un sistema de IA debería anticipar eventos futuros usando información pasada y en tiempo real de las distintas fuentes de datos en la sala de operaciones a medida que ocurren, tanto humanas como no humanas43.
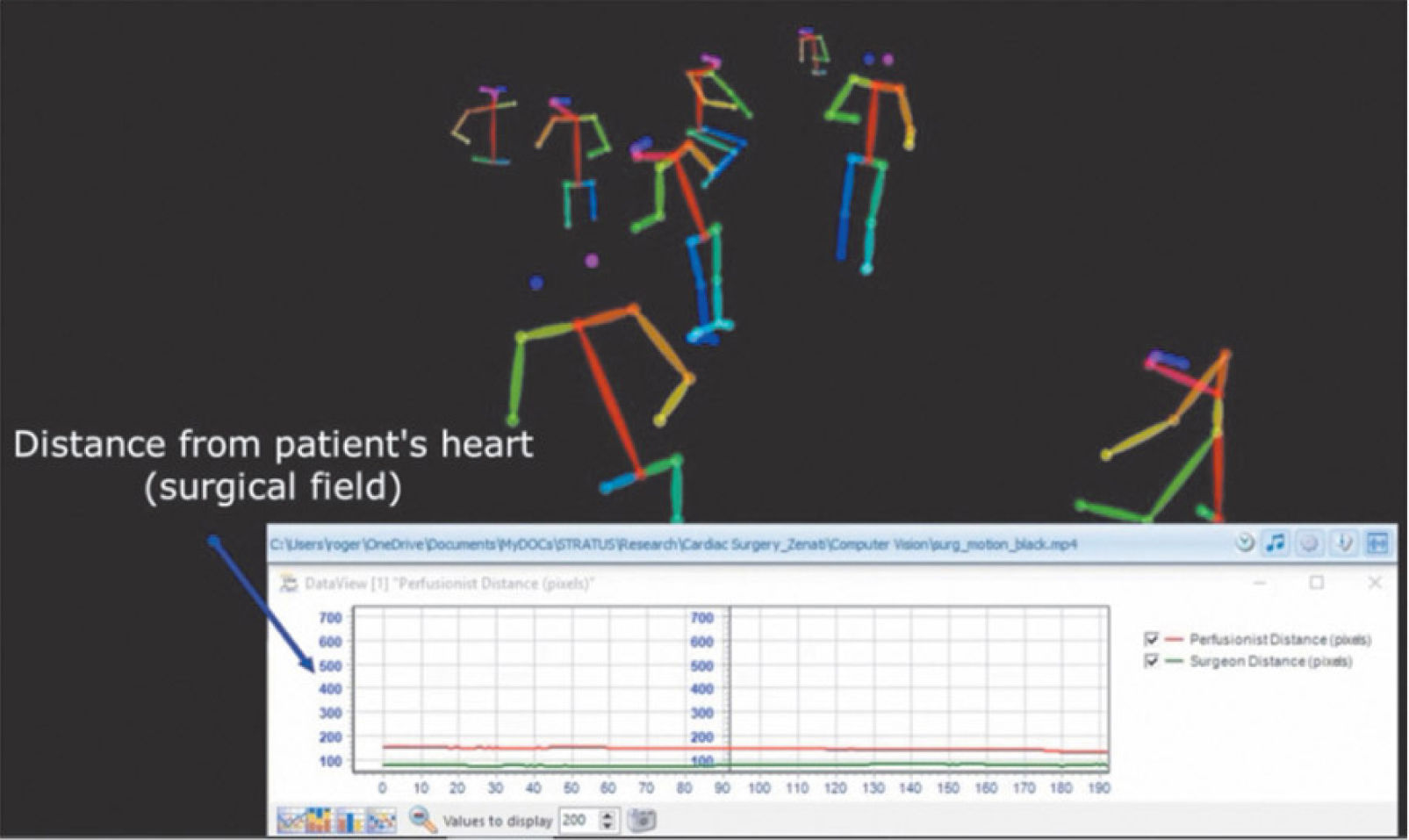
Por otra parte, en la utilización de datos de imágenes y videos, para englobar todos los avances y potencialidad futura del uso de la IA en la actividad clínica y quirúrgica, recientemente se ha creado un campo interdisciplinario denominado “cirugía inteligente” (cognitive surgery) o “cirugía guiada por inteligencia” (cognition-guided surgery)41, que envuelve a las técnicas de visión por computadora aplicadas a la cirugía. Sus principales aplicaciones están relacionadas con segmentación del flujo de trabajo quirúrgico44,45, detección y reconocimiento de instrumental46, intervenciones quirúrgicas guiadas por imágenes47, seguimiento de gestos y movimientos del cirujano para extraer métricas objetivas de habilidades psicomotoras en técnicas específica, entre otras. Además, una nueva área aplicada en procedimientos complejos dependientes del trabajo en equipo, como en cirugía cardíaca, es en el estudio del comportamiento, la dinámica y la coordinación del equipo y de sus individuos en la sala de operaciones. La centralidad y proximidad de los miembros del equipo son ejemplos de métricas de comportamiento investigados en estos estudios48,49 (Fig. 7).

Sistema de visión por computadora registrando la posición y movimientos de los integrantes de un pabellón de cirugía cardíaca48.
En la Cleveland Clinic (Ohio, USA) se estableció en el 2019 un centro multidisciplinario para IA clínica (Center for Clinical Artificial Intelligence). Mantiene un registro clínico cardiovascular computacional desde 1971 recolectando datos de cada cirugía cardíaca. Dentro de sus principales líneas de trabajo de la ciencia de datos clínicos en cirugía cardiotorácica ha desarrollado:
Creación de modelos predictivos comparativos de sobrevida en pacientes con varias intervenciones quirúrgicas para cardiomiopatía isquémica50
Actualización continua de la estimación del riesgo de mortalidad para pacientes en lista de espera para transplante cardíaco51 Selección de variables para el estadío de cáncer esofágicos
15Ciencia de datos clínicos en clínica las condesClínica Las Condes cuenta con registro médico electrónico desde el año 2009 de forma sistemática e ininterrumpida, con un sistema de clase mundial, siendo uno de los centros de salud en Chile con más experiencia en esta área y con el mayor corpus de datos clínicos electrónicos.
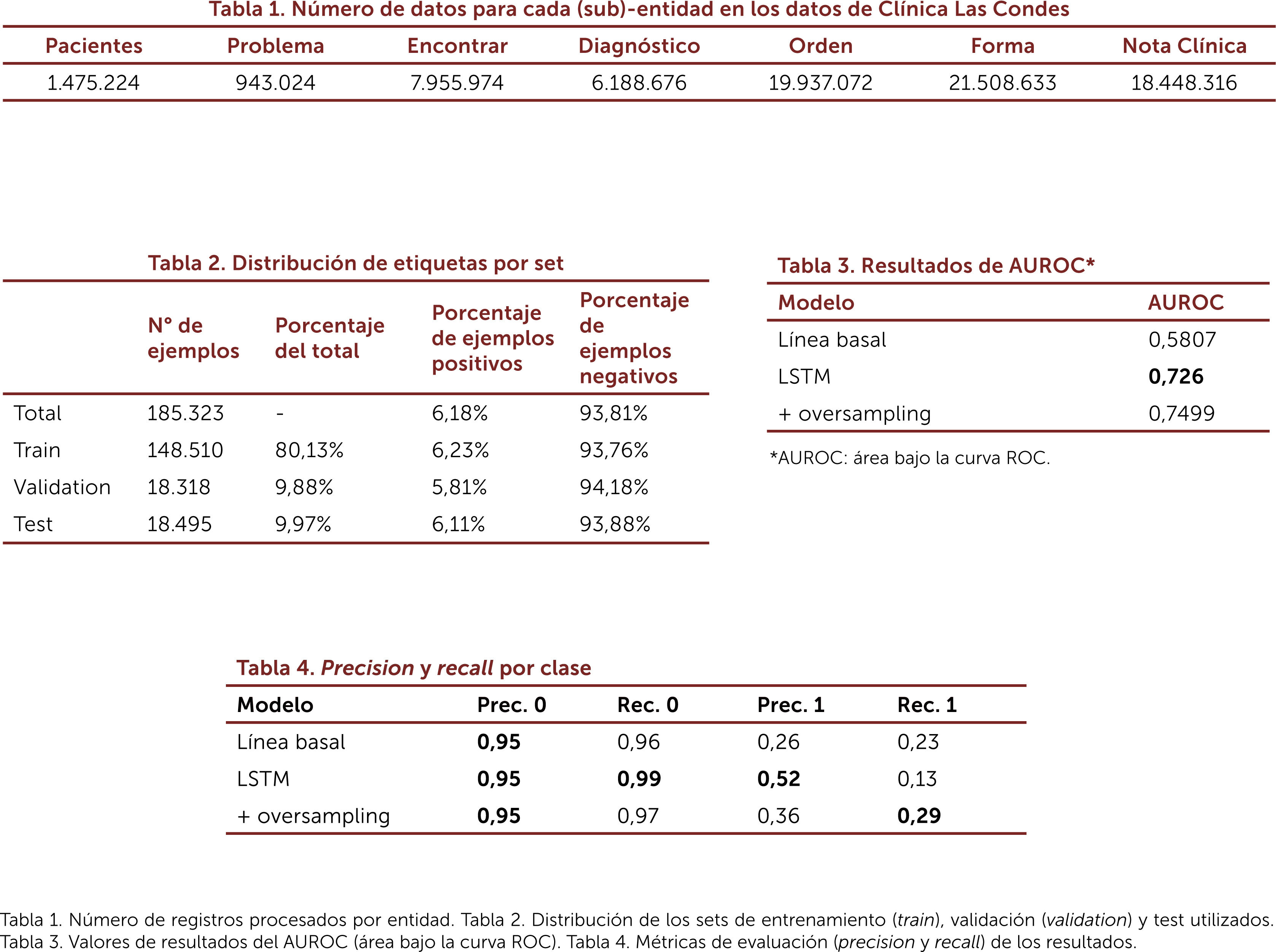
En 2019 desarrolló con datos propios, un modelo predictivo de rehopitalizaciones utilizando Redes Neurales Profundas (DL). Mediante este trabajo, “Predicting unplanned readmissions with highly unstructured data” presentado el en año 2020 en la 8thInternational Conference on Learning Representations específicamente en el workshop AI for affordable healthcare52, se obtuvieron con datos propios en español un 76% de “accuracy” (métrica de evaluación) para predecir una rehospitalización no planificada dentro de los siguientes 30 días al alta, con cualquier diagnóstico y por cualquier causa. Estos resultados fueron comparables a los mejores modelos publicados a la fecha del trabajo en la literatura internacional, pero con corpus de texto clínico en idioma inglés (AUROC 0,77 y AUROC 0,76)16. Se utilizaron datos anonimizados de casi un millón y medio de pacientes en 8 años de registros, procesando alrededor de casi 60 gigabytes de datos (Fig. 6). Esta publicación fue el primer modelo predictivo de rehospitalizaciones con datos chilenos y en español12.

Tablas de resumen del trabajo “Predicting unplanned readmissions with highly unstructured data”52.
El procesamiento de datos clínicos desde un EHR es particularmente complejo debido a la heterogeneidad de estos (numéricos, temporales y series de tiempo, categóricos, texto libre, imágenes)21. Existe también una dependencia temporal por la relación entre los eventos clínicos, pero no en el conjunto de información que compone un encuentro. Además, existe irregularidad temporal en la ocurrencia de las visitas y la densidad de la distribución de ellas entre distintos pacientes, o incluso en distintos periodos del mismo paciente53. Nuestro trabajo nos permitió comprobar que mediante DL se logra mejores resultados en este tipo de modelos predictivos, como ya ha sido publicado con texto en inglés12,21.
Este año hemos creado en Clínica Las Condes una Unidad de Ciencia de Datos Clínicos (como un área de desarrollo del Centro de Innovación en Salud, CIS), dedicada a diseñar e implementar una gobernanza de datos clínicos, de tal manera de facilitar el acceso a los datos en forma eficiente y segura para la institución, junto con generar constantemente nuevo conocimiento y aplicaciones en el área de fundamento de los datos aplicados a la salud con técnicas computacionales modernas.
Tabla 1. Número de registros procesados por entidad. Tabla 2. Distribución de los sets de entrenamiento (train), validación (validation) y test utilizados. Tabla 3. Valores de resultados del AUROC (área bajo la curva ROC). Tabla 4. Métricas de evaluación (precision y recall) de los resultados.
Surge cada vez más evidencia en el desarrollo de algoritmos computacionales innovadores y en la expansión del uso de modelos cognitivos humanos para ser aplicados mediante IA, dando espacio a nuevas formas de trabajo en equipo entre el ser humano y máquina en aplicaciones al cuidado de la salud54.
En cirugía cardíaca, se han desarrollado nuevos sistemas que integran datos fisiológicos del equipo quirúrgico con datos del paciente y de los dispositivos del pabellón, como un indicador de rendimiento que podríamos denominar “inteligente”55,56. Nuevos estudios de ML entregan herramientas basadas en datos para optimizar la comunicación y coordinación del equipo multidisciplinario en una sala de operaciones, que ayuda a mitigar errores en un sistema complejo como lo es un pabellón de cirugía cardíaca57,58.
La evidencia de ciencia de datos clínicos en el mundo comienza a ser cada vez más relevante. Blackstone et al51 propusieron un sistema de “analítica dinámica” de predictores de mortalidad en pacientes en lista de espera para transplante cardíaco, que “sigue” al paciente a través del tiempo actualizando continuamente la predicción de moratalidad basado en eventos adversos y en resultados seriados de indicadores de laboratorio, como un modelo de riesgo continuo59.
Sin duda las técnicas computacionales modernas aplicada en medicina han venido para quedarse. No deja de sorprender cómo a partir de la formulación de las ideas simples de problemas complejos de Alan Turing en la primera mitad del siglo XX, hoy contamos con herramientas computacionales tan poderosas y sofisticadas como las que conocemos actualmente, y en forma transversal con soluciones que impactan en toda la sociedad, incluyendo la medicina en general y la cirugía cardíaca en particular. Conocer sus conceptos y entender sus aplicaciones es fundamental. El desarrollo de la ciencia de datos clínicos así lo demuestra, tanto en el ámbito público como privado, y los profesionales con estos conocimientos son cada vez más requeridos. “Los médicos no serán reemplazodos por algoritmos; sin embargo, los sistemas de salud que no usen ML serán reemplazados por aquellos que sí lo hacen” (Ran Balicer, World Medical Association Conference, Tel Aviv, Israel, 2019).
Declaración de conflicto de interésEl autor declara no tener conflictos de intereses.