









The rapid development of artificial intelligence (AI) has significantly transformed digital marketing enhancing its effectiveness and raising new ethical and privacy concerns. This study investigates the ethical implications of AI-based digital marketing, particularly focusing on user privacy. In terms of methodology, a systematic literature review (SLR) was conducted to identify relevant variables, followed by Multiple Correspondence Analysis (MCA) using R within the framework of homogeneity analysis of variance using alternating least squares (HOMALS). The MCA analysis identified 3 multivariate groupings, and 21 individual variables extracted from 28 studies. The MCA identified a total of 4 clusters in the eigenvalues/variances analysis, and 5 clusters in the biplot analysis. The findings emphasize the need for a balanced approach that respects user privacy and ethical use of data when developing actions using AI-based digital marketing. However, no significant relationship is evident between the study of variables such as cross-device tracking or data-driven technologies and, the ethics of AI-based digital marketing, despite these being the most profitable actions in this environment. There is no evidence of developing personalized social media content or ads linked to privacy standards. However, a strong connection between behavioral analytics, smart content and metaverse is identified, highlighting the risks of this emerging technology in this research field, as it is not linked to privacy or ethics. Among the results, the strong proximity of real-time tracking, IoT, and surveillance variables underscores the critical need to ethically understand how user behavior in real-time is being monitored, as they do not offer a strong link to privacy or ethics. Additionally, this study provides 21 future research questions that address whether these practices are being ethically implemented, following standards like “privacy-by-default” or “privacy-by-design,” and complying with privacy laws in AI-based digital marketing. To ensure these practices align with ethical standards, it is essential to adopt frameworks prioritizing data dignity, which calls for treating user data as an extension of personal identity, requiring responsible and ethical handling throughout the data collection and processing lifecycle.
The development of new technologies, particularly artificial intelligence (AI), has brought about substantial changes in business models worldwide over the past decade (Kanbach et al., 2024). Companies now use the Internet as the main foundation for strategic (Wamba-Taguimdje et al., 2020), management (Ganesh & Kalpana, 2022), and production development (Sohn & Kwon, 2020). In the face of this paradigm shift, communication and marketing strategies have become essential for companies to reach a global audience (Campbell et al., 2020; Davenport et al., 2020; Babatunde et al., 2024).
The advancement of AI has made digital marketing strategies increasingly effective. According to authors like Grandhi et al. (2021), effectiveness in digital marketing is understood as the positive profitability percentage of digital advertising goals as well as the impact on the correct audience. Also, thanks to the development of data-driven decisions and automations -driven by AI- both digital marketing and social networks have optimized their algorithms to make them even more effective (Saura, 2021).
In this context, there is no doubt that the development of AI, and specifically AI-based digital marketing, enhances business outcomes, increases Return of Investment (ROI), and drives success actions (Almestarihi et al., 2024). However, recent literature (Barth et al., 2022) suggests that these advancements may rise privacy concerns among users as new ethical challenges that could compromise individual's autonomy. Concerns not only arise from the rapid velocity at which this technology is evolving but also from the possible unethical use of user data (Saura, 2021). As such, the ethical implications of AI-based digital marketing practices demand careful scrutiny to ensure that user privacy is respected and protected ethically (Du & Xie, 2021).
Also, it is well known that, thanks to technologies such as machine learning, users who spend several hours weekly enjoying content on the Internet and through social networks are, without being aware, training the algorithms that track and optimize the content displayed on their digital screens (Brunborg & Andreas, 2019; Coyne et al., 2020). The objective of these activities is to promote and sell products or services or to increase engagement with the users themselves and to create personalized nudges. In an ecosystem that is increasingly automated and enables massive control over public opinion and the gathering of data from users, privacy and ethics have become fundamental concepts linked to the development of digital marketing actions in automated environments (Martin & Murphy, 2017; Cooper et al., 2023) despite the introduction of privacy regulations designed to mitigate consumer susceptibility (Goldberg et al., 2024).
In this context, authors like Du and Xie (2021) and Willems et al. (2023) discuss the existence of a privacy paradox, which is directly linked to the use of AI algorithms in digital marketing strategies and the ethical actions of both, advertisers and, the tools that digital platforms enable for the development of digital marketing. That is, AI-based digital marketing strategies are nurtured, optimized, and enhance their performance based on the collection and analysis of millions of user data points (Dwivedi et al., 2021). This data is collected from various sources and linked to categories such as demographics or geographics (factual), psychographics (attitudinal) or personality composed of psychology and persuasion (behavioral) and variables (Saura et al., 2021). These algorithms can collect data from many data points such as browsing history, mobile applications, search history, calls, messages, and enjoyed content, among many other sources (Dwivedi & Nath, 2020; Saura et al., 2022). Subsequently, once these data points linked to users have been structured, companies can filter and optimize their AI-based digital marketing campaigns automatically to identify market niches where the likelihood of purchase is very high. At this point, smart digital marketing targets users with products or services to encourage them to make a purchase persuasively (Livingstone et al., 2024).
In relation to this environment, three types of data points derived from online user interactions appear in the literature (Saura et al., 2021) as User-Generated Content (UGC), that refers to data that users intentionally create and share, the User-Generated Behavior (UGB), that involves data generated through users' online actions, together, these form User-Generated Data (UGD), encompassing all data from user interactions in digital environments. Both actively shared and passively collected, highlighting the complex interplay between user participation and privacy concerns in the digital age (Bélanger & Crossler, 2011). Using these data typologies, and collecting data points from various data sources, AI-based digital marketing is able to automate advertising actions and increase effectiveness to very high profitability percentages raising ethical concerns and motivating policy makers to find a solution for risk prevention (Nayyar, 2023).
As a result, the paradox is identified when it is analyzed that the more data companies collect from users, the greater the efficiency of digital ads and thus the profitability of campaigns in digital environments (Sharma et al., 2022). This has led to a situation where companies aggressively attempt to gather more and more user data, creating markets for buying and selling data and advertising campaigns focused exclusively on data collection (Lee & Cho, 2020). The paradox becomes clear when it is understood that users are demanding personalized, adapted and smart content linked to their personalities at the same time they are concerned about their privacy. Therefore, users should be aware that companies are trying to obtain their data to monetize it in their AI-based digital marketing campaigns; however, it has been shown that the use of connected devices or social networks, as well as Internet browsing, generates dopamine in user's brains -a chemical linked to addiction (Sherman et al., 2016; Bhargava & Velasquez, 2021)- that could boost digital ads profitability as it could increase the time that users are spending in front of digital platforms creating data-points to be collected. Therefore, on one hand, companies are encouraging users unconsciously, to generate more dopamine in their brains to become addicted to the use of these technologies (Aytac, 2024) to create data sources to train algorithms and improve ads profitability. On the other hand, the more hours these users spend connected, enjoying content and generating dopamine, the more data the companies will obtain using cross-devices algorithms and thus the greater the profitability of their actions. Where, then, does user privacy stand? Have AI-based digital marketing strategies ceased to be ethical? Are there mechanisms that can ensure that the intentions of AI-based digital marketing strategies respect user privacy? What about the automation strategies for massive data collection and the ethics of their possible behavior influence? What could be the remedy that solves the problem of “the more data about a user, the more profitable the AI-based digital marketing actions”?
In response to these questions, the present study aims to cover the gap in the literature related to how the new AI-based digital marketing paradigm intersects with privacy and ethics. Specifically, this research seeks to understand the connection between digital marketing strategies, AI, and user privacy to determine whether current approaches to AI-based digital marketing are ethical, given the complexities of the privacy paradox.
With this goal, the present study poses the following research question (RQ1): How do the primary uses of AI-based digital marketing align with ethical standards and respect for user privacy? To answer this research question, the following objectives are proposed:
- •
Identify different theoretical perspectives on AI-based digital marketing
- •
Explore the principles of ethics in AI-based digital marketing actions
- •
Generate knowledge about the main uses of AI-based digital marketing strategies
- •
Provide future guidelines on the use of AI-based digital marketing that respects privacy and the ethical use of user data
After a thorough, systematic literature review (SLR) to highlight significant contributions within the research area, the present study develops a Multiple Correspondence Analysis (MCA) (Le Roux & Rouanet, 2010; Moschidis et al., 2024) within the framework of homogeneity analysis of variance using alternating least squares (HOMALS) (De Leeuw & Mair, 2007). The methodology is computed using the programming language R. This method allows for the visual representation of data and the identification of significant correlations, culminating in distinct findings. It should be highlighted that the present study is original in its focus on the intersection of AI-based digital marketing, ethics, and user privacy, an emerging area that remains underexplored. It seeks to understand how these marketing practices align with ethical standards, filling a critical gap in the current literature. Employing an innovative MCA in R within the homogeneity analysis framework, this research introduces a novel approach not previously applied in this context, offering fresh insights and future guidelines.
The structure of this manuscript is as follows. First, the introduction and the theoretical framework are presented. Secondly, the research methodology, followed by the data analysis are developed. Thirdly, the discussion and future research questions are presented. The paper concludes by discussing the practical and theoretical implications of the findings.
Theoretical frameworkIn a globalized and automated context, automated decision-making is becoming a routine for companies (Rusthollkarhu et al., 2022). Today, more companies use tools daily that operate with AI or that can be connected to existing tools to enhance their intelligence (Bobrytskyy & Stříteský, 2024). Algorithms driven by the development of AI are helping businesses increase profitability, quality content, and optimize their digital campaigns using, for instance, generative AI (Dwivedi et al., 2023). However, automated decisions in digital environments have been the subject of previous studies (See Kuziemski & Misuraca, 2020; Santos et al., 2022).
In fact, initiatives such as the study of ethical design in social networks and digital environments are becoming relevant in the current literature (Saura et al., 2021a). This analytical perspective on ethics in digital environments discusses three fundamental variables. Firstly, it is necessary to analyze whether there are (i)advertising objectives aimed at pursuing users in digital environments. Secondly, it is necessary to examine whether there are (ii)growth objectives that attempt to interact with users in such a way that the existing relationship between the digital platform or digital marketing actions progressively increases over time, whether by generating dopamine or by prompting subscription or affiliation actions. Thirdly, (iii) engagement objectives. These objectives attempt, through any means, to increase the number of contacts a user has with such a strategy, platform, or connected device.
If these three objectives are present in a strategy developed by a company in digital environments, whether in digital marketing or in environments like social media or digital platforms, the unethical design stands (Literat & Brough, 2019). Therefore, a design that invades user privacy and, in the worst cases, after massive analysis and automation of decision-making by algorithms, can aggressively influence users' online behavior and their daily actions and habits (Zuboff, 2019). In response to this paradigm, there are already studies discussing surveillance capitalism (Zuboff, 2023) as a way to influence society's consideration and decision-making processes without their awareness, using AI-based digital marketing strategies as a means of action.
That is, with the massive use of connected devices or Internet of Things (IoT) that collect data and receive ads and AI-based digital marketing or social ads strategies, large multinational corporations or even governments can organize algorithms around the acquisition of personal user data and subsequently, in an unethical manner, use these data points during promotional or even electoral periods (Andrew & Baker, 2021) to train machine-learning algorithms. For example, Donald Trump's electoral campaign against Hillary Clinton used the algorithm developed by Cambridge Analytica to influence undecided voters; similar evidence may be found in the Brexit campaign (see Risso, 2018). Also, the European Commission initiative to boost the “Privacy by default” in IoT devices (Saura et al., 2021b) is highlighted. These advertising actions carried out on the Internet can be automated using AI, thereby aiming to influence users' considerations to achieve specific objectives involving questionable non ethical environments (Williamson, 2024).
Likewise, there are also studies highlighting the importance of identifying and educating users about the actions that companies can develop on the Internet (Sethi et al., 2020). That is, the foundations of robust privacy in terms of personal data and ethical factors (Elgesem, 2002). Although there are laws designed to protect users, improper practices on platforms such as social networks or digital platforms that engage in AI-based digital marketing can enable these companies to gather data without the users' full awareness. It should be understood that there are user data points that users publish consciously and data points that can be collected of which users are unaware. Indeed, these latter types of data are what can allow algorithms, through the automation of decision-making, to directly influence users' online behavior and, thereby, alter and modify their behavior (Shmueli & Tafti, 2023).
The privacy paradox in AI-based digital marketingAs previously indicated, there is evidence of a paradox in terms of business and behavioral actions linked to the development of AI-based digital marketing. It is well known that AI improves with data over time, and that this data is largely extracted from the actions and behaviors of users in digital environments (Mirsch et al., 2017). At the same time, users themselves are aware of their privacy, thanks to governments investing in educating new generations on how to handle their data publicly or via the Internet over the last decade (Williamson, 2017). However, as previously explained, it has been demonstrated that the use of social networks or connected devices generates dopamine, a chemical that creates addiction in the brain, similar to other industries that have much stricter regulation in terms of quantity, such as the alcoholic beverage, tobacco, or gambling industries (Aytac, 2024).
While it is true that there is regulation regarding the type of actions that companies can undertake in digital environments linked to data collection and the conscious privacy of users (Sun et al., 2024), it is also true that many more data points can be automatically collected, of which users are unaware as a result of their behaviors. For example, following a political party on a social network like X (former Twitter) allows an algorithm to understand that the user sympathizes with the ideas supported by that political party. Also, liking a photo on a social network signals to an algorithm that the user likes the products and services within that photograph. Then, the algorithm, through visual recognition (Liu et al., 2024) will identify the specific products of that photograph, allowing it to optimize social media advertising. Is this data processing ethical? Is the user aware that this action will be tracked and try to influence his/her behavior with commercial purposes when mixing with the currently collected data?
These types of data collection actions could invade privacy and may not be ethical, but in most cases, users are unaware that these actions are providing data to the algorithms that will subsequently show them digital advertising (Hacker, 2023). If companies with more data are more profitable, they will be interested in increasing the dopamine generated in users so that the profitability of their results is greater (Nosthoff & Maschewski, 2024). Considering this scenario, different cases arise that complete a privacy paradox in the absence of limits on the consumption of online products and services or digital marketing strategies.
Firstly, there is a discrepancy between the (i)concerns expressed by users versus the behaviors observed. Digital environment users often indicate in surveys (Baruh et al., 2017) and interviews (Paine et al., 2007; Schroeder et al., 2022; Barth et al., 2022) that they value privacy and are concerned about how companies use their data. However, in practice, these users accept privacy terms and conditions without paying much attention to them (Custers et al., 2014; Obar & Oeldorf-Hirsch, 2020) as they urgently want to start using the digital service (Rudolph et al., 2018).
It is in these policies that platforms detail their tracking of online activity and their sharing of this information with third parties for economic benefit or to offer personalized content tailored to each user (Acar et al., 2020). This leads to the second situation in the paradox, (ii) personalization versus privacy. As noted earlier, AI allows for the personalization of content in digital marketing, providing unique experiences and highly relevant ads linked to users' personalities and behaviors. Many users appreciate receiving such recommendations and content, but this requires a very thorough analysis of personal data related to the user. This fact can be perceived as an intrusion into that user's personal privacy (Han et al., 2023) and, therefore, not ethical, potentially even altering their behavior by understanding how their personality and emotions are shaped in digital environments (Mogaji et al., 2020; Walker & Milne, 2024).
The third situation concerns the (iii) omnipresent technology and connected devices. More connected devices -or IoT devices- are appearing, and the trend is expected to continue (Ratten, 2024). The introduction of AI to these devices enables AI-based digital marketing strategies to collect increasingly more data for use in advertising actions. While this can enhance user experiences through personalization and intelligent content, it also exponentially increases the options for collecting personal data without explicit and conscious user consent, i.e., increasing the collection of data points from user behaviors that are not directly authorized (Zhang et al., 2023).
The fourth situation relates to (iv) transparency in data management and consent. As previously noted, there are regulations such as the General Data Protection Regulation (GDPR) published and approved by the European Commission that aims to regulate data handling and collection transparently (Voigt & Von dem Bussche, 2017). However, numerous studies show that users are not informed about their rights or do not understand how companies can use AI to analyze their data (Kawaf et al., 2024). The final consequence is a mismatch between the consumer's perception of how their data is used and how it is actually treated. With databases containing millions of data points, it is very difficult for both users and regulatory institutions to be sure that AI algorithms have not used a database to improve their automated decisions, which will be used in AI-based digital marketing campaigns or content management on social networks, digital platforms, the Metaverse or any other Internet-based system.
This research has presented these four situations that define a privacy paradox with AI-based digital marketing, and following this, articles that discuss this situation are evidenced (see Table 1). Although some of them do not define it as a paradox, they all highlight and value the need for study in each of these areas that are presented as the new privacy paradox of AI-based digital marketing.
A new privacy paradox in AI-based digital marketing.
| Enterprises | Authors | Users | Authors | |
|---|---|---|---|---|
| Concerns expressed by users versus the behaviors observed |
| Almestarihi et al. (2024)Kröger et al. (2022)Grandhi et al. (2021)Fatima et al. (2019)Bonneau and Preibusch (2010) |
| Goldberg et al. (2024)Behera et al. (2022)Boerman et al. (2021)Barth et al. (2019) |
| Personalization versus privacy |
| Babatunde et al. (2024)Kyi et al. (2024)Mogaji et al. (2020)Walrave et al. (2018) |
| Yang (2024)Saura (2021)Nair and Gupta (2021)Preibusch (2010)Milne (2000) |
| Omnipresent technology and connected devices |
| Van Esch and Stewart Black (2021)Bandara et al. (2020)Choi et al. (2018) |
| Barbosa et al. (2022)Hoyer et al. (2020)Merhi et al. (2019) |
| Transparency in data management and consent |
| Cheah et al. (2022)Saura et al. (2021c)Van Ooijen and Vrabec (2019) |
| Quach et al. (2022)Schomakers et al. (2019)Chang et al. (2018)Sarathy and Robertson (2003) |
Source: the authors.
This research develops two methodological approaches aimed at addressing the proposed objectives. Firstly, an SLR is conducted to identify the main variables related to AI-based digital marketing and ethics, as well as the concepts linked to the privacy paradox. Once the SLR has been completed, a methodology known as MCA is applied within the framework of HOMALS. Through the development of this methodology, visual clusters composed of variables are identified to elucidate the relationships among the analyzed concepts.
Systematic literature reviewRegarding the development of the SLR, a review focused on the analysis of academic databases directly related to the research objectives has been conducted, including Web of Sciences (WoS), ScienceDirect, IEEE Xplore, ACM Digital Library, and AIS Electronic Library. It should be noted that SLRs are characterized by the search for theoretical answers to the authors' research questions. Therefore, prior to conducting an SLR, as noted by Calderon-Monge and Ribeiro-Soriano (2024), theorizing and highlighting the main contributions and contexts linked to the industry or research field on which the review is intended should be emphasized. Thus, once the problems are formulated and explained, they should be linked to a research gap that can theoretically be associated with the results of the SLR. Additionally, authors such as Collins et al. (2021) emphasize that one of the main considerations related to the SLR should be its connection to an emerging and relevant research theme, thus adding significance to the method itself, as SLRs are effective methodologies, particularly when studying a novel or emerging topic. As previously mentioned, this is the case with the present study on AI-based digital marketing and ethics as an emerging theme.
To structure the development of the SLR, the following framework has been proposed. Firstly, the main contributions supporting or analyzing the proposed research problems are analyzed. The primary uses of AI-based digital marketing in the current literature are identified, as well as the role of ethics in the analyzed actions, linking these variables to a privacy perspective. Secondly, studies relevant to the subject matter are analyzed. In this part, the importance of using databases directly linked to the specialization and areas of study is vital. Hence, as previously indicated, the following databases are proposed: WoS, ScienceDirect, IEEE Xplore, ACM Digital Library, and AIS Electronic Library. To identify these contributions, the following terms were used in the databases: “Digital marketing” AND “artificial intelligence” AND “privacy”. Once AI-based digital marketing is linked with privacy, the study aims to analyze and discuss whether such actions could be directly associated with ethical principles or not. Furthermore, in cases where the overall results did not coincide with the established criteria, similar queries such as “online marketing” OR “AI digital marketing” OR “interactive marketing” OR “smart marketing” were utilized.
The queries were conducted between April 2nd and 5th, 2024. In order to ensure a comprehensive and focused SLR, the selection of keywords was carefully crafted to capture the core elements of the present study. The terms “digital marketing”, “artificial intelligence” and “privacy” were chosen as they directly address the study's main concerns (how AI-driven digital marketing intersects with privacy issues and ethical considerations). The search included variations such as “online marketing”, “AI digital marketing”, “interactive marketing” and “smart marketing” to broaden the scope and capture the diverse terminology present in this evolving field. This method identifies relevant literature that may not directly use the primary keywords but still offers insights into AI-based digital marketing practices within an ethical and privacy context. The careful selection and application of these terms across chosen databases deepen the SLR, ensuring that a wide range of perspectives is considered (Kitchenham et al., 2009).
Also, the title, abstract, and keywords were used as the main sections to include articles in the final sample before their in-depth analysis. In the review section, the selected contributions are analyzed in-depth with the aim of linking their development and theorization to the second part of the previously presented two-step methodological framework (Iden & Eikebrokk, 2013).
Multiple correspondence analysis (MCA) and homogeneity analysis of variance by means of alternating least squares (HOLMAS) approach developed in RIn order to develop the second part of the proposed methodology, this study employs MCA (Le Roux & Rouanet, 2010). These analyses are linked to the theoretical framework known as HOMALS (De Leeuw & Mair, 2007; Barbosa et al., 2022) which is a procedure that constructs visual matrices with clusters and dependent and independent variables and can be used to identify and analyze connections among multiple variables. Thus, the dimensional maps represent keywords around the two axes, depicting the position of clusters and potential associations between them. The development of MCA theoretically justifies the exploratory statistical analysis of the descriptors identified in the dimensional map (Moschidis et al., 2024). This allows for the joint association of relevant exposures from the analyzed articles in the form of clusters and variables, and the linking between them. If variables or descriptors that are not linked together are identified, they will not appear or form clusters. Thus, through exploratory analysis and based on descriptive statistics, research questions, and proposed objectives can be addressed.
For the implementation and computation of MCA in R, categorical variables are identified and encoded as a result of content analysis of the articles included in the SLR. These categorical variables are structured into groups of words, which in turn form multivariable categories. In total, this study proposes three categorical variables: digital marketing, AI, and privacy. On these variables, a total of 21 individual variables have been identified as key in the SLR analysis. These individual variables are grouped into clusters around the categorical variables. The first categorical variable, “DigitalMarketing” defines the perspective of the analyzed studies in direct relation to the research objectives with a focus on digital marketing. The second variable, “ArtificialIntelligence” similarly defines the studies but with a focus on the use of this technology in digital marketing. The third variable, “Privacy” defines a perspective centered on the analysis of privacy within this research domain. Studies may focus on all or several of the categorical variables.
The individual variables are as follows: “Ethics” determines the study of actions directly or indirectly linked to ethics in the application of AI-based digital marketing; “PersonalizedAds” represents the study and analysis of actions used in AI-based digital marketing to intelligently personalize advertisements; “SocialAds” represents the same as the “PersonalizedAds” variable but focuses on ads and publicity in social networks, as it is also part of digital marketing strategies; “Targeting” represents the intelligent analysis through algorithms or AI strategies to improve the precision of AI-based digital marketing strategies; “BehavioralAnalytics” contemplates the perspective of user behavior and its potential influence through AI-based digital marketing; “BigData” involves the use of large amounts of data in AI-based digital marketing strategies; “SocialMediaPlatforms” represents the development of these techniques within social media platforms like X, Facebook, or Instagram, among others; “Cross-DeviceTracking” highlights the development of this technology capable of personalizing advertisements across different devices; “RealTime” focuses on the analysis and application of real-time AI-based digital marketing strategies as well as data collection and transfer; “SecurityRisk” evaluates potential security risks associated with the use of automation and AI in digital marketing; “DataRisk” considers the risks related to the handling and storage of large amounts of data; “PersonalData” analyzes the management and protection of personal data in the context of AI-based digital marketing; “Surveillance” examines the implications of surveillance and monitoring in AI-based digital marketing campaigns driven by both companies and governments; “DataDrivenTech” explores new data-driven technologies propelled by AI-based digital marketing; “IoT” studies the integration of IoT and the massive collection of data with connected devices; “UserEngagement” focuses on AI tactics to increase user engagement in digital marketing campaigns; “RegulationLaw” addresses the laws and regulations affecting the use of AI in digital marketing; “SmartContent” investigates the creation of AI-adapted smart content; “Cookies” analyzes the study of cookies in tracking and personalization; “Metaverse” explores the impact and opportunities of the metaverse in AI-based digital marketing; “FakeContent” studies the generation and detection of false content such as fake news or deep fakes, among others.
Accordingly, the articles have been coded by the authors following a protocol established in studies utilizing samples from RSL and intended to be computed with machine learning or Natural Language Processing (NLP) algorithms (Kolla, 2016; Shao et al., 2022). Thus, a “1″ is added if the variable is analyzed in the study, or a “0″ if the variable is not identified in the development of the study. These coding provide a result regarding the distance between the variables, providing dimensions of linkage between said variables. In this manner, with the final database coded with a total of 24 variables (3 categorical and 21 individual), the MCA study is computed in R.
As a result of computing the MCA analysis in R, the statistical variables related to chi-square, p-value, variance, percentage of variance, and cumulative percentage of variance are defined. In this context, the chi-square test is a statistical method utilized to assess whether a significant difference exists between an expected distribution and an observed distribution. In the presented approach, the variance, is defined as the squared deviation from the mean, quantifies the dispersion of data points around the mean or median value. The percentage of variance and cumulative percentage of variance reflect the proportionate contribution and cumulative contribution of input parameters within the dataset, respectively. Additionally, the p-value represents the probability that, under the null hypothesis, the observed results or more extreme outcomes would occur by chance. In HOMALS analysis, the p-value is employed to evaluate the accuracy of the representation of the study's variables.
Finally, it should be noted that the closer variables are to the center of a category, the stronger their linkage. Therefore, within the X and Y axes of the graphical representation, if the results of group or individual variables are within the same space of the dimension, it signifies their linkage. The closer variables are to each other, the stronger their linkage. Similarly, the distance of a variable from the origin reflects the mean variance as a trend of the response from the analysis of the rest of the variables. This variant corresponds to the most frequent categories that are analyzed. Therefore, the keywords appearing in the graphs and possessing multiple characteristics belong to those categories that are more frequent. Consequently, keywords or indicators that are farther from the origin are less frequent in the database.
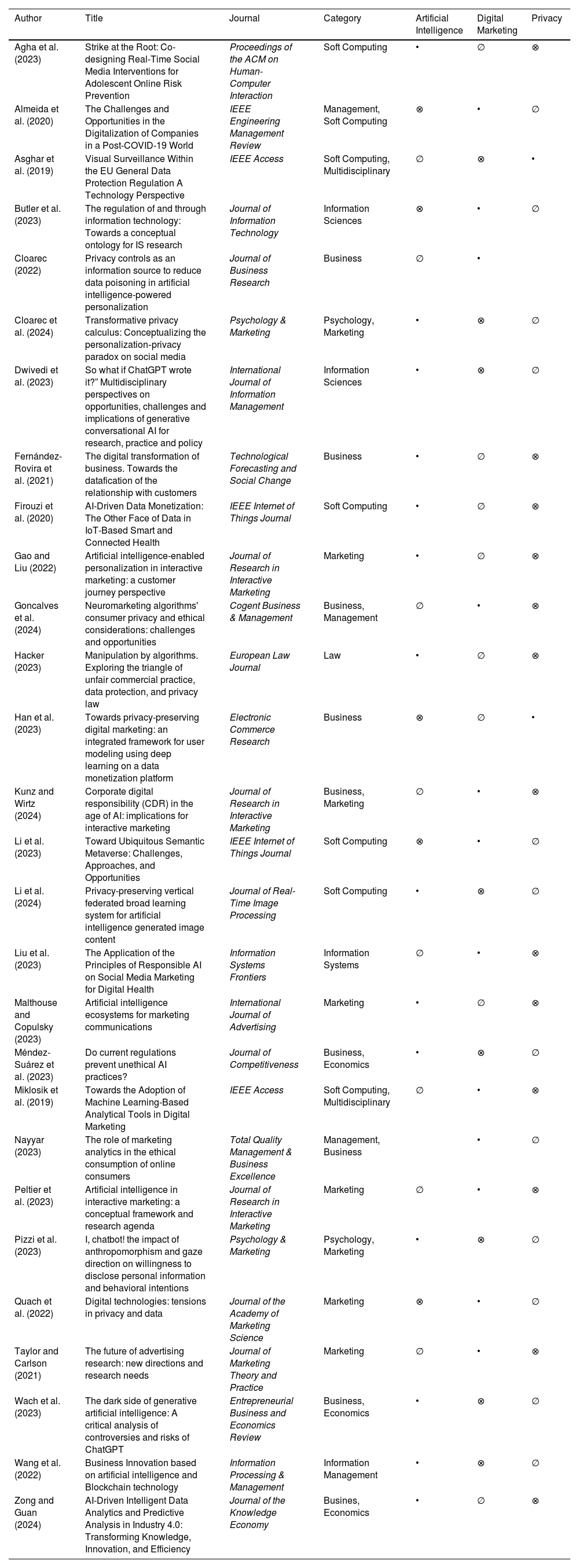
ResultsAs indicated before, specialized databases were utilized for the development of the SLR. Consequently, the results were as follows: From WoS, a total of 93 articles were identified, of which 22 were selected for the study sample. From ScienceDirect, 3 articles were identified, all of which were included in the study sample. From IEEE Xplore, 5 articles were obtained, of which 3 were selected. No results directly related to the objectives of this research were found in the ACM Digital Library and AIS Electronic Library databases. Out of the total of 101 articles, 28 were included as the sample for the present investigation. Consequently, Table 2 presents the individual studies categorized by author, title, journal, and research category.
Systematic literature review results.
| Author | Title | Journal | Category | Artificial Intelligence | Digital Marketing | Privacy |
|---|---|---|---|---|---|---|
| Agha et al. (2023) | Strike at the Root: Co-designing Real-Time Social Media Interventions for Adolescent Online Risk Prevention | Proceedings of the ACM on Human-Computer Interaction | Soft Computing | • | ∅ | ⊗ |
| Almeida et al. (2020) | The Challenges and Opportunities in the Digitalization of Companies in a Post-COVID-19 World | IEEE Engineering Management Review | Management, Soft Computing | ⊗ | • | ∅ |
| Asghar et al. (2019) | Visual Surveillance Within the EU General Data Protection Regulation A Technology Perspective | IEEE Access | Soft Computing, Multidisciplinary | ∅ | ⊗ | • |
| Butler et al. (2023) | The regulation of and through information technology: Towards a conceptual ontology for IS research | Journal of Information Technology | Information Sciences | ⊗ | • | ∅ |
| Cloarec (2022) | Privacy controls as an information source to reduce data poisoning in artificial intelligence-powered personalization | Journal of Business Research | Business | ∅ | • | |
| Cloarec et al. (2024) | Transformative privacy calculus: Conceptualizing the personalization‐privacy paradox on social media | Psychology & Marketing | Psychology, Marketing | • | ⊗ | ∅ |
| Dwivedi et al. (2023) | So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy | International Journal of Information Management | Information Sciences | • | ⊗ | ∅ |
| Fernández-Rovira et al. (2021) | The digital transformation of business. Towards the datafication of the relationship with customers | Technological Forecasting and Social Change | Business | • | ∅ | ⊗ |
| Firouzi et al. (2020) | AI-Driven Data Monetization: The Other Face of Data in IoT-Based Smart and Connected Health | IEEE Internet of Things Journal | Soft Computing | • | ∅ | ⊗ |
| Gao and Liu (2022) | Artificial intelligence-enabled personalization in interactive marketing: a customer journey perspective | Journal of Research in Interactive Marketing | Marketing | • | ∅ | ⊗ |
| Goncalves et al. (2024) | Neuromarketing algorithms' consumer privacy and ethical considerations: challenges and opportunities | Cogent Business & Management | Business, Management | ∅ | • | ⊗ |
| Hacker (2023) | Manipulation by algorithms. Exploring the triangle of unfair commercial practice, data protection, and privacy law | European Law Journal | Law | • | ∅ | ⊗ |
| Han et al. (2023) | Towards privacy-preserving digital marketing: an integrated framework for user modeling using deep learning on a data monetization platform | Electronic Commerce Research | Business | ⊗ | ∅ | • |
| Kunz and Wirtz (2024) | Corporate digital responsibility (CDR) in the age of AI: implications for interactive marketing | Journal of Research in Interactive Marketing | Business, Marketing | ∅ | • | ⊗ |
| Li et al. (2023) | Toward Ubiquitous Semantic Metaverse: Challenges, Approaches, and Opportunities | IEEE Internet of Things Journal | Soft Computing | ⊗ | • | ∅ |
| Li et al. (2024) | Privacy-preserving vertical federated broad learning system for artificial intelligence generated image content | Journal of Real-Time Image Processing | Soft Computing | • | ⊗ | ∅ |
| Liu et al. (2023) | The Application of the Principles of Responsible AI on Social Media Marketing for Digital Health | Information Systems Frontiers | Information Systems | ∅ | • | ⊗ |
| Malthouse and Copulsky (2023) | Artificial intelligence ecosystems for marketing communications | International Journal of Advertising | Marketing | • | ∅ | ⊗ |
| Méndez-Suárez et al. (2023) | Do current regulations prevent unethical AI practices? | Journal of Competitiveness | Business, Economics | • | ⊗ | ∅ |
| Miklosik et al. (2019) | Towards the Adoption of Machine Learning-Based Analytical Tools in Digital Marketing | IEEE Access | Soft Computing, Multidisciplinary | ∅ | • | ⊗ |
| Nayyar (2023) | The role of marketing analytics in the ethical consumption of online consumers | Total Quality Management & Business Excellence | Management, Business | • | ∅ | |
| Peltier et al. (2023) | Artificial intelligence in interactive marketing: a conceptual framework and research agenda | Journal of Research in Interactive Marketing | Marketing | ∅ | • | ⊗ |
| Pizzi et al. (2023) | I, chatbot! the impact of anthropomorphism and gaze direction on willingness to disclose personal information and behavioral intentions | Psychology & Marketing | Psychology, Marketing | • | ⊗ | ∅ |
| Quach et al. (2022) | Digital technologies: tensions in privacy and data | Journal of the Academy of Marketing Science | Marketing | ⊗ | • | ∅ |
| Taylor and Carlson (2021) | The future of advertising research: new directions and research needs | Journal of Marketing Theory and Practice | Marketing | ∅ | • | ⊗ |
| Wach et al. (2023) | The dark side of generative artificial intelligence: A critical analysis of controversies and risks of ChatGPT | Entrepreneurial Business and Economics Review | Business, Economics | • | ⊗ | ∅ |
| Wang et al. (2022) | Business Innovation based on artificial intelligence and Blockchain technology | Information Processing & Management | Information Management | • | ⊗ | ∅ |
| Zong and Guan (2024) | AI-Driven Intelligent Data Analytics and Predictive Analysis in Industry 4.0: Transforming Knowledge, Innovation, and Efficiency | Journal of the Knowledge Economy | Busines, Economics | • | ∅ | ⊗ |
• = Main focus ∅ = Secondary focus ⊗ = Third focus.
Source: The authors.
In terms of the inclusion criteria for the research, the guidelines proposed by PRISMA were followed. Accordingly, inappropriate terms for inclusion as well as those not congruent with the research objectives were identified within the main fields such as title, abstract, and keywords. This filtering aids in determining the content direction of articles that can be included in the SLR. Thus, a total of 95 out of 101 articles were deemed suitable for inclusion in the study. Subsequently, with the aim of excluding articles based on their presented content, research objectives not directly or indirectly aligned with the theme posed in the current study were identified. Likewise, terms and descriptions falling outside the research topic were identified. Here, a total of 54 articles were excluded.
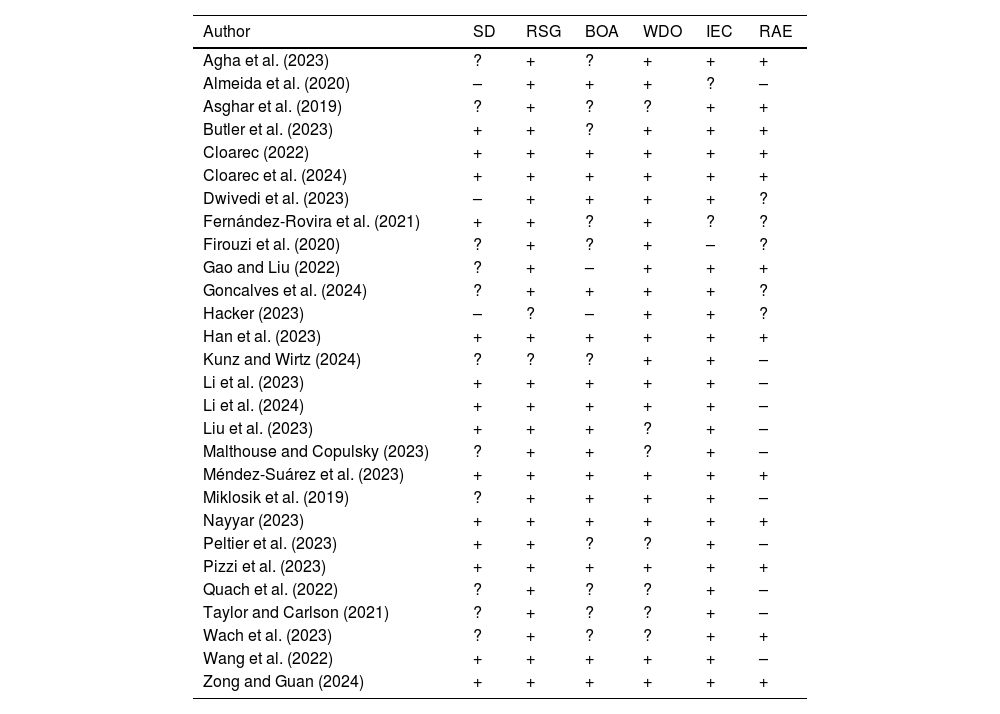
Lastly, in order to include in the study those articles deemed to have better quality assessments, a risk bias assessment (RBA) of the included studies was conducted. Out of the total of 41 articles, 13 were eliminated reaching out the final sample of 28 articles. The results of the RBA can be consulted in Table 3.
Risk bias assessment (RBS) of the studies included in the SLR.
| Author | SD | RSG | BOA | WDO | IEC | RAE |
|---|---|---|---|---|---|---|
| Agha et al. (2023) | ? | + | ? | + | + | + |
| Almeida et al. (2020) | – | + | + | + | ? | – |
| Asghar et al. (2019) | ? | + | ? | ? | + | + |
| Butler et al. (2023) | + | + | ? | + | + | + |
| Cloarec (2022) | + | + | + | + | + | + |
| Cloarec et al. (2024) | + | + | + | + | + | + |
| Dwivedi et al. (2023) | – | + | + | + | + | ? |
| Fernández-Rovira et al. (2021) | + | + | ? | + | ? | ? |
| Firouzi et al. (2020) | ? | + | ? | + | – | ? |
| Gao and Liu (2022) | ? | + | – | + | + | + |
| Goncalves et al. (2024) | ? | + | + | + | + | ? |
| Hacker (2023) | – | ? | – | + | + | ? |
| Han et al. (2023) | + | + | + | + | + | + |
| Kunz and Wirtz (2024) | ? | ? | ? | + | + | – |
| Li et al. (2023) | + | + | + | + | + | – |
| Li et al. (2024) | + | + | + | + | + | – |
| Liu et al. (2023) | + | + | + | ? | + | – |
| Malthouse and Copulsky (2023) | ? | + | + | ? | + | – |
| Méndez-Suárez et al. (2023) | + | + | + | + | + | + |
| Miklosik et al. (2019) | ? | + | + | + | + | – |
| Nayyar (2023) | + | + | + | + | + | + |
| Peltier et al. (2023) | + | + | ? | ? | + | – |
| Pizzi et al. (2023) | + | + | + | + | + | + |
| Quach et al. (2022) | ? | + | ? | ? | + | – |
| Taylor and Carlson (2021) | ? | + | ? | ? | + | – |
| Wach et al. (2023) | ? | + | ? | ? | + | + |
| Wang et al. (2022) | + | + | + | + | + | – |
| Zong and Guan (2024) | + | + | + | + | + | + |
Yes= + No = - Doubtful =?.
Source: The authors.
The RBA is composed of the following variables that determine the quality of the study being evaluated and included in the results of the RSL. Study design (SD) evaluates the overall quality of the study design and its academic coherence, random sequence generation (RSG) refers to unbiased sampling safety and the elimination of systematic patterns or biases that may influence the results; blinding of outcome assessment (BOA) involves the use of any technique or methodological development to minimize bias in the evaluation of study outcomes; withdraw and drop out (WDO) takes into account possible methods for identifying concerns regarding high rates of withdrawal and dropout that could lead to incomplete data; inclusion-exclusion criteria (IEC) for the use of variables or indicators involved in the study and proper justification, and reporting adverse events (RAE), if limitations encountered in the research development are accurately detailed.
Multiple correspondence analysis resultsAs previously indicated, this study develops an MCA in R supported by the HOMALS theoretical framework. Other authors such as Kamalja and Khangar (2017) proposed the development of this method to construct data matrices from data analysis that could be extracted from various kind of sources. This approach can also be implemented using software like SPSS. However, the increasing adoption and usage of new languages such as R or Python in research (Hill et al., 2024) make them the choice for this study, particularly due to the emerging use of capabilities related to machine learning. Regarding HOMALS, it supports conducting research in a dimensional map where keywords are visualized along two positional axes to measure the distance and relationships between these keywords (De Leeuw & Mair, 2007).
Therefore, this theoretical framework justifies the development of descriptive statistical analysis based on variables or descriptors appearing in a graphical map, identifying associations between variables. Hence, the greater the distance between these keywords, the higher the likelihood of no linkage between them. Authors such as Franco and Esteves (2020) highlight the potential for identifying research opportunities through clustering and grouping variables around a theme. These clusters identify thematic groupings that can be explained based on the theory surrounding a subject. Thus, in MCA, categorical variables suggesting a common theme among other variables can be proposed, determining the perspective of analysis.
It should be noted that the variables used are structured around groups of words that in turn form multivariate groupings of categories (Saura et al., 2021b). This study consists of 3 multivariate groupings and 21 individual variables. Likewise, each of the 28 studies identified in the RSL takes the form of individual indicators forming a total of 21 individual variables and 3 multivariate groupings for MCA analysis. Specifically, the 3 multivariate groupings are named as dimensions in the graph representing the model in R (Digital Marketing, Artificial Intelligence, and Privacy). The remaining individual variables have been presented in the methodology section under the MCA subsection.
Next, once the study is computed based on these characteristics, the statistical descriptive variables mentioned earlier are calculated to define the development of MCA. In this sense, the average chi-square value of independence between the two variables equals 386.2111. The calculation of p-value equals 1. This result, as indicated by Saura et al. (2021b), means that if the chi-square result exceeds the critical value calculated from row 1, column 1° and p = 1, then the row and column variables are not independent but associated with each other, as in the present study. Regarding the eigenvalue indicators corresponding to variance, percentage of variance, and cumulative percentage of variance, they are presented in Table 4. Additionally, Annex 1 (Supplementary material) provides details on the variables and dimensions represented in Figs. 1-4.
Eigenvalues dimensions 1 to 24.
| Dim.1 | Dim.2 | Dim.3 | Dim.4 | Dim.5 | Dim.6 | Dim.7 | Dim.8 | Dim.9 | Dim.10 | Dim.11 | Dim.12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1 | 1.153 | 6.952 | 5.479 | 4.838 | 3.302 | 3.077 | 2.319 | 2.134 | 2.058 | 1.735 | 1.240 | 1.172 |
| R2 | 22.946 | 13.825 | 10.895 | 9.621 | 6.567 | 6.119 | 4.61 | 4.244 | 4.093 | 3.451 | 2.467 | 2.331 |
| R3 | 22.946 | 36.771 | 47.667 | 57.288 | 63.856 | 69.975 | 74.589 | 78.834 | 82.927 | 86.379 | 88.846 | 91.177 |
| Dim.13 | Dim.14 | Dim.15 | Dim.16 | Dim.17 | Dim.18 | Dim.19 | Dim.20 | Dim.21 | Dim.22 | Dim.23 | Dim.24 | |
| R1 | 1.035 | 7.943 | 6.79 | 5.156 | 4.667 | 3.653 | 2.547 | 1.559 | 7.526 | 6.05 | 3.13 | 1.717 |
| R2 | 2.059 | 1.579 | 1.350 | 1.025 | 0.928 | 0.726 | 0.506 | 0.310 | 0.149 | 0.120 | 0.062 | 0.003 |
| R3 | 93.237 | 94.817 | 96.167 | 97.192 | 98.121 | 98.847 | 99.354 | 99.664 | 99.813 | 99.934 | 99.996 | 100.000 |
R1 =Variance, R2 =percentage of variance, R3 =cumulative percentage of variance.

It should be noted that words and clusters appearing close to each other in terms of distance in Figs. 1-4 imply that they are related and influence each other in categorical and thematic terms. Figs. 1 and 2 present the eigenvalues/variances. This analysis is useful for examining and exploring the relationships between categories of multiple categorical variables. The eigenvalues represent the amount of variance each dimension extracts from the data. A high eigenvalue indicates that the dimension significantly explains differences in the data. As for the dimension percentages, they represent the proportion of variance explained by each principal dimension or axis observed between variable categories. In Fig. 1, Dimension 1 on the X-axis represents 22.9 % of the variance, and Dimension 2 on the Y-axis represents 13.8 % of the variance. Additionally, eigenvalues and variances calculations have been computed along with the Biplot calculations (See Fig. 3-4).



In Fig. 1, cos2 is a measure indicating the quality of representation of variables in each dimension of the analysis. A cos2 close to 1 suggests that the analyzed dimension robustly represents the variable or category, while a low cos2 indicates otherwise. The color range represents the strength of cos2, and the distance between variables is shown on the X-axis with a maximum value of 1.2 points and on the Y-axis with a value of 0.8 points. Additionally, Fig. 2 shows the contributions of Row Points, indicating how much each row point (variable categories) contributes to forming each dimension or axis of MCA. This concept is relevant for understanding the influence of each variable within a cluster and the dimensions identified during analysis. Clusters have been drawn once researchers understood the relationships between the analyzed variables. However, the average distance between variables and clusters is low, highlighting their influence and strength as represented by cos2 values.
For example, although Cluster 1 (C1) shows a relatively low average cos2, some included variables exhibit high distances, forming a cluster with varying robustness in terms of cos2. Cluster 3 (C3), for instance, shows the highest relevance in terms of cos2. Fig. 1 identifies four clusters: Cluster 1 (C1) includes variables such as “DigitalMarketing”, “ArtificialIntelligence”, “Privacy”, “Ethics”, “Cookies”, “FakeContent”, “SmartContent”, “BigData”, “BehavioralAnalytics”, and “Metaverse”. Cluster 2 (C2) is represented by variables like “Surveillance”, “RealTime”, “Ethics”, “PersonalData”, “Artificial Intelligence”, “Behavioral Analytics”, and “Privacy”. Cluster 3 (C3) includes variables like “Social Ads”, “PersonalizedAds”, “Targeting”, “Social Media Platforms”, “UserEngagement”, and “Personal Data”. Lastly, Cluster 4 (C4) consists of variables such as “DataRisk”, “Cross-DeviceTracking”, “Data-driven technology”, “IoT”, and “Security Risk”.
It should be emphasized that regardless of the cos2 score of each variable, this study considers all variables forming a cluster, even if their scores differ (Moschidis et al., 2022). That is to say, for cluster analysis, both the relationship between variables and their influence in terms of cos2 in forming the cluster are taken into account. Furthermore, the results of the MCA are analyzed based on the research objectives, linking the existing relationships between digital marketing, AI, and privacy. The Biplot (See Fig. 3) visually represents both the rows (categories) and columns (variables) in a single graph. Unlike the contributions of row points graph (Figs. 1 and 2), which focus on quantifying and highlighting the relative importance of each category in forming the MCA dimensions, typically in a tabular or list format, the Biplot provides an integrated graphical view showing both categories and variables along with their interrelationships (Kassambara, 2017). Thus, Fig. 3 shows an overall visual perspective where relationships and patterns can be interpreted.
In the previous Fig. 1, both row points (variable categories) and column points (variables themselves) are represented as points in a two-dimensional space, allowing for the visualization of variable categories. Biplots also include vectors that represent the variables. However, in Fig. 3, short vectors appear indicating how variables contribute to dimensions and clusters and how they are related to each other. This allows for simultaneous visualization of the proximity between categories and their association with variables related to the clusters. Also, in Fig. 4, variables are represented as vectors pointing in the direction of maximum variance, explaining how individual variables relate to the dimensions of the multivariate analysis. Longer arrows indicate contribution of the variable to that dimension or axis of the Biplot. Therefore, this aspect of the Biplot allows for visualizing both the structure of the variables and their relationship to the principal dimensions of the analysis. It should be noted that the categorical variables of “DigitalMarketing”, “ArtificialIntelligence”, and “Privacy” under study are located near the center of the X and Y axes. Therefore, those variables farther from these axes are less relevant in terms of influence on the study subject (For example, “SecurityRisk” and “DataRisk”).
When defining the quality of visual representations, there are minor differences between the Biplot graph and the eigenvalues/variance graph. For instance, in the Biplot graph, the variable “Metaverse” is included in C4, whereas in the eigenvalues/variance graph, this variable is linked to C1. Similarly, the variable “Data-DrivenTechnology” is included in C5 in the Biplot graph, while in the eigenvalues/variance graph, it is included in C4. These two variables are situated between two interrelated topics: those represented in C4, which focuses on data security and risk among devices when data-driven technologies are used, and the main cluster of the study, which links the principal topics related to “DigitalMarketing”, “ArtificialIntelligence”, and “Privacy” variables.
DiscussionAfter the development of the study, the identification of four clusters through MCA in Fig. 1 provides a profound understanding of the relationships between key variables in the context of AI-based digital marketing and its ethical and privacy implications. Thus, C1 involves the inclusion of variables such as “DigitalMarketing”, “ArtificialIntelligence”, and “BigData”, highlighting the integration and dependence on advanced technologies to enhance the effectiveness of digital marketing. The closed presence of “Ethics”, “Privacy”, and “Cookies” underscores the ethical and privacy concerns that arise from the intensive use of data.
Studies have shown that personalization and behavioral analytics, powered by Big Data and AI, can significantly increase the efficiency (Zong & Guan, 2024) but also pose risks to privacy and ethics by handling large volumes of personal data without adequate user consent (Custers et al., 2014). However, the presence of the variable “FakeContent” in close proximity to the center of this cluster (C1) highlights its relevance in terms of scientific studies in the literature and its connection to AI-based digital marketing strategies. This fact underscores researchers' concerns about the potential of AI-based digital marketing to create fraudulent content or to manipulate users automatically for commercial purposes or data point acquisition, among other objectives. Also, in C1, the “Metaverse” variable adds an emerging dimension to the cluster, showing how new digital frontiers can further complicate these concerns. The “Metaverse” represents an environment where digital interactions are amplified, making the protection of privacy and ethics in AI even more critical. This ethical concern is intensified by the proximity of the variables “SmartContent” and “Behavioral Analytics,” both can provide highly personalized and immersive experiences (Kamila et al., 2024), but also raise questions about content authenticity (Fake Content) and users control over their data (Kröger et al., 2022). These two practices in new digital environments can drive unethical behavior among companies (Literat & Brough, 2019), governments (Chang et al., 2018), or third parties (Fernández-Rovira et al., 2021). Therefore, the combination of these variables in C1 underscores a scenario where advanced technologies and digital marketing practices are linked to ethical and privacy concerns. This necessitates continuous attention and a balanced approach to ensure that the benefits of these technologies are not achieved at the expense of user rights and trust.
Similarly, C2 highlights “Surveillance” and “Real-time analysis”, emphasizing the current technologies' capability to monitor and analyze user behavior in real-time. Authors such as Andrew and Baker (2021) and Zuboff (2023) highlight concerns regarding surveillance of user behavior, and in the present study, the results support their interpretations due to lack of control, transparency, and understanding of automated processes. Then, surveillance and the collection of personal data for behavioral analysis raise serious concerns about privacy invasion and the ethical use of data. These events are primarily linked to the significant economic profitability that third parties could achieve by accessing such data (Campbell et al., 2020). Also, “Ethics” and “Privacy” are again prominent here, indicating the need to address these issues effectively to maintain consumer trust similarly, to prevent users from feeling that their behavior is being influenced. We agree on this point with research such as that of Paine et al. (2007) and Rudolph et al. (2018).
The third cluster (C3) underscores the interconnection between “SocialAds”, “PersonalizedAds”, and “SocialMediaPlatforms”. The focus on personalization and precise ad targeting relies on user “UserEngagement” and “PersonalData”. The literature suggests that personalization enhances the relevance and effectiveness of ads, but it can also be perceived as invasive, potentially leading to negative user reactions if not managed carefully. Regarding the personalized ads and content demanded by users on social media, is evidenced in C3. However, the identified clusters do not show evidence of a relationship between actions on social media and variables such as “Privacy” or “Ethics”, which are beyond the scope of C3 where these topics are addressed. However, C3 is indeed related to “PersonalData”, thus demonstrating the existing connection with users' personal data, though not specifically with their privacy. Authors such as Han et al. (2023) and Li et al. (2024) have also expressed concerns in this area.
At the same time, C4 groups variables related to “DataRisk” and “SecurityRisk”, highlighting the inherent dangers of “Data-drivenTechnology” and “Cross-DeviceTracking”. The results draw attention to the relative distances in Fig. 4 from the Biplot axes, where the variables of C4 Eigenvalues are notably distant in terms of relevance linked to AI-based Digital Marketing. In other words, the intelligence provided by AI to digital marketing makes it highly efficient in terms of profitability, thanks to “Cross-DeviceTracking” and “Data-DrivenTechnology.” However, our results show that the literature is not addressing the understanding of the connections between these variables and privacy or ethics in AI-based digital marketing. This analysis is critical because, without these variables being relevant in the central axis of the analyzed dimensions, significant theoretical and practical implications related to these variables may remain unexamined, contributing to a risk for the proper understanding of privacy in AI-based digital marketing.
Likewise, IoT amplifies these concerns by connecting multiple devices and increasing data collection points. The literature suggests that while these technologies can provide significant benefits in terms of efficiency and personalization, they also amplify security and privacy risks, requiring a robust and proactive risk management approach (Agha et al., 2023). However, these variables also appear distant from the center of the analyzed axes, especially far from “Privacy” and “Ethics”, despite being technologies that should be developed and studied considering the main privacy standards. Also, it is important to highlight that in Fig. 1, “Cross-DeviceTracking” appears alongside “Data-drivenTechnology”, “IoT”, “DataRisk”, and “SecurityRisk”, indicating a close relationship between these variables. This grouping suggests that cross-device tracking and data-driven technology are intrinsically linked to data risks and security, particularly in the context of IoT, where the interconnection of multiple devices amplifies privacy and security concerns.
Studies have shown (see Firouzi et al., 2020) that the expansion of connected devices and the integration of advanced technologies like IoT exponentially increase the data collection points, thereby increasing the vulnerabilities to which personal data is exposed. However, in Fig. 3 of the Biplot analysis, it has been observed that the “Metaverse” joins these issues, while “Data-drivenTechnology” and “Cross-DeviceTracking” disappear, thus leaving a cluster C4 composed of “Metaverse”, “DataRisk”, and “SecurityRisk”. This new configuration highlights the relevance of the “Metaverse” as an emerging environment where concerns about data privacy and security are critical. Therefore, “Metaverse”, by amplifying digital interactions and personalizing user experiences, introduces new dimensions of risk that need to be carefully managed from a privacy perspective.
Additionally, the Biplot reveals the formation of a new cluster (C5) that includes “BigData”, “Data-DrivenTechnology”, “Cross-DeviceTracking”, and “SmartContent”. This cluster reflects the interdependence of large volumes of data and advanced technologies for creating intelligent and personalized content. The relationship between these variables suggests that the use of “BigData” and “Data-DrivenTechnologies” is fundamental for developing content that is not only relevant but also optimized for multiple devices, maximizing the effectiveness of digital marketing. These variations between the figures underscore the complexity and dynamics of the relationships between emerging technologies and ethical and privacy concerns.
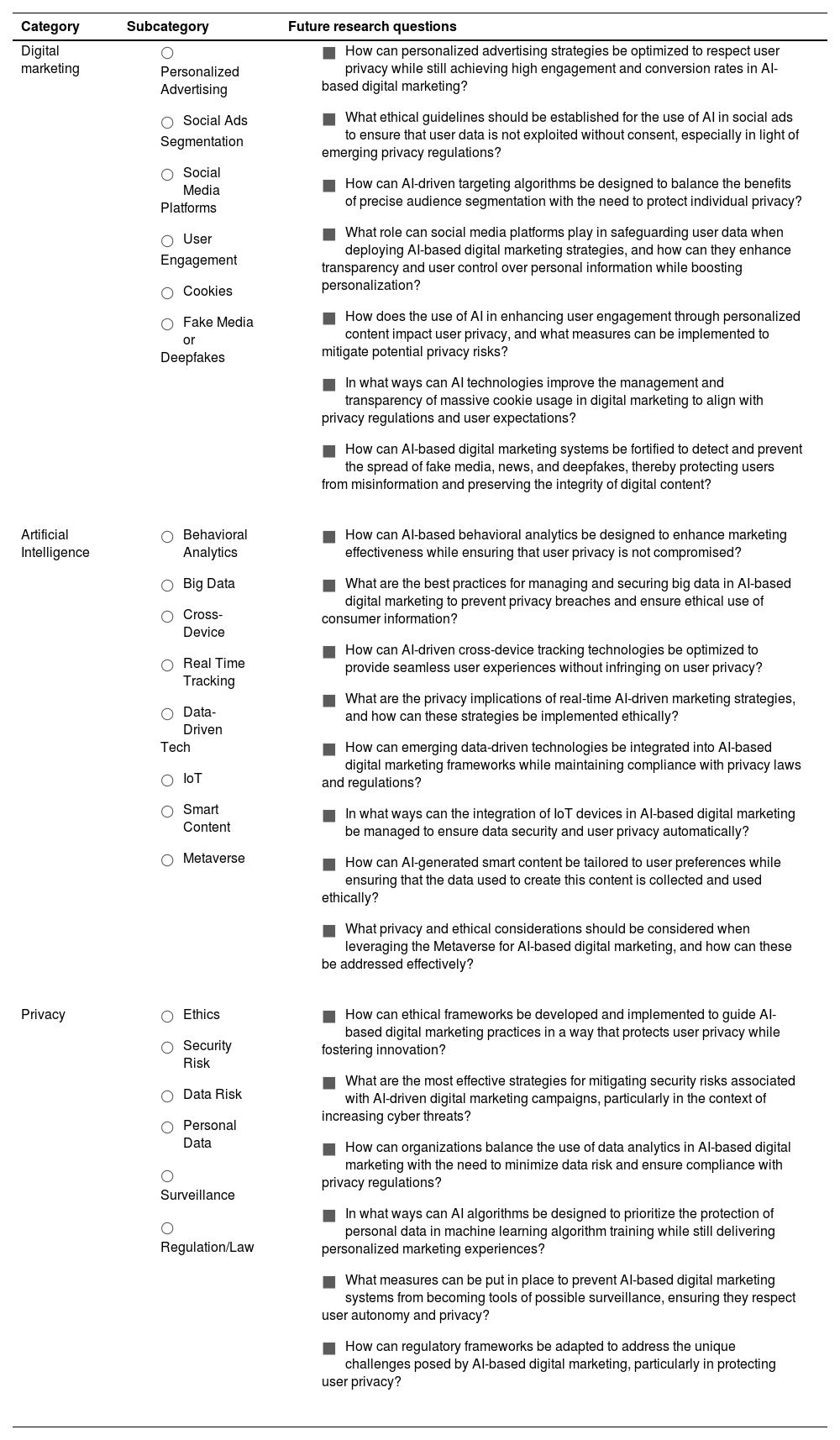
Future research agendaWith the aim of establishing a future agenda for the development and application of AI-based digital marketing strategies, Table 5 proposes a total of 21 future research questions to be explored in this field. The research questions are divided into 3 multivariate categories (Digital Marketing, Artificial Intelligence, and Privacy), which are the same variables identified as a result of the SLR and coded for computation in the MCA. Additionally, the subcategories within these variables, listed in the second column, are directly linked to the defined future research questions.
Future research questions on AI-Digital Marketing and privacy.
| Category | Subcategory | Future research questions |
|---|---|---|
| Digital marketing |
|
|
| Artificial Intelligence |
|
|
| Privacy |
|
|
Source: the authors.
After a thorough SLR to highlight significant contributions within the AI-based digital marketing, the present has developed an MCA within the framework HOMALS. This method allowed for the visual representation of data and the identification of significant correlations, culminating in distinct findings for the present study. To answer the RQ1 (How do the primary uses of AI-based digital marketing align with ethical standards and respect for user privacy?) this study has identified different theoretical perspectives on AI-based digital marketing, explored the principles of ethics in these marketing actions, and generated knowledge about the main uses of AI-based digital marketing strategies. A total of 3 multivariate groupings and 21 individual variables extracted from 28 studies were identified. After processing in the MCA with R, a total of 4 clusters were identified in the eigenvalues/variances analysis, and 5 clusters in the MCA with Biplot analysis. These results allowed for the examination of findings and their connections to the proposed objectives. Additionally, this study provides future guidelines for AI-based digital marketing practices by defining a total of 21 future research questions that ensure compliance with privacy laws and ethical standards, reinforcing the importance of maintaining user trust and integrity in digital interactions.
The findings emphasize the need for a balanced approach that respects user privacy and ethical use of data. However, it should be highlighted that no significant relationship is evident between the study of variables such as cross-device tracking or data-driven technologies and the ethics of AI-based digital marketing, despite these being the most profitable actions in this environment. The results also reveal intricate relationships between key variables in AI-based digital marketing and its ethical and privacy implications. Another finding is the capability of current technologies to monitor and analyze user behavior in real-time, raising serious concerns about privacy invasion and ethical data use. The balance between utilizing user data for personalization and maintaining user trust is critical, especially as personalized ads and social media platforms rely heavily on personal data and user engagement. However, these variables were not linked to any privacy or ethical node in the network, meaning that there is no evidence that links privacy standards or ethical perspectives and data personalization. The study emphasizes that while personalization increases digital ads effectiveness, it should be managed carefully to avoid negative user reactions.
The variables related to each other such as IoT, data-driven technologies, and cross-device tracking (C4) have not shown relationships with privacy or ethics variables. This fact raises serious concerns regarding the application of AI-based digital marketing when utilizing these variables. Therefore, the current study brings attention to the inherent risks of data-driven technology, including security and data risks associated with cross-device tracking and the IoT. These technologies, while beneficial for efficiency and personalization, increase massive data collection points and thus amplify the risk of privacy violations.
The inclusion of the Metaverse also highlights how emerging digital frontiers amplify these concerns, introducing new dimensions of risk. The central role of Big Data and data-driven technologies in creating personalized content points to the need for ethical and secure data management practices. Among the results, the strong proximity of the variable fake content with AI-based digital marketing underscores the critical need to ethically understand these technologies to advance automated processes. These variations stress the importance of continuously adapting security and privacy strategies to keep pace with technological advancements.
Finally, this research contributes significantly to the understanding of the complex interplay between AI-based digital marketing, ethics, and privacy in a current privacy paradox where users demand personalized content, but to offer it, enterprises should collect as much data as possible. This fact underscores the necessity of ongoing attention to these issues as technologies evolve. The study calls for future research to continue exploring these dynamics, particularly in emerging areas, to develop robust frameworks that protect user privacy while leveraging the benefits of AI in digital marketing. This balanced and proactive approach is crucial for sustainable and ethical advancement in the digital marketing landscape.
Theoretical implicationsThe present study presents some theoretical implications related to AI-based digital marketing. In this way, the integration of advanced technologies such as AI and Big Data within AI-based digital marketing strategies highlights the reliance on data-driven decision-making processes. This approach enhances marketing effectiveness by enabling personalized consumer interactions and precise targeting. However, the study reveals a critical disconnect between these technological advancements and ethical principles, notably in the domains of user privacy and data ethics.
Despite the potential benefits of AI in enhancing marketing efficiency, concerns persist regarding the ethical use of personal data and the transparency of automated decision-making processes. Therefore, research is needed on how the automation and training of AI algorithms used in digital marketing can either contribute to or mitigate risks to user privacy. Therefore, theoretical perspectives like Hildebrandt (2008) on data protection and autonomy suggest that AI-driven marketing practices should respect individual autonomy and adhere to principles of fairness in data processing. Theoretical frameworks such as Nissenbaum's contextual integrity theory emphasize the importance of respecting contextual norms and values in data practices, suggesting that AI-driven personalization should align with societal expectations of privacy and fairness (Nissenbaum, 2009). Also, theoretical perspectives from critical data studies emphasize the need for a critical stance on the governance and regulation of digital environments, advocating for policies that safeguard user rights while fostering innovation. Furthermore, the present study challenges the traditional views on data ownership in digital marketing. It suggests a shift toward a more user-centric model where consumers have greater control over their data, and companies operate with a “data stewardship” mindset rather than mere data ownership. This shift not only has ethical implications but also necessitates a rethinking of how digital marketing strategies are designed and implemented, especially when using AI to drive engagement and personalization. Theoretically, this aligns with the growing discourse on “data dignity” which calls for treating user data as an extension of personal identity, requiring ethical handling and processing.
Finally, the operationalization of real-time tracking and behavioral analytics as central components of AI-based digital marketing is highlighted. These practices facilitate dynamic user profiling and content customization, optimizing user engagement and conversion rates. However, the proximity of these variables to surveillance and data collection practices raises significant ethical dilemmas concerning user autonomy and consent. This dilemma points to a gap in current theoretical models that fail to adequately address the dual role of AI-based digital marketing as both, a tool for business success and a potential risk to user autonomy. Future theoretical explorations should focus on developing frameworks that balance these opposing forces, incorporating principles of ethical AI use and transparent data governance to safeguard consumer rights in increasingly complex digital ecosystems.
Practical implicationsThe theoretical insights into AI-based digital marketing suggest several practical implications for industry and policymakers. Firstly, businesses leveraging AI algorithms in digital marketing should prioritize transparency and user consent in data collection and processing practices. Implementing clear policies and user-friendly interfaces that inform consumers about how their data is utilized can foster trust and mitigate concerns about privacy violations. Secondly, organizations should invest in robust data governance frameworks that align with regulatory requirements and ethical principles. This includes adopting “privacy-by-default” and “privacy-by-design” approaches that integrate privacy considerations into developing and deploying AI technologies. Once privacy protections at the outset of product design have been implemented, businesses can proactively address risks associated with AI-driven data analytics and personalized marketing strategies. In addition, companies need to emphasize user education, informing individuals about how AI-based marketing strategies operate and how their data is being utilized. If these strategies are correctly developed, users can make more informed decisions about the data they share, creating a more transparent and trust-based interaction between companies and consumers.
Moreover, there is a growing imperative for interdisciplinary collaboration between technologists, ethicists, and legal scholars to develop comprehensive guidelines and best practices for AI-based digital marketing. This collaboration can facilitate the development of ethical guidelines that balance innovation with user protection, ensuring that AI technologies contribute positively to consumer welfare and societal well-being. Such guidelines should address complex issues like real-time tracking, behavioral analytics, and cross-device monitoring, providing a clear framework for what constitutes ethical use of these technologies. Furthermore, businesses should develop mechanisms to allow users to easily opt out of data collection practices, thus giving them greater control over their personal information. This would align with ethical standards and respect for user privacy, fostering a more ethical AI-based marketing environment. Therefore, continuous monitoring and evaluation of AI systems in digital marketing are essential to identify and mitigate potential biases and discriminatory outcomes. Implementing algorithmic audits and regular impact assessments can help organizations detect and address unintended consequences of AI applications, thereby promoting fairness and equity in digital marketing practices.
From a policy perspective, there is a critical need for regulations that specifically target AI-based digital marketing practices. Current data protection laws, such as the GDPR, provide a foundation but may not adequately address emerging automated AI-driven technologies. Policymakers should consider drafting specific guidelines requiring transparency in AI operations, mandating that companies disclose the extent of data collection, and the mechanisms used to target and personalize marketing content. Furthermore, legislation should enforce the adoption of “privacy-by-default” principles in the development of AI technologies, ensuring that ethical considerations are embedded within the algorithms and data processing methods from the outset. Additionally, regulatory bodies should develop a certification system for AI-based digital marketing practices, similar to certification marks, to signify compliance with ethical standards and data privacy regulations. This new certification would not only act as a marker of ethical business practices but also provide consumers with a clear indicator of which companies adhere to privacy and ethical norms in their marketing strategies. Regular audits by these regulatory bodies should be enforced, requiring companies to demonstrate adherence to privacy laws and ethical guidelines. This ongoing oversight would help maintain high standards within the industry, prevent misuse of AI in marketing, and ensure consumer rights are protected in the evolving digital landscape.
LimitationsThis study on AI-based digital marketing and its ethical implications has several limitations that should be acknowledged. Firstly, the research primarily relies on a SLR and MCA which means the findings are contingent upon the quality and scope of the existing literature. The SLR methodology, while comprehensive, is limited by the inherent biases and gaps in the available studies, which may affect the generalizability of the results. Secondly, the study focuses on theoretical and conceptual analysis rather than empirical validation. The lack of primary data collection means that the practical applicability of the theoretical insights and frameworks proposed remains untested in real-world settings. Future research should aim to validate these findings through empirical studies involving direct engagement with stakeholders in digital marketing and AI fields.
Authors contributionConceptualization: JRS, VS and DOD. Data curation: JRS, Formal analysis: JRS, VS and DOD; Methodology: JRS; Resources: JRS, VS and DOD: Software: JRS: Supervision: VS and DOD: Validation: VS and DOD: Visualization: JRS: Roles/Writing - original draft: JRS, VS and DOD: Writing - review & editing: JRS, VS and DOD.+