

con esta revisión se pretende conocer la situación actual de la inteligencia artificial para su uso clínico en la reproducción asistida a partir del estudio de las limitaciones encontradas.
Metodologíase realiza una revisión exhaustiva a través de las bases de datos como PubMed, Elsevier y la biblioteca de sociedades científicas, en búsqueda de artículos originales, mediante el uso de una combinación de palabras clave como Artificial intelligence, FIV, ART.
Resultadosexisten algoritmos capaces de analizar los diferentes parámetros seminales entre los que destacan la concentración, la motilidad y la morfología del esperma humano, y es en este último parámetro donde se centra el papel fundamental de la inteligencia artificial. Además, se están desarrollando algoritmos con imágenes estáticas o secuencias de time-lapse tanto en los diferentes puntos concretos del desarrollo embrionario como en los periodos determinados.
Conclusionesgran parte de las publicaciones son de carácter retrospectivo, por lo que la mayoría de los algoritmos parecen encontrarse en fases iniciales. En lo referente al mundo comercial, también se necesitan estudios que corroboren su funcionamiento. Las limitaciones con las que se suele lidiar son, además de la naturaleza del estudio, conseguir un algoritmo explicable, introducir otros parámetros que afecten también en el resultado y el conjunto de los datos. Por ello, es necesario realizar ensayos controlados aleatorizados en diferentes clínicas en los que se expongan algoritmos explicables que mediante el análisis de diferentes parámetros consigan resultados fiables para la práctica clínica.
The aim of this review is to learn about the current situation of artificial intelligence for clinical use in assisted reproduction based on a study of the limitations that have been found.
Search MethodsAn exhaustive review is carried out through databases such as PubMed, Elsevier and the library of scientific societies, searching for original articles, using a combination of keywords such as Artificial intelligence, FIV, ART.
ResultsThere are algorithms capable of analysing different seminal parameters, among which the concentration, motility and morphology of human sperm stand out, and it is on this last parameter where the fundamental role of artificial intelligence is focused. Moreover, algorithms are being developed with static images or time-lapse sequences both at different specific points of embryo development and at specific periods.
ConclusionsMuch of the literature is retrospective, so most of the algorithms appear to be in the early stages. In the commercial world, there is also a need for corroborative studies. The limitations often encountered are, in addition to the nature of the study, getting an explainable algorithm, introducing other parameters that also affect the outcome and the data set. It is therefore necessary to conduct randomised controlled trials in different clinics in which explainable algorithms are presented that through the analysis of different parameters achieve reliable results for clinical practice.
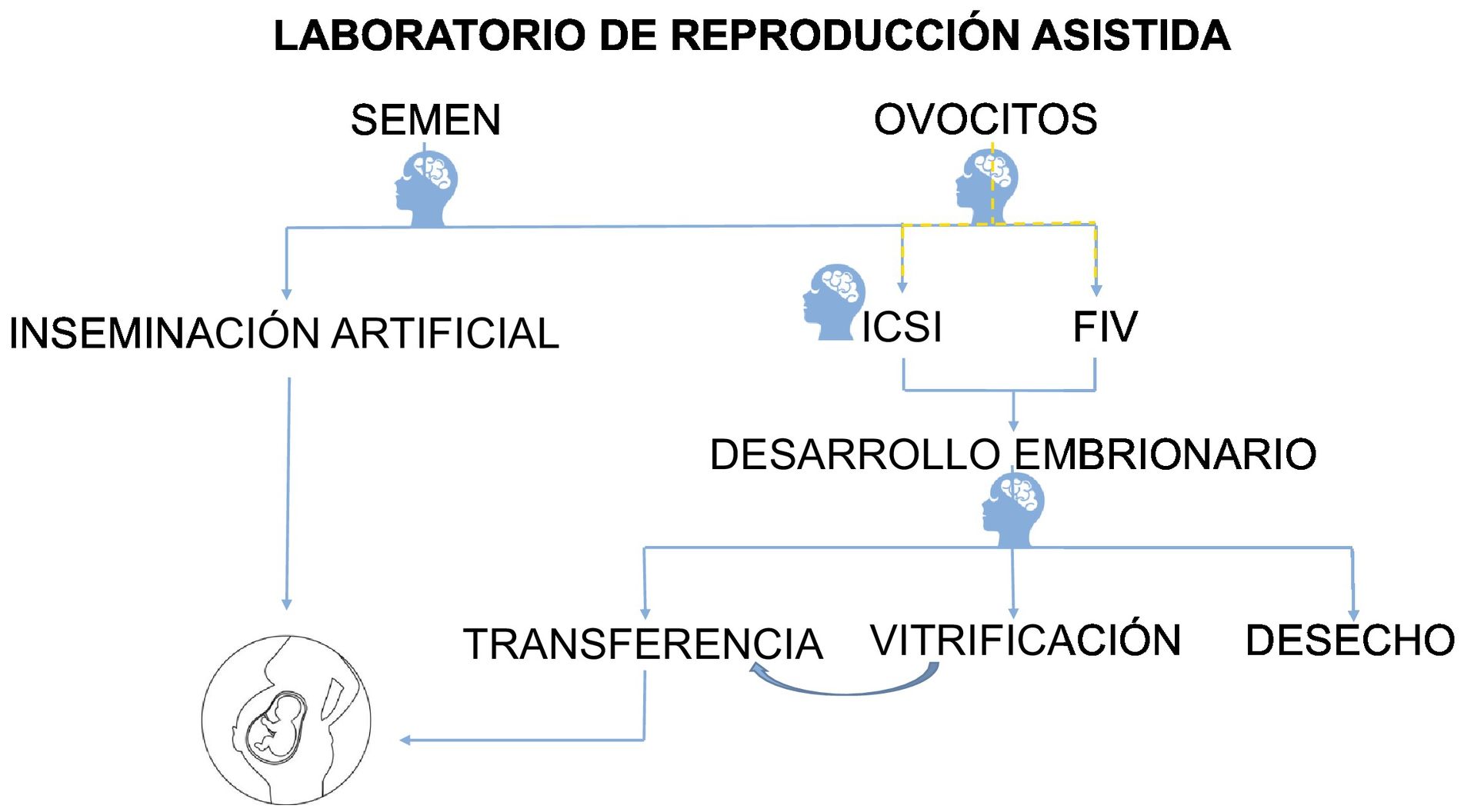
En un centro de reproducción asistida, el personal del laboratorio se enfrenta a múltiples situaciones en las que tiene que evaluar y tomar decisiones basándose en los análisis visuales (fig. 1). Respecto al factor masculino, es necesario realizar al menos un seminograma para examinar la calidad seminal, analizando multitud de parámetros macroscópicos y microscópicos entre los que destacan la concentración de espermatozoides, diferenciando por tipos de motilidad y el análisis de su morfología. Se ha visto una diferencia de resultados entre las distintas clínicas de reproducción asistida, sobre todo en el recuento de los espermatozoides móviles progresivos, así como en la morfología (Álvarez et al., 2005).

Esquema simplificado del proceso de laboratorio de reproducción asistida.
El embriólogo realiza un análisis de semen del paciente masculino y evalúa los ovocitos de la paciente. En el caso de la técnica ICSI, se selecciona el mejor espermatozoide para inyectar en el ovocito. Durante el desarrollo embrionario se selecciona el embrión que se va a transferir y los embriones que se van a conservar mediante vitrificación, se descartan los embriones de desecho.
Respecto al cultivo embrionario, también se realizan evaluaciones morfocinéticas, donde surgen ciertas discordancias entre los parámetros morfológicos como la multinucleación y la asimetría (Martínez-Granados et al., 2017; Sundvall et al., 2013). Las interpretaciones, por tanto, al depender del ojo humano, convierten el trabajo de un embriólogo en un proceso subjetivo y sesgado que depende de la experiencia profesional y la carga asistencial.
Es por ello que debemos conseguir que dicho proceso sea lo más objetivo posible, basándonos en la evidencia, y no hay evidencia sin análisis de datos. Teniendo en cuenta que nos encontramos en la era de la big data y tenemos a nuestra disposición una gran cantidad de datos, se nos da la posibilidad de utilizarlos e incorporarlos en el día a día para optimizar el trabajo. Una forma de ello se consigue mediante la automatización de los laboratorios, lo que cada día se hace más inminente.
Conocemos inteligencia como la facultad de la mente que permite aprender, entender, razonar y tomar decisiones a partir de una idea determinada de la realidad. Esta capacidad puede reproducirse a partir de programas informáticos que son ejecutados por máquinas, lo que se conoce como inteligencia artificial. Existen algoritmos basados en el aprendizaje automático o machine learning, capaces de aprender a partir de datos sin ser programados. En comparación con las estadísticas tradicionales o clásicas, el aprendizaje automático se enfoca en predecir los resultados para poder proporcionar decisiones sobre el resultado óptimo y así ayudar al personal del laboratorio, en lugar de simplemente estimar y calificar las condiciones (Wang et al., 2019).
La selección de un modelo de aprendizaje automático está determinada por la tarea a realizar (clasificación, regresión, agrupamiento, reducción de dimensionalidad y aprendizaje de características y asociación), las características del conjunto de datos (estructurados, no estructurados, semiestructurados o metadatos) y el enfoque de aprendizaje planteado (supervisado, no supervisado, semisupervisado, de refuerzo) (Dimitriadis et al., 2022; Sarker, 2021). De acuerdo con estas variables se puede elegir entre varias perspectivas para construir algoritmos con diferentes modelos de aprendizaje. La selección de dichos modelos es una tarea tediosa, ya que diferentes algoritmos, utilizando conjuntos de datos iguales, obtienen rendimientos distintos. Esto sustenta la idea de probar varias arquitecturas a la vez para asegurar un enfoque matemático y computacional adecuado (Burkov, 2019; Dimitriadis et al., 2022; Sarker, 2021).
Frente a una cantidad creciente de datos, destaca por su mayor rendimiento el aprendizaje profundo o deep learning. Este forma parte de una familia más amplia de enfoques de aprendizaje automático basados en redes neuronales artificiales o artificial neural networks (ANN). Uno de los algoritmos de aprendizaje profundo más utilizados es la red neuronal convolucional o convolutional neural network (CNN), por sus usos en varias áreas como reconocimiento de imágenes y videos, procesamiento y clasificación de imágenes, procesamiento de lenguaje natural, etcétera. (Dimitriadis et al., 2022; Sarker, 2021; Wang et al., 2019). Por tanto, teniendo en cuenta la cantidad de análisis visuales de un laboratorio de reproducción asistida, conseguir una inteligencia artificial precisa se logra a partir de 2 pilares fundamentales: el aprendizaje profundo y la visión por ordenador. El aprendizaje profundo es capaz de manejar patrones desconocidos o características complejas no visibles para el ojo humano a la vez que identifica correlaciones. La visión por ordenador se encarga de dirigir al aprendizaje profundo a dichas regiones de interés específicas (VerMileyea et al., 2021).
Para conseguir generalizar el rendimiento del algoritmo para cualquier dato desconocido es necesario partir de una fase de entrenamiento que se divide en un conjunto de datos de entrenamiento más pequeños y otro conjunto de validación, el cual trata de imitar el de la prueba, ayudando a ajustar el algoritmo. Al completar esta fase de entrenamiento, debe confirmarse que el modelo es generalizable y no demasiado específico a través de un conjunto de datos de prueba por separado. Para entrenar un modelo con estas características, es necesario disponer de una gran cantidad de información de calidad, lo que implica que sea diversa, representativa y equilibrada (Choi et al., 2020; VerMileyea et al., 2021). Esto es debido a que según el principio GIGO (garbage in, garbage out), si le introducimos basura, el sistema nos devolverá basura (Abellán-García Sánchez et al., 2021). Existen estrategias efectivas para optimizar el tamaño del conjunto de datos, como realizar un aumento o una validación cruzada. El aumento de datos consiste en manipular las imágenes en el conjunto de entrenamiento (por ejemplo, rotaciones, recortes, cambios de tamaño...), lo que permite que los ejemplos se multipliquen sin un aumento real en el tamaño (Dimitriadis et al., 2022; Riegler et al., 2021). Por otro lado, lo métodos de validación cruzada consisten en dividir el conjunto de datos en varios subgrupos de forma aleatoria e ir asignándolos y reasignándolos a los de entrenamiento, validación y prueba (Marín and Chang, 2021; Zhao et al., 2021).
Tanto los médicos como los embriólogos deben aprender cómo usar e interpretar mejor los algoritmos de inteligencia artificial, incluso en qué situaciones se deben aplicar y cuánta confianza se debe depositar en estos (Medical Association, 2019). Se complica con el uso del aprendizaje profundo, ya que además de ser complejo, funciona como una caja negra en la que se conoce la entrada y la salida, pero no está claro qué características se identificaron para dar la salida correspondiente, lo que es muy contraintuitivo. Existen propuestas para aumentar la comprensión de estos algoritmos y poder llegar a una inteligencia artificial explicable (Barredo Arrieta et al., 2020). Además, para garantizar la seguridad y la eficacia y así facilitar su adopción, grupos de reguladores han propuesto marcos que brindan una base regulatoria sólida; sin embargo, debido a su reciente aparición, aún quedan aspectos que definir. Como recomendación para mejorar el marco actual se ha descrito el proceso de desarrollo del algoritmo de inteligencia artificial en 4 fases: I) viabilidad, II) capacidad, III) eficacia y IV) durabilidad. El objetivo de la fase I es demostrar si este puede competir con el estado actual de la técnica en condiciones ideales (por ejemplo, contra sistemas recientes, el análisis de un embriólogo u otros estudios relacionados). A continuación, la fase II consiste en demostrar que el algoritmo funciona de manera constante en un entorno que simula las condiciones del mundo real. La evaluación de la eficacia, ya en la fase III, se realiza a través del rendimiento general en el mundo real mediante la evaluación prospectiva en varios entornos clínicos y la validación local. Por último, en la fase IV los fabricantes tienen la obligación de realizar un seguimiento del producto a lo largo de su incorporación en el laboratorio (Larson et al., 2021).
ObjetivoEl objetivo de este trabajo es dar a conocer los últimos avances del desarrollo de los algoritmos de inteligencia artificial en el campo de la reproducción asistida, más concretamente en el ambiente del laboratorio, en las actividades que realiza un profesional cualificado. Valoramos si existe concordancia entre estos y aquellos que se encuentran en el mundo comercial. Por último, exponemos las limitaciones que dificultan el uso actual en la clínica y discutimos las perspectivas futuras.
Material y métodosDiseñoSe ha realizado una revisión exhaustiva de los documentos de las sociedades científicas dedicadas a la aplicación de la inteligencia artificial en el laboratorio de reproducción asistida, así como de las revisiones y los estudios científicos sobre el tema a tratar.
Estrategia de búsquedaEn primer lugar, se llevó a cabo una búsqueda en PubMed y Elsevier, también en la biblioteca de las sociedades científicas, sobre la automatización del laboratorio de reproducción asistida y la inteligencia artificial en las técnicas de reproducción asistida (ART), utilizando palabras clave como «Artificial intelligence», «FIV», «ART».
Se analizaron además las referencias bibliográficas de los artículos seleccionados con el fin de rescatar otros estudios potencialmente incluyentes para la revisión. Dichos artículos fueron localizados a través de PubMed y de Google Scholar.
Criterios de inclusión y exclusiónRespecto a los estudios científicos, se aplicó como criterio de inclusión que los estudios incorporaran conclusiones positivas sobre el potencial clínico del algoritmo. El principal criterio de exclusión fue el año de publicación y la presencia de estudios posteriores.
Extracción de datosTras la búsqueda inicial se localizaron 31 estudios, aunque se excluyeron 11 que no fueron relevantes para el objetivo de esta revisión.
Para proceder a la selección, se revisaron los abstracts y en caso necesario los artículos completos con el fin de decidir si la información que contenían estaba o no relacionada con nuestro objetivo.
Análisis de los datosLa información analizada se estructuró en subapartados en función del proceso de reproducción asistida del cual forme parte: análisis de semen, técnica de ICSI, análisis de ovocitos y desarrollo embrionario.
Del conjunto de estudios analizados se extrajo, para cada grupo, información sobre el objetivo del estudio, el método de inteligencia artificial desarrollado, el conjunto de datos utilizado, si los resultados son comparados con otros algoritmos o técnicas o con el análisis manual, así como del resultado (tablas 1-4).
Resumen de los estudios que utilizan algoritmos de inteligencia artificial en el análisis del semen
| Objetivo | Algoritmo | Conjunto de datos | En comparación | Resultado | |
|---|---|---|---|---|---|
| (Valiuškaitė et al., 2021) | Evaluación de la motilidad de la cabeza de los espermatozoides | R-CNN | RetrospectivoVISEM: 85 pacientes, 1 video (muestra) por paciente | Métodos de laboratorio | Precisión del 91,77% en la detección de cabezas y buena correlación en la predicción de la motilidad |
| (Marín and Chang, 2021) | Segmentación de la cabeza del espermatozoide, el acrosoma y el núcleo | 2 CNN:U-Net y Mask RCNN | RetrospectivoSCIAN-SpermSegGS: 210 espermatozoidesData Science Bowl de 2018: más de 37,.000 núcleos de células | Segmentación manual | U-net con aprendizaje por transferencia fue el mejor modelo, logrando hasta un 95% de superposición |
| (Yüzkat et al., 2021) | Clasificación morfológica de la cabeza del espermatozoide | 6 modelos CNN con la técnica de fusión | RetrospectivoSMIDS: 3.000 imágenesHuSHeM 216 imágenesSCIAN-Morpho 1.132 imágenes | Etiquetas manuales | Rendimientos máximos de clasificación para los de datos de SMIDS, HuSHeM y SCIAN-Morpho del 90,73, 85,18 y 71,91%, respectivamente |
| (Kanakasabapathy et al., 2019) | Análisis de morfología mediante teléfonos inteligentes | CNN | ProspectivoMonocéntrico35 pacientes | Método de laboratorio convencional | Identificar la calidad morfológica normal y anormal con una precisión del 88,5% |
| (Agarwal et al., 2019) | Análisis de la concentración, la motilidad, la morfología y el pH seminal | Sin información(LensHooke X1 PRO) | ProspectivoMulticéntrico135 muestras | Manual en el laboratorio de los hospitales | Concentración, motilidad y pH comparables al manual, pero morfología con limitaciones |
| (Monteiro et al., 2021) | Medir la concentración y la motilidad | CNN(Mojo Aisa) | ProspectivoMonocéntrico60 muestras | Manual laboratorio del hospital | Requiere un mayor desarrollo para rangos de concentración por debajo de 5 M/ml |
Resumen de los estudios que utilizan algoritmos de inteligencia artificial en la técnica de ICSI
| Objetivo | Algoritmo | Conjunto de datos | En comparación | Resultado | |
|---|---|---|---|---|---|
| (Abbasi et al., 2021) | Reconocer las anomalías morfológicas de las cabezas de los espermatozoides (acrosoma, cabeza y vacuola) | 2 CNN:DTL y DMTL | RetrospectivoMHSMA: 1.540 imágenes de cada grupo | Con estudios existentes en el conjunto de los datos MHSMA y la evaluación visual con Grad-cam | La mayor mejora en la precisión de las etiquetas de cabeza y vacuola se logró con DTL (84 y 94%, respectivamente), mientras que el modelo DMTL alcanzó la mayor precisión en la etiqueta del acrosoma (80,66%). |
| (Mendizabal-Ruiz et al., 2022) | Identificar, rastrear y cuantificar los patrones de motilidad de los espermas individuales en tiempo real para hacer un ranking y seleccionar el mejor espermatozoide para ICSI | Sin información(SiD) | RetrospectivoMonocéntrico383 espermatozoides | – | Pudo identificar patrones de movimiento beneficiosos de espermatozoides individuales que pueden tener un impacto significativo tanto en la fertilización normal como en la formación de blastocistos durante la ICSI |
Resumen de los estudios que utilizan algoritmos de inteligencia artificial en el análisis de ovocitos
| Objetivo | Algoritmo | Conjunto de datos | En comparación | Resultado | |
|---|---|---|---|---|---|
| (Targosz et al., 2021) | Segmentación semántica de los ovocitos | 71 modelos neuronales profundos CNN | RetrospectivoMonocéntrico334 fotografías de los ovocitos | Manual y entre ellos | El mejor modelo alcanzó alrededor del 85% de precisión en el entrenamiento y 79% en la validación |
Resumen de los estudios que utilizan algoritmos de inteligencia artificial durante el desarrollo embrionario
| Objetivo | Algoritmo | Conjunto de datos | En comparación | Resultado | |
|---|---|---|---|---|---|
| (Fukunaga et al., 2020) | Determinar el número de pronúcleos | Aprendizaje profundo CNTK | RetrospectivoMonocéntrico1200 embriones | Juicio embriólogo | Sensibilidad de 0PN del 99%, 1PN del 82% y 2PN del 99%, se evaluó bien la superposición de 2PN |
| (Zhao et al., 2021) | Segmentación del citoplasma, los pronúcleos y la zona pelúcida | CNN | No está claro si se recopilaron de forma prospectivaMonocéntrico1.218 imágenes | Manual y con otros estudios | Las precisiones de la segmentación fueron en el citoplasma más del 97%, pronúcleos más del 84% y la zona pelúcida sobre el 80% |
| (Liao et al., 2021) | Predecir la formación de blastocistos y blastocistos utilizables | CNNRNN(STEM y STEM+) | RetrospectivoMonocéntrico10.432 videos para análisis y 577 para conteo de células | Manual y otros algoritmos de selección de embriones basados en time-lapse | Mayor eficacia predictiva |
| (Erlich et al., 2022) | Asignación de etiquetas de pseudo-clasificación | CNN(KID+) | RetrospectivoMulticéntrico50.145 imágenes | Manual, otro estudio y KIDScore D3 | Resultados mejores en la clasificación de múltiples grupos de embriones |
| (Bormann et al., 2021) | Monitorización de indicadores claves de rendimiento de un proceso de fecundación in vitro (KPI) | CNN | RetrospectivoMonocéntrico2.449 embriones (Entrenar, evaluar y probar la red)876 embriones (puntuación KPI) | Otras técnicas de KPI | Las predicciones generadas tenían una alta asociación con las tasas de embarazo y una baja variación con el desempeño individual del embriólogo |
| (Thirumalaraju et al., 2021) | Clasificación de embriones en día 5 en función de su calidad morfológica | Varias arquitecturas CNN | Retrospectivo2 conjuntos de datos: MonocéntricoSRBT | Manual | El modelo Xception se desempeñó mejor en la diferenciación entre los embriones en función de su calidad morfológica |
| (Loewke et al., 2022) | Predicción de embarazo clínico (latido fetal) a partir de la imagen, el día de captura de esta y la edad del paciente | Conjunto de 3 modelos CNN | RetrospectivoMulticéntricoImágenes de 8.537 blastocistos | Manual | Mejores resultados en clasificar embriones organizados en un grupo grande y diverso de pacientes |
| (ver Milyea et al., 2020) | Análisis de embriones (blastocistos) del día 5 para la predicción de los resultados clínicos del embarazo | Varias arquitecturas CNN(Life Whisperer) | Retrospectivo1er estudio piloto monocéntrico de 5.282 imágenes2° estudio multicéntrico de 3.604 imágenes | Manual | Mejora de precisión promedio del 24,7% |
| (Berntsen et al., 2022) | Predicción de la implantación a partir de los parámetros morfocinéticos | CNN(iDAScore) | RetrospectivoMulticéntrico115.832 secuencias de time-lapse de embriones | KIDScore D5 | El modelo de selección tiene un AUC de 0,67 para los embriones transferidos |
| (Chavez-Badiola et al., 2020) | Predecir la ploidía y la implantación en un conjunto de datos conocido de imágenes estáticas de blastocistos | CNN(ERICA) | RetrospectivoBase de datos de1.231 imágenes de blastocistos | Conjunto de pruebas, etiquetas asignadas aleatoriamente, embriólogos capacitados | Extrajo con éxito 94 características que se introdujeron en el software de formación, logrando un 70% de precisión |
| (Bori et al., 2021) | Predecir la probabilidad de lograr un nacimiento vivo utilizando el perfil proteómico de los medios de cultivo y la morfología del blastocisto | Tres arquitecturasANN | RetrospectivoMonocéntrico186 imágenes de embriones | – | Precisión excelente para detectar embriones euploides capaces de dar como resultado un nacimiento vivo, especialmente en términos de IL-6 y MMP-1 |
La automatización del análisis de semen comenzó a partir de los años 80, con el desarrollo de los sistemas CASA (Computer Assisted Semen Analysis) (de Monserrat Vallvè, n.d.). Estos surgieron con la finalidad de estudiar el movimiento de los espermatozoides e interpretar esta información con ayuda de algoritmos. Su evolución junto al desarrollo tecnológico ha generado el aumento de sistemas CASA actuales producidos por varias compañías como Microptic (SCA), Hamilton Thorne (IVOSII y CEROSII) o MES (SQA-Vision, SQA-V Gold), algunos obteniendo información más detallada de otros parámetros seminales además de la motilidad (Agarwal et al., 2022).
El desafío principal en el que se centran la mayoría de los estudios es poder realizar evaluaciones morfológicas gracias a los algoritmos de inteligencia artificial. Por un lado, se plantea explorar la cinemática de los espermatozoides basándose en su cabeza usando una CNN basado en regiones. Con ello, se pretende determinar si una muestra es apta para el proceso de inseminación artificial. Con la base de datos de video de VISEM el algoritmo logró una precisión del 91,77% en la detección de las cabezas y los resultados de la predicción de la motilidad de los espermatozoides mostraron una muy buena correlación con la establecida usando los métodos de análisis de laboratorio (Valiuškaitė et al., 2021). Destacar que no se aporta información sobre cuántos embriólogos participan en la anotación de la imagen o en el análisis para asegurarnos de que no ha podido introducirse sesgo; además, el siguiente paso deberá incluir la validación del método. Por otro lado, se han desarrollado y sugerido algoritmos de aprendizaje profundo para poder llegar a predecir la morfología haciendo uso del aprendizaje por transferencia, donde se ha visto que su impacto es sustancial (Marín and Chang, 2021). El transfer learning o aprendizaje por transferencia es un enfoque en el que el algoritmo aprende una tarea y se basa en ese conocimiento mientras aprende otra diferente, pero relacionada (Dimitriadis et al., 2022). Aplicado a este estudio vemos cómo se compararon 2 arquitecturas de aprendizaje profundo (U-Net y Mask-RCNN), entrenándose solamente con la base de datos SCIAN-SpermSegGS (imágenes de espermatozoides) o entrenándose previamente con Data Science Bowl de 2018 (imágenes de núcleos segmentados). U-net con aprendizaje por transferencia fue la mejor configuración para segmentar la cabeza, el acrosoma y el núcleo del espermatozoide, logrando hasta un 95% de superposición en comparación con la segmentación manual (Marín and Chang, 2021). Podemos apreciar cómo el uso del aprendizaje por transferencia está en auge, incluso planteándose para futuros estudios, como en el estudio que implementa la técnica de fusión sobre 6 modelos de CNN. En dicho estudio, se obtuvieron rendimientos máximos de clasificación morfológica de la cabeza del espermatozoide para los conjuntos de datos SMIDS, HuSHeM y SCIAN-Morpho del 90,73, 85,18 y 71,91%, respectivamente (Yüzkat et al., 2021).
Para aquellos laboratorios más humildes o para aquellos pacientes que por diversos motivos como pudor o falta de tiempo necesitan realizar un seminograma en el hogar, se ha planteado el desarrollo de sistemas de análisis de semen más accesibles a partir de teléfonos inteligentes. Mediante microscopia evalúan la motilidad y concentración de los espermatozoides sin dificultad, y aprendizaje profundo se logró implementar el análisis de morfología. Adaptando una red neuronal convolucional profunda, se pudo identificar correctamente las muestras en función de la calidad morfológica normal y anormal con una precisión del 88,5%. Sin embargo, el siguiente paso del desarrollo de este dispositivo es el manejo de muestras de microfluidos que puedan mejorar la preparación de muestras para uso doméstico (Kanakasabapathy et al., 2019).
En el mercado podemos encontrar los primeros sistemas de tecnología automatizada con fines diagnósticos. El dispositivo LensHooke X1 PRO se basa en la microscopia óptica de inteligencia artificial (AIOM) y el uso del aprendizaje automático para la medición de parámetros como el pH seminal, la concentración, la motilidad y la morfología de los espermatozoides evaluándolos en función de los criterios de la 5ª edición de la OMS. Los resultados obtenidos por el algoritmo de LensHooke, del cual no se dan detalles, se correlacionan según un estudio prospectivo multicéntrico con los obtenidos manualmente, a excepción del estudio de la morfología que presentó limitaciones (Agarwal et al., 2019; VerMileyea et al., 2021). Además de los parámetros anteriormente mencionados de pH, concentración, motilidad y morfología, el sistema SCA SCOPE parece analizar otros como el test de penetración del moco cervical, vitalidad, fragmentación y presencia de leucocitos gracias a su algoritmo de aprendizaje automático. Desafortunadamente, no hay presencia de artículos en las bases de datos consultadas que puedan respaldar su funcionamiento. Por otro lado, encontramos el primer microscopio de análisis de semen impulsado por inteligencia artificial, Mojo aisa. Sin embargo, el algoritmo utilizado de CNN necesita un mayor desarrollo, ya que parece presentar un límite de detección a concentraciones bajas y necesita cierto tiempo para proporcionar los resultados, lo que no favorece el uso en clínicas con volúmenes grandes de trabajo (Monteiro et al., 2021). Cabe señalar que en el próximo congreso de American Society for Reproductive Medicine (ASRM) en 2022, se presentará un resumen en el que se indica continuar con el desarrollo de Mojo Aisa para mejorar la precisión a concentraciones muy bajas y se postula que aprenda a evaluar la morfología (Parrella et al., 2021).
Inteligencia artificial en la técnica ICSILa técnica más utilizada de reproducción asistida es la inyección intracitoplasmática de los espermatozoides, conocida como ICSI (Haddad et al., 2021). Con el desarrollo del sistema ICSI robótico en 2011, donde la participación del embriólogo se reduce, surge el hecho de que la medición automatizada demuestra ser más eficaz que la manual a la hora de seleccionar el mejor espermatozoide para inyectar en el ovocito (Dai et al., 2021; Lu et al., 2011). Teniendo en cuenta que los parámetros de motilidad y morfología de un espermatozoide reflejan la integridad de su ADN, cabe esperar algoritmos de inteligencia artificial diseñados para la selección del mejor espermatozoide para inyectar (Zhang et al., 2021).
En esta técnica es necesario seleccionar los mejores espermatozoides en muestras sin fijar ni teñir. Por ello, además de los estudios mencionados previamente que también pueden ser de utilidad, hay estudios más enfocados a desarrollar algoritmos capaces de seleccionar en tiempo real con aumento entre 400x y 600x, el mejor espermatozoide en fresco con base en el acrosoma, la forma de la cabeza y si hay presencia de vacuolas (Abbasi et al., 2021; Javadi and Mirroshandel, 2019). La base de datos utilizada para ambos casos fue MHSMA, creada en el estudio de entrenamiento de una CNN personalizada para reconocer las anomalías morfológicas de las cabezas de los espermatozoides (Javadi and Mirroshandel, 2019). Para mejorar la precisión de esta se realizó el estudio de 2 algoritmos, uno basado en el aprendizaje por transferencia (DTL) y un segundo basado en el aprendizaje por transferencia multitarea (DMTL). Ambos modelos mostraron una mejora en la precisión, más concretamente de las etiquetas de cabeza y vacuola con DTL (84 y 94%, respectivamente), mientras que el modelo DMTL alcanzó la mayor precisión en la etiqueta del acrosoma (80,66%) (Abbasi et al., 2021). Cabe destacar que en dichos estudios se emplearon Grad-CAM para generar explicaciones visuales, lo que ayuda a comprender mejor el modelo.
A día de hoy, podemos encontrar el sistema Baibys, una plataforma de ICSI robótica automatizada, que expone clasificar los espermatozoides en función de su morfología y motilidad a gran aumento (IMSI). Baibys anuncia aislar y extraer de forma autónoma espermatozoides individuales óptimos para la microinyección en un tiempo reducido. Lamentablemente, no parece haber artículos en las bases de datos consultadas que confirmen su funcionamiento ni validen su uso. Además, ensayos controlados aleatorizados actuales no apoyan ni refutan el uso clínico de dicha técnica, la cual parece ser una herramienta eficaz para reducir la incidencia de defectos estructurales en comparación con ICSI. Se requieren análisis retrospectivos multicéntricos para investigar la relación entre las características morfológicas del espermatozoide individual y el potencial de desarrollo de un recién nacido sano (Dieamant et al., 2021; Itoi et al., 2022; Teixeira et al., 2020). Pendiente de patente y de un estudio multicéntrico encontramos SiD, un asistente de selección de espermatozoides en tiempo real capaz de identificar, rastrear y cuantificar los patrones de motilidad de espermas individuales (como motilidad progresiva, velocidad en línea recta y trayectoria curvilínea) en tiempo real (Mendizabal-Ruiz et al., 2022).
Inteligencia artificial en análisis de ovocitosDespués de una punción folicular nos encontramos con ovocitos en varias etapas de madurez meiótica. Los métodos de la inteligencia artificial pueden ser una herramienta útil para evaluar la calidad de estos y su potencial de fertilización.
Como parte de una investigación más amplia, se han probado 71 modelos de redes neuronales profundas para la segmentación semántica de ovocitos. Se analizaron 13 áreas de interés entre las que cabe señalar el cuerpo polar, el citoplasma, la zona pelúcida, el espacio perivitelino y las vacuolas. Los resultados obtenidos muestran que dichos modelos, obteniendo la mejor arquitectura, una precisión de entrenamiento alrededor del 85 y 79% para los de validación, pueden usarse como redes predefinidas en otras tareas como, por ejemplo, la detección del cuerpo polar para un sistema ICSI automatizado o clasificar según características morfológicas (Targosz et al., 2021).
Future fertility ha desarrollado Violet-Oocyte Prediction, un software capaz de detectar características del ovocito que pueden indicar la probabilidad de fertilización y el desarrollo del embrión (blastocisto). Por ahora, solamente se ha encontrado un resumen presentado en el congreso de ESHRE (European Society of Human Reproduction and Embryology) 2020 en el que se demostró que Violet superaba a 17 embriólogos de 8 clínicas tanto en la predicción de la fertilización (aumento de la precisión un 21,8%) como en el desarrollo del blastocisto (aumento de la precisión del 20,2%) (Nayot et al., 2022). Sin embargo, cabe destacar que actualmente se encuentran realizando un estudio prospectivo multicéntrico para validar la tecnología.
Inteligencia artificial durante el desarrollo embrionarioLa fertilización sigue un curso de eventos que el embriólogo debe entender y evaluar adecuadamente para poder tomar decisiones sobre qué embrión transferir y cuáles vitrificar para su posterior uso, desechando los restantes.
Entre las primeras 16 a 18 horas, se realiza el control de la fertilización, en el que se observa el número, la apariencia y la localización de los cuerpos polares, el número y la apariencia de los pronúcleos y los cuerpos precursores nucleolares, así como el halo citoplasmático (ASEBIR, 2015). Podemos encontrar algoritmos de inteligencia artificial capaces de clasificar cigotos en función del número de pronúcleos, como el algoritmo de aprendizaje profundo CNTK, capaz de detectar la ausencia, si hay solo uno o la presencia de los 2 con una sensibilidad del 99, 82 y 99%, respectivamente, pudiendo evaluarse también la superposición adecuadamente (Fukunaga et al., 2020). Además de los pronúcleos, también se pueden examinar otros patrones morfocinéticos como el citoplasma del cigoto y la zona pelúcida gracias a un algoritmo de CNN de segmentación, del cual ha sido validada su precisión, la reproducibilidad y la velocidad por un estudio en el que se obtuvo una precisión de la segmentación del citoplasma superando el 97%, pronúcleos más del 84% y la zona pelúcida alrededor del 80% (Zhao et al., 2021).
Durante la etapa de escisión, se deben hacer controles a las 43 y 45; luego a las 67 y 69 horas después de la inseminación, en el día 2 y el día 3, respectivamente. Aquí se evalúan los parámetros morfocinéticos como el número de células y el ritmo de división, fragmentación, tamaño y forma de los blastómeros (estadio específico o no), multinucleación, anomalías citoplásmicas, la zona pelúcida y el grado de compactación (ASEBIR, 2015).
Usando la monitorización de time-lapse, un estudio ha desarrollado un enfoque de aprendizaje profundo que puede predecir de forma automática y precisa la formación de blastocistos, STEM, y si estos son utilizables, STEM+, basándose en videos de los primeros 3 días (Liao et al., 2021). Destacar que este estudio aleatorizado se comparó con la evaluación de 4 embriólogos por separado, número razonable para reducir la subjetividad, y con otros algoritmos de selección de embriones como el software aprobado por la FDA Eeva (disponible en la incubadora time-lapse de sobremesa Geri+), que según un estudio prospectivo multicéntrico ayuda a predecir el desarrollo embrionario e identificar aquellos embriones en el día 3 con mayor probabilidad de convertirse en blastocistos (Conaghan et al., 2013). Esta predicción se realiza en función del tiempo entre la citocinesis 1 y 2 (P2) y entre la citocinesis 2 y 3 (P3), por lo que es un estudio de un parámetro cinético. Su uso exclusivo o de apoyo al estudio morfológico parece ser dudoso, lo que no implica que se pueda usar junto con otros marcadores de time-lapse (Jacoby et al., 2016).
Proporcionando estimaciones continuas de la viabilidad del embrión desde el día 2 encontramos el clasificador KID+, propuesto por Fairtility, el cual demostró superar tanto la evaluación de 8 embriólogos y métodos informados anteriormente, como la proporcionada por KIDScore-D3 (Erlich et al., 2022). KIDScore-D3 (disponible en las incubadoras Embryoscope) se trata de un algoritmo semiautomático de apoyo a la decisión aprobado por la FDA que predice el potencial de implantación evaluando parámetros morfocinéticos hasta el día 3 (Petersen et al., 2016).
Por otro lado, se ha desarrollado un sistema de inteligencia artificial de monitorización de indicadores claves de rendimiento de un proceso de fecundación in vitro (KPI) para evaluar el desempeño individual del embriólogo y las condiciones de cultivo. Gracias a esto, se ha propuesto el primer KPI de etapa de escisión demostrado para detectar las alteraciones en un entorno que deriva en cambios en los resultados del embarazo (Bormann et al., 2021).
Se considera que un embrión cultivado in vitro con buen pronóstico de implantación alcanza el estadio de blastocisto en el día 5. Además, existen varias ventajas que apoyan la transferencia en este día, como la sincronía entre el estadio embrionario y el ambiente uterino. En el blastocisto es preciso diferenciar el blastocele, la zona pelúcida, la masa celular interna y el trofectodermo, así como su grado de expansión (ASEBIR, 2015).
Podemos encontrar estudios capaces de clasificar embriones en el día 5 en función de su calidad morfológica. En un estudio se compararon varias arquitecturas diferentes para clasificar las imágenes de embriones en estadio de blastocisto capturadas en el dispositivo Embryoscope y otras obtenidas mediante otras plataformas por la Sociedad de Biólogos y Tecnólogos Reproductivos (SRBT). El modelo Xception, sometido a aprendizaje por transferencia, se desempeñó mejor en la diferenciación entre los embriones en función de su calidad morfológica; sin embargo, se requieren evaluaciones adicionales sobre la consistencia de la red para ser concluyentes (Thirumalaraju et al., 2021). Las redes propuestas en el estudio deben modificarse para ser clínicamente viables y adaptarse a aplicaciones como seleccionar el mejor embrión para transferir o, yendo más lejos, poder predecir un recién nacido vivo.
Clasificando los embriones en el estadio de blastocisto a partir de las imágenes, el día de captura de estas y la edad del paciente se puede predecir el embarazo clínico (presencia de latido fetal). Sin embargo, los mejores resultados se obtienen al clasificar embriones de un grupo grande y diverso de pacientes, por lo que se necesitan trabajos futuros para garantizar un rendimiento mejorado individualizado. Además, se han destacado posibles limitaciones relacionadas con la calidad de la imagen, el sesgo (la firma óptica de cada centro y que aparezcan objetos en la imagen como la micropipeta en casos que se realizan biopsia) y la variación de las puntuaciones (Loewke et al., 2022). Destacar en este estudio el uso de técnicas de atribución para la interpretación, como gradientes integrados y mapas de oclusión.
Disponible en la web encontramos Life Whisperer, una aplicación de software basada en la nube que, haciendo uso del aprendizaje profundo y la visión por ordenador, puede identificar características morfológicas en embriones de día 5 para predecir la viabilidad del embrión a partir de las imágenes (ver Milyea et al., 2020). Este algoritmo ha sido sometido a un estudio piloto monocéntrico que ha confirmado su viabilidad y a un siguiente estudio multicéntrico para asegurar su generalización; sin embargo, los datos en ambos estudios fueron recopilados de forma retrospectiva.
Actualmente, se está probando en un ensayo controlado randomizado multicéntrico del sistema de inteligencia artificial iDAScore, que sería el único que haciendo uso del aprendizaje profundo completamente automatizado tiene en cuenta todo el desarrollo del embrión para poder clasificarlos según la probabilidad de implantación (número de registro ACTRN12620000197932 en el Registro de Ensayos Clínicos de Australia y Nueva Zelanda, ANZCTR). Evalúa parámetros morfocinéticos de desarrollo embrionario bien establecidos (número de pronúcleos, división en 2, 3 y 5 blastómeros, tiempo hasta el blastocisto completo y clasificación de la masa celular interna y trofectodermo) de forma más eficaz que KIDScore-D5 y que la morfología general (Berntsen et al., 2022). KIDScore-D5 se trata de un sistema semiautomático, el cual a partir de parámetros morfocinéticos puede predecir el potencial de la implantación hasta el día 5 y servir de apoyo a la decisión (Gazzo et al., 2020). Un estudio actual prospectivo, multicéntrico, aleatorizado y controlado indicó que el uso de un modelo de selección de time-lapse como KIDScore para elegir blastocistos para la transferencia de un solo embrión fresco en día 5 no mejoró la tasa de embarazo en curso en comparación con la morfología sola. Cabe destacar que a causa de la COVID-19 se tuvo que detener el ensayo antes de tiempo (Ahlström et al., 2022).
Con potencial de clasificar con éxito los blastocistos en función de su precisión para predecir la ploidía y el potencial de implantación, encontramos el modelo de inteligencia artificial ERICA (Chavez-Badiola et al., 2020). Sin embargo, cabe destacar que los embriones fueron etiquetados como positivos basándose únicamente en los resultados de la gonadotropina coriónica humana beta (beta-hCG), lo cual no confirma la implantación exitosa, ya que esta se define como la presencia de (al menos) un saco gestacional o un latido cardíaco para excluir posibles abortos espontáneos precoces.
El término ómica está muy a la orden del día, se refiere a la aplicación de técnicas de alto rendimiento que simultáneamente toman en consideración las alteraciones en el genoma, el epigenoma, el transcriptoma, la proteoma o el metaboloma en una determinada muestra biológica. Por tanto, parece de utilidad combinar esta información con la inteligencia artificial para personalizar el tratamiento y predecir el resultado. Se ha propuesto un modelo preliminar para seleccionar el embrión con mayor probabilidad de dar lugar a un recién nacido vivo en una cohorte euploide, combinando morfología y perfil proteómico. Parece que las concentraciones de IL-6 y MMP-1 en medio de cultivo son útiles para identificar los embriones exitosos. Sin embargo, se necesitan estudios prospectivos con conjuntos de datos más grandes para obtener resultados concluyentes (Bori et al., 2021). Por otro lado, integrando la información ómica, demográfica y de estilo de vida, junto con la inteligencia artificial, se ha propuesto un protocolo para proponer opciones de tratamiento óptimas y mejorar las tasas de éxito (Siristatidis et al., 2021).
DiscusiónSon muchos los momentos en los que la inteligencia artificial puede tomar decisiones en el laboratorio de reproducción asistida, desde que entra una muestra de semen, se extraen ovocitos en una punción folicular y/o se generan embriones.
Respecto a la parte de andrología, hemos visto algoritmos capaces de analizar diferentes parámetros entre los que destacan la concentración, la motilidad y la morfología del esperma humano, en este último parámetro es donde se centra el papel fundamental de la inteligencia artificial. Bien es cierto, que la mayoría analizan la cabeza, pasando la pieza intermedia y la cola a segundo plano, y podrían realizarse más estudios con el espermatozoide entero (Marín and Chang, 2021; Valiuškaitė et al., 2021; Yüzkat et al., 2021). Todos los algoritmos parecen encontrarse realizando o habiendo superado la fase II y es necesario continuar con la evaluación de la eficacia (fase III) a través del rendimiento general en el mundo real, mediante estudios prospectivos en varios entornos clínicos. En el caso del dispositivo comercial LensHooke X1 PRO, parece haber superado la fase III mediante su estudio prospectivo multicéntrico; no obstante, sería necesario saber más acerca de la evaluación morfológica que en los estudios disponibles se encuentra limitada (Agarwal et al., 2019). Al igual que el sistema Mojo Aisa, el cual parece necesitar más estudios para mejorar sus resultados a bajas concentraciones, la ampliación de la evaluación morfológica y, si fuera posible, disminuir el tiempo de procesamiento (Monteiro et al., 2021).
En el caso de los estudios enfocados a seleccionar el mejor espermatozoide para realizar la técnica de inyección citoplasmática ICSI, gracias a la inteligencia artificial es posible detectar patrones de motilidad que pueden relacionarse con un mejor espermatozoide para inyectar y también se puede clasificar morfológicamente a los espermatozoides sin teñir (Abbasi et al., 2021; Javadi and Mirroshandel, 2019; Mendizabal-Ruiz et al., 2022). Sin embargo, vemos cómo la evaluación detallada en tiempo real de la motilidad y la morfología de forma simultánea es un desafío para el cual aún no se ha llegado a anunciar solución en las bases de datos consultadas. Esto nos hace desconfiar y necesitar más información acerca de Baibys, que dice analizar ambos parámetros, para poder plantearnos su uso clínico.
En lo referente al estudio de ovocitos y embriones, vemos cómo se están desarrollando algoritmos con imágenes estáticas o secuencias de time-lapse tanto en diferentes puntos concretos del desarrollo embrionario como en un periodo determinado (etapa pronuclear, de escisión o en estadio de blastocisto) (Bori et al., 2021; Bormann et al., 2021; Fukunaga et al., 2020; Liao et al., 2021; Loewke et al., 2022; Thirumalaraju et al., 2021; Zhao et al., 2021). Sin embargo, al igual que en los casos anteriores, la mayoría de las publicaciones son de carácter retrospectivo y faltan estudios prospectivos multicéntricos y ensayos controlados aleatorizados cuyo resultado sea la predicción de nacidos vivos. Sobre todo, en el caso de aquellos algoritmos que analizan solamente parámetros morfocinéticos, ya que su utilidad se está poniendo en duda mediante diferentes estudios (Ahlström et al., 2022; Jacoby et al., 2016). Sistemas que podemos encontrar más cerca del mercado como Violet, iDAScore, LifeWhisperer, KID+ o ERICA deben aportar más información para indicar en qué fase de desarrollo se encuentran y garantizar su uso clínico.
En un campo tan complejo como el de la reproducción asistida, en el que por el bien del paciente se quieren obtener resultados satisfactorios lo antes posible, parece difícil intentar incorporar un sistema nuevo, también complejo, como es la inteligencia artificial, con los riesgos que actualmente esta conlleva. Parece que el método de desarrollar algoritmos de inteligencia artificial para abordar los problemas que surgen en un laboratorio de reproducción asistida siga la misma pauta que la de obtener resultados del propio algoritmo, la forma bruta. Por un lado, la mayoría solo se basa en segmentar imágenes o clasificar en función de características, por lo que, además de evaluar su eficacia mediante estudios prospectivos, también deben implementarse para predecir recién nacidos vivos. Por otro lado, los que ya obtienen predicciones, la mayoría son sobre cómo llegar a un blastocisto o conseguir la implantación y lo que realmente nos interesa es saber si va a dar lugar a un recién nacido vivo y sano. Esta gran diversidad de estudios, que la mayoría no se pueden comparar entre ellos, solo nos indican el potencial que tiene el uso de la inteligencia artificial, pero no nos garantizan su uso actual.
Sin embargo, a partir de los diferentes estudios podemos ver cómo se van implementando métodos para superar sus limitaciones y mejorar su desarrollo.
Proporcionar una mayor transparencia del algoritmo es beneficioso tanto para comprender el funcionamiento como para hacer un buen uso. Vemos cómo van aplicándose métodos apareciendo el uso de técnicas de visualización simple como mapas de calor o de oclusión o gradientes integrados (Abbasi et al., 2021; Javadi and Mirroshandel, 2019; Loewke et al., 2022).
Se van utilizando otros parámetros además de los obtenidos a través de las imágenes o videos como puede ser la edad del paciente, el día de captura de la imagen o el perfil proteómico (Bori et al., 2021; Loewke et al., 2022). Parece necesario seguir con ello e incluir una gran cantidad de parámetros que pueden tener implicaciones sobre el espermatozoide, el ovocito o el embrión. Algunos ejemplos podrían ser desde el punto de vista del paciente, el índice de masa corporal, o desde el punto de vista del laboratorio, la altitud a la que se encuentra este, ya que varían los niveles de CO2 a los que se pueden encontrar los gametos o embriones o incluso los medios de cultivo utilizados.
Los algoritmos son tan buenos como los datos en los que se basan. Se están empezando a usar bases de datos de imágenes, sobre todo en los estudios de esperma, como SMIDS, HuSHeM, SCIAN y MHSMA entre otros, o de vídeo, como VISEM, disponibles públicamente para desarrollar los algoritmos. En el caso de las de imágenes hay diversidad de clasificaciones como por ejemplo SMIDS que clasifica en función de normal, anormal y no esperma, HuSHeM en cabeza normal, cónica, periforme y amorfa y SCIAN-Morpho en normal, cónico, periforme, pequeña y amorfa y MHSMA en normal y anormal tanto el acrosoma, la cabeza, vacuola y cola y el cuello. Hay que tener en cuenta que dependiendo de la base de datos pueden presentar limitaciones como conjunto de datos desequilibrado o reducido o en algunos casos puede haber disparidad de opiniones entre la clasificación de los expertos. El uso de bases de datos públicas ayuda a garantizar un estándar común que permita proporcionar resultados reproducibles y comparables. Sin embargo, parece necesario que estas deban superar sus limitaciones y estar actualizándose y mejorándose, siguiendo los avances tecnológicos y nuevos hallazgos. Además, deberían crearse más bases de datos públicas con grandes conjuntos de datos de calidad para evaluar el semen, los ovocitos y los embriones.
Según decía Ignacio Hernández Medrano, neurólogo del Hospital Ramón y Cajal de Madrid y cofundador de Mendelian, durante el acto de entrega de los premios a la Innovación Científica para Jóvenes Investigadores de la Fundación Pfizer, existen tendencias que crecen de forma lineal y mejoran tan lentamente que enmascaran otras que crecen de forma distinta. Estas últimas aparecen y quieren cambiarlo todo de forma que empiezan siguiendo una linealidad hasta el punto de que son lo suficientemente buenas y evolucionan siguiendo una tendencia exponencial. Sin embargo, antes de llegar a este punto les cuesta mucho arrancar, debido a que tienen problemas. Estableciendo una similitud con la inteligencia artificial, en el mundo de la reproducción asistida podríamos encontrar varios inconvenientes expuestos anteriormente que impiden que esta no termine de integrarse.
Sin embargo, la tecnología no tiene porqué ser perfecta, simplemente mejor de lo que tenías antes y la inteligencia artificial puede brindar grandes ventajas como ayudar a priorizar, a optimizar el tiempo sabiendo qué espermatozoide junto a qué ovocito va a dar lugar a un embrión de buena categoría y cuál embrión transferir primero, ya que al final lo que se pretende mediante la reproducción asistida es la obtención de un recién nacido sano en el menor tiempo posible. Además, la automatización de los procedimientos incorporando inteligencia artificial permitiría lograr la estandarización y reducir la variabilidad entre clínicas y sirve de apoyo y justificación frente a las decisiones que toma el embriólogo, siempre y cuando cumpla con su deber de aprender cómo usar e interpretar mejor los algoritmos y realizar controles de calidad, entre otros (Medical Association, 2019).
El hecho es que se busca obtener mejores resultados reduciendo al máximo la probabilidad de error y la inteligencia artificial tiene potencial de ayudar al laboratorio de reproducción asistida con ello en un futuro cercano. Por tanto, tiene que llegar el momento en el que la inteligencia artificial termine de hacerse un hueco y se convierta en un básico de apoyo al embriólogo.
ConclusiónLa inteligencia artificial ha llegado para quedarse y está empezando a tener un impacto en la medicina reproductiva, un campo en constante evolución que está dispuesto a emplear nuevas tecnologías para lograr el objetivo de conseguir un recién nacido sano en casa lo antes posible.
Varios estudios han aplicado aprendizaje automático en aquellos momentos de toma de decisión en el laboratorio de reproducción asistida, tratando de mostrar la relevancia clínica que poseen. Encontramos algoritmos capaces de analizar diferentes parámetros seminales, entre los que destacan la concentración, la motilidad y la morfología, y de seleccionar el mejor espermatozoide para realizar la técnica de inyección citoplasmática ICSI. Además, se están desarrollando algoritmos capaces de segmentar, clasificar y predecir la formación del blastocisto, el potencial de implantación o incluso la obtención de un recién nacido vivo y sano. Todo ello a partir de imágenes estáticas o con secuencias de time-lapse tanto en diferentes puntos concretos del desarrollo embrionario como en un periodo determinado (etapa pronuclear, de escisión o en estadio de blastocisto). En lo referente al mundo comercial vemos cómo se deben aportar estudios que corroboren su funcionamiento, ya que algunos dispositivos no presentan ningún estudio en las bases de datos consultadas y los pocos que presentan son retrospectivos o presentan limitaciones.
Las limitaciones con las que se suelen tener que lidiar son, además de la naturaleza del estudio, conseguir un algoritmo explicable, introducir otros parámetros que afecten en el resultado y el conjunto de datos. Para conseguir una implementación confiable, exitosa y eficaz de la inteligencia artificial en la clínica se tienen que producir ensayos controlados aleatorizados en diferentes clínicas en los que se expongan algoritmos explicables que mediante el análisis de diferentes parámetros consigan un resultado a partir de conjuntos de datos generalizados y públicos que permitan un mejor desarrollo comparable y reproducible o de datos prospectivos.
En resumen, la inteligencia artificial puede considerarse una herramienta prometedora para resolver muchos desafíos en el laboratorio de reproducción asistida. Sin embargo, en la actualidad, aún tiene que seguir desarrollándose y afianzarse para tener una validez clínica confiable.
DeclaracionesFuente de financiaciónLa presente investigación no ha recibido ayudas específicas provenientes de las agencias del sector público, sector comercial o entidades sin ánimo de lucro.
Conflicto de interesesEl siguiente artículo no ha recibido financiación específica de ninguna institución y se ha realizado dentro de las actividades académicas establecidas en el Máster Universitario en Medicina y Genética Reproductivas de la Cátedra de Biomedicina Reproductiva Hospital HLA Vistahermosa junto con la Universidad Miguel Hernández.
