






El ensayo clínico con asignación al azar es el método más fiable para determinar la eficacia de una intervención terapéutica y el procedimiento de elección cuando se trata de obtener la autorización sanitaria de un nuevo medicamento. La asignación aleatoria es el único procedimiento que asegura que los pacientes incluidos en el estudio provienen de la misma población y, por tanto, que al iniciar el estudio son comparables. Además, la asignación aleatoria favorece el enmascaramiento de las intervenciones y, desde un punto de vista ético, asegura que todos los pacientes tengan la misma probabilidad de que se les incluya en un determinado grupo experimental1.
La asignación al azar es, por lo tanto, una pieza clave del proceso de inferencia que permite aplicar a pacientes futuros los resultados obtenidos en un ensayo clínico, pero ello no implica que cualquier decisión terapéutica deba basarse en un ensayo clínico aleatorizado. Como concluyen Smith y Pell2, «aquellos que defiendan que sólo el ensayo clínico aleatorizado puede dar base suficiente para la adopción de una intervención terapéutica o preventiva deberían participar como voluntarios en un estudio aleatorizado y con intercambio del tratamiento sobre el efecto del paracaídas en la prevención del politraumatismo en un salto desde 1.000 metros de altura». El efecto del paracaídas es de tal magnitud que sobrepasa los posibles sesgos de una comparación con datos procedentes de otras fuentes.
Por otra parte, hay situaciones en que la asignación aleatoria resulta difícil de llevar a término. Los problemas del ensayo clínico en psicoanálisis son un claro ejemplo: a) la selección de pacientes es compleja en el estudio STOPPP3, de un total de unos 1.500 pacientes se seleccionó una muestra de 756, de los que se incluyó en el estudio a 202, que se asignaron a psicoanálisis o psicoterapia; b) el número de abandonos es elevado se ha calculado que en un análisis de 5 años de duración sólo continuarán en tratamiento la mitad de los que lo iniciaron4, y c) la selección del analista no es al azar, sino que elige libremente el propio paciente lo que puede ser un sesgo importante, dado que la experiencia profesional del analista se considera decisiva. No resulta extraño que el psicoanálisis haya recurrido de forma casi exclusiva a los estudios de casos clínicos y a algunos estudios de carácter empírico. Pero el problema es más amplio: en 1998 Martha N. Hill, presidenta de la American Heart Association, ya indicó que el hecho de que la enfermedad cardiovascular fuera la primera causa de muerte en Estados Unidos se debía, al menos en parte, a la brecha existente entre los ensayos clínicos, que habían demostrado la eficacia de diferentes intervenciones terapéuticas, y la práctica diaria de los profesionales de la salud, el propio comportamiento de los pacientes y la actitud del público en general5. De hecho, esta observación fue posterior a la constitución en 1995 de la International Society for Pharmacoeconomics and Outcomes Research, cuya finalidad es trasladar la investigación farmacoeconómica y de resultados en salud a la práctica, para asegurar que los recursos sanitarios se utilizan de forma eficiente, justa e inteligente.
Así pues, se acepta que los estudios no aleatorizados son necesarios cuando: a) resulta imposible o no es ético realizar un ensayo clínico controlado; b) el objetivo del estudio es analizar la efectividad en condiciones de práctica clínica real; c) interesa evaluar el coste-efectividad de una intervención terapéutica, o d) la cadena causal del efecto de la intervención es muy compleja6.
Los ensayos clínicos pragmáticos, en los que se pretende que las condiciones experimentales sean lo más similar posible a las de la práctica clínica habitual serían una alternativa pero, hasta el momento, no han alcanzado la generalización que parecen merecer7. En estos ensayos no aleatorizados, el problema se puede compensar en parte mediante métodos bayesianos que cuantifiquen hasta qué punto los resultados obtenidos son explicables por posibles sesgos de selección de pacientes8.
Un problema adicional en todo estudio es la posibilidad de que se cometa un fraude. Las normas de buena práctica clínica, implementadas en Europa en 1997, no parece que hayan resuelto definitivamente este problema9. Es muy importante disponer de salvaguardas que faciliten la realización de auditorías en caso de sospecha justificada de resultados poco creíbles.
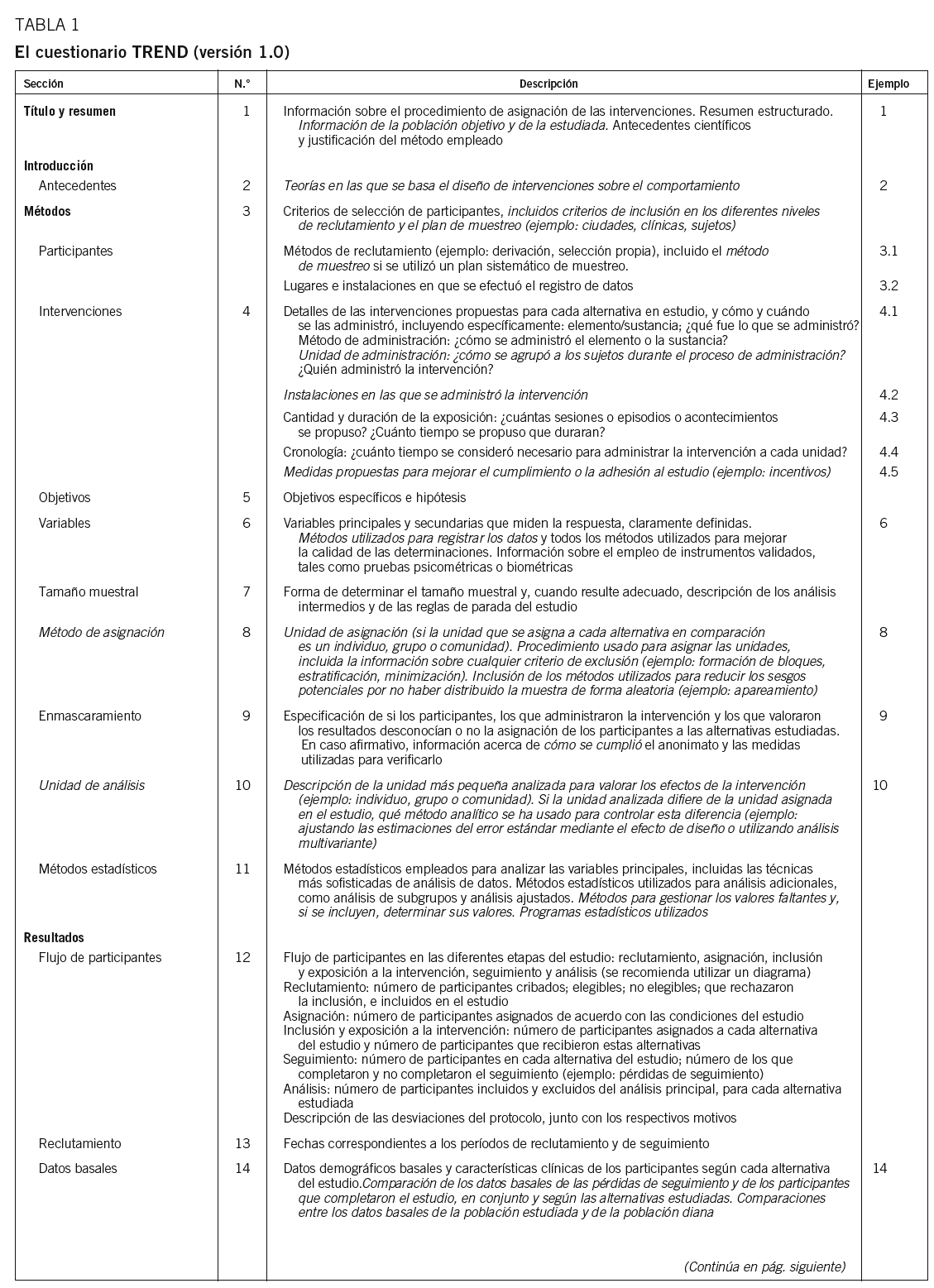
La lista de comprobación TREND
Es una realidad que las decisiones clínicas no siempre se adoptan de acuerdo con los datos obtenidos mediante un ensayo clínico. La experiencia del médico, la práctica clínica y, en último extremo, los estudios de carácter pragmático tienen una importancia a veces decisiva.
El objetivo de TREND es mejorar la calidad de los artículos científicos o de las guías terapéuticas que pueden servir como base para efectuar recomendaciones sobre intervenciones en ciencias de la salud y de la conducta.
Es imprescindible que todo estudio se realice de acuerdo con unas normas que aseguren la fiabilidad de los datos obtenidos y la calidad de las conclusiones que pueden derivar de ellos. Por este motivo, los Centers for Disease Control and Prevention y un grupo de editores de revistas científicas han desarrollado con el nombre de Transparent Reporting of Evaluations with Non-Randomized Designs (TREND) una guía que se publicó por primera vez en marzo de 2004 y que deberían cumplir autores, revisores y editores de estudios de intervención no aleatorizados10. La publicación de la guía TREND aporta transparencia a la evaluación de intervenciones sobre la salud mediante estudios distintos de los ensayos clínicos11. El adjetivo transparent no es casual: los autores consideran que la claridad en la exposición de los datos es un elemento clave en cualquier estudio relativo al cuidado de la salud.
A continuación se mencionan los puntos de la lista de comprobación TREND que son específicos y aquellos comunes con la lista CONSORT de los estudios aleatorizados.
Puntos específicos
Esta lista de comprobación se diferencia de la CONSORT fundamentalmente en que requiere información adicional sobre los apartados siguientes (entre paréntesis, la numeración de dichos apartados de la guía TREND):
a) La teoría que justifica la intervención estudiada (2) y una descripción detallada (4) de ésta.
b) Una definición exhaustiva de la población objetivo (1), del método empleado para reclutar la muestra (3), y del diseño experimental (8), especificando la unidad de asignación.
c) El método empleado para decidir qué intervención se asigna a dicha unidad (8) y los métodos utilizados para reducir o controlar posibles sesgos (11).
d) La unidad en la que se basa la recogida de datos (10) y, en especial, si ésta difiere de la unidad de asignación12, y cómo se ha tenido en cuenta en el análisis dicha diferencia.
e) Los métodos empleados para controlar la pérdida de información originada por los datos faltantes, y la descripción de los programas estadísticos (11).
f) Comparaciones de los datos iniciales observados con los datos de las pérdidas de seguimiento y de la población objetivo (14), así como entre los grupos en comparación (15) (aspecto de especial relevancia, ya que su proveniencia de una población única no queda garantizada por la asignación al azar).
g) Análisis de las variables intermedias en la cadena causal (17).
h) Una discusión, aún más detallada, de la interpretación (20) y extrapolación (21) de los resultados.
Puntos comunes con CONSORT
Como en la lista de comprobación CONSORT, en TREND hay que especificar:
a) La existencia de un protocolo pormenorizado que incluya tanto el análisis estadístico (11) de la variable principal (6) como el tamaño muestral (7) requerido.
b) La hipótesis que se desea contrastar (5) y su derivación de la teoría previa (2).
c) Los métodos para homogeneizar los grupos, sea restricción (3), estratificación (8) o enmascaramiento (9).
d) El rigor del seguimiento (12) y de la gestión de datos (6).
Es importante saber si la asignación se hizo directamente a cada unidad o a un grupo de ellas con una característica común12. Esta característica común puede ser el centro asistencial o el profesional sanitario (8), ya que, en este caso, el análisis deberá ser más sofisticado (11) para poder considerar las dos unidades que introducen variabilidad, es decir, el paciente y el centro o el profesional. Por supuesto, hay que especificar hasta qué punto las unidades han seguido el protocolo de la intervención (12 y 16). En resumen, los diseños no aleatorizados deben ser capaces de controlar, con el mismo rigor que los aleatorizados, las variables conocidas que pueden influir en la respuesta, sea en el momento de la asignación (8) o del análisis (11, 15, 18).
Por supuesto, el informe de todo estudio, sea o no aleatorizado, requiere aclarar sus condiciones de inferencia. La primera, ya comentada previamente, es si se trata de un estudio confirmatorio, con una hipótesis previa (5), o de un estudio exploratorio que ha analizado exhaustivamente (11 y 18) los datos en busca de un cierto patrón y que se limita a hacer sugerencias para proyectos confirmatorios futuros. La segunda son las condiciones temporales (13), geográficas (3) y otras (3, 14), que definen la población en estudio para que futuros profesionales puedan valorar el grado de extrapolabilidad, también conocida como validez externa.
Conclusión
Cuando existen razones que impidan la realización de un ensayo clínico controlado son necesarios los estudios de intervención no aleatorizados, pero para comunicar con transparencia los resultados obtenidos en ellos debe emplearse de forma sistemática la lista de comprobación TREND. Eso no implica que los estudios no aleatorizados no deban emplear los restantes niveles de calidad metodológica que se han hecho tradicionales en el ensayo aleatorizado, ni que la supresión de la aleatorización no introduzca un grado de incertidumbre difícil de cuantificar13.
La traducción que se encuentra en la tabla 1 de este artículo se ha efectuado siguiendo con la mayor fidelidad posible el texto en inglés. El ejemplo que figura en la tabla 2 se refiere a una intervención educativa sobre el sida realizada en Estados Unidos, pero no parece difícil adaptar las exigencias del cuestionario a cualquier otra intervención sanitaria de carácter no aleatorizado de nuestro entorno.



