






The rapid integration of generative AI (GenAI) into industries and society has prompted a re-evaluation of copyright and intellectual property rights (IPR) frameworks. GenAI's ability to produce original content using data from human-created sources raises critical ethical and legal concerns. Current copyright and IPR frameworks, designed around human authorship, are insufficient to address these challenges. This study, using a multi-perspective approach, explores GenAI's disruptive potential in replicating or transforming copyrighted materials, challenging established IPR norms. Findings highlight gaps in legislation and the opacity of GenAI platforms. To address these issues, this study presents a Dynamic Ethical Framework linked to a future global fair use policy, aiming to guide responsible GenAI development and use. By incorporating insights from domain experts, this study contextualizes emerging challenges and potential solutions within broader societal and technological trends. That said, this study calls for international collaboration and further research to reform IPR related laws and frameworks, ensuring they remain relevant and equitable in a GenAI-driven era.
Generative Artificial Intelligence (GenAI) utilises machine learning and deep learning technologies, employing algorithms such as Generative Adversarial Networks (GANs) and transformer models to create new content based on user prompts (Dwivedi et al., 2023). Open AI's ChatGPT was launched in November 2022 and quickly reached 100 million users, becoming the fastest-adopted consumer application in history (Hu et al., 2023). OpenAI's Generative Pre-Transformer (GPT) models are trained on vast datasets to produce content that is often indistinguishable from that created by humans and has the potential to revolutionise how work is undertaken across industries and business functions (MIT Technology Review, 2023). The impact that GenAI will have on global economies is likely to be transformational with estimates between US$2.6 and $4.4 trillion of value added to the global economy each year, thereby increasing the total economic impact of AI by 40% (McKinsey & Company, 2023). It is predicted that AI will automate half of all work between 2040 and 2060, and that the impact of GenAI will accelerate this progress, a decade earlier than previous estimates (MIT Technology Review, 2023). The capabilities of GenAI to create new content in the form of text, images, software, and now with the advent of OpenAI's Sora, the ability to create video from text-based input, is nothing short of staggering. GenAI tools such as ChatGPT, Gemini and Bing AI - utilise Large Language Models (LLMs) that have been trained on billions of diverse data sources and parameters including: internet data, academic journals, books and news articles (Dwivedi et al., 2023; Lucchi, 2023). However, confusion exists on the detailed process and legality of the LLM training process, due to the minimal levels of transparency and accountability from GenAI providers. This has profound legal and ethical consequences related to the protection of human creativity, authorship, and content ownership (Frosio, 2024).
The training of LLMs and widespread use of GenAI has revealed a set of complex and evolving legal challenges surrounding the use of GenAI technologies, particularly concerning copyright and the notion of authorship (Bonadio et al., 2022a; Salami, 2021). Copyright is a specific type of intellectual property that protects original authorship, such as literary, artistic, musical, and other creative works. Copyright grants the creator exclusive rights to use, distribute, and modify their work, typically for a limited period. Intellectual property rights (IPR) refers to the broad set of legal rights that protect human creation such as artistic works, inventions, designs and images (Hugenholtz & Quintais, 2021). Although copyright laws cover direct copies of pixels, text and software, the imitation content developed by GenAI, is based on LLMs effectively trained by digesting and utilising the original copyrighted data, somewhat negating the “AI generated” new content claim (Dwivedi et al., 2023). The emergence of AI as a non-human creator, directly challenges the existing legal infrastructure built around the human creator (Frosio, 2024; Liu et al., 2023). This presents a number of complexities - for example in a scenario where an artist utilises a GenAI tool to create a digital artwork, the AI produces the artwork based on the styles and influences from LLM trained copyrighted works. The original artist could claim copyright over the AI generated works arguing that their original artwork was used, whereas the digital artist and GenAI platform could perhaps argue that the AI output is derivative work. These issues have led some artists and content creators to initiate legal action against organisations such as Stable Diffusion and also Midjourney in the Getty case, over improper use of 12 million licenced photos (Reuters, 2023). Claims of software piracy have been made against OpenAI and Microsoft over the creation of Copilot - now integrated into MS Office 360 (Jo, 2023; Kahveci, 2023). Researchers have emphasised the misinformed narrative of purely AI-generated work and the fact that it does not currently exist, there is always a human creator in the loop somewhere, and the concept of AI-generated work is overly simplistic and potentially misleading, acting as a disservice to those seeking to experiment creatively with GenAI systems (Dwivedi et al., 2023; Fenwick & Jurcys, 2023; Lim, 2023).
The Wall Street Journal's interview with OpenAI's Chief Technology Officer (CTO) - Mira Murat in March 2024, on OpenAI's latest AI image generation system Sora, highlighted concerns about the potential misuse of copyrighted work to train AI models and the lack of transparency from OpenAI regarding its data practices. The responses from the OpenAI CTO led many commentators to question whether the organisation has adequately safeguarded the rights of content owners and creators (Wall Street Journal, 2024). The “arms race” for developing AI products has demonstrated questionable adherence to IPR with Meta admitting to using both Instagram and Facebook content to train its Llama 2 LLM based model. These practices and the potential for big tech companies such as Alphabet with its access to huge levels of Google controlled internet data, to utilise the vast data resources at their disposal, raising significant ethical concerns relating to consent and copyright of user data during the training of LLMs (Business Insider, 2024).
The existing legal system is being asked to adjudicate on the bounds of what constitutes “derivative works” (an essential element of the creation process building on existing works and creating something new and innovative) and the interpretation of fair use doctrine, which allows copyrighted work to be used without the creators permission for: commentary, criticism, teaching and research use; the outcome of which is a profound destabilisation of copyright law (Amankwah-Amoah et al., 2024; Appel et al., 2023; Crawford & Schultz, 2024; Gans, 2024; Jodha & Bera, 2023). The absence of a traditional mechanism of authorship in AI-generated content creation, could potentially shift the economic benefits away from human creators towards those who own or operate the AI technologies and platforms (Israhadi, 2023). This shift could significantly impact the livelihoods of artists, writers, and other creators, potentially leading to economic disparities and a devaluation of human creativity (Crawford & Schultz, 2024; Dwivedi et al., 2023). Balancing the transformational technological advances now possible with GenAI together with the preservation of content creators’ rights to compensation, is critical to navigating the copyright landscape in this new era (Lee et al., 2024; Liu et al., 2023; Lucchi, 2023).
Whilst a limited number of studies have sought to shed light on the implications for copyright and IPR from the widespread use and adoption of GenAI (Dwivedi et al., 2023; Fenwick & Jurcys, 2023; Lucchi, 2023; Zhong et al., 2023), this emerging research area is somewhat lacking a deeper analysis of the multitude of complexities facing content creators and policy makers. We assert that by developing a multi-contributor perspective on the critical aspects of GenAI, copyright and IPR, we create valuable new insight and the establishment of a new research approach and research agenda. This study, therefore, aims to conduct a detailed examination of the various challenges posed by GenAI. We advocate for a proactive, informed, debate and research agenda relating to copyright law and intellectual property with an appeal to move from engaged to generative scholarship that takes into account misuse case analysis for prospective theorisation. We posit that this approach can develop much needed focus on values and creativity of the human in the loop to ethically and responsibly navigate within this complex landscape.
The remainder of this study is organised as follows. The next section outlines the approach to the study and examines the impact this research style has had on the development of literature on emerging phenomena and its influence on policy. Section 3 presents the individual expert contributions that cover the range of perspectives and insights to this subject. The Discussion is outlined in section 4 where we discuss the key themes from the contributions and present the Dynamic Ethical framework. The paper is concluded in the final section.
ApproachThis study is consistent with prior research that employs a multi-perspective expert-based approach, initially proposed by von Foerster (2003) and subsequently developed by Dwivedi et al., (2024; 2023; 2021). This method concentrates on gathering valuable insights from authoritative contributors on cutting-edge research themes. This study invited specialists from both academia and practice to discuss the critical issues related to GenAI and its impact on copyright and intellectual property rights (See Table 1 for the list of contributions included in this study). Each contribution offers distinct insights and viewpoints, reflecting their dual expertise in academia and/or practice. This collaborative approach offers valuable insight, especially when the topic at hand has been minimally explored within the existing literature or is an emerging issue that has yet to be thoroughly explored within the extant research. Previous research that has adopted this approach, namely Dwivedi et al., (2023), has achieved notable recognition and policy impact, with citations from entities such as the European Union, Joint Research Centre, European Commission, and The Policy Institute (PlumX Metrics, 2024). This underscores the significant impact and broad scope of adopting a multi-expert perspective. Earlier studies using this approach have been widely referenced, helping to shape research agendas on diverse topics such as AI, Smart Cities, Digital Marketing, the Metaverse, and impacts of Covid19, while also expanding the discourse to a broader audience.
Contributors and section titles.
| Section # | Title | Contributors |
|---|---|---|
| TitleAbstractKeywords | Adil S. Al-Busaidi, Raghu Raman, Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi | |
| 1. | Introduction | Adil S. Al-Busaidi, Raghu Raman, Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi |
| 2. | Approach | Adil S. Al-Busaidi, Raghu Raman,Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi |
| 3.1 | The Impact of Generative AI on Copyright and IPR: Emerging Implications | Nicola Lucchi |
| 3.2 | Navigating Legal Landscapes: Copyright Conundrums and Generative Artificial Intelligence | Parul Gupta & Apeksha Hooda |
| 3.3 | Copy, right, copy right, or copyright? A challenge of and for Generative AI | Gareth H. Davies |
| 3.4 | Unlocking the Intersection of Generative AI and Intellectual Property Rights: Moving towards Misuse Case Analysis | Anuragini Shirish |
| 3.5 | Creativity and Information Intermediaries in the Age of Generative AI | Paulius Jurcys & Mark Fenwick |
| 3.6 | The Role of Regulation and Policy in Safeguarding Copyright and Intellectual Property in the Age of AI | Ramakrishnan Raman & Shashikala Gurpur |
| 3.7 | Will copyright and IPR issues constrain GenAI transformations? | Paul Walton |
| 3.8 | Emerging Implications of Generative AI for Intellectual Property Rights | Daryl Lim |
| 3.9 | The synergy between Intellectual Property Rights Agreements, and Artificial Intelligence in safeguarding Food Manufacturing Trade Secrets | Mohammed AlRizeiqi & Adil S. Al-Busaidi |
| 3.10 | Copyright and Generative AI: Is there a Match or is it a Match? | Tanvi Misra |
| 3.11. | Generative AI: Creative Disruption and Legal Intellectual Property Challenges | Adil S. Al-Busaidi & Thuraya Al-Alawi |
| 4. | Discussion | Adil S. Al-Busaidi, Raghu Raman, Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi |
| 5. | Conclusion | Adil S. Al-Busaidi, Raghu Raman, Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi |
| References and Formatting | Adil S. Al-Busaidi, Raghu Raman, Laurie Hughes, Mousa Ahmed Albashrawi, Tegwen Malik & Yogesh K. Dwivedi |
Whilst the multi-expert format could be criticised for an element of overlapping narratives across perspectives, we maintain that the preservation of the unique emphasis of each contributor enriches the overall narrative. Another limitation of the multi-contributor format is the length of the paper. However, this study has limited the contributions to eleven due to the specialised nature of this emerging topic. We argue that the encouraging further debate and discussion on the fast-evolving topic of GenAI and its impact on copyright and IPR is important, and by compiling diverse opinions and perspectives into a single document we provide a valuable resource for readers to compare and contrast a range of views and perspectives. We recommend that readers engage with the paper selectively, focusing on segments that resonate most with their interests and the range of broader themes within the paper. Having listed the sections and their contributors in Table 1, the numbering and section/topic headings are subsequently used in the remaining sections of this paper.
Expert ContributionsThe intricate relationship between generative artificial intelligence (GenAI) and copyright, as well as intellectual property rights (IPR), constitutes a complex and rapidly evolving field of inquiry. This section presents individual contributions,1 as listed in Table 1, that offer alternative perspectives on this emerging phenomenon.
The Impact of Generative AI on Copyright and IPR: Emerging Implications - Nicola LucchiIntroductionIn the era of synthetic creativity, the rapid advancement of GenAI technologies poses unprecedented challenges and opportunities for copyright and other IPRs (Laukyte and Lucchi, 2022). As AI's capabilities extend into the realms of creating complex, original content, from written works to visual arts, the traditional boundaries of copyright law and intellectual property are being redefined. This transformation necessitates a re-evaluation of legal, ethical, and societal norms governing creativity, ownership, and the sharing of intellectual goods (Bonadio et al., 2022a).
The socioeconomic model underpinning GenAI is characterized by two principal features: its dependency on human-generated content, provided without financial compensation, and its aversion to regulatory oversight by public authorities (Lucchi, 2023; Strowel, 2023). This aversion goes beyond traditional private-government interactions, fuelled by shared beliefs about the values of emerging technologies. Despite being based on assumptions that are increasingly recognized as obsolete and misleading, these perceptions persist with the tenacity of long-held habits.
AI systems universally rely on machine learning algorithms, which necessitate vast quantities of data for effective training and subsequent performance optimization (Goldberg, 2017; Lucchi, 2023). From a legal perspective, it is noteworthy that most of this data comes from individuals’ creative work, for which they receive no compensation (Epstein et al., 2023). Furthermore, the acquisition of this data often occurs without obtaining the legally prescribed consent from the copyright holders, which is a critical consideration (Bonadio & McDonagh, 2020; Dornis, 2021; Lucchi, 2023; Senftleben & Buijtelaar, 2020). Given the substantial economic value derived from such data, this situation raises significant ethical and legal concerns. It also presents a paradox where the very essence of a shared digital economy—data—is generously given away, often without a second thought to the potential for financial recompense. Addressing this imbalance requires a nuanced dialogue that extends beyond the scope of this short article. However, it is imperative to acknowledge the role of individual data providers in powering the advancement of AI technologies, and the overlooked potential for compensatory mechanisms to ensure equitable benefit sharing (Geiger and Iaia, 2024).
The Evolution of Creativity in the Age of AIThe rise of GenAI technologies, such as GPT (Generative Pre-trained Transformer),2 Gemini,3 Grok,4 and DALL-E,5 has blurred the lines between human and machine creativity (Bonadio & McDonagh, 2020; Buccafusco, 2016; Dornis, 2020; Ginsburg & Budiardjo, 2019; Guadamuz, 2017; Lucchi, 2023; Mezei, 2023; Sobel, 2017). These AI models can generate textual content, images, and even music that rival the quality of human-produced works, raising profound questions about the nature of creativity and the definition of authorship. The ability of AI to draw from vast datasets of existing works to produce new creations challenges the very foundation of copyright laws built on the concept of human authorship and originality. Yet, we stand at the dawn of this technological revolution with recent advancements, such as multimodal AI systems that seamlessly integrate text, images, and videos, and diffusion models capable of generating hyper-realistic content, reveal the potential for even more sophisticated and intricate forms of machine creativity. These innovations not only expand the boundaries of AI's creative capabilities but also amplify the legal and ethical complexities surrounding intellectual property in ways we are just beginning to grasp.
Legal Challenges and Jurisdictional PerspectivesThe advent of AI-generated content has exposed gaps in existing copyright frameworks, which traditionally recognize only human authors. One of the primary legal challenges is determining the ownership and copyrightability of AI-generated works. The Berne Convention, along with various global copyright norms, does not mandate that works must be authored by humans. However, numerous jurisdictions, including those in the European Union and the United States, underscore the necessity for a human creator behind a copyrightable work. Furthermore, the structure of copyright law is predominantly oriented towards a human-centric perspective. This is highlighted by the Berne Convention's stipulation that the copyright term extends beyond the lifetime of the author for an additional number of years after their death.6 Such a regulation inherently assumes the author's mortality, thus implying human authorship. Jurisdictions around the world grapple with these questions, offering varied responses. For instance, the United States’ copyright law does not currently recognize non-human creators, leaving AI-generated works in a sort of legal limbo.7 Similarly, the approach to copyright within the European Union reveals a nuanced comprehension of AI's contributions, highlighting the necessity for a work to embody the author's “intellectual production” and distinct creative expression to fulfil the criterion of originality.8 This perspective underscores the challenges faced in reconciling AI authorship and creativity model within the framework of copyright law.
Intellectual Property Rights in the Age of Machine LearningAs previously noted, GenAI technologies rely heavily on existing data, including copyrighted materials, to train their algorithms. This practice has sparked debates on the legality and ethics of using copyrighted works to train AI systems without the explicit permission of copyright holders.9 The unresolved question of whether AI-generated works are derivative or wholly original under the law creates uncertainty for creators, users, and AI developers alike. GenAI systems, which include technologies capable of producing art or generating textual content, predominantly utilize vast repositories of human-created data for their training processes. This reliance on pre-existing content generates legal concerns under the current copyright laws. A notable dilemma pertains to the heterogeneous nature of the datasets utilized. While a segment of these datasets comprises content that is informational in nature and not limited by copyright constraints, a considerable portion probably embodies copyrighted materials. This phenomenon is starkly observable in the realms of text processing, facial recognition, and image recognition training datasets, where copyrighted content is frequently incorporated. Such practices invariably solicit legal scrutiny concerning the conditions under which copyrighted materials may be utilized legitimately.
In the United States, the doctrine of fair use introduces a degree of flexibility, allowing limited exploitation of copyrighted materials for specified purposes, including criticism, commentary, research, or teaching purposes.10 In particular, in the domain of AI development and the collection of data for its training, the fair use doctrine under section 107 of the U.S. Copyright Act can play a significant role, traditionally protecting economically important endeavours, as demonstrated by the landmark case of the Google Books project.11 However, its application to the data utilized for AI training awaits more definitive interpretation through future and ongoing case law (Sobel, 2017).12 Despite the potential for broad application, this legal flexibility is circumscribed, with the current absence of explicit guidelines fostering a climate of uncertainty among both AI developers and content creators.
In contrast, the European Union law delineates two distinct exemptions for Text and Data Mining (TDM) :13 the first is specifically designed to support research and innovation within a non-commercial context, and the second, more broad-based exemption, applies to various purposes, provided rights holders have not explicitly prohibited such use.
In particular, the first exemption facilitates the mining of copyrighted content by researchers and entities for scientific research and innovation purposes, without the necessity for explicit consent from copyright holders, contingent upon fulfilment of specific conditions.14 This legislative provision significantly benefits academic and research institutions, empowering them to dissect large data volumes in previously unfeasible manners, thus expediting scientific advancements and innovative breakthroughs. The second, broader exemption applies to any party engaging in such activities with legally accessed works, extending beyond scientific research purposes.15 This exemption allows rights holders to opt out by explicitly reserving their rights. They can do so in a recognizable format, which includes machine-readable indicators for publicly accessible online content, metadata, and the terms and conditions of a website or service. Furthermore, the recently approved EU AI Act stipulates that creators of GenAI systems must devise a compliance strategy with EU copyright laws.16 This entails employing sophisticated technology to acknowledge and adhere to copyright notices. Hence, AI developers are mandated to ensure their systems respect copyright protections by recognizing and abiding by the stipulations set forth by rights owners. This directive ostensibly aims to equip creators with the necessary insights to discern the use of their works as training data, thereby facilitating an informed decision regarding the reservation of their rights for TDM purposes. However, despite the European regulatory framework appearing clearer, in reality, it introduces complexities and stringent conditions that challenge the breadth of permissible use of copyrighted materials (Margoni and Kretschmer, 2022; Senftleben, 2022). This paradoxically creates a scenario where – amid the facade of clarity – the practical application of these rules demands careful navigation to avoid infringement, potentially stifling innovation by limiting access to vital data for AI development and other creative endeavours.
Adapting Copyright and IP in the AI EraIn this evolving landscape, a pressing task emerges for stakeholders. Adapting copyright and IP in the AI era requires lawmakers and policymakers to confront a nuanced challenge: finding a balanced approach. Such balance must protect the rights of intellectual property holders while also nurturing the fertile ground of AI innovation. The rigidity of current copyright laws could choke the growth of GenAI technologies, yet too lenient a stance may leave human creators unprotected and their intellectual contributions undervalued. This delicate balance requires a comprehensive understanding of the technological, legal, and ethical dimensions of AI and creativity.
Recognizing the limitations of current legal frameworks, there is a growing consensus on the need for new paradigms that accommodate the realities of AI-generated content and, more broadly, the emerging ‘synthetic society’ (van der Sloot, 2024). It is this evolving concept of a “synthetic society” that invites us to reconsider traditional notions of creativity and ownership. As AI systems become integral to cultural production, frameworks like joint human-AI authorship or statutory licenses for AI training may become pivotal. Envisioning a future where AI and human creators collaborate seamlessly, the challenge lies in crafting legal norms that not only protect individual contributions but also nurture an ecosystem where innovation and cultural heritage coalesce harmoniously. Proposals include identifying a form of joint authorship between AI developers and human operators, creating new categories of copyright specifically for AI-generated works, and developing international standards to harmonize copyright laws in the age of AI (Bonadio et al., 2022b; Salami, 2021). The consideration of joint authorship between AI developers and human operators, along with the creation of new copyright categories for AI-generated works, appears to be a logical step forward. It acknowledges the collaborative nature of AI-generated content and the blurred lines between human and machine contributions to creative processes. These efforts aim to ensure that copyright and IPR evolve to reflect the changing landscape of creativity and innovation. Regarding the legitimate use of copyright-protected works to train AI systems, there are – for example – proposals to introduce a statutory license for machine learning or an AI levy within copyright law in order to compensate human authors for market share and income losses due to the substitution by GenAI in creative fields (Geiger and Iaia, 2024; Senftleben, 2023). This approach seeks a balance, fostering AI innovation while acknowledging human creators’ contributions. It is rooted in balancing fundamental rights, suggesting a way to compensate creators fairly for their works used in AI training. This idea aligns with evolving copyright laws to support AI's role in creativity and innovation, ensuring creators are rewarded also in this new AI-driven context.
ConclusionAs GenAI continues to reshape the landscape of copyright and IPR, it becomes increasingly clear that existing legal frameworks are ill-equipped to address the complexities of AI-driven creativity. The path forward requires a comprehensive re-evaluation of copyright law and intellectual property rights, with an eye towards fostering innovation while protecting the rights of creators also in this new AI-driven age. This endeavour is not solely the purview of legal professionals but a collective societal task that calls for dialogue, collaboration, and innovative thinking. As we navigate this uncharted territory, the goal must be to create a legal and ethical framework that supports the dynamic interplay between human creativity and AI, ensuring that the AI-powered future is one where technology serves to enhance, not diminish, our shared cultural heritage and intellectual achievements.
Navigating Legal Landscapes: Copyright Conundrums and Generative Artificial Intelligence - Parul Gupta & Apeksha HoodaIntroductionOne hundred million users by the end of two months after launch made Chatbot ChatGPT, a prototype GenAI, one of the fastest-adopted consumer applications. ChatGPT was launched by in November 2022 by OpenAI, a company backed by Microsoft (Hu et al., 2023). While TickTok took nine months to reach this milestone and Instagram reached there in two and a half years after launch, ChatGPT became the fastest-growing technology innovation by acquiring 100 million users in just two months (Chow, 2023). ChatGPT is just one example of GenAI applications which has a built-in algorithm to facilitate continuous learning from input data and future decision-making that may be independent or directed by the user. GenAI applications are capable of generating text, audio, video, synthetic data or even codes (Gordijn & Have, 2023). While GenAI's growing popularity is attributable to its simple user interphase and ease of use, its capability to provide indistinguishable content from human-created content reflects its potential to have significantly large macroeconomic and social effects (Dwivedi et al., 2023; Ooi et al., 2023). According to a recent report by Goldman Sachs (2023) it is expected that in the next ten years, GenAI would boost productivity growth by 15% and would drive a $7 trillion increase in global GDP. Business firms from a large range of industries are showing increasing interest in GenAI applications spanning from early use cases in IT automation, digital labour etc. to specialized core areas of business (Kanbach et al., 2024). For example, healthcare companies are increasing adopting GPT4 for analysing patients’ health, medication and check-up records and drafting responses to patients’ queries. Another prominent presence of GenAI can be witnessed in the marketing and advertising industry where applications such as Performance Max suite are being used to enhance the efficiency of marketing and advertising campaigns. In general, GenAI applications have transformed a large number of business functions (Ooi et al., 2023).
While GenAI has tremendously improved the efficiency and productivity of businesses, it has also drawn significant criticism due to its profound legal and ethical implications for both business and society at large. This process adopted by GenAI applications for self-learning, decision-making and generating output while responding to users’ request has been questioned for its legality, particularly regarding the potential infringement of copyrights owned by input creators. This concern stands out as one of the most commonly reported legal issues (Kucukali, 2022). Numerous lawsuits filed against GenAI applications worldwide have raised pertinent legal questions regarding copyright infringements. For example, could GenAI applications use or reuse public repositories of texts, codes, images etc. without giving credit to its creators and taking permission from its creators, in certain cases where permission was necessary? Should this usage be treated as an infringement of the copyrights of the original creators? And the final question is who should be held liable if the output of GenAI infringes the copyrights in the existing works- the platform or the user?
It is crucial to understand the legal risks associated with GenAI applications, particularly in relation to copyrights, before businesses fully embrace the benefits they offer. In the subsequent sections, we delve into legal aspects of copyrights in the original works, and legal complexities surrounding GenAI applications and its copyright conundrums.
Mechanics of GenAI and its Copyright ConundrumsGenAI is an advanced form of artificial intelligence that is capable of generating new content such as audio, video and text etc. indistinguishable from human-created material (Appel et al., 2023; World Economic Forum, 2024). GenAI achieves this by employing well-tested neural networks across vast datasets to uncover underlying patterns and relationships. A noteworthy feature of GenAI is its capacity for self-learning through both supervised and unsupervised training methods. The mechanics of GenAI applications such as ChatGPT can be divided into four broad stages (Pavlik, 2023; Peck, 2023): Firstly, there's pre-training, where the GenAI is trained on extensive datasets. Following this, the model undergoes the transformer architecture stage, where transformers utilize self-attention mechanisms to evaluate the significance of each word or pixel in generating the output. Transformers serve as the cornerstone of GenAI models. Subsequently, the model can be fine-tuned on specific datasets or images relevant to the task at hand, such as text or image generation. Once fine-tuning is complete, the GenAI generates output based on user prompts, assigning probabilities to each word or pixel in its vocabulary or image repository. The output generation occurs iteratively, with each word or pixel influencing the prediction of the next.
In summary, GenAI models operate by harnessing deep learning to generate outputs based on learned patterns during pre-training and fine-tuning stages, utilizing publicly available data. However, the legal implications of this methodology have raised concerns, particularly regarding potential copyright infringement (World Economic Forum, 2024). Questions are raised in the court of law whether the use of data by GenAI applications for pre-training or fine-tuning constitutes copyright infringement. Should liability arise, who bears responsibility—the GenAI platform owner or the user who initiated the query? These questions underscore the complexities surrounding copyright and accountability in the age of GenAI.
Deciphering Legal Liabilities of Generative Artificial Intelligence Systems in Copyright InfringementThe above discussion highlights two primary forms of copyright infringement in existing works involving; firstly, when GenAI uses or makes copies of the existing works for self-training and secondly, when GenAI output closely resembles with those existing works. As legal disputes over alleged copyright infringements by GenAI applications continue to rise, policymakers and courts worldwide have begun to scrutinize the self-training processes and outputs generated by GenAI applications within the context of existing legal frameworks for copyrights protection.
Although law is a subject of land and the specifics of legal provisions may differ between countries, copyright protection laws universally prohibit the reproduction of entire or significant portions of copyrighted works. For instance, the Digital Millennium Copyright Act of 1998 (DMCA), a United States copyright law, affords extensive legal protection to the rights of original creators, encompassing artistic, literary, and digital content. It prohibits distribution, reproduction, public display, construction of derivative works, and circumvention of technological measures employed by creators of original works (U.S. Copyright Office Summary, 1998). Similarly, the Copyright Act of 1957 in India encompasses a broad spectrum of works, ranging from artistic creations to open-source computer code and cinematographic films, under its ambit17 (Copyright Office, Government of India). In addition to safeguarding the exclusive rights of creators, legal protections extend to moral rights such as attribution and integrity of the work. In the European Union (EU) member states, creators of original works enjoy exclusive rights to distribute, reproduce, perform, display, and create derivative works for either the lifetime of the creator or a fixed duration if the creator is a legal entity. Moral rights, including the right to be acknowledged as the original creator and to object to derogatory treatment of their work, are inherent in the definition and scope of copyrights (Hutukka, 2023).18 While the range of protected creative works and activities forbidden to the non-owners is quite extensive in copyright laws across the countries, most incorporate exceptions allowing for limited fair use of copyrighted works. The fair use doctrine allows the use of copyrighted material without the permission of the owner for a transformative purpose in a manner for which it was unintended. Under this principle original works can be used without creators’ permission for the purposes such as news reporting, scholarships, criticism, teaching and research and comments (Appel et al., 2023).
Legal ComplexitiesFrom an in-depth review of copyright laws, it is evident that copyright laws across countries provide two broad technological measures; those aimed at preventing unauthorized access to the original works of creators and those designed to prohibit unauthorized copying or utilization of the original work to produce similar works. Within the current legal frameworks, GenAI applications may be liable for copyright infringement if they both had access to the original works and GenAI generated output is substantially similar to the original works (Zirpoli, 2023). It is noteworthy that courts have recognized circumstantial evidence, such as access to the original works, as sufficient to establish a case of "copying from the original works." For instance, proof of access may be demonstrated by evidence indicating that the underlying works were publicly available and that the GenAI platform was trained using those works to generate outputs. Although, the test for “substantially similarity with the underlying work/s” is complex, leading relevant cases have defined it in terms of both “qualitative and quantitative significance of the copied portion in the questioned work compared to underlying work/s as a whole (Lucchi, 2023).
In the context of GenAI, the test of “substantial similarity” may require no less than original underlying work/s where an ordinary common man would not be able to differentiate between the original work and GenAI generated work (Lemley, 2023). However, there is no significant agreement as to how likely it is that GenAI platforms may generate a substantially similar output. Defending the allegations of copyright infringement, OpenAI recently argued that a well-designed GenAI program typically avoids copying significant portions or unaltered data from a specific work during training or output generation. Therefore, any “substantial similarity with a particular original work” is a highly unlikely accidental outcome (Appel et al., 2023). On the other hand, in another lawsuit it was alleged19 that the images produced by a GenAI system called Stable Diffusion were highly similar to and derivative of the original images. The original creators of the image claimed that the methodology used to determine the similarity underestimated the true rate of copying from the original images (David, 2023).
In addition to the discussions surrounding "substantial similarity tests," a critical question arises: who bears responsibility if a GenAI system violates copyright in original works—the platform owner or the user? According to prevailing legal principles, both parties could potentially be liable. For instance, if a user is directly responsible for using a GenAI platform to gain unauthorized access to original works, reproduce them, or generate substantially similar works, the platform owner could face potential liability under the "vicarious infringement doctrine" for failing to oversee the infringing activity on its platform. This liability stems from the platform owner's ability to supervise activities on its platform and its direct financial interest in those activities (Zirpoli, 2023). One noteworthy complication here is that user might not be aware of the work that was copied or reproduced in response to his/her prompt. Moreover, the user did not have direct access to the original work in question. Consequently, within existing legal frameworks, it becomes challenging to determine whether the user, the GenAI platform owner, or both should potentially be held liable for copyright infringement.
Concluding Remarks and Directions for Future ResearchIt is evident from the above discussion that existing legal frameworks for copyright protection lack clarity and agreements on establishing potential legal liability for copyright infringements by GenAI applications. Litigations in various jurisdictions bring to light several pertinent issues within the context of GenAI applications and copyright infringements, such as the definition of "derivative works," the criteria for determining "similarity with the existing works," and the interpretation of the fair use doctrine, among others (Lucchi, 2023). Historically, clashes between technological advancements and copyright laws have arisen, with some technology companies successfully defending against allegations of copyright infringement. For instance, Alphabet successfully defended its Google search engine from the legal liability for using text from copyrighted books. The court of law accepted Google's argument that transformative use under the fair use doctrine allowed for the scrapping of text from books to develop the Google search engine (Appel et al., 2023). However, past judgments may not serve as direct precedents for disputes involving potential copyright infringements by GenAI applications due to the unique complexities involved. We invite future studies to examine the complexities and provide insights into application and scope of fair use doctrine” in the context of GenAI applications.
Recent legal battles, such as the Warhol Foundation versus Lynn Goldsmith case,20 shed light on crucial considerations, particularly regarding the "similarity test" and the determination of a work's transformative nature under fair use. For example, the recent judgment of the apex court of the U. S. in a legal battle between Warhol foundation and Lynn Goldsmith can be useful to understand when a new piece of work passes the “similarity test” and gets the status of “transformative piece of work” under the fair use doctrine. The court in the instant case held that original works like those of other photographers were protected by copyright laws even against the famous artists. The protected rights included the derivative works that transformed the original works. It was further stated in the judgment that the fair use argument might not prevail if the use had a purpose and character which was not sufficiently distinct from the original work (Mangan & Drinkwine, 2023). Future research should focus on how the outcomes of ongoing litigations influence legal interpretations concerning the potential liability of GenAI platform owners and users for copyright infringements. Clarity on these matters is increasingly urgent, given the widespread adoption of GenAI applications for both creative and non-creative purposes.
The prevailing uncertainty poses significant challenges for businesses utilizing or considering leveraging GenAI applications. Failure to ensure that derivative works generated by GenAI applications fall within the parameters of the fair use doctrine and GenAI output is not “substantially similar to existing works" may expose businesses to penalties for copyright infringements, whether intentional or inadvertent. The legal complexities and lack of clarity within existing frameworks impede the optimal realization of GenAI applications' transformative potential in business operations. Future scholarly research should aim to investigate legal solutions that address the existing ambiguity and complexities surrounding copyright issues in GenAI, including the fair use doctrine and the "substantial similarity test."
Copy, Right, Copy Right, or copyright? A challenge of and for Generative AI - Gareth H. DaviesIntroduction“Congress shall have the power… to promote the progress of science and useful arts, by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries”.
When the above was written into the United States Constitution providing the basis for copyright protection across a new nation, the authors likely gave little thought to the prospect of machines being the authors and inventors. Since then, technology has raced ahead as GenAI puts us in a position where the law is catching up with the concept of machines as originators of new material, while we are already working with such output.
Modern legislators in jurisdictions around the world are trying to grapple with the regulation challenges from GenAI, but without governments missing out on the opportunities for improved productivity and the new sectors created by such a paradigm shift. Most recently, the debate surrounding GenAI has become prominent as ChatGPT presents a tipping point for its application (Teubner et al., 2023).
Not only in writings, GenAI has also advanced in fields such as musical composition, from conceptual (De Mantaras & Arcos, 2002) to commercial (Drott, 2021). Recorded music alone represents a global annual market worth $26bn, with particular growth in Asia and emerging economies.21 Understanding the provenance, the process of generation, and the ownership of such material is therefore key in determining the rights and revenues of works. This begs questions, not readily resolved, even in the ‘real’ world. For example, a recent dispute involving the singer-songwriter Ed Sheeran involved studio recordings and notes being used to evidence the originality of his work. This shows that even the natural creativity ‘black box’ is sometimes challenged to show the origins of its creations (Komlos, 2021; Bosher, 2022).
Amongst challenges of potential bias, privacy infringement, and misuse, there are the questions of whether GenAI infringes others’ existing rights and/or creates new ones (Dwivedi et al., 2023; Fui-Hoon Nah et al., 2023; Lucchi, 2023). Much like real intelligence, the artificial is limited by the quality and extent of its prior knowledge, making the provenance of training data a key question (Dwivedi et al., 2023). Questions of copyright relating to the materials entered into the black box as training sources, are being tested in the courts (Samuelson, 2023; Peres et al., 2023) and are to be determined before arriving at the further question of ownership of output. While some argue the output could simply be considered as being for the public domain (Palace, 2019), there is a need for clarity in order to advance AI use. It therefore remains that resolving the challenges of copyright sits amongst the five critical areas for research in use of AI (Van Dis et al., 2023).
Historical Context of Technology and CopyrightSince the Statute of Anne in 1710, copyright had been entwined with challenges posed by technology, since the printing press through to recordable digital media, and of course the Internet.22 The printing press ushered in government controls over this disruptive technology, focusing on restricting the reproduction and diffusion of material. At first, this was to secure government control in managing the information available to the population. This may resonate with modern concerns over GenAI use for electoral interference, such as to create malign deep fakes of political messaging. However, earlier focus has shifted to development of the printers’ business models and the interests of authors. In turn, an economy was created around intellectual property rights, moving beyond established production factors of land, capital, and physical labour.
More recently, a similar debate has emerged around using the vast data available through the Internet to create news feeds, with data-scraping search tools creating questions about technology re-presenting copyrighted material. In parallel, Google Books, displaying portions of copyrighted material verbatim, presented further questions over copyright infringement. However, it was legally determined that such re-production was not sufficiently ‘substantial’ to be of issue (Sag, 2018).
Debate has often focused on how existing regulations fit with a new disruptive technology. Recently, the fair use or similar consideration of processing copyrighted material for training GenAI has been supported by scholars in the US (Sag, 2018), though notably remains the subject of discussion (Henderson et al., 2023). As the original notion of fair use related to non-commercial application, this becomes stretched as GenAI enters widespread commercial use (Teubner et al., 2023;Henderson et al., 2023).
Around the WorldThe Berne Convention (Ricketson et al., 2022) provides almost global protection for authors, with rights to their works recognised beyond borders. However, prevailing consideration is to only recognise humans’ creations as benefiting from copyright, as reflected in recent rulings affirming this position (Peres et al., 2023). Despite this, some academics have credited ChatGPT as a co-author, noting that GenAI has contributed to their works (Stokel-Walker, 2023). This may be to simply garner interest, to hedge their bets if the machines do indeed rise against us at some point, or more likely to satisfy publishers' requirements (Stokel-Walker, 2023).
A useful early summary of copyright in an emerging AI age was provided by Gaudamuz (2017) for the World Intellectual Property Office, in response to the emergence of AI-generated literary and artistic creations, along with Google exploration of AI to author news articles. This preceded the recent post-pandemic emergence of ChatGPT-driven interest in GenAI and a host of other AI applications. Governments worldwide have been prompted to accelerate their work on related regulation, including copyright legislation, albeit lagging behind the technology's progress.
United StatesAs noted earlier, the US Constitution presented the clear intention for economic benefit from monopolies over intellectual produce. Even subsequent emphasis on freedom of speech enshrined in the First Amendment has not curtailed development of copyright protections. However, US copyright remains focused on human creativity, and “the fruits of intellectual labor” noting these “are founded in the creative powers of the mind” (Gaudamuz, 2017). While claims over GenAI output might therefore be questionable, there is also the issue of potential infringement of what it uses to learn. The US fair use doctrine provides a level of cover, though with consideration needed, including the extent to which inputs are transformed – i.e. dissimilar to the input(s) (Henderson et al., 2023; Lee et al., 2024; Samuelson, 2023). While technology may be more adept at processing vast amounts of information, it begs the question whether something is ‘copied’ becoming a higher bar than that put to human authors – leading back to the Ed Sheeran example.
ChinaEvolution of Intellectual Property Rights protection, specifically Copyright, and how it has mirrored its history in the US is described by Yu (2003). Alford (1995) had also described how Chinese copyright development reflected the original UK state-control of political messaging, alongside the more commercial purpose. In a shift from ‘world factory’ to pursuing technology leadership in Artificial Intelligence, China has major entities such as Huawei, Alibaba and Tencent, accompanied by evolving government oversight and regulation (Roberts et al., 2023; Lundvall & Rikap, 2022).
The question of whether AI or only humans can provide the ‘intellectual achievement’ required by Chinese copyright law is discussed by Wan and Lu (2021), citing differing conclusions from Chinese courts. As China's role in the global technology market progresses, how this aligns with broader regulation will become of significant importance (Roberts et al., 2021).
United KingdomThe UK had been at the forefront of copyright legislation since the Statue of Anne, responding to the emergence of the printing press. This was initially to restrict distribution of material undesirable to the government of the time, rather than to protect or incentivise authorship. It did point towards a relationship between authors’ rights, business models, and technology. Two centuries later, the Copyright, Designs and Patent Act (1988) was forward-thinking in giving consideration to ‘computer-generated’ works, crediting the person who made the ‘arrangements necessary for the creation’. However, this could not have foreseen the breadth, depth and context of creation through GenAI.
While there may be acknowledgement of technology as an originator, questions remain to be resolved. Ongoing efforts to develop a government code of practice on copyright and AI are being met by legislators pushing against the free mining of third party copyrighted materials, which looks to put limits on use of training data (HoC, 2023). It is also notable that despite Brexit, there is consideration of UK regulators looking to work closely with their EU counterparts on this challenging shared issue (Matthews, 2024).
European UnionIn an EU context, some argue that the emerging approach to regulation of Text and Data Mining (TDM) positions copyright law as a potential obstacle rather than an enabler for the learning required by commercial GenAI (Rosati, 2019). The EU has been working to develop rules for ‘trustworthy’ AI within its Artificial Intelligence Act23 (European Union Artificial Intelligence Act, 2024), including the requirement for provision of summaries of copyrighted materials used in AI training.
A tension exists between the pursuit of digital technology leadership, where previous technologies (e.g. Internet search and social media) have been captured by US firms, while protecting broader citizen interests. De Gregorio (2021) describes the shift from the laissez-faire permission offered to internet providers encouraging innovation, through to the more rights-based protection offered by the approach to privacy in the General Data Protection Regulation. Internet services had been let off from responsibility over potential copyright infringements in what they host, while greater responsibility may be required of AI technology. Achieving these dual ambitions is therefore a central challenge for future legislation and regulation.
Rules for the Arms RaceNatural creativity draws upon learnings and experiences, lost in the real neural networks of the mind that are themselves not fully understood. Therefore, it may seem unfair to hold the artificial to a greater expectation, demanding to unpick the origins and workings of its creations. However, work such as that of Vyas et al., and Barak (2023) provides encouragement that GenAI is not sampling and thereby infringing material from which it learns. This supports the fair use rationale for AI to be afforded intellectual freedom, while Henderson (2023 et al., (2023) urges caution.
Meanwhile, the role of the people as well as technology needs focus. Roberts et al., (2023) call for public engagement in the development of policy, while Stokel-Walker (2023) describes how publishers require transparency and responsibility amongst authors. This sits alongside the public good of democratisation of knowledge and its exploitation, akin to the revolution seen with the internet as information became more accessible. As such, the purpose remains for Intellectual Property Rights to seek the balance of public interest, including to incentivise creators. In turn, it provides a social science rather than a technology question, as Samuelson (2023) stresses the importance for researchers to take part in this debate in order to realise fit for purpose legislation and regulation.
The unresolved issues of GenAI and copyright lead to the need for further research and subsequent policy development and legislation, including for protections around fair use (Henderson et al., 2023). Other technological phenomena already pose associated challenges with which the law is still catching up. Regulation of social media remains a live issue, including where it transcends nations. This creates a problem space not only for researchers, but for practitioners and legislators around the world. As Lucchi (2023) suggests, there is even scope to consider whether an entirely new approach to copyright may be needed, as disruptive as GenAI itself – though would Artificial Intelligence be conflicted if it were to come up with its own answer?
Being first in regulating and thereby resolving these challenges may appear like a goal to secure the spoils of GenAI. However, ‘winning the regulation race’, as Smuha (2021) describes, is perhaps not about being first to legislate, but is instead about achieving an outcome of conformity and interoperable market access - a destination best arrived at together.
Unlocking the Intersection of Generative AI and Intellectual Property Rights: Moving Towards Misuse Case Analysis - Anuragini ShirishDemocratization and widespread use of GenAI tools such as ChatGPT, Claude, Mid Journey, DALL.E, Microsoft Copilot, etc., by citizens, professionals, creators, consumers, businesses, customers, and employees has led policymakers, legislators, researchers, and the business community to proactively analyse use cases as a way to understand this emerging phenomenon better (Chandra et al., 2022; Deloitte, 2024; Houde et al., 2020; Stohr et al., 2024). Use case analysis can bridge the commonly experienced information asymmetry problem between researchers and industry, which impedes researchers from effectively intervening and contributing through engaged scholarship that can promptly address societal challenges and advance knowledge boundaries. Use case analysis might also give researchers clarity and structure to an inadequately defined phenomenon. It can also pave the way to conceptualization and theorization to explain how and why a focal phenomenon may lead to various positive instrumental and humanistic outcomes. With the accessibility of AI misuse case repositories, researchers can be inspired to use projection and prospection types of theorization (Houde et al., 2020) ,24 which will enhance engaged scholarship and also encourage generative scholarship. While an engaged scholar dives deeper into an already known phenomenon, a generative scholar indulges in future-oriented, imagination-focused and values-based prospective theorization (Gümüsay & Reinecke, 2024; Houde et al., 2020; Ochmann et al., 2024). In this editorial piece, I reflect on the utility of "misuse cases" analysis as a valuable approach to prospective theorization in GenAI using a design fiction approach. In particular, I consider how GenAI and intellectual property rights lay the foundations of a responsible research enquiry (Gümüsay & Reinecke, 2024).
Three core terms first need to be defined for this analysis: misuse case, mis-actor, and intellectual property rights. GenAI ‘Misuse case’ is defined as a completed sequence of actions performed by one or many misactor(s) resulting in a loss for the organization or some specific stakeholder (Sindre & Opdahl, 2001). ‘Misactor’, in this context, refers to real/artificial entities (entities) that interact with the GenAI system and initiate (with or without intention) the misuse case (Sindre & Opdahl, 2001). Here, we take the definition for intellectual property (IP) as provided by WIPO, “as creations of the mind, such as inventions, literary and artistic works, designs, symbols, names and images used in commerce” (WIPO, 2024). IP rights are foundational to patents, trademarks, industrial designs, geographical indications, copyrights and related rights (such as performance(er) rights) as well as trade secrets (WIPO, 2024). However, in certain jurisdictions, other sui generis rights such as databases, integrated circuits, fashion design (in France) may also be entitled to property rights. There are also other rights, such as personality rights as well as rights to image and respect for privacy, which are often implicated along with IP rights in misuse cases. Personality rights are similar to property rights, allowing individuals to control the commercial use of their identity, such as name, image, likeness, or other identifier, even after death in some jurisdictions. In Table 2, I construe a few misuse cases at the intersection of GenAI and IP/Personality Rights. The following table describes the AI system, its modality (including text, code, audio, image, video to hybrid), the stage for which the misuse case has implications (development, deployment (use) or maintenance), and the GenAI application context. Finally, I introduce both the ‘Misactor’ initiating the ‘Misuse case’, providing details and linking the misuse case to a specific IP Rights.
GenAI-IP Right Misuse Case Analysis.
| Modality (M), Stage (S); Application (Ap) | Misactor(s) | Misuse case: IP Rights/Personality Rights |
|---|---|---|
| M:TextS:Development/Deployment/MaintenanceAp: Content writing | Negligent/ill-informed employee of Alpha Company | Confidential Information/Trade SecretsAn employee of Alpha company may be using free version of a GenAI tool (such as ChatGPT) to personalize marketing messages. In doing so, they may inadvertently give away trade secrets or waive confidentiality in commercially sensitive information when using such content as part of their prompts. This information input could then be integrated into the training data of the GenAI system, thereby exposing access to cybercriminals who may employ technical or social engineering methods such as prompt hacking or prompt injection. Such misuses could severely damage the reputation, person, and property of Alpha company. |
| M: Image/3D ModelS: DeploymentAp: Personalized Design Production | A third party named Beta, commissioned to assist in product design of jewellery by a startup called Gamma. | Industrial DesignA trainer within a reputed design agency, Beta, takes recourse in GenAI tools (Such as DALL.E/Meshy) to churn out a few personalized 3D jewellery designs using both in-house input images as well as images built into the AI tool. The unaware manager approves the design prototypes and sends them to Gamma for an assigned fee. The AI-assisted 3D output of the design had 97 per cent similarity to a 2D design registered in the name of a reputed fashion brand in France. The AI system that generated these designs did not disclose if their training data included prior art, such as pre-registered industrial designs. The terms of use also did not specify how ownership of AI output might be determined and if users of the tool had any license to derivative rights that were generated by AI via the tool. Without any information, the trainee working for Beta assumed that such a use would not be risky. Hence, she did not find it essential to disclose it to her manager. Due to this misuse incident, Gamma company was sued for design rights violations by the reputed fashion brand, causing huge financial and reputational damage which led the Gamma company to close its operations. Moreover, Gamma company could not have sued the Beta company for damages since their contractual engagement did not expressly specify if AI-assisted designs were prohibited/accepted. In addition, the contract did not require Beta Company to check for prior art similarities as part of their contractual engagement. |
| M: Video/Audio/S: DeploymentAp: Marketing | Negligent marketing team of Company ABC | Performers’ & Personality RightsThe marketing team at ABC chose to leverage the latest GenAI tools that allow for accessible face-swapping/audio cloning possibilities for their new marketing campaign. They chose to web scrap a few videos, pictures and audio tracks that are publicly available on a handful of sports stars. They used this data as input to generate audio and video deepfake content to lure online social media users to buy their new brand of health drink. Sports stars have personality rights and performer's rights, which protect their sports performance and likeness, name, and voices. The concerned sports personalities collectively launched legal suits against ABC for passing off and infringing upon these IP/personality rights. ABC company lost the legal battle and incurred financial, legal and reputational loss. |
| M: HybridS: MaintenanceAp: Online course generation | Optimistic Educational Institute STAR located in China and the US. | CopyrightsSTAR commissioned one of its educators to produce an online course entirely generated by AI tools (e.g., Thinkify/NOLEJ) based on IP-licensed content provided as input data to the AI system. The online course that was fully AI generated using the educator's IP-licensed input data/parametrization became a great success due to various gamification and student engagement factors integrated into the course. The course generated good profits for STAR in China and the US. In the meantime, seeing the success of this venture, a same size competitor school reproduced a similar online course using the same AI system as STAR. Soon, STAR lost its prospective students to the competitor, as it could not successfully defend its work as copyright protected in the US courts. Since AI cannot (yet) be considered an 'author' under copyright laws in the US and the educator was not found to expend sufficient human creativity to generate the online course. Despite having obtained rights to intellectual content from third parties in the creation of their course, STAR could not successfully prove copyright violation in this case. Nevertheless, it may have been possible to claim authorship if STAR had gone to trial in China instead of US, since AI-generated output with sufficient human inputs to shape its originality has been considered worthy of copyright protection in China25. However, AI alone is not considered an 'author' per the current Chinese copyright laws (the situation is the same for patent claims/infringement suits). |
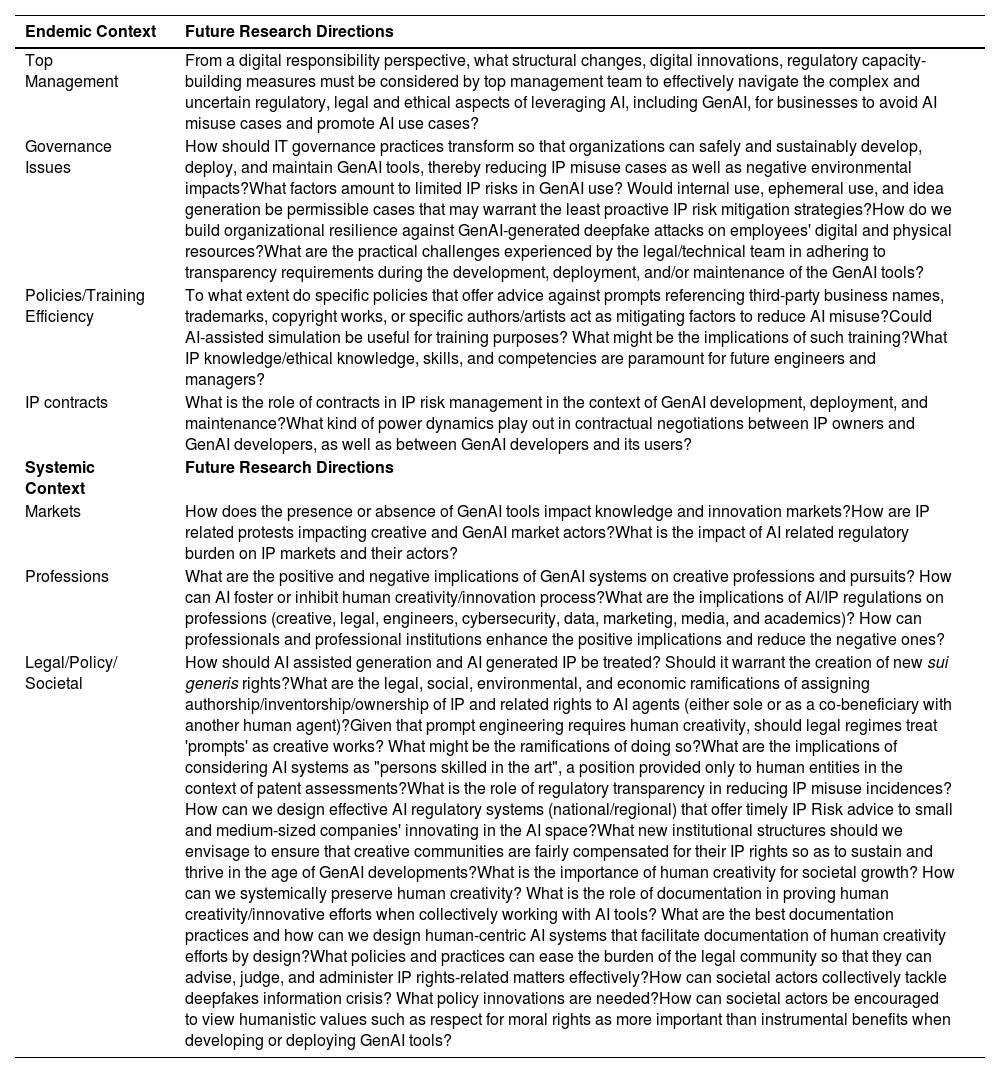
This misuse case analysis provided in Table 2 allows us to look at the murkiness involved in the development, deployment, and maintenance of GenAI applications from the perspective of IP risks. The territoriality of IP rights poses yet another vital impediment to AI-IP risk resilience. Until there are harmonized laws and regulations across different regions, it will be difficult to predict the right course of action regarding GenAI development and deployment concerning IP rights. The recent EU AI act has created an obligation upon the provider of GenAI systems to respect all IP rights and communicate with sufficient transparency details in the training dataset used (European Union, 2024). All AI generated synthetic content (deepfake) must be watermarked before their deployment. In a recent work, we detailed how deepfakes, a GenAI phenomenon, can negatively impact institutions such as states, markets, professions, and communities (Shirish & Komal, 2024). In this work, we provide an in-depth misuse case analysis and argue for the need to consider the whole-of-society approach and indulge in innovative policy design to tackle such wicked problems faced by global societies after comparing the US, UK, India, China, and EU legal provisions. To continue this enquiry on GenAI and regulatory issues, I provide research directions for the endemic and systemic context in Table 3.25
Research directions.
| Endemic Context | Future Research Directions |
|---|---|
| Top Management | From a digital responsibility perspective, what structural changes, digital innovations, regulatory capacity-building measures must be considered by top management team to effectively navigate the complex and uncertain regulatory, legal and ethical aspects of leveraging AI, including GenAI, for businesses to avoid AI misuse cases and promote AI use cases? |
| Governance Issues | How should IT governance practices transform so that organizations can safely and sustainably develop, deploy, and maintain GenAI tools, thereby reducing IP misuse cases as well as negative environmental impacts?What factors amount to limited IP risks in GenAI use? Would internal use, ephemeral use, and idea generation be permissible cases that may warrant the least proactive IP risk mitigation strategies?How do we build organizational resilience against GenAI-generated deepfake attacks on employees' digital and physical resources?What are the practical challenges experienced by the legal/technical team in adhering to transparency requirements during the development, deployment, and/or maintenance of the GenAI tools? |
| Policies/Training Efficiency | To what extent do specific policies that offer advice against prompts referencing third-party business names, trademarks, copyright works, or specific authors/artists act as mitigating factors to reduce AI misuse?Could AI-assisted simulation be useful for training purposes? What might be the implications of such training?What IP knowledge/ethical knowledge, skills, and competencies are paramount for future engineers and managers? |
| IP contracts | What is the role of contracts in IP risk management in the context of GenAI development, deployment, and maintenance?What kind of power dynamics play out in contractual negotiations between IP owners and GenAI developers, as well as between GenAI developers and its users? |
| Systemic Context | Future Research Directions |
| Markets | How does the presence or absence of GenAI tools impact knowledge and innovation markets?How are IP related protests impacting creative and GenAI market actors?What is the impact of AI related regulatory burden on IP markets and their actors? |
| Professions | What are the positive and negative implications of GenAI systems on creative professions and pursuits? How can AI foster or inhibit human creativity/innovation process?What are the implications of AI/IP regulations on professions (creative, legal, engineers, cybersecurity, data, marketing, media, and academics)? How can professionals and professional institutions enhance the positive implications and reduce the negative ones? |
| Legal/Policy/ Societal | How should AI assisted generation and AI generated IP be treated? Should it warrant the creation of new sui generis rights?What are the legal, social, environmental, and economic ramifications of assigning authorship/inventorship/ownership of IP and related rights to AI agents (either sole or as a co-beneficiary with another human agent)?Given that prompt engineering requires human creativity, should legal regimes treat 'prompts' as creative works? What might be the ramifications of doing so?What are the implications of considering AI systems as "persons skilled in the art", a position provided only to human entities in the context of patent assessments?What is the role of regulatory transparency in reducing IP misuse incidences?How can we design effective AI regulatory systems (national/regional) that offer timely IP Risk advice to small and medium-sized companies' innovating in the AI space?What new institutional structures should we envisage to ensure that creative communities are fairly compensated for their IP rights so as to sustain and thrive in the age of GenAI developments?What is the importance of human creativity for societal growth? How can we systemically preserve human creativity? What is the role of documentation in proving human creativity/innovative efforts when collectively working with AI tools? What are the best documentation practices and how can we design human-centric AI systems that facilitate documentation of human creativity efforts by design?What policies and practices can ease the burden of the legal community so that they can advise, judge, and administer IP rights-related matters effectively?How can societal actors collectively tackle deepfakes information crisis? What policy innovations are needed?How can societal actors be encouraged to view humanistic values such as respect for moral rights as more important than instrumental benefits when developing or deploying GenAI tools? |
“AI models are not a vast warehouse of copyrighted material.” - Marc Andreessen
Innovation and creativity primarily rely on the freedom to experiment with new tools available at different times, and across different social, economic, and cultural settings. In this editorial, we pose a provocative question: Are traditional copyright ‘intermediaries’ in the contemporary world now impeding progress and innovation by imposing various restrictions on the experimentation with and utilization of generative AI tools in the creative process?
Fair Use and Generative AICopyright-related issues are at the heart of the debate surrounding GenAI. More specifically, some of the most complex ongoing cases revolve around the legality of using copyrighted material to train GenAI models, and whether AI companies can invoke the fair use doctrine to justify their activities. In the United States, the first factor of the fair use doctrine—the purpose and character of the use—includes two primary considerations: (i) whether the use of the source work is commercial or non-commercial, and (ii) whether the use is transformative.
The “transformativeness” element requires us to address whether the defendant has added new meaning, purpose, or message to the plaintiff's source work. Historical precedents like Sony Betamax, Google Books, and Google's adaptation of Java—a desktop programming language—into a mobile operating system for Android, showcase the potential societal benefits of such transformations.
In the case of GenAI, the transformative impact and added value to society are even more evident. To assess the transformativeness in the age of AI, it becomes crucial to ask: What is the actual value that GenAI delivers to various stakeholders, the broader society, and future generations?
As we stand at the dawn of a new age of GenAI, it may be worth questioning whether the four traditional factors of fair use test are adequate or if we need to introduce new considerations to capture the evolving social contract between humanity and disruptive technologies. Perhaps it is time to move beyond an assessment of transformativeness and consider alternative standards or criteria. At this pivotal moment, should we not also include additional, complementary factors in our evaluation of fair use? If so, it is imperative to discuss what these additional factors might be.
To find answers, we might start by examining the range of stakeholders benefiting from GenAI. Another concept to consider is disruptiveness. The relationship between disruptiveness, innovation and new value appears to be complementary, suggesting that both could play a crucial role in reshaping our understanding of fair use in the age of GenAI.
A New Social Contract with Technology?GenAI is reshaping the entire discussion around copyright, emerging as one of the greatest, yet most misunderstood, ‘gifts’ to humanity. In the following, we suggest that AI serves as a crucial awakening, revealing how we risk being confined by the monopolistic grip of copyright holders and information intermediaries, as well venture capital firms that back the development of GenAI technologies.
There is a pervasive belief that GenAI signals the end of the world—a notion propelled by misinformation or misunderstanding about the potential of AI technologies. Very few technologies have been as heavily burdened with prejudices and misconceptions as AI. The concept of AI has been featured in fiction for over a century, typically culminating in catastrophic endings or dystopian narratives. This persistent story is undoubtedly contributing to the current scepticism. Never before has a technology “arrived” with so much prejudice and semantic baggage.
Can society keep pace with this new technology? It appears not, as our entire infrastructure—economic, cultural and legal—is anchored to outdated models of creativity focused on individual authors, original expressions and exclusive rights that are typically held by powerful intermediaries, such as publishing, record and software companies. These models not only restrict our ability to adapt but also blind us to the possibilities that new technologies such as AI offer. Our models of creativity and the entire infrastructure around creativity are out of sync with the times and are struggling to keep up.
In the current system, virtually no one benefits—a falsehood perpetuated by copyright holders and echoed by the U.S. Copyright Office. This pervasive myth does not serve anyone well. Not only is the legal framework out of touch with today's creative environment, it also contributes to social exclusion, in which creators—artists—are denied new opportunities for creativity.
The problem with the existing copyright framework is that it disproportionately empowers intermediaries—large organizations that own copyrights, such as publishers. These intermediaries propagate the myth that they are protecting creators. However, in many cases, they have appropriated economic rights for themselves and monetized these works to their own advantage, often at the expense of artists and consumers.
How could the emergence of GenAI tools shift the balance of power between these powerful intermediaries and artistic creators? GenAI equips artists with new tools, enhancing their creativity. Yet, equally important, it also exposes the reality that all creativity is historically situated and contingent upon the existing social, technological, and economic frameworks, including the tools available. Creativity is and never has been, the product of uniquely gifted individuals conjuring something out of nothing but is a situated, networked, contingent process involving historically contingent tools, traditions, identities, and roles. This observation is not meant to decry creativity and individual creators but to acknowledge the historical importance of the “creativity machine,” as revealed—on this account—by GenAI.
What we are now witnessing, therefore, is “old wine in new bottles”, a new form of social exclusion where dominant intermediaries attempt to use the legal system to restrict artists freedom to create. Conversely, GenAI represents a potential moment of liberation for artists and the society as a whole, challenging the power of these intermediaries.
More practically, when intermediaries—including publishers, government agencies like the U.S. Copyright Office, university governing bodies, and technology giants—require disclosure of GenAI tool usage in the creative process, or in some cases, disclaim ownership of the creative content, they are attempting to maintain control over creativity, and it is important not to be fooled by this.
Should we not consider the benefits of unleashing “the creativity machine,” allowing it to operate freely without the constraints imposed by intermediaries? What if we liberated the creativity machine from the structures and power dynamics that intermediaries use to hinder progress?
What is needed now is new social contract between humans and technology, specifically GenAI, focusing on: (a) finding consensus on the use of data to train GenAI, and particularly in the U.S., how the fair use doctrine could be applied to companies integrating GenAI into their tools and digital platforms; (b) exploring new compensation models for the use of copyrighted content in various GenAI contexts; (c) ensuring that copyright-related research is grounded in empirical studies and prejudice and fantasy; and (d) tailoring these studies to specific issues such as voice, name, image, likeness, robotics, and genetic research.
GenAI is not a monster that threatens to eradicate humanity. That is a narrative perpetuated by incumbent information intermediaries deeply worried that their economic and social power might be challenged or otherwise disrupted. Rather, we should think of AI as a gift, revealing the truth of all creativity—the creativity machine—and offering new creative possibilities that usher in a new era for humanity.
The Role of Regulation and Policy in Safeguarding Copyright and Intellectual Property in the Age of AI - Ramakrishnan Raman & Shashikala GurpurBrief Overview of Generative AI and its CapabilitiesRecently, AI has gained popularity with autonomous vehicles and by assisting many human operations with creative robots among others. Academics, policy makers, businesses and community members are increasingly aware of learning algorithms. ChatGPT is a quick and rich source of data. Thus, AI is a necessity rather than an avoidable option, creating new possibilities and challenges. GenAI can be prompted to generate essays, pictures, paintings and other artworks in part by exposing them to a huge number of existing works. GenAI is capable of generating new images, messages and other content (or ‘outputs’) in response to a user's textual requests (or ‘inputs’). Some of the examples are, OpenAI's DALL-E 2 and ChatGPT programs, Stability AI's Stable Diffusion program, and Midjourney's program. Thus, the legal implications of GenAI have increased as they have wide range of potential use for businesses and people. Whether such works can be protected as intellectual property in general and copyright in particular?
Importance of Copyright and Intellectual Property Rights (IPR) ProtectionIntellectual property rights are a set of exclusive rights of the inventor or creator or their assignee to protect one's invention or creation for a certain period of time and to fully utilize such invention. Thereby, these rights serve the purpose of protecting such invention or creation, incentivising the creator or inventor and encouraging disclosure/publication which ultimately serves public interest. Innovation-based economies with strong IPR protection have witnessed increased prosperity and technological advancement. IPR provides a mechanism of handling infringement, piracy and unauthorised use. Originally, only patents, trademarks and industrial design were protected as Industrial Property, which later earned the wider connotation as Intellectual property. Across different categories of IPR such as copyrights, patents, designs, trademarks and trade secret, the criteria include originality, inventive or creative step and useful innovation as value creation with utility. In this article, the discussion on IPR is restricted to copyright, in relation to GenAI. This is based on the latest legal and policy- related developments across the world, in the UK, USA and the EU among others.
Copyright is the right held on the expression of idea in material form, serving the social purpose of rewarding and encouraging creative work. It includes literary works such as books and other writings, musical and dramatic compositions, artistic works such as paintings and sculptures, cinematography works, films, audio tapes and computer software. It provides exclusive rights to the copyright holder, including the right to distribute, reproduce, perform or display or broadcast, make adaptation, make copies and distribute the copyright-protected work. In the USA the protection by copyright extends for a minimum period of 50 years or up to 70 years after the death of the author. Related rights such as neighbouring rights are the rights of performers like actors, singers and musicians, producers of phonograms or sound recordings and broadcasting organisations. A copyright generated in a member country of the Berne Convention is automatically protected in all the member countries without any need for registration. Therefore, it is not territorial and can be transferred, sold or gifted. Any unauthorised use of such copyrighted content amounts to infringement.
Copyright infringement can occur due to any intentional or unintentional copy or use by third person without the authorisation or permission of the copyright owner or without giving credit. It attracts legal action for damages, accounts and injunctions to prevent further use. Infringements do not include certain acts of fair dealing which are allowed by the law, without the permission of the author or copyright holder, are not. These are called fair use and these include criticism, comment, news reporting, multiple copies for classroom use, scholarship and research. The four determinant factors of fair use include purpose and character of commercial or non-profit use, nature of the work, amount and substantiality of portion used from copyrighted work, and the effect of the use upon the potential market or actual value of the copyrighted work. Investigations in this area look into possible bad faith and any transformative purpose in the infringement. This part of the law is crucial.
Based on various Euro-based international frameworks of World Intellectual Property Rights Organisation (WIPO) and series of norm-creating conventions, national legislations and policies, most jurisdictions require human creativity or originality. This refers to the creation of the mind. In this context, the creators of GenAI outputs claim that significant human involvement in manipulating inputs merits such works to be copyright protected or trademark protected as the case may be. The training methods used by the GenAI systems operate by recognising and recreating patterns in data like any machine-learning software. These programs produce code, writing, music and art. These require human-generated data, which could be already copyright-protected, hence resulting in copyright-infringement
Role of Regulation and Policy in Addressing the Impact of GenAI on Copyright and IPR LandscapesGenAI has posed an IPR problem. Two possibilities emerge here: AI as the author or AI-assisted authorship. The first may compete with or cause the violation/infringement of IPR or copyright of the original human creator or artist by the GenAI. The second may result in the claim of the violation/infringement of IPR or copyright of the GenAI. The basis can be that the content of GenAI be considered sufficiently human- authored, making it eligible for copyright, since the AI receives prompts from human generated context of visual, written or music works. Can the use of the AI- tech determined expressive elements of work, artfully arranged or modified by the artist, affect the copyright claim of the author utilising AI assistance?
How GenAI Reshapes Copyright and IPR LandscapesPrevalent approaches in the US, UK, EU or India show that AI as an author is not accepted. AI-assisted authorship reduces the human author's copyright claim. With increasing use, regulatory approaches are just emerging. The terrain of law and policy remains less navigated, with scope for recommendations and possible future reforms or trends for businesses, creators and users. Some of the European jurisdiction such as Germany and France permit TDM or the Text and Data mining for scientific purposes, as exception to copyright, just like fair use.
Expiry of the copyright period provides exception. For example, the Next Rembrandt is a computer-generated 3D–printed painting developed by a facial-recognition algorithm. The algorithm had scanned and fed data into a computer, from 346 known paintings by the Dutch painter, in a process lasting 18 months. The painting was developed in 2017. As the original paintings were over 350 years old, there was no fear of copyright infringement.
GenAI authored by the machine, challenges the traditional copyright essentials of originality by human authorship, whether it assists or generates a creative work.
Take this example: X spends several weeks curating several prompts using an AI tool Midjourney, with high level of intellectual attentiveness. X is manually crafting the finished product of art, an AI-generated print called ‘Théâtre D'Opéra Spatial’, which won an art fair prize demonstrating a high level of intellectual attentiveness. Can X claim copyright?
The copyright claim has been rejected.
Another case of infringement is by a TikTok user, Ghostwriter977, claiming to be a song writer, wrote a song entitled ‘Heart on My Sleeve’ and used AI to imitate the voices of Drake and The Weekend. Only the music was new, but the voices were clearly perceivable as that of the original singer. The huge popularity of the song caused the Universal Music Group to ask for its removal from Spotify, Apple Music and other platforms due to copyright violations.Many still question if the song really violated the copyright, as there was creative intervention of new music.
Lawsuits challenging the use of copy-righted materials are on the increase in the USA and the UK. A gross violation occurs if AI companies while training the AI, did not obtain copyright-holder's consent as it can damage the market and value of art. In January 2023, three artists filed a class action lawsuit against Stability AI, Deviantart, and Midjourney for their use of the image-generating models Stable Diffusion and Midjourney. Stable Diffusion is alleged to have used unauthorised copies of millions, if not billions, of copyrighted images to train a GenAI system to ‘remix these works to derive (or ‘generate’) more works of the same kind’ without the knowledge or consent of the original artists. The resulting images then compete with the originals on the open marketplace, flooding it with an endless number of copies or near copies that permanently damage artists’
In September 2023, OpenAI was sued for misusing their writing to train ChatGPT. Another complaint was filed by the US Authors Guild27 and 17 well-known authors claiming that OpenAI copied their work without permission. Both lawsuits claim that the results produced by ChatGPT are derivative, meaning that they mimic, summarise or paraphrase their books harming the market. ChatGPT is trained on works in the public domain instead of copyrighted works. Copyrighted works need license and must obtain consent.
The fair use exception is advanced here based on the Google Bookcase, arguing that storing fits in fair use theory, explained earlier. The courts analysed whether the use of digital copies of print books to create Google Books constitutes a copyright infringement. In this case, the court found that Google's act of digitising and storing copies of thousands of print books to create a text searchable database was fair. In comparison, the march of technology and the transformation in ChatGPT are different. It is because the large language training models may be used commercially, which is not a fair use as the original creation's purpose is deviated from. Also, if there is transformation of the original content into a different form, then claim of original creation can be advanced. Whether a machine can claim such authorship or intellectual labour? Hence, AI claim for copyright has been rejected. The recent US Supreme Court Decision to compensate Ms. Goldsmith on photograph of Prince, in Andy Warhol Foundation for the Visual Arts, Inc. v. Goldsmith,28 shows that the argument in granting copyright to GenAI for its creation is not favoured.
Other pending lawsuits in the US, also show that fair use exception is challenged when infringement occurs in training language models (LLMs). The suit by stock photo provider Getty Images, accused Stability AI, of unlawfully using more than 12 million copyrighted images from the Getty website to train its Stable Diffusion AI image generations system, stating that “..at times produces images that are highly similar to and derivative of the Getty Images proprietary content that Stability AI copied extensively in the course of training [its] model”. Further, it alleged that the output sometimes even includes “a modified version of a Getty Images watermark, underscoring the clear link between the copyrighted images that Stability AI copied without permission and the output its model delivers.29”
Another pending lawsuit Andersen v. Stability AI et al. ,30 is a class action by three artists. The AI companies Stability, Midjourney and DeviantArt were accused of direct and vicarious copyright infringement. The artists claim that the AI companies used their copyrighted works without authorization to train AI programs to create works in their artistic style, which in turn allows users to generate unauthorized derivative works.
The complaint reverberates the socio-economic impact of this practice, while stating, “siphon[s] commissions from the artists themselves,” whose jobs may be “eliminated by a computer program powered entirely by their hard work.”
Returning to GenAI, a key question is whether using data to train AI-assisted part of a human authorship is also rejected and excluded in claims for copyright while using AI prompts. The superiority of dignity of human creativity over machine creativity is also an extreme approach, as WIPO (world intellectual property organisation) states. On September 15, 2022, artist and AI researcher Kristina Kashtanova was granted a copyright registration for a graphic novel entitled Zarya of the Dawn. Although Ms. Kashtanova had identified herself as the sole author of the work on the application, it became public that Ms. Kashtanova had used an AI tool (Midjourney) to generate many of the images in the work. After an investigation, the Copyright Office cancelled the original copyright certificate and issued a new one that excluded the artwork generated by AI but preserved Ms. Kashtanova's rights in other aspects of the work, such as the arrangement of the images and the text.
In July 2019, AI researcher Dr. Stephen Thaler filed two patent applications under the inventor's name “DABUS,” an acronym for his AI program. When the applications were denied, Dr. Thaler filed a lawsuit in the Eastern District of Virginia.31 The district court and Federal Circuit each affirmed the USPTO's finding that only human beings can be inventors. On April 24, 2023, the US Supreme Court denied a petition for certiorari in Thaler v. Vidal, No. 22–919 (U.S. Apr. 24, 2023). On 18 August 2023 the District Court for the District of Columbia held that, while copyright is ‘designed to adapt with the times’, ‘human creativity is the sine qua non at the core of copyrightability’. At the same time, it noted, ‘The increased attenuation of human creativity from the actual generation of the final work will prompt challenging questions regarding how much human input is necessary to qualify the user of an AI system as an “author” of a generated work’. Creative control is pivotal, reflecting the need to preserve the essence of human-driven creativity from mechanistic outputs. For content creators, accurate documentation is paramount in establishing authorship. Careful identification and claiming of human-authored elements prevent challenges to copyright validity. The US Copyright Office thus obliges authors to use GenAI to identify themselves and highlight such elements. The painting SURYAST by Ankit Saini where he had co-authored with his own AI tool RAGHAV, was refused the Copyright in 2023 because of the lack of details on how and who had created RAGHAV. It is the 5th case of refusal by the US copyright office.
In the light of the above, the middle path is to encourage GenAI, track the sources and balance the credits and incentives between the original creator and the AI. But the challenge experienced by Amazon in the flooding of publications assisted by AI or Hollywood script writers who have protested about the adoption of GenAI. The recent AI Act of the European Union, on the other hand, is a ground- breaking comprehensive law which protects IP while being vigilant to GenAI. The approach is to protect and reward the original copyright holder while incentivising innovation through GenAI.
However, legal approaches indicate that, whether a product competes or compares, the violation occurs either as tort violating the personality rights or as infringement causing financial or market loss. The data-deidentification, pre-process, data privacy and secrecy of the original creator and transformation of data by the AI are the key challenges for protection of original creator's copyright and equity. Further, in case of AI use, how to assess human involvement in GenAI output, and how much human involvement is required - will be the subject of future decisions in national court practice while determining grant or modification of copyright. This is usually done on a case-by-case basis relying on track changes and other technical basis.
Another challenge is fundamental and serious. AI can generate fraudulent IP by cloning the IP-protected products based on prompts irrespective of purpose. Instances of cloning the companies, industrial products, government authorities and criminal activities such as generating false invoices, counterfeit drugs or contraband goods are emerging in many jurisdictions such as Turkey, Europe among others.
ConclusionCall to action for policymakers: A Balanced policy allowing protection of IP and copyright in AI and with AI to incentivise innovation, to encourage invention and novelty and not to prevent innovation, to facilitate coexistence of AI with existing approaches, to accrue the benefit to protect all stakeholders, to allay fears, to create mechanism of compensation and fair share of profits or royalty, to create forensic technology to track and investigate original creation and creator
Industry stakeholders: Just and fair treatment of original creators, technologically equipping, using technology responsibly, not to lose money for future litigation, to prevent risk, to indemnify with insurance and researchers: not to use without giving credit or without consent or permission if fair use, to follow and comply with fair use, not to plagiarise.
Companies or businesses: Businesses may reap the many benefits of AI if they mitigate the attendant risks. Some of these include;
- •
Setting a company AI policy addressing acceptable parameters (not pirated works) and AI tools, investigating whether their models were trained with any copyrighted content, reviewing the terms of service and privacy policies of AI platforms and avoid GenAI tools that cannot confirm that their training data and software components are properly licensed or otherwise lawfully used, including in case of due diligence for mergers and acquisitions.
- •
This must extend to GenAI usage in contracts with vendors and customers such as, avoidance of illegal or unauthorised data, indemnification of potential infringement including the failure to license and for content creators to follow terms of web use on scraping and social media platform terms to be reviewed while posting original content
Importance of adaptive regulation and policy in ensuring the continued protection of copyright and intellectual property rights in the age of AI: The courts and legislations must establish guidelines and parameters around ownership and use of AI-generated materials. The regulation must be realistic and encouraging AI innovation. It should protect IP in works, AI assisted, or AI generated, on case-by-case basis, based on forensic evidence, digitally obtained. Such protection must provide for all forms of IP beyond copyright and trademark.
Efforts must be taken to train the legal profession, legislators and leaders to better understand the positive impact from GenAI and how this advanced technology can lead to a better human life, to have technology tribunals or courts with interdisciplinary panels of judges (as in Green courts). Any regulation must contain a mechanism of compensating the creators or owners of ‘scraped’ data and protecting GenAI's ownership of output to reward creativity, innovation and coverage of risks posed. Some experts suggest looking at lessons from the music industry's experience of unrestrained piracy from the file-sharing service, Napster. Litigations and policy discussed above throw some light on this labyrinth of ambiguity and uncertainty.
New regulation could help detect and defend transborder IP infringements irrespective of where the AI is created, licensed or used. Regulation and judicial interpretation must be focused on encouraging disruption through the use of AI, rather than banning it, while ensuring equitable rights of original creators or communities either by license or by digital registration. Initiatives such as co-creating IP and co-creating new knowledge or business with collaborative agreements that could indemnifying risks with insurance or contractual arrangements are advocated. Regulation can be effective only if there is an awareness of IP across user groups, businesses, creators and the community at large. History has shown the unfounded fear of new media displacing print media, as both co-exist today. In a future scenario where users prefer GenAI's curated work than human created works, it is critical that the original human author must be protected and honoured within any legal and policy framework.
Will Copyright and IPR Issues Constrain GenAI Transformations? - Paul WaltonGenAI is changing how people and organisations access and understand information of all types. As a result, the supply chain for information, where it comes from and how it is processed, accessed and understood, is being redefined. But copyright and IPR have the potential to create friction in parts of the supply chain and, as a result, alter its character and effectiveness. But since GenAI sidesteps existing copyright and IPR controls and the legal position is unclear (Appel et al., 2023), there is uncertainty about what controls might be needed.
The risks this creates for organisations are summarised in this article. They affect one of the fundamental benefits of GenAI—that it can empower people in their relationship with information. So, there is a tension between empowerment and control that organisations need to manage.
The changes needed to implement GenAI at scale, like AI in general (Sanders, Wood, 2020), are widespread and have a long lead time. The risks change over time:
- •
Short-term: there are immediate legal and commercial risks—organisations need to ensure that their current use of GenAI doesn't leave them open to legal challenge; but these controls may inhibit the use of GenAI and consequent benefits.
- •
Medium-term: organisations need to understand the extent to which copyright and IPR controls can be aligned to the level of risk as GenAI scales. This requires enough clarity about the legal position to strike the right balance between empowerment (needed to deliver the benefits of GenAI) and control (to mitigate the risks).
- •
Long-term: organisations need to understand how copyright and IPR issues could constrain the potential of GenAI and, therefore, how they will affect the transformation needed to implement new GenAI-enabled ways of working.
Information and data power the modern organisation and GenAI promises major improvements. It provides new capabilities, offering a number of improvements, including:
- •
The AI assistant—people will have AI support to help them with shaping their work, accessing and managing the information they need and drafting outputs (and the introduction by Microsoft of their Copilot range of products, for example, indicates the direction of travel);
- •
Better user interfaces—because LLMs, a type of GenAI, are so fluent with language they enable a different kind of interface between people and technology, one that is closer to human interaction;
- •
More innovation—GenAI has already been useful in medical research and other fields but, much more widely, by automating commodity information tasks (through the AI assistant), GenAI can free up people to be more innovative and creative.
These capabilities will change the nature of work (Fountaine et al., 2021) for which organisations will need to make major changes over an extended period (Sanders, Wood, 2020).
Because GenAI provides information in a new way, it sidesteps the current mechanisms that protect copyright and IPR. The context for this issue is complicated. There are legal uncertainties—GenAI “comes with legal risks, including intellectual property infringement […] it also poses legal questions that are still being resolved” and “before businesses can embrace the benefits of GenAI, they need to understand the risks — and how to protect themselves.” (Appel et al., 2023).
The regulatory environment is, in any case, complicated and changing. Because of the nature of the technology, the issue is global and touches many different legal systems. Regulators are already struggling to keep up with the rate of technological change, although regulation for AI is starting to appear (see, for example, the EU AI Act).
The technology is still immature and is likely to develop much further and continue to push the boundaries of the regulatory envelope.
There is a lack of transparency—a general problem with the type of machine learning that GenAI uses is that the workings of the models cannot be completely understood, and it is not always possible to determine why a model has generated a particular output.
There are three implications of this context. First, this is not a one-off change that organisations can make now. It is an evolving picture that requires an agile approach. Secondly, organisations will need to understand the risks and understand how to control them at scale. Thirdly, it touches many different organisational disciplines (for example, legal, commercial, technical, operational, sales and marketing) that need to cooperate to understand and mitigate the risks.
Short-term RisksOrganisations need to protect themselves against the immediate risks. These include, for example (Baker, 2023):
- •
Use of training data in outputs: GenAI models are trained on data or code that might have some legal protection (through copyright, IPR or licencing) and the model outputs may be sufficiently similar to the inputs to violate these protections or require additional caveats. But generally, these legal protections will be unknown to the user.
- •
Data leakage: The flip side of this is that GenAI models can be additionally trained on organisational data that can then leak elsewhere. So, inadvertently, organisational data can leak and, even where the usage is acceptable, it may be available without a recognition that the data has attached copyright or IPR conditions. There is also a risk that data used for prompting may leak.
- •
Insufficient data governance: One of the great potential benefits of GenAI is that it will enable much better access to organisational data. However, organisations may have data subject to confidentiality, copyright or IPR protections in a location that becomes accessible to widely accessed GenAI through insufficient data governance. This data may then become available inappropriately.
- •
Innovation: AI is already being used to support creativity and innovation. But the same uncertainties are present because “most IP offices require a human inventor to be listed on a patent, and consequently, it's currently unclear how—or even if—AI can be represented as having contributed to a patented invention.” (Baker, 2023).
For these reasons, the uncontrolled use of GenAI, in its current state, presents a major risk and some organisations have instituted policies that require legal (or senior) approval for the use of GenAI. But the genie is already out of the bottle—GenAI tools were widely available online before the policies were implemented—so implementation may be difficult.
Medium-term RisksImplementing a simple policy on restricting use is likely to throttle innovation and empowerment and make the approving body a bottleneck. In the medium term, organisations need to find a way to understand the risks and find the right balance between empowerment and control. This will require risk-based governance so that routine, low risk use cases can be implemented quickly without incurring a large overhead.
Given the pace of innovation, this may not be straightforward. Already, Internet-based GenAI is widely available and GenAI is being included in standard enterprise tools (for example, with the inclusion of GenAI-enabled tools in Microsoft products). In addition, GenAI is being included in (so-called) no/low-code technologies that enable people who aren't professional developers to build applications.
GenAI will become embedded in organisations in new and innovative ways and the governance will need to keep pace without stifling innovation. Even technical professionals may not be aware of the risks so widespread communications will be required to ensure that there is the right level of awareness of both risks and governance.
Understanding and mitigating the risks requires the ability to bring together a wide range of expertise. But many organisations do not have existing mechanisms to do this—the risks of GenAI are new and different. A complete approach to assurance is required (UK Department for Science, Innovation and Technology, 2024) that covers the delivery of GenAI-enabled solutions.
As well as policies and assurance, another mechanism being adopted is the use of GenAI in enterprise tools rather than Internet tools. This allows organisations a greater degree of contractual cover and much greater control over the use of data by the GenAI. A range of architectures and solutions exist to support this.
Long-term RisksIn the longer term, organisations need to decide how GenAI (and AI in general) will change their information supply chain. But implementing AI (including GenAI) at scale is complex (Sanders, Wood, 2020) requiring that organisations understand the following considerations:
- •
The potential and benefits: GenAI (and AI more generally) will change the nature of work (Fountaine et al., 2021). Completely new capabilities like the AI assistant or new types of user interface will democratise commodity skills and provide easier and better access to information. The potential benefits for sales and marketing and organisational productivity are large.
- •
The nature and scale of the change required: Making the changes required to implement these capabilities at scale will require transformation (Sanders, Wood, 2020). As well as the governance changes discussed above, widespread changes will be needed to processes (to adapt to the ways in which work will change), assurance (UK Department for Science, Innovation and Technology, 2024), architecture (to incorporate GenAI technologies and connect it appropriately), data governance (so that GenAI will not be able to access data inappropriately), skills (so that people will work effectively with the technology) and culture (so that people trust the role that the technology will play).
- •
The potential extent of changes required can already be seen in the use of GenAI for software engineering where it is enabling major changes and increased productivity throughout the software engineering lifecycle.
These changes pose several questions:
- •
what risk-based governance needs to be in place?
- •
what controls and assurance model are needed to mitigate different types of risk?
- •
what products and services are consistent with the mitigations?
- •
what contractual arrangements are required to allocate risks appropriately?
Copyright and IPR issues may impose constraints that affect each of these. But resolving these issues has a long lead time which means that organisations have a further difficult question to address: what level of uncertainty is acceptable in planning transformational activities? Organisations will only be able to steer a transformation successfully if they can relate copyright and IPR issues to:
- •
the commercial approach to GenAI technology, the ability to attribute risk appropriately and the consequent impact on technology architecture;
- •
the assurance model required (which will depend on the copyright and IPR controls required);
- •
data governance and the controls required around the management and use of data.
These factors will impact any business case associated with GenAI because they may have a major impact on the balance between desirability and viability for any change and the level of risk to take into consideration.
Research DirectionsThe timetable for the mitigation of short-term risks leaves little time for research. But the uncertainties about the other risks require research. For example:
- •
Risk-based governance. How will potential different resolutions of copyright and IPR issues impact organisational governance? The scale of uptake of GenAI across organisations and its use by a wide range of people means that the scale of the governance required is organisation-wide. How can organisations be confident that policies are implemented effectively when use of the technology is so easy and it changes so quickly?
- •
Other applications of GenAI. The techniques of GenAI can apply to a wide range of structured data but, currently, only a few examples have been widely implemented. But as it develops in other areas, what will be the copyright and IPR issues that arise?
- •
The information supply chain for organisations. How can organisations understand the impact of copyright and IPR issues on implementing GenAI at scale? How can they balance the need to act with the uncertainties that exist?
GenAI has revolutionized innovation and the creative business by enabling faster and more personalized content creation, lowering barriers to entry for non-professionals, and enhancing scalability across various sectors (Davenport & Mittal, 2022). This innovative technology has enabled organizations to optimize production and provide new creative possibilities to a wider array of users. At the same time, GenAI relies on large datasets that include copyrighted materials for training purposes (Neelbauer & Schweidel, 2023). Additionally, the global nature of AI deployment means that IP protection has become an international issue, with varying laws and regulations across different jurisdictions.32 This editorial outlines how GenAI is poised to reshape the IP landscape, creating profound ramifications for industry, policymaking, and society at large.
Challenging Settled NormsGenAI has disrupted established copyright norms by generating derivative works and employing innovative approaches for content creation. For instance, the New York Times sued OpenAI, alleging that OpenAI's language model, Chat GPT, used copyrighted articles without permission to train OpenAI's models (Grynbaum & Mac, 2023). The outputs, while original and not direct reproductions of any specific images in its training data are influenced by the copyrighted material from which it learned. It challenges the boundaries of fair use, particularly around the aspect of transformation and the impact on the market value of the originals. This prompts urgent inquiries on the equilibrium between innovation and the safeguarding of IPR in the era of GenAI.
OpenAI has also argued that its training processes only use materials that are either publicly available or have been duly licensed, thereby not infringing on copyrighted expressions (Ustundag & Wheeler, 2024). For example, OpenAI says its models decompose language into fundamental elements without retaining any copyrighted material. OpenAI has also argued that its use is “transformative,” a defence that has prevailed in past cases, including Google Books.
GenAI may affect demand for original works or present a new and untapped licensing opportunity, such as writing articles or creating summaries, challenging how far courts are willing to extend fair use to GenAI (Ustundag & Wheeler, 2024). If the use is deemed unfair, AI developers would be forced to license underlying content used in training their models (Metz et al., 2024). This shift would change the economics and feasibility of developing GenAI technologies, potentially slowing innovation in the field. However, it may create a new market for collective licensing, offering copyright holders a means to monetize their works in the AI ecosystem.
Establishing a compulsory copyright licensing regime specifically tailored for AI could standardize how AI companies access and use copyrighted content, potentially reducing litigation and fostering a more innovation-friendly environment (Kientzle & White, 2024). This proposal, though, is mired in complexities, particularly concerning how to value copyrighted materials used in AI training (Davis, 2023). There is an urgent need for clearer regulations and explicit rules within the technology sector. The pursuit of innovation must be balanced with respect for IP to ensure that the digital advancements of our age are built on a sustainable equilibrium among stakeholders.
Future Research DirectionsLicensing potential, fair use restrictions, and GenAI development economics provide several avenues for further research:
- 1.
Whether contractual provisions are sufficient: The widespread and variegated use of GenAI makes indemnification and comprehensive contractual clauses essential for mitigating risks associated with copyright infringement. Research could focus on evaluating the language and enforceability of indemnity clauses within user agreements, how these agreements are perceived and understood by users, and how they potentially influence user behavior and the acceptance of AI technologies. Carefully crafting AI service agreements to address copyright infringement risks explicitly is crucial. Compulsory licensing provisions are also contractual in nature, underscoring the need for scrutiny and balancing.
Relatedly, developing technological methods to track and audit the use of data in AI training and operations can address some of the transparency issues at the heart of copyright debates. Research into blockchain or similar technologies to create immutable records of data use and content generation could provide clarity and accountability for metering access to copyrighted works. In this regard, combining legal analysis with technological insights is crucial to developing copyright frameworks that can adapt to the rapid advancements in AI.
- 2.
Impact of AI on Creative Industries: Empirical studies that assess how AI tools are affecting jobs, production methods, and profitability across various creative sectors (like music, writing, and visual arts) can provide insights into the economic ramifications of AI. These studies can help in crafting policies that advocate for human artists and creators, while also embracing technological innovation. Future research also should examine how legal frameworks concerning authorship and creativity may adapt in response to AI, including incorporating new definitions and criteria that recognize the collaborative nature of AI-generated works, and the influence of human oversight in their development.
- 3.
Global IP Law Harmonization: As AI technologies operate across borders, it is becoming increasingly vital for countries all over the world to work together in order to unify intellectual property rules pertaining to AI. Future research could focus developing a unified framework that would permit international agreements on AI and copyright by conducting comparative studies of different legal systems. This would provide consistent protection while simultaneously stimulating innovation on a global scale at the same time.
Singapore has taken proactive steps by amending its Copyright Act to include a computational analysis defence specifically designed for AI machine learning (Tan & Rooke, 2024). This legislative change aims to create a safe harbour for AI development, ensuring that companies can innovate without the fear of infringement claims. Singapore's strategy facilitates technological advancement but positions the country as an attractive destination for AI firms seeking legal clarity and stability.
As nations globally strive to reconcile the interests of copyright proprietors with the expanding AI sector, the Singaporean framework offers a benchmark that merges legal precision with adaptability, allowing for the continued growth and integration of AI technologies in various sectors. This framework could potentially harmonize global copyright laws, benefiting creators and innovators alike.
ConclusionsGenAI forces a re-evaluation of existing copyright norms and necessitates adaptive legal responses to strike a balance between innovation and copyright protection. Interdisciplinary research and empirical studies are crucial in understanding and navigating the complexities GenAI introduces to the creative industries and beyond. This type of research is essential for addressing the intricate difficulties at the convergence of technology, law, and business, facilitating the development of frameworks that reconcile innovation with legal and ethical norms. Overall, it is vital to shape a future where legal integrity and technological progress coalesce.
The Synergy between Intellectual Property Rights Agreements, and Artificial Intelligence in Safeguarding Food Manufacturing Trade Secrets - Mohammed AlRizeiqi & Adil S. Al-BusaidiThere is an ever-increasing demand for high-quality, safe food products around the world, which are associated with population growth and diet preferences among consumers (Gardner, 2013). Higher consumer preferences lead to higher business competitiveness, exclusivity, and more product inventions (Ashoor, 2021; Brody and Lord, 2007). With innovative solutions, the products move from the Research & Development section at the lab scale level to more mechanized large-scale industrial processing. IP protection could be for patenting novel and useful products, novel processes designed for the process of certain manufacturing, or even file IP protection for certain process software for better enforcement of protection (Dreyfuss and Ginsburg, 2014). Protecting the intellectual property (IP) of these products undoubtedly contributes to the exclusive legal protection of the rights of both inventors and innovators. Thus, the process incentivizes more innovations and economic competitiveness of the hosted firms. Intellectual property rights contribute to enhancing the recognition of the research team that participated in developing the innovative product, disclosure, filing for IPs, registering at the World Intellectual Property Organization WIPO, and obtaining patents. Economically, it brings economic returns to industry and enhances competitive advantages and further triggers higher consumer utilities in the long run. Hence, major industrial countries as India and China have moved toward more legally stringent roles in registering intellectual property rights to better incentivise the patent creator. Moreover, the legislative framework highlights the importance of protecting valued inventions, adding more confidence in the marketplace and more economic competitiveness. Therefore, strategies are to incentivise companies to be more innovative and creative toward monopolist for certain high valued lucrative products. Accordingly, IPR protection enhances the company's position or brands in the financial markets.
Protection varies from one country to another, as does the time duration for IP provisional registration and protection. Trademark protection on the other hand is given to the owner for an unlimited period, whereas 20-year protection is given for registered patents, as well as conditional protection for some types of patents. Different countries have different paths for registering and protecting innovation that differ from others, both in the method used and in the time duration for obtaining protection. In the United States, the US Patents Office (USPTO) registers patents whereas the trademark is registered in individual state offices.33 In Europe, both patents and trademarks are registered in EUIPO.34 Additionally, the world has become more globalized as a result of means of e-commerce, one market approach, for consumer desires (Strazzullo et al., 2022). The development of smart solutions through blockchain technology in the industries as in smart food creates a domain of security solution to tackle any harm to systems of production (Khalil et al., 2022). The trend of e-commerce during Covid-19 pandemic shows a higher preference level among consumers in both developed and developing countries alike as a proactive plan toward consumer safety. E-commerce creates another hurdle for protection of the organizational charts and customers demand portfolios (Khan et al., 2022). Therefore, protecting any product requires codifying the means of protection and making more stringent and committed protection agreements to avoid breach of confidentiality. The aim of this section is to overview the impact of utilizing regenerative Artificial Intelligence in protecting Intellectual Property Rights, especially trade secrets in food manufacturing.
Trade secrets are a different alternative from the other types of Intellectual Property rights. It relies mainly on confidentiality rather than publicity for better competitiveness advantages and product indefinite lifespan. It has different approaches as a result of the importance of maintaining competitive secrecy and also as a result of the effort and sometimes the cost required to reach the final product concept (Quinto & Singer, 2009). A good example is the trade secrets associated with food companies such as Coca-Cola, Mars, Nestle, various sauces from Heinz, sweets, Kellogg's, Harvest Morn, eclipse foods, impossible foods, Beverage, refreshments industries, and many others. It also includes various industries in software science and engineering, algorithms, heavy industries, and engines, as they are highly competitive and have a global demand for products. Thus, the concept of intellectual property has gone beyond the concept of tangible intellectual property to include intangible intellectual property as formulas, equations, programs, methods of production, designs and so forth. For instance, registering a food formula or a software under trade secrets is more valuable than protecting a patent to avoid unauthorized rivals from copying the product. The trade secrets move beyond development of new products to customers list as in medical care facilities and telecom firms. The strategy within food firms is to maintain the position of the company in the global market and increase the shared value in the stock markets. The trade secret, if kept conformality, stays indefinitely as the case of a cola company since the 1880s. Similar things with other big food companies as KFC, distinctive flavor since the 1950s. This perpetual protection of Coca cola formula trade secrets gives the company a competitive advantage over other rivals giving them a head in terms of safeguarding the duration of their invention. Therefore, trade secrets are a valuable asset for food companies and other manufacturers and protection through non-disclosure agreements is an obligation to avoid the misuse of confidentiality.
Despite the positive advantages of trade secrets, the main challenge is the leak of the information via different means (Radauer et al., 2023). Cybersecurity threats can easily steal confidential information. On the other hand, there is a rapid increase in genetically modified food GMO and a rapid increase in the utilization of nanoparticles in producing foods (Clarkson, 2015). This evolution will make a powerful development in the scale of production and would need an urgent protection for the codes of processes. In the meantime, there is a rapid increase in the production of food additives INS, food supplements, vitamins and fortification procedures that would make a bigger competition among the different players in food manufacturing. However, maintaining the trade secrets must implement a robust security system and stringent Non-Disclosure Agreements NDA to address and identify the critical control points CCPs within the food supply chain (Clarkson, 2015). Thus, the commercial protection found in the International Trade Law and linked to the intellectual property of these products as well as agricultural products.35
GenAI plays a major influence on the Food trade secrets. AI transforms agriculture and food sciences to more production, optimization, and technical advancement (Aleksiev & Doncheva, 2022). The application of AI started from the land use, water usage, fertilizers till the prediction of food spoilage and microbial rate proliferation. Therefore, the AI shapes a new arena of a food value chain from the land or the sea to consumer health. Alongside the changes are the use of fertilizers, pesticides residues, and hygienic-sanitary practices (Kataoka et al., 2017). Usually, the food trade secrets undergo several steps as part of new food products development which take quite a longer time of 6–8 months. The process started with the raw materials selections as an input, formulation of ingredients or recipes in the lab, different lab testing, shelf-life testing and market test analysis (Fuller, 2011). It usually takes around 8 months of product definition, and implementation till it reaches the prototype development. During the AI arena, it became wise to use the technology to shorten the time to a few days of raw materials sorting and formula generations. The accelerated shelf-life testing using AI advancement techniques would make it easier in a very few days. This time management and constraint would save process time, budget, cost of IP registration and minimize the possible risks in the food process value chain. It would also increase the success rate of the product in the market. The new formula could also be the new line extension of flavor, color, shape, appearance or integrity of the product as a new form of an existing product with a new trade secret.36
There are cases of developing new protein foods from vegetable protein that matches the needs of vegan diets consumers and some consumers worldwide. The AI could also assess the cultural attributes from the sales department to form a new product that matches the cultural attributes. This was obvious in Mac products in Maharaja Mac in India, McBaguette in France and Mega Teriyaki in Japan. The success rate for successful NPD products is also very low around 5–8% after 30 months of sales in the real market (Salnikova & Stanton, 2019). In the sensory evaluation of foods, the AI technology uses e-nose for flavor testing and e-mouth as textural profile analyzer for mastication. Therefore, beside the negative effects of AI on the confidentiality of food trade secrets, it plays a role in improving the success rate through formula, algorithms, prediction modelling of products safety, shelf testing under several storage conditions and cook up time constraints. Therefore, there are positive aspects in the use of artificial intelligence applications in the development of food products with several kinetics modelling techniques, imaging of raw materials selections and assessing the consumers behavior for cultural and creative products. Thus, promoting the trade secrets of these products if the necessary protection is available. On the other hand, there must be legal enforcement that protects trade secrets between partner companies, which enhances more economic competitiveness. Therefore, trade secret protection is a legal tool for protecting industrial and consumer data. There is an increasing use of innovation-enhancing data in the agricultural and food processing sectors, both in the field and in quality control and food safety. Artificial intelligence is enhanced for manufacturing and food product development and thus more innovation and trade secrets. Conversely, artificial intelligence can be used to copy trade secrets of copycat products unless it finds explicit provisions in the food law technical barriers to trade,37 whether at the level of the World Trade Organization (TRIPS) or the level of intellectual property protection as in World Intellectual Property Organization (WIPO). The open-source AI or simple copy would harm the perpetual trade secrets without clear legal enforcement. The widely available open-source AI for researchers might restrict the commercialization advantage of the trade secrets for novel, and non-disclosed food products in markets.
Copyright and Generative AI: Is there a Match or is it a match? - Tanvi MisraThe rapid expansion of digital technologies compels policymakers, judiciary, and legislative bodies to swiftly address the convergence of national laws with technological innovation. These stakeholders respond with policy and governance guidance in the various domains of convergence. One prominent domain intersecting with technology and the business models developed in response to it has been copyright. From the era of tape recorders to Napster and extending to online platforms and on-demand services, the digital copyright discourse has leaned towards prioritizing access to copyright content over the creation and subsistence of copyright in that content. The discourse mirrors the evolving digital frontier of copyright, especially when a technological advancement gains widespread adoption.
While graphic design software, such as Adobe Photoshop or Canva, has continued to evolve the digital capabilities of content creation, they offer the interested human user tools akin to pen and paper for precise design creation tasks. With the advent of content sharing platforms, user generated content has come to the forefront. It brought with it a deeper interaction of human creation and technology, however, more from the point of authorized access to copyright content. In parallel, computer-generated or computer-assisted works, which are created autonomously by algorithms or through a combination of human and machine processes, have long raised unique copyright authorship and subsistence questions in the past. The recent widespread adoption of GenAI tools has made these questions central to the digital copyright frontier. With the increasing prevalence of GenAI-driven content creation tools, and the blurred lines between human-authored and AI-generated works, it's imperative to carefully assess and apply the international copyright framework and meaningfully consider the potential requirement of re-evaluating the national copyright framework.
Human centric AuthorshipCopyright authorship in autonomous GenAI outputs and in GenAI assisted outputs has been a ‘Berne-ing’ question from the perspective of the user of GenAI tools. Eminent copyright scholars have opined that the Berne Convention, which is the oldest and the most fundamental international copyright treaty, emphasizes the human centric approach to copyright. The subject matter of copyright protection under Article 2 of the Berne Convention informed the fundamental shared understanding among the contracting states regarding the meaning of authorship as the persons who created the works rendering the explicit definition of authorship unnecessary (Ginsburg, 2018). Thus, it is reasonable to interpret "authors" and "authorship" within the Berne Convention and across the international and national copyright framework as referring to those persons who create the works. For cinematographic works, the Berne Convention provides copyright to be attributed to the "maker", however it is widely cautioned that this should not undermine the fundamental human-centric notion of authorship and authors’ rights.
In almost all jurisdictions, whether implicit in the national copyright legislation or determined through underlying policy and judicial interpretations, originality, which is the threshold requirement for subsistence of copyright, is held to be an expression of human authorship. Courts in various jurisdictions including the United States, the United Kingdom, the European Union, Australia, and Singapore have all upheld the necessity of a human author of copyright works. The U.S. Copyright Office has reiterated the necessity of human authorship in the graphic novel “Zarya of the Dawn” which utilized Midjourney, a form of GenAI, to produce a series of images which the human author used in the graphic novel alongside her human-generated storyline. Thus, while autonomous GenAI outputs are not eligible for copyright protection, GenAI-assisted outputs featuring human contribution are eligible, contingent upon the ‘originality’ of the human-contributed work. An implication of this is that optional copyright registration procedures, being voluntary under the international copyright framework, might gain more relevance by requiring human authors to explicitly disclaim any material produced by GenAI. The requirement of formality free protection of copyright works may be stretched to accommodate this delineation of human and GenAI authorship, considering this as a substantive condition relating to creation like ‘originality’. There cannot, however, be a condition to the enjoyment and exercise of copyright (WIPO, 2004).
Originality as a Necessary Condition for Subsistence of Copyright in the GenAI OutputDetermining the subsistence of copyright, which requires the necessary assessment of originality, in works created with human assistance through GenAI poses a more intricate challenge than the notion of human authorship in copyright. What is the human author's contribution in the expressive content of the GenAI output that meets the legal threshold of ‘originality’? The concept of ‘originality’ itself varies across different national jurisdictions. If there is no ‘originality’ in the GenAI output attributable to a contribution by the human author, there will be no GenAI-assisted creation eligible for copyright protection. Prompt engineering as a human contribution leads to a diverse array of GenAI outputs, sparking ongoing legal scrutiny regarding its impact on the originality requirement in the United States. The inherent unpredictability of AI algorithms, which can generate different results even with identical prompts, raises questions about meeting originality standards for the human author. There is ongoing deliberation over whether both the individual who programs the AI and user of AI should be considered authors.
Input for Training of GenAILLMs and other GenAI systems are typically trained with vast amounts of data, some of which may include copyrighted material. According to some commentators and AI developers, these models do not store the expressive content of a copyrighted material for retrieval or reproduction. Instead, training data is ingested and analyzed for statistical patterns after being tokenized into dimensions enabling semantic and structural analysis. What is learned is the patterns inherent in the content across the entire training data set, rather than the content itself, which is not subject to copyright, thus leading to non-liability for unlicensed Text and Data Mining (TDM) activities (BSA Comments on Draft Approach to AI and Copyright, 2024). On the other hand, an analysis by the News/Media Alliance (and other commentators on copyright material in general) states that GenAI developers predominantly access and use online news, magazine, and digital media content to train their GenAI models. LLMs typically store valuable media as compressed copies or effective compressed copies, for their written expression, aiming to analyze and identify sequences of words. This involves capturing of the expressive content of the copyright material, which fuels the success of LLMs and other models by aiding them in predicting the next word in a sentence (AI-White-Paper-with-Technical-Analysis, 2023).
Unauthorized acts of accessing, reproducing, and storing of copies of copyright material could breach copyright and contractual restrictions. One way of permitting such acts is through national copyright provisions on limitations and exceptions to copyright and related rights framed in accordance with the ‘three-step test’. The three-step test specifies that non infringing uses of copyright works and protected subject-matter are limited to (a) certain special cases; (b) which do not conflict with a normal exploitation; and (c) do not unreasonably prejudice the legitimate interests of the authors. The three-step test is applicable cumulatively to each act that derives benefit from copyright (that is each act that results in the “enjoyment of copyright”). There has also been a growing awareness that consideration of the three-step test is needed to ensure that a fair balance of rights and interests is struck.
National legislative trends indicate that many jurisdictions have enacted purpose specific fair dealing exceptions to facilitate certain TDM activities (Rosati, 2023). The current TDM provision in Singapore is widely acknowledged to be broader in scope compared to similar provisions in Japan, UK, and EU national copyright legislations and regional frameworks. The TDM provision in Singapore contains certain specific conditions, such as lawful access to copyrighted material and the exclusive use of copies for computational data analysis, which is specifically defined in the Act. The definition necessitates the utilization of specific copyrighted material for the extraction and analysis of information or data and its use as an example of information or data for improving the functioning of a computer program. Circumventing an access control measure would make any access to a copyright work unlawful and the TDM exception would not apply. Additionally, Singapore's copyright law prohibits contractual override, that means any contractual term that purports to exclude or restrict the operation of the exception will be void and unenforceable. The TDM provision in Japan mandates a distinction between data use solely for analysis and processing and those involving "enjoyment" of the work, which would negate the exception. "Enjoyment" encompasses benefiting from the content, disqualifying the data's use under the TDM exception, if present. The third step of the three-step test is also specifically mentioned. At present there is ongoing public consultation in Singapore and Japan on areas in the respective copyright acts including lawful access for TDM exceptions to be applicable. In the US, no legislative reforms have occurred, with ongoing litigation shaping the extent to which fair use doctrine accommodates unlicensed TDM activities, particularly in training AI systems.
Future research will explore several areas concerning the interaction between GenAI technology and copyright law, and some key areas are reflected in this paper. Firstly, assessment of the originality requirement in the human contribution to a GenAI assisted work. Secondly, analyzing whether the outputs generated by these models are consequent or not on the use of the copyright material at the input stage. In other words, whether there is a causality between input and output, and to what extent is it relevant. This would require a necessary further enquiry into what would be the proof of infringement in a claim which would need varying degrees of veracity at the interim stage and trial stage. Thirdly, careful consideration is required on the impact of purposeful prompt engineering by a user to solicit infringing outputs and solutions for identifying and ‘forgetting’ copyright material determined to be used unauthorizedly as input. Fourthly, how a GenAI assisted output can serve a competing function of disseminating expressive content to the public would provide valuable insights into the applicability of the three-step test. Fifthly, to examine whether the offering of licenses by rightsholders could override copyright exceptions for TDM purposes. Understanding how different jurisdictions navigate these and other issues would determine the potential need for national legislative reforms, an assessment of which itself could be a focus of future research in this area.
A crucial aspect for future research is the nature of liability associated with GenAI technology. As GenAI systems become more prevalent in content creation and data analysis, questions arise regarding accountability for any potential copyright infringement or other legal violations. Examining the applicable national legal frameworks and potential liabilities for developers, users, and owners of GenAI systems could provide valuable insights into addressing these challenges. All these areas of future research should aim to ensure a match of copyright with GenAI technology and not a match between them.
Generative AI: Creative Disruption and Legal Intellectual Property Challenges- Adil S. Al-Busaidi & Thuraya Al-AlawiLegal Challenges of AIGenAI is rapidly advancing, generating content by training its model using large amounts of data, some of which may be protected by copyright law. This rapid advancement and its emerging use cases are not only disrupting “traditional views of creativity, authorship, and ownership” (Holloway et al., 2024) but also “pushing the boundaries of copyright law” (Holloway et al., 2024). This is evident in the collective lawsuits filed by eight newspapers, including New York Daily News, Chicago Tribune, Orlando Sentinel, Sun-Sentine, Mercury News, Denver Post, Orange County Register, and Pioneer Press, against OpenAI and Microsoft (Novet, 2024). The publishers have accused OpenAI and Microsoft of reusing their work without permission and incorrectly attributing false information to them. The legal implications of these cases are significant, as they challenge the existing copyright laws and raise questions about the role of AI in creative processes.
The issue with these filed lawsuits is that IPR laws in many countries were formulated before the development of GenAI (WIPO 2024a). For this very reason, complexities of filing IPR surfaced. For example, an AI inventor, Device for the Autonomous Bootstrapping of Unified Sentience (DABUS), was rejected for protection by IPR because no human inventor was involved (WIPO 2024a). As a result, the US Copyright Office has provided guidelines on creative works generated by AI. The guidelines suggest that “a creative contribution from a human is required… text prompt alone may not establish copyright” (WIPO 2024a). Contrary to this guideline, the Beijing Internet Court (BIC) allows individuals to retain copyright rights in the case of AI-generated images. The rationality of the BIC is that an individual has contributed with aesthetic choice with his/her prompt engineering (WIPO, 2024a).
Complexities of GenAI and IPOther countries (e.g., UK, South Africa, New Zealand, India, Ireland) accommodate copyright protection requests for work generated by computers without human authors (WIPO, 2024a). This raises the question of AI personhood. Some efforts have been made to conceive and define what counts as legal AI personhood (Graves, 2023; Kurki, 2019). Kurki (2019) suggested three contexts to be considered when it comes to treating AI as a person: a) moral status or value context; b) responsibility context (holding AI responsible); and c) commercial context (holding an autonomous role in commercial transactions. More research is needed to explore the current impact and the rapid progression of GenAI and the questions of GenAI related to ownership, co-ownership, personhood, and the balance approaches between innovation promotion and IPR protection.
While some countries have laws that allow exceptional use of protected IP to promote innovation under the fair use principle, such as text, temporary copying, and data mining (WIPO, 2024a), other countries might need more informed, data-driven research IPR policies in the age of GenAI. That being said, some organizations have already taken steps to regulate and attempt to protect their innovative creative outputs. For example, to mitigate copyright infringement, some companies declare ‘Opt Out’ for using their content to train the AI models. Recently, Sony Music warned AI developers from using its content to train AI models (Sony Music, 2024).
Research AgendaAs we can see above, different organizations and different countries handle GenAI creative work differently, further complicating IPR laws in the age of GenAI. We call on researchers to develop theories and frameworks that could help the scientific community and practitioners understand and explain the complexities of GenAI on IPR. One question worthy of investigating is the dialectical tension having WIPO striving to promote an ecosystem that enables creativity and innovation while protecting the inventor's rights at the same time. What models and theories could better help to understand and unpack the complexity of the opposing forces between enabling innovation and protecting IPR? Are approaches like dialectical views (e.g., Benson, 1977) relevant to unpacking the complexities of GenAI? We present, in the below section, types of IP, GenAI disruption, and potential areas of investigation for each IP type.
Patentsare an exclusive right for a limited time, normally 20–25 years, given by the country's authority office to the inventor due to his/her effort in inventing a new solution, either a product or process, if it meets the conditions of novelty, inventive step, and industrial application. The monopoly right is given in exchange for disclosing the details of the invention to society. While GenAI could infringe the content of filed patents, GenAI could also be used to discover new drugs and unpack new scientific patterns. We call on researchers to develop frameworks that could further help employ GenAI aimed at helping discover new inventions and systems that could expedite patenting filing and patent applications. Questions of (c)ownership could also be explored, and under what conditions, given that the patent is based on a generated formula with human prompts.
Trademarksare signs that distinguish one competitor's products or services from those of others. They can be words, letters, numerals, drawings, shapes, pictures, or a combination of all these. Trademarks must be novel and precise and not mislead the consumer. How could GenAI help inventors generate trademarks and find gaps in brand names? What are the benefits and risks of using GenAI on Trademarks filings? How could new startups and SMEs capitalize on the power of GenAI to file trademarks?
Industrial design isthe external appearance of products. The World Intellectual Property Organization (WIPO) defines industrial design as “the ornamental aspect of an article” (WIPO, 2024c). It can consist of three-dimensional features like the shape or configuration of the product, two-dimensional features like patterns, lines, and colors, or a combination of these. What are different ways to elevate the power of GenAI to produce aesthetically creative industrial design? What is the relationship between Industrial designs generated by GenAI and brand acceptance?
Copyright and related rightsare the rights given to the authors for their literary and artistic work. Copyright does not provide the right to the idea itself; it is the expression of that idea by creating a book, a novel, poetry, paintings, films, computer programs, or any other kind of artistic creation. The related right, as its name is linked with the copyright by disseminating the work through different intermedia. It mainly consists of three categories: performing artists, producers of sound recordings, and broadcasting organizations. What are the various models that could help creators using GenAI to produce art, music, and literature to avoid copyright infringements? Under what conditions creators are allowed to scrape existing copyrighted content without violating IPR?
Geographical indicationsare “signs used on products that have a specific geographical origin and possess qualities or a reputation that are due to that origin” (WIPO, 2024b). In general, the name and the place of origin determine a geographical indication. How could blockchain technology and GenAI help verify the origins and attributes of goods protected by geographical indications?
Trade secretsare confidential information, either technical, commercial, or both, that the inventor prefers to keep secret rather than disclose to the public. It may give the company a competitive advantage over the competitors. AI-related commercial contracts are still evolving and developing, and the mechanism by which AI developers license their AI solutions is not precise. In these commercial activities, AI-generated outputs and their ownership raise IP ambiguity, and confidential information (e.g., trade secrets) might be compromised (WIPO, 2024a). How would GenAI negatively impact trade secrets? What are the most effective ways to contract commercial activities of GenAI solutions without disclosing confidential information?
New plant varietiesare plants that, through successive generations, exhibit unique characteristics distinguishing them from other known plants. These varieties are not naturally found in the wild but are developed through human efforts in plant breeding. How could GenAI help researchers in genomics and bioinformatics develop new plant varieties?
DiscussionThe individual contributions from the invited experts present a number of unique perspectives on how the widespread use of GenAI has impacted copyright and IPR. Fig. 1 highlights the range of challenges identified by expert perspectives and presents a thematic analysis of the major topics related to copyright and intellectual property discussions. The analysis of the individual contributions and development of the presented themes is detailed in the following sections.
Emerging Challenges and Implications for Copyright and IPR
GenAI's capability to generate original content such as text, images, and music is redefining the traditional boundaries of copyright law (3.7) .38 The democratization and widespread use of GenAI tools has prompted an active analysis of use cases that seek to improve understanding of GenAI's applications and implications (3.4). GenAI operates through advanced neural networks and learning models, involving stages of pre-training on vast datasets. These stages have led to the generation of new content based on user inputs (3.2). This shift necessitates a reassessment of legal, ethical, and societal norms and challenges related to creativity, ownership, and the sharing of intellectual goods (3.1, 3.4). The implications of the widespread adoption of GenAI and copyright have been felt at a global level. The United States focuses on human creativity and intellectual labor and has questioned the ownership of GenAI outputs and the legality of its learning processes, whereas China has reflected on its own evolution of copyright law, grappling with whether AI can meet the criteria of "intellectual achievement”. The UK was slow to foresee the extent of GenAI's capabilities with current discussions seem to focus on the regulation of AI in respect to third-party copyrighted materials. The EU has faced tensions between fostering digital technology whilst protecting citizen rights, with ongoing development of regulations like the Artificial Intelligence Act (3.3, 3.6). The territorial nature of IP rights poses challenges in managing risks across different jurisdictions. The recent EU AI act, which mandates transparency in the use of training datasets and watermarking of AI-generated synthetic content, exemplifies efforts to harmonize GenAI regulation (3.4).
Legal Complexities and Navigating the Evolving LandscapeThe relationship between technology and copyright has been contentious, starting from the printing press to digital media and the Internet. Each new technology has prompted adjustments in copyright law (3.3). Leading copyright scholars highlight that the Berne Convention, a cornerstone international copyright treaty, underscores a human-centric approach to copyright. According to Article 2 of the Berne Convention, the understanding among member states is that "authors" are those who have physically created the works, making an explicit definition of authorship unnecessary (Ginsburg, 2018). While the Convention allows copyright to be attributed to the "maker" of a cinematographic work, it is emphasized that this should not detract from the primary focus on human creators and their rights, preserving the human-centric essence of authorship within both international and national copyright frameworks (3.10, 3.11). The rise of AI-generated content highlights gaps in existing copyright frameworks, which generally recognize only human authors. Initially, U.S. copyright law, established by the Constitution, aimed to promote innovation by granting exclusive rights to human authors and inventors, without foreseeing AI's role as potential creators (3.3). There's a significant legal debate over whether AI-generated works can be copyrighted and how laws should adapt to acknowledge AI's role in creative processes (3.1). Legal discussions focus on whether GenAI's use of copyrighted data during training constitutes infringement and who bears responsibility—the platform owner or the user (3.2). GenAI systems extensively use existing data, including copyrighted material, to train their LLM's, leading to debates over the legality and ethics of such practices (3.1, 3.2, 3.3, 3.10, 3.11).
The recent lawsuits, such as those involving Stability AI and OpenAI, where the central issue is whether the use of copyrighted materials to train AI systems constitutes infringement highlights the complexity in this area. Notable legal challenges include cases like the New York Times suing OpenAI for allegedly using copyrighted content without permission. These cases test the boundaries of fair use, especially concerning transformation and market impact (3.8). OpenAI argues that its training processes decompose language into basic elements, which are transformative and do not retain copyrighted material, drawing parallels with successful defenses in cases like Google Books (3.8). These legal challenges highlight the tension between innovation and copyright protection (3.6). Some jurisdictions, such as the EU and the US, offer certain flexibilities (e.g., text and data mining exemptions, fair use doctrine) but also introduce complexities and conditions that could hinder innovation (3.1, 3.5, 3.10). The global deployment of AI technologies means that IP protection must be addressed across varying international jurisdictions (3.8). Legal frameworks like the DMCA in the U.S. and similar laws globally offer some protections and exceptions, but GenAI's complex operations challenge these traditional structures (3.2).
Organizations face a dilemma between leveraging GenAI to empower individuals with better access to information and the need to manage legal and commercial risks (3.7). The need to balance protecting intellectual property rights and trade secrets with fostering AI innovation is critical (3.9, 3.4). Proposals for adapting include recognizing joint authorship between AI and humans, creating new copyright categories for AI-generated works, and potentially establishing statutory licenses to compensate creators whose works are used in training AI (3.1). The concept of 'misuse cases' analysis involves examining potential negative outcomes from GenAI interactions, focusing on hypothetical scenarios where actions can result in harm or loss to stakeholders is advocated as a way to engage with this complex landscape triggering the generative scholarship of researchers and practitioners. This analysis is crucial for identifying IP risks and preparing for effective mitigation strategies in GenAI development, deployment and maintenance stages (3.4).
Creativity, Authorship, Ownership and the Role of IntermediariesCopyright traditionally protects human creativity, ownership and originality. The advent of AI challenges these definitions because AI can generate new content by learning from existing copyrighted materials without clear human authorship (3.6). GenAI has significantly enhanced content creation by making it faster, more personalized, and scalable, lowering barriers for non-professionals to enter creative fields (3.8). GenAI has expanded beyond textual content to fields like music composition, influencing significant market segments like the global music industry, worth US$26 billion annually, raising critical questions about the ownership and rights associated with AI-generated content (3.3). The current copyright system is described as outdated, overly restrictive, and controlled by powerful intermediaries who benefit at the expense of creators (3.5). Intellectual property rights are designed to protect and incentivize creators, extending exclusive rights to use, modify, and commercially exploit their creations (3.6). Discussions about fair use, particularly in training LLMs, are ongoing. There exists an ongoing debate on whether AI can be considered an author or if its outputs merely assist human creativity, complicated by current legal frameworks that typically do not recognize AI as capable of holding copyrights (3.6). It is problematic to ascertain the human author's contribution to the expressive content of the GenAI output that meets the legal threshold of ‘originality’ (3.10). The original notion of fair use for non-commercial purposes is being tested as GenAI enters commercial domains (3.3). IPR is essential for protecting creations such as inventions, artistic works, and trademarks and is foundational in assessing the implications of GenAI. Misuse cases often involve breaches of these rights, underscoring the need for careful management of GenAI in relation to IP (3.4). However, there is a different perspective that posits whether copyright intermediaries (like publishers and copyright holders) are hindering innovation by attempting to impose restrictive copyright laws that limit the use of GenAI tools in creative processes (3.5). There exists a case for perhaps revisiting the traditional factors of the fair use test to better accommodate the social contract between humans and disruptive technologies like GenAI, possibly adding new factors to the evaluation process (3.5).
Regulation, Policy, and Ethical ConsiderationsInnovations in AI pose huge challenges to creators and regulators, particularly concerning who holds copyright when AI generates outputs (3.6). GenAI models are marked by reliance on large amounts of human-generated content, used without compensation, and a general resistance to regulatory oversight. This poses ethical and legal concerns, especially since the data often include copyrighted materials acquired without proper consent (3.1). As GenAI technologies like ChatGPT have rapidly developed and adopted, they challenge existing legal and ethical frameworks at a global level, creating friction within the information supply chain (3.7) as well as information distortion through ease at which deepfakes can be infused (3.4). Legislators struggle to balance regulation with the opportunities GenAI offers for productivity and new industry sectors (3.3). Historical cases (like Sony Betamax and Google Books) illustrate how transformative uses of copyrighted material can benefit society.
For GenAI, it's important to evaluate the transformative impact and added value that these technologies bring to society and the potential for the technology to liberate artists from the constraints imposed by traditional copyright intermediaries, offering a new form of creative freedom (3.5). Balanced policies are needed that protect original creators' rights while also fostering innovation in AI (3.6, 3.9). The widespread use of GenAI could either diminish demand for original works or create new licensing opportunities. There is a potential need for compulsory copyright licensing specifically tailored for AI, which could standardize usage of copyrighted content and reduce litigation (3.8).
Perspectives on the Future and the Adaptation of Copyright LawThe ongoing evolution of AI technologies requires a comprehensive re-evaluation of copyright laws and IPR to ensure they are suited for the age of synthetic creativity. Stakeholders need to engage in dialogue and develop innovative, balanced solutions that protect creators while promoting technological advancement (3.1, 3.6). There's an ongoing need for clarity in how laws apply to GenAI, particularly regarding what constitutes a derivative work, the criteria for "substantial similarity", and the application of fair use doctrine. Future research is urged to explore these issues to ensure that legal frameworks can adequately address the novel implications of GenAI technologies (3.2). There is a call for more research and clear policies to address the unresolved legal issues surrounding GenAI and a greater emphasis on risk-based governance (3.7). The overarching challenge is to balance innovation with the rights of creators and the public interest, possibly requiring a re-evaluation or entirely new approaches to copyright law (3.3). There exists a necessity for a comprehensive approach to policy design, addressing GenAI's complex social, ethical, and legal challenges. Calls are needed for continued research into the both endemic and systemic issues posed by GenAI, suggesting that innovative policy solutions are required to manage these emerging technologies effectively (3.4, 3.5, 3.9). Responsible research enquiry in this domain would involve pivoting from engaged scholar to a generative scholar who can proactively indulge in prospective theorization efforts (3.4). Policy makers need to better understand how AI is reshaping jobs and production processes in creative sectors, and how legal definitions of authorship and creativity might evolve (3.4).
The Future of AI Innovations and Intellectual Property Constraints: Dynamic Ethical FrameworkIt is clear from the expert contributions presented in this paper, that current copyright and IPR laws are not fit for purpose to deal with the rapid advancements in GenAI technology. Current legal frameworks do not work or are ill equipped to deal with the complexities of AI-driven content creation. GenAI's ability to push the boundaries and landscape of creativity, authorship and ownership has exposed significant shortcomings in copyright laws, exposing the many dilemmas underlying fair compensation for IP rights. We propose the Dynamic Ethical Framework (see Fig. 2) as a mechanism to develop greater insight into the many underlying complexities and competing stakeholder priorities surrounding the development and use of GenAI models.

This proposed framework presented in Fig. 2, requires consideration within both the innovation and development of GenAI technology (illustrated in the “GenAI Platform Developers” element of the framework) and as responsible practices by users around “authorship” and “ownership” of the GenAI outputs. In this context – GenAI platform developers and owners such as OpenAI, Google AI and Microsoft Azure AI are deemed to be responsible for LLM training and development. These elements should be driven and guided by an ethical framework that fosters innovation whilst fostering the “fairness” aspects of policy in the development of copyright and IPR of content. The three key elements are discussed below:
GenAI Platform DevelopersMany of the current issues around GenAI content and copyright, IPR issues stem from the training data of LLMs. The current situation of poor levels of transparency on the training and composition of LLMs raises issues relating to the protection of original copyrighted data and the fair use of “underlying content used in training their models” (3.8). The fact that there is a “current absence of explicit guidelines”, creates a “climate of uncertainty among both AI developers and content creators” (3.1). With this in mind, any ethical framework must ensure that transparency exists in this domain coupled with responsible data usage and clear terms of reference of service for users of this technology. GenAI platform developers must be incentivized and take responsibility to ensure that potential risks around content misuse are mitigated when training and developing LLMs.
AuthorshipThe literature has debated the feasibility and implications for “a machine can claim such authorship” (3.6). After all, AI technology has the capability of generating outputs that raise “profound questions about the nature of creativity and the definition of authorship” (3.1). With some arguing that authorship must stem from a “human centric approach to copyright” something that is stressed in the Berne Convention (3.10). However, users of GenAI must also be mindful and transparent when authoring work that has utilized GenAI to assist in its creation. This would necessitate that such work has been created fairly by disclosing the role of AI in data creation and developing full traceability where AI created data can be integrated to provide visibility of original sources. In consideration of “how legal constructs around authorship and creativity might evolve in response to AI” (3.8), revised terms of service of GenAI models could encapsulate these factors. The terms of service would facilitate “reconciling AI authorship and creativity model within the framework of copyright law” by creating a “form of joint authorship” (3.1) that is considerate of the “legal, social, environmental, and economic ramifications of assigning authorship/inventorship/ownership of IP and related rights to AI agents” (3.4).
OwnershipThe literature has identified that the current legal frameworks and current fair use policies are struggling to protect content creators (3.1, 3.3, 3,4). It is for this reason that a future ethical framework must protect against unauthorized use or exploitation of AI-generated content by GenAI providers and its users through clear “guidelines and parameters around ownership” (3.6, 3.9). These factors are somewhat complicated by “the inherent unpredictability of AI algorithms, which can generate different results even with identical prompts, raises questions about meeting originality standards” (3.10). The current lack of transparency in the training of LLMs by GenAI platform developers, is likely masking the inadvertent use of copyrighted data to “disclaim ownership” (3.5). It is thus critical that accountability, attribution and permission/consent is given around ownership of content. This must be driven by an ethical framework but also assisted by GenAI platform developers and responsible data usage. Any framework must be mindful of not stifling the “creativity machine” with unnecessary “structures and power dynamics that intermediaries use” (3.5) whilst “protecting Generative AI's ownership of output to reward creativity and innovation” (3.6).
The fluidity of the current situation is represented by the dynamic aspect of the proposed framework, representing the “dynamic interplay between human creativity and AI content” (3.1). The framework needs to sit comfortably within current (or updated) laws, policies and regulations whilst working within an environment that encourages best practice through adequate licensing, setting of guidelines and standards and the “power dynamics that play out in contractual negotiations between IP owners and GenAI” (3.4). The Dynamic Ethical Framework and the environment it operates within, needs to be integrated with misuse case analysis, training, education and awareness raising initiatives for GenAI providers (developers), stakeholders and policy makers. The combination of these factors will drive forward a future “Global Fair AI Use” Policy that encapsulates the fair use doctrine from the US and the “fair dealing” framework in the UK and Canada, to deliver a clear, unified global policy that transcends borders. It is critical to ensure international collaboration on GenAI policy and copyright and to harmonize intellectual property laws (3.8, 3.4). The proposed framework is posited as helping in addressing “the existing ambiguity and complexities surrounding copyright issues in Generative Artificial Intelligence, including the "fair use doctrine" and the "substantial similarity test." (3.2).
Recommendations for Research and PolicyThe individual topics from the expert contributors relating to copyright and the use of GenAI have highlighted a number of paths forward that directly impact both academia and practice.
Researchers are encouraged to develop and test several of the research propositions emerging from the discussion presented by expert contributors in this study. Many of the individual contributions highlight the need for further research that analyses the implications of a balanced policy that incorporates the needs of GenAI providers, protects IP and copyright, whilst engendering further innovation. Future policy will need to offer clarity, fairness and protection requiring a comprehensive understanding of the ethical, technological and legal dimensions of AI and creativity. Interdisciplinary research and empirical studies are critical to furthering our understanding on how the further adoption of GenAI can better adhere to a fair and just ethical and legal policy framework. The global nature of LLM training and GenAI adoption, necessitates an intergovernmental approach to policy development and governance where a consistent approach can be developed that serves to offer a pragmatic solution to the myriad of complexities in this area.
A key area for future research is the development of a greater understanding of the liability related to GenAI technology. As GenAI based systems increasingly contribute to content creation and data analysis, questions about accountability for potential copyright infringements or other legal issues are emerging. The investigating of national and international based legal frameworks and possible liabilities for developers, users, and owners of GenAI platforms using generative scholarship, could offer valuable insights into tackling these challenges. The goal of such research should be to align IP including copyright laws with GenAI technology, rather than the development of an adversarial relationship that would stifle further innovation.
Implications for PracticeThe current position of poor levels of transparency and accountability in the training of LLMs has perpetuated the disconnect and feelings of disenfranchisement from content creators and copyright owners. As governments and policy makers attempt to catch up with the implications of widespread GenAI usage, the industry is likely to face increased levels of scrutiny and accountability on the detailed processes inherent in LLM building and training. GenAI platform developers are recommended to focus on the development of auditable LLM training processes that ensure higher levels of transparency to engender greater levels of understanding of the link between original content and GenAI developed data. Practitioners can use ‘misuse case analysis’ detailed in this work as an innovative tool to responsibly understand the implication of GenAI tools and IP risks at development, deployment and maintenance stages. This shift in focus to a more proactive and transparent approach could develop increased trust within the industry and help to develop a path toward a fair use orientated approach to the use of IP including copyrighted data that better recognizes the role of content creators (Gans, 2024).
ConclusionsThis study has developed a multi-perspective narrative of the underlying complexities surrounding GenAI and how it is reshaping perspectives on existing IP and copyright law. The ability of GenAI to create original content, has the effect of democratizing content creation and enhancing scalability across sectors. However, the technology presents many challenges due to the training of LLM on datasets that often contain copyrighted materials, necessitating a re-evaluation of intellectual property rights within a global context. Legal disputes, such as the New York Times versus OpenAI, highlight the complexities of defining fair use, particularly around transformation and market impact. We present the Dynamic Ethical Framework and “Global Fair AI Use” Policy for Responsible Development and Use of GenAI tools and technology, which provide a structured model as a lens for both researchers and practitioners to examine the many complexities and key factors relating to IPR and copyrights in the increasing use of human-created content by GenAI platform developers. This evolving landscape demands adaptive legal frameworks that balance innovation benefits with intellectual property protection. Proposals for new regulatory approaches, such as compulsory licensing tailored for AI, aim to standardize the use of intellectual property and copyrighted content and reduce litigation, fostering an innovation-friendly environment. Stakeholders must engage in dialogue to develop policies that protect creators' rights while accommodating technological advancements, ensuring that IP and copyright law evolves in step with GenAI.
DisclosureSome parts of the manuscript may have been edited with the assistance of Generative AI tools, such as GPT-4, for grammar correction and stylistic improvements. All content, intellectual contributions, and final interpretations remain the responsibility of the authors, who have thoroughly reviewed and approved the final version of the manuscript.
CRediT authorship contribution statementAdil S. Al-Busaidi: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. Raghu Raman: Conceptualization, Data curation, Formal analysis, Funding acquisition, Methodology, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. Laurie Hughes: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. Mousa Ahmed Albashrawi: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. Tegwen Malik: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. Yogesh K. Dwivedi: Writing – review & editing, Writing – original draft, Visualization, Validation, Supervision, Software, Resources, Project administration, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. Thuraiya Al- Alawi: Writing – review & editing, Writing – original draft. Mohammed AlRizeiqi: Writing – review & editing, Writing – original draft. Gareth Davies: Writing – review & editing, Writing – original draft. Mark Fenwick: Writing – review & editing, Writing – original draft. Parul Gupta: Writing – review & editing, Writing – original draft. Shashikala Gurpur: Writing – review & editing, Writing – original draft. Apeksha Hooda: Writing – review & editing, Writing – original draft. Paulius Jurcys: Writing – review & editing, Writing – original draft. Daryl Lim: Writing – review & editing, Writing – original draft. Nicola Lucchi: Writing – review & editing, Writing – original draft. Tanvi Misra: Writing – review & editing, Writing – original draft. Ramakrishnan Raman: Writing – review & editing, Writing – original draft. Anuragini Shirish: Writing – review & editing, Writing – original draft. Paul Walton: Writing – review & editing, Writing – original draft.
Note: The views and opinions expressed by each contributor in their respective subsections are solely their own and do not necessarily represent the collective views and reflections of all co-authors.
https://chat.openai.com/
https://gemini.google.com/?hl=it
https://grok.x.ai/
https://openai.com/research/dall-e
See art. 7(1), Berne Convention for the Protection of Literary and Artistic Works, Sep. 9, 1886, 102 Stat. 2853, 1161 U.N.T.S. 3.
Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence, 88 Fed. Reg. 16190 (Mar. 16, 2023) (to be codified at 37 C.F.R. pt. 202).
See, for instance, Case C-5/08 Infopaq International A/S v Danske Dagblades Forening and Case C-145/10 Eva-Maria Painer v Standard Verlags GmbH et al., emphasizing the requirement for a work to reflect the author's “intellectual production” and personal creative touch to meet the originality criterion.
Numerous lawsuits in the US challenge the use of copyrighted content for training generative AI systems, see e.g. Getty Images (US), Inc. v. Stability AI, Inc., No. 1:23-cv-00135-GBW (D. Del. Mar. 29, 2023); Silverman et al. v. OpenAI, Inc. et al., No. 4:23-cv-03416 (N.D. Cal. Jul. 7, 2023); Tremblay et al. v. OpenAI, Inc. et al., No. 4:2023-cv- 03223 (N.D. Cal. Jul. 7, 2023); The New York Times Co. v. Microsoft Corp., No. 1:23-cv-11195 (S.D.N.Y.).
17 U.S.C. § 107 (2018).
See Authors Guild v. Google, Inc., 804 F.3d 202 (2d. Cir. 2015).
See supra note 8.
See art. 3 and 4, Directive Council Directive (EU) 2019/790 of the European Parliament and of the Council of 17 April 2019 on Copyright and Related Rights in the Digital Single Market, 2019 O.J. (L 130)
See art. 3, Directive Council Directive (EU) 2019/790.
See art. 4, Directive Council Directive (EU) 2019/790.
See European Parliament legislative resolution of 13 March 2024 on the proposal for a regulation of the European Parliament and of the Council on laying down harmonised rules on Artificial Intelligence (Artificial Intelligence Act) and amending certain Union Legislative Acts (COM(2021)0206 – C9-0146/2021 – 2021/0106(COD)).
Copyright Office, Government of India. THE COPYRIGHT ACT, 1957 (14 OF 1957). Accessed March 17, 2024, https://www.copyright.gov.in/Documents/Copyrightrules1957.pdf
In 2019, European Union countries adopted “Directive 2019/790 on copyright and related rights in the Digital Single Market," a EU directive to harmonize copyright laws across member states Czarny-Drożdżejko, E. (2020). The subject-matter of press Publishers’ related rights under Directive 2019/790 on Copyright and related rights in the digital single market. IIC-International Review of Intellectual Property and Competition Law, 51(5), 624–641.).
Getty Images vs. Stable Diffusion creator Stability AI
Andy Warhol Foundation for Visual Arts, Inc. v. Goldsmith. 143 S. Ct. 1258.
https://ifpi-website-cms.s3.eu-west-2.amazonaws.com/IFPI_GMR_2024_State_of_the_Industry_db92a1c9c1.pdf
Joyce, C., Ochoa, T. T., Carroll, M. W., Leaffer, M. A., & Jaszi, P. (2016). Copyright law (Vol. 85): Carolina Academic Press Durham, NC.
https://www.europarl.europa.eu/RegData/etudes/BRIE/2021/698792/EPRS_BRI(2021)698792_EN.pdf
See generally repositories such as https://www.aiaaic.org/aiaaic-repository and https://incidentdatabase.ai/
Beijing Internet Court Civil Judgment (2023) Jing 0491 Min Chu No. 11279 , accessed on 20 November: https://english.bjinternetcourt.gov.cn/pdf/BeijingInternetCourtCivilJudgment112792023.pdf.
Paulius Jurcys's research for this paper was supported by the JST Moonshot R&D Grant Number JPMJMS2215.
Author's Guild v. Google , 804 F.3d 202, 212 (2d Cir. 2015).
Andy Warhol Foundation for Visual Arts, Inc. v. Goldsmith (2023). Harvard Law Review, 137 (1). Accessed March 5, 2024. https://harvardlawreview.org/print/vol-137/andy-warhol-foundation-for-visual-arts-inc-v-goldsmith/#footnote-ref-2
Getty Images (US) Inc. v. Stability AI, Ltd. and Stability AI, Inc., No. 1:23-cv-00135-GBW (D. Del. March 29, 2023) Amended Complaint at ¶¶ 61-62 (Dkt. 13).
Andersen v. Stability AI et. al., No. 3:23-cv-00201 (N.D. Cal. January 1, 2023) Complaint at 8-9 (Dkt. 1).
Thaler v. Permutter, Case No. 22-cv-1564 (D.D.C. 18 August 2023).
https://www.lexology.com/library/detail.aspx?g=aab8f7b7-e529-4859-a557-7aa342cf2833