







This study compares data collection approaches in the assessment of grammatical development in Spanish-speaking children. Specifically, we compared error rates produced in data collected using samples from spontaneous language versus elicited production, using both broad (overall) and narrow measures (errors with noun phrases).
Methods and participantsMonolingual-Spanish-speaking five-year-olds (n=55) were divided into typical language development (TL) and at-risk (Risk) according to a preexisting test, Tamiz de Problemas del Lenguaje. All children completed an elicited production and a narrative task.
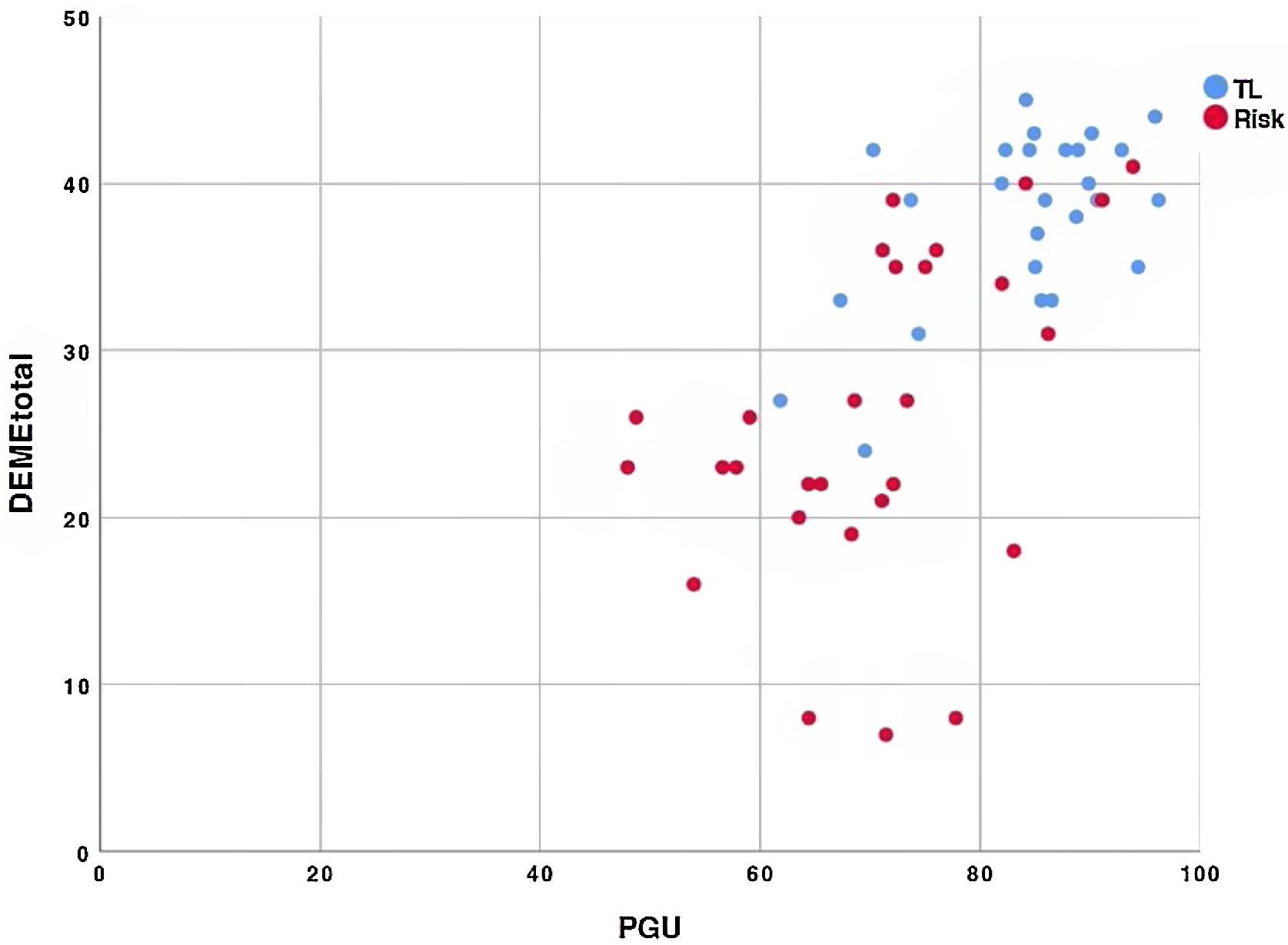
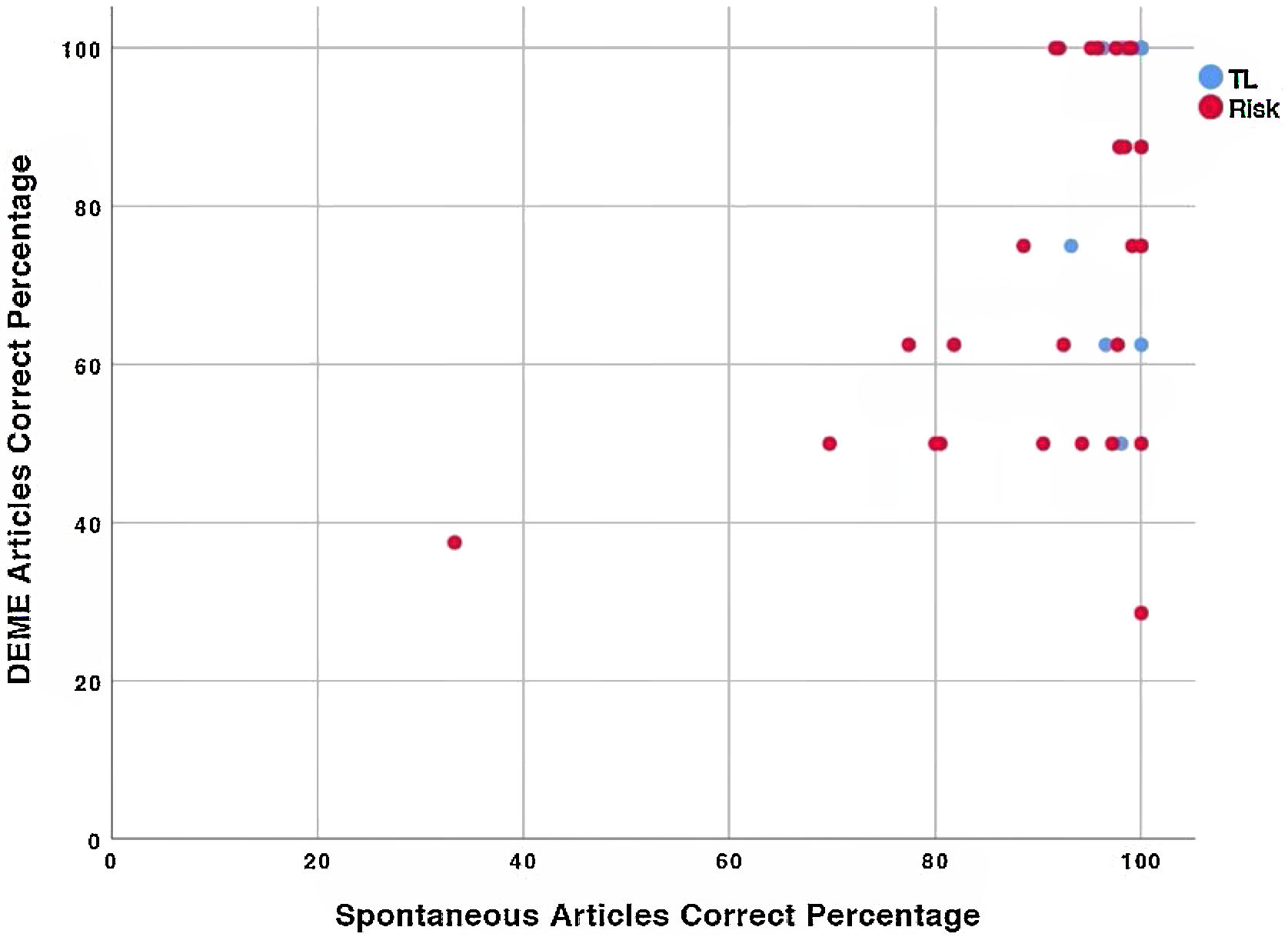
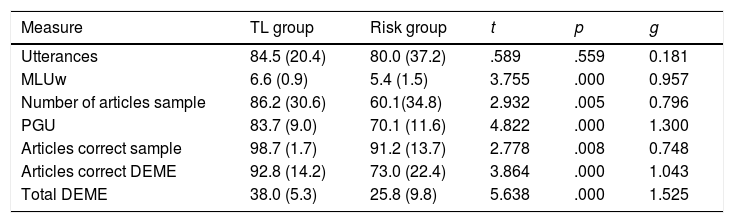
ResultsChildren in the TL group outperform children in the Risk group in all measures used in this study. Statistically significant differences were found between children at Risk and TL children in both spontaneous and elicited language measures, although the effect size of the elicited language measures was considerably higher. Elicited and spontaneous tasks are more likely to produce results that are in accord than in disaccord. However, when results are in disaccord, the results almost always show low performance in elicited language but high performance in spontaneous language. Elicitation methods do not seem to have an impact on the type of error produced for neither narrow nor broad measures.
Este estudio compara los enfoques de recolección de datos para la evaluación del desarrollo gramatical en niños que hablan español. Específicamente, comparamos las tasas de error producidas usando muestras de lenguaje espontáneo versus la producción elicitada, usando medidas generales (todos los errores) y específicas (errores con frases nominales).
Métodos y participantesLos niños monolingües de cinco años de habla hispana (n=55) se dividieron en dos grupos: desarrollo del lenguaje típico o a riesgo de desórdenes del lenguaje, para lo cual se usó el Tamiz de Problemas del Lenguaje. Todos los niños completaron una producción del lenguaje elicitada y una tarea narrativa.
ResultadosLos niños del grupo típico superan a los niños del grupo a riesgo en todas las medidas utilizadas en este estudio. Se encontraron diferencias estadísticamente significativas entre los niños a riesgo y los niños típicos en las medidas de lenguaje espontáneo y elicitado, aunque el tamaño del efecto de las medidas de lenguaje elicitado fue considerablemente mayor. El lenguaje elicitado y espontáneo producen mas resultados que están de acuerdo que en desacuerdo; sin embargo, cuando los resultados están en desacuerdo, casi siempre muestran un bajo rendimiento en el lenguaje elicitado pero un alto rendimiento en el lenguaje espontáneo. Los métodos de obtención no parecen tener un impacto en el tipo de error producido ni para medidas específicas ni amplias.


