







Gender classification is a fundamental face analysis task. In previous studies, the focus of most researchers has been on face images acquired under controlled conditions. Real-world face images contain different illumination effects and variations in facial expressions and poses, all together make gender classification a more challenging task. In this paper, we propose an efficient gender classification technique for real-world face images (Labeled faces in the Wild). In this work, we extracted facial local features using local binary pattern (LBP) and then, we fuse these features with clothing features, which enhance the classification accuracy rate remarkably. In the following step, particle swarm optimization (PSO) and genetic algorithms (GA) are combined to select the most important features' set which more clearly represent the gender and thus, the data size dimension is reduced. Optimized features are then passed to support vector machine (SVM) and thus, classification accuracy rate of 98.3% is obtained. Experiments are performed on real-world face image database.
Gender classification is gaining popularity in the current research field. There is a wide range of applications that involves the use of this mechanism; intelligent user interfaces, demographics and customer-oriented publicizing are some of them.
With the advancement in human-computer interaction field, there is a growing demand for secure protection techniques such as face recognition [1]; finger prints recognition [2]; gesture recognition, and gender classification. Generally speaking, the features of an object are of two types; appearance based (global) and geometric based. The former extract the features from the full facial expression, which is considered an easy task. The latter method is used to get the characteristics of every gesture of the face; giving the benefit of face rotation to have a look from various angles.
In the 1990s, Golomb et al. [3], trained two-layer neural network called SEX-NET and attained 91.9 % classification accuracy rate. They used a total of 90 frontal face images. In 1995, Brunelli and Poggio et al. [4], extracted geometric features and utilized them to train the networks. They claimed a 79% classification accuracy rate. Sun et al. (2002) [5], asserted that genetic algorithm (GA) works considerably well for vital feature's selection task. They used principal component analysis (PCA) to create features' vector and GA to select the vital features. They attained a 95.3% accuracy rate after training support vector machine classifier by using those vital features. In 2004, A. Jain et al. [6], extracted facial features using independent component analysis (ICA), and then categorized gender using liner discriminant analysis (LDA). They provided results using normalized FERET database and attained a 99.3 % classification accuracy rate. In 2006, Sun et al., [7] used local binary pattern (LBP) to create features' vectors in the input of AdaBoost and attained a 95.75% classification accuracy rate. In 2007, Baluja and H Rowley [8] attained a 93% classification accuracy rate. They used pixel comparison operators with Adaboost classifier. In 2010, Nazir et al., [9] utilized discrete cosine change (DCT) to extract the vital facial features and utilized K-nearest neighbor classifier to categorize gender. In 2011, S. A. Khan et al., [10] used discrete wavelet change (DWT) to extract facial features. They claimed that classifier performance could be improved by assembling different classifiers using weight majority technique. They performed experiments at Stanford University Medical Students (SUMS) face database and received a 95.63% classification accuracy rate.
A major problem with all these proposed techniques is that these take into account only frontal face images (e.g., SUMS, FERET). The images in these databases consist of pictures that have a clean background, are occlusions free, furnish merely frontal faces, encompass limited facial expressions and have consistent lighting effects. But, real-time images are normally captured in unconstrained settings and conditions. A real-time picture normally contains momentous emergence variations like illumination change, poor picture quality, makeup or occlusions and disparate facial expressions. Gender recognition in an unconstrained environment is a very challenging task compared to images captured in constrained settings like FERET, and SUMS face databases. This problem has been highlighted by few researchers. Shakharovichet al. (2002) [11] gathered 3500 face pictures from the web. They used Haar-like features and obtained a 79% accuracy rate with Adaboost and 75.5% with SVM. W. Gao and H. Ai (2009) [12], claimed a 95.5% classification accuracy rate by performing experiments on 10,100 real-time images. They also used Haar-like features but used probabilistic boosting tree. We supposed they used these results as benchmarks as their databases are not publicly available. N. Kumar et al. (2009) [13] performed experiments on real-time images. They received a 81.22% classification accuracy rate by training countless binary “attributes” classifiers. Their emphasis was put more on face verification and not on gender classification.
The major contributions of our work are as follows:
- •
Proposed technique is robust to illumination and expression changes due to local texture feature selection.
- •
Combination and optimization of facial and clothing features provides improved accuracy while using less number of features.
- •
Technique presented in this manuscript gives superior results on real-world face image dataset when compare to the existing methods.
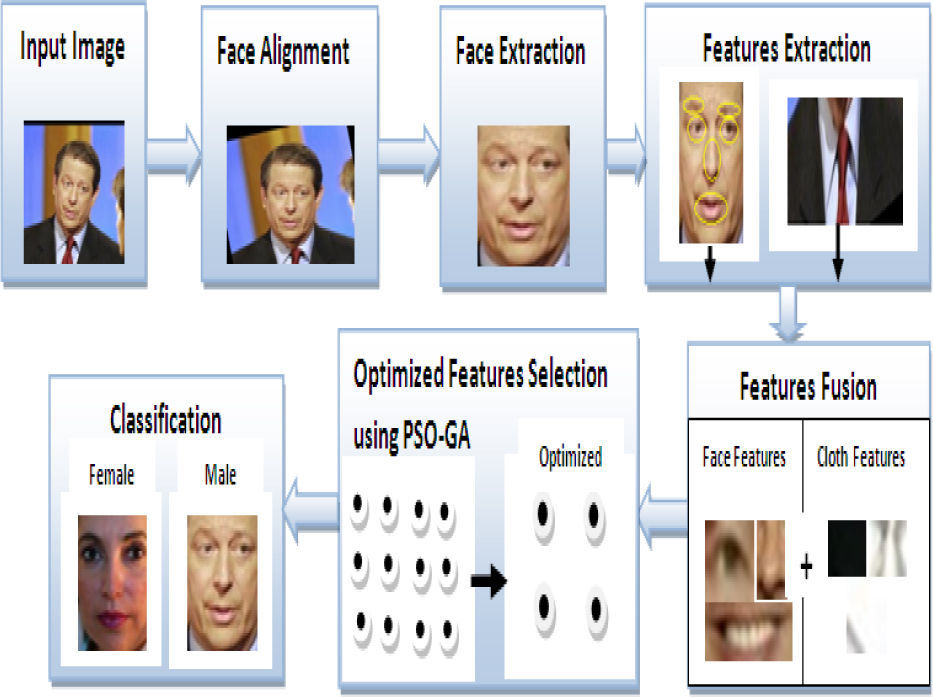
The proposed method consists of the following steps as depicted in Figure 1.

Pre-processing: First, we align the images by using commercial software [14] and then perform histogram equalization to normalize the face.
Face extraction: Facial portion is extracted and unwanted area is removed using spatial co-the ordinate system.
Features extraction: Facial local features like nose, mouth and eyes are extracted using the local binary pattern (LBP). A Color histogram is used to save the color information while LBP carries the textures' information of clothes.
Features fusion: In this step, facial and clothes features are fused by a concatenation method.
Optimized features selection: Only most important feature sets are selected using hybrid PSO-GA algorithm.
Classification: In this step, support vector machine (SVM) is used to classify gender.
2.1Facial portion extractionA solitary tiny picture normally contains thousands of pixels. This huge data set seriously affects the computational time and makes the system slow that is why pixel-based approaches are very expensive. Thus, to remove the unwanted area and to extract merely facial portion we use spatial co-ordinate system. By using hit and trial method we set the X and Y coordinates values. Figure 2 depicts a sample of extracted images.
2.2Feature extraction
To get improved results, we extract both facial and clothing features of gender. The features' extraction mechanism is explained below.
Facial local features extraction: Face portion plays an important role in representing the gender. Features get from the whole face portion are known as global features. Global features are affected if a face contains some occlusion or illumination change. The sub-face individual features like nose, eyebrows and mouth, etc., are known as local features. Local features are robust to variations like illumination, face occlusions and alignment. In this work, we extract the features of nose, mouth, chin, eyes and forehead. First, facial components are located using active shape model (ASM) [15], and then facial components are cropped from the image. In the next step, local binary pattern (LBP) is applied to extract the features from facial components.
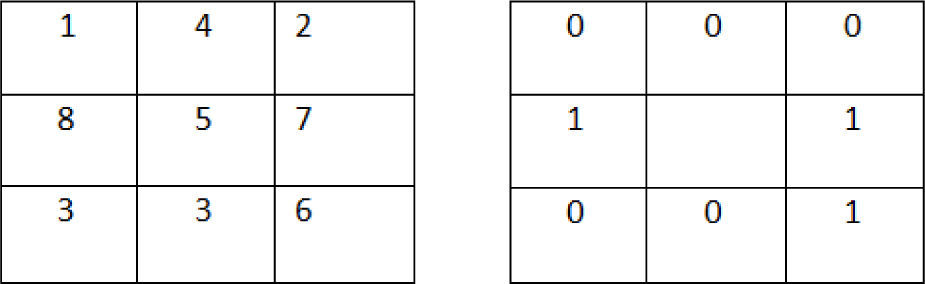
Lian and Lu [16] used LBP for gender classification. The working algorithm of LBP is simple but efficient to carry texture information and also stable under illumination change. The operator of LBP labels the neighbor pixels values by thresholding with center value.
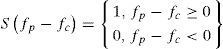
Here represent the center value, and represents the neighbors' pixels. Equation 2, represents the LBP operator at the center.
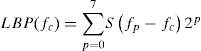
In LBP, the center pixel is selected, and the neighborhood pixels are either, modified to 0 if the gray levels are smaller than center, or to 1 if the gray levels are larger than a center. The center pixel is next substituted by the binary code of its neighborhood like 00011011, as it is shown in Figure 3.

Cloth features extraction: Hauling out various characteristics from clothes is very exigent due to diverse classification in garment's styles, consistency, outlines and insignia comparatively from facial appearance of human being.
Even matching garments represent different characteristics with different human bodies, although cloth attribute is generally superfluous because of its bulky deviation in today's research work. Therefore, we consider identical gender cloths with the same features regardless of dissimilarity as shown in Figure 4.

Based on these arguments, we apply color histogram and local binary pattern algorithm while extracting characteristics of the clothes. Both schemes are resistant to illumination and rotation transformation. Local binary pattern carried texture information and color histogram contains color information of clothes. The clothing texture images are shown in Figure 4.
2.3Features normalization and fusionThe feature vector of the face and clothes are represented by and Dimensions of both feature vectors are different, that is why we normalize both feature vectors between
Diversity is present between the facial and clothing feature vectors, which affect the fusion process of both feature vectors. For example, if the values of are in between and values of are in between {0 and 1}, then the distance is more sensitive to as compare to. In order to solve this problem, we normalized both feature's vectors.
Let n and n′ represents the features' values before and after normalization. We compute the normalized features by using Min-Max technique.
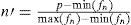
In Equation 3, the function generated at and the and represents the minimum and maximum values of all possible ‘n’ values.
The advantages of feature level fusion are obvious. By combining and fusing different features, we not only are able to preserve the discriminative information about the face but we also can eliminate redundant features. To take advantage of different features' extraction (techniques for better classification) and to make a proposed technique more robust to variations in expressions, illumination and pose changes, we have fused face and clothing features by the concatenation method.
Let the normalized features vectors of ‘ then; ’ represent the concatenation features vector. Procedure for feature fusion is provided below.
2.4Optimized features selectionIn machine learning, the features' selection procedure is a process of selecting the optimal facial features and discarding redundant features that increase the classification accuracy rate. To select the optimal features, a combination of particle swarm optimization and genetic algorithm is used.
Genetic algorithm: In 1970, Holland provided the idea of a genetic algorithm. GAs is a stochastic search algorithms modeled on the procedure of natural selection; that underlines biological evolution. GAs has successfully been applied in many search, optimization, and machine learning problems [17]. GAs is used to simulate procedures in natural systems that are vital for evolution. GA searched for the best solution in search space intelligently and works in an iterative order, such as that new generation is created from the old one. The strings in GA's are represented as binary codes. In GA's, a fitness function computes the fitness of every string. The standard operators used in GA's are mutation, crossover and selection.
Particle swarm optimization: is a population- based stochastic optimization technique that was developed by Kennedy and Eberhart in 1995 [18]. A particle in search space can be considered as “an individual bird of a flock.” To find the best solution PSO uses local and global information. The fittest solution is found by utilizing the fitness function and velocities of the particles. In PSO, the particle position gets updated by using local and global positions of every particle around its neighbor. The particles move across the problem space searching for the optimal particles (features). The procedure is then repeated for a fixed number of periods or until a minimum, error is attained [18].
K-nearest neighbor: The K-nearest acquaintance (K-NN) method was introduced by Fix and Hodges in 1951, and is one of the most accepted nonparametric methods [19]. KNN classifies the new data based on the knowledge of training data. Random procedures are used to solve the lazy problems. The working procedure of KNN is that it calculates the distance from the query instance and the training data. In our work, we used leave-one-out cross validation strategy of 1-NN and the distance between neighbors is calculated using Euclidean distance. 1-NN strategy is easy to implement as it is independent of user-specified parameters. The particles are coded as binary strings, i.e., S=F1 F2.….Fn, n=1, 2,.….m; where bit value ‘1’ represents selected features, and ‘0’ represent unselected features. The initial population is generated randomly, and leave-one-out cross validation strategy is used to evaluate the fitness value. To select the best solution from population, mutation and crossover operators are applied without modification. We used rand-based roulette-wheel scheme. In this work, the two cutting points are chosen using the 2-point crossover operator. First, a check is performed for mutation, and if mutation exists, then the offspring are mutated, and the code conversion is performed from 1 to 0 and similarly from 0 to 1. Next, if the mutated chromosomes resulted worthier than parents, then the replacement is performed with the worst parent and in another case, the replacement is performed with the lower quality one. The performance of GA is enhanced by applying the PSO for each new generation. In this work, the adaptive values are used to renew the particle. pbest and gbest are the best adaptive values in pbest group. The particle position and speed are tracked after the values of pbest and gbest are obtained. The below equations are used to perform the updating process.
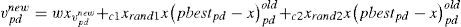
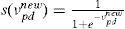
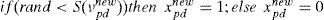
Before updating the particle, the worth of gbest is checked to prevent particle from getting trapped in local optimum. The gbest value is updated if it is found that its value remains a number of times. Equation 4 is used to calculate the features after the update. Here V represents the velocity.
The features are selected and represented by “1” if value of greater than random produced disorder {0.0∼1.0}, and the features are unselected and represent by “0” if value of is less than the random produced disorder {0.0∼1.0}. The GA was configured to encompass 20 chromosomes and was run for 100 generations in each trial. The crossover rate and mutation rate was 1.0 and 0.1 respectively. The number of particles used is 20. The two factors rand1 and rand2 are random numbers between (0, 1), whereas C1 and C2 are acceleration (learning) factors, with C1=C2=2. The inertia weight ‘w’ was set as 0.9. The maximum number of iterations utilized in our PSO was 100.
2.5Classification using support vector machineThe gender classification problem can be thought of as a two-class problem and the goal of this problem is to separate the two classes by mean of a function. SVM is a useful technique for data classification and is easier to use than Neural Networks. SVM takes data (features) as input and predicts based on training data set to which class these features belong. The goal of SVM is to find the optimal hyper plan such that the error rate is minimized for an unseen test sample. According to the structural risk minimization principals and VC dimension minimization principle [20] a linear SVM uses a systematic approach to find a linear function with the lowest capacity.
The SVM classifier correctly separates the training data of the labeled set of M training samples where € and are the associated label, i.e., (ε {-1, 1}). The hyper plan is defined as:
3Results and discussion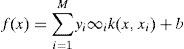
We used MATLAB 2009a environment for our experiments. Label faces in the wild, (LFW) [21], face database was used for experiments. This database contains 13,233 images collected from a web. To remove unwanted area, face portion was extracted using spatial co-ordinate system and then, as shown in Figure 5, histogram equalization was applied to normalize the face image. We selected 400 face images, 200 male and 200 female for our experimental setting. As shown in Figure 6, all the faces were aligned using commercial aligned software (Wolf et al 2009) [14].
 and after (b) normalization")
 and align (b) image")
We did avoid those images for which it was difficult to establish the ground truth as shown in Figure 7.

The 5-fold cross validation is used in all experiments. First, the image is resized to 32×32 and then it is divided into blocks of size 8×8. For geometric-based features extraction, first the five facial points are located using active shape model and then local binary pattern is used to extract the local features from these points. In the next step, we extract the clothing features by applying the LBP, which carry texture information and color histogram, which carry the color information of cloths. After facial and cloths features extraction we pass these features to support vector machine (SVM) to find the classification accuracy rate.
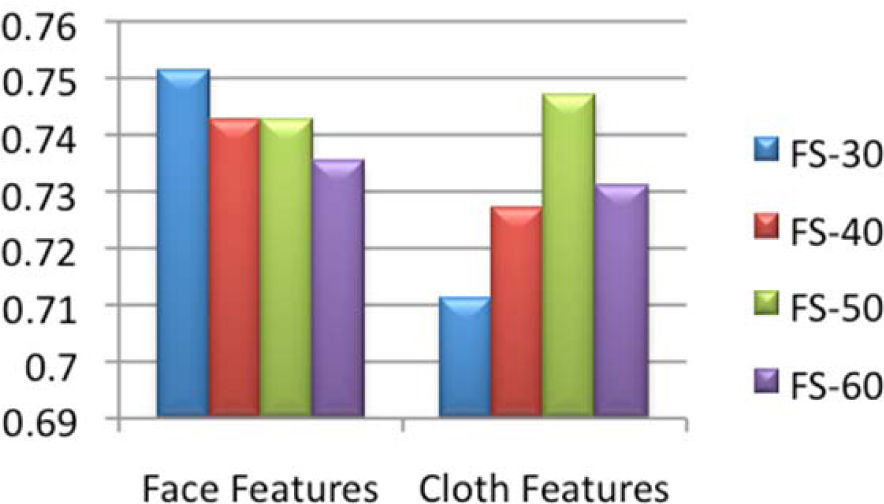
Figure 8, shows the classification accuracy of facial and clothing features; extracted using different features set (i.e., 30, 40, 50 and 60). Figure 8, also shows that in case of clothing features, FS-30 produce the higher accuracy rate (i.e., 75%) as compared to other features set and FS-50 produce 74% in case of clothing features.

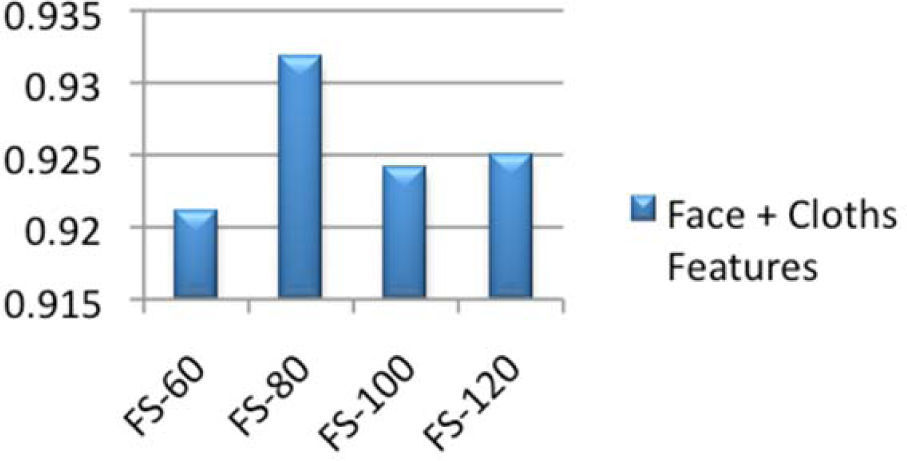
After the extraction of facial and clothing features, fusion of features is performed using the concatenation method and features vectors of size 60, 80, 100 and 120 are generated. Figure 9, shows the classification accuracy rate after features fusion. We examine that classification accuracy rate of face and cloth features are low separately but when features of both types are fused then classification accuracy rate increases dramatically. The drawback is that the data dimension size also increases due to fusion process; hence, to reduce the data dimension size, optimized features are selected in the next step.

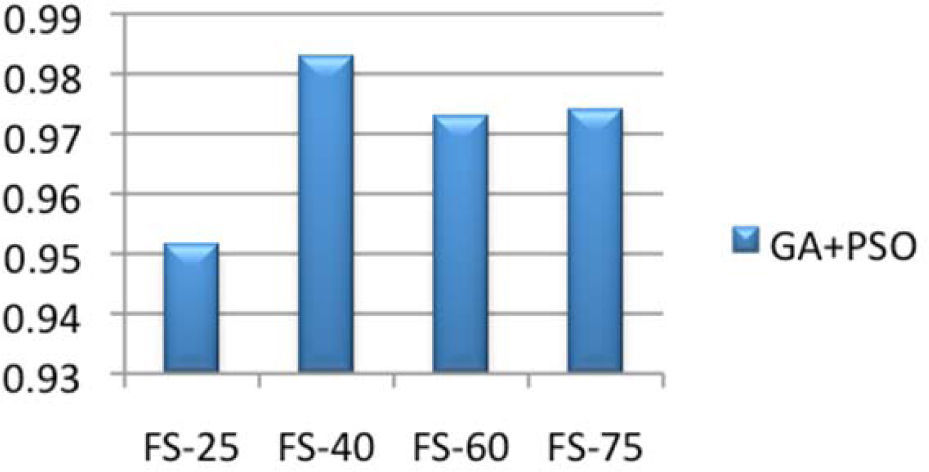
In the next step GA and PSO were combined using leave-one-out cross validation strategy of 1-NN and distance between neighbors was calculated using Euclidean distance. The features set (i.e., 80), were passed to GA-PSO, which eliminates the redundant features and GA-PSO get back the result as optimized features (i.e., 40). After optimization step the support vector machine was trained and tested by optimized features. 1:3 and 3:1 testing to training ratio was used for SVM. Figure 10 shows the accuracy rate after features optimization. The results depict that the hybrid GA-PSO was very useful for features optimization. By using this technique, the enhancement in the classification accuracy rate (i.e., 98%) is noteworthy and it also reduced the data dimension size (i.e., from 80 features set to 40 features) that is shown in Figure 10.

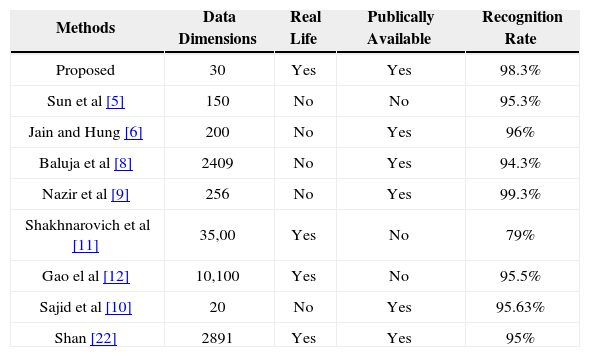
Table 1, presents a comparison of our proposed technique with other gender classification techniques. In our proposed technique we overcome the problems like high dimensions (i.e., by utilizing the minimum number of features), variation in pose or occlusions (i.e., by combing facial and clothing features). We used real life images that have large amount of variations in facial expression and poses. The database that we have used is also publically available which helps to benchmark for future. In Table 1, the proposed technique using real life face images is also publically available as compared to other techniques face databases. The high recognition rate of 98% is obtained.
Proposed method comparison with state-of-the- art gender classification techniques
| Methods | Data Dimensions | Real Life | Publically Available | Recognition Rate |
|---|---|---|---|---|
| Proposed | 30 | Yes | Yes | 98.3% |
| Sun et al [5] | 150 | No | No | 95.3% |
| Jain and Hung [6] | 200 | No | Yes | 96% |
| Baluja et al [8] | 2409 | No | Yes | 94.3% |
| Nazir et al [9] | 256 | No | Yes | 99.3% |
| Shakhnarovich et al [11] | 35,00 | Yes | No | 79% |
| Gao el al [12] | 10,100 | Yes | No | 95.5% |
| Sajid et al [10] | 20 | No | Yes | 95.63% |
| Shan [22] | 2891 | Yes | Yes | 95% |
In previous studies most of the researchers worked on frontal face images. In this work both face and clothing-based features were extracted and fused which made the systems supportive of variations in expressions and poses. Furthermore, we also concentrated on reducing the data dimensions and struggled to produce optimal features' set that extra precisely embodies a gender face. In this paper, features were optimized by employing hybrid GA-PSO algorithm. Hybrid optimization results in improved 98.3% classification accuracy rate using label in wild face images (LFW) database. Furthermore, we aim to discover swarm-based optimization algorithms (SOAs) like Ant dominion optimization and make our arrangement more precise and stable.