




El machine learning, statistical learning o aprendizaje automático es un concepto perteneciente al ámbito de la Ciencia de la Computación, que se refiere a la capacidad de las máquinas para construir modelos matemáticos de alta eficiencia predictiva, a partir de grandes paquetes de datos por medio de una serie de herramientas basadas en la estadística, la algorítmica y la recursividad, y mejorar los mismos conforme se incorpora nueva información. Si bien ya en el campo de la Senología hay diversos proyectos, principalmente orientados a la interpretación de imágenes tanto en Radiología como en Anatomía Patológica, aún es excepcional el empleo sistemático de esta tecnología como fuente de adquisición de nuevos conocimientos, en particular en lo concerniente a la toma de decisiones clínico-terapéuticas. Todos los especialistas involucrados en el campo de la Senología estamos obligados a familiarizarnos con esta metodología, para poder dirigirla apropiadamente, lejos de su utilización con ánimo de lucro, máxime cuando los éxitos cosechados en otros ámbitos sociales permiten intuir que su implementación en Medicina no solo puede resultar útil sino inevitable.
Machine Learning or Statistical Learning is a concept belonging to the field of Computer Science that refers to the ability of machines to build mathematical models with high predictive efficiency from large data packages through a series of tools based on Statistics, Algorithmics and recursion, and to improve them as new information is incorporated.
Although in the field of breast disorders there are already various projects mainly oriented to the interpretation of images in both Radiology and Pathology, the systematic use of this technology as a source of acquiring new knowledge is still exceptional, particularly with regard to clinical-therapeutic decision-making. All the specialists involved in the field of breast disorders are obliged to familiarize ourselves with this methodology, in order to properly direct it away from its use for profit, especially when the successes achieved in other social spheres allow us to intuit that its implementation in Medicine can not only be useful but unavoidable.
“There was a time when humanity faced the universe alone and without friends. Now he has creatures to help him; stronger creatures than himself, more faithful, more useful, and absolutely devoted to him. Mankind is no longer alone...”.
Machine learning (ML), red neuronal (neural networks) o deep learning son expresiones cada vez más frecuentes en la literatura biomédica. Así si hacemos una búsqueda en la base PubMed de la National Library of Medicine, mientras que en el año 2015 tan solo aparecen 3.292 trabajos publicados conteniendo alguno de estos términos en su título o en el resumen, en 2022 son ya 44.699. Si restringimos la búsqueda al terreno de la Senología incorporando el término breast a la búsqueda son solo 59 y 1.096 el número de referencias que aparecen respectivamente en esos años.
Se trata de expresiones pertenecientes al ámbito de una nueva ciencia, la ciencia de datos o Big Data, cuyos avances y resultados son ya, desde sus inicios en la década de los 90, tan prometedores como incuestionables en campos sobre todo vinculados a la Economía (mercados financieros, aseguradoras, marketing, etc.). Pero, esta tecnología encaminada al desarrollo de modelos matemáticos dinámicos por máquinas analizando grandes paquetes de datos, capaces de aprender y mejorar su eficiencia predictiva con la «experiencia» (nuevos datos), como parte del antiguo y ambiguo concepto de Inteligencia Artificial, ¿es compatible con la Medicina y en particular con la Senología?, ¿cuál es la metodología subyacente sobre la que se fundamentan estos modelos?, ¿podría tener alguna utilidad para nosotros tanto en la toma de decisiones clínicas como en lo referente a la adquisición de nuevos conocimientos?, y si tal es el caso, ¿cuáles son los obstáculos que impiden un desarrollo similar al que se está produciendo en otros sectores de la sociedad?
Para responder a estas cuestiones y otras que se irán planteando a lo largo de este texto, conviene empezar por el principio, el desarrollo histórico que ha conducido al estado actual de las cosas. Continuaremos con un breve análisis introductorio de esta metodología que se postula como firme candidata a sustituir al decadente paradigma de la Medicina basada en la evidencia. Finalmente abordaremos algunas de las infinitas posibilidades que esta tecnología ofrece y que en Senología se perfilan como terreno natural para la misma (en ciertos casos que comentaremos, firmes realidades ya), con sus pros y sus contras.
Un poco de historiaEn 1936 el matemático británico Alan Turing desarrolló un concepto teórico, la máquina de Turing, base de los conceptos de algoritmo y computación, precursor de la moderna Ciencia de la Computación1, y cuya consecuencia casi inmediata fue la construcción del primer ordenador en 1938, bautizado como Z1, a cargo del ingeniero alemán Konrad Zuse. Esta nueva ciencia se anotó su primer éxito notable de la mano del propio Turing, que con la ayuda de un enorme artilugio conocido como la Bombe consiguió descifrar el código Enigma con el que el Tercer Reich dirigía las temibles «manadas de lobos», los submarinos U-boote alemanes, que acechaban en el Atlántico a los convoyes de suministros angloamericanos2.
Un segundo hito en esta historia se produjo en el año 1969, el 29 de octubre, a las 22:30, cuando en el seno de la organización gubernamental estadounidense ARPANET (Advanced Researchs Projects Network), a través de la línea telefónica, Charlie Kline, por medio de un computador del tamaño de una nevera, en la UCLA (Universidad de California en Los Ángeles), logró comunicar el mensaje «L»-«O» a otro localizado en el SRI (Stanford Research Institute), a más de 500 km de distancia, donde esperaba Bill Duvall. Había nacido la red de redes, Internet, debutando con el primer «cuelgue» de la historia, ya que si bien se pretendía transmitir la palabra «login» la comunicación falló tras la transmisión de los 2 primeros caracteres3,4.
La industria de la electrónica y el hardware fue creciendo, consiguiendo cada vez dispositivos con mayor capacidad y velocidad computacional, tamaños más reducidos y precios asequibles que hicieron posible la popularización y el uso doméstico de estos aparatos.
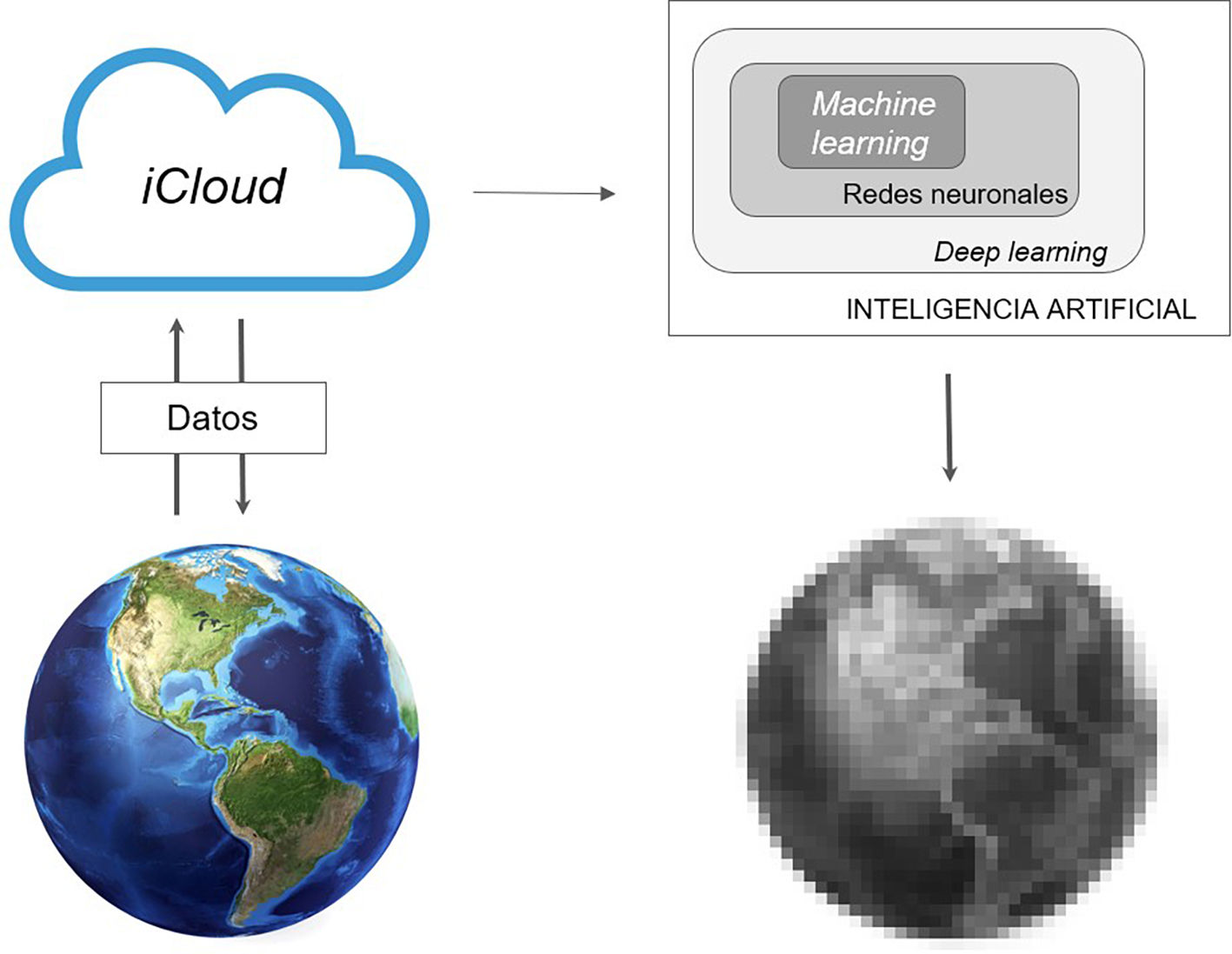
Con el desarrollo del Cloud Computing, la tecnología en la nube, el procesamiento y almacenamiento de datos pasa a convertirse en un servicio público, como puede ser el suministro doméstico de agua o de electricidad5. Convergen así, en el momento presente, cantidades ingentes de datos (como ejemplo, en 2016 se transmitieron 1,3 zettabytes, lo que equivale a unos 250.000 millones de DVD6) y máquinas con alta capacidad de computación en tiempo finito capaces de analizar, modelizar y aprender de esos datos, proporcionando información, tanto más precisa conforme se incorpora nueva información, sobre aquellas personas o entes que los generan, por medio de una nueva metodología estadística, inaccesible solo unas décadas atrás por falta de capacidad para el procesamiento masivo de datos (fig. 1). Curiosamente, en lo que parece un nuevo movimiento pendular de la historia, si Fisher a principios del siglo XX desbancó a los estadísticos de la escuela Biometrika, liderados por Karl Pearson, que consideraban que solo las grandes muestras tenían utilidad para el análisis estadístico, protagonizando la tercera revolución de la estadística (la estadística inferencial, a partir de muestras pequeñas)7, un nuevo paradigma basado en muestras enormes, el Big Data, parece devolverle la razón a Pearson, en lo que sin duda merece ser bautizada como la cuarta revolución.
¿Qué es el ML?
El machine learning, statistical learning o aprendizaje automático es un concepto propio del campo de la Ciencia de la Computación y de la Inteligencia Artificial, que se refiere a la capacidad de las máquinas para aprender autónomamente a partir de grandes paquetes de datos, por medio de una serie de herramientas basadas en la estadística, la algorítmica y la recursividad que les permiten clasificar, detectar patrones y construir modelos predictivos, entendiendo por «aprender» la aptitud para reajustar los modelos construidos, a partir de los errores detectados en su aplicación sobre nuevos conjuntos de datos, aumentando la eficiencia predictiva del modelo, maximizando la función de recompensa del algoritmo6, acorde a la definición de Hawkins de inteligencia en el marco memoria-predicción8.
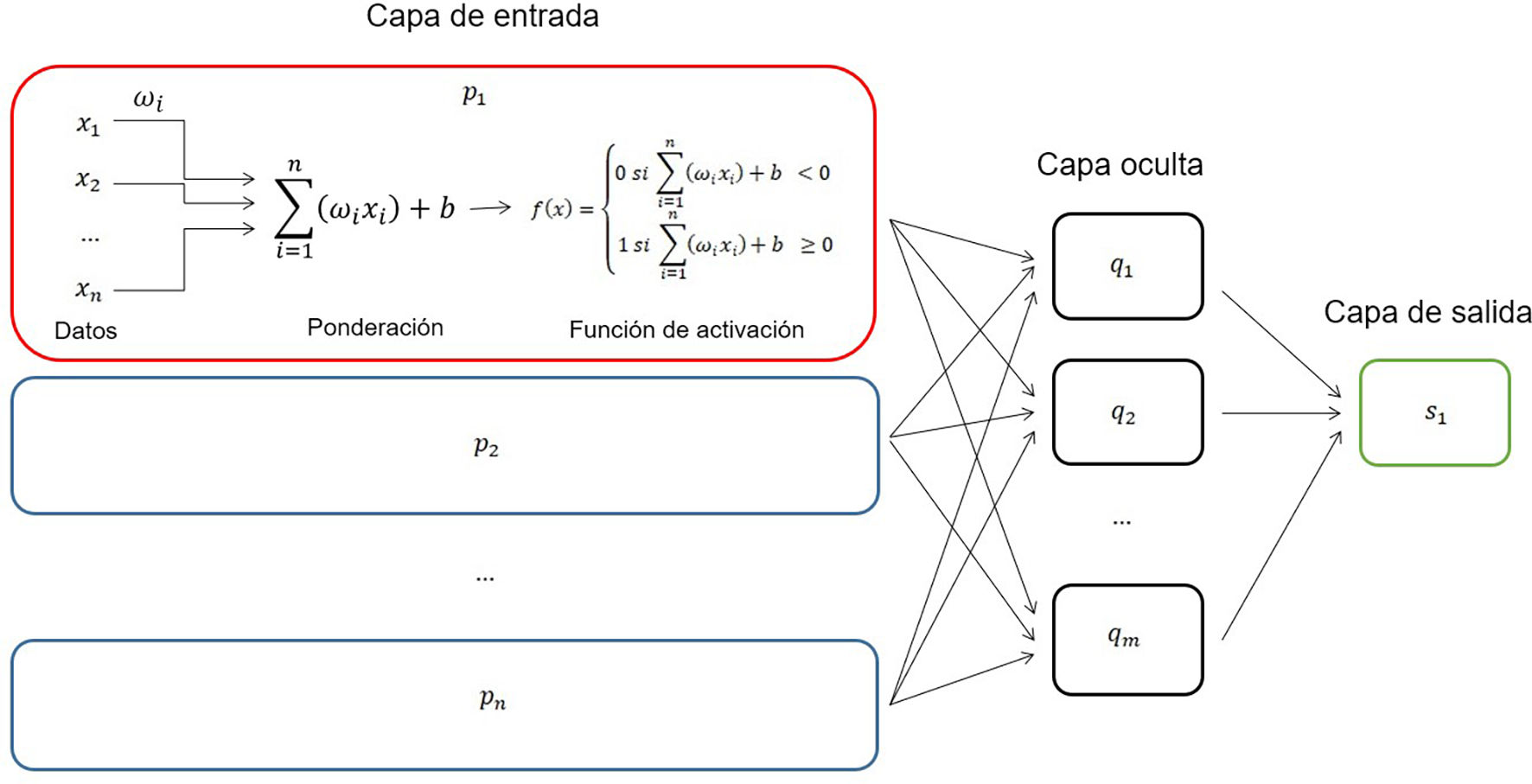
No debe confundirse con el deep learning que implica un nivel de complejidad y autonomía mayor, por medio de las llamadas redes neuronales, donde cada unidad elemental (perceptrón9,10) se integra en una red estructurada en diversas capas, encaminadas a conseguir los mismos propósitos (modelos predictivos de alta precisión), pero cada vez con menor participación del ser humano conforme aumenta la complejidad de la red (fig. 2).
 integrado en una red neuronal multicapa con n neuronas pi de entrada, una capa oculta de m neuronas qi y una de salida (s1). Se ha designado como ωi el peso relativo de cada dato, y como f(x) la denominada función de activación (modificado de Wikipedia9,10).")
Arquitectura de un perceptrón (p1) integrado en una red neuronal multicapa con n neuronas pi de entrada, una capa oculta de m neuronas qi y una de salida (s1). Se ha designado como ωi el peso relativo de cada dato, y como f(x) la denominada función de activación (modificado de Wikipedia9,10).
Básicamente podemos distinguir 2 tipos de aprendizaje en el ámbito del ML en función de la naturaleza del problema que se aborda: supervised learning (aprendizaje supervisado) y unsupervised learning (aprendizaje no supervisado)11.
Sea cual sea la modalidad, el ML divide los datos en 2 conjuntos: uno de entrenamiento (training data set) y otro de validación (test data set). Este proceso con el subsiguiente análisis se produce de manera recursiva miles-millones de veces promediando el resultado final (cross-validation), de modo que la máquina evita los sesgos derivados del proceso de muestreo.
Supervised learningEn este caso el investigador está interesado en predecir el valor que tomará una variable dependiente (respuesta) por medio del análisis de un vector de variables independientes (informativas o predictores). Por ejemplo, queremos predecir la respuesta a la neoadyuvancia con cierto quimioterápico en pacientes con cáncer de mama en función de características como tipo histológico, estadificación del tumor, fenotipo molecular, edad, enfermedad de base de la paciente, etc., y esperamos que el ordenador nos ofrezca un modelo con alta capacidad predictiva en términos de respuesta SÍ / NO. Una parte del proceso, el etiquetado de las variables, debe ser llevada a cabo por el ser humano y de ahí que reciba el nombre de aprendizaje supervisado.
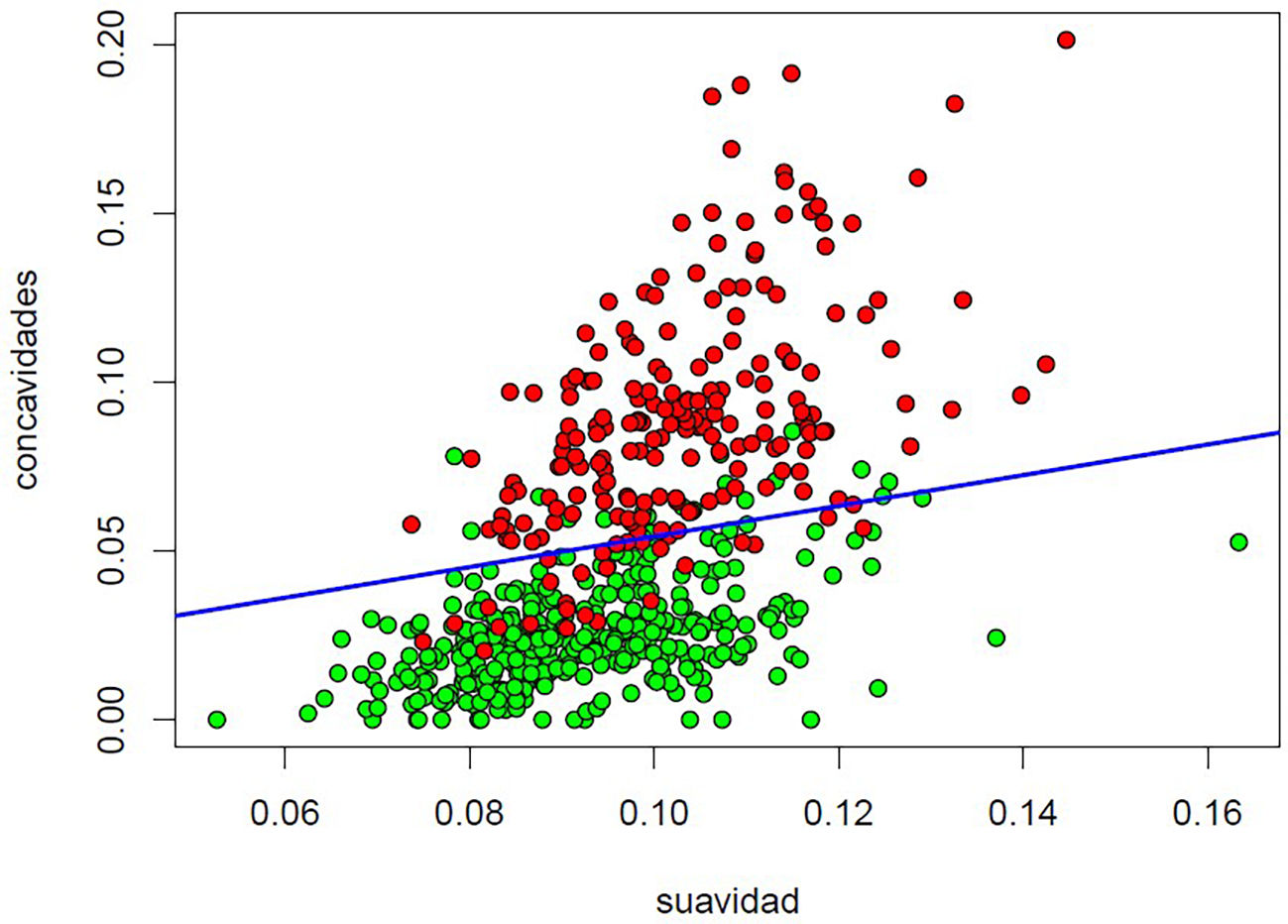
Entre las herramientas estadísticas que utiliza el dispositivo en este tipo de análisis cabe citar entre otros los métodos de regresión lineal y logística, y los modelos de regresión lineal generalizada, el k-Nearest neighbors, el naive Bayes, los árboles de decisión y bosques aleatorizados (random forest), el gradient boosting y el support vector machine12, cuya descripción excede el objeto de este artículo (los interesados pueden consultar el texto de James et al.11) (fig. 3). Resulta especialmente útil en problemas de diagnóstico y pronóstico13.
 de los datos de la base Breast Cancer Wisconsin (Diagnostic) Data Set, disponible en kaggle (https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data) de imágenes de preparaciones de PAAF de lesiones palpables con 2 variables explicativas (suavidad de los bordes del núcleo celular y número de concavidades en el contorno nuclear), con el fin de predecir el diagnóstico final de benignidad/malignidad (contrastado con el diagnóstico anatomopatológico definitivo). El hiperplano obtenido (en azul) clasifica las imágenes correctamente en el 91,39% de los casos.")
Supervised Learning. Ejemplo de análisis basado en el Support Vector Machine lineal (el más sencillo) de los datos de la base Breast Cancer Wisconsin (Diagnostic) Data Set, disponible en kaggle (https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data) de imágenes de preparaciones de PAAF de lesiones palpables con 2 variables explicativas (suavidad de los bordes del núcleo celular y número de concavidades en el contorno nuclear), con el fin de predecir el diagnóstico final de benignidad/malignidad (contrastado con el diagnóstico anatomopatológico definitivo). El hiperplano obtenido (en azul) clasifica las imágenes correctamente en el 91,39% de los casos.
Aquí nuestro interés se centra en analizar un vector de variables sin determinar ninguna en particular como respuesta, con el ánimo de encontrar relaciones que nos permitan clasificar las observaciones en grupos de comportamiento homogéneo, en base a la estructura interna de los datos. Por ejemplo, consideramos la información obtenida en una población de mujeres con la esperanza de poder separarlas en función de ciertos parámetros en grupos, tal vez, por ejemplo, por su riesgo de cáncer de mama. En este caso, y si bien el proceso no está exento de la participación humana, la máquina examina datos crudos sin etiquetar, sin «supervisión».
El ordenador emplea para ello, entre otras, técnicas de clustering (k-means, hierarchical clustering…), reducción de dimensionalidad por análisis de componentes principales y detección y análisis de anomalías (nuevamente se remite a los interesados a la obra de James et al.11 para mayor detalle).
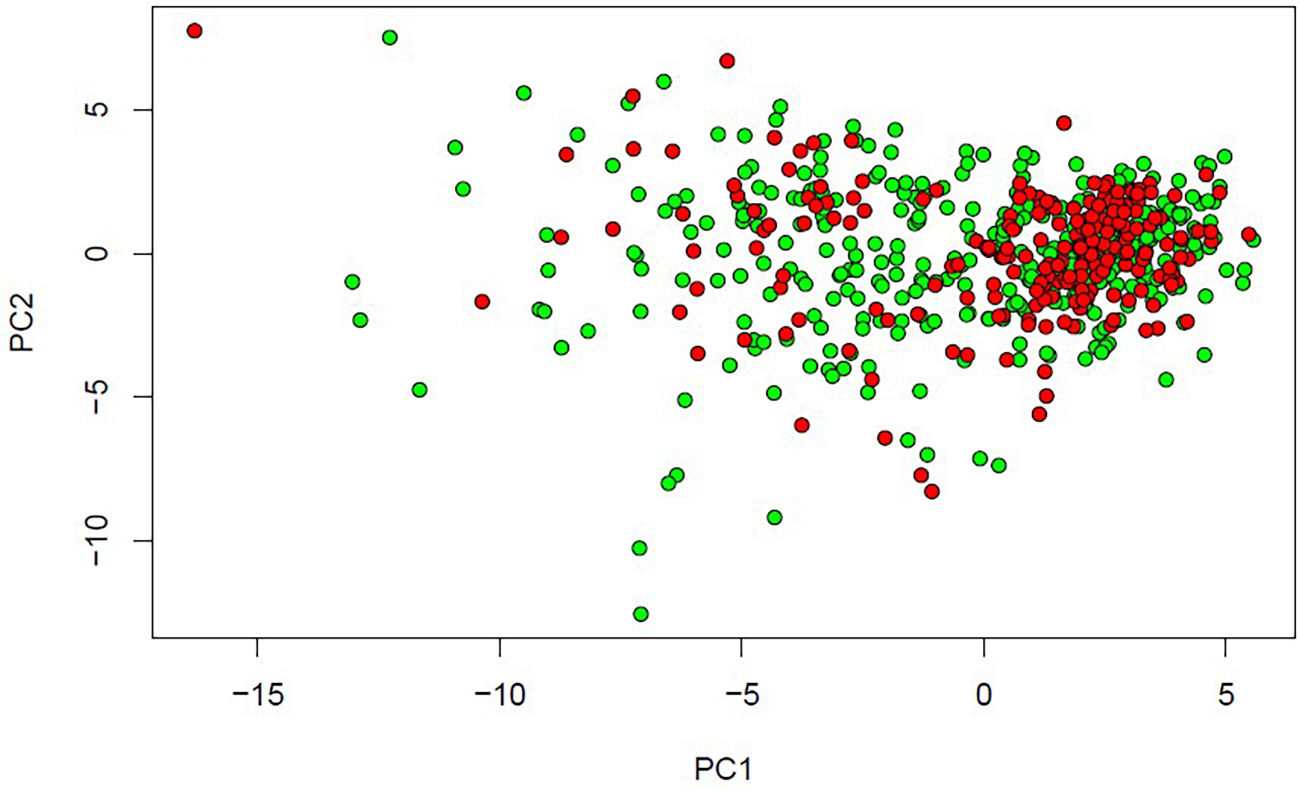
En el contexto actual de enfermedades basadas en el modelo etiofisiopatogénico caracterizadas por una enorme heterogeneidad, el unsupervised ML se perfila como un interesante instrumento para formalizar conjuntos de comportamiento más homogéneo14 (fig. 4).
![Unsupervised Learning. Se analiza la misma base de datos que en la figura 3 (Breast Cancer Wisconsin [Diagnostic] Data Set) con reducción de la dimensionalidad por PCA (principal component analysis). Considerando solo los 2 primeros componentes principales (que no son otra cosa que combinaciones lineales de las 30 variables consideradas en la base), que explican la mayor proporción de la variancia de los datos, la proporción de variancia acumulada es del 63,24%. Si consideráramos un espacio 6-dimensional con los 6 primeros componentes principales, la variancia acumulada alcanzaría el 88,76%. Con los 10 primeros componentes principales la variancia acumulada llega al 95,16%, lo que representa una reducción de la dimensionalidad a la tercera parte de la original.](https://static.elsevier.es/multimedia/02141582/0000003600000004/v3_202312261643/S0214158223000336/v3_202312261643/es/main.assets/gr4.jpeg?xkr=ue/ImdikoIMrsJoerZ+w997EogCnBdOOD93cPFbanNdpat93VGvFjbapQxS+SN8ApeAkqG3oJbY6SHkPxanGxPsRVDnYj9OOFbOBcbS2xXx540y9FDwpMg4r20Auq5xYIbDjIRF4DzifwWRDjaQ1Ydc6bWRyLzOu9eZzV7YzgzwIWowiUrrYL7ko3YTXj+ePmwXwSGTh3enICHZqbrCr0CjdS77H9NVNwu3Wo1smMkGQJNU6CEmSb179etiKdyXn3xHzjzbBrNvaaYpKGNkb6Fgjd1iJN+A4mDt9lwm5taM= "Unsupervised Learning. Se analiza la misma base de datos que en la figura 3 (Breast Cancer Wisconsin [Diagnostic] Data Set) con reducción de la dimensionalidad por PCA (principal component analysis). Considerando solo los 2 primeros componentes principales (que no son otra cosa que combinaciones lineales de las 30 variables consideradas en la base), que explican la mayor proporción de la variancia de los datos, la proporción de variancia acumulada es del 63,24%. Si consideráramos un espacio 6-dimensional con los 6 primeros componentes principales, la variancia acumulada alcanzaría el 88,76%. Con los 10 primeros componentes principales la variancia acumulada llega al 95,16%, lo que representa una reducción de la dimensionalidad a la tercera parte de la original.")
Unsupervised Learning. Se analiza la misma base de datos que en la figura 3 (Breast Cancer Wisconsin [Diagnostic] Data Set) con reducción de la dimensionalidad por PCA (principal component analysis). Considerando solo los 2 primeros componentes principales (que no son otra cosa que combinaciones lineales de las 30 variables consideradas en la base), que explican la mayor proporción de la variancia de los datos, la proporción de variancia acumulada es del 63,24%. Si consideráramos un espacio 6-dimensional con los 6 primeros componentes principales, la variancia acumulada alcanzaría el 88,76%. Con los 10 primeros componentes principales la variancia acumulada llega al 95,16%, lo que representa una reducción de la dimensionalidad a la tercera parte de la original.
Aunque es posible escribir un código para ML con prácticamente cualquier lenguaje de alto nivel, son 2 los que se han convertido en los preferidos de los usuarios por sus particularidades: R y Python. Ambos son lenguajes interpretados por software de libre distribución. R es más ligero y más adecuado para un análisis estadístico básico por tener gran cantidad de librerías ad hoc. Python es más pesado pero mucho más eficiente en términos de tiempo de computación, lo que lo hace preferible para la programación de algoritmos recursivos complejos.
En ambos casos hay plataformas de soporte en la red donde los usuarios cooperan altruistamente en la resolución de problemas particulares, supervisión de librerías y creación de otras nuevas (Stack Overflow, Rpubs…). Existen además sitios web que ofrecen bases de datos para su análisis, en ocasiones con importantes recompensas económicas para el usuario que consiga el modelo más preciso (Kaggle, DrivenData, Devpost, Innocentive CrowdAnalytix…).
Presente y futuro del ML en SenologíaYa en algunas áreas de la Senología el ML es una realidad. Así diversos proyectos trabajan en la interpretación de imágenes para la detección del cáncer de mama15,16 así como en el diagnóstico anatomopatológico donde destaca el proyecto C-Path17. Mención aparte merece el Sage Bionetworks-DREAM dirigido más específicamente al pronóstico14,18.
Sin embargo, son escasas todavía las iniciativas orientadas a la adquisición de conocimiento por medio de esta nueva metodología, especialmente en el ámbito de la toma de decisiones clínico-terapéuticas19–21. En este sentido se apuntan como líneas donde el ML va a tener un papel incuestionable: el screening del cáncer de mama, la detección de grupos de riesgo así como de mayor probabilidad de respuesta a un cierto esquema terapéutico y los estudios de supervivencia.
En este camino, que probablemente nos lleve a un cambio en el paradigma científico actualmente basado en el modelo agotado de la Medicina basada en la evidencia, se interponen importantes obstáculos, algunos de los cuales abordaremos a continuación:
- 1)
Un importante handicap es el desconocimiento del médico de este tipo de técnicas tan ajenas a la práctica médica cotidiana13.
- 2)
Nada desdeñable es el temor del hombre a verse reemplazado por la máquina, si bien en realidad solo supone un cambio de rol donde el médico pasará a ser quien determine las necesidades, seleccione las variables informativas, interprete los modelos y evalúe la eficiencia del sistema6,13.
- 3)
Necesidad de grandes paquetes de datos que obliga a procesos de homogeneización en la informatización y codificación de las historias clínicas, y universalización del acceso a las mismas, superando los problemas éticos y de protección de datos que esto conlleva. En esta dirección ya hay algunas iniciativas legales en el marco de la comunidad europea como por ejemplo es la European Union General Data Protection Regulation (GDPR 2016/679)), así como grupos de trabajo que intentan establecer un marco para el correcto empleo desde un punto de vista ético de la Inteligencia Artificial22.
- 4)
Se requiere una alta capacidad de computación, tanto mayor cuanto mayor es el volumen de datos y la complejidad de los modelos considerados.
- 5)
Oposición a la dinámica del ML donde prima la detección de asociaciones de variables sobre la búsqueda de relaciones causales dominante en la Medicina actual. En este sentido apunta el fenómeno conocido como black box6: los datos entran en la máquina, siguen un recorrido algorítmico-recursivo encriptado nada trasparente y resulta un modelo en ocasiones muy difícil de interpretar, desde la perspectiva del modelo etiofisiopatogénico de la enfermedad (¿aceptaríamos un modelo con una eficacia predictiva digamos del 99%, que determinara la respuesta a un quimioterápico en el que una de las características implicadas fuera, por ejemplo, el signo del zodiaco de la paciente?). El ML no ofrece causalidad sino más bien guías de actuación adaptadas al perfil de cada paciente (¿no es la causalidad una ficción?)23.
- 6)
Se requiere un notable esfuerzo de ingeniería de selección de variables para la construcción del modelo23, si bien las redes neuronales y el deep learning en gran medida han venido a soslayar esta cuestión a expensas de una mayor opacidad en el proceso. No obstante, siempre será necesario cierto conocimiento previo, cierta estructura y una hipótesis de partida (teorema del no free lunch de Wolper, es decir, no se puede obtener algo a partir de nada)24.
Por el contrario, las ventajas potenciales son evidentes:
- 1)
La posibilidad de estudiar grandes paquetes de datos emergentes de poblaciones más que de muestras pequeñas soslaya una práctica estadística en muchas ocasiones metodológicamente cuestionable y que ha conducido a lo que se conoce como crisis de replicación (resultados difícilmente replicables o reproducibles)25.
- 2)
El ML ofrece la posibilidad de conseguir decisiones clínico-terapéuticas personalizadas para cada paciente, en función del valor que toman en cada caso las variables informativas13 tan lejos de las guías clínicas actuales, basadas en enfoques epidemiológicos generales.
- 3)
Si bien el sesgo en la recogida de datos sigue presente (la calidad del análisis siempre dependerá de la calidad de los datos), el proceso está libre de sesgo en el análisis y en la detección de variables ocultas y combinaciones entre ellas, que insospechadamente pudieran determinar el resultado final que se pretende determinar.
- 4)
La capacidad de aprendizaje de la máquina puede conducir a modelos con eficiencia predictiva enormemente alta (tanto mayor conforme van entrando nuevos datos).
A la vista de todo lo expuesto parece obvio que todos los especialistas involucrados en el campo de la Senología estamos obligados a familiarizarnos con esta tecnología, para poder dirigirla apropiadamente sobre directrices sustentadas en el ars medendi y fomentar su uso democrático lejos de intereses comerciales6. El ser humano ya confía en los ordenadores para la ejecución de los complejos cálculos de cualquier obra de ingeniería civil, para mandar vehículos de exploración no tripulados a otros planetas, o para obtener imágenes en 3D y manipular el instrumental quirúrgico a distancia en la cirugía robótica. ¿Algún día seremos capaces de confiar en las máquinas para la toma de decisiones clínicas? No me cabe ninguna duda de que sí.
FinanciaciónEste artículo no ha recibido ningún tipo de financiación de agencias del sector público, del sector comercial ni de entidades sin ánimo de lucro.
Responsabilidades éticasPor la naturaleza del artículo no procede consideración ética alguna.
Conflicto de interesesEl autor es miembro del Comité Editorial y revisor por pares de la revista.

