




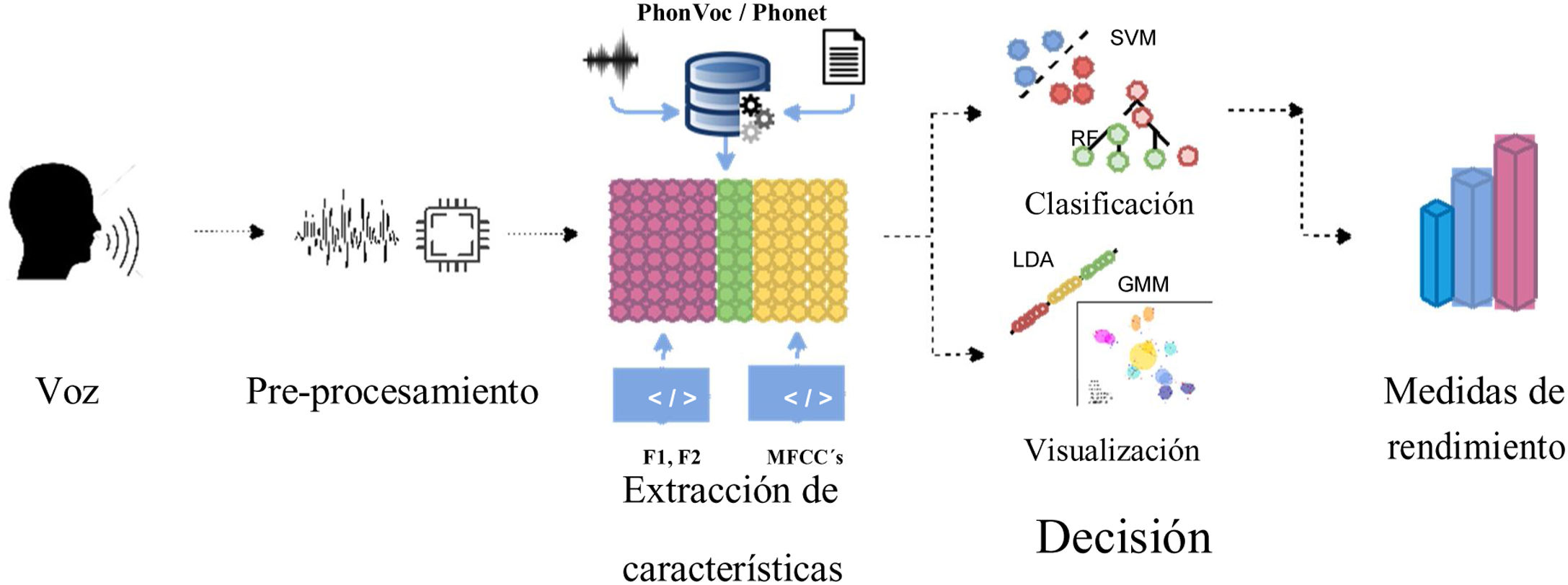
Las investigaciones recientes han mostrado que el análisis de las señales de habla provee información relevante para el apoyo diagnóstico y monitoreo de pacientes con enfermedad de Parkinson (EP). En este trabajo se propone una metodología para la construcción de mapas articulatorios basados en información articulatoria y fonológica del habla tal que permita la clasificación automática de personas con EP vs. personas asintomáticas y que además logre una fácil visualización e interpretación de los resultados.
Materiales y métodosSe consideraron 100 grabaciones de audio de un texto leído que contiene todos los sonidos del español hablado en Colombia. Se extrajeron características articulatorias y además fonológicas a través de dos herramientas: PhonVoc y Phonet. Luego, a partir del alineamiento forzado se obtuvieron los tiempos de ocurrencia de los fonemas para agrupar las clases fonológicas. Posteriormente se implementaron dos clasificadores, máquinas de soporte vectorial y árboles aleatorios.
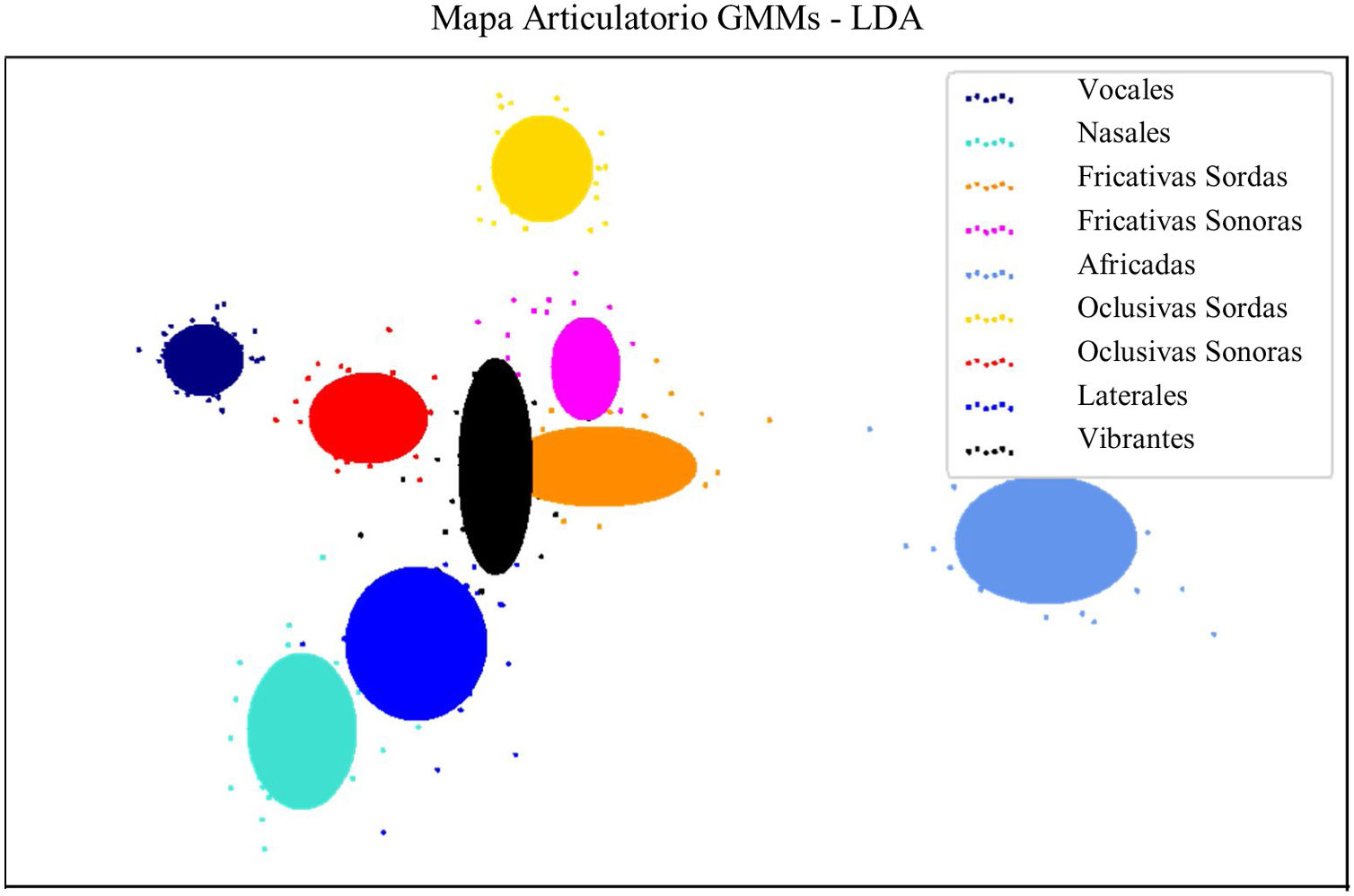
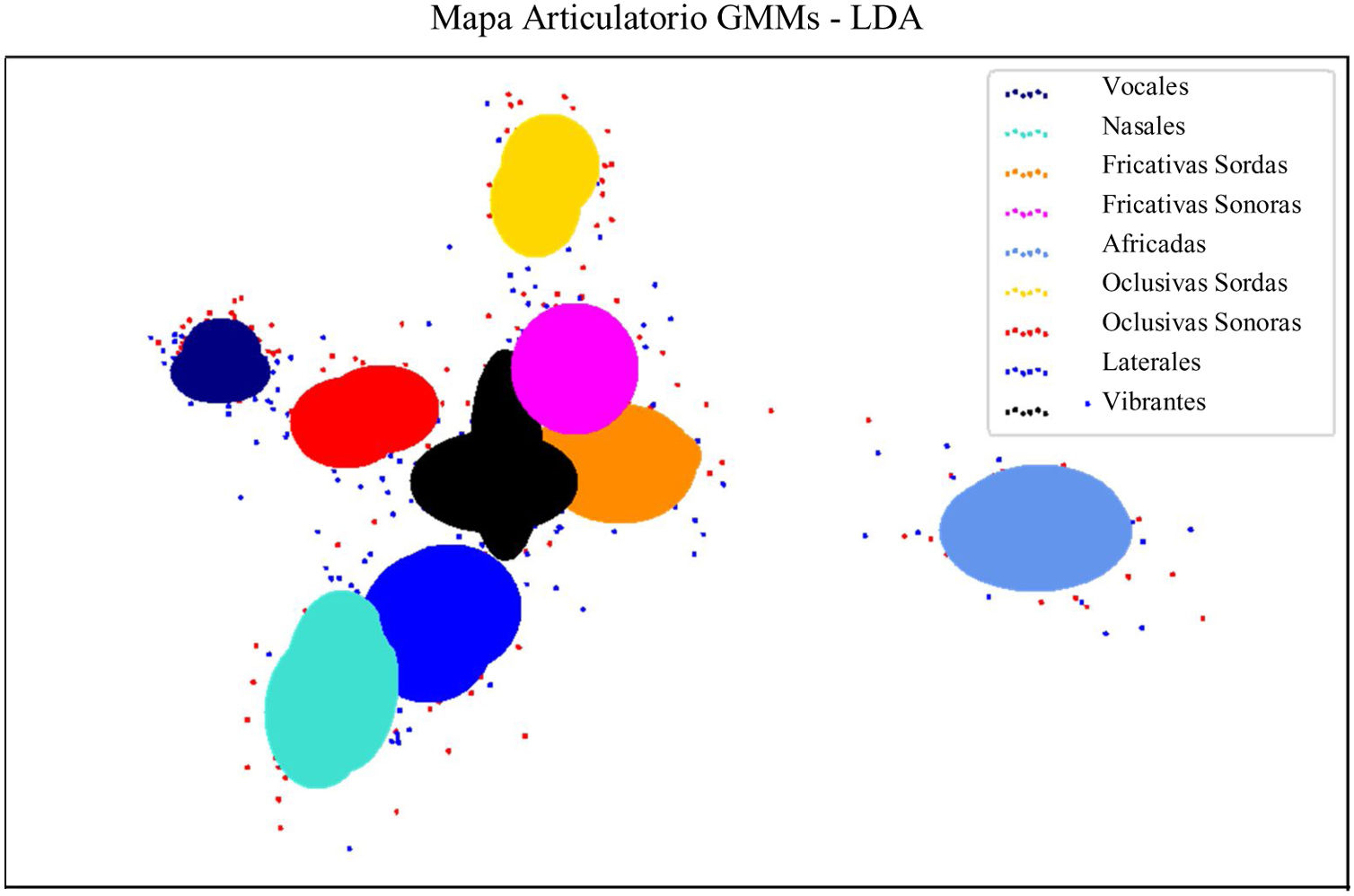
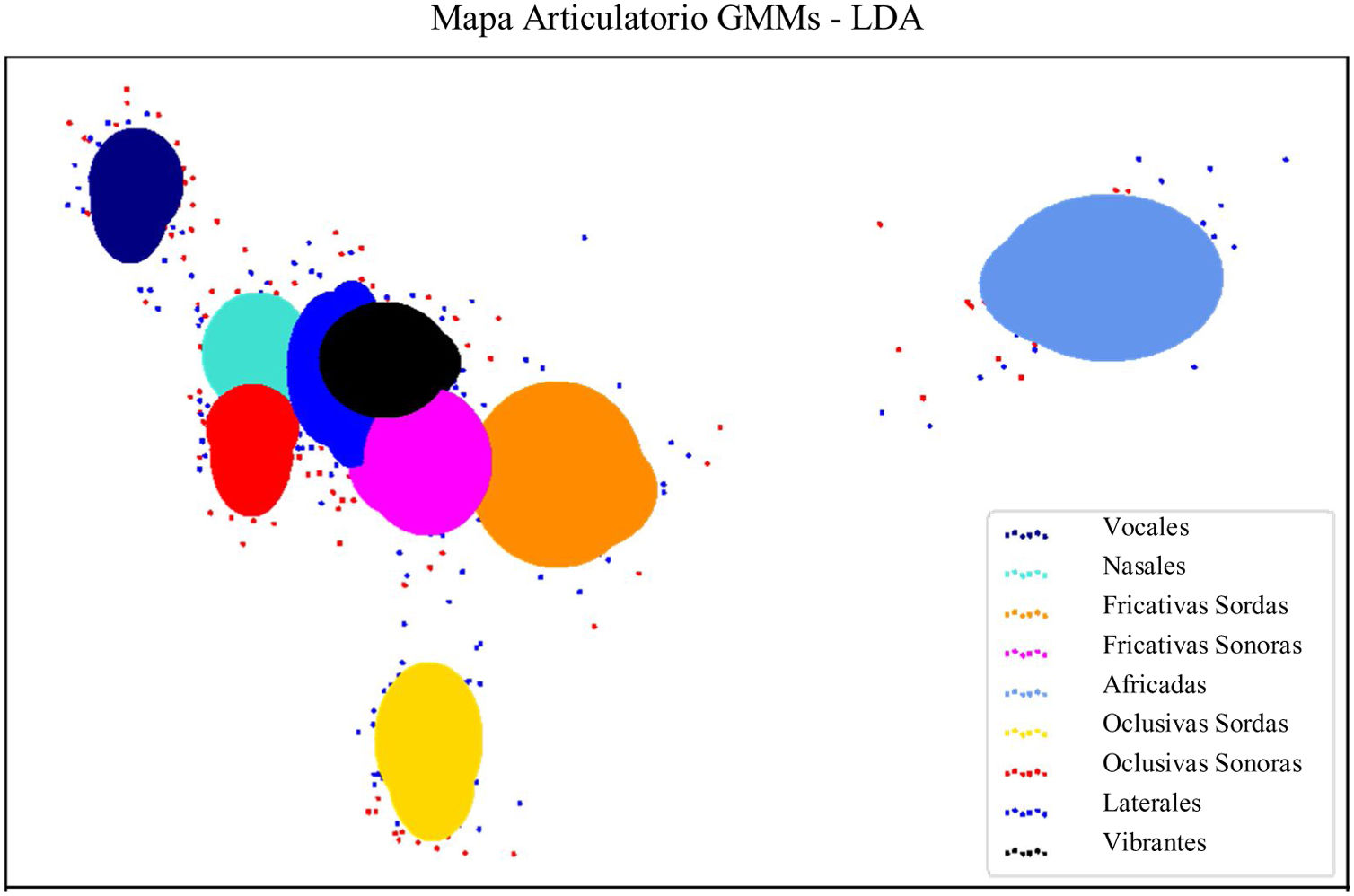
ResultadosLos experimentos muestran un acierto de hasta 90% en la clasificación de pacientes vs. asintomáticos con la clase fonológica «Vocales» y aciertos superiores al 80% para las clases «Nasales», «Fricativas sordas» y «Oclusivas sonoras». Para facilitar la interpretación visual de los resultados se construyeron mapas articulatorios usando mezclas de modelos Gaussianos (GMMs, por las siglas en inglés de Gaussian Mixture Models) que agruparon las clases fonológicas en dos dimensiones.
ConclusionesLa metodología propuesta es una alternativa adecuada tanto para la detección automática de la EP como para la evaluación del déficit articulatorio en los fonemas contenidos en las clases fonológicas.
Recent studies have shown that speech analysis provides relevant information to support the diagnosis and monitoring of patients suffering from Parkinson's disease (PD). In this work a methodology is proposed to create articulatory maps based on articulatory and phonological information such that allow a clear and interpretable visualization of the results.
Materials and methodsA total of 100 speakers were recorded while reading a text with 36 words that includes all phonemes of the Colombian Spanish. Phonological features are extracted with two toolkits: PhonVoc and Phonet. Forced alignment is used to obtained the time-stamps per phoneme. Support vector machines and random forests are used to classify between PD patients and non-symptomatic subjects.
ResultsAccuracies of up to 90% are observed when the phonological class «Vowels» is considered and also accuracies above 80% are found for «Nasals», «Voiceless ficatives» and «Voiced Stop». Articulatory maps are created based on Gaussian mixture models with the aim to enable the interpretation of results.
ConclusionsThe proposed methodology is suitable for the automatic detection of PD and also to assess possible articulatory deficits in the production of specific phonological classes.


