






Evaluar el rendimiento de ChatGPT-4 para resolver escenarios clínicos de oftalmología, en concreto preguntas de la especialidad de los exámenes a médico interno residente (MIR).
DiseñoDiseño transversal de evaluación de herramienta diagnóstica.
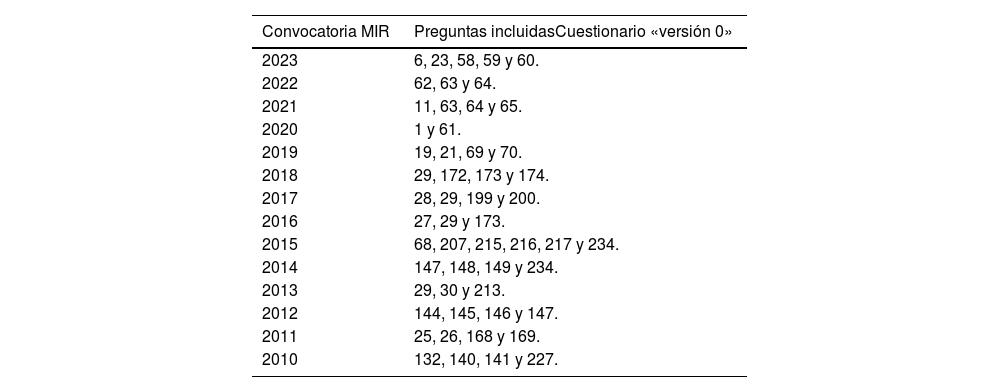
MétodoSe han recopilado las preguntas de oftalmología de los exámenes MIR de las convocatorias 2010-2023. Se ha calculado el rendimiento de ChatGPT-4 para resolver exitosamente las cuestiones planteadas. Por otro lado, ha comparado los resultados con los obtenidos por profesionales oftalmólogos. Además, se han calculado la sensibilidad, especificidad y coeficientes de probabilidad positivo y negativo.
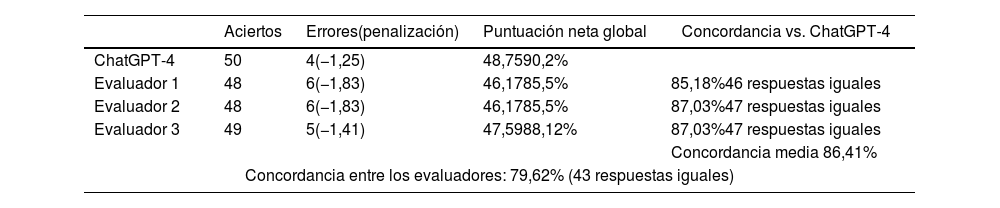
ResultadosSe recopiló un total de 54 preguntas, siendo las de la subespecialidad «Retina» las más frecuentes. La puntuación global de ChatGPT fue del 90,2%, con una sensibilidad del 92,59% y una especificidad del 96,8%. La concordancia media con las respuestas de los evaluadores fue del 86,41%. La concordancia entre los evaluadores fue del 79,62%.
ConclusionesChatGPT-4 es una herramienta útil para resolver escenarios clínicos y preguntas teóricas oftalmológicas. Una adecuada utilización de la herramienta, supervisada por profesionales, puede servir para optimizar los procesos asistenciales de los pacientes oftalmológicos.
To evaluate the performance of ChatGPT in solving clinical scenarios in ophthalmology, specifically questions from the specialty exams for Resident Medical Interns (MIR).
DesignCross-sectional design for evaluating a diagnostic tool.
MethodOphthalmology questions from the MIR exams from the 2010-2023 sessions were collected. The performance of ChatGPT in successfully answering the questions was calculated. The results were also compared with those obtained by ophthalmology professionals. Additionally, sensitivity, specificity, and positive and negative probability coefficients were calculated.
ResultsA total of 54 questions were collected, with those from the subspecialty “Retina” being the most frequent. ChatGPT's overall score was 90.2%, with a sensitivity of 92.59% and a specificity of 96.8%. The average concordance with the evaluators’ answers was 86.41%. The agreement between the evaluators was 79.62%.
ConclusionsChatGPT-4 is a useful tool for solving clinical scenarios and theoretical questions in ophthalmology. Proper use of the tool, supervised by professionals, can help optimize the care processes for ophthalmology patients.
